基于人工免疫结合余弦相似度的病毒特征提取算法
2017-08-12杨应华
杨应华 夏 勇
1(兰州财经大学信息中心 甘肃 兰州 730020) 2(西北工业大学计算机学院 陕西 西安 710129)
基于人工免疫结合余弦相似度的病毒特征提取算法
杨应华1夏 勇2
1(兰州财经大学信息中心 甘肃 兰州 730020)2(西北工业大学计算机学院 陕西 西安 710129)
针对现有计算机病毒特征提取算法无法有效提取未知病毒和变种病毒的特征,本文借鉴人工免疫思想,提出一种基于人工免疫结合余弦相似度的病毒特征提取算法。在代码层,算法采用TF-IDF对病毒DNA进行趋向性提取建立病毒候选基因库;在基因层,算法利用可变r匹配规则提取病毒候选基因库生产病毒检测基因库;在程序层,算法采用余弦相似度算法评估待测程序与病毒的相似度,对待测程序进行识别。经仿真实验,本算法与其他病毒特征提取算法相比,在较低虚警率的情况下有较高的病毒识别率。
人工免疫 特征提取 TF-IDF算法 可变r匹配 余弦相似度
0 引 言
传统计算机反病毒技术是以病毒特征码为检测基础,对已知病毒有较高的识别率。但对未知或变异病毒缺乏有效识别。人工免疫系统[1]可通过类似生物免疫的机能,构造强大的信息处理能力,以区分“自我”与“非我”,这种区分非我的功能与计算机病毒的识别颇为相似[2-3]。针对于此,国内外学者提出了基于人工免疫系统的计算机病毒识别模型[4-6],其中,阴性选择算法[7-8]及其改进算法成为基于人工免疫系统的病毒识别算法的代表。文献[9]提出了一种具有疫苗算子的可变模糊匹配阴性选择算法,基于模糊思想并采用疫苗理论,对建立特异性免疫应答具有自适应性。文献[10]提出了一个基于带有惩罚因子的阴性选择算法的恶意程序检测模型,在阴性选择算法中引入惩罚因子,摆脱了传统阴性选择算法中对“自体”和“异体”有害性定义的缺陷,对完全未知的恶意程序具有较高的识别率。文献[11]提出了一种可变模糊匹配阴性选择算法,通过调整匹配阂值降低黑洞数量,利用模糊思想,实现连续相似度的模糊匹配,使病毒的检测范围加大,病毒识别率进一步提高。改进算法在自适应和病毒检测率上有一定的提升,但缺少对检测关联的深入挖掘,病毒的识别率有待进一步的提高。
