音量增大时语音的长时共振峰分布特征变化及其对声纹鉴定的影响
2017-07-31贾丽文
贾丽文
(山西警察学院,山西太原030012)
音量增大时语音的长时共振峰分布特征变化及其对声纹鉴定的影响
贾丽文
(山西警察学院,山西太原030012)
长时共振峰分布特征是近年来才开始使用的研究方法。目前尚未广泛的应用于声纹鉴定实务。本文将采用长时共振峰分布特征来探究声纹鉴定实务中经常遭遇的一种情形,即检材语音和样本语音音量不同的情况。实验用Lombard效应法增大语音,对30位发音人在正常和85分贝噪音两种不同的条件下进行录音。考察长时共振峰分布特征的变化,以期对声纹鉴定实务提供帮助。
声纹鉴定;音量增大;Lombard效应;长时共振峰分布
对语音音量增大时语音的声学参数的研究可谓不少,但应用长时共振峰分布特征这一声学参数的可谓凤毛麟角。长时共振峰分布特征是近年来才开始使用的研究方法。它最早由Nolan和Grigoras提出,该方法不是分析具体的目标元音,而是提取一整段语音中的全部元音信息进行分析,得出每条共振峰的整体分布情况。因此,这种方法取名为长时共振峰分布法(Long-Term Formant Distribution,缩写为LTF)。该分布特征不仅可以概括发音人声道的整体共鸣特点,还能反映出发音人一定的发音习惯,可以用于区分不同发音人。具有高效省时、便捷快速以及普适性的优点。尤其是对于不同种的语言,只要能够获取大量语段得到长时的元音就可以观测其LTF。也有学者开始将这一特征应用到话者自动识别系统中。国外学者Jessen研究长时共振峰特征在音量增大时的变化,得到的结论是第一共振峰的长时共振峰值均有所增加,用T检验可见显著性差异。第二共振峰和第三共振峰的变化均无统一的规律,用T检验不可见显著性差异。但是该文只是比较了长时共振峰的均值,并没有考察长时共振峰的分布特征。本文将考察音量增大时尝试共振峰的分布特征。
1 实验设计
1.1发音人
发音人为30名成年男性,无喉部疾病及手术历史,说标准的普通话。发音者均来自北京大学和中国政法大学的本科生和硕士研究生,年龄在19岁~26岁之间。
1.2录音内容
发音内容为短文为《北风与太阳》。
1.3录音设备
本文实验样本均在北京大学语言学专业录音室录制。声卡型号为创新(Creative)SB X-Fi Surround 5.1 Pro。使用百灵达(BEHRINGER)XENYX 502调音台。使用SONYECM-44B领夹式麦克风录音,采样频率为22 kHz,精度为16位。录音软件为Cool Edit Pro 2.1。
1.4语音增大的方法
本实验所采用的语音增大的方法是Lombard效应法。Lombard效应是基于人类都有Lombard反射。Etienne Lombard在1909年第一个发现人们在环境嘈杂的时候,说话声音会变大。因此就将这种人的反射称为Lombard效应。Lombard效应法的通常做法是通过头戴式耳机给发音者加噪声,从而使话者的声音被动增大。
本实验采用Lombard效应法的具体做法是使发音者头戴加有噪声的耳机。噪音的声压级保持不变,为85分贝的白噪。噪音由Praat软件生成。由电脑千千静听软件播放。
1.5录音过程
