基于大数据的高校教师职业生涯规划研究
2017-07-25方丹丹
方丹丹
(对外经济贸易大学 信息化管理处,北京100029)
基于大数据的高校教师职业生涯规划研究
方丹丹
(对外经济贸易大学 信息化管理处,北京100029)
随着大数据技术的发展,探讨大数据在高等教育领域的深度应用,成为当前高校关注的热点,文章探讨了大数据技术给高校教师职业生涯规划带来的新思路和方法,从数据采集、数据处理、数据应用三个层次构建了基于大数据的高校教师职业发展规划总体框架,并重点介绍了模型和算法的选择,为大数据在高校人才培养方面的应用提供可行性参考。
大数据;职业生涯规划
随着大数据时代的到来,云计算、智能化、移动化、数据挖掘等新兴技术的应用和普及,使得数据处理能力与日俱增,通过大数据技术可以对事物进行多维度、多层次的数据分析,获得有价值的信息,及时准确、全面深入地把握事物发展的规律,对未来的发展方向和趋势进行预测,极大地提高我们认识世界的能力。在教育领域,也迅速掀起了大数据促进教育改革和创新发展相关研究的热潮,大数据的教育应用研究迅猛发展起来。2014年3月,教育部办公厅印发的《2014年教育信息化工作要点》中指出:加强对动态监测、决策应用、教育预测等相关数据资源的整合与集成,为教育决策提供及时和准确的数据支持,推动教育基础数据在全国的共享。可见,大数据与教育领域的深度融合,是当前教育事业发展的必然趋势。大数据技术应用于高校教师职业生涯规划的研究也是重要的研究方向,定性的研究方法向定量化的研究方向转变,确定教师职业发展规划的指标因子以及挖掘教师个人信息中的知识与规律,创新研究教师职业发展的路径,通过对不同岗位、不同阶段、不同目标的教师在自我认知的数据分析基础之上,辅助教师制定个人的职业生涯规划。
一、大数据概述
大数据(Big Data)一词最早出现在20世纪90年代,主要用来表示数据的量化特征,相当于日常用语中的“数据量大”[1]。而2008年9月《自然》杂志所出版的文章Big Data:Science in the Petabyte Era,将大数据赋予了一种全新的科学理念,超越了单纯数量意义的描述,引起了学术界的广泛关注[2]。美国首屈一指的咨询公司麦肯锡是研究大数据的先驱,在其报告《Big data:The next frontier for innovation,competition,and productivity》中给出的大数据定义是:大数据指的是大小超出常规的数据库工具获取、存储、管理和分析能力的数据集。但它同时强调,并不是说一定要超过特定TB值的数据集才能算是大数据。随后,又出现了许多大数据的定义,综合各种定义,概括大数据的特征:并没有明确的界限,它不仅仅是数据量大,还有类型繁多、价值密度低、速度快、时效高的特征。
二、高校教师职业生涯规划的现状和不足
高校教师职业生涯规划是高校教师结合自身特点和所处的环境,制定职业发展目标,对影响职业发展的各方面进行规划,并根据目标的实现程度,不断反馈和调整,最终实现目标的过程[3]。
职业生涯规划对高校教师的发展至关重要,合理的职业生涯规划有助于教师了解自己以及自身所处的职业环境,明确发展方向,预测发展前景,克服发展的盲目性,极大地挖掘自身的潜能,实现个人价值和社会价值。
