一种非结构化数据查询优化存储系统设计
2017-08-08王秋琳宋立华闫丽飞
王秋琳,宋立华,闫丽飞,林 晖
(福建亿榕信息技术有限公司 福建 福州350003)
一种非结构化数据查询优化存储系统设计
王秋琳,宋立华,闫丽飞,林 晖
(福建亿榕信息技术有限公司 福建 福州350003)
针对电力系统信息运维现状,研究并设计了电力业务非结构化数据查询优化存储系统。首先详述了非结构化数据存储系统的架构方案;针对分布式存储问题,提出了均衡分布优化策略,并在此基础上设计了协同数据查询优化方案。数据集划分时间、数据集读取时间、查询正确率、数据节点服务器负载和请求响应时延等实验表明,所搭建的评测环境可满足测试需要,所研制的方案具有一定的优势,满足电力业界主流分布式存储技术的能力特征及适用性。
非结构化数据;查询优化;存储系统;均衡分布
电力系统实时数据包括运行数据、负荷状况、故障信号以及维护业务等,是电网信息调度中心分析电网稳定、计算潮流、查看设备运行状态的依据。这些实时系统信息数量巨大、种类繁多、实时性高,包含了各业务子系统产生的文本、图片、语音、视频等文件,属于典型的非结构化数据[1]。这些数据的读取速率通常在每秒百M以上,交换性强,给电力企业信息调度中心造成了存储与查询难题。故针对电力系统信息运维现状,如何构建一个高性能、高可用、高保险的存储系统是目前电力数据处理领域研究的重要课题。
1 非结构化数据存储系统架构
电网实时数据种类多、数量大,且数据格式不统一,为典型的非结构化数据,其操作方式多为一次写入、多次读取,以便满足电力设备故障分析、电力自动化设备优化调整等方面的需要。为适应实时电力数据处理的要求,支持多种存储架构思路和分布式存储技术,提升数据查询优化性能,该存储系统所配置的基础软硬件设施包括Mongodb数据库、Oracle数据库、SAN存储、NAS存储以及廉价PC Server存储服务器等[2]。
其中,数据存储层是整个存储系统的基础,实现电力数据的高速、并行、实时处理,包括元数据处理单元、文件路径及权限元数据处理单元、分布式存储计算单元、集中式存储计算单元等。
元数据管理组件层包括与存储构架相连的一些底层的设备驱动组件和Web Service组件,提供设备驱动和Web应用服务的底层实现,同时负责数据的管理与访问。该层为架构优化设计的核心,将替代EMC的Documentum产品,作为非结构化平台底层核心元数据管理组件,集中体现分布式存储功能支持及性能优化思路。在内部,该层管理组件由Client和Server两端组成[3]。Client端可为上层的非结构化数据管理平台接入组件或全文检索组件所引用,实现对底层的文件传输、存储、元数据管理各功能的调用;Server端则由元数据服务逻辑节点Meta Server、文件传输及存储管理逻辑节点File Server、路径与权限内存服务逻辑节点Name Server、离线计算单元逻辑节点Offline Computation Server、分布式存储逻辑节点 PC Storage Cluster Server组成[4]。
该层设计方案的另一个独特之处在于整体架构不依赖于任何第三方组件,即所有目前采用的第三方组件均可替换,包括文档数据库Mongodb、内存KV数据库Riak、分布式存储服务Riak-CS等[11]。同时,该层具有全面的服务高可用性。任何服务逻辑节点都有采用集群部署或主备部署模式,整个系统不存在单点故障,能够提供高稳定的服务质量。另外,File Server端的文件流式传输服务支持部署到多台服务器、离线计算节点Off-Line Computation支持不受数量限制的物理机及虚拟机部署,可实现对非结构化平台不断增长的业务提供柔性支持[5]。服务层与应用层为客户提供服务,包括具体的数据处理程序、身份注册与认证服务、密码服务、文件和数据的读写与传输、网页浏览与电子邮件服务等。
中间件主要包括分布式协调及调度服务——Zookeeper,分布式消息中间件——MetaQ,为各方案提供分布式环境下调度及消息服务方面的支持。
2 多服务器的分布式系统数据查询优化
2.1 电力数据的均衡分布优化策略
电网状态数据的实时性强、数据量大,考虑实时性的需求,同时也为减少因过度强调存储平衡而带来的数据频繁迁移,避免已存数据的不同数据中心的数据重分布而引起的数据大规模传输,需对电力数据进行均衡分布处理。传统的分布处理通常按存储设备性能高低进行聚类分析,对同一设备类中的数据采用一致Hash算法进行分配[6]。然而,以上分布策略未考虑到数据间的关联关系,数据所在的位置决定着数据查询的效率、数据读取和传输的效率。故需对均衡分布策略进行优化改进。
依据同一数据库和不同用户间数据的关联性以及共享性的要求,此处提出的优化策略为先通过特定优化算法进行关联数据的初步分类,之后根据各数据依赖关系,将具有数据依赖关系的数据存放在同一服务器上。此处所谓的依赖关系是指电力数据按照类型、大小、数据源等为依据进行聚类处理后得到的关联性,可认为被归为一类的数据彼此间具有一定的依赖关系。在该系统中,采用改进的遗传算法进行源数据的分布优化。设现将第组中的数据A按需存储到设备②中、数据B存储到设备③中、数据C存储到设备①中,则可用数据分布矩阵表示为

