基于多特征的藏文微博情感倾向性分析
2017-07-18于洪志加羊吉
江 涛,袁 斌,于洪志,加羊吉
(西北民族大学 中国民族语言文字信息技术重点实验室,甘肃 兰州 730030)
基于多特征的藏文微博情感倾向性分析
江 涛,袁 斌,于洪志,加羊吉
(西北民族大学 中国民族语言文字信息技术重点实验室,甘肃 兰州 730030)
中英文微博大都以单一语种来表述,而将近80%的藏文微博都是以藏汉混合文本形式呈现,若只针对藏文内容或中文内容进行情感倾向性分析会造成情感信息丢失,无法达到较好效果。根据藏文微博的表述特点,该文提出了基于多特征的情感倾向性分析算法,算法使用情感词、词性序列、句式信息和表情符号作为特征,并针对藏文微博常出现中文表述的情况,将中文的情感信息也作为特征进行情感计算,利用双语情感特征有效提高了情感倾向性分析的效果。实验显示,该方法对纯藏文表述的微博情感倾向性分析正确率可达到79.8%,针对藏汉双语表述的微博在加入中文情感词、中文标点符号等特征后,正确率能够达到82.8%。
藏文微博;混合文本;情感倾向;情感词;词性序列
1 引言
微博作为一种通过关注机制分享简短实时信息的广播式社交网络平台,已吸引了海量的用户使用,发布和查看微博已成为人们每天必做之事[1]。用户发布微博通常是为了表达自己的心情或看法,如对网购产品的看法,对时事发表评论等,因此微博中蕴含着丰富的情感信息。对微博的情感倾向性研究有助于商家及时掌握产品的反馈信息,也有利于舆情信息的收集与分析。

藏文的情感知识库建设相对滞后,在藏文词法和句法分析上的准确度与中文也存在较大差距,将中文微博情感分析的方法直接应用到藏文微博分析中无法取得较好效果。本文在藏文情感词典缺乏的情况下,采用人工标注加点间互信息计算的方法从现有语料中构建藏文情感词典,利用藏文格语法分析提取藏文微博中的词性序列和句式作为情感特征,并根据藏文微博常出现藏汉混排的特点,将中文文本的情感特征也作为情感倾向性的判断依据,大幅提高了藏文微博倾向性分析的准确率。
2 相关工作
由于倾向性分析是文本情感分析的组成部分,故TREC评测、NTCIR评测以及COAE评测均设置了相应的评测项目,而随着微博应用的快速发展,面向微博的情感倾向性分析已成为热门研究课题。目前微博情感倾向性分析方法主要分为两类: 基于情感知识的方法和基于特征分类的方法。
2.1 基于情感知识的方法
基于情感知识的方法主要通过现有的情感知识(情感词典、极性词典等)及语义规则来判定文本的情感倾向性,该方法需要建设情感知识库,使用情感词典统计文本的正向情感词和负向情感词个数,根据其差值判断情感倾向性。文献[2]根据中文微博的特点,提出了基于层次结构的多策略情感分析框架,对微博的属性,如链接、表情符号、情感词典等进行了特征选择,采用基于表情符号结合情感词典的方法进行情感分类。文献[3]以HowNet 的情感词典为基础构建微博情感词典,在对文本进行分句、分词、标注后,构建自动机来计算短文本情感倾向性。文献[4]在传统情感词典的基础上,加入表情符号词典和网络新词,构建专门的微博词典,同时对微博进行修辞分析和句式分析以提升倾向性分析的效果。文献[5]基于Apriori算法对金融文本进行属性抽取,构建金融情感词典和语义规则识别情感单元及强度,进行文本的情感倾向性计算。文献[6]使用自建的藏文词典,采用TF-IDF统计的方式计算微博的情感倾向,并在小规模语料中进行了测试,分类准确率可达65%。
