基于深度模型的场景自适应行人检测
2017-07-26蔡英凤孙晓强袁朝春江浩斌
蔡英凤 王 海 孙晓强 袁朝春 陈 龙 江浩斌
(1江苏大学汽车工程研究院, 镇江 212013)(2江苏大学汽车与交通工程学院, 镇江 212013)
基于深度模型的场景自适应行人检测
蔡英凤1王 海2孙晓强1袁朝春1陈 龙1江浩斌2
(1江苏大学汽车工程研究院, 镇江 212013)(2江苏大学汽车与交通工程学院, 镇江 212013)
针对现有基于机器学习的行人检测算法存在当训练样本和目标场景样本分布不匹配时检测效果显著下降的缺陷,提出一种基于深度模型的场景自适应行人检测算法.首先,受Bagging机制启发,以相对独立源数据集构建多个分类器,再通过投票实现带置信度度量的样本自动选取;其次,利用DCNN深度结构的特征自动抽取能力,加入一个自编码器对源-目标场景下特征相似度进行度量,提出了一种基于深度模型的场景自适应分类器模型并设计了训练方法.在KITTI数据库的测试结果表明,所提算法较现有非场景自适应行人检测算法具有较大的优越性;与已有的场景自适应学习算法相比较,该算法在检测率上平均提升约4%.
场景自适应;行人检测;深度结构;卷积神经网络
现有的行人检测方法可分为2类:基于背景建模的方法和基于机器学习的方法.背景建模法难以应对场景动态变化的问题,仅适用于固定摄像头,如监控场景.而基于机器学习的方法则是利用特征表达,从大量训练样本中学习并构建行人分类器或检测器,其对动态及静态场景均适用,是目前主流的研究方法.
在分类器训练中,特征描述和分类器构造是2个关键问题.在特征描述方面,早期的行人检测方法多采用如纹理、轮廓、边缘等单一特征[1-2].近年来出现了多种更优的人工设计的图像表达特征,如HOG和LBP特征等[3-4].分类器是影响检测性能的另一个关键因素,用于确定最优的决策边界.目前行人检测领域最具代表性的分类器是支持向量机(SVM)和AdaBoost分类器[5-6].近年来又出现了许多改进方法[7],进一步提升了行人检测的性能和速度.
实际应用中,已有检测器在新场景下的行人检测性能往往急剧下降,其主要原因是新旧场景的差异,使得原有训练集和新场景中的样本遵从不同的数据分布.而当新旧场景存在分布差异时,原有基于样本同分布统计学习方法的检测器在新场景下难以有效地检测行人.基于此,场景自适应方法(scene adaptation)和迁移学习(transfer learning)[8-10]逐步引入机器学习领域.与传统的统计学习方法不同,它们利用从一个场景或环境中学习到的知识来帮助完成新环境下的学习任务.
为了实现已有检测器和样本在新场景下的迁移和自适应,首先需要获取新场景下高质量的行人样本.目前在视频行人检测领域,新场景下样本的获取方法主要有人工标注和自动获取2类[11-13].在样本的自动获取方面,常用的方法有:背景减除法[14],其产生的样本可靠性不高;半监督的自训练方法[15],其不能完全反映新场景的数据分布特性;利用上下文信息及跟踪等进行样本选取的方法[16-17].由于新旧场景数据分布可能存在差异,上述方法均存在新场景下自动获取的样本标注的噪声及噪声程度不同的问题,因此需要寻找一种对目标场景下新标注样本置信度进行度量的方法.
设计一个具有场景自适应学习能力的训练方法对行人检测器进行重新训练,也是一个需要解决的关键问题.文献[18]提出了一种采用ConvNet框架的分类器训练方法,该方法通过保留共享滤波器及剔除非共享滤波器实现了分类器迁移.Wang 等[16]提出了一个通用性较好的迁移框架,其在原始的SVM目标函数中加入源-目标场景关联度惩罚项.获取检测器后,重新标注目标样本和源样本,进行新一轮的训练和优化,输出最终的检测器.Cao等[19]对AdaBoost算法进行扩展,提出了ITLAda-Boost方法,该方法通过计算分类器在源和目标数据集上的错分率来动态调整样本权重,最终的分类器由每轮得到的分类器线性加权组合而成.上述方法所采用的特征均为人工设计特征,不能按照分类对象的不同而进行调整;浅层模型的分类器结构也不能很好地描述高维复杂的超平面,因而在分类面生成上也存在局限性.