此方法编码简单,只需要选取n个(数据个数)位置,填充为1即可,几乎等同于无编码。而同样表示数据分布关系的二进制位串则一定需要编码,而且编码需要解析,且增加很大解析工作量。且以该矩阵进行编码可方便后期进化算法中的交叉变换。该矩阵为整个解空间,故不管行或列如何交叉变换,得到的解均是满足最优解或次优解要求的。另外,因分布矩阵中的行列交叉可演化出所有解的情况,故采用分布矩阵可避免传统遗传算法中的变异操作,进而可节省大量的计算资源[7]。
在通常的二进制编码方式下,变异操作知识简单地将基因某一位取反,即将“0”变为“1”,将“1”变为“0”。采用矩阵方式的遗传算法不需要进行变异,因为矩阵之中的交叉交换就可以演化出所有的解情况,故可节省大量的计算步骤。
以给定初始解作为进化种群,在该种群中进行个体的进化操作,同时设定其适应度函数。该适应度函数通过比较种群中个体对各自环境的适应程度来决定染色体的优劣,应该有效的反应每一染色体与最优解染色体之间的差距。适应度是评价染色体优劣的唯一标准[16]。根据用户使用历史与数据访问历史记录,服务器的能力和网络性能,可为每一种位置计算出一个适应值,此处以NetValue表示数据k分布在机器i上时的网络性能度量,以SeverValue表示数据k分布在机器i上时的服务器处理性能和负载能力的度量,即

则适应度Fi的计算式为

以矩阵Fi中对角线元素表示第i组中的数据A、B、C存放位置的适应度。
假设在用户需要调用数据时,设备①上存储的A、B、C 3个数据的网络状况评分分别为 1、7、5(数值越大,表明网络状态越好),设备②网络连接评分为 3、1、6,设备③为 8、3、9,则可得

