基于领域的影响力最大化与病毒营销
2017-07-18刘泉,张铭
刘 泉,张 铭
(北京大学 信息科学与技术学院,北京 100871)
基于领域的影响力最大化与病毒营销
刘 泉,张 铭
(北京大学 信息科学与技术学院,北京 100871)
近年来随着新浪微博、人人网等社交网络新媒体的涌现,线上影响力传播得到了越来越多企业和研究机构的关注。如何在给定资源的约束下实现最大的传播范围(影响力最大化问题),对病毒营销等市场战略的有效开展有着重要意义。如果能充分利用社交网络上的异质性信息来更准确地定位用户所属的领域,进而基于领域实现影响力最大化,将对从整体角度出发的传统研究和片面的结构或内容角度的研究形成很好的补充。该文同时利用新浪微博上用户之间的社交关系和微博内容的话题两个维度的信息将用户划分为不同的领域;进而提出了一种基于贪心和动态规划混合的改良算法实现基于领域的影响力最大化。实验表明该文的领域影响力模型较好优化了传统影响力最大化的时间消耗,同时拥有相近的精度。
影响力最大化;领域发现;领域影响力
1 引言
随着互联网的发展逐渐进入Web2.0时代,越来越多的人们开始在在线社交网络上分享信息、表达情感、进行互动。国外以Facebook、Twitter为代表的社交网络最为活跃。而在中国,新浪微博和人人网则是众多社交网站中的领头羊。从2009年8月开始内测至今,新浪微博已经拥有超过五亿用户,日活跃用户高达6 000多万。社交网络的流行给人们的生活方式和商业模式带来了巨大改变。近年来也吸引了来自学术界和工业界人士的高度关注与探索。
社交网络的分析是一个前沿交叉研究方向,用到了大量来自数据挖掘、机器学习、自然语言处理、信息检索等领域的知识。主要的研究方向有社区发现、推荐系统、信息传播、情感分析等。在这些不同的研究方向中,信息传播,特别是影响力传播对其他相关研究的开展起着基础性的作用。影响力,顾名思义,是指一种为别人所乐于接受的方式,改变他人的思想和行动的能力。表现在社交网络上,则是指用户因为受到其他用户的影响(比如看到对方的微博、评论、转发等)而改变原有认识或情感,或者是对某个新鲜事物从不了解到开始关注。
传统的影响力研究大多集中在心理学等领域,研究人员通过线下实地调研取证来分析影响力的相关特征。近年来随着社交网络的兴起,大量社交数据的积累为影响力的研究开辟了新的途径。同时,整个社交网络的普及也早已引起了商家的关注。如何在社交网络这个新媒体上进行营销和品牌推广,成了当今商界一个重要新兴问题。一些成功的网络营销案例逐渐形成了一个新的专有名词“病毒营销”,即通过用户的口碑宣传网络,让信息像病毒一样传播和扩散,利用快速复制的方式传向数以千计、数以百万计的受众,实现杠杆递增作用。从病毒营销中抽象出来的影响力最大化(influence maximization)问题,最早由Kemple[1]等人提出,是指对于指定k值,寻找k个具有最大影响力范围的节点集。虽然这个问题早已被证明是NP-完全的,但是众多研究机构却并没有放弃各种各样优化寻找过程的算法研究。更多相关工作的探讨将在第二节予以介绍。
影响力最大化问题具有强烈的社会意义,尤其对于企业、商家利用最少营销成本获取尽可能大的目标客户宣传范围具有重要指导意义。举例来说,某公司推出了一款新饮料,为了能最大化地利用社交网络中的口碑效应进行宣传,同时为了控制营销成本预算,公司需要从消费人群中选取一小部分影响力较强的用户,让他们免费试饮或给予他们报酬,使他们愿意在各自的社交圈内分析对这款饮料的感受。此时,如何优化选取这些初始消费者(即种子用户)就显得至关重要。
传统的影响力的研究大多是在整个社交网络上的分析。然而实际生活经验启示人们: 每个人都有各自的圈子和领域,某人在某个领域具有较高的影响力,并不代表他在其他领域也同样具有较高的影响力。比如姚明对篮球对体育很有发言权,他说的话可能会影响到很多粉丝的认知;然而对于计算机编程,他的话可能就不再那么具有说服力。最近的一些研究引入了从话题角度对影响力的分析,虽然一定程度上弥补了之前整体视角的漏洞,却也未能对社交网络的结构属性给予足够的关注。
同样对于影响力最大化的研究主要也集中在全局网络下如何优化Kemple[1]等人最初提出的贪心算法。近年来偶尔有文章致力于利用社区发现来在子网络下最大化影响力,虽然简化了问题规模但未对社交网络的内容维度进行充分利用;而另外一些基于话题的研究则只关注内容维度忽略了潜在的社交关系信息。如果能够同时利用好社交网络上的结构和内容维度的信息,或许能够为人们求解影响力最大化问题提供更好的精度和速度。
为了解决上述问题,本文将同时利用社交网络用户间相互关注的结构维度信息和相似主题的内容维度信息来进行领域划分。模型首先对微博用户的博文内容进行预处理,并利用Twitter-LDA主题模型[12]无监督地训练出不同话题,再结合结构维度的信息进行聚类;之后在各个子领域利用经典的linear threshold模型来最大化各自领域的影响力,并与直接在全集上最大化影响力的结果进行比较。数据集源自中国流行的社交网站新浪微博(10多万有效用户及这些用户的超过1千万的微博内容)。实验效果显示领域影响力最大化模型相比传统影响力模型具有极低的时间代价,并具有很高的精度。
2 相关工作
Kempe[1]等人首先提出两种随机的影响力传播模型,即independent cascade模型和linear threshold模型,并证明了两种模型下的影响力最大化问题是一个NP完全的难题,他们提出的贪心算法为后来诸多的研究提供了基础的框架和参照。然而贪心算法在大规模数据量面前却问题重重,自此以后很多相关研究都在试图解决这个问题。Leskovec[2]等人利用子模性,提出了一种基于lazy-forward改进的CELF算法来优化种子选取的过程,相较之前的贪心算法有了近700倍的速度提升。Chen[3]等人提出了最大影响力路径来有效限制影响力的计算到局部网络,并在IC和LT模型下分别验证了自己模型的效果。更多相关工作集中在优化影响力函数和延展性上,或者结合整体网络的新特性,比如潜在的传播网络等[4-6]。
Yu[7]等人在2010年首次提出引入社区发现来优化影响力最大化的种子选取过程: 首先将整个社交网络划分成不同的子社区,然后利用一种动态规划算法基于前k-1步选取的种子集来动态计算第k步应当选取种子所在的社区。Barbieri[8]等人在2013年亦首次提出从话题的角度分析影响力最大化,并将传统的Independent cascade模型和Linear threshold模型扩展到不同的话题下(TIC, TLT)。之后紧随的[9-10]两篇基于话题影响力最大化文献分别从引入必要的预处理和在线实时计算的角度进行优化。
近期以来的相关工作,或从社区发现,或从话题分类,对之前的影响力最大化问题有了进一步的研究。然而,它们都没有充分利用社交网络潜在的丰富信息。前者只利用了网络的社区属性,而忽略了内容属性,比如话题;而后者只利用了内容属性,忽略了用户相互交流的社交属性。社交网络本质上是一个不同纬度网络组成的异质性网络(heterogeneous networks),如果能够充分利用其潜在的这些不同纬度的信息特征,将对研究人们影响力提供更深入的视角。本文作者发表的论文[11]正是从异质性网络切入分析不同领域的影响力的特征,本文则从基于领域的影响力最大化角度来进行研究。
3 模型
3.1 异质性网络
在新浪微博等社交网络中,用户可以通过不同的媒介形式进行交互。例如,一个用户可以关注另一个用户,或者转发他的微博。为了便于后文的分析,这里将介绍一些必要的定义与标记符。