本文对场景自适应学习算法的样本自动选取和分类器模型的建立进行了研究.首先,借鉴投票机制,提出了一种带置信度度量的样本自动选取方法;然后,利用DCNN深度结构的特征自动抽取能力和特征自编码器对源-目标场景特征相似度的度量能力,构建了新的场景自适应分类器模型并设计了训练方法.
1 采用投票机制的置信样本选取
Bagging(Bootstrap aggregating)是Hamid等[20]提出的一种集成学习方法,它将多个不同的子学习器集成为一个总的学习器.其理论基础是通过选取不同的数据子集,并利用在不同数据子集上训练得到的子学习器的“投票”机制获得对未知样本的最终判定(见图1).
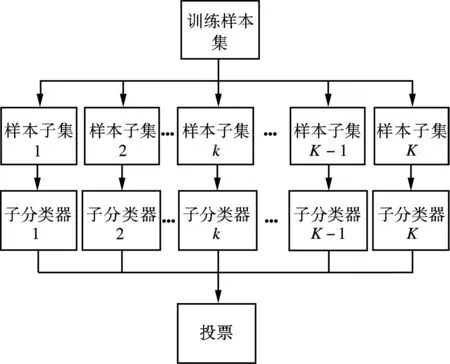
图1 Bagging集成学习方法
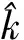
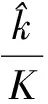
(1)
因为样本均为自动生成和标记,其置信度不大于1,其取值为(0,1].
实际工程中,在不同的场景下,选取不同的时间段,采用不同的图像采集设备,以不同的分辨率采集了K=10个相对独立的数据集.将这些数据集构建成10个样本子集,并用来进行子分类器训练,以实现带置信度的目标场景样本生成.
2 基于DCNN及自编码器的场景自适应分类器训练
现有的场景自适应学习方法均采用低层人工特征进行分类器训练,因此仅在分类器参数层面进行迁移调整.而已有研究结果表明,样本的特征表达方法往往决定了分类器分类能力的上界,分类器参数的训练只能是对该上界的逼近.近年来兴起的深度模型存在结构灵活和具有特征自学习能力两大优点,满足本文应用.因此,本文以深度模型中的深度卷积网络(DCNN)对特征进行抽取,并结合自编码器,利用目标场景样本对所抽取特征进行筛选,寻找并采用更适应目标场景的特征进行分类器训练,从而实现新场景的自适应学习.
本文提出的行人场景自适应学习的训练模型如图2所示.该模型在训练阶段以源场景训练样本和目标场景训练样本共同作为输入,并可以同时完成自动编码重构和分类识别.在特征抽取方面,本文采用一组2层的深度卷积神经网络(DCNN).作为深度学习常用模型之一,DCNN是一种生物启发训练的架构,它隐式地从训练数据中进行特征学习,并具有局部权值共享的结构优势,使得其在图像处理方面有着特征生成效果好、计算复杂性低等独特的优越性[22].本文所采用的DCNN的具体结构及参数如图3所示.
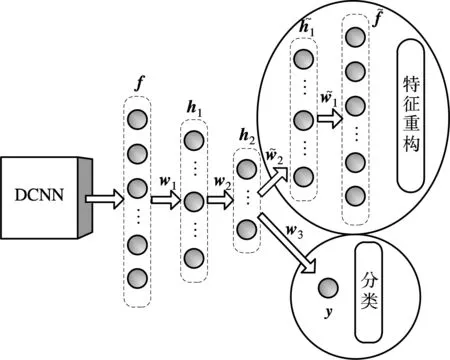
图2 复合深度模型示意图
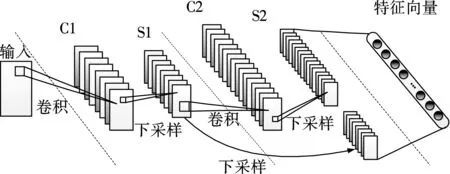
图3 DCNN的具体结构及参数
该DCNN包括1个输入层、2个卷积-下采样层及1个特征向量输出层.其输入层大小为32×64像素,该尺寸和所有待训练样本的像素尺寸保持一致.2个隐层均采用大小为5×5像素的卷积核,下采样滤波器大小均为2×2,选用“池最大”操作.因此,2个隐层的卷积层C1,C2和下采样层S1,S2大小分别为28×60,10×26,14×30,5×13像素.特征层和下采样层S2及下采样层S1的二次下采样层相连,共包含600个神经元.在该结构中,特征向量输出层实质是由下采样层S1和S2组合而成,其目的是保留图像在多尺度下的特征信息.
