分布式数据库聚合计算性能优化
2017-07-31肖子达朱立谷冯东煜
肖子达,朱立谷,冯东煜,张 迪
(1.中国传媒大学 计算机学院,北京 100024; 2. 安防大数据处理与应用北京市重点实验室,北京 100024)
分布式数据库聚合计算性能优化
肖子达1,2*,朱立谷1,2,冯东煜1,2,张 迪1,2
(1.中国传媒大学 计算机学院,北京 100024; 2. 安防大数据处理与应用北京市重点实验室,北京 100024)
(*通信作者电子邮箱shawzida@gmail.com)
针对分布式数据库在分析应用方面的聚合计算性能较低的问题,以MongoDB数据库为研究实例,提出了一种基于片键和索引的数据库性能提升方法。首先,通过分析业务特征指导选择的片键字段,该字段需要保证数据在分片节点上的均匀布局; 其次,通过研究分布式数据库的索引效率, 利用删除查询字段索引的方法进一步提升计算性能,该方法能充分利用硬件资源提高聚合计算的性能。实验结果表明,采用高基数粒度的分片片键能够让数据在集群上均匀地分布在各个数据节点上,而舍弃索引使用全表查询能够有效提高聚合计算的速度,聚合计算优化方法能够有效提高聚合计算的性能。
NoSQL;MongoDB;MapReduce;聚合计算;性能优化
0 引言
在大数据应用方面,非关系型数据库NoSQL(Not Only SQL)技术可以满足存储和分析大数据的需求。Moniruzzaman等[1]认为NoSQL的发展是适应超大规模的商业智能和社交网络数据的。不同计算系统需要依据业务模型、事务需求和系统开销来使用NoSQL[2-3]。
MongoDB是近年广泛使用的一种NoSQL数据库,其拥有动态的数据模式、自动分片和聚合计算等功能。相比传统的关系型数据库,MongoDB拥有更多的聚合方法来完成联机分析处理(On-Line Analytical Processing, OLAP)的任务。
聚合方法在单机上无法满足大规模数据的处理,NoSQL则提供了分布式集群架构,比如MongoDB支持水平扩展。除了水平扩展计算资源外,还能从片键选择、索引创建等方面来提高有限资源系统的聚合计算性能。通过分析MongoDB的特性,本文提出一种依据应用场景来选择分片片键的方法,并通过实验分析结果来衡量不同片键分布特征导致的不同影响,表明聚合计算的性能达到了较高水平。
1 相关研究
1.1 MongoDB
MongoDB是一种文档型的NoSQL数据库,其数据以BSON(Binary Serialized Document Format)格式存储。Chitra等[4]指出MongoDB特别合适存储用户信息、产品信息和各种网络内容(博文、消息)。MongoDB的数据模式是动态的,数据结构十分灵活,在同一集合内的文档格式可以不一致,并且单个文档内部还可以嵌套文档或者数组。这样依据应用需求自由存放不同类型的数据的方式在关系型数据库系统上是无法实现的。文献[5-6]比较了MongoDB和关系型数据库的读写性能, 表明MongoDB在数据量越大的情况下表现得越优异;文献[7-9]则在具体应用上使用MongoDB提高系统的处理能力。这些研究分析都表明MongoDB性能是非常优异的。
NoSQL系统的一个关键特征就是分布式模型采用的是“share nothing”架构,在该架构下水平扩展时,不同服务器不会共享硬件资源[10]。MongoDB的水平扩展通过自动分片来实现,这种实现对应用程序是透明的,与单机环境下的MongoDB数据库操作一样。
MongoDB的分片集群成员如下:
1)mongod节点。mongod分片节点用来存储分片集合数据。通常,分片节点接收来自路由节点的操作请求。
2)config节点。config配置节点用来存储分片集群信息。配置节点通常会返回路由节点需要的数据分布信息。
3)route节点。route路由节点用来接收客户端的请求并将操作请求发给每个分片。通过询问config节点来得知目标分片节点的信息。
