基于并行数据库的海量数据分析处理方法的研究
2017-07-24梁萌,管阳
梁 萌,管 阳
(陕西国防工业职业技术学院 陕西 西安710300)
基于并行数据库的海量数据分析处理方法的研究
梁 萌,管 阳
(陕西国防工业职业技术学院 陕西 西安710300)
随着计算机信息处理系统的迅速发展,传统的计算机数据处理能力已不能为如今海量的数据处理提供快速,简捷,高效的数据分析处理。针对这一问题,文中提出了并行数据库的海量数据分析处理方法,该方法详细对比了MapReduce和并行数据库技术,然后确定选用并行数据库的方法来处理海量数据。最后在该方法的基础之上,提出了从数据读取到数据处理的整个算法流程,该算法大幅缩短了海量数据处理的时间,使得数据处理更加高效,在未来的发展中有较强的实用价值。
海量数据;并行数据库;处理时间
随着时代的不断进步,信息化的气息也遍布在当今各个领域,尤其在计算机行业。随着系统硬件地不断精确化,系统软件更要不断的更新。近年来,研究者面临着接收、处理、分析爆炸式的数据信息的问题,如何使这些数据更加高效的运转成为了当今研究者普遍关心的问题。海量数据既为大量数据[1],在人们日常生活中,例如水利部门测量的大量数据,气象局不时获得的气象信息等,这些数据均极其庞大,同时这些数据的格式也是千变万化,有声音、文字、图像等。对于一个企业而言,这些数据至关重要,大量的数据统计不仅可发现客户潜在的需求,同时还能够开发出更多满足客服需求的应用。然而,任何事情均有两面性,数据量的增大必然会导致大量数据存储及处理速度的难题[2],为了解决以上难题就必须要求研究者不断提出更高效的算法,本文提出的算法就是在该问题的前提下研究更加高效的数据处理及分析方法。
目前,硬件系统的性能改善已提高到了有限度的境界。此外,文中可从软件上改善数据处理的方式,目前最流行的技术就是多核技术[3],该技术的核心为并行技术,即分而治之,本文所要讨论的并行技术为MapReduce技术和并行数据库技术[4]这两种主流技术。
1 海量数据的存储
对于一个企业而言,数据既是财富,随着信息化时代的飞速发展,数据量的增加突飞猛进,这就要求企业必须解决对海量数据存储的难题。在此阶段,各大企业也均提出了各自的解决方案,成功地完成了大数据的存储难题,目前大多数企业采用文件服务器的方式进行数据的存储,一小部分企业采用服务器内置存储空间的方法来存储文件数据,还有少部分企业采用NAS网关共享SAN网络的方式来存储数据[5]。此外,还有较少的一部分采用NAS网络、集群式NAS、分布式文件系统及多协议支持的统一存储系统解决数据存储问题[6]。随着信息化时代的不断进步,这些方法也会不断的被更新或取代。
2 海量数据的处理
2.1 MapReduce技术
由于Google搜索引擎每天要处理巨大的数据信息,因此该公司在2004年时提出了MapReduce技术,该技术可分为Reduce和 Map两个概念[7]。现实中的诸多东西均可通过Reduce操作表达出来,而表达出的数据通过Map操作进行处理,如图1所示为Map/Reduce执行流程图,从input到output经历了Map/Reduce操作。为了能在不同的机器上运行,Map操作首先将数据进行了分区处理,完成分区处理后,Map操作又将数据进行了分块的处理。在图1中Reduce操作通常根据用户的指定完成数据分区数量和分区函数的划分。

