基于阶段时序效应的奇异值分解推荐模型
2017-07-31张曦煌
黄 凯,张曦煌
(江南大学 物联网工程学院,江苏 无锡 214122)
基于阶段时序效应的奇异值分解推荐模型
黄 凯*,张曦煌
(江南大学 物联网工程学院,江苏 无锡 214122)
(*通信作者电子邮箱569261386@qq.com)
针对传统基于时序效应的奇异值分解(SVD)推荐模型在对用户预测评分建模过程中只考虑评分矩阵,采用复杂的时间函数拟合项目的生命周期、用户偏好的时序变化过程,造成模型难于解释、用户偏好捕获不准、评分预测精度不够高等问题,提出了一种改进的综合考虑评分矩阵、项目属性、用户评论标签和时序效应的推荐模型。首先,通过将时间轴划分时间段,利用sigmoid函数将项目的阶段流行度变换为[0,1]区间上的影响力来改进项目偏置;其次,利用非线性函数将用户偏置的时序变化转变为阶段评分均值与总体均值偏差的时序变化来改进用户偏置;最后,通过捕获用户对项目的阶段兴趣度,结合其相似用户在此时间段对该项目的好评率,生成用户项目交互作用影响因子,实现用户项目交互作用的改进。在Movielence 10M和20M电影评分数据集上的测试表明,改进模型能更好地捕获用户偏好的时序变化过程,提高评分预测准确性,均方根误差平均提高了2.5%。
推荐系统;时序效应;奇异值分解;项目流行度;协同过滤
0 引言
推荐系统作为解决互联网“信息过载”的一种有效手段,已得到人们的普遍关注和高速的发展,并已发展成一门独立的学科[1]。尤其自2006年Netflix推荐系统比赛以来,大量关于推荐系统的算法接踵而至,掀起了推荐系统研究的热潮。近年的研究中,许多研究员开始关注时序效应对用户兴趣爱好的影响,并在传统的协同过滤[2-4]、二部图[5]等推荐算法的基础上进行改进,取得了一定成果:文献[6]认为项目的最新评分数据对用户评分的影响比历史数据更大,提出了一种加权皮尔逊相关系数度量项目相似性的协同过滤推荐算法,有效提高了用户最新评分数据对用户推荐结果的影响;文献[7]根据用户消费项目的时序行为构建用户(项目)关系结构图,并将其成功融合到基于概率矩阵分解的协同过滤算法中,不仅提高了预测精度,而且因子向量也具备一定的解释性;文献[8]基于矩阵奇异值分解(Singular Value Decomposition,SVD)技术提出了一种融合时序效应的奇异值分解推荐模型(TimeSVD),该模型引人时间函数拟合用户偏置、项目偏置、用户项目交互作用的时序变化过程,但模型中并未融入引起这些变化的主要因素;文献[9]将时间效应看成与用户、项目特征向量同维度的隐因子向量融入到加入偏置的SVD推荐模型(BiasSVD)[10]中,虽精度得到一定的提高,但过多的隐因子容易造成模型的过拟合现象;文献[11]对上下文(包括时间上下文)相关推荐算法进行了阶段性综述,阐述了时间上下文等信息能对推荐结果产生积极的作用。
值得注意的是,现有的各种考虑时序效应的推荐算法大多只针对评分矩阵建模(如文献[7-9]),而忽略了项目本身属性和用户评论标签对用户评分预测的影响。本文主要针对文献[8]中提出的TimeSVD模型利用复杂的时间函数对用户偏好建模,造成模型解释困难、用户偏好捕获不准、评分预测精度不够高等一系列问题,在充分挖掘评分矩阵,项目属性和用户评论标签等有用资源隐藏信息的基础上,将影响项目偏置、用户偏置、用户项目交互作用时序变化的主要因素融入模型,从而提高模型的评分预测精度。下面先对BiasSVD和TimeSVD模型进行介绍,并在其后章节详细阐述本文改进模型的建模思想。
1 BiasSVD与TimeSVD模型

