基于数据挖掘的网络用户兴趣分类研究
2017-07-24张志强
张志强
(西安外事学院 陕西 西安 710077)
基于数据挖掘的网络用户兴趣分类研究
张志强
(西安外事学院 陕西 西安 710077)
在移动互联网发展快速的今天,数据是最宝贵的资源之一,如何利用海量数据完成特定应用。本文基于数据挖掘技术实现网络用户兴趣分类为用户提供特定服务,设定合理的用户兴趣模型确保个性化服务优劣的核心。提出一种基于HITS算法通过用户访问量实现兴趣分类的策略,通过网络数据采集、模型分析完成对兴趣数据的处理,得出了HITS在用户兴趣分类方面有较大的优势。
移动互联网;海量数据;数据挖掘;兴趣分类
数据挖掘的基础技术研究已经进展了将近十年,各类基于数据挖掘的应用服务已经得到了广泛的推广。对于互联网的使用,如何实现面向用户群的特定服务推广是学者专家以及各类互联网公司研究的热点问题,本文提出了一种面向用户兴趣分类的移动互联网数据分类算法。
1 概 述
数据挖掘技术的发展推进了移动互联网应用的广泛推广,根据 CNNIC (China Internet Network Information Center)公布的统计结果表明,截止到2015年12月,中国网民规模达到6.88亿,手机用户也达到了1.27亿,如何提升用户上网感知度是当前互联网研究的热点问题。
网络用户兴趣分类是指根据互联网用户的访问点击量来实现自动分类推荐功能,常见有通过统计关键词、点击链接等方式来统计用户的兴趣热点,比如用户输入关键词“苹果”,有些用户关注水果“苹果”方面的知识,有些用户关注“IPhone”等系列电子产品的知识,通过这种方式形成个性化服务。利用数据挖掘技术完成个性化服务的研究[5]。
当前对于兴趣分类研究,国内外学者已经做了大量的研究工作,Cantador I[1]等人提出了一种从个人配置的语义信息文件中获取用户兴趣的方法。主要策略是对用户共享的这些语义信息文件进行聚类,得到若干类簇,并根据聚类结果,建立多层结果的兴趣模型。Kramar T[2]等人提出了一种基于元数据的用户兴趣模型,其中元数据是由从用户访问的每个页面提取的关键字,术语和标记等词组与扩展的词组合而成的序列。当用户使用短语进行搜索时,可以根据这种扩展的词组能准确的获取用户所需要的信息。Liu Z,Chen X[3]等人针对微博用户发表的信息的嘈杂性和词语的多样性,提出一种将基于转化的方法和基于频次的方法相结合的关键词提取方法来挖掘用户的兴趣。
文中提出一种利用数据挖掘技术实现网络用户兴趣分类的应用模型,首先介绍了经典的HITS模型理论,从数据采集、理论分析等方面介绍模型的具体实现过程,并通过实验分析了模型的性能特性。
2 HITS模型介绍
在互联网搜索领域中,HITS(Hypertext Induced Topic Search)算法是一种重要的基于权重排序的互联网数据搜索算法,HITS算法的核心是利用网页设计中两个通用的值:hub值与authority值,所谓hub值是由页面所指向的所有网页的authority值构成;而authority值由指向该页面的所有网页hub值构成。在互联网应用中,通常采用较高权值的网页更加倾向与其它相关网页进行连接,换句话说,多个权值高的网页若指向同一个未知网页,那么该网页具备更高权值的可能性会很大[5-7]。
HITS的逻辑实现过程如下公式如下所示,描述过程如下:假设在实际网络中节点i在时刻t时的authority值由所有指向i节点在t-1时刻的hub值累加构成,如公式(1)所示,而公式(2)中表示节点i在时刻t的hub值由节点i所指向的所有节点的t-1时刻的authority值累加构成,而公式(3)和公式(4)是权值计算的迭代过程,经过 n次迭代后实现authority值和hub值的归一化,直到排序结果趋于稳定后停止迭代。
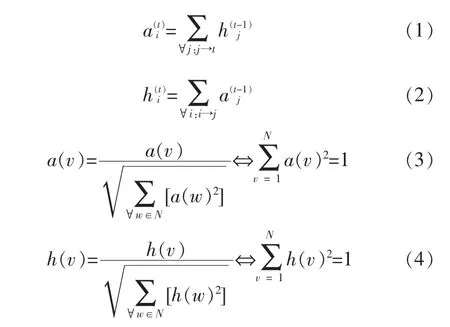
文中针对HITS模型在实际互联网应用中存在的问题进行改进,传统的HITS模型通常在网页访问中将hub中每一个指向的链接都将指定一个权重高的值,假若页面中仅有1条链接,那么hub值会被传递给连接页面的authority值,但如果一个页面存在大量的连接时,将会有大量的hub值被传递给页面的authority值,这显然是不符合实际应用情况的。为此本文对公式(2)提出进行了修改,如公式(5)所示,在模型中增加了网络流的方向性,Oi,out表示用户i的出度。