图1 Map/Reduce执行流程
2.2 并行数据库技术
并行数据库技术即将并行计算和数据库技术相融合的产物。为了提高对数据处理的效率,人们不断意识到通过在空间和时间上的并行化处理能大幅改善效率,任务并行和数据并行共同组成了并行计算,两者作用也大相径庭。对于事物的管理和协调,任务并行处理会使其更加复杂化,相反并行数据的功能就是将复杂的,庞大的大任务分解成诸多的子模块,便于处理。吞吐量和响应时间[8]是衡量一个数据库优劣的性能指标,对于并行数据库的设计,研究者要以提高这两者性能为前提。并行数据库的体系架构图如图2所示,该架构的设计是以共享内存为前提设计的[9]。图2所示为共享磁盘及无共享体系设计的体系架构,该体系架构使得所有处理器共同享用一个内存,从而使通信效率极高,访问内存的速度也较快,在对数据进行存取或处理时占较大的优势,故通常情况下选用该体系架构。
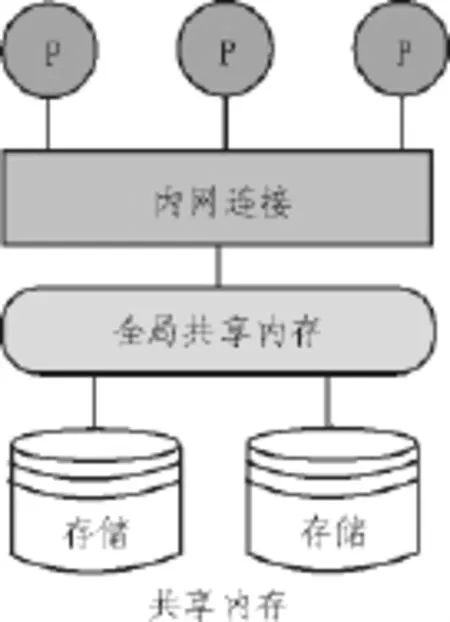
图2 并行数据库的体系架构
通过对MapReduce技术和并行数据库技术的对比,文中选用并行数据库来对数据进行分析和处理,因本算法旨在提高数据库的效率,而索引则是提高数据库效率的一种方式,由于MapReduce技术是不支持索引的,当必须要用到索引时其需要根据应用编写具体的索引程序,而并行数据则将具有共性的索引程序按照标准的格式进行固化,从而大幅度提高了数据库的效率。
2.3 海量数据处理语言选择
对于一般数据而言,通常只需数据库便可完成数据的处理,但对于海量数据库的处理,其还需要程序的帮助才能完成。程序操作文本是处理程序数据库和文本之间快速有效的方法,该方法对于文本的处理出错率低。文本格式能以任何方式存储,通常常见的日志均是以文本格式存储的,对于这些日志数据的清除处理,可选用导入数据库的方法[10]来完成。但通常情况下,对于大量数据的清除会选用编程处理,因而程序对于处理复杂数据起着至关重要的作用,程序的优劣直接决定着数据的准确性和高效率性。
当处理庞大的数据时,编程语言的选择极其重要,因每一种语言针对的方面不同,在处理不同类问题时效率会出现差异,这就需要编程者在编程之前深思熟虑,仔细权衡编程时间和运行时间的优先性。脚本语言由于运行时间长,因而在大数据的遍历问题上不被人们接受。此外,其无法控制内存的使用及文件的读写程序,且在大数据的处理中大多情况下要为文件进行优化,统筹兼顾,C/C++是处理海量数据的最佳选择[11]。
3 处理海量数据的算法实现
在并行数据库的基础下,对于海量数据库算法实现分成两部分,分别为海量数据库的读取算法和海量数据库的分析算法。前者对于任何文本文件类型的数据,均能够以字符的形式读取出来,后者则需根据海量数据的类型格式进行不同的处理。如图3所示,该文件以.csv格式存储,文件在25 M左右,有152 049行,81列,其存储形式如图3所示,理论上该算法的执行时间约为7 s[12]。
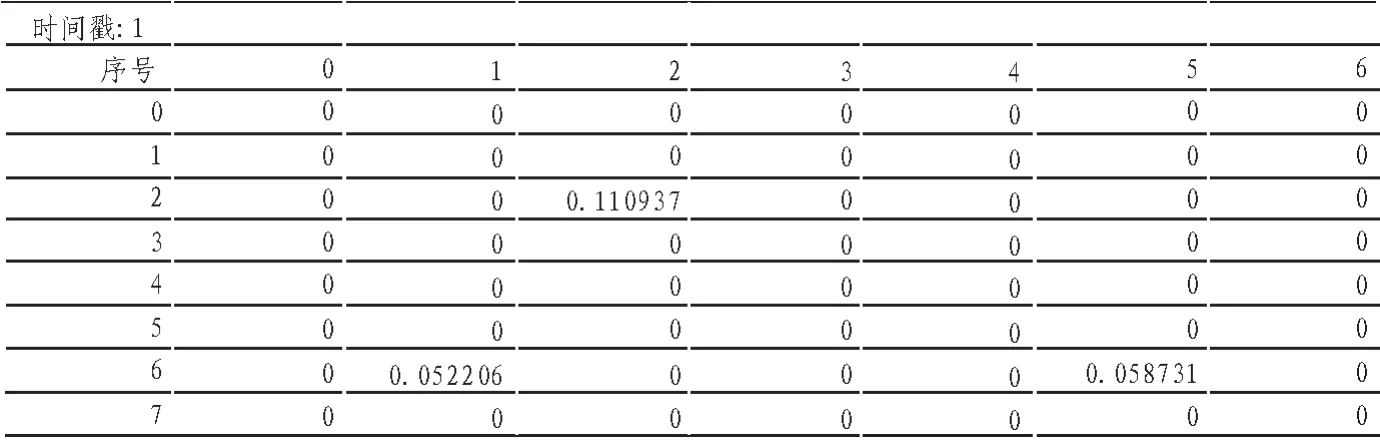
图3 文件内容形式
3.1 海量数据的读取算法
