动态演讲视频的多模态话语分析
2017-08-16管乐
管 乐
(1.中山大学南方学院国际学院,广州 510970;2.广东外语外贸大学英文学院,广州 510420)
动态演讲视频的多模态话语分析
管 乐
(1.中山大学南方学院国际学院,广州 510970;2.广东外语外贸大学英文学院,广州 510420)
运用Lim提出的“综合性多符号模式框架”和张德禄提出的“基于系统功能语言学理论设计的动态多模态话语分析框架”,对动态演讲视频进行多模态话语分析。研究发现:在演讲视频中,语言、声音特征、表情、手势、姿势和动作都是建构整体意义的重要资源;在动态演讲多模态话语中,演讲者的语言模态为主模态;为了构建整个交际事件的整体意义,还需要运用其他模态相互协调、相互补充和相互配合。文章对于演讲爱好者了解演讲中不同的模态是如何来实现话语意义以及如何提高演讲水平具有一定的指导作用。
TED演讲视频;多模态话语;模态
近年来,随着多模态话语研究的深入,研究者开始注意到语言符号虽然对语篇意义的生成有显著作用,但是视觉符号对语篇的意义生成也起着重要的作用。多模态语篇分析是由O’Toole[1]开创的一种新的语篇分析模式。Kress 等[2]指出多模态语篇是任何通过一种以上符号编码实现意义的语篇。该理论已应用于多种媒体分析,如:Baldry等[3]运用多模态语篇分析了媒体、网页、电影和广告等;Knox[4]运用系统功能符号学对网页进行了研究;Martinec等[5]把多模态语篇分析运用到电影海报、广告和照片等语篇中,证明了该理论框架的可行性。
张德禄[6]指出多模态语篇是运用听觉、视觉、触觉等多种感觉,通过语言、图像、声音、动作等多种手段和符号资源进行交际的现象。由此可见,演讲视频是综合了包括语言、图像、声音、空间和身体动作等多种符号来实现语篇整体意义的多模态语篇。从国外的学者对演讲的研究来看:Rendle-Short[7]对学术演讲中肢体语言和语言使用进行了研究,发现两者之间存在复杂的关系;Morton[8]对学术演讲的体裁进行了分析。从国内对演讲的研究来看,它们主要从语用学和外语教学的角度研究了演讲视频,例如:徐珊[9]从语用学的角度探讨演讲视频中虚假语用预设的功能研究,曹井香等[10]运用TED模式的英语演讲任务激发学生使用英语的热情。目前运用多模态话语分析动态演讲视频的研究还比较少。本文以声音专家Julian Treasure在TED大会中关于如何保持听力的演讲为研究对象*本文所分析的视频及相关语料来自于网页:http://ielts.zhan.com/tifen/32783.html.,结合Lim[11]提出的“综合性多符号模式框架”和张德禄[6]提出的“基于系统功能语言学理论设计的动态多模态话语分析框架”,对此动态演讲视频进行多模态话语分析。
一、动态多模态话语分析框架
张德禄根据Halliday的系统功能语言学,结合 Lim提出的综合性多符号模式框架,提出了一种动态多模态话语分析综合理论框架,该框架由文化语境层面、情景语境层面、内容层面和表达层面四个层面组成,如图1所示。[6]从该框架来看,在一定文化语境的影响下,讲话者话语意义的表达要受到意识形态和体裁系统的制约,同时还需根据所处的情景语境和交际目的来选择表达的话语意义[12]。在表达话语意义的过程中,讲话者需要根据体裁结构运用合适的交际模态将选择的意义体现出来。选择的意义主要包括图像意义和声音意义。其中,图像意义通过视觉模态以及相关特征体现出来,声音意义通过听觉模态以及相关特征体现出来。在体现意义的同时,关键是要注意各模态之间是否相互协调、相互补充和相互配合以构建话语整体意义。不同的模态体现的意义属于同一个交际事件,需要整合为一体才具有交际意义[12]。张德禄把不同模态话语之间的关系总结为互补和非互补两大类,互补关系可分为强化和非强化,非互补关系可分为交叠、内包和语境交互关系[6]。

图1 动态多模态话语分析框架
随着时间的变化,不同模态话语之间的关系也会随之出现动态变化。有时语言在话语整体构建中是主要的交际形式,手势、姿势、音乐等其他模态对语言起强化作用。视觉模态和听觉模态之间的关系变化与整个话语建构关系密切。总之,动态多模态话语分析框架主要研究动态多模态语篇中图像、文字以及话语之间的多模态关系[6]。
二、语料和研究方法
(一)语料