MongoDB可以通过分片集群来提高系统的可用性,将聚合计算应用到分片集群上时无需应用程序进行附加的操作。分片是分割数据,将数据块分别存储在不同机器上的过程[11],但这种方法只是从资源分配角度提高系统的性能,不能不假思索地认为它就是解决“数据库很慢”的最佳方案。
分片集群的片键是集合的一个键,MongoDB根据片键来拆分数据。对于不同的分片片键类型,聚合计算的效率还是有差别的。分片的片键选择对于集群的读写操作有着重大影响,在实际使用时应该仔细斟酌。拥有良好的分布随机性和局部性特性的片键具有均衡的读写操作性能,但又侧重于不同应用场景:如果应用是“一次写入多次查询”的场景,则应该使用具有最优局部性特征的范围片键;相反,如果是写入操作比读取更加频繁的场景,则应该使用散列片键[12]。
MongoDB的MapReduce功能是MapReduce编程模式[13]的简化实现。在MapReduce模型中, 数据被Map端处理后产生的中间数据要被分配到Reduce端[14]。这是一种非常强大的数据聚合工具。在分片集群的情况下,MongoDB还能进行MapReduce并行计算。图1展示的MapReduce在分片集群下的并行计算。作为MongoDB的路由节点,mongos将客户端发出的请求进行暂存,并询问存储各分片信息的config节点,以获得相关数据的位置; mongos得到数据的分布后,将请求发给各个分片节点shard; 各shard节点进行mapper和reducer处理,并将处理数据返回给mongos; mongos将处理完的数据进行合并以及传递给最后的reducer。

图1 MongoDB的MapReduce模型Fig. 1 MapReduce model of MongoDB
MongoDB提供的MapReduce聚合计算能够帮助完成大量数据的聚合任务。定时执行聚合分析任务考验数据库集群的性能。文献[15-16]将MapReduce运用到在线聚合上通过并行处理提高在线请求的相应速度。文献[17]通过Hadoop的MapReduce计算能力来提高整个MongoDB集群的计算能力,但这样做的副作用是数据的读写性能明显降低。
综上所述,使用MongoDB实现大数据的处理与应用是可行的,但在大规模运行聚合计算时还是存在优化调整的空间。
1.2 相关研究
许多研究人员从如下几个方面提出提升分布式数据库分片性能的方法: 吴润秀等[18]提出了一种基于粒计算的数据分片模型; Liu等[19]通过数据操作频率改进分片集群的均衡性能; Huang等[20]实现了复合自身应用的数据块迁移方法,在其自己实现的自动分片控制器中移动最大频率块, 但是衡量基本数据处理性能时过多地依赖于经验而很难进行预先确认; Wang等[21]通过代理节点实现动态热扩散的负载均衡, 这种方法通过占用更多的资源监控系统负载来实现动态均衡。林基明等[22]提出一种基于分片分配选择器的算法来优化查询执行计划。
在不同的具体应用中,有多种字段可以作为片键的候选字段。Kang等[23]使用MongoDB作为传感器数据仓库,选择采用两个字段作为复合片键:第1个字段设置为粒度适中的字段,第2个字段设置为更细粒度和高基数的字段,这样,第1个字段能够均匀分布在不同分片上,而同一分片上的数据块也能通过第2个字段分割得更加细小。 Kookarinrat等[24]的分析得出,同时拥有随机性和局部性特征的片键可以提供一个优异的读写性能。
以上工作都是从分片负载均衡的角度提高分片性能,而对具有数据分析需求的系统,不能只是简单地在均匀分布集群上套用MapReduce方法,因为数据的均匀分布并不能保证聚合分析任务在各节点上同时完成。因此,对于聚合计算的应用场景,应该采用更有针对性的优化方法。
2 聚合计算优化方法
MongoDB的聚合操作是一种消耗内存资源和磁盘读性能的计算过程。MongoDB的MapReduce是其中最灵活的计算接口。通过建立分片集群,可以有效提高MapReduce的运算能力。在已有硬件资源一定条件下,本文采取一种基于数据特征的优化方法(流程如图2)来提升集群的聚合计算能力。

图2 优化方法流程
Fig. 2 Flow of optimization method