录音时,保持麦克风与发音者之间的距离为50 cm。整个录音过程中发音人的位置保持不变。发音词表在发音人正对面,录制过程中,发音人不能出现前探、后仰、左右摇摆等情形,发音过程中要保证发音人的嘴与麦克风之间的距离不变。在噪音条件下发音时要求发音者的发音能够尽量使自己听到自己的发音内容。
1.6声学测量
本文中,声学分析均使用软件Wavesurfer。
使用Wavesurfer软件将发音者所朗读的短文《北风与太阳》中的无声部分、辅音、鼻音等全部切除,留下共振峰结构明显的元音。剪切完成后的语音保持在10 s~15 s,具体时长信息见表1。

表1 短文剪切前后时长对比
长时共振峰分布提取采用宽带语图,提取四条共振峰。窗口类型为哈明窗。下采样频率为10000 Hz。LPC阶数为12。
2 实验结果
本实验中主要考察四个共振峰长时的均值和分布形态,第一、二、三、四共振峰的长时分布分别记作LTF1、LTF2、LTF3、LTF4。
2.1长时共振峰均值
四条共振峰的长时均值见图1,T检验结果见表2。
四张图按照自上而下的顺序分别为第一、二、三、四共振峰的长时均值统计图。在单张图中横坐标表示发音者顺序,依次为1号~30号发音人。纵坐标表示共振峰的频率值(单位:Hz)。图中黑色条形表示发音者在正常条件下的共振峰值,灰色条形表示发音者在Lombard效应下,即在噪声环境下音量增大时的共振峰值。

表2 四条共振峰的长时均值的T检验结果

图1 四条共振峰长时均值统计图
由统计图可见:LTF1在音量增大时均有所升高,T检验结果为显著性相关。LTF2、LTF4在音量增大时均有升有降,没有统一的规律,但二者之间仍有显著性差异。并且,对于LTF2均值而言,其变化的幅度非常小,大部分占正常发音时共振峰频率值的0%~3%,只有一个人达到了8%。可以说LTF2均值在音量增大时基本没有变化。LTF3在音量增大时有升有降,没有统一的规律,但P值为0.799,说明音量增大时,LTF3没有显著性差异。
2.2共振峰长时分布形态
共振峰长时分布形态的具体做法是对所提取的四个共振峰的长时频率值进行频数分布,即一定频率范围内出现的次数,可以得到四条共振峰的长时分布特点。
(1)LTF1分布形态

图2 1号发音者LTF1分布图
以1号发音者为例,对其LTF1进行统计,结果如图2所示。图2上图为发音者在正常条件下所得LTF1的分布特征,下图为发音者在Lombard条件下,即音量增大时的LTF1的分布特征。每一图中,X轴为统计的频率范围(单位:Hz),Y轴为频数,即出现的次数。由图2可见LTF1在正常条件下和音量增大时的差别较大。
在正常条件下,LTF1先呈现缓坡上升,在575Hz~625 Hz时达到顶峰,之后极速下降,在大于925Hz的范围内已经极少有分布。而在音量增大时,LTF1先呈现急速上升,在525 Hz~740 Hz的范围内均匀分布,无明显“尖峰”,之后急速下降,在925 Hz~1025 Hz的范围内仍有分布。LTF1在正常和音量增大时相差较大的情形不仅仅出现在1号发音者身上,对于所有的发音人都出现了此现象。可见,发音人在正常和音量增大时的LTF1截然不同。
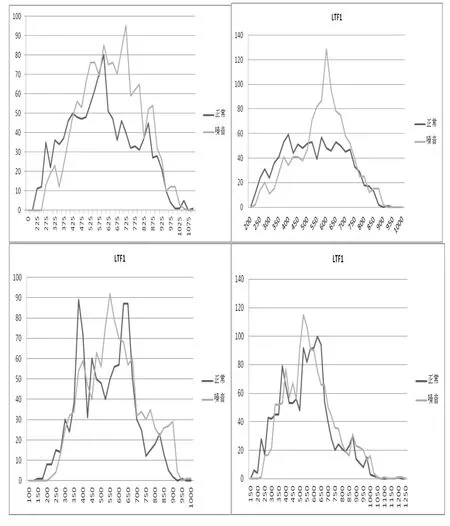
图3 不同话者两种条件下LTF1的分布形态
