基于周期均值叠加法的漳卫南运河产汇流区降雨量预测
2017-07-21戴永翔
戴永翔
基于周期均值叠加法的漳卫南运河产汇流区降雨量预测
戴永翔
(海河水利委员会漳卫南运河管理局,山东德州253009)
漳卫南运河来水量主要由源头产汇流区降水量形成,降水量大小直接决定了中下游径流量。利用周期均值叠加法,对漳卫南运河产汇流区主要控制断面范围内雨量站进行降雨量模拟与实测值对比,预测2017年降雨量,为预测中下游主要控制断面径流量提供基础数据。
周期均值叠加法;断面;预测;降雨;漳卫南运河
1 基本情况
(1)流域概况。漳卫南运河流域位于海河流域南部,流域面积37 700 km2,发源于太行山脉,由漳河、卫河、卫运河、南运河、漳卫新河组成,总体走向为西南向东北,流经晋、豫、冀、鲁4省及天津市,入渤海。
(2)降水特点。流域内降水地区分布不均,多年平均年降水量一般在500~800 mm,局部小于500 mm或大于800 mm。季节分配不均,多年平均夏季(6—8月)降水量占全年降水量的70%~80%,其它季节较少。
(3)主要产汇流控制断面。漳卫南运河产汇流区主要是卫河上游和漳河上游,主要控制断面为合河、淇门、元村和观台,中下游不产流,主要为引用水区。
2 周期均值叠加法
概率统计方法越来越多地应用到水文预报工作中,其基本原则是对大量的历史资料应用数理统计方法,寻求分析水文要素历史变化的统计规律以及与其它因素的关系,然后依据这些规律进行水文预报。笔者利用SPSS统计分析软件,采用周期均值叠加法,分析漳卫南运河上游产汇流区主要控制断面的降水量。
2.1 基本原理
一个随时间变化的等时距水文要素观测样本,可以被看成是有限个不同周期波相互叠加而成的过程,其数学模型为:

式中:x(t)是水文要素系列;pi(t)为第i个周期波系列;ε(t)为误差项。