在构建数据集合时,需要预估集群的工作负荷以选择合适的片键。集群数据分布情况受到字段粒度的影响,聚合操作性能也受到查询条件和读写I/O的影响。一个好的片键应该满足写操作扩展和查询分离的目的。通过使用两个字段作为复合片键能够有效地分布数据文件[23],但是这种方法也会增加查询数据的时延,因为均匀分布的数据失去了局部性特征。MapReduce的输入通常为一定范围内的数据,这种情况下,考虑查询字段组成片键能改善时延增加的情况。
在确定字段后,需选择合适的片键类型来确定数据在集群中的分布方式。片键的类型分为连续型、哈希型和标签型三种。默认的片键都是连续型,而连续型片键会导致数据先插入到某个节点,然后再迁移到其他节点。为了解决这个问题,MongoDB引入了哈希片键。哈希片键会为片键字段创建哈希值,MongoDB集群依据该哈希值执行分块和分片操作。集合的分布对于写入和读取都是随机的,这会对读取操作造成影响。在前期实验中发现:由于其较慢的读性能,这种片键方式不太适合MapReduce运行。第三种片键类型是标签型。通过创建分片,可以将片键的指定范围手动指向指定的分片节点上,这样也能得到数据均匀分布的结果。默认连续型和标签型都是比较适用于MapReduce的运行环境。
接下来需要消除相关的索引。因为在大范围读场景中,索引查询将进行两次查询过程,原本能提高查询速度的索引反而会增加数据库的响应时间。关于到底在何时不该使用索引,Chodorow[25]认为当查询需要返回集合中2%~60%的数据时就应该对索引查询和全表查询进行比较,而聚合操作是对集合内全体数据进行聚合计算,查询的数据量远超过普通的即席查询数据量, 所以本文的建议是对于需要聚合操作的数据集合,不对作为片键的字段进行索引。创建片键后,MongoDB可以手动删除该索引,使得在进行MapReduce时采用全表查询的方式。通过上一步片键的选择保证数据的均匀分布,以及这一步的聚合计算全表查询使得聚合计算的性能在有限资源的条件下提高。在后一章的实验分析将会进一步证明。
在实际应用中,集合数据中有如下几个字段可以作为候选片键: _id字段是一种包含自增的时间戳和随机数的ObjectId对象; date字段为MapReduce计算的查询参数,对date字段的索引会影响查询效率; name字段为Map函数分组的依据,数据分片的读写和执行MapReduce的效率会受该字段影响。依据本文方法可以判断出date字段或者date和name的组合字段是合适的片键。
上述方法能在数据库需要应用MapReduce时作为数据库设计的参考方法,下面将通过实验来验证该方法的可行性和有效性。
3 实验与分析
针对不同的应用场景,片键的均匀性、随机性、局部性特征对插入与读取操作的影响各不相同[24]。通过实验来探索不同片键对于聚合计算的影响,并验证本文方法选择的环境是否对聚合计算最优。本文方法通过选择业务的查询字段作为片键字段,还充分利用删除集合索引的步骤来减少聚合计算查询时间。
3.1 实验背景
实验目的是满足邮政局寄递信息离线数据分析需求,其数据库根据寄件日期按月份划分集合存储,每一条运单记录作为一条文档存储在集合中,且每条运单文档包括运单 ID、寄件日期、收件日期以及寄件人和收件人信息。
3.2 实验环境
实验的硬件设备包括6台3.3 GHz CPU、16 GB内存的服务器,硬盘容量2 TB。实验数据采用固定时间范围内的数据以满足MapReduce分析历史数据的场景,数据总量超过2亿条,占用硬盘104.3 GB的空间。
实验的分片集群如图3。MongoDB采用8节点分片集群,其成员配置如下: 4个分片节点(shard1~shard4)、3个配置节点(config)、1个路由节点(mongos)。

图3 分片集群实验环境Fig. 3 Fragment cluster experimental environment