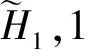
(2)
(3)
(4)
(5)
(6)
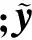
该网络的训练方法如下:设第n个训练样本在DCNN中所抽取的特征为fn,其对应的标签为yn,则该训练样本所对应的参数集为{fn,yn,sn,vn}.其中,vn表示该样本是否属于目标场景,如果该样本属于目标场景,则令vn=1;反之,vn=0.sn是样本的置信度,如果样本属于源场景,则sn=1;反之,sn∈(0,1),由式(1)计算得到.在训练样本参数集设定完成的基础上,以反向传播(back-propagation,BP)算法对网络权值进行训练,并设计了如下目标函数:
(7)
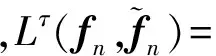
3 实验与分析
在KITTI 道路图像数据库中对本文所提出的场景自适应的行人检测分类器进行实验.在该数据库中,若检测框与实际行人外接矩形框有80%以上的重叠率,则视为实现了一个行人的成功检测.ROC曲线被用来作为各行人检测方法的性能评价指标.
本文中的实验图片均来自于KITTI道路图像数据库,该数据库包含多种道路情况下拍摄的图像,并对道路物体(包括行人)进行了准确标注[23].KITTI道路图像数据库被人为随机地分为训练集和测试集两部分,KITTI训练集含有图片7 481张,其中含有行人约1.3×104个;KITTI测试集含有图片7 518张,其中含有行人约9 000个.实验中,正样本源训练数据仍来自于第1节所述的10个相对独立的行人样本集,不同的是此处将所有行人样本汇集成一个大的正样本库,共计行人样本7 500个.正样本目标场景训练数据来自于KITTI道路图像训练集,由第3节采用投票机制的置信样本选取方法生成,其中c值分别取0.7,0.8,0.9和1.0进行实验.所有训练的负样本则是由KITTI数据库中训练集随机生成的不含行人的图片集构成,共2.0×104张.测试集随机选取了KITTI测试集中的2 000张道路图片,其中含有行人3 687个.
为对所提算法进行评估,将本算法和现有的图像识别中的非场景自适应学习算法和场景自适应学习算法进行了比较,其中非场景自适应学习算法包括DPM[21]、Imagenet深度卷积神经网络(DCNN-Imagenet)[22]及改进的深度卷积神经网络(DCNN-IM)[24],场景自适应学习算法包括文献[16]提出的基于置信编码SVM的算法、文献[19]提出的基于ITL-AdaBoost的算法以及文献[18]提出的基于ConvNet的算法.
图4为不同算法在KITTI数据库下的ROC曲线图,其中,横坐标为单幅图像的误检率(false positive per image, FPPI).从图4可看出,当FPPI为1时,本文方法、文献[18] 、文献[19]、文献[16]的检测率分别为84.6%,80.5%,75.2%和73.7%.与上述场景自适应算法相比,本文算法在检测率上平均提升约4%.此外,当FPPI为1时,3种非场景自适应学习算法的检测率均在70%以下.图5是文献[21]、文献[18]和本文算法在KITTI数据库部分测试图片上的检测结果.其中,绿色实线框为正确检测行人,黄色虚线框为漏检行人,红色虚线框为误检行人.
由图5可看出,与已有的图像识别中的场景自适应学习算法相比,本文所提算法具有目标场景样本生成自动化、目标场景行人识别率高等优势.