对于高校教师职业生涯规划的相关研究已取得一些成果,研究者们对现状进行了充分的分析,目前存在的不足主要表现在如下几个方面:高校教师对职业发展满意度较低,且缺乏明确的规划和目标;重视程度和支持力度不够,缺乏系统的职业规划政策和指导;职业生涯规划内容片面、形式单一、缺少创新,缺乏个性化,达不到预期效果;研究成果以理论研究为主,缺少定量研究,缺少可操作的模型。
三、大数据给高校教师职业发展规划带来新机遇和挑战
大数据时代,不仅对高校教师的知识体系、教学方式、教学评价等带来了革命性的影响,也为教师进行职业生涯规划提供了新思路和方法。
1.以大数据为依据,帮助教师建立更完整、准确的自我认知和职业环境认知
良好的自我认知是职业生涯规划的前提和关键,自我认知包括对自己的专业技能水平、性格特征、兴趣爱好、特长、个人需求等各方面的认识和了解,传统的自我认知建立在自己感知的基础上,是感性的认知,不是量化的,而大数据可以将“人”数据化。随着全社会信息化程度越来越高,越来越多的业务依赖于信息化应用,用户在与应用交互的过程中产生大量的数据;此外,网络数据记录了用户的行为,可穿戴设备记录人们的身体状况、行动轨迹等。无处不在的数据,为人们的自我认知提供了量化的工具,使人们能够更加准确客观地认识自己。
职业环境认知包括晋升制度、奖励制度、薪酬制度等学校职业环境,也包括社会地位、收入福利等社会职业环境。职业环境会随着国家或者学校的政策调整而发生变化。大数据时代,高校教师可以更多更快地获取到外界的大量实时信息,学校整体职业环境、学校的发展规划、学科建设情况、职业发展前景都可以通过数据进行展示,为教师分析自身所在的职业环境和职业发展趋势,提供了有力的数据支撑。
2.大数据分析帮助教师选择职业规划路线
在自我认知和职业环境认知的基础上,教师对职业生涯路线做出选择,不同的发展路线,对教师的素质要求不同,也会产生不一样的职业发展的结果。一般而言,教师根据自身的条件和所处的环境,对个人的职业生涯路线做出的判断和选择,很多时候都是主观判断的结果。而以大数据分析为基础,一方面可以清晰地看到不同职业发展路线的要求和区别,也可以看到不同职业发展路线带来的影响和结果,甚至可以看到学校历年的职业发展路线选择的历史数据,为个人进行选择提供依据。
3.个性化的大数据服务辅助教师职业发展
选定职业发展路线之后,教师需要制定阶段性目标,确定相应的教育、发展和培训计划,并做出合理安排,个性化的大数据服务是结合教师的个人特征和阶段性目标,进行个性化的推荐,推荐的内容包括教学资料、科研项目、图书、培训等各个方面,让数据参与到教师的成长过程中,帮助教师更好地发展。
4.大数据报告对阶段性目标进行总结和修正
教师职业规划的过程还包括根据目标的实现程度,不断反馈和调整,最终实现既定目标。大数据报告对教师各方面的数据进行总结和分析,随时生成的大数据报告可以让教师随时了解和掌握目标实现的情况,对产生的偏差进行不断修正和调整。
四、基于大数据的高校教师职业发展规划总体框架
本研究从数据采集、数据处理、数据应用三个层次构建了基于大数据的高校教师职业发展规划总体框架,如图1所示。
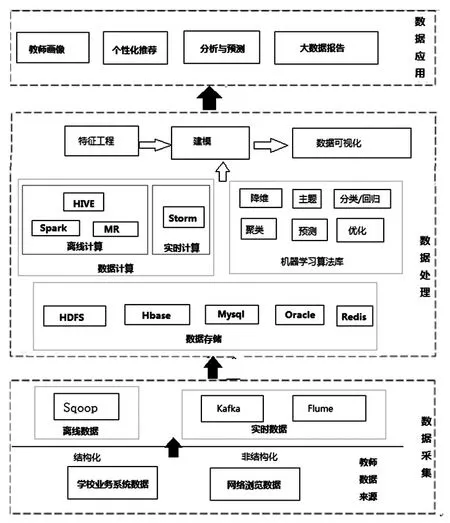
图1 基于大数据的高校教师职业发展规划总体框架
1.数据采集