TED是技术(technology)、娱乐(entertainment)、设计(design)三个英语的缩写,它是美国的一家私有非营利机构,TED大会的宗旨是向人们传播“值得传递的新思想、新信息、新观点”。从2006年起,TED总裁克里斯·安德森决定将录制的演讲资源制作成TED Talks上传至互联网,全球的观众可以免费下载和观看精彩的演讲视频,如今TED大会全球访问量超过40亿,这种以“互联网+演讲”的模式掀起了TED演讲传播的热潮。作为TED主题之一的教育类演讲一直是最受关注的演讲话题之一。著名的声音专家Julian Treasure在TED 的演讲讲坛中的一次讲演视频在互联网上被大量转载,点击率超过了100万次。*截至2016年11月23日笔者登录TED该视频的网站时,该视频的点击量已达1,017,673次;该视频的网址为:http://www.ted.com/talks/julian_treasure_shh_sound_health_in_8_steps.本文选取的语料是声音专家Julian Treasure在TED大会中关于如何保持听力健康的演讲,此次演讲持续的时间并不长,只有7分9秒,但却给所有观众留下了深刻的印象。
(二)研究方法
本文运用动态多模态话语分析框架(图1),从文化语境、情景语境和模态间的关系来分析动态演讲视频的多模态话语。以下是张德禄提出的对动态多模态语篇进行切分的三个标准[13]:首先,作为切分话语单位的主要标准,语篇的每一个主题由多个部分或阶段组成,每个阶段又分为多个次要单位;然后根据语篇过程的发展,找到语篇主题发生变化的转折点,这个转折点可作为切分单位的边界,同时转折点又引发新的语篇内容,包括参与者和情景成分的变化;最后与语篇主题相关的处于前景的事物和特征是进行切分的重点对象。张德禄[13]指出在语篇层面,每个图像可以实现一个事件,一系列交际事件形成一个情节,几个情节可以组成一个故事或者一个语篇。在演讲视频中,根据演讲语篇的发展,可分为演讲开头、演讲主题阐述、演讲高潮和结束四个部分,每一个部分由若干个情节构成。本文依据张德禄[13]提出的以上三个标准对Treasure的演讲视频进行切分。
按照张德禄[14]提出的语篇切分方法,Julian Treasure的这段演讲视频的体裁结构包括9个阶段,这9个阶段分成19个步骤和22个情节以及25个事件和25个图像,可见每个阶段由若干个步骤构成,每个步骤可分为若干个情节,每个情节可分为若干个事件,事件通过图像来实现,每一个图像标志着一个语篇单位、一个语法过程和一个信息单位[14]。Julian Treasure的这段动态演讲视频切分结果如图2所示:
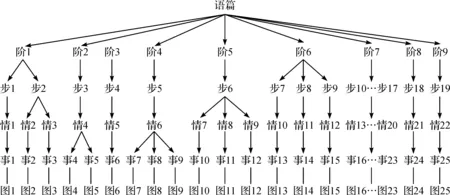
图2 动态演讲视频切分
三、动态演讲视频的多模态分析
(一)文化语境
文化语境包括文化习俗和社会规范两个方面,是指与言语交际相关的社会文化背景[14]。前者是指人们在语言、行为和心理上的集体习惯或生活模式,后者是指一个社会对言语交际活动作出的各种规定和限制。根据交际的目的,文化语境决定了话语交际的目的。
演讲是指在公众场所,以有声语言为主要手段,以体态语言为辅助手段,针对某个具体问题,鲜明、完整地表达自己的见解和主张,阐明事理或抒发情感,进行宣传鼓动的一种语言交际活动[15]。随着科技的发展,演讲者还可以借助多媒体技术进行图像的演示。近年来TED所推出的通过视频传播新思想的演讲模式受到了广大观众的热捧,TED总裁安德森宣传要像拍电影一样打造18分钟的极致演讲视频,所有TED演讲长度需在18分钟之内,因为如果超过了18分钟就很难抓住观众的注意力,观众通过“注意力之争”能够认真地听完全部演讲内容从而获取演讲中有价值的信息。
本文选取的是Julian Treasure在TED会议上关于如何保护听力健康的演讲。在这个日益嘈杂的世界中,人们正逐渐丧失聆听的能力。在这场简短而引人入胜的演讲中,Treasure指出了噪音和戴耳机给人们听力造成的危害,同时介绍了三种保护听力的方法,提出了八种可以改善听力健康的方法,在短短的7分钟时间里,演讲主题鲜明、思路清晰、内容丰富。Julian Treasure本次演讲的体裁结构总共包括九个阶段:演讲开头(一个阶段)、演讲主题(三个阶段)、演讲高潮(四个阶段)和演讲结尾部分(一个阶段)。