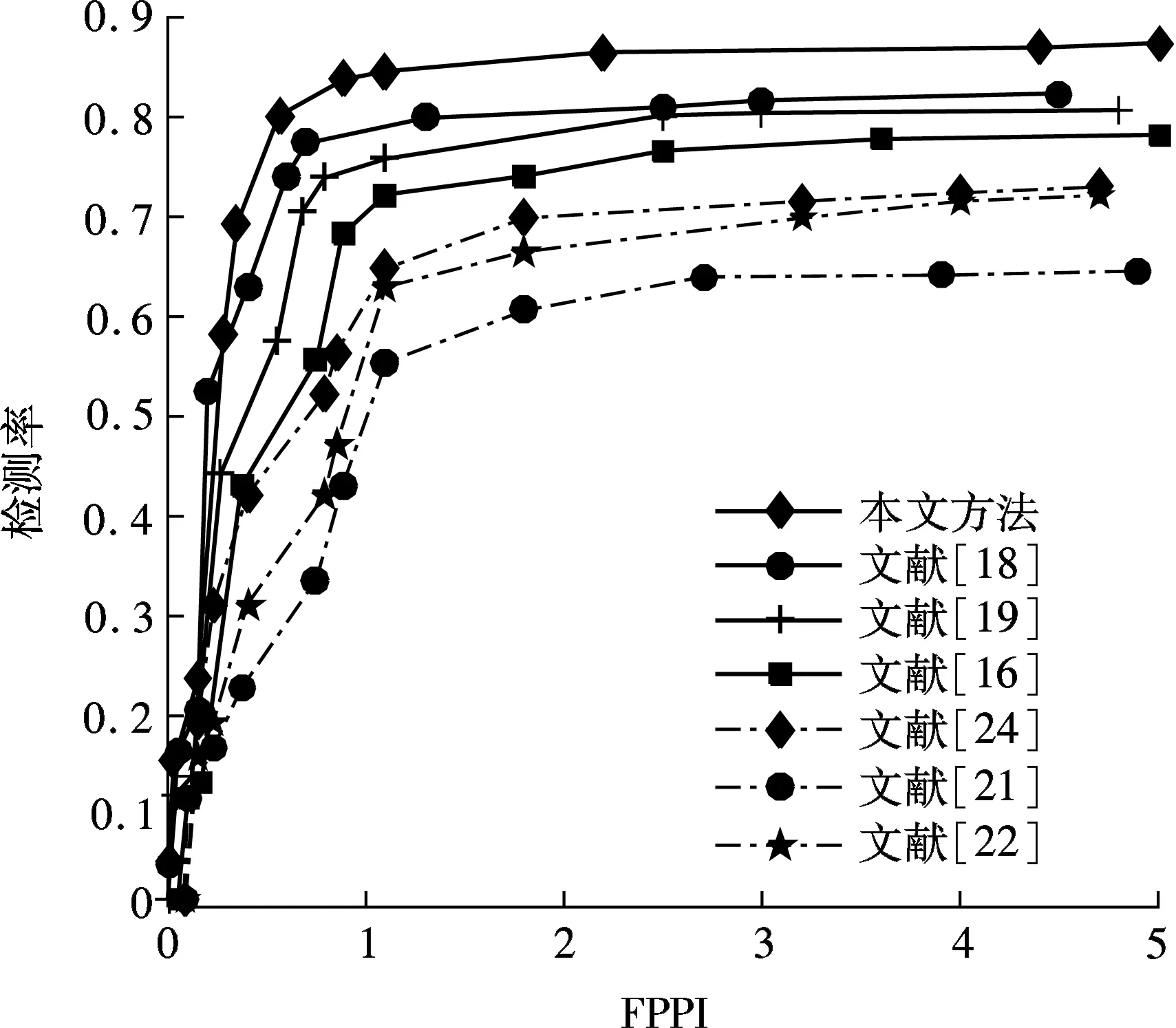
图4 不同算法在KITTI数据库下的ROC曲线图
4 结语
本文提出一种采用投票机制置信样本选取和复合深度结构的场景自适应行人检测算法.借鉴投票机制,提出了一种带置信度度量的样本自动选取方法,解决了新样本置信度评价问题;采用DCNN深度结构,引入具有源-目标场景特征相似度度量能力的自编码器,构建了场景自适应复合深度结构分类器模型,并设计了训练方法.在KITTI数据库上的测试结果表明,所提算法较现有非场景自适应行人检测算法具有较大的优越性;此外,与已有场景自适应学习算法相比,该算法具有目标场景样本生成自动化、目标场景行人识别率高等优势.
References)
[1]曾波波, 王贵锦, 林行刚. 基于颜色自相似度特征的实时行人检测[J]. 清华大学学报(自然科学版), 2012, 52(4): 571-574. Zeng Bobo,Wang Guijin,Lin Xinggang. Color self-similarity feature based real-time pedestrian detection[J].JournalofTsinghuaUniversity(ScienceandTechnology),2012, 52(4): 571-574.(in Chinese)
[2]姚雪琴, 李晓华, 周激流. 基于边缘对称性和HOG的行人检测方法[J]. 计算机工程, 2012, 38(5): 179-182. DOI:10.3969/j.issn.1000-3428.2012.05.055. Yao Xueqin, Li Xiaohua, Zhou Jiliu. Pedestrian detection method based on edge symmetry and HOG[J].ComputerEngineering, 2012, 38(5): 179-182. DOI:10.3969/j.issn.1000-3428.2012.05.055.(in Chinese)
[3]Hoang V D, Le M H, Jo K H. Hybrid cascade boosting machine using variant scale blocks based HOG features for pedestrian detection[J].Neurocomputing, 2014, 135: 357-366. DOI:10.1016/j.neucom.2013.12.017.