教师数据主要来源于学校业务系统数据和网络服务器的浏览数据,学校业务系统包括人力资源管理系统、教务系统、教学平台、科研管理系统、图书借阅系统、E卡通系统等,可以获取到教师基本信息、教学信息、科研成果、图书借阅信息、校内消费信息等数据,这些数据大多是结构化数据,不要求实时处理,因此可通过ETL(Extract-Transform-Load)工具进行数据的自动采集,将数据从源端经过抽取(extract)、转换(transform)、加载(load)至目的端。网络浏览数据是从网络服务器获取到用户的网络行为数据,这部分数据以非结构化数据为主,数据量巨大、多类别、更新频率高,可采用一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统Flume工具进行采集。
2.数据处理
数据处理包括数据存储、数据计算、数据分析与挖掘等,本研究采用一个开源分布式计算平台Hadoop。采集到的数据首先要进行数据存储,ETL工具采集到的数据一般存储到传统关系型数据库mysql或者oracle中,再通过Sqoop工具导入到hbase中。Flume采集到的海量网络浏览数据采用Lambda大数据架构,分为批处理和实时处理两部分,批处理部分采用Hadoop实现,包括HDFS和Hadoop MapReduce,包括对全部数据集的预计算。实时处理利用流处理系统如kafka、Storm、S4、Spark等,采用各种复杂的增量算法实现。
数据计算采用分布式计算框架,根据不同的应用场景选择离线计算、交互式计算或者流式计算,主要用到的框架包括 MapReduce、Spark、Impala、Storm等。
数据分析与挖掘使用Mahout机器学习算法库提供的一些可扩展的经典算法的实现,包括聚类、分类、推荐过滤、频繁子项挖掘等,应用到各个不同的模型中。
3.数据应用
本研究的数据应用包括:教师画像、个性化推荐、分析与预测、大数据报告四个部分。教师画像是对现实世界中教师的数学建模,是通过分析挖掘教师尽可能多的数据信息得到的,用标签的集合来表示。个性化推荐基于教师画像的标签特征,构建推荐模型,选择推荐算法,实现推荐感兴趣的信息给教师。分析与预测结合教师画像的标签特征和学校职业规划环境,分析个人职业发展的方向和目标,并预测是否能够达到下一个目标。大数据报告以数据的方式总结个人阶段性成果,分析职业发展过程中现实和目标的偏差。
五、基于大数据的高校教师职业发展规划的模型与算法
教师画像、个性化推荐、分析与预测、大数据报告四个部分既是一个整体,各部分相互联系,又是不同的功能模块,无论是需求设计、功能设计、架构设计、模型和算法设计上都有很大的区别。本研究拟从共性和方法上进行论述,重点介绍模型和算法的选择。
建模的过程是在明确需求、了解数据、构造特征的基础上,根据实际的应用场景,选择模型和算法,本研究的模型和算法如图2所示。
1.数据预处理
数据处理的流程,一般先要明确问题,了解数据的规模,重要特征的覆盖度,并明确需求和数据的匹配度。再对数据进行预处理,数据预处理的过程包括对数据进行集成、数据采样、数据清洗、缺失值处理、噪声数据处理、数据冲突处理等。其次是特征工程,特征是指对所需要解决的问题有用的属性,特征的提取、选择和构造是通过相关系数等方式来计算特征的重要性,针对所解决的问题选择最有用的特征集合,本研究构造的特征包括:教师的性别、年龄、教育程度、籍贯、收入水平等基础属性,教师的教授课程、学生人数、课时量、学生评价等教学属性,教师的论文、科研项目、横向课题、纵向课题、学术会议等科研成果属性,专业、研究方向、职称等专业技能属性,阅读偏好、消费偏好等兴趣偏好,借阅图书、E卡消费、资料搜索等行为属性。