基于情感知识的方法简单直观,对于结构简单的句子能够取得较好的分类效果,但在实际应用中存在较大的局限性。首先情感词典容易受到建设成本和规模的限制[7],其次词语的情感极性会随时间和语境的变化而发生改变,仅凭情感知识无法准确判定词语的情感极性。
2.2 基于特征分类的方法
基于特征分类的方法主要是选取文本中的情感特征,利用机器学习算法在已标注情感信息的数据上训练分类模型,使用该模型预测文本的情感倾向性。机器学习模型包括支持向量机(support vector machine,SVM)、朴素贝叶斯(naïve bayes,NB)和最大熵(maximum entropy,ME)等。文献[8]首次将机器学习的方法应用到文本情感分类中,从文本中抽取出unigram、词性、词的位置特征等特征,在SVM、NB、ME上分别进行实验,得出将unigram作为特征并使用SVM模型效果最好。文献[9]基于远距离监督的机器学习算法实现了Twitter信息的情感分类,利用一元语法、二元语法及两种语法模型相结合的方式实现Twitter信息特征的抽取,该方法对特定领域的倾向性分析效果较为明显。文献[10-12]将Twitter上的标签、表情符号和产品评价等信息作为特征,分析其对微博情感分析的影响,采用机器学习方法实现了Twitter的情感分类。文献[13]使用三种机器学习算法、三种特征选择算法及三种特征项权重计算方法对微博进行了情感分类的实证研究,实验证明TF-IDF作为特征权重,采用SVM和IG方法对微博的情感分类效果最好。文献[14]提出一种基于SVM和CRF多特征组合的微博情感分析方法,使用词性、情感词、否定词、程度副词和特殊符号等多文本特征进行情感分析。文献[15] 针对微博文本特征及微博间转发、评论关系特征,构建情感分析用词典、网络用语词典及表情符号库,实现了基于短语路径的微博话题情感倾向性判定算法。基于特征分类的机器学习方法是当前倾向性判别的主流方法,情感倾向性分析结果优于基于情感知识的方法,但该方法需要大规模标注语料用于模型训练。
目前关于微博的情感分析研究主要集中在中英文微博方面,面向藏文微博的情感分析研究还处于起步阶段,藏文的情感知识库建设相对滞后,情感词典的规模较小,如果采用基于情感知识的方法进行情感分析,会出现情感词遗漏并影响情感分析的结果,本文根据藏文语法特性和藏文微博多以藏汉双语形式表述的特点,在现有情感分类算法基础上,提出基于多特征分类的藏文微博情感倾向性分析方法。
3 藏文微博情感特征
3.1 微博符号特征
微博文本中的表情符号能够较为简洁、直观地表达情感和态度,能够反映作者的情感倾向。如表示“[鼓掌]”,表达作者对某事物的强烈赞同;表示 “[棒]”,表达赞美之意;表示“[咒骂]”,表达作者对某事物的深恶痛绝,表示“[抓狂]”,表达非常愤怒而又无处发泄的情感,体现作者的负面情绪。目前以藏文发布的微博主要来自新浪微博和腾讯微博,本文以新浪和腾讯微博平台自带的表情库为基础构建了表情符号词典,依据情感倾向类别和程度将表情符号分为正面强烈情感、正面普通情感、负面强烈情感和负面普通情感,并给“强烈”和“普通”两种程度的表情赋予相应情感值。
3.2 藏汉情感词典