1.1 加入偏置的SVD推荐模型(BiasSVD)
(1)

1.2 考虑时序效应的SVD推荐模型(TimeSVD)
TimeSVD模型在BiasSVD模型的基础上考虑了时间t对基准预测和用户项目交互作用的影响。模型如下:
bi(tui)=bi+bi,Bin(tui)
(2)
(3)
devu(t)=sign(tui-tu)·|tui-tu|β
(4)
(5)
(6)

2 改进的TimeSVD模型
TimeSVD模型虽已取得较好的预测精度,但整个模型建立在复杂的时间函数之上,并不能解释项目的生命周期、用户兴趣爱好随时间的变化为何会是这样的一个函数关系。与TimeSVD建模思想完全不同的是,本文将这种时序变化的关系建模在其主要影响因素基础之上,从而精确拟合用户真实的评分过程。
2.1 项目偏置bi(tui)的改进
不同于TimeSVD模型对项目偏置的建模,本文认为项目的流行度(popularity)在一定程度上影响着项目的基准得分,因此本文将项目偏置的时序变化建模在项目的阶段流行度基础之上。
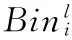

图1 项目偏置时间轴时间段的划分Fig. 1 Phase division of item bias time axis
项目的阶段流行度直接反映为此阶段项目得到的评分和评论数的总数, 因此直接对评分矩阵和评论标签进行统计,获取项目i的阶段流行度,计算方法如式(7)所示:
(7)
其中:card{·}为求取集合元素个数,集合κ(i)、TAG(i)分别为项目i的评分集合和评论集合。阶段流行度表示为本阶段内评分和评论的人数,不能直接作为项目偏置的影响力,因此需要找到合适的变换方式将流行度值变化为[0,1]区间上。庆幸的是sigmoid函数正好满足这样的变换,计算公式为:f(x)=1/[(1+exp(-x))],其能实现(-∞,+∞)的数值变换到[0,1]区间。变换前需要将流行度值作适当调整,调整方法如式(8)所示:
(8)
其中常数C对变换结果起缩放作用,取值根据数据库中用户评分数量的多少而定。为了使每个项目流行度影响力幅度可以动态调整,以适应不断变化的项目偏置,本文为每个项目引入一个流行度影响力变换因子γi,则流行度的阶段影响力可表示为式(9):
(9)


图2 项目阶段流行度对项目偏置的影响力Fig. 2 Influence of item phase popularity to item bias
从图2可以看出,项目阶段流行度的影响力随着时间的增大呈衰减震荡的形式,这正符合项目的生命周期过程。考虑到除流行度外还有其他因素对项目偏置产生影响,本文为每个项目引入一个参数δi表示其他因素造成的项目偏置的变化。这样项目偏置的时序变化最终被建模为:
(10)
式(10) 把时序对项目偏置的影响建模为阶段流行度对目偏置的影响,这样更能反映项目生命周期随时间的变化过程,其中bi为项目偏置变化的基准。
2.2 用户偏置bu(tui)的改进
TimeSVD算法在对用户偏置建模时利用两种非线性函数模拟用户偏置随时间可能的变化过程,虽已取得一定效果,但也有其不妥之处。其中式(4)的主要缺点在于随着时间的不断推进|tui-tu|的值将不断增大,这势必造成参数β调整幅度变得很大,若初始化不恰当极有可能造成训练时均方根误差不收敛;而式(5)极其复杂,需对每个用户u指定ku个控制点(也称为控制核),一方面ku的值较难确定,另一方面算法复杂度也大,很难用于实际的推荐系统。