图2 模型与算法
2.模型与算法选择
明确问题和需求后,根据问题的分类,选择模型和算法。
分类问题是找出数据库中的一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据库中的数据项映射到给定的类别中。聚类类似于分类,但与分类的目的不同,是针对数据的相似性和差异性将一组数据分为几个类别。属于同一类别的数据间的相似性很大,但不同类别之间数据的相似性很小,跨类的数据关联性很低。回归分析反映了数据库中数据的属性值特性,通过函数表达数据映射的关系来发现属性值之间的依赖关系。关联规则是隐藏在数据项之间的关联或相互关系,即可以根据一个数据项的出现推导出其他数据项的出现。
选择模型和算法考虑的因素包括:数据训练集的大小、特征的维度、所要解决的问题是否是线性可分、特征是否独立、对性能有哪些要求等。选择方法可采用奥卡姆剃刀原理,这个原理称为“如无必要,勿增实体”,即“简单有效原理”。比如对于分类问题,只要认为问题是线性可分的,即可采用LR分类器 (Logistic Regression Classifier),该模型比较抗噪,效率高,可以应用于数据特别大的场景,很容易分布式实现。比如Ensenble方法(组合方法),根据training set训练多个模型,然后综合各个模型的结果,做出预测,该方法组合多个模型,可以获得更好的效果,使集成的模型具有更强的泛化能力。
建模时通常会执行多次迭代,选择合适的模型算法,运行多个可能的模型,然后再对这些参数进行微调以便对模型进行优化,最终选择出一个最佳的模型。
3.模型与算法评价
最后需要对模型和算法进行评价,本研究采用广泛应用于信息检索和统计学分类领域的两个度量值:准确率和召回率,来评价结果的质量,如表1所示。
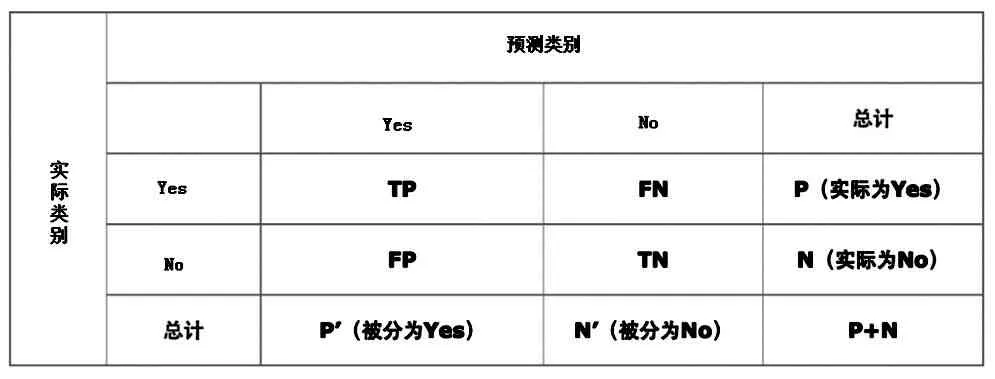
表1 模型和算法评价
准确率accuracy=(TP+TN)/(P+N),就是被分对的样本数除以所有的样本数。通常来说,准确率越高,分类器越好;召回率recall=TP/(TP+FN),召回率是覆盖面的度量,度量有多少个正例被分为正例。
六、结束语
大数据技术的蓬勃发展,带来了各行各业的大数据应用创新,在高等教育领域亦如此,不仅在教学方式、教学管理、学生管理等各个方面,在高校教师的职业发展方面,大数据应用也有其应用价值。本文提出了教师画像、个性化推荐、分析与预测、大数据报告四个方面的创新应用,并从技术角度,在数据采集、数据处理、数据应用三个层次构建了基于大数据的高校教师职业发展规划总体框架,重点讨论了模型和算法的选择。基于本文的研究内容,可作为高校构建支撑高校教师职业生涯规划的大数据平台的参考。未来随着技术的更新和进步,在技术架构、模型和算法的选择方面,可以继续进行更深一步的探讨。
[1]安涛,赵可云.大数据时代的教育技术发展取向[J].现代教育技术,2006(2).
[2]宋学清,刘雨.大数据:信息技术与信息管理的一次变革[J].情报科学,2014(9).
[3]汪霞.关于高校教师职业生涯规划的思考[J].信阳师范学院学报(哲学社会科学版),2010(2).
(编辑:鲁利瑞)
G645
A
1673-8454(2017)14-0072-04