从样本序列中识别周期波时,可将样本序列分成若干组,当分组组数等于客观存在的周期长度时,组内各个数据的差异较小,但是组间各个数据的差异较大;反之,如果组间差异显著大于组内差异,序列就存在周期,其长度就是组间差异最大而组内差异最小的分组组数。通常而言,一个序列的总体差异是固定的,若组间差异增大,则组内差异就减小,通常可以通过F检验判断组内差异比组间差异小的程度。
2.2 显著性检验
设水文要素随时间变化的等时距样本序列为X(1),X(2),…,X(n),排成表1的形式,其中j=1,2,…,b,表示分为b组,b=2,3,…,m(m=[n/2]);就是说,样本序列可能存在的周期数b为2,3,…,m。i为每-组含有的项数,i=1,2,…,a表示每组有a个数据,Xj为每组的均值。
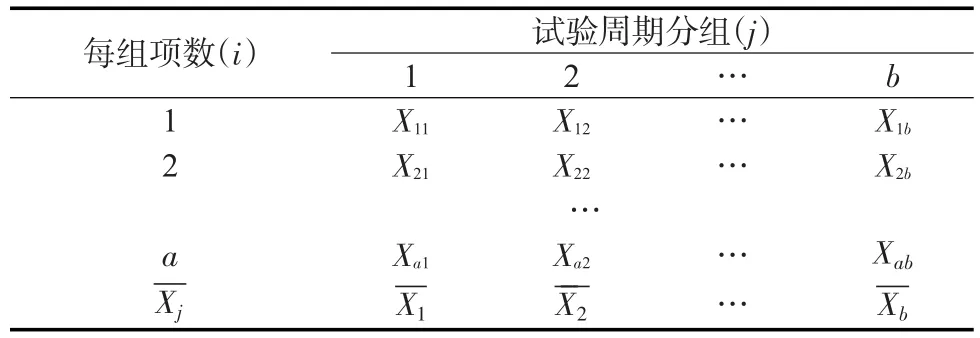
表1 试验周期分组排列
对于不同的b,可计算相应的方差F,其计算公式为:
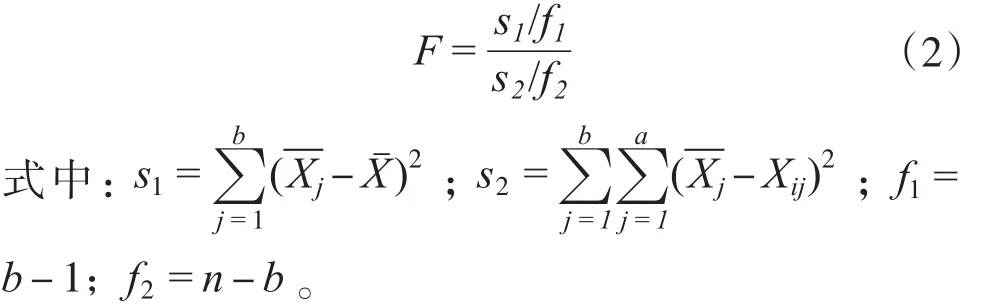
当b=2,3,…,m时,可计算得m-1个F值。由f1、f2以及选定的可信度a,可查出相应的m-1个Fa,挑选最大的F值,与对应的Fa值比较,若F≤Fa,则表明在这一信度上不存在周期,要重新选择可信度;若F>Fa,则表明存在周期,对应的b即为周期长度,各组均值即为第一周期波隔年的振幅。先将所识别的第一周期波按年份排列起来构成第一周期波序列,再从样本中剔除第一周期波序列,形成新序列,重复上述过程寻找新周期,直到不能识别或不想识别为止,然后对所识别的周期波进行外延及线性叠加即可进行预测。