针对以上问题,本文在借鉴前人研究成果的基础上,提出了一种基于人工免疫相关思想结合余弦相似度算法提取病毒特征,充分利用了关键特征的关联性,提升算法的检测效率。
1 病毒特征选择
1.1 选择病毒特征
计算机病毒自身机理与生物学中的病毒相似,受生物免疫系统对病毒查杀的启发,将生物领域中的研究应用到计算机中。病毒的特征主要存放在其DNA中,DNA由许多不同的基因组成,而基因又是由若干脱氧核苷酸(ODN)组成,结合生物研究结论,将计算机病毒中所用到的生物术语定义如下:
(1)DNA:计算机病毒整个程序的代码;
(2) 基因:代表计算机病毒特征的字符串;
(3) 脱氧核苷酸:计算机病毒中每2 B字符串。
决定计算机病毒作用的关键代码往往只有少许片段,如何定位并提取关键代码是病毒特征提取的关键。本文引进ODN浓度作为平衡因子采用TF-IDF特征词定位算法对计算机病毒的关键代码进行定位提取。训练集合为Q,所用变量定义如下:
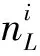
(1)
(2)
根据上式的结果可以得出ODNi的TF-IDF值:
(3)
为了解决集合Q中选取合法代码与病毒代码的不均等性,引入ODNi浓度函数作为平衡因子,浓度函数f(C)如下:
(4)
利用浓度函数f(C)平衡合法代码集与病毒代码集的随机性。ODNi趋向性选择函数S(ODNi)如下:
(5)
根据式(5)可知,当S(ODNi)L大于S(ODNi)V时,ODNi在合法代码的ODN中,反之ODNi在病毒代码的ODN中。根据式(5)的计算结果可以建立ODN库,本文拟采用滑动窗口的方式来对ODN进行计数,算法伪代码如下:
Temp2. 读取合法代码,flag[i]=0;