依据片键和索引构成情况的不同将实验内容分为10组,每组实验数据均达到2 000万条。实验数据设计如表1所示。实验01、03、05、07、09组数据集合针对5种片键情况以全表查询的方式实验。01组数据采用时间戳自增的ObjectId类型_id作为片键; 03组数据以_id为片键并创建时间字段标签感知分片(tag-aware)机制,标签分片采用固定时间范围划分数据,时间粒度保证每个分片执行MapReduce的任务量是均等的。01组和03组主要探究标签感知分片功能对MapReduce计算的影响; 05组数据以时间字段作为片键; 07组以字符字段和时间字段组成复合片键; 09组以时间字段和字符字段组成复合片键。这3种分片方式用来与本文提出的优化方法中关于片键的候选片键进行比较。实验02、04、06、08、10组通过索引的方式查询数据,与前一组实验互为对照,以验证本文方法中关于索引问题的论述。

表1 各测试集合的模式Tab. 1 Patterns of each test set
3.3 实验步骤
基于应用的目的,使用MapReduce对数据集合进行聚合统计,聚合计算进行“name”字段分组并统计数量的任务。首先,在进行计算之前,查询“date”时间范围的目标数据。在mapper中,将字符串字段“name”作为分组依据,在reducer中将收到的分组数据进行累加。这个任务能够验证本文方法对聚合计算性能的影响。
此外,为了衡量索引对查询性能的影响,实验将添加对name字段的单值查询,对date字段的范围查询。
每个环境都进行上述两个测试单元,针对每个分片环境的实验步骤如下:
1)导入数据,设置索引、片键以及相关分片配置信息(针对标签分片的操作步骤)。
2)运行MapReduce脚本,依此累加等距时间范围内的数据进行聚合分析,并运行查询脚本,随机查询姓名字符串和时间范围的相关数据。
3)删除数据以及配置信息,重复步骤1)~2)直到完成所有分片情况。
重复进行实验能排除偶然因素对数据产生的影响,在统计性能指标时不会将离群值纳入结果中。
3.4 实验结果与分析
3.4.1 MapReduce的实验结果
片键对于MapReducde并行计算有着很大的影响。如图4、5所示,在相同的索引环境下,使用查询字段(date字段)作为片键的处理速度是最快的,而使用复合索引的运行性能比使用单片键date的性能差。作为复合片键的比较,查询条件匹配越低({date:1, name: 1})的效率要比匹配越低({ name: 1, date:1 })执行速度慢。实验数据中,date字段相比name字段重复值较小。

图4 无索引聚合计算性能指标Fig. 4 Metric of aggreagation without index

图5 有索引聚合计算性能指标Fig. 5 Metric of aggreagation with index
当数据写入完毕,MongoDB分布式环境下运行Balancer进程,该进程会完成各个节点的数据迁移以达到数据均匀的情况。数据分布的最终结果如表2。

表2 各集合分片分布 %Tab. 2 Distribution of shards of each cluster %
从表2中可以看出来,高基数(high cordinality)的字段(date字段)作为片键的首位字段反而不能够有效地将数据均匀分布,证明了将基数粒度较小的字段放置在复合片键首部的情况性能会更好[23]。
通过实验还可以得出,具有过高基数的字段作为片键在查询分离上也会有着明显的性能缺陷。通过表2的分片数据可以看出,_id类型作为片键能将数据均匀分布到分片上,但是这种均匀分布并不能提高分片上并行计算的速度。数据依据时间分布则可以保证时间连续的数据在存储空间上的连续性,这能提高MapReduce的查询效率,但是这种提高远远没有使用其他字段作为片键的性能好。
索引可以提高单次查询的效率,对于MapReduce定位目标数据有着很大的影响。这是MongoDB默认将索引存放在内存中以提高查询速度,但如图6~10的各个片键条件下的MapReduce性能指数表明,没有索引的集合的处理速度最快。这是因为在有索引的情况下,MapReduce需要进行两次查询:一次是在索引条目中查找,一次是根据索引指针去查找相关文档数据。
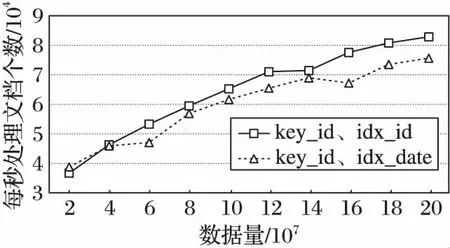