情感词是表达人们内心情绪的词语,能够较好表征文本的情感倾向,利用情感词和情感极性可以提升情感倾向的判定效果。鉴于藏文微博中大量出现藏汉混排的现象,我们分别建立了藏文情感词词典和中文情感词典。目前藏文还没有公开的情感词典,本文采用人工标注和自动扩展的方式从大量藏文微博语料中提取情感词。首先人工挑选感情色彩强烈的词语作为基准词语,然后从微博文本中自动抽取形容词、动词和名词并将其作为情感词的候选项,运用基于扩展的点间互信息(so-PMI)的方法计算候选词与基准词的相似度,从而判断候选词的情感倾向,将情感倾向较强的词语一并收录到词典中[16]。中文情感词词典是在HowNet和NTUSD的基础上建立起来的,HowNet发布的情感分析用词语集里中文词语约8 942个,NTUSD是台湾大学总结整理的中文情感词典,包含正向情感词2 812个,负向情感词8 276个。
3.3 词性序列特征

3.4 句式特征
微博文本句式多样,随意性较强,主要句式有感叹句、反问句、疑问句、陈述句,句式不同所反映的情感程度也有所不同。感叹句是抒发强烈情感的句式,情感表达程度最强。反问句是在强调某种肯定或否定的表述,是陈述句的强调性的表现,情感程度略低于感叹句。疑问句表达的是一种不甚了解但比较关心的一种态度,情感表达程度略高于陈述句。另外,微博用户往往会以连续的标点符号或拟音词来表达其强烈的情感,以此来表述比句子本身更强烈的情感倾向。对于此类连续标点和拟音词,我们分析整理连续出现两次以上的相同符号,并根据各句式所能表达情感的特点,结合连续标点符号和句式信息赋予不同句式相应的情感系数。
4 情感分类器
藏文微博情感倾向性分析处理的对象为纯藏文微博和藏汉混排微博两类,对于纯藏文微博,本文选取情感词、表情符号、否定词、程度副词、词性序列作为情感特征。针对藏汉混排微博,首先提取微博表情符号和藏汉两种语言的情感词,其次对藏文部分进行句子成分分析,判断是否存在成分缺失或代词指代情况,若存在缺失或指代,使用中文部分替换并协同提取混排文本的词序特征。为选出更能表达情感倾向的特征,以及解决情感词歧义问题,本文使用期望交叉熵来选择情感特征,情感倾向性判别采用支持向量机作为情感分类器。
4.1 语料预处理
(1) 过滤。去除URL链接、用户名(如@YYY、@用户的ID)、话题(新浪微博中的话题是用#XXX#格式来表示的)。
(2) 语种判断。藏文微博常涉及藏文和中文两种语言的文本表述,因此需要进行语种判断和文本提取。本文利用藏文和中文字符编码,并结合藏文高频字词实现藏汉语种判别和提取。
(3) 分词及词性标注。藏文文本分词及词性标注采用西北民族大学祁坤钰教授开发的基于HMM的藏文词性自动标注软件实现,中文文本使用中国科学院计算技术研究所的ICTCLAS进行分词和词性标注。分词过程中加入用户词典,词典主要由微博流行词语、表情符号词汇组成。
4.2 期望交叉熵
期望交叉熵(expectation cross entropy)又称为相对熵(relative entropy),是一种基于信息论的参数估计的方法。其原始含义为: 当不知道X的真实分布h(x)时,假设X服从的分布为g(x),然后计算g(x)与h(x)的距离即为交叉熵[18]。g(x)与h(x)之间的距离也称为KL距离,是Kullback-Leibler差异(Kullback-Leiblerdivergence)的简称,如式(1)所示。
期望交叉熵方法的原理与信息增益方法相同,唯一不同的是期望交叉熵不考虑特征未出现的情况。期望交叉熵反映文本类别的概率分布和在出现了某个特征项的条件下, 文本类别的概率分布之间的距离,特征项的期望交叉熵值越大,对文本类别分布的影响也越大。