Temp6. 滑动窗口前移1 B;goto Temp3;直到合法代码结束;
Temp7. goto Temp2;直到Q中所有合法代码统计完;
Temp8. 读取一个病毒代码;flag[i]=0;
Temp12. 滑动窗口前移1 B;goto Temp9;直到病毒代码结束;
Temp13. goto Temp8;直到Q中所有病毒代码统计完;
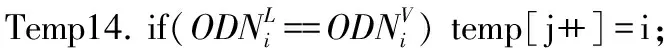
算法除了考虑ODN浓度,还重点考虑关键ODN的遗传特性,基于TF-IDF特征词定位算法检测出合法代码和病毒代码共有的ODN库。根据病毒的ODN库经过匹配生成病毒的候选基因库,然后再经过一系列匹配建立病毒的检测基因库。
1.2 病毒候选基因库
利用病毒ODN库与病毒程序进行连续匹配,生成病毒候选基因库,病毒候选基因以基于rcb匹配规则的形式生成。rcb匹配规则是指两个字符串采用滑动窗口的方式从相同位置开始向后匹配,直至不再匹配为止,停止匹配后计算匹配了多少个病毒ODN库中的ODN。与阈值T进行比较,若大于阈值T则认为此段病毒代码含有足够多的病毒信息,可将此段病毒看作病毒候选基因。阈值T的大小对候选基因的选择至关重要,因为ODN为2 B,阈值T过大容易造成病毒候选基因过长,病毒提取的准确性降低;阈值T过小,提取的候选基因太短,缺乏对病毒提取的连续性和完整性。而常用计算机指令多为1 B或2 B,这里将阈值T设为3,这样最小的候选基因为4 B,可由4个ODN组成,至少包括4个计算机指令。图1为候选基因生成流程示意图。

图1 候选基因生成流程示意图
1.3 病毒检测基因库
病毒检测基因库的覆盖率与训练集的数目呈正相关,为了提高病毒检测基因库的检测覆盖率,扩大病毒识别范围,本文将未知病毒和特种病毒作为可疑程序进行检测判定。病毒检测及检测基因库的形成流程如图2所示。
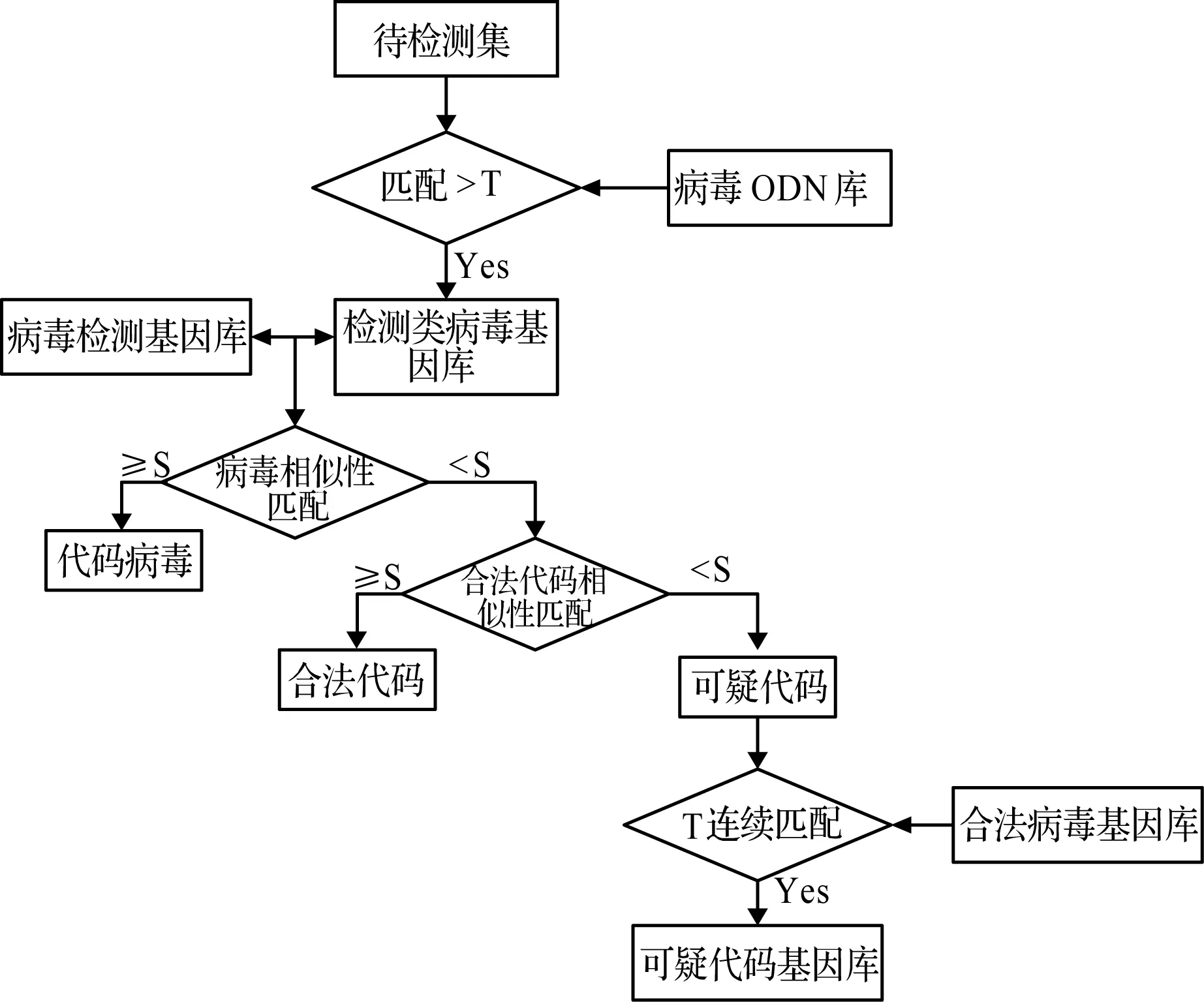
图2 病毒检测流程示意图