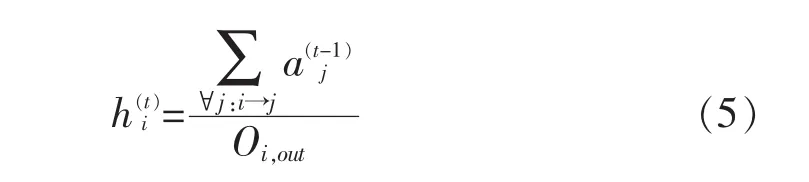
2.1 数据采集
数据采集主要完成模型数据的采集工作,通过对互联网上所关注用户-数据的抓取,利用文献[4]中所提的HTML页面数据收集算法,通过wireshark网络工具采集具体的数据信息。采集结果如表1所示。

表1 数据采集结果
通过将用户浏览的html页面内容表示成文本的特征向量形式,作为数据预处理的过程,便于后续模型的使用。
2.2 模型实现
文中通过Hadoop框架进行模型的实现设计,通过IE浏览器实现搜索引擎的连接,在Hadoop的编程框架中利用MapReduce函数匹配搜索引擎并进行分析处理[6]。在Map阶段对数据进行预处理,去除字段不完整的记录,按照设定的规则拆分相应字段,用于匹配各个搜索引擎的Host字段,然后根据各个搜索引擎的特点,进行相应的解码[10]。采取这种处理模式,实现了对多个搜索引擎(也可认为是多业务输出的目的)的处理,伪代码如下:
2.3 实验验证


在本节中,我们评估使用相应的测试集本文提出的分类器的性能。该实验基于SVM根据该信息在个人网站发布的用户的消费意愿进行分类。本章中所使用的所有数据均来自Amazon.com。
在亚马逊的网站有10个大类和60多万的采购数据,这些数据从数字设备选定表1所示。从所有的采购数据,2 000条记录,随机拿起本实验中使用amazon.com的数据类别。我们删除了这些短信息,最后剩下的是第1 898个标记后,我们获得了990个消费意图的信息和908个没有信息消费的意图[11-15]。
通过获人工标注的方法得测试数据,我们从个人网站随机抽取的发布信息的记录。然后手动注明这些记录是否与消费兴趣相关,依照本文提出的分类算法得出如表3所示的分类结果。
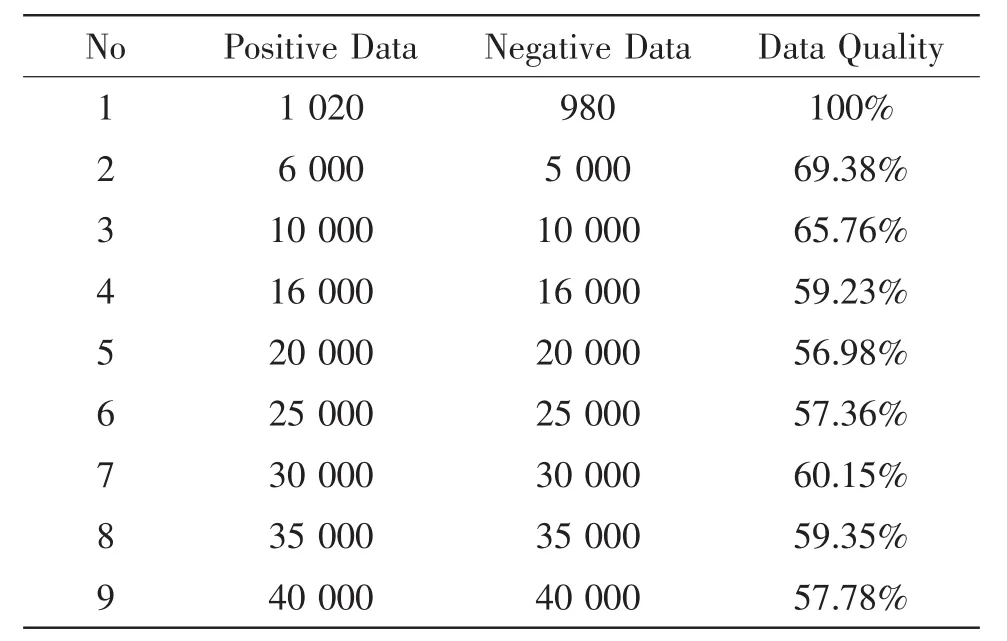
表2 测试数据
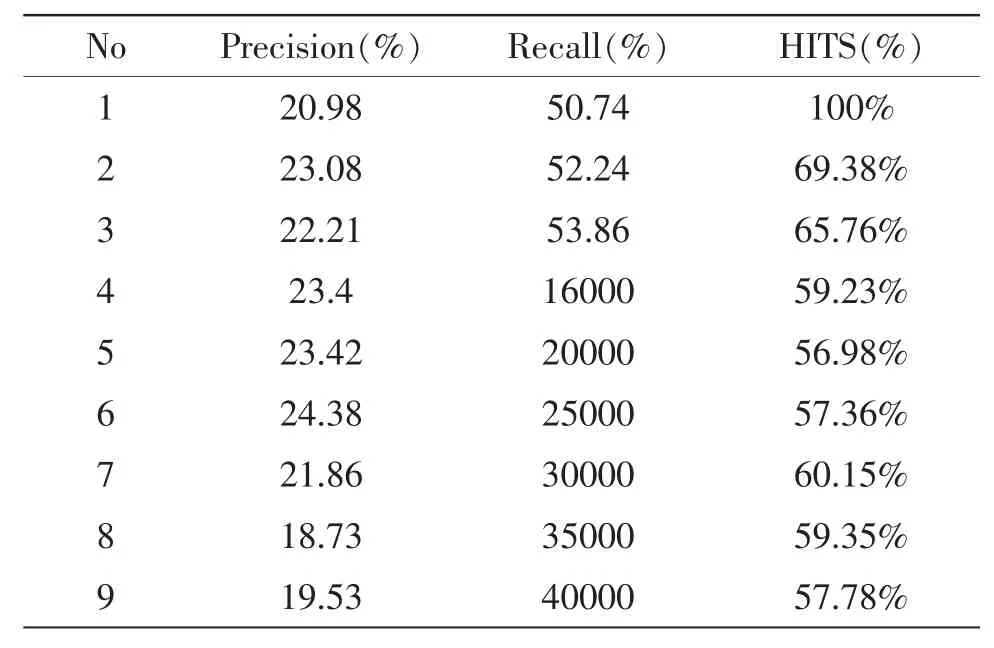
表3 改进的HITS分类性能
通过该测试结果显示在本文提出HITS算法在网络用户兴趣分类上有明显的应用效果。
3 结 论
文中利用数据挖掘的思想设计实现了用于解决互联网用户兴趣分类的研究,利用经典的HITS算法的迭代思想,对算法进行部分改进实现,并且按照数据采集、模型实现,采用Hadoop的挖掘框架完成整个模型的设计,实验证明模型的性能的优势。
[1]Cantador I,Castells R.Extracting multilayered communities of Interest from semantic user profiles:Application to group modeling and hybrid recommendations[J].Computers in Human Behavior,201l,27(4):1321-1336.
[2]Kramar T,Barla M,Bielikovi M.Personalizing search using socially enhanced interest model builtfrom the stream of User’S activity[J].J.Web Eng.,2013,12(1&2):65-92.
[3]Liu Z,Chen X,Sun M.Mining the interests of Chinese microbloggers via keyword extraction[J],Frontiers of Computer Science,2012,6(1):76-87.
[4]梅佩.基于浏览内容的用户兴趣研究[M].北京:北京交通大学,2015.
[5]陈如明.大数据时代的挑战,价值与应对策略[J].移动通信,2012(17):14-15.
[6]陈吉荣,乐嘉锦.基于Hadoop生态系统的大数据解决方案综述 [J].计算机工程与科学,2013,35(10):25-35.
[7]Liu C, Zhou W X.Heterogeneity in initial resource configurationsimproves a networkbasedhybrid recommendation algorithm[J].Physica A:Statistical Mechanics and itsApplications,2012,391(22):5704-5711.