如图4所示为海量数据读取的流程图,该读取算法既是根据该流程编写而成,首先需要为文件创建映射对象[13],完成映射对象的创建之后即可获得系统分配粒度,然后将文件映射对象找到其在应用程序中的地址,查看文件大小,最后文件以字符的形式被读取处理出来。当完成读取之后,撤销文件的映射[14-15],结束整个算法流程。
3.2 海量数据的分析算法流程
该阶段对海量数据分析处理的过程,如图5所示。首先建立信息存储文件库,以csv格式进行存储,数据以逗号作为分隔符是该存储文件的特点,图5所示流程图旨在将图3文件中的各个时间点的有效数据,以及行列值提取出来,算法实现严格按照图5流程图进行编写。图6,7为海量算法执行海量数据的结果图,从图6中可发现,对于海量数据的访问时间达到了7 s的理论值,在图7中也能清析的看到提取的有效数据结果,该算法的验证,对未来大数据的处理,起到了至关重要的作用。

图4 读取海量数据
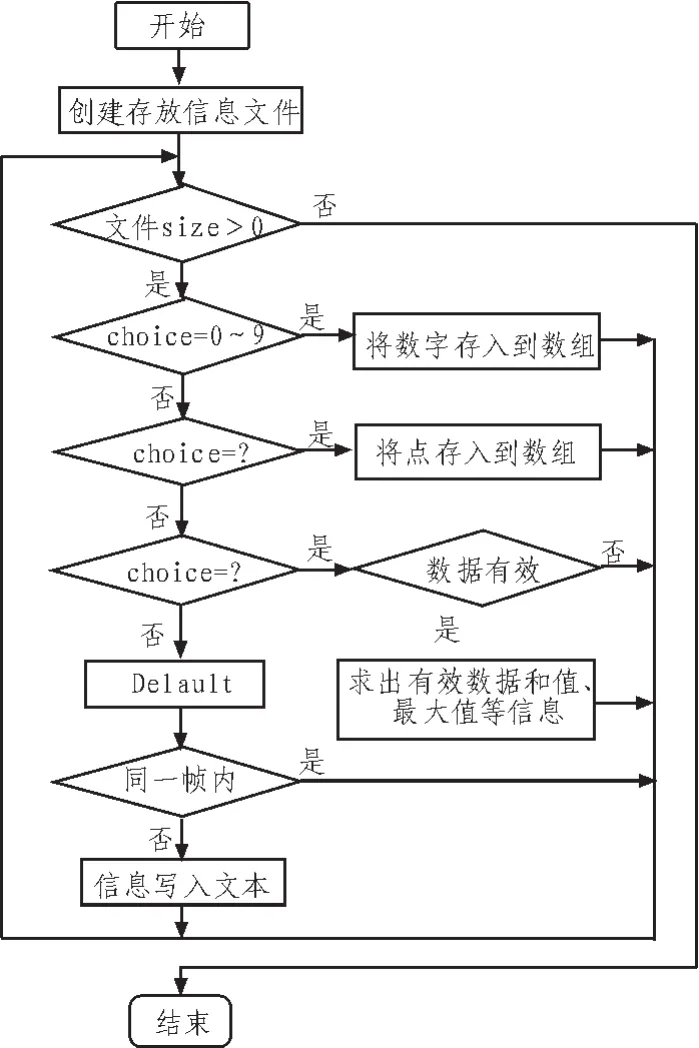
图5 海量数据处理

图6 显示执行时间

图7 提取有效数据结果
4 结束语
文中提出了一种基于并行数据库的海量数据处理算法,该算法旨在解决当前大数据时代下庞大数据存储及处理的难题,通过流程图设计再到算法验证,证实了该算法的可行性及高效性,在未来具有良好的发展前景。
[1]陈康,郑纬民.云计算:系统实例与研究现状[J].软件学报,2009,20(5):1337-1348.
[2]Dean J,Ghemawat S.MapReduce:Simplified data processing on largeclusters[M].In Proc.OSDI,2004.
[3]David J,DeWitt,Jim Gray.Parallel database systems [M].The Future of High Performance Database Processing,1992.
[4]Ben Lorica.HadoopDB[M].An Open Source Parallel Database,2009.
[5]盛昀瑶,夏惠芬.云计算系统架构与实例研究[J].软件导刊,2012,11(12):3-5.
[6]冯朝一.云理论在数据挖掘中的应用研究 [D].南宁:广西大学,2007.
[7]陈丹伟,黄秀丽,任勋益.云计算及安全分析[J].计算机技术与发展,2010,20(2):99-102.
[8]Kostenetskii P S,Lepikhov A V,Sokolinskii L V. Technologies of Parallel Database Systems for Hierarchical Multiprocessor Environments.December,2006.
[9]曹媛媛.云计算关键技术应用及发展[J].电子科技,2011,24(11):141-143.
[10]李凯,常征.基于云计算的并行数据挖掘系统设计与实现[J].微计算机信息,2011,27(6):121-123.
[11]刘鹏.云计算[M].2版.北京:电子工业出版社,2011.