用户偏置本身被定义为用户的评分均值与总体均值的偏差,此偏差自然反应用户偏置的变化。类似于式(3),用户偏置阶段时序变化被建模为:
(11)
(12)
式(12)为用户阶段评分均值,式(11)中各参数的含义与式(3)相同。这样建模的好处在于充分利用用户评分的阶段统计信息来模拟用户偏置的变化过程,使模型更加合理可靠。
2.3 用户项目交互作用的改进
本文认为正是用户与项目的交互作用才产生了千变万化的评分。用户与项目的交互作用,一方面受用户兴趣爱好的影响,另一方面与其相似用户对该项目的喜好有很大的关系。用户喜欢一个项目,首先要对这种类型的项目感兴趣,其次是其相似用户群也觉得这个项目好,那么这个项目可能会得到目标用户的青睐。
基于这种想法,本文对评分矩阵、项目属性进行深度挖掘,捕获用户在不同时间段对不同类型的项目的兴趣度以及在此时间段内其相似用户群对该项目的好评率,融合二者以得到用户项目交互作用影响因子。
为了捕获用户在不同时间段对不同类型的项目的兴趣度,参照文献[12]为所有项目建立项目属性表。属性表为每个项目附属了一个长度为p的属性向量(ai,1,ai,2,…,ai,p),i∈[1,m],属性值1代表该项目具有此属性,0则无。基于属性表,结合用户评分矩阵,可以统计用户在不同时间段上对各个属性的评价次数,注意这里的时间段的划分应和用户偏置时间段的划分保持一致。这样便得到一个与属性向量同维度的项目属性阶段评价次数向量:
(13)
其中,wu,i(i=1,2,…,p)为用户在项目属性上的评价次数。通过用户阶段属性评价次数向量,可以了解用户近期对项目各个属性的感兴趣程度,从而进一步了解到用户对项目的综合兴趣度。
为了消除不同时间段内评价次数大小不一带来的差异,将用户阶段属性评价次数向量进行归一化处理,如式(14):
(14)

(15)
(16)

(17)
其中:N1为用户u的K近邻中评分了项目i的用户数;N2为N1中4分以上评分的用户数(对于5星级评分项目,4分以上为好评)。这样用户项目交互作用影响因子为:
ω(u,i,tui)∈[0,1],用户项目交互作用部分被建模为:
(18)

2.4 改进模型的确定
通过前面对项目偏置、用户偏置、用户项目交互作用三部分的改进,用户预测评分最终被建模为式(19):
(19)
本文把这个模型称作TimeSVD#。为了学习模型中的参数bi、γi、δi、bu、αu、qi、pu、xi、yu,可以最小化以下平方误差:
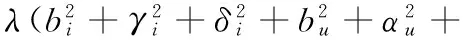
‖xi‖2+‖yu‖2)
常量λ控制正则化程度,一般通过交叉验证获得,最小化过程通过随机梯度下降法实现,算法伪代码如下:
输入 评分矩阵、电影属性、评论标签;迭代次数Iter、学习步长η、正则化参数λ;CI、C、CU;模型参数bi、γi、δi、bu、αu、β、qi、pu、xi、yu初始化值。
输出 TimeSVD#模型参数。
1)
forcount=0;count≤Iter;Iter++ do
2)
foreach (u,i,tui)∈κdo
3)
4)

5)
δi=δi+η·(eui-λδi)
6)
bu=bu+η·(eui-λbu)
7)