算法将待检测集集合与病毒ODN库根据设定的阈值T进行连续匹配生成检测病毒基因库;然后将检测病毒基因库与病毒检测基因库根据阈值S进行相似度匹配,若不小于阈值S则为病毒代码,反之进行下一步的合法代码相似性判断;与合法代码进行相似性匹配,若不小于阈值S则为合法代码,反之为可疑代码;并将检测集与合法类病毒基因库进行规则匹配,生成可疑代码基因库。
病毒代码与病毒ODN库通过匹配规则生成病毒候选基因库,但是病毒ODN库中的部分ODN可能存在于合法代码ODN中。这使病毒候选基因库与合法代码类病毒基因库存在部分匹配的可能。降低病毒检测的准确率。在人工免疫系统中应用最多的是rcb匹配规则,因为其很好地体现两个字符的相似程度。rcb匹配比较的是一串连续的字符串,容易脱离整体。结合病毒候选基因库与合法代码类病毒基因库存在部分匹配的问题,本文采用rcb r字符块规则[12]的可变r匹配规则来对病毒候选基因库进行训练建立病毒检测基因库。
可变r匹配规则是指病毒候选基因库中的某个基因α采用滑动窗口的方式与合法类病毒基因库中的每个基因从相同位置进行连续匹配,直至不再匹配为止,停止匹配后计算匹配了多少个ODN。若匹配成功ODN数目不小于r,则认为两个基因匹配成功,此时将基因α删除,重复以上匹配过程,直到病毒候选基因库中匹配成功的所有基因被删除。此时,病毒候选基因库就成为了病毒检测基因库。
r的取值是可变的与匹配基因的长度有关。若r取值过大,则会降低匹配成功率,影响病毒检测基因库的生成;若r取值过小,则会误删病毒候选基因库中的基因,r的取值应为:
(6)
通过这样的r取值后,病毒候选基因库中与合法程序类病毒基因库相匹配的基因,都会被最大程度地识别并删除,提高了对病毒的区分度。
2 病毒程序检测模型
病毒检测基因库中所包含的病毒基因只是代码片段,由病毒基因片段上升到对病毒程序的检测,需要建构一个病毒程序检测模型,以实现对病毒程序的高效识别和检测。余弦相似度[13]是计算相似度的一种算法,最常用于文本相似度的检测中。该算法将两个待测文本根据相关指标建立向量,然后通过测量两个向量间的内积空间夹角余弦来度量两个文本的相似度。向量的夹角越小即余弦值越大表明两个文本的越相似,反之亦然。
