一种基于SAE和BP网络相结合的人脸识别模型
2017-07-24李森林石元泉黄隆华
李森林,石元泉,黄隆华
(怀化学院计算机技术与工程学院,湖南怀化418008)
一种基于SAE和BP网络相结合的人脸识别模型
李森林,石元泉,黄隆华
(怀化学院计算机技术与工程学院,湖南怀化418008)
基于浅层BP网络的模式识别在诸多领域有着广泛的应用,但对于稀疏高维度的数据,在网络模型训练时计算量大、参数繁多、训练慢、准确率低.提出了一种基于稀疏自动编码器(Sparse auto-Encoder,SAE)和浅层BP网络相结合的人脸识别模型.在深度SAE模型中,通过设置隐藏节点数少于输入输出节点数方法,自动学习样本的多种特征表示,来实现数据的降维和去稀疏性,将该方法产生的特征表示作为输入新样本数据,用于BP网络模型进行图像识别.通过人脸识别实验表明,第一通过SAE模型得到的特征表示进行人脸识别是可行的;第二SAE模型获得的多种表示分别进行人脸识别,并非第j层表示比第i层表示(j>i)效果一定好;第三该方法比单纯浅层BP网络进行人脸识别在效果上有一定程度的改善和提高.
稀疏自动编码器;神经网络;人脸识别;高维度数据;维度约减
1 引言
浅层BP网络在模式识别上的应用,经过该领域研究人员多年努力探索,取得了积极的成果.1957年,周绍康提出统计决策理论方法求解模式识别,促进了模式识别研究工作的发展.80年代,荷甫菲尔德发表的两篇重要论文,推动了神经网络在模式识别的研究工作.因为人工神经网络方法具有较强的解决复杂非线性模式识别的能力,因此广泛得到人们的重视[1].虽然人工神经网络的自学习功能非常强大,可以通过反复学习的过程获得对数据背后规则的隐性表达,在模式识别上具有一定的优势;但对于具有稀疏性、多维度数据的神经网络,在模型训练时由于参数繁多,训练慢、准确率差,实现也比较困难.自2006年,加拿大多伦多大学教授、机器学习领域的泰斗GeoffreyHinton和他的学生在《科学》上发表了一篇文章,开启了深度学习在学术界研究热潮,作为深度模型之一的稀疏自动编码器利用人工神经网络的特点,能够自动尽可能的学习复现数据的多种表示[1].稀疏自动编码器(Sparse auto-Encoder,SAE)模型是一种深度无监督特征学习算法,能够根据输入等于输出重构输入数据特征,在图像识别、语音识别、自然语言处理(NLP)等方面表现出较好的优势[1-3],近几年来受到学术界和工业界的高度重视.以多伦多大学Hinton教授和斯坦福大学AndrewNG副教授等人为代表的领军人物,对多层神经网络方面的理论和应用都进行了艰苦探索,开启了对深度网络重新认识和重点研究.目前Google公司、微软公司和百度公司等都成立了自己的深度网络学习研究院,并获得了巨大成功.近几年来,SAE在无监督数据特征自动提取上获得了丰硕的成果.文献[3]从手机和汽车领域产生的语料库,通过SAE模型自动学习其词向量,并完成语句识别.文献[4]中Glorot等人在自动编码器算法的基础上添加纠正激活函数,实验表明效果显著.文献[5]在基于Auto Encoder的智能监控指纹识别系统中通过自动编码器获得网络权值等参数用于指纹图像识别文献.文献[6]将自动编码器算法运用到中文词性标注的文本分类中,获得了一定的效果.文献[7]将堆叠SAE应用于数字图像处理,实现了数据特征降维,并提高了分类精度.由此,通过深度SAE模型能较好地提取数据间连接的隐含特征,并利用这些特征来解决模式识别与数据挖掘问题.为此我们提出了一种稀疏自动编码器和浅层BP网络相结合的人脸识别模型.首先通过深度SAE模型自动学习得到原始样本降维后的多种表示.将该方法产生的特征表示作为输入样本,通过浅层BP神经网络进行模型训练和验证.通过人脸识别实验表明,SAE和浅层BP网络相结合的识别模型,效果上有一定提高.