8)
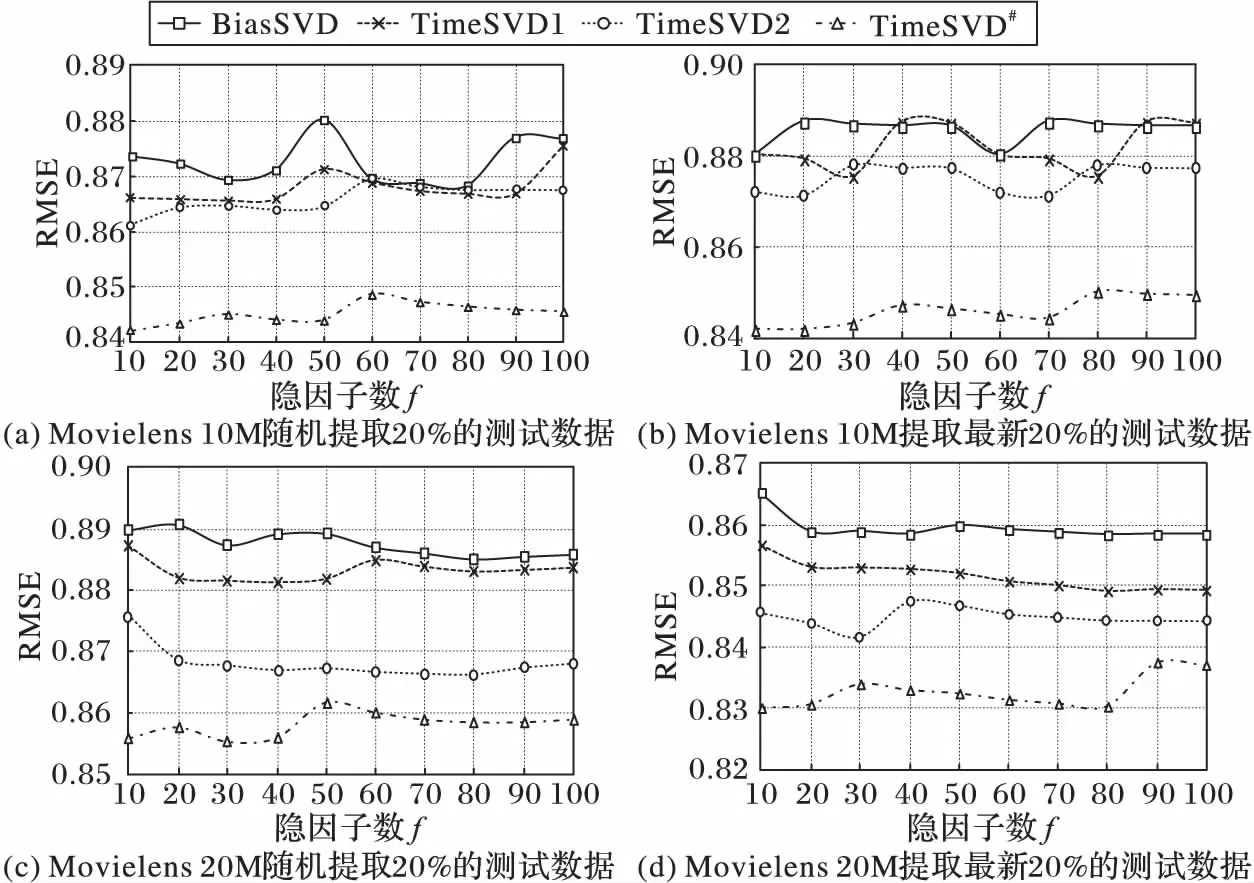
fork=0;k 9) qi,k=qi,k+η·(eui·pu,k·ω(u,i,tui)-λ·qi,k) 10) pu,k=pu,k+η·(eui·qi,k·ω(u,i,tui)-λ·pu,k) 11) xi,k=xi,k+η·(eui·yu,k-λ·xi,k) 12) yu,k=yu,k+η·(eui·xi,k-λ·yu,k) 13) η=0.9η 2.5 时间复杂度分析 TimeSVD#模型的计算过程主要包括两个步骤:第1步计算项目的阶段流行度影响力、用户阶段评分均值与总体均值偏差、用户阶段项目属性评价次数向量和用户相似性系数等信息;第2步利用第1步获得的数据计算各变量的导数,对模型进行训练。 3.1 评价标准 本实验采用推荐系统广泛使用的均方根误差(Root Mean Square Error,RMSE)作为性能评判指标。定义为: 3.2 实验数据集 实验采用著名电影评分数据集Movielens 10M和20M,该数据集由Minnesota大学研究项目组GroupLens团队提供(http://www.gouplens.org),供推荐系统学习和科研使用。该数据集由ratings.txt、movies.txt、tags.txt三个文件组成,分别存储用户评分、电影属性、用户评论标签信息。具体信息见表1。 表1 实验数据集Tab. 1 Experimental datasets 本文采取两种方法提取训练集和测试集。方法一分别提取每个用户最新的20%的数据作为测试集,剩余的80%的数据作为训练集;方法二随机提取每个用户20%的数据作为测试集,剩余的80%的数据作为训练集。 3.3 模型参数的设置 3.3.1 参数初始化 3.3.2 学习速率η和正则化参数λ的选取 学习速率η不仅影响模型的训练时间而且影响模型的预测精度。其值设置过大,虽然训练误差下降快,但是模型参数调整粗糙,容易产生过拟合现象;设置过小,模型参数调整精细,但训练时间较长。正则化参数λ也称惩罚因子,用来避免过拟合现象发生。图3显示了Movielens 20M数据集上提取用户最新的20%的数据作为测试数据,在不同学习率η和正则化参数λ交叉作用下的RMSE三维图。图3呈多波峰多波谷状,二者对RMSE的影响并没有严格的规律可循,一般的做法是选取效果较好的学习率η和正则化参数λ的组合用于模型的训练。本文设置η=0.020、λ=0.028,能取得较为理想的效果。 图3 不同学习率η和正则化参数λ交叉作用下的RMSEFig. 3 Test RMSE under cross influence of different learning rate η and regular parameter λ 3.4 比较实验 本文选取BiasSVD、TimeSVD1、TimeSVD2(用户偏置分别使用式(3)和式(5))与TimeSVD#模型进行实验对比。 图4显示了不同测试集上,训练RMSE降到0.80时,各模型隐因子数(f)与测试RMSE的关系曲线。可以看出,TimeSVD#模型在较少的隐因子数目下已能取得比其他模型较优异的性能,从图(a)与图(b)或图(c)与图(d)的对比看出,TimeSVD#对用户最新评分的预测更为精准,与其他三个模型相比,性能平均提高了3.7%,2.5%和1.4%左右, 说明此模型比TimeSVD模型对用户近期兴趣爱好的捕获更加准确,具有更好的实际应用价值。 图4 Movielens 10M和20M数据集上的实验结果Fig. 4 Experimental results tested on Movielens 10M and 20M datasets 图5显示了Movielens 20M数据集上,选取用户最新20%的作为测试集,f=50时, RMSE与迭代次数的变化关系曲线。可以看出TimeSVD#在5次迭代后即表现出比其他模型优秀的性能,误差能收敛到0.82~0.83,与TimeSVD2模型相比,性能平均提高了2.5%; 而且随着迭代次数的增加,RMSE仍有下降趋势,而其他模型几乎已经收敛。主要原因在于TimeSVD#建立在影响项目生命周期和用户偏好变化的主要因素之上,能有效捕获它们的变化过程,而TimeSVD模型直接利用函数进行拟合,对项目生命周期和用户兴趣漂移的正确捕获具有一定局限性。 图5 不同迭代次数下的RMSE变化曲线Fig. 5 RMSE curves under different number of iterations 本文从影响项目偏置、用户偏置和用户项目交互作用的主要因素对用户偏好建模,通过划分时间段的方式充分挖掘评分矩阵、项目属性和评论标签中的有用信息,能有效地捕获项目生命周期和用户兴趣爱好变化的过程。实验表明,该模型能有效提高用户评分预测精度,取得较好的推荐结果。在接下来的研究中,将尝试对模型引入社交网络、项目结构网络等方面的信息,解决推荐系统用户冷启动和项目冷启动两大经典难题,同时寻求并行化策略,使算法在性能和效率两方面得到进一步提升。 References) [1] 王国霞,刘贺平.个性化推荐系统综述[J].