图6 _id片键集合MapReduce性能指标Fig. 6 Metric of MapReduce with _id shard
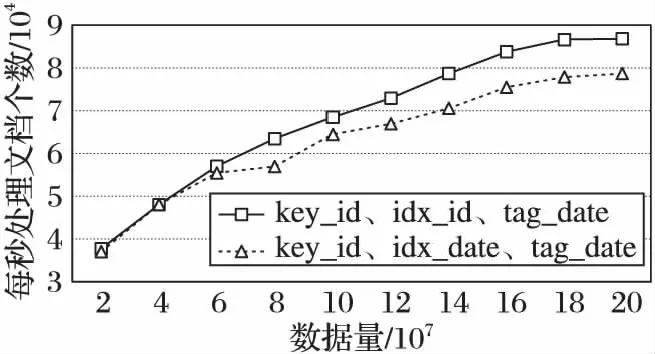
图7 带标签的_id片键集合MapRedcude性能指标Fig. 7 Metric of MapReduce with tagged _id shard
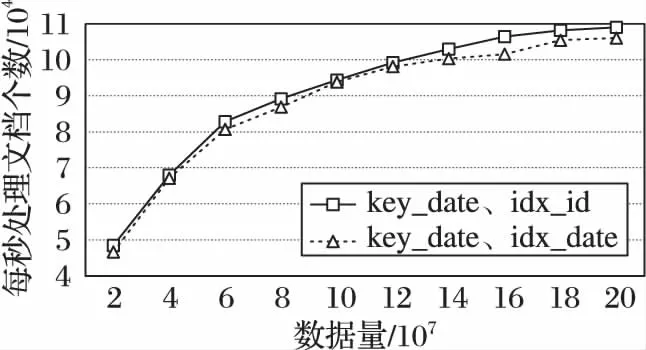
图8 date片键集合MapReduce性能指标Fig. 8 Metric of MapReduce with date shard
从聚合计算的应用场景来说,其目标数据是集合中一部分文档,聚合计算的查询时间复杂度是O(n2);而优化方法针对聚合计算的查询条件,直接进行全表查询来使得查询时间与数据量趋于线性关系。从存储代价方面分析,实验环境下2 000万条数据产生的索引占用内存空间达到 2 GB以上,而将数据量增加到2亿条数据时,内存索引达到了21 GB以上,MongoDB的进程频繁地在内存和磁盘中交换索引,进而降低聚合处理速度。全表查询的MapReduce比索引查询的MapReduce快4倍。通过分析这样的性能指标,可以明显看到本文提出的优化方法对于聚合操作的性能是有明显提升的, 并且数据量越大优势越明显。

图9 name&date片键集合MapReduce性能指标Fig. 9 Metric of MapReduce with combined name&date shard

图10 date&name片键集合MapReduce性能指标Fig. 10 Metric of MapReduce with combined date&name shard
3.4.2 查询操作的实验结果。
单值查询和范围查询是数据库的基本应用场景,数据库可以通过索引提高查询速度,以下将通过实验来验证没有索引的集群对于查询的响应速度。
通过表3可以看出,删除索引显然降低了单值查询的性能。有无索引是对查询条件的字段是否建立索引。

表3 查询响应时间指标 sTab. 3 Response time of search function s
4 结语
分布式数据库的聚合功能使得MongoDB能够满足数据分析的任务,在满足基本统计分析的要求下,应用开发者和数据库管理员还可以从聚合计算框架的特性上进一步调优数据库系统。本文方法以实际的项目出发,分别从片键和索引两个方面来探究MongoDB聚合操作的优化方法,而这种方法能够应用到同类分布式架构的数据库系统。采用高基数粒度的分片片键能够让数据在集群上较均匀地分布在各个节点,而当聚合计算的查询字段是低基粒度的字段时,可以与高基粒度组合成复合片键来满足数据计算和均匀存储的需求。而另一种片键选择的方法适用于部分业务场景,这种片键在较高粒度的字段中选择最能提高聚合计算速度的字段,而不应满足数据的均匀分布。对于聚合计算任务更频繁的情形,舍弃索引查询使用全表查询能够有效提高计算速度。这种索引优化的方法将以降低普通查询响应性能为代价来提高整个分布式系统的计算能力。
综上所述,在一个资源有限的集群中,通过本文方法可以有效提高聚合计算的性能。这种方法从具体的应用场景出发,分析出满足系统聚合计算性能要求的片键并能推广至同类型数据库。
在接下来的工作,还将继续探索MongoDB的最佳设计方法,以帮助数据库管理员合理地配置数据库集群;最终目标是建立一个基于分布式系统的聚合计算模型来完成多种场景管理和分析数据的功能。
References)
[1] MONIRUZZAMAN A B M, HOSSAIN S A. NoSQL database: new era of databases for big data analytics-classification, characteristics and comparison[EB/OL]. [2016-04-20]. https://arxiv.org/ftp/arxiv/papers/1307/1307.0191.pdf.