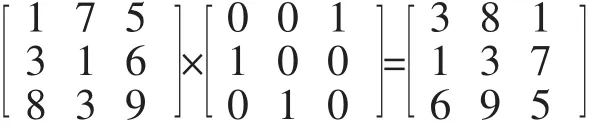
将海量电网监测数据分布存储的目的在于使得其能在不同的服务器上并行计算和安全存储,然而,为提高用户在不同服务器上调取、查询非结构化数据的速率,需进行分布式数据的查询优化[8]。为减轻主控服务器的查询、处理压力,同时以便均衡网络负载压力,该系统采用递归查询方式来实现多服务器的协同数据查询。
该递归查询方式由相关的数据库来协调完成,不需要主控服务器的全程参与,其查询步骤如下:
1)查询请求:由终端用户向主控服务器发送请求,申请查询资格;
2)初步查询:收到用户请求的主控机对申请数据表进行分析,对包含数据的服务器进行定位,同时将分析结果下传至邻近数据库;
3)数据下传:数据库服务器间将相关数据及主控定位信息持续下传;
4)下传查询:信息持续传递到末端数据库服务器;
5)查询回传:末端数据库服务器查询相关数据,并将结果按原路回传至邻居服务器;
6)查询优化:根据查询优化规则,部分地开始链接和选择数据表,将部分结果按原路返回到首端数据库服务器;
7)结果递交:最终首端数据库服务器将查询结果递交给发出查询请求的终端用户。
3 存储系统性能评测
3.1 评测环境搭建
为评测系统存储性能,验证数据均衡与优化查询算法的有效性,利用1台PC机作为元数据服务器,用于存储客户端连接与逻辑处理信息,其硬件资源配置信息为Intel Core i7处理器、16 GB DDR3内存、SATA3 1TB硬盘;3台PC作为数据存储节点,用于存储缓存与持久化数据存储,其硬件资源配置信息为Intel Core i5-4590处理器、8 GB DDR3内存、SATA3 4TB硬盘;1台PC作为性能测试节点,用于模拟用户发送的数据查询及传输请求,其硬件资源配置信息为Intel Core i5-4590处理器、4 GB DDR3内存、SATA3 2TB硬盘;为排除网络延迟影响,各服务器间以千兆以太网相连组成局域网。3个数据节点采取主从模式,测试节点向应用节点发送数据请求并等待响应[10]。
实验数据主要包括电力监控视频(<500 MB)、监视图片(平均<3 MB)、周用电负荷报表文本数据、变电站各设备状态文本数据、月运行故障报表数据、运维及营销文本数据、客户资料文本数据等几十种数据文件,多数报表及文本文件文件,大小一般分布在10~2 048 kB范围内,总文件个数超过约为158 420 000个,总存储大小超过约2509 GB。
为满足同一数据库和不同用户间数据的关联性、共享性要求,将以上现有实验数据根据式(1)~(3)所示的优化策略进行关联性分类,依据各数据间的依赖关系进行数据集划分。此处依据电力业务类型、各文件大小比例关系、各文件关联度大小、服务器处理性能和负载能力度量需求等因素划分数据集,每个数据集以文件切片的方式进行分布式存储,随机分布于3个数据节点上。为使得实验结果更具有说服性,元数据与数据集间的调用关系也随机确定,其元数据由一个二元组{Cp,Di}进行描述,其中Cp表示所查询或申请的数据所在的数据中心节点,Di为调用的数据集。
3.2 测试结果与分析
对该分布式存储系统进行的性能测试包括数据集划分时间、数据集读取时间、查询正确率、数据节点服务器负载和请求响应时延实验,相同的测试实验重复10次,排除最值并取平均。数据集的划分与查询读取时间的统计结果如图1~2所示,由图可知,随着数据集文件切片中包含文件数的增多,依据关联性划分的所需时间将增大,同时对数据集中某用户申请查询的数据读取影响也较大,因小文件的有效查询时间与其在数据集中的位置以及服务器处理负载能力度量值均有关系,故在后期实验中,将文件分片的大小设定为每数据集包含小文件不超过600个。

图1 划分数据集平均时间

图2 数据集读取平均时间
用户发送查询申请的数据查询正确率统计结果如图3所示。在该实验中,通过性能测试节点模拟实际电力系统中多个用户同时发送不同查询申请的查询实验,查询正确率为查询结果与查询申请数的比值,可看出,随着同时发送查询申请数量的增大,基于本文系统的数据查询正确率略有下降,但均不低于99.4%,在可接受范围内,同时发送查询数量的增长对查询正确率影响不大[11]。
为验证本文均衡分布优化策略的有效性,分别利用本文策略与一致Hash算法、SequenceFile算法对比测试相应的节点服务器负载和请求响应时延[12]。其对比结果如图4~5所示。由结果可知,当系统分别存 储 50 000、100 000、150 000、200 000、250 000、300 000个小文件时,本文策略与SequenceFile算法在降低数据存储节点负载方面都要优于一致Hash算法。在平均响应时延方面,本文策略的平均时延低于其余两者,随着查询请求数量的增加,时延增势最为缓慢。