计算机工程与应用,2012, 48(7):66-76.(WANG G X, LIU H P. Survey of personalized recommendation system[J]. Computer Engineering and Applications, 2012, 48(7): 66-76.) [2] SARWAR B, KARYPIS G, KONSTAN J, et al. Item-based collaborative filtering recommendation algorithms[C]// Proceedings of the 10th International Conference on World Wide Web. New York: ACM, 2001: 285-295. [3] SALAKHUTDINOV R, MNIH A, HINTON G. Restricted boltzmann machines for collaborative filtering[C]// Proceedings of the 24th International Conference on Machine Learning. New York: ACM, 2007: 791-798. [4] KOREN Y. Factorization meets the neighborhood: a multifaceted collaborative filtering model[C]// Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2008: 426-434. [5] ZHOU T, REN J, MEDO M, et al. Bipartite network projection and personal recommendation[J]. Physical Review E, 2007, 76(4): 046115. [6] DING Y, LI X. Time weight collaborative filtering[C]// Proceedings of the 14th ACM International Conference on Information and Knowledge Management. New York: ACM, 2005: 485-492. [7] 孙光福,吴乐,刘淇,等.基于时序行为的协同过滤推荐算法[J].软件学报, 2013,24(11):2721-2733.(SUN G F, WU L, LIU Q, et al. Recommendations based on collaborative filtering by exploiting sequential behaviors[J]. Journal of Software, 2013, 24(11): 2721-2733.)[8] KOREN Y. Collaborative filtering with temporal dynamics[J]. Communications of the ACM, 2010, 53(4): 89-97. [9] XIANG L, YANG Q. Time-dependent models in collaborative filtering based recommender system[C]// Proceedings of the 2009 IEEE/WIC/ACM International Joint Conferences on Web Intelligence and Intelligent Agent Technologies. Piscataway, NJ: IEEE, 2009: 450-457. [10] KOREN Y, BELL R, VOLINSKY C. Matrix factorization techniques for recommender systems[J]. Computer, 2009, 42(8): 30-37. [11] ADOMAVICIUS G, TUZHILIN A. Context-aware recommender systems[M]// Recommender Systems Handbook. Berlin: Springer, 2011: 217-253. [12] 杨兴耀,于炯,吐尔根·依布拉音,等.考虑项目属性的协同过滤推荐模型[J].计算机应用, 2013, 33(11):3062-3066.