2.1 模型建立
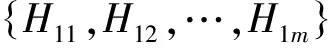
Pi1Pi2Pinj
(7)
(8)
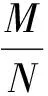
(9)

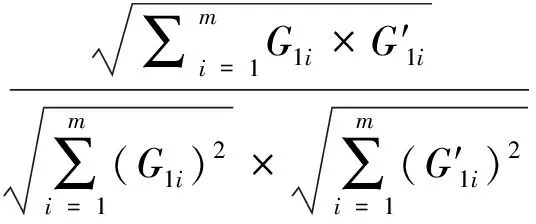
(10)

2.2 模型分析
通过模型计算出的相似度值与相似矩阵中每一个元素值成正比,与病毒检测基因库中基因长度成反比,则相似阈值k满足:
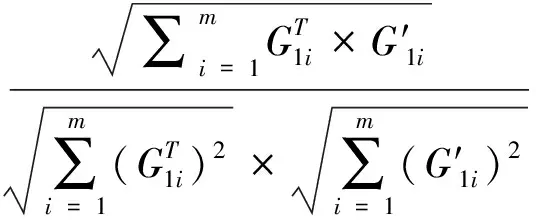
(11)
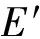
(12)
3 仿真实验
本文仿真实验使用两组数据集:一是文献[14]中使用的1 512个恶意程序;二是北京大学计算机智能实验室的cilpku08数据集(http://www.cil.pku.edu.cn/ resources.)。这个数据集含有最新的3 547个恶意程序,表1和表2分别为两组实验数据的详细信息。仿真实验从Windows7平台上收集到3 682个合法程序,根据病毒程序属性将其分680类,仿真是在Windows 7系统下,CPU:i3-3240@3.4 GHz,RAM:4 GB。待检测程序检测的正确率与相似阈值k的关系如图3所示。
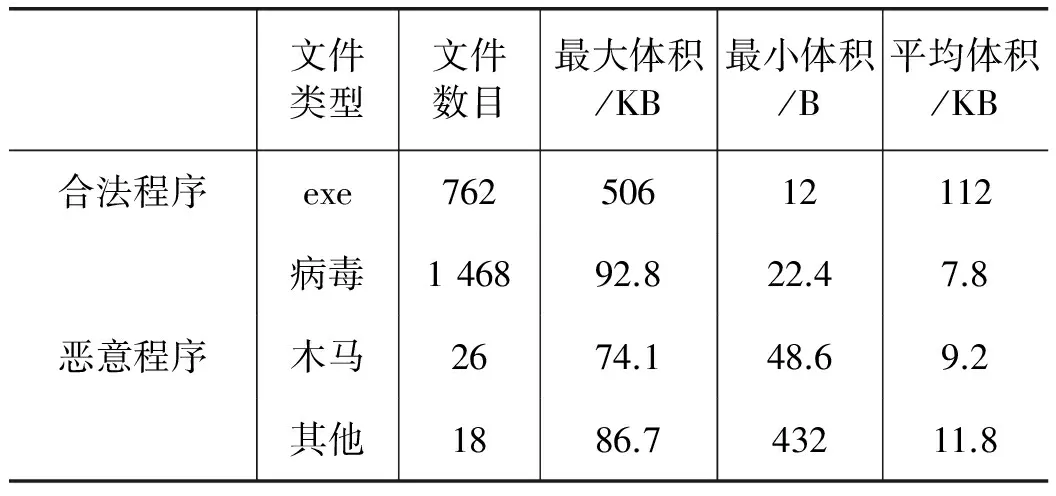
表1 文献[14]所用数据集
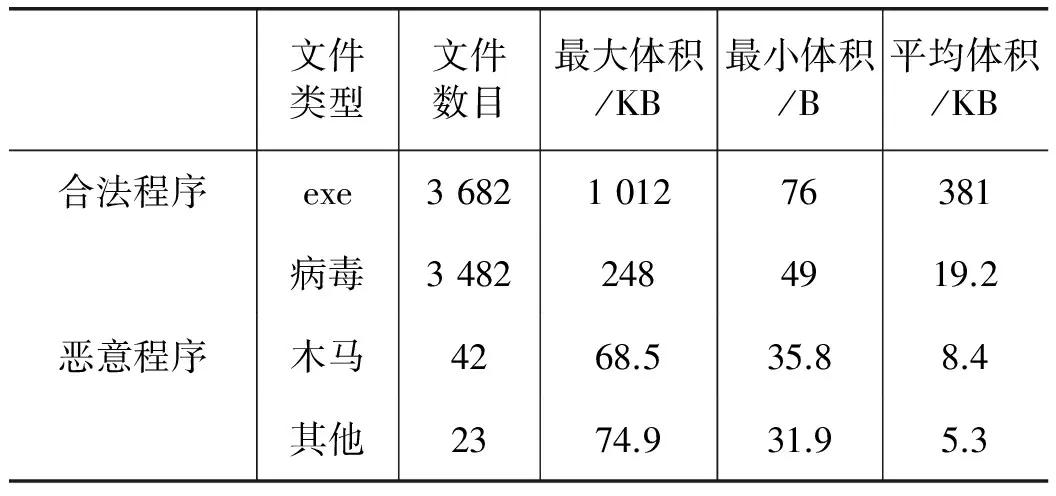
表2 cilpku08数据集
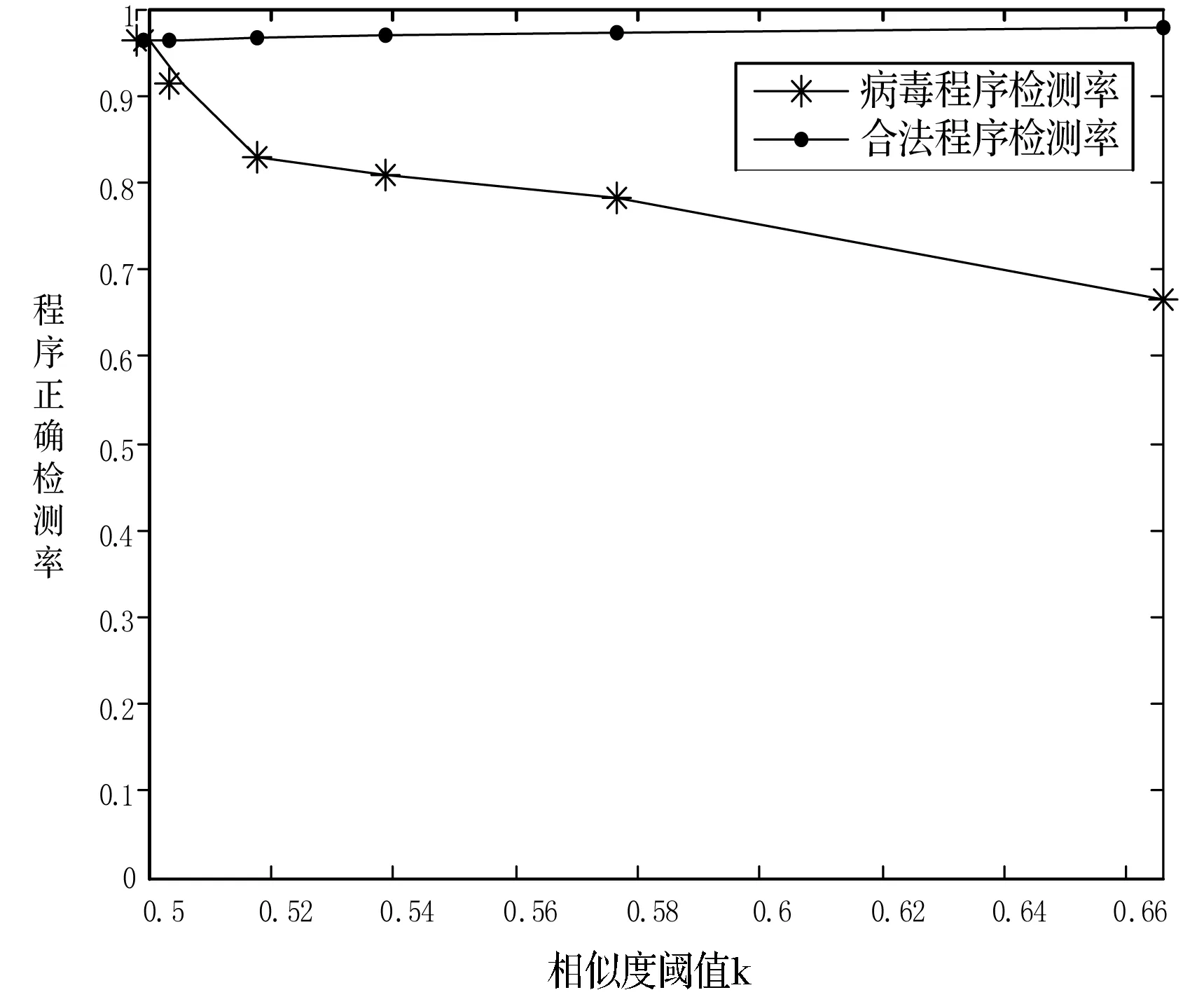
图3 程序正确检测率