图3以30人中的4人为例,可见LTF1不仅人各不同,其在两种条件下的变化也不尽相同。在图3中X轴为统计的频率范围(单位:Hz),Y轴为频数,黑色线表示发音者在正常条件下的共振峰分布,灰色线表示发音者在噪音条件下、即音量增大时的共振峰分布。对于左上图的发音人,其在正常和音量增大时的LTF1是相似的,整体上体现出噪音量增大时的LTF1比在正常环境下的LTF1要整体向右移动4个统计频率范围。对于右上图的发音人,其在正常条件下的共振峰分布十分平稳不见“尖峰”,但在音量增大时却出现了集中的“尖峰”。同样,左下图的发音人,在正常条件下的共振峰分布有两个“尖峰”,但是在音量增大时却只有一个。而右下图的发音人,则呈现出正常和音量增大时共振峰分布相似的情形。总之,对于正常和音量增大时LTF1的变化特征并无明显规律可循。
(2)LTF2分布形态
比较LTF1,LTF2的分布形态在音量增大时的变化则很有规律。对于30位发音人笔者得到了相同的结论。即音量增大时的LTF2较正常条件下并无明显的变化。图4以30人之中的两人为例来表现这种规律。
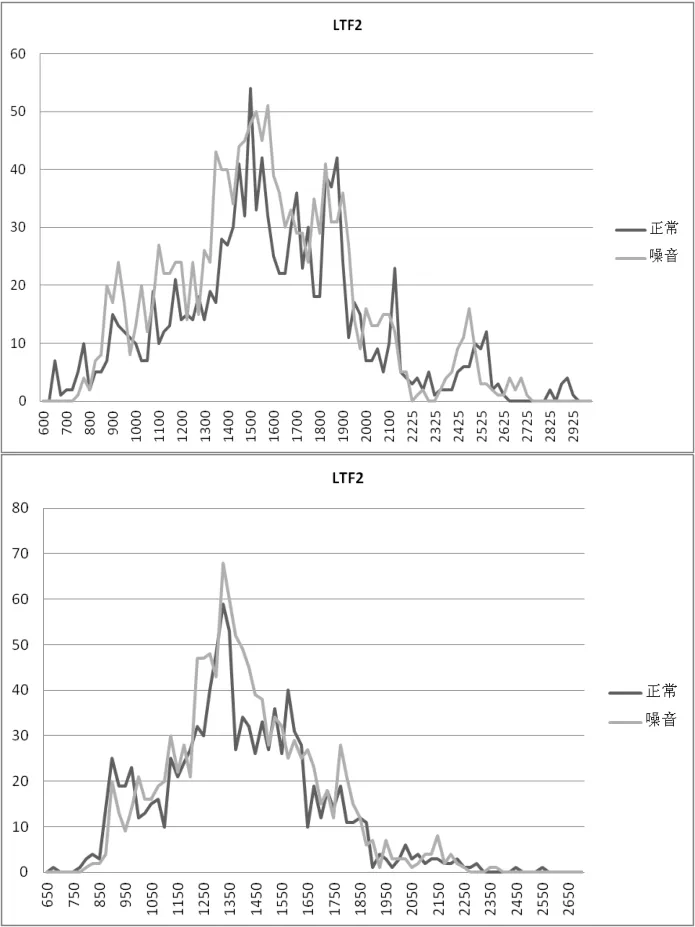
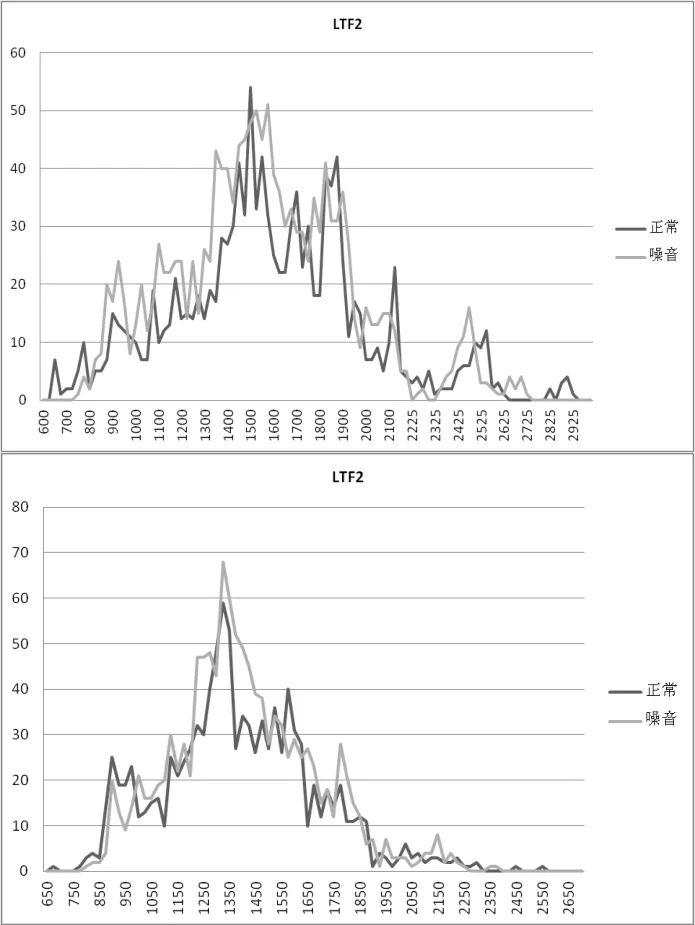
图4 不同话者的LTF2分布特征
在图4上图中发音者在正常和音量增大两种状态下的LTF2均有两个“尖峰”,且第一“尖峰”区域均集中在1400 Hz~1600 Hz范围内,第二“尖峰”区域均集中在1800 Hz~1900 Hz的范围内。整体形态相似并且均在2450 Hz~2600 Hz的范围内达到一个小“尖峰”。在下图中,发音者在正常和音量增大时的LTF2十分相似。均在1250 Hz~1450 Hz的范围内达到“尖峰”。对于同一发音者,LTF2在正常和音量增大时的分布十分相似,但是不同的发音者的LTF2相差很大。由图4也可证实。上图发音者有“尖峰”较多且有两个相对集中的“尖峰”区域,而下图发音这只有一个“尖峰”区域,且“尖峰”所在区域的频率值也不尽相同。上图发音者的LTF2的频率分布600 Hz~2925 Hz,而下图发音者仅从650 Hz~2550 Hz。
(3)LTF3分布形态
笔者对于30位发音人LTF3的统计研究也得到了相同的结论。以30人中的2人为例。结果见图5。

图5 不同话者的LTF3分布特征
由前人的研究可得,LTF3的分布特征为有一个“尖峰”,这一特征无一例外的适用于所有的人。对于音量增大时与正常条件下LTF3的差别,我们所得出的结论是在噪音条件下的LTF3的“尖峰”均高于在正常条件下的“尖峰”,换言之,在音量增大时频率表现的更为集中。由图5可见,在音量增大和正常两种条件下,发音者的LTF3均出现了一个“尖峰”,且“尖峰”的集中区域在同一区域。音量增大时的LTF3并未出现左移或者右移的现象,而是比正常条件下的“尖峰”集中范围内更高。仅从LTF3的分布形态而言,我们似乎很难区分不同的发音人,但事实上,区分不同发音人却异常简单,因为不同话者的“尖峰”所在的频率区域是不同的。如图5所示,上图的发音者“尖峰”集中在2500 Hz~2750 Hz,且频率分布在2125 Hz~3875 Hz的范围内,而下图发音者“尖峰”集中在2300 Hz~2500 Hz,频率分布在1600 Hz~3400 Hz的范围内。因此,LTF3对于话者同一的认定也有很大的价值。