[2] HAN J, HAIHONG E, LE G, et al. Survey on NoSQL database[C]// Proceedings of the 2011 6th International Conference on Pervasive computing and applications. Piscataway, NJ: IEEE, 2011: 363-366.
[3] HAN J, SONG M, SONG J. A novel solution of distributed memory NoSQL database for cloud computing[C]// Proceedings of the 2011 IEEE/ACIS 10th International Conference on Computer and Information Science. Piscataway, NJ: IEEE, 2011: 351-355.
[4] CHITRA K, JEEVARANI B. Study on basically available, scalable and eventually consistent NoSQL databases[J]. International Journal of Advanced Research in Computer Science and Software Engineering, 2013, 3(7): 1356-1360.
[5] NYATI S S, PAWAR S, INGLE R. Performance evaluation of unstructured NoSQL data over distributed framework[C]// Proceedings of the 2013 International Conference on Advances in Computing, Communications and Informatics. Piscataway, NJ: IEEE, 2013: 1623-1627.
[6] PARKER Z, POE S, VRBSKY S V. Comparing NoSQL MongoDB to an SQL DB[C]// Proceedings of the 51st ACM Southeast Conference. New York: ACM, 2013: Article No. 5.
[7] ABRAMOVA V, BERNARDINO J. NoSQL databases: MongoDB vs cassandra[C]// Proceedings of the International C*Conference on Computer Science and Software Engineering. New York: ACM, 2013: 14-22.
[8] AMERI P, GRABOWSKI U, MEYER J, et al. On the application and performance of MongoDB for climate satellite data[C]// Proceedings of the 2014 IEEE 13th International Conference on Trust, Security and Privacy in Computing and Communications. Piscataway, NJ: IEEE, 2014: 652-659.
[9] KANADE A, GOPAL A, KANADE S. A study of normalization and embedding in MongoDB[C]// Proceedings of the 2014 IEEE International Advance Computing Conference. Piscataway, NJ: IEEE, 2014: 416-421.
[10] CATTELL R. Scalable SQL and NoSQL data stores[J]. ACM SIGMOD Record, 2011, 39(4): 12-27.
[11] 郑静静, 叶焱, 刘太君, 等. 基于 Flex, Red5 和 MongoDB 的视频直播, 录制及存储系统设计[J]. 计算机应用, 2014, 34(2): 589-592.(ZHENG J J, YE Y, LIU T J, et al. Design of live video streaming, recording and storage system based on Flex, Red5 and MongoDB[J]. Journal of Computer Applications, 2014, 34(2): 589-592.)
[12] KAUR H, SINGH J. Improvement in load balancing technique for MongoDB clusters[J]. International Journal of Applied Information Systems, 2015, 8(4):31-35.
[13] DEAN J, GHEMAWAT S. MapReduce: simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107-113.
[14] 杨俊杰, 廖卓凡, 冯超超. 大数据存储架构和算法研究综述[J]. 计算机应用, 2016, 36(9): 2465-2471.(YANG J J, LIAO Z F, FENG C C. Survey on big data storage framework and algorithm[J]. Journal of Computer Applications, 2016, 36(9): 2465-2471.)
[15] MOHAN B, GOVARDHAN A. Online aggregation using MapReduce in MongoDB[J]. International Journal of Advanced Research in Computer Science and Software Engineering, 2013, 3(9): 1157-1165.
[16] RAO B R M, GOVARDHAN A. Sharded parallel MapReduce in MongoDB for online aggregation[J]. International Journal of Engineering and Innovative Technology, 2013, 3(4): 119-127.
[17] DEDE E, GOVINDARAJU M, GUNTER D, et al. Performance evaluation of a MongoDB and Hadoop platform for scientific data analysis[C]// Proceedings of the 4th ACM workshop on Scientific Cloud Computing. New York: ACM, 2013: 13-20.
[18] 吴润秀, 吴水秀, 刘清. 基于粒计算的数据分片算法[J]. 计算机应用, 2007, 27(6): 1388-1391.(WU R X, WU S X, LIU Q. Data fragment algorithm based on granular computing[J]. Journal of Computer Applications, 2007, 27(6): 1388-1391.)