4.3 支持向量机分类
支持向量机是Vapnik和其领导的贝尔实验室小组在1995年提出的一种基于统计学习理论的新型的通用学习方法,它是在统计学习理论的VC理论和结构风险最小化原理的基础上发展起来的[19]。SVM分类方法是一种具有很好泛化能力的预测工具,已广泛应用于文本分类、文字识别、图像处理等领域。在微博情感分析领域,SVM被证明具有最好的分类效果,与其他机器学习方法相比具有更好的鲁棒性[13-14]。
支持向量机是有指导的机器学习算法,根据情感倾向性分析模型训练的需要,本文将藏文微博语料标注为褒义、贬义和中性三种情感类别,使用台湾大学林智仁(Chih-JenLin)教授开发的支持向量机算法库Libsvm*http://www.csie.ntu.edu.tw/~cjlin/libsvm/index.html进行情感倾向性分析模型的训练与预测。
5 实验结果与分析
5.1 实验语料
目前还没有公开的藏文微博语料可用于实验评测,我们通过微博接口抓取和人工标注的方式自建了藏文微博情感倾向语料库,语料均来自新浪微博,去掉重复和纯链接微博,共选出20 000条微博作为实验语料。藏文微博语料库分为三部分: 第一部分微博内容以纯藏文内容表述;第二部微博内容以中文表述为主,含有少量的藏文;第三部分微博内容为藏汉双语混排文本,双语内容量较为均衡,此部分语料所占比例最大。藏文微博语料类型如表1所示。
5.2 评价方法
本文采用COAE2014提供的评价方法进行情感倾向性分析算法评价,以准确率P(precision)、召回率R(recall)、F值(F-measure)作为评价指标,即
其中,A表示情感分类器分类正确的微博个数;B表示情感分类器分类错误的微博个数;C表示没被分类和分类错误的微博个数;F是对准确率和召回率的一个平衡均值评估。
5.3 实验分析
本文分别设计纯藏文微博倾向性分析对比、藏汉双语混排微博双语和单语特征对比,以及藏汉双语混排微博特征选择方法对比三组实验,从而确定本文所提出方法的优势和不足。
5.3.1 纯藏文微博倾向性分析对比实验
本实验提取藏文微博的情感符号、藏文情感词、藏文词性和藏文词性序列作为特征,使用TF-IDF和期望交叉熵进行特征表示和选择,利用SVM算法训练情感倾向性分类模型。藏文微博情感分析的研究成果非常少,为验证本文方法的有效性,使用文献[6]提出的基于情感词典的藏文微博情感分析方法和本文方法进行比较,同时选取朴素贝叶斯(NB)分类模型与本文的SVM分类模型进行实验对比。三种方法的实验结果见表2。
从表2中可以看出,与基于情感词典的纯藏文微博情感分析方法相比,本文提出融合多特征的倾向性分析方法在准确率和召回率上都有很大提升。基于情感词典的方法没有考虑微博中出现的表情符号和句子语法成分等特征,其结果依赖于正负情感词的个数,导致其分析结果的准确率和召回率都不高。本文方法在藏文情感词典的基础上,充分考虑了微博中出现的各种情感信息,如表情符号、藏文的否定词、程度副词、词性序列信息等,倾向性分析效果要优于基于情感词典的方法。与朴素贝叶斯的情感分类方法相比,本文采用的SVM情感分类方法具有更好的鲁棒性。因此在选择相同情感特征的前提下,SVM情感分类方法具有更高的准确率。

表2 纯藏文微博情感分析实验结果
5.3.2 藏汉双语混排微博双语与单语特征对比实验