(4)LTF4分布形态
第三和第四共振峰被认为在声纹鉴定中较有价值,因为其稳定性较强,个体差异也比较大。但是对于音量增大时LTF4却不像LTF3那么理想。没有统一的规律,但是比起LTF1而言,仍有一些趋势值得研究和探讨。
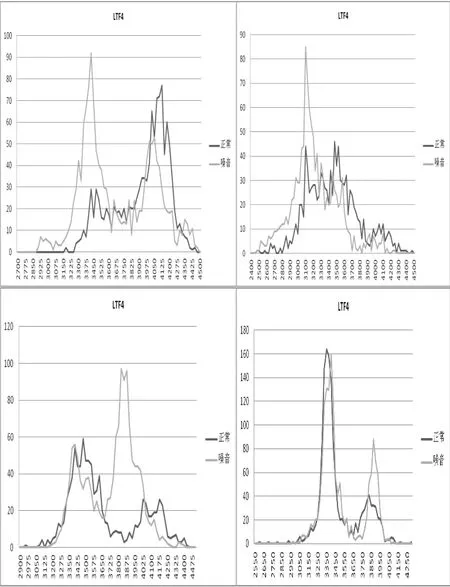
图6 不同话者LTF4分布形态
图6选取了30位发音人中的4位有代表性的发音人,其余发音人的规律大体相同。四图分别为四位发音者的LTF4。由图6不难发现以下几点。首先,对于同一发音者而言其在正常和音量增大时的LTF4具有很大的差别。在左上图中,发音人在正常条件下的LTF4呈现一个较小的“尖峰”,然后在4050 Hz~4150 Hz的频率范围内达到一个较高的“尖峰”;而音量增大时LTF4先达到较高的“尖峰”之后又出现较小的“尖峰”,两种状态下的LTF4呈现出轴对称的关系。在右上图中,正常状态下,LTF4分布平缓,小峰较多并无“尖峰”;而在音量增大时3000 Hz~3200 Hz的范围内出现较为集中的“尖峰”。在下方两图中,也明显可见两状态下LTF4的差别。其次,不同发音者无论在正常条件下还是音量增大时的LTF4分布均不相同。在正常条件下有的发音者出现两个较为明显的“尖峰”,如左上图和下方两图,但是两个“尖峰”的分布形态各不相同,有的前者较高有的后者较高;而有的发音者则未见明显的“尖峰”,如右上图。在音量增大时,有的发音者呈现出一个明显的“尖峰”,而有的发音者则呈现出两个“尖峰”。
虽然LTF4呈现出很多的差别,但是我们依旧从中发现了两个非常有趣的规律或者趋势。第一,发音者在正常和音量增大时的“尖峰”的集中频率相同。只是“尖峰”的形态有所不同。例如,在左上图中,发音者无论在在正常还是音量增大两种状态下,其“尖峰”均集中在3375 Hz~3475 Hz和3975 Hz~4150 Hz的范围之内。只是“尖峰”的形态不同,在正常条件下时两个范围的“尖峰”先小后大,而在音量增大时下大后小。在右下图中,正常和音量增大时的“尖峰”均集中在3250 Hz~3450 Hz和3750 Hz~3950 Hz两个频率范围之内。在形态上,3250 Hz~3450 Hz的“尖峰”的形态相似,而3750 Hz-3950 Hz的“尖峰”则在音量增大时要比在正常条件下大。第二,发音者在正常和音量增大时的LTF4有部分是重合的。换言之,虽然从总体上看两种状态下的LTF4是不同的,但是却有部分LTF4重合或者相似。例如,在左上图中,在大于3675 Hz的频率范围内,LTF4的分布形态相似,均为平稳上升然后产生一个“尖峰”。在右上图中,在大于3300 Hz的频率范围内,LTF4的分布形态近乎重合。在左下图中,在3050 Hz~3650 Hz的频率范围内,LTF4的分布形态相似。在右下图中,在2950 Hz~3650 Hz的频率范围内,LTF4分布形态相似,均达到“尖峰”且“尖峰”的频数也十分相近,均在160上下。这种趋势,有利于我们更好的认识LTF这一特征,当然,对于我们进行话者的同一认定有一定的辅助作用。