2 基本模型
2.1 自动编码器模型
自动编码器是使用了反向传播梯度下降算法的人工神经网络模型,由两个主要部分组成,即编码器网络和译码器网络.通过让目标值等于输入值,训练调整网络权重参数直至收敛.每一层的重新编码就是输入数据新的特征表示[2].编码器网络在训练和部署的时候被使用,而译码器网络只是在训练的时候使用.
一般步骤如下:
(1)输入的数据为无标签数据,通过输入到一个自编码器进行重新编码,再通过解码器完成对编码表示的解码.解码后的数据信息和开始时的输入信号构成误差不符合设定的标准时,通过随机梯度下降算法调整优化自编码器模型的节点权重和偏置,直至达到重构误差最小,这样获得的编码就是输入数据信号的一个特征表示,如图1所示.
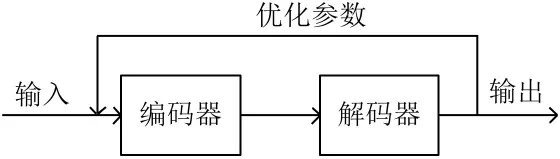
图1 自动编码实现过程
(2)通过自编码器产生的特征表示再作为下一层输入,按步骤(1)训练.得到第二层新的数据表示,SAE多层网络结构如图2所示.
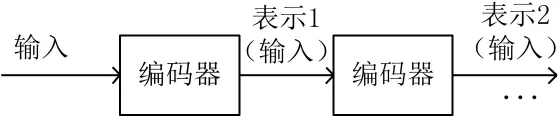
图2 自编码多层网络
2.2 BP神经网络
BP(Back Propagation)是一种基于梯度下降的反馈算法,网络模型通过逆向传播误差来调节各层权值和偏置,直至满足条件为止.该网络模型能学习和存贮输入/输出模式的非线性映射关系,是广泛应用于模式识别算法之一.浅层BP网络模型结构一般分输入层(input layer)、隐含层(hidden layer)和输出层(output layer)共三层,隐层和输出层具有阈值,网络各层节点间的连接具有权值.各层根据输入、权重和激励函数计算输出,最后根据输出值与期望值的误差,据此进行反向传播训练模型,达到可以接受的范围之内,调整权重的算法为一般梯度下降算法.BP神经网络隐藏层和输出层节点的输入依赖于前一层节点的输出.
因为BP算法的非凸性,导致神经网络易陷入局部极小值、收敛速度慢缺点,实验中引入了前人提出的逐步搜索法选择初始权值,用附加动量项和动态变步长方法修改权值.

图3 人脸识别系统
3 算法流程
3.1 总体思路
稀疏自动编码器通过输出约等于输入的BP网络模型,实现对高维空间中的稀疏向量转换为低维空间的向量,并且保留了原始数据的本质特征并实现了去噪和降维的效果,为BP网络实现有监督学习提供了保证[3].本文运用单层和多层SAE方法对输入数据进行特征提取,将提取出的特征再输入到BP神经网络进行训练和识别.人脸识别系统框架如图3所示.
系统人脸识别的具体步骤为:
(1)预处理[4]:预处理过程一般包括二值化、噪声点去除、数字特征分离、图像平滑、归一化处理和细化等过程.在该识别系统的设计中,预处理由二值化(binarization)、归一化(normalization)和平滑(smooth)3大过程组成.首先对人脸图像进行二值化处理,并进行数据归一化,以消除各数字在位置和大小上的差异,从而提高图像识别的准确率.得到归一化后的人脸图像矩阵.