[4]孙锐, 陈军, 高隽. 基于显著性检测与HOG-NMF特征的快速行人检测方法[J]. 电子与信息学报, 2013,35(8): 1921-1926. DOI:10.3724/SP.J.1146.2012.01700. Sun Rui, Chen Jun, Gao Jun. Fast pedestrian detection based on saliency detection and HOG-NMF features[J].JournalofElectronics&InformationTechnology, 2013, 35(8): 1921-1926. DOI:10.3724/SP.J.1146.2012.01700.(in Chinese)
[5]孙锐, 侯能干, 陈军. 基于特征融合和交叉核SVM的快速行人检测方法[J]. 光电工程, 2014, 41(2): 53-62. DOI:10.3969/j.issn.1003-501X.2014.02.009. Sun Rui, Hou Nenggan, Chen Jun. Fast pedestrian detection method based on features fusion and intersection kernel SVM[J].Opto-ElectronicEngineering, 2014, 41(2): 53-62. DOI:10.3969/j.issn.1003-501X.2014.02.009.(in Chinese)
[6]崔华, 张骁, 郭璐, 等. 多特征多阈值级联 AdaBoost 行人检测器[J]. 交通运输工程学报, 2015, 15(2): 109-117. DOI:10.3969/j.issn.1671-1637.2015.02.014. Cui Hua, Zhang Xiao, Guo Lu, et al. Cascade AdaBoost pedestrian detector with multi-features and multi-thresholds[J].JournalofTrafficandTransportationEngineering, 2015, 15(2): 109-117. DOI:10.3969/j.issn.1671-1637.2015.02.014.(in Chinese)
[7]王海, 蔡英凤, 陈龙, 等. 基于 Haar-NMF 特征和改进 SOMPNN 的车辆检测算法[J]. 东南大学学报(自然科学版), 2016, 46(3): 499-504. DOI:10.3969/j.issn.1001-0505.2016.03.008. Wang Hai, Cai Yingfeng, Chen Long, et al. Vehicle detection algorithm based on Haar-NMF features and improved SOMPNN[J].JournalofSoutheastUniversity(NaturalScienceEdition), 2016, 46(3): 499-504. DOI:10.3969/j.issn.1001-0505.2016.03.008.(in Chinese)
[8]蔡英凤, 王海. 视觉车辆识别迁移学习算法[J]. 东南大学学报(自然科学版), 2015, 45(2): 275-280.DOI:10.3969/j.issn.1001-0505.2015.02.015. Cai Yingfeng, Wang Hai. Vision based vehicle detection transfer learning algorithm[J].JournalofSoutheastUniversity(NaturalScienceEdition), 2015, 45(2): 275-280. DOI:10.3969/j.issn.1001-0505.2015.02.015.(in Chinese)
[9]Daumé H Ⅲ, Marcu D. Domain adaptation for statistical classifiers[J].JournalofArtificialIntelligenceResearch,2011, 26(1):101-126.
[10]Pan S J, Yang Q. A survey on transfer learning[J].IEEETransactionsonKnowledgeandDataEngineering, 2010, 22(10): 1345-1359. DOI:10.1109/tkde.2009.191.
[11]陈荣, 曹永锋, 孙洪. 基于主动学习和半监督学习的多类图像分类[J]. 自动化学报, 2011, 37(8): 954-962. Chen Rong, Cao Yongfeng, Sun Hong. Multi-class image classification with active learning and semi-supervised learning[J].ActaAutomaticaSinica, 2011, 37(8): 954-962.(in Chinese)
[12]Wang M, Li W, Wang X. Transferring a generic pedestrian detector towards specific scenes[C]//ProceedingsofIEEEConferenceonComputerVisionandPatternRecognition. Providence, Rhode Island, USA, 2012:3274-3281.
[13]Liang F, Tang S, Wang Y, et al. A sparse coding based transfer learning framework for pedestrian detection[C]//ProceedingsofInternationalConferenceonMultimediaModeling. Huangshan, China, 2013: 272-282.
[14]Nair V, Clark J J. An unsupervised online learning framework for moving object detection[C]//ProceedingsofIEEEConferenceonComputerVisionandPatternRecognition. Washington, DC, USA, 2004: 317-324. DOI:10.1109/cvpr.2004.1315181.