1)演讲开头:演讲者从健康的定义过渡到讲述耳朵的作用。
2)演讲主题1:耳朵的功能。
3)演讲主题2:噪音的危害。
4)演讲主题3:耳机的危害。
5)演讲高潮1:三种简单的保护听力的方法。
6)演讲高潮2:耳朵的三个“好朋友”。
7)演讲高潮3:提出了八种可以改善听力健康的方法。
8)演讲高潮4:七件改善你们的听觉健康的事情。
9)演讲结尾:演讲者的祝愿和致谢。
(二)动态演讲视频的情景语境分析
根据系统功能语言学理论,情景语境是文化语境的一个重要内容。情景语境主要包括语场三个变项: 语场(field)、语旨(tenor)和语式( mode)。语场是指语篇所涉及的具体内容;语旨是指参加者的身份和他们之间的社会角色关系、交际双方的关系;语式是指语言在具体环境中所起的作用,即交际的媒介和渠道。Julian Treasure本次演讲的语场是2010年7月在美国TED会议上的对如何保护听力的一次演讲;语旨是美国TED大会媒体,声音专家Julian Treasure和在场的观众;语式是美国TED大会通过网络向全球免费播放由著名声音专家Julian Treasure进行的演讲,演讲者穿着得体、用词专业、语速平缓、语言流利,演讲者主要通过声音模态来传递关于如何保护听力的主题,同时综合了演讲者的身体模态、姿势模态、手势以及版面布局模态、图像模态等共同构建动态演讲视频的多模态意义。
(三)动态演讲视频的多模态话语分析
本节按照Julian Treasure演讲视频的开头、演讲主题、演讲高潮和演讲结束四个部分所体现的模态关系进行分析。
1.动态演讲视频开头部分
在演讲的开头部分,Julian Treasure面带笑容,目光正对观众,手拿着多媒体演示器走上了TED演讲的讲台。然后演讲者通过语言模态,伴随着手势模态(双手伸开)指出人身体中的每一部分都在以不同的频率振动,此时手势模态是一种辅助手段,属于次要模态。接着Julian Treasure通过多媒体演示工具呈现出一张图像,此时视觉模态通过图像成为主要的交际形式,声音模态起强化作用,在图像出现的同时还伴随着音乐模态,此时听觉模态和视觉模态共同表达交际者的整体意义(事件1),缺一不可,图像和声音(音乐)构成了典型的相互协调的模式。从事件2来看,观众通过主模态即视觉模态了解了耳朵的主要功能,同时演讲者的语言模态只是起强化作用的辅助模态。从事件3来看,演讲者的声音模态和手势模态以及图像构成的视觉模态三者互为协调,共同为阐述耳朵的另外一个重要功能这一交际事件服务,这三种模态之间的关系属于非强化协调关系。动态演讲视频开头部分的多模态话语分析见表1。

表1 动态演讲视频开头部分的多模态话语分析
2.动态演讲视频主题部分
在动态演讲视频的主题部分,声音专家Julian Treasure主要以提供信息型的模式讲述了三个重要问题:一是耳朵的功能,包括删减性的倾听和扩展式倾听(事件4和事件5);二是噪音的危害(事件6);三是耳机的危害,包括幻听(事件7)、压缩音乐(事件8)和耳聋(事件9)。下面就演讲的主体部分的模态进行分析。
从情节4来看,Julian Treasure主要通过视觉模态中的文字模态即海明威的一句名言,向观众说明了认真倾听是一种主动技能,视觉模态为主模态,语言模态对听觉模态具有强化互补作用,目的是告诉观众倾听是处理声音与声音之间的关系,也是一种与生俱来的能力,从而引出事件4和事件5的内容,即不同的倾听姿势对获取信息的影响。从事件4和事件5来看,听觉模态是主模态,演讲者使用语言模态的同时,运用图像即视觉模态来补充说明删减性的倾听(reductive listening)和扩展性的倾听(expansive listening),形成非强化协调关系。从事件6来看,演讲者双手慢慢抬起,表情严肃,此时的话语类型属于提醒注意类。演讲者运用表情模态和手势模态提醒观众要对噪音的危害引起重视,因为噪音正在降低欧洲总人数25%的人口的健康和生活质量,可见表情模态和手势模态对语言模态具有强化突出作用。通过视觉模态,演讲者运用图像扩充语言表达的意义,此时的视觉模态对听觉模态具有强化补充作用。从事件6来看,演讲者用图像指出了人们摆脱噪音的方法即戴耳机,这时视觉模态是主模态,听觉模态与视觉模态之间是互补非强化协调关系。事件7到事件9演讲者分别讲述了耳机给人们带来的三大严重的健康问题:幻听(事件7)、压缩音乐(事件8)、耳聋(事件9)。在构建事件整体意义的时候,听觉模态和视觉模态相互结合,演讲者运用图像详细说明了三大健康问题,图像模态和声音模态相互配合、相互协调,共同体现交际意义。动态演讲视频主题部分的多模态话语分析见表2。