(2)自编码器自动学习特征:特征提取方法的选择是影响识别率的一个十分重要的因素.必须指出的是,对于不同的识别问题和不同的样本数据,使用不同的特征提取方法的适应性差别很大.在一定意义上,特征提取和特征选择的主要目的都是要达到特征降维.特征提取就是要通过某种变换的方法重新组合原始高维特征,获得一组较为低维的新特征,而特征选择是根据某种评价准则或根据专家的经验知识来挑选出那些对分类最具影响力的特征,并生成新的较易处理的特征.由于人脸图像数据特征维度较高,数据量较大,人工提取特征比较困难,本文利用单层Sparse Auto-Encoder方法自动学习每张人脸图像的新特征,并实现降维.由于隐藏层单元数没有一个固定的确定算法,我们根据经验和一般原则进行了不同数值的尝试.
(3)BP神经网络分类与检测:通过自编码器学习的新特征输入到BP神经网络进行训练,直到神经网络收敛或满足停止训练的条件;并利用原始数据进行模型测试,由于原始数据和降维后的特征数据维度不同,需要对原始数据归一化后进行维度约减,本文中采用了相对简单的方法,即在SAE特征提取过程中,对连接权重值约等于零的原始特征数据项进行删除,保留权重值较大相对重要的特征项.
(4)利用人脸识别模型进行人脸识别检测.
3.2 自编码原理
本文通过自动编码器对输入数据的自动学习,采用经典随机梯度下降算法进行训练,为了便于对比,设置了单层、多层的自编码神经网络,图4是一个单层自编码神经网络的示例图[5],学习结构有三层:输入层单元数等于输出层单元数,隐藏层单元数较少,迫使自编码神经网络去学习输入数据的新表示,进行降维和去稀疏性.需要在自编码神经网络加入稀疏性限制,因为输入的数据中隐含着一些特定的关联结构,通过学习就可以获得输入数据中的这些相关性.给隐藏层神经元加入稀疏性限制的规则[6-7]是:神经元的输出接近于1被激活,输出接近于0被抑制.隐藏层神经元j的训练集上平均活跃度公式为


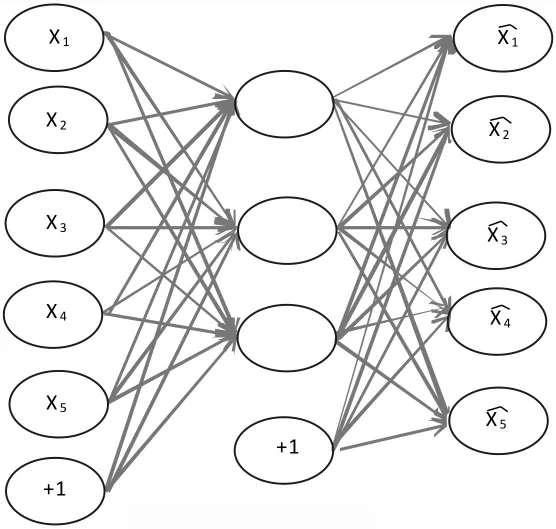
图4 单层自动编码器

在多层桟式自编码器网络中,需要把前一层自编码器的输出作为其后一层自编码器的输入,进而依次训练网络的每一层,来训练整个深度SAE网络.训练思路为:首先训练一个只含一个隐藏层的网络,参数固定后,开始训练有两个隐藏层的网络,在含有两个隐藏层的网络训练完成固定参数,在增加一层,依次类推.最终得到深度网络的所有权重参数和含有不同隐藏层的数据特征表示.用W(k,1),W(k,2),b(k,1),b(k,2)表示第k个自编码器对应的W(1),W(2),b(1),b(2)参数,对栈式自编码网络从前向后的每一层自编码器的编码过程为:a(l)=f(z(l)),z(l+1)= W(l,1)a(l)+b(l,1),其中a(l)表示第l层的输出;从后向前的每一层自编码器的解码过程为:a(n+l)=f(z(n+l)),z(n+l+1)= W(n-l,2)a(n+l)+b(n-l,2),其中,a(n)向量是最深层隐藏单元的激活值,也是对输入值的更高阶的表示.通过将a(n)作为BP网络分类器的输入特征,用于人脸图像识别.