周期均值叠加法就是利用组间与组内的差异来识别数据系列内在的周期,参数主要就是看F检验的检验值。一般情况下,如果通过95%检验,就可认为有对应的小周期,相应的数据系列就可看作是周期波。为防止出现伪周期现象,再用方差分析来识别周期时其信度标准不要太低,一般不要低于0.10。
3 产汇流区降水量预测
由于漳卫南运河产汇流区降水量主要集中在6—9月,其降水量最大,占年降水量的比例最高,采用周期均值叠加法分别对合河、淇门、元村和观台等
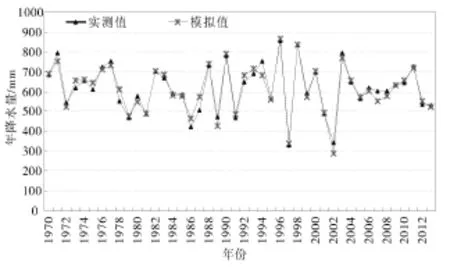
图1 合河站控制区域1970—2013年年降水量与模拟值对比
3.2 其它断面控制区域降水量预测
同理,利用周期均值叠加法对其它断面控制区域降水量进行模拟对比,预测得到2017年淇门站控制区域平均降雨量为592.3 mm、6—9月降雨量为421.2 mm,元村站控制区域平均降雨量为595.9 mm、控制断面所控区域进行年降水量和6—9月降水量预测。卫河流域以合河、淇门、元村为控制断面分别选取雨量站进行降水量分析和预测。漳河流域以岳城水库的入库控制断面观台站控制流域范围选取雨量站进行降水量分析和预测。
由于降水量的历史演变受到多种因素的影响,需要根据实测的降水量资料,借助数理统计的方法进行分析,判定其是否存在着周期性。在分析降水量要素的数据是否存在周期时,根据数据的数目n列出可能存在的周期,一般存在的周期T为2,3,…,k,k=n/2(当n为偶数时),k=(n-1)/2(当n为奇数时)。然后按周期长度T分别排列,每一行为一个T周期,每一列(组)的数值(设有a个)为同一位相的降水量数据值,计算出它们的组间与组内数据差异的大小F(方差比),在这些F值中挑选最大值和选定信度下的Fa进行比较分析,决定其是否存在周期及存在何种周期。如果降水量要素存在着周期性的变化,那么就可以根据分析出来的周期分别进行外推,然后再叠加起来进行降水量预报。
3.1 合河断面控制区域降水量预测