表2 动态演讲视频主题部分的多模态话语分析
表2续

动态演讲视频多模态话语分析(主题部分)语篇意义听觉模态视觉模态其他模态前景化多模态特征事件8:压缩音乐主模态互补非强化协调文字模态(非强化协调)听觉模态视觉模态事件9:耳聋主模态互补非强化协调文字模态(非强化协调)听觉模态视觉模态
3.动态演讲视频高潮部分
在动态演讲视频的高潮部分,Julian Treasure主要以提供信息型的模式介绍了保护听力的三种方法,耳朵的三个“好朋友”,八种可以改善听力健康的方法和七件改善听觉的方法,演讲涉及的内容非常丰富。动态演讲视频高潮部分的多模态话语分析见表3。从表3来看,在动态演讲的高潮部分,听觉模态始终处于前景化位置,为主模态。在介绍保护听力的三种方法的时候,演讲者运用听觉模态的同时,使用图像即视觉模态对听觉模态进行补充说明,声音和图像是构建交际整体意义的重要部分,两者相互协调共同起作用。在演讲的高潮部分,演讲者以语言模态为主要模态、图像模态与观众听觉模态三者的互补非强化协调关系,三者的协调使用更能吸引观众的注意力,使演讲在高潮部分推进和深化主题,引人入胜。

表3 动态演讲视频高潮部分的多模态话语分析
从事件12来看,观众通过视觉模态看到了三个字母“WWB”,接着演讲者通过语言模态和图像中的声音模态对“WWB”进行了解释,即wind、water和bird,这三种大自然的声音对健康十分有利。图像作为背景出现的同时,风、水和鸟的声音处于前景化,从而使音乐模态在整个交际意义中突显出来,因此音乐模态起强化突出的作用。从事件13和事件14来看,演讲者头部稍偏左,手握多媒体演示器,表情沉默,没有发出任何声音,此时演讲者的视觉模态处于前景化的位置,表情模态和手势模态起互补强化作用,突出了演讲的高潮之一“保持沉默也是耳朵的好朋友”。从事件15来看,演讲者运用语言模态详细讲解了七件改善听觉健康的事情,本部分讲解的速度比较快,所以演讲者在运用语言模态的同时,还运用了带有文字模态的图像,演讲者的语言模态、文字模态以及观众的听觉模态三者之间互补协调,表达了交际事件的整体意义,取得了最佳的交际效果。
4.动态演讲视频结尾部分
在动态演讲视频的结尾部分,演讲者运用语言模态表达了对观众的美好祝福,祝愿大家听力健康,同时伴随着音乐模态即小鸟的歌声结束了此次演讲。从模态分布来看,听觉模态是主模态,处于前景化,图像视觉模态以及音乐模态对听觉模态进行补充形成非强化协调关系,使演讲的结尾部分精炼、生动,升华了演讲的主题,格外具有启发性和感染力。动态演讲视频结尾部分的多模态话语分析见表4。

表4 动态演讲视频结尾部分的多模态话语分析
四、结 语
本文通过动态多模态话语分析框架,从演讲视频的开头部分、主体部分、高潮部分和结尾部分对声音专家Julian Treasure共7分钟的演讲视频进行了详细的多模态话语分析,主要有以下三个方面的发现:
a)在演讲的整个过程中,演讲者的语言模态为主模态,始终处于前景化位置。
b)为了取得最佳的演讲效果使演讲更具感染力和启发性,在演讲的主题部分和高潮部分,演讲者为实现交际事件的整体意义,还综合运用了音乐模态、文字模态、图像模态、手势模态对语言模态进行互补或强化,语言主模态与其他不同模态之间主要属于互补非强化协调关系。
c)为了使整个演讲内容更加深刻和富有条理,在演讲的开头和结尾,演讲者都使用了相同的音乐模态,首尾照应;音乐模态作为语言模态的补充,两者形成了非强化协调关系,加深了观众的印象。
动态演讲视频的多模态话语分析,对演讲爱好者了解演讲中不同的模态实现话语意义的方式以及提高演讲水平具有指导作用。本文的研究拓展了多模态话语分析理论的研究范围,在后续的研究中将通过不断地实践来验证和发展该理论,推动多模态话语研究的发展。
[1] O’ TOOLE M. The Language of Displayed Art [M]. London: Leicester University Press,1994.