3.3 BP网络训练和验证
公式中增加动态可调整的b为垂直位移,当判断出网络进入平坦区时,按10%调高b参数(初始值为0.1),使其避免因获得0输出而使相应的连接权获得训练机会;公式中ω为水平位移,它使得作用函数沿水平方向左右移动,当f(x)接近1时,减少ω,当f(x)接近0时,增加ω,能提高神经元的自适应能力,同时也加快了算法的收敛速度,尽快脱离平坦区.公式中系数λ决定着Sigmoid型函数的幅度,通过调整参数可以大大改变误差曲面变化率,避开局部极小.
由于采用图像的初始数据进行网络验证,这些数据的维度与自动编码器提取的特征数据维度不一样,必须调整数据维度才能验证网络.考虑到网络的泛化性能,对原始数据归一化后进行维度约减,一对在SAE特征提取过程中,对连接权重值约等于零的原始特征数据项进行删除,保留权重值较大相对重要的特征项;二对近似0的原始特征数据项删除;三随机挑选一定比例的原始特征数据项进行删除.
4 实验分析
4.1 实验过程
实验使用了耶鲁大学的人脸数据库(http://cvc.yale. edu/projects/yalefaces/yalefaces.html),数据库有200幅不同的图像,是一个112×92像素、256级的灰度图像[10-12],但在不同时间、光照略有变化、不同表情和脸部细节下获得的,尺度差异在10%左右,人脸姿态也有相当程度的变化.如图5所示每文件夹有10幅图像.对其进行SAE降维;采用BP神经网络对训练样本集进行训练测试.实验采用Bp网络、PCA+BP和SAE+BP三中模型对上述图像进行了人脸识别,并实验了不同隐藏层神经元数量,取得的一些实验数据.在SAE+BP模式识别实验中,对每幅图像(1×10304行向量)采用了单层、双层和多层隐藏层SAE模型将数据向量维度压缩到1× 1000,1×500,1×200,1×100,1×50.由于将数据向量维度压缩到1×1000和1×50,存在数据维度过大和过小,导致数据特征冗余和损失,不利于人脸识别.故后面实验数据是主要基于1×200和1×100维度下获得的.由于特征表示数据量较多,下面只给出了含有单层、双层的SAE模型下,相对应部分数据特征表示,如表1所示.

图5 人脸图像文件夹

表1 部分人脸数据经过SAE压缩后特征对比
实验过程中对数据进行了单层SAE和多层SAE模型进行了训练和验证,由于超过四层的桟式自动编码器模型参数多,训练难度大,本文仅在含有一到四层隐藏层的模型下,进行了人脸识别训练也验证,误差和准确率如表2所示.通过比较可以看出单层SAE+BP识别率比其它几种模型稍好,在实验过程中发现,基于PCA+BP模型的人脸识别,通过PCA降维损失了部分特征数据,从而造成识别率稍低.在多层SAE+BP模型中,由于随着隐层数量的增加,网络参数指数增加,网络收敛难度较大,易陷入极小值,导致SAE模型获得的多种表示分别进行人脸识别,并非第j层表示比第i层表示(j>i)效果一定好.
4.2 实验结论
人脸图像经过灰度化后可以增强人脸图像的特征,提高人脸的识别率;基于SAE维度约减后可以实现有效的降维,本实验中人脸图像的样本的特征向量为10304维,降维后为100维,可以降低运算量,提高人脸识别的速率;基于桟式的多层SAE网络提取人脸特征用于分类效果有所下降.