3 实验分析
LTF所反映的是话者共振峰分布的平均状态。对于同一话者不同的语料所得到的LTF的形态是相同的。不同话者的LTF的形态具有明显的差别。因此,LTF在声纹鉴定中具有重要的鉴定价值。
在发音者音量增大的时候LTF也发生了相应的变化。这种具体的变化表现为:第一、共振峰的长时均值呈现出:在音量增大时,LTF1均值升高,LTF2、LTF3、LTF4的长时均值均有升有降。第二、在音量增大的时候,LTF1的分布未出现明显的变化规律,不同的话者呈现出的变化不尽相同;LTF2的分布与音量增大前的长时共振峰分布相吻合;LTF3的分布与音量增大前的长时共振峰分布在同一频率范围出现“尖峰”并且音量增大时的“尖峰”要明显高于音量未增大时的高峰;LTF4的分布与音量增大前的长时共振峰分布形态部分重合,且对于不同的话者而言其重复的部分不尽相同。
为什么会出现长时共振峰分布形态上的变化?笔者认为这与不同元音共振峰的结构,以及不同元音增大时共振峰的变化息息相关。大部分研究认为,对于单个元音,音量增大时,第二和第三共振峰的变化均有升有降无统一规律。但是当元音集中,考察长时的共振峰分布时却出现统一的变化规律。虽然这种规律目前尚无法从生理角度进行解释,但是,这一特征却有助于长时共振峰分布特征应用于声纹鉴定实务。
4 结论与讨论
首先,长时共振峰分布能够反映更多的共振峰信息,应当成为声纹鉴定所采用的测量参数。当语音音量增大时,第二、三共振峰长时分布形态所表现出的明显规律可以为声纹鉴定得出否定结论提供相应的依据,可以为认定同一结论的得出提供相应的佐证。
其次,在语音音量增大时,第二、三共振峰长时分布形态都表现出明显的规律。可为声纹鉴定进行同一认定提供新的思路和方法。但是使用长时共振峰分布这一声学特征来进行声纹鉴定应当满足一定的条件。第一,被检验的语料时长不宜过短。这也就是说,当检材语音或者样本语音的时长只有几个单词、一句话或者几句话时,长时共振峰分布这一参数将不能够使用。因为我们得不到能够用来分析的长时元音的语段。国外学者研究显示,剪切后的语段,即只有元音所组成的语段的时长应当满足不小于10秒的条件。这一条件的提出是针对英语这一语种。由于汉语的复杂性以及目前尚未确定究竟多长的时间能够获得最良好的长时共振峰分布,因此,剪切后的语段不宜过短。第二,长时共振峰分布特征的应用对于语段的质量要求较高。共振峰分布反映的是一种共振峰的形态,因此,语音要能够清晰地反映出共振峰的结构。质量差的语音,共振峰结构不清晰,得到的共振峰的分布形态也是错误的。对原本的共振峰分布的形态产生掩蔽,做出的鉴定意见也是需要质疑的。
最后,本实验是在较为理想的实验室环境下进行的。语音的录制也采用较为优良的录音设备。但是在鉴定实践中,语音的录制设备花样繁多,常常为手机或者录音笔等。录制设备的不同、信道的差异也会对语音的声学参数分析带来影响。这些变化虽未体现在本文中,但是也应当引起鉴定人员的重视。
[1]Nolan F,Grigoras C.A case for formant analysis in forensic speaker identification[J].International Journal of Speech Language and the Law,2005,12(2):143-173.