[2] KRESS G, VAN LEEUWEN T. Reading Images: The Grammar of Visual Design [M].2nd ed. London: Routledge, 2006.
[3] BALDRY A, THIBAUL P J. Multimodal Transcription and Text Analysis: A Multimedia Toolkit and Course Book with Associated Online Course[M]. London: Equinox,2006.
[4] KNOX J. Visual-verbal communication on online newspaper home pages [J].Visual Communication,2007(6):19-53.
[5] MARTINEC R, VAN LEEUWEN T. The Language of New Media Design: Theory and Practice [M].London: Routledge,2007.
[6] 张德禄.多模态话语分析综合理论框架探索[J].中国外语,2009,6(1):24-30.
[7] RENDLE-SHORT J. Managing the transitions between talk and silence in the academic monologue [J]. Research on Language and Social Interaction,2005,38(2):179-218.
[8] MORTON J. Genre and disciplinary competence: A case study of contextualization in an academic speech genre[J]. English for Specific Purposes,2009,28(4):217-229.
[9] 徐珊.虚假语用预设视角下的TED演讲言语幽默的生成机制解析[J].西南科技大学学报(哲学社会科学版),2014,31(6):78-89.
[10] 曹井香,王丽莉,张婉云.TED模式大学生英语演讲课程任务设计与实践[J].外语教育研究,2015,3(4):14-17.
[11] LIM F V. Developing an integrative multi-semiotic model [C]// L. O’Halloran (Ed.). Multimodal Discourse Analysis: Systemic-Functional Perspectives. London: Continuum,2004:220-246.
[12] 张德禄,袁艳艳.动态多模态话语的模态协同研究:以电视天气预报多模态语篇为例[J].山东外语教学,2011,32(5):9-16.
[13] 张德禄.多模态外语教学的设计与模态调用初探[J].中国外语,2010,7(3):48-53.
[14] 阳卓胜.谈谈语境在翻译中的作用[J].英语广场(学术研究),2014(7):52-53.
[15] 武宏伟.演讲、朗诵与讲故事[J].语文建设,2011(9):75-77.
(责任编辑: 任中峰)
Multimodal Discourse Analysis of Dynamic Speech Video
GUANYue
(1.International School, Nanfang College of Sun Yat-Sen University, Guangzhou 510970, China;2.School of English Studies, Guangdong University of Foreign Studies, Guangzhou 510420, China)
Based on Lim’s comprehensive multi-semiotic framework and Zhang Delu’s dynamic multimodal discourse analysis framework, this paper analyzes the multimodal discourse of dynamic speech video. It is found that the modes of language, voice, facial expressions, gestures, posture and movement are important resources for construing the meaning of speech. In the dynamic multimodal speech discourse, the speaker’s language mode is the main mode. In order to construct the whole meaning of the communicative event, it is necessary to coordinate and complement other modes. This study will help speech enthusiasts to understand how to achieve the discourse meaning with different modes and improve speech skills.
TED speech video; multi-modal discourse; modes
10.3969/j.issn.1673-3851.2017.02.004
2016-10-19 网络出版日期:2017-01-03
广东高校重大项目:青年创新人才类项目(社科类)(2015WQNCX190) ;广州市哲学社会科学发展“十二五”规划课题(15G76);广东省哲学社会科学“十三五”规划“外语学科专项”重点项目(GD16WXZ33)
管 乐(1980-),湖南湘潭人,讲师,硕士,2016-2017年广东外语外贸大学访问学者,主要从事外国语言学及应用语言学方面的研究。
H03
A
1673- 3851 (2017) 01- 0025- 08