[15]Rosenberg C, Hebert M, Schneiderman H. Semi-supervised self-training of object detection models[C]//ProceedingsofIEEEWorkshoponApplicationofComputerVision. Breckenridge, CO, USA, 2005: 29-36. DOI:10.1109/acvmot.2005.107.
[16]Wang M, Wang X. Automatic adaptation of a generic pedestrian detector to a specific traffic scene[C]//ProceedingsofIEEEConferenceonComputerVisionandPatternRecognition. Colorado, CO, USA, 2011:3401-3408.
[17]Sharma P,Huang C,Nevatia R. Unsupervised incremental learning for improved object detection in a video[C]//ProceedingsofIEEEConferenceonComputerVisionandPatternRecognition. Providence, Rhode Island, USA, 2012: 3298-3305.
[18]Li X, Ye M, Fu M, et al. Domain adaption of vehicle detector based on convolutional neural networks[J].InternationalJournalofControl,AutomationandSystems, 2015, 13(4): 1020-1031. DOI:10.1007/s12555-014-0119-z.
[19]Cao X, Wang Z, Yan P, et al. Transfer learning for pedestrian detection[J].Neurocomputing, 2013, 100: 51-57. DOI:10.1016/j.neucom.2011.12.043.
[20]Hamid P, Sajad P, Zahra R, et al. CDEBMTE: Diverse ensemble based on manipulation of training example[J].PatternRecognition, 2012, 7329: 197-206.
[21]Felzenszwalb P F, Girshick R B, McAllester D, et al. Object detection with discriminatively trained part-based models[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2010, 32(9): 1627-1645. DOI:10.1109/TPAMI.2009.167.
[22]Krizhevsky A, Sutskever I, Hinton G. Imagenet classification with deep convolutional neural networks[C]//AdvancesinNeuralInformationProcessingSystems. Lake Tahoe, USA, 2012: 1097-1105.
[23]Geiger A, Lenz P, Urtasun R. Are we ready for autonomous driving? The KITTI vision benchmark suite[C]//2012IEEEConferenceonComputerVisionandPatternRecognition. Providence, Rhode Island, USA, 2012: 3354-3361. DOI:10.1109/cvpr.2012.6248074.
[24]Tomè D, Monti F, Baroffio L, et al. Deep convolutional neural networks for pedestrian detection[J].SignalProcessing:ImageCommunication, 2016, 47: 482-489. DOI:10.1016/j.image.2016.05.007.
Scene adaptive pedestrian detection algorithm based on deep model
Cai Yingfeng1Wang Hai2Sun Xiaoqiang1Yuan Chaochun1Chen Long1Jiang Haobin2
(1Automotive Engineering Research Institute, Jiangsu University, Zhenjiang 212013, China) (2School of Automotive and Traffic Engineering, Jiangsu University, Zhenjiang 212013, China)
To solve the problem that the detection effect of the existing machine learning based pedestrian detection algorithms decreases dramatically when the distributions of training samples and scene target samples do not match, a scene adaptive pedestrian detection algorithm based on the deep model is proposed. First, inspired by the Bagging(Bootstrap aggregating) mechanism, multiple relatively independent source samples are used to build multiple classifiers and then target training samples with confidence score are generated by voting. Secondly, using the automatic feature extraction ability of DCNN (deep convolutional neural network) and adding a deep auto-encoder to perform the source-target scene feature similarity calculation, a deep model-based scene adaptive classifier model is proposed and its training algorithm is designed. The experiments on the KITTI dataset demonstrate that the proposed algorithm performs better than the existing non-scene adaptive pedestrian detection algorithms. Besides, compared with the existing scene adaptive object detection algorithms, the proposed algorithm improves the detection rate on average by approximately 4%.
scene adaption; pedestrian detection; deep structure; deep convolutional neural network
10.3969/j.issn.1001-0505.2017.04.009
2016-11-06. 作者简介: 蔡英凤(1985—),女,博士,副教授,caicaixiao0304@126.com.
国家自然科学基金资助项目(U1564201,61403172,61601203)、中国博士后基金资助项目(2014M561592,2015T80511)、江苏省重点研发计划资助项目(BE2016149)、江苏省自然科学基金资助项目(BK20140555)、江苏省六大人才高峰资助项目(2014-DZXX-040,2015-JXQC-012).
蔡英凤,王海,孙晓强,等.基于深度模型的场景自适应行人检测[J].东南大学学报(自然科学版),2017,47(4):679-684.
10.3969/j.issn.1001-0505.2017.04.009.
TP391.4
A
1001-0505(2017)04-0679-06