从图3曲线走向可以看出:随着相似度阈值k的增大,合法程序检测率呈平稳递增的趋势,相反病毒程序检测率则出现较大幅度的降低。这是由于相似度阈值k与可变匹配阈值r成反比,可变匹配阈值r与病毒检测率成正比。虽然随着相似度阈值k的不断增大,合法程序检测率呈递增趋势,但是递增的幅度是相当平缓的,而对于病毒程序的检测率却是明显的降低,本文取相似阈值k为0.5。
本文利用第一数据集验证本文算法的效果,利用第二组数据集,通过随机抽取来比较验证本文算法的稳定性和泛化能力。本文将文献[14]中提供的病毒随机分成5份,并从Window 7系统下的3 682个合法程序中随机抽取1 512个合法程序同样分成5份,利用本文算法进行5倍交叉仿真实验,实验结果如表3所示。

表3 第一组数据集分组实验对比 %
在分组的数据集上各检测合法程序与实验病毒程序相互独立,实验的可信性较高。通过仿真实验可知,本文算法在5组实验数据集合上能保持较低的虚警率,同时取得了较高的病毒识别率。
为了进一步验证本文算法的有效性,仿真实验在3 552个病毒程序和3 682个合法程序数据集上随机选出1 314个程序(其中655个合法程序,659个病毒程序),按照训练集和检测集0.5、1、0.5的比例进行三次不同划分与实验,实验结果如表4所示。

表4 实验结果
从表4可以看出,模型对训练集和检测集都有较高的识别率。其中模型对训练集中的合法程序有一定的记忆,训练好的模型对合法程序的识别率在98.5%以上,对未知的病毒程序平均识别率在91%左右。并且,模型的识别率不因训练集和检测集合规模的缩小而有所降低,在测试3中,训练集上程序远小于检测集上的程序,但此时模型对训练集上病毒程序的识别率为92.4%,高于测试1和测试2的识别率。训练好的模型在检测集上也表现出色,测试3中,对合法程序的识别率为99.4%,对病毒程序的识别率为91.6%,均高于模型在测试1和测试2上的识别率,说明模型能在小数据集上利用有限的知识敏锐学习。训练完成后模型可获得较高的识别率,具有较高的泛化能力。