均匀选择合河水文站控制范围内33个雨量站,利用周期均值叠加法对1970—2013年年降水量和历年6—9月降水量进行模拟对比,平均相对误差分别为3.6%和6.5%,模拟值与实际值较为接近(如图1—2所示),以此预测2017年年降水量和6—9月降水量。通过预测得到2017年卫河流域合河水文站控制区域平均降雨量为585.0 mm、6—9月降雨量为448.1 mm,详见表2—3。 6—9月降雨量为389.9 mm,观台站控制区域平均降雨量为532.5 mm、6—9月降雨量为430.4 mm。
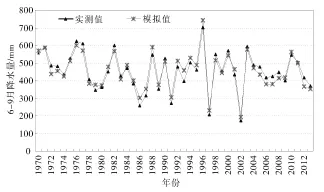
图2 合河站控制区域1970—2013年6—9月降水量与模拟值对比
3.3 成果汇总
利用周期均值叠加法,预测2017年漳卫南运河主要产汇流区降雨量见表4。
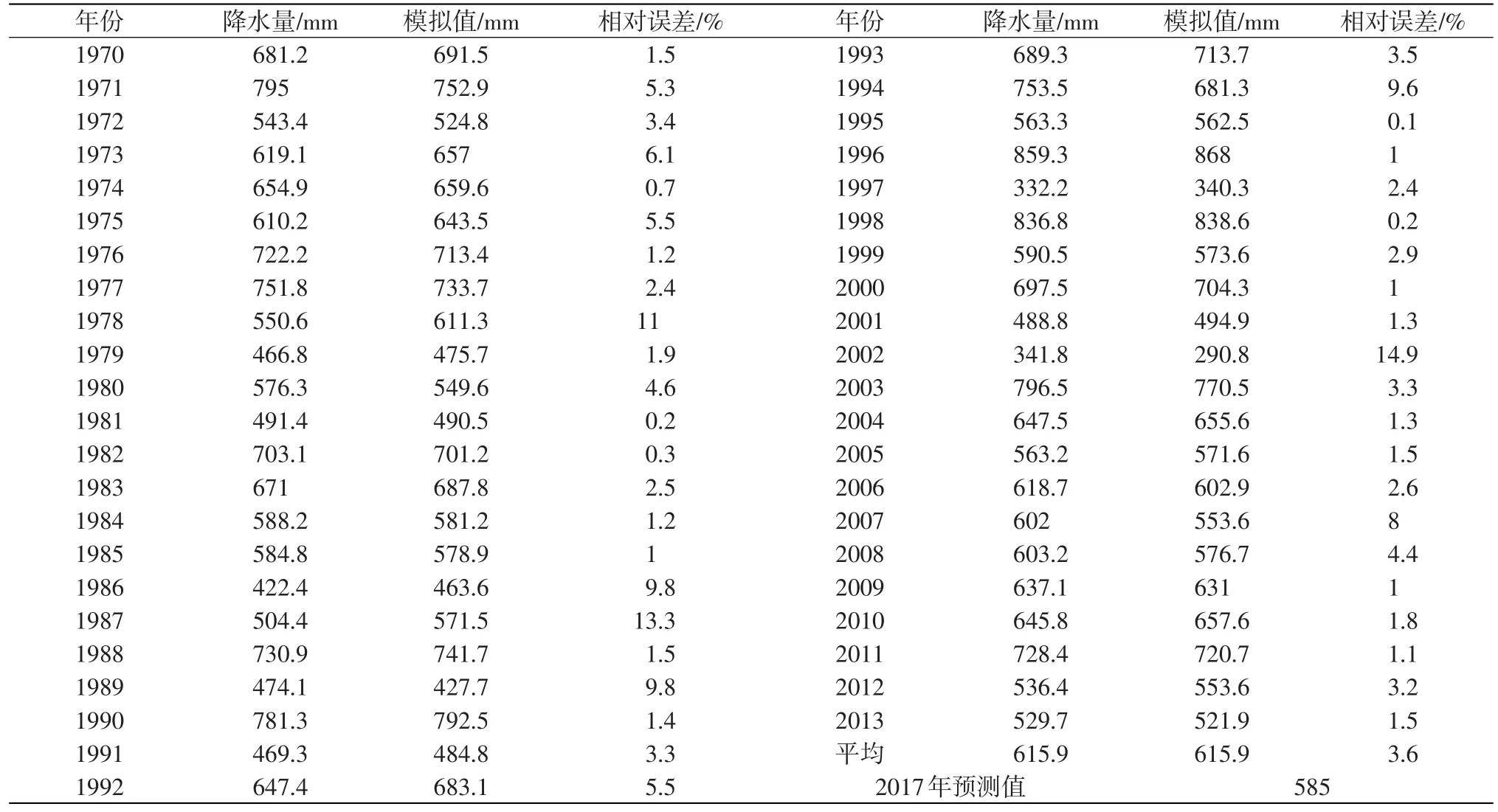
表2 合河站控制区域1970—2013年年降水量与模拟值统计
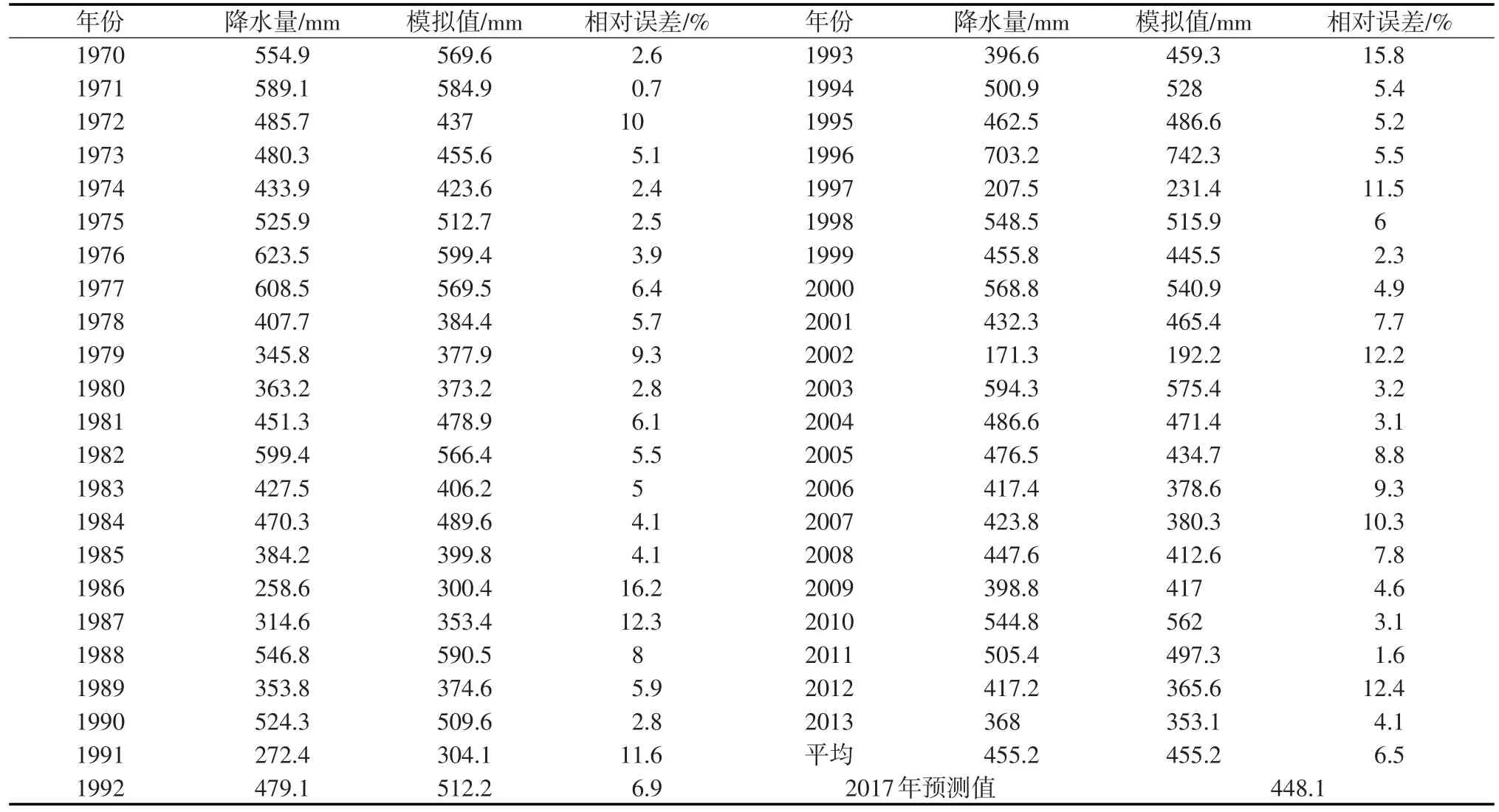
表3 合河站控制区域1970—2013年6—9月降水量与模拟值统计

表42017 年漳卫南运河主要产汇流区降雨量预测
4 结语
研究表明,利用周期均值叠加法对产汇流区控制范围内雨量站历年降水量进行模拟对比,平均相对误差较小,存在周期性变化,可以根据分析出来的周期进行外推,然后叠加起来进行降水量预报,方法可行,精度较高。
TV121+.7
A
1004-7328(2017)03-0047-03
10.3969/j.issn.1004-7328.2017.03.015
2017—04—25
戴永翔(1972—),男,高级工程师,主要从事水资源管理、工程建设管理工作。