表2 不同模型测试数据对比
5 结束语
人脸识别模型很多,不同的模型参数调整非常复杂,没有一个固定的算法,只能不断的选择不同的参数进行尝试.在不断测试过程中,发现固定的学习速率下,稀疏自动编码器网络的隐层数和节点数的选择等在某些情况下都会影响识别率和网络训练速度[12].对于不同情况必须结合数据多次尝试找出相对好的识别方案.设计过程中,不论参数如何调整,都难以大幅度提高识别率.以后需要从改进算法或引入深度学习方法进一步提高识别率,而不是只是方法创新.本文只是提出了一种基于SAE和BP相结合的人脸识别模型,并进行了实验,该模型能否很好的应用于NLP、语音识别以及其它领域有待深入研究.
[1]DAHL G E,YU D,DENG L,et al.Context-dependent Pretrained deep neural networks for large-vocabulary speech recognition[J].Audio,Speech,and Language Processing,IEEE Transactions on,2012,20(1):30-42.
[2]刘勘,袁蕴英.基于自动编码器的短文本特征提取及聚类研究[J].北京大学学报(自然科学版),2015(2):282-288.
[3]贺宇,潘达.付国宏.基于自动编码特征的汉语解释性意见句识别[J].北京大学学报(自然科学版),2015(2):234-240.
[4]ZEN H,SENIOR A,SCHUSTER M.Statistical parametric speech synthesis using deep neural networks[C]//Acoustics,Speech and SignalProcessing(ICASSP),2013IEEEInternational Conference on.Piscataway,NJ:IEEE,,2013:7962-7966.
[5]司马江龙,邓长寿.基于BP神经网络的人脸识别系统[J].江苏:九江学院学报(自然科学版),2011(3):26-28.
[6]秦胜君,卢志平.稀疏自动编码器在文本分类中的应用研究[J].科技技术与工程,2013,31(13):9422-9425.
[7]林少飞,盛惠兴,李庆武.基于堆叠稀疏自动编码器的手写数字分类[J].微机处理,2015,36(1):47-53.
[8]李志清,傅秀芬.基于PCA的3种改进BP算法性能研究[J].计算机工程,2011,37(21):108-110.
[9]李森林,邓小武.基于二参数的BP神经网络算法改进与应用[J].河北科技大学学报,2010,31(5):120-123.
[10]BAHDANAU D,CHO K,BENGIO Y.Neural machine translation by jointly learning to align and translate[J].CoRR,2014:abs/1409.0473.
[11]李康顺,李凯,张文生.一种基于改进BP神经网络的PCA人脸识别算法[J].计算机应用与软件,2014,31(1):158-161.
[12]KRIZHEVSKY A,SUTSKEVER I,HINTON GE.Image net classificationwithdeepconvolutionalneural.etworks[C] //Advances in Neural Information Processing Systems.Red Hook,NY:Curran Associates,2012:1097-1105.
A Face Recognition Model Based on SAE and BP Network
LI Sen-lin,SHI Yuan-quan,HUANG Long-hua
(School of Computer Technology and Engineering,Huaihua University,Huaihua,Hunan 418008)
Pattern recognition based on shallow neural network has a key role in many fields.For sparse highdimensional datum,it has slower training rate and lower accuracy.So,the author proposes a model with sparse autoencoder connecting shallow BP network,In depth SAE model,Multi-features are automatically learned through setting the hidden nodes,being less than the input and output nodes.So data-dimensionality becomes little.New features are inputted into shallow neural network model to train and test.Face recognition experiments show that it is feasible to complete face recognition through SAE model and multi-layer represents mustn't be better than single-layer represents for face recognition and new model has a better result to some extent than only BP neural network.
sparse auto-encoder;neural network;face recognition;high dimension data;dimension reduction
TP3
A
1671-9743(2017)05-0078-05
2016-11-17
李森林,1973年生,男,河北邯郸人,讲师,研究方向:机器学习等.