下面将在更大数据集上验证模型的识别性能,即用训练好的模型对整个数据集进行检测识别,表5为检测结果。
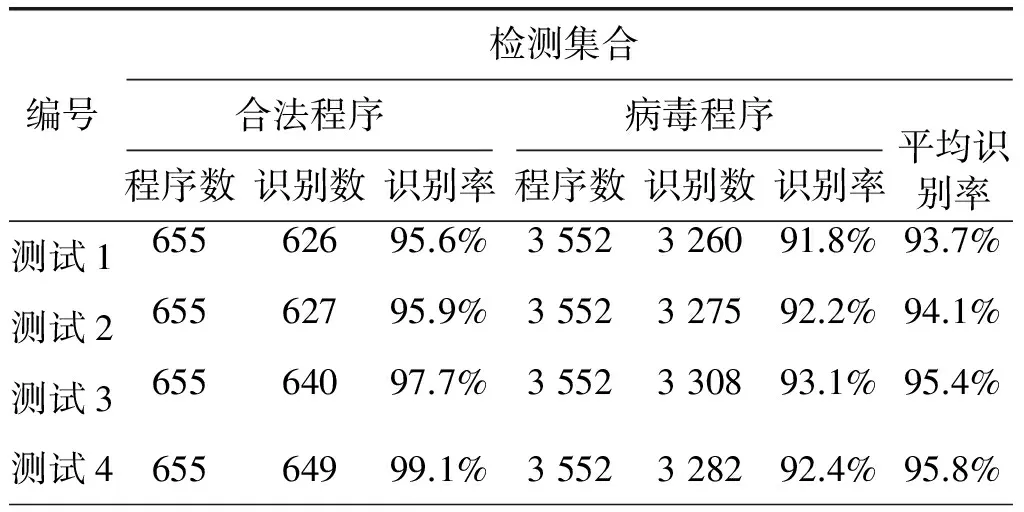
表5 全部数据实验结果
模型对检测集合中的合法程序的识别率都在95%以上,随着训练的加强,模型对合法程序的识别率呈逐步上升的态势;对病毒程序的识别率在93%以上,随着测试次数的增加,对病毒程序的识别率也在上升,但上升的幅度平缓。
为了对比本文算法与其他特征提取算法的差别,本文将在1 314个程序集合上分别运行ID3算法、J48算法、SMO算法以及本文算法来比较算法的性能,实验结果如表6所示。

表6 算法性能对比 %
从表6的实验结果,可以看出本文算法的虚警率虽比ID3算法稍高,但比其他两个算法都低;在保持较低虚警率的情况下,本文算法的病毒识别率都高于其他算法。这是本算法在病毒代码层采用TF-IDF算法对病毒DNA片段进行趋向性提取,在基因层采用可变r匹配规则提取病毒检测基因库;在样本层采用余弦相似度算法评估检测程序与病毒的相似度,最大程度提高病毒的识别率。
4 结 语
本文在前人研究的基础上,借鉴人工免疫相关思想,通过利用TF-IDF算法在代码层对病毒DNA进行趋向性提取,建立病毒候选基因库;在基因层采用可变r匹配规则匹配建立病毒检测基因库;最后利用余弦相似度算法评估待测程序与病毒的相似度。层层筛选病毒层内特征,在有效控制病毒基因库规模的情况下,提升了对变异病毒及未知病毒的检测准确率。
[1] Deng P S, Wang J H, Shieh W G, et al. Intelligent automatic malicious code signatures extraction[C]// IEEE, 2003 International Carnahan Conference on Security Technology, 2003. Proceedings. IEEE Xplore, 2003:600-603.