图3 用户申请查询正确率
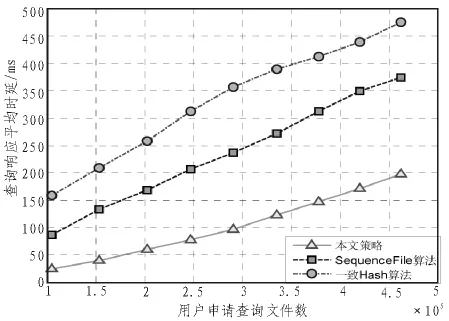
图4 平均查询请求响应平均时延

图5 数据节点服务器负载对比结果
4 结束语
文中研究并设计了电力业务非结构化数据查询优化存储系统。为降低电力公司存储成本、提升数据管理及服务的性能水平,满足上层各业务系统在非结构化数据领域的使用需求,文中首先详述了非结构化数据存储系统的架构方案;针对分布式存储问题,提出了均衡分布优化策略,并在此基础上设计了协同数据查询优化方案。数据集划分时间、数据集读取时间、查询正确率、数据节点服务器负载和请求响应时延等实验表明,所搭建的评测环境可满足测试需要,所研制的方案具有一定的优势,满足电力业界主流分布式存储技术的能力特征及适用性。
[1]赵俊华,文福拴,薛禹胜.云计算:构建未来电力系统的核心计算平台[J].电力系统自动化,2010,34(10):1-8.
[2]张逸,杨洪耕,叶茂清.基于多 Agent的电能质量辅助服务平台[J].电力自动化设备,2012,32(12):92-96.
[3]张健.电力企业核心业务数据存储方案设计[D].成都:电子科技大学,2010.
[4]张逸,杨洪耕,叶茂清.基于分布式文件系统的海量电能质量监测数据管理方案[J].电力系统自动化,2014,38(2):102-107.
[5]丁杰,奚后玮,韩海韵.面向智能电网的数据密集型云存储策略[J].电力系统自动化,2012,36(12):65-72.
[6]王培.智能电网监测数据的云存储研究[D].北京:华北电力大学,2012.
[8]陈锦铭,袁晓冬.电能质量在线监测平台的设计与开发 [J].电力信息化,2011,9(3):60-64.
[9]马惠芳.非结构化数据采集和检索技术的研究与应用 [D].上海:东华大学,2013.
[10]沐连顺,崔立忠,安宁.电力系统云计算中心的研究与实践 [J].电网技术,2011,35(6):171-175.
[11]李成华,张新访,金海.MapReduce:新型的分布式并行计算编程模型[J].计算机工程与科学,2011,33(3):129-135.
[12]郑伟,周喜超,王维洲.一种高性能的多级异构电能质量数据库同步方法[J].电力科学与工程,2010,26(10):21-24.
Design of a storage system for unstructured data query optimization
WANG Qiu-lin,SONG Li-hua,YAN Li-fei,LIN Hui
(Fujian Yirong Information Technology co.,LTD.Fuzhou 350003,China)
Aiming at the current situation of electric power system information operations,this paper researched an electric power business storage system for unstructured data query optimization.Firstly,the architecture scheme of unstructured data storage system was detailed.Then,for the distributed storage problems,the balanced distribution optimization strategy was proposed and the collaborative data query optimization scheme was designed based on the proposed strategy.The experimental results such as dataset partition time,reading time,data query accuracy,server load and request response time delay etc indicated that the evaluating environment could meet the needs of the testing and the developed scheme had certain advantages which meet the ability of electric power industry mainstream distributed storage technology characteristics and applicability.
unstructured data;query optimization;storage system;equilibrium distribution
TN73
:A
:1674-6236(2017)13-0016-05
2016-05-19稿件编号:201605189
王秋琳(1980—),男,福建龙岩人,高级工程师。研究方向:电力信息系统建设、大数据存储、大数据分析。