[12]Armbrust M,Fox A,Griffith R,et al.Above the Clouds:ABerkeley View of Cloud Computing[EB/ OL].[2011-01-10].http://www.EECS.berkeley.edu/Pubs/TechRpts/2009/EECS-2009-28.pdf.
[13]李成华,张新访,金海,等.MapReduce:新型的分布式并行计算编程模型[J].计算机工程与科学,2011,33(3):129-135.
[14]拓守恒.云计算与云数据存储技术研究[J].电脑开发与应用,2010,23(9):1-3.
[15]杨丽婷.基于云计算数据存储技术的研究[D].太原:中北大学,2011.
Research on the analysis and processing method of massive data based on parallel database
LIANG Meng,GUAN Yang
(Shaanxi National Defense College of Industrial Technology,Xi'an 710300,China)
According to the rapid development of computer information processing system, data processing ability of traditional computer has not been able to now for the massive data processing provides fast,simple,efficient data analysis and processing,resulting in the massive data parallel database processing method.The methods were compared with MapReduce and parallel database technology,and then determine the selection method of parallel database processing of massive data based on this method,put forward from the read data to the data processing of the whole algorithm,the proposed algorithm can greatly shorten the data processing time,makes the data processing more efficient,there is strong practical value in the future.
massive data;parallel database;processing time
TN99
A
1674-6236(2017)10-0132-04
2016-10-09稿件编号:201610018
国家自然科学基金(60902079)
梁 萌(1981—),女,陕西户县人,硕士,讲师。研究方向:计算机数学教学,数据分析与处理。