[2] 莫宏伟. 人工免疫系统原理与应用[M]. 哈尔滨:哈尔滨工业大学出版社,2002.
[3] 李涛. 计算机免疫学[M]. 电子工业出版社, 2004.
[4] Ou C M. Host-based intrusion detection systems adapted from agent-based artificial immune systems[J]. Neurocomputing, 2012, 88(7):78-86.
[5] 陈岳兵,冯超,张权.面向入侵检测的集成人工免疫系统[J].通信学报,2012,33(2):125-131.
[6] 芦天亮,郑康锋,刘颖卿.基于动态克隆选择算法的病毒检测模型[J].北京邮电大学学报,2013,36(3):39-43.
[7] Forrest S,Perelson A S,Allen L,et al.Self-nonself discrimination in a computer[C]// Proceedings of the 1994 IEEE Symposium on Research in Security and Privacy IEEE. Los Alamitos,CA,1994.221-231.
[8] Dasgupta D, Forrest S.Novelty detection in time series data using ideas from immunology[C]// Proceedings of the 5th International Conference on Intelligent Systems.Cancun,Mexico:Springer,1996:82-87.
[9] 王辉,于立君,毕晓君,等.具有疫苗算子的可变模糊匹配阴性选择算法[J]. 哈尔滨工业大学学报,2011,43(6):141-145.
[10] 张鹏涛,王维,谭营.基于带有惩罚因子的阴性选择算法的恶意程序检测模型[J].中国科学,2011,41(7):789-802.
[11] 王辉,于立君,王科俊,等.一种可变模糊匹配阴性选择算法[J].智能系统学报,2011,6(2):178-185.
[12] Hou H Y, Dozier G. An evaluation of negative selection algorithm with constraint-based detector[C]// ACM Southeast Regional Conference 2006. Melbourne, Florida, USA, 2006. 134-139.
[13] 陈大力,沈岩涛,谢槟竹,等.基于余弦相似度模型的最佳教练遴选算法[J].东华大学学报(自然科学版),2014,35(12):1697-1699.
[14] Henchiri O,Japkowicz N. A feature selection and evaluation scheme for computer virus detection[C]// Proceedings of the 6th International Conference on Data Mining(ICDM’06). Hong Kong.China,2006:891-895.
VIRUSFEATUREEXTRACTIONALGORITHMBASEDONTHECOSINESIMILARITYOFARTIFICIALIMMUNESYSTEM
Yang Yinghua1Xia Yong2
1(InformationCenter,LanzhouUniversityofFinanceandEconomics,Lanzhou730020,Gansu,China)2(SchoolofComputerScience,NorthwesternPolytechnicalUniversity,Xi’an710129,Shaanxi,China)
The existing computer virus feature extraction algorithm cannot effectively extract unknown viruses and variants of the virus characteristics, thus a virus feature extraction algorithm based on the cosine similarity of artificial immune system is proposed with the help of artificial immune theory. Establishing the virus candidate gene bank by adopting TF-IDF to carry on the tendency extraction to the virus DNA in the code layer algorithm; using variable r matching rule to extract virus candidate gene pool to produce virus detection gene bank in gene layer algorithm. Finally, the program layer uses the cosine similarity algorithm to evaluate the similarity between the test program and the virus, and to recognize the test program. Simulation experiments show that the proposed algorithm has higher virus recognition rate compared with other virus feature extraction algorithms in the case of low false alarm rate.
Artificial immune Feature extraction TF-IDF algorithm Variable r matching Cosine similarity
2016-07-08。国家自然科学基金项目(61471297)。杨应华,讲师,主研领域:数字图像检索与信息安全。夏勇,教授。
TP393
A
10.3969/j.issn.1000-386x.2017.08.054