[19] LIU Y, WANG Y, JIN Y. Research on the improvement of MongoDB auto-sharding in cloud environment[C]// Proceedings of the 2012 7th International Conference on Computer Science & Education. Piscataway, NJ: IEEE, 2012: 851-854.
[20] HUANG C W, HU W H, SHIH C C, et al. The improvement of auto-scaling mechanism for distributed database — a case study for MongoDB[C]// Proceedings of the 2013 15th Asia-Pacific Network Operations and Management Symposium. Piscataway, NJ: IEEE, 2013: 1853-1857.
[21] WANG X, CHEN H, WANG Z. Research on improvement of dynamic load balancing in MongoDB[C]// Proceedings of the 2013 IEEE 11th International Conference on Dependable, Autonomic and Secure Computing. Piscataway, NJ: IEEE, 2013: 124-130.
[22] 林基明, 班文娇, 王俊义, 等. 基于并行遗传最大最小蚁群算法的分布式数据库查询优化[J]. 计算机应用, 2016, 36(3): 675-680.(LIN J M, BAN W J, WANG J Y, et al. Query optimization for distributed database based on parallel genetic algorithm and max-min ant system[J]. Journal of Computer Applications, 2016, 36(3): 675-680.)
[23] KANG Y S, PARK I H, RHEE J, et al. MongoDB-based repository design for IoT-generated RFID/sensor big data[J]. IEEE Sensors Journal, 2016, 16(2): 485-497.
[24] KOOKARINRAT P, TEMTANAPAT Y. Analysis of range-based key properties for sharded cluster of MongoDB[C]// Proceedings of the 2015 2nd International Conference on Information Science and Security. Piscataway, NJ: IEEE, 2015:1-4.
[25] CHODOROW K. MongoDB: the Definitive Guide[M]. Sebastopol: O’Reilly Media, 2013: 103.
This work is partially supported by the National Natural Science Foundation of China (61730063).
XIAO Zida, born in 1992, M. S. candidate. Her research interests include distributed system, data visualization.
ZHU Ligu, born in 1965, Ph. D., professor. His research interests include computer system structure, mass storage.
FENG Dongyu, born in 1989, Ph. D. candidate. Her research interests include big data system architecture, distributed system.
ZHANG Di, born in 1987, Ph. D. His research interests include data visualization, cloud storage.
Performance optimization of distributed database aggregation computing
XIAO Zida1,2*, ZHU Ligu1,2, FENG Dongyu1,2, ZHANG Di1,2
(1.SchoolofComputerScience,CommunicationUniversityofChina,Beijing100024,China;2.BeijngKeyLaboratoryofBigDatainSecurity&ProtectionIndustry,Beijing100024,China)
Aiming at the problem of low computational performance of distributed database in analysis applications, taking MongoDB database as an example, a method was put forward to improve the performance of database based on chip and index. Firstly, the characteristics of the business was analyzed to guide the choice of shard key field, and the selected key field needed to ensure that the data is evenly distributed on the cluster nodes. Secondly, by studying the index efficiency of the distributed database, the method of deleting the query field index was used to further improve the computing performance, which could make full use of hardware resources to improve the performance of aggregation computing. The analysis and experimental results show that the shard key field with high cordinality can distribute data evenly on each data node in the cluster, and the use of full table query can effectively improve the convergence speed, thus the optimization method can effectively improve the performance of aggregation computing.
Not Only SQL (NoSQL);MongoDB;MapReduce;aggregation computing;performance optimization
2016-07-01;
2016-11-17。 基金项目:国家自然科学基金资助项目(61730063)。
肖子达(1992—),男,湖南长沙人,硕士研究生,主要研究方向:分布式系统、数据可视化; 朱立谷(1965—),男,北京人,教授,博士生导师,博士,主要研究方向:计算机系统结构、海量存储; 冯东煜(1989—),男,辽宁锦州人,博士研究生,主要研究方向:大数据系统架构、分布式系统; 张迪(1987—),男,甘肃兰州人,博士,主要研究方向:数据可视化、云存储。
1001-9081(2017)05-1251-06
10.11772/j.issn.1001-9081.2017.05.1251
TP316
A