[8]Nacher J C,Akutsu T.On the degree distribution of projected networks mapped frombipartite networks[J].Physica A:Statistical Mechanics and its Applications,2011,390(23):4636-4651.
[9]Pieter N,Michiel H.Mining twitter in the Cloud: A Case Study [C]//CLOUD 2010,Miami,FL,United states, IEEE Computer Society, 2010: 107-114.
[10]Abraham R,Martinez T.Twitter:Network properties analysis[C]//CONIELECOMP 2010,Cholula Puebla,Mexico,IEEE Computer Society,2010:180-184.
[11]余肖生,孙珊.基于网络用户信息行为的个性化推荐模型 [J].重庆理工大学学报自然科学版,2013,27(1):47-50.
[12]Garcia L M.Programming with Libpcap Sniffing the Network From OurOwn Application[J]. Hakin9-ComputerSecurityMagazine,2008:2-2008.
[13]XurenW,Famei H,An implement of broadband network monitoring system based on libnidsand winpcap [C]//New Trendsin Information and Service Science,2009-NISS!09.International Conference on.IEEE,2009:812-814.
Research on data mining classification based on user interest
ZHANG Zhi-qiang
(Xi'an International University,Xi'an 710077,China)
In today's rapid development of mobile Internet,data is the most precious resources,how to use the vast amounts of data to complete a specific application.Thispaperproposedthatthedata mining technology network user interest classification is to provide users with a particular service,andset a reasonable user interest model is to ensure that the core of personalized service merits.Also presenting a user views HITS algorithm to achieve the classification of interest policy,through the network data collection,analysis model to complete the processing of the data of interest,and by examples demonstrate obtain the advantages of the policy.
mobile Internet;vast amounts of data;data mining;classification of Interest
TN929.5
A
1674-6236(2017)10-0034-04
2016-07-18稿件编号:201607130
教育部信息管理中心项目(EIJYB2015053);西安市专项基金项目(16IN08)
张志强(1978—),男,河南许昌人,硕士,讲师。研究方向:数据挖掘、云计算、计算机网络。