(YANG X Y, YU J, TURGUN I, et al. Collaborative filtering recommendation models considering item attributes[J]. Journal of Computer Applications, 2013, 33(11):3062-3066.) [13] RESNICK P, IACOVOU N, SUCHAK M, et al. GroupLens: an open architecture for collaborative filtering of netnews[C]// Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work. New York: ACM, 1994: 175-186. HUANG Kai, born in 1988, M. S. candidate. His research interests include data mining, recommender system. ZHANG Xihuang, born in 1962, Ph. D., professor. Her research interests include embedded system, computer networking. Singular value decomposition recommender model based on phase sequential effect HUANG Kai*, ZHANG Xihuang (CollegeofInternetofThingsEngineering,JiangnanUniversity,WuxiJiangsu214122,China) The traditional Singular Value Decomposition (SVD) recommender model based on sequential effect only considers scoring matrix and uses complicated time function to fit item’s life cycle and user’s preferences, which leads to many problems, such as difficult to explain model, inaccurate to capture user’s preferences and low prediction accuracy. In view of the drawbacks, an improved sequential effect model was proposed which considered scoring matrix, item attributes and user rating labels comprehensively. Firstly, the time axis was divided into different phases, the project’s popularity was converted to influence in [0,1] to improve project bias by sigmoid function. Secondly, the time variation changes of the user bias were transformed into time variation changes of user rating mean and overall rating mean by nonlinear function. Finally, the influence factors of the user project interaction were generated to achieve the user project interaction improvement by capturing the user’s interest, combining with favorable rate of the similar users. The tests on the Movielence 10M and 20M movie scoring data sets show that the improved model can better capture the time variation change of user preferences, improve the accuracy of scoring prediction, and improve the root mean square error by 2.5%. recommender system; sequential effect; singular value decomposition(SVD); item popularity; collaborative filtering 2016-09-27; 2016-11-26。 黄凯(1988—),男,贵州毕节人,硕士研究生,CCF会员,主要研究方向:数据挖掘、推荐系统; 张曦煌(1962—),男,江苏无锡人,教授,博士,主要研究方向:嵌入式系统、计算机网络。 1001-9081(2017)05-1392-05 10.11772/j.issn.1001-9081.2017.05.1392 TP311.13 A3 实验评估




4 结语