[2]曹洪林,孔江平.长时共振峰分布特征在声纹鉴定中的应用[J].中国司法鉴定,2013,66(1):62-67.
[3]Jessen M,Becker T.Long-term Formant Distribution as a forensic-phonetic feature[J].Journal of the Acoustical Society of America,2010,128(4):2378.
[4]Kirchhuebel C.The effects of Lombard speech on vowel formant measurements[J].Journal of the Acoustical Society of America,2010,128(4):283-291.
Change of Long-term Formant Distribution and Its influence of Forensic Speaker Identification When the Volume Increases
JIA Li-wen
(Shanxi Police College,Taiyuan Shanxi,030012)
Long-term formant distribution is a research method that has been used in recent years.This method has not been widely used in forensic speaker identification.This paper will use long-term formant distribution to explore a situation which is often encountered in forensic speaker identification,that is the volume of voice and sample is different.Experiment used Lombard effect method to increase voice.Sound recordings were made by 30 persons under two different conditions:normal and 85 dB noise.The experiment will examine the change of long-term formant distribution,in order to provide help to forensic speaker identification.
forensic speaker identification;volume increase,Lombard effect;long-term formant distribution
O572.25
A
〔责任编辑 高彩云〕
1674-0874(2017)01-0024-05
2016-11-16
贾丽文(1988-),女,山西太原人,助教,研究方向:证据法学,刑事技术,声纹鉴定。