在对藏汉双语混排微博进行情感倾向性分析时,一般做法是抽取单语特征进行情感计算,本实验在提取情感符号、藏文情感词、藏文词性序列特征的基础上,增加了中文情感词特征和中文句式标点符号特征。随机抽取6 000篇藏汉双语混排微博作为实验语料进行模型的训练和测试,该微博语料主要分为“藏文评论中文叙述”“藏文叙述中文评论”“汉藏混合评论叙述”三种类型。双语特征与单语特征情感分析实验结果详见表3。

表3 双语特征和单语特征情感分析实验结果

5.3.3 藏汉双语混排微博特征选择方法对比实验
文献[13]对信息增益、DF和卡方三种特征方法做了比较,并证明信息增益+TF-IDF+SVM对微博的情感分类效果最好。本文选取6 000条藏汉双语混排微博语料分别采用期望交叉熵+TF-IDF、 信息增益+TF-IDF 和互信息+TF-IDF的方法进行实验对比,实验结果见表4。从实验结果可看出,本文所采用方法对藏汉双语混排微博语料的分类效果要优于其他两种。原因在于藏汉双语混排微博文本是两种语言的混合表述,词语出现的频率参差不齐,信息增益的方法对极少出现的词很敏感,互信息未考虑特征出现频率对类别的影响程度,而期望交叉熵不考虑特征未出现的情况,降低了非频繁词的影响,因此情感分类结果好于信息增益和互信息。
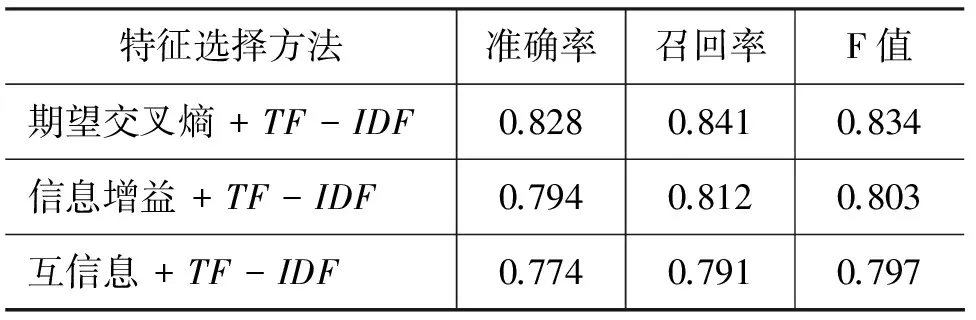
表4 藏汉双语混排微博特征选择方法对比实验结果
6 结束语
微博作为主流的信息传播工具,具有强大的社会影响力,对藏文微博进行情感倾向性分析研究有利于藏文舆情分析技术的发展。本文根据藏文微博的特点提出了多特征融合藏文微博情感倾向性分析方法,并针对藏文微博普遍存在藏汉文本混合的情况,将中文情感词和中文句式特征一并作为情感分析的依据,实验表明该方法有效地提高了藏文微博倾向性分析的准确率和召回率。藏文微博倾向性分析研究刚刚起步,由于情感知识库规模及藏文词法分析准确率的限制,对纯藏文表述的微博进行情感分析的结果与中文微博的相比存在一定差距。下一步将提高藏文情感知识库的质量及藏文词法句法分析的水平,融合机器学习和语义规则的方法来提升藏文微博倾向性分析的效果。
[1] 文坤梅,徐帅,李瑞轩. 微博及中文微博信息处理研究综述[J].中文信息学报,2012,26(6): 27-37.
[2] 谢丽星, 周明, 孙茂松. 基于层次结构的多策略中文微博情感分析和特征抽取[J]. 中文信息学报, 2012, 26(1): 73-83.
[3] 韩忠明,张玉沙,张慧,等. 有效的中文微博短文本倾向性分类算法[J].计算机应用与软件, 2012,29(10): 89-93.
[4] 刘培玉, 张艳辉, 朱振方,等. 融合表情符号的微博文本倾向性分析[J].山东大学学报(理学版),2014,49(11): 8-13.
[5] 吴江,唐常杰,李太勇,等. 基于语义规则的Web金融文本情感分析[J].计算机应用,2014,34(2): 481-485.
[6] 张俊,李应兴. 基于情感词典的藏文微博情感分析研究[J].硅谷, 2014,24(20): 220-222.
[7] Neviarouskaya A, Prendinger H, Ishizuka M. Sentiful: a lexicon for sentiment analysis[J]. Affective Computing, IEEE Transactions on, 2011,2(1): 22-36.
[8] PANG Bo, LEE L,Vaithyanathan S. Thumbs up? sentiment classification using machine learning techniques [C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing.2002: 79-86.
[9] Alec Go,Richa Bhayani, Huang Lei. Twitter Sentiment Classification using Distant Supervision[R].CS224N Project Report, Stanford: 2009.
[10] Jiang Long, Yu Mo, Zhou Ming, et al. Target-dependent Twitter sentiment classification [C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics. Somerset: ACL, 2011: 151-160.
[11] Davidav D, Tsur O, Rappoport A. Enhanced sentiment learning using Twitter hashtags and smileys [C]//Proceedings of the 23rd International Conference on Computational Linguistics. Bejing, 2010: 241-249.
[12] Kouloumpis E, Wilson T, Moore J. Twitter sentiment analysis: the good the bad and the omg! [C]//Proceedings of ICWSM.AAAI Press,2011,11: 538-541.
[13] 刘志明, 刘鲁. 基于机器学习的中文微博情感分类实证研究[J].计算机工程与应用, 2012, 48(1): 1-4.
[14] 李婷婷, 姬东鸿. 基于SVM和CRF多特征组合的微博情感分析[J/OL].计算机应用研究, 2015.
[15] 刘全超, 黄河燕, 冯冲.基于多特征微博话题情感倾向性判定算法研究[J]. 中文信息学报, 2014,28(4): 123-131.
[16] Alina Andreevskaia, Sabine Bergler. Mining WordNet for a fuzzy sentiment: sentiment tag extraction from WordNet Glosses [C]//Proceedings of the 11th Conference of the European Chapter of the Association for Computational Linguistics.Trento: Association for Computational Linguistics, 2006: 209-216.
[17] 卢伟胜, 郭躬德, 陈黎飞. 基于词性标注序列特征提取的微博情感分类[J]. 计算机应用,2014,34(10): 2869-2873.
[18] Pu Qiang , Yang Guo Wei .Short-text classification based on ICA and LSA [C]//Proceedings of International Symposium on Neural Networks, 2006(ISNN 2): 265-270.
[19] Vapnic V. The nature of statistical learning theory [M]. Springer, 2000.
Multi-featureBasedSentimentAnalysisofTibetanMicroblogs
JIANG Tao, YUAN Bin, YU Hongzhi, JIA Yangji
(Key Lab of Chinese National Linguistic Information Technology, Northwest University for Nationalities, Lanzhou, Gansu 730030, China)
While most Chinese or English micro-blogs are in just one single language, nearly 80% Tibetan Micro-blogs are mixed text of Tibetan and Chinese languages. If emotion orientation analysis is only targeted at Tibetan or Chinese, this analysis would be partial and fail to achieve its goal. According to the expression features of Tibetan micro-blogs, this paper puts forward the algorithm of multi-feature sentiment analysis, upon such features as emotional words, the sequence of part of speech, sentence information and emoticon signs. Dealing with Tibetan micro-blogs, this algorithm takes into consideration the emotional information of Chinese language and has improved the effect of sentiment analysis with the help bilingual information. The experimental results indicate that the sentiment analysis accuracy concerning monolingual Tibetan expression is 79.8%, which is boosted up to 82.8% after taking into consideration of the features of Chinese emotional words and Chinese punctuations.
Tibetan micro-blog; mixed text; sentiment orientation; emotional words; part of speech sequence

江涛(1983—),博士,讲师,主要研究领域为自然语言处理。

袁斌(1989—),硕士,工程师,主要研究领域为数据挖掘。

于洪志(1947—),学士,教授,主要研究领域为自然语言处理。
1003-0077(2017)03-0163-07
2015-06-05定稿日期: 2016-10-25
国家自然基金(61262054);西北民族大学中央专项资金资助研究生项目(Yxm2014001);国家科技支撑计划项目(2014BAK10B03);甘肃省科技重大专项项目(1203FKDA033)
TP391
:A