本文的异质性网络同时利用了结构信息和内容信息,即判别给定的两个用户是否应当划分到同一个领域中,主要可以根据以下两点判别。
(1) 是否具有相似的社交圈;
(2) 是否在博文中讨论相似的话题。
3.2 话题维网络
隐含狄利克雷分布(latent dirichlet allocation,LDA),是一种主题模型,它可以将文档集中每篇文档的主题按照概率分布的形式给出。同时它是一种无监督学习算法,在训练时不需要手工标注的训练集,需要的仅仅是文档集以及指定主题的数量k。此外LDA还可以对每一个主题均可找出一些词语来描述它。自Blei等人于2003年提出后在文本挖掘等领域产生了深远的影响。
然而社交网络上大量的碎片信息使得LDA英雄无用武之地。就新浪微博而言,用户的每条微博不超过140字,短小、简练、口语化是微博内容的显著特征。为了能够从短小的微博内容中发现主题,北大网络所博士研究生赵鑫等人[12]提出的Twitter-LDA主题模型,对社交网络上短小、高频的文本更加友好。
为了构建本文的话题维网络,爬取了十万微博用户每人最近的100条微博,共计1 000余万条微博内容,经过分词等预处理,输入至Twitter-LDA模型中通过无监督式学习发现共同的话题,并指定话题个数为20(经验值);根据输出的每个单词在给定话题上的概率分布值,可以遍历每个用户的每条微博中的词语,为用户产生一个20维的话题向量,即在20个话题中每个话题的总概率值,由此形成话题维网络X2。具体的计算过程如图1伪代码所示。

图1 话题维向量网络计算伪代码
3.3 划分领域
为了计算领域影响力最大化,首先需要从异质性社交网络X1、X2中发现不同的领域。众多聚类算法中,有关实验表明谱聚类在社交网络社区发现中具有较稳定和高效的表现。谱聚类算法源于图形分割问题,主要工具是图像的Laplacian矩阵。
令W表示每维社交网络X1、X2相似度矩阵的加权邻接矩阵,D表示相应的度数矩阵,I表示原矩阵,Laplacian矩阵L被定义为式(1)。
本文使用normalizedcut并计算L矩阵的前k个特征向量,从而将维度由n维降至k维。社交关系维X1,话题维X2分别产生一个Laplacian矩阵L1, L2。进一步,使用Lei等人[13]提出的utility integration方法将这三维网络加和,平均效用矩阵可由式(2)获得。
其中对谱聚类算法而言,效用矩阵M等价于Laplacian矩阵,即
由式(1)~式(3)可以推导出平均Laplacian矩阵

3.4 领域影响力最大化
如前文所述,病毒营销已经成为信息时代常见的营销手段之一。它的低成本和高覆盖率已经得到越来越多人的关注。然而成本再低终归是有成本的,比如一家食品公司为了推广某项新产品准备先给一部分客户免费品尝或体验,如何优化选取这批初始用户,使得总成本落在预算以内同时尽可能最大化人们口耳相传的覆盖面,就是典型的影响力最大化问题。为了便于后文讨论,首先来形式化地定义影响力最大化问题。
给定社交网络G和种子数目k,对于给定的一种影响力传播模型,选取k个节点构成的初始活跃节点集S使得σ(S)最大。其中σ()是给定的影响力函数。
Kempe等人[1]最早提出了两种基础的影响力传播模型: 独立级联(independent cascade)和线性阈值(linear threshold)。为便于与同类工作比较,本文采用线性阈值模型,其核心特点在于对每个节点用一个阈值来表示该用户被影响的难易程度。当它的邻居节点累计给这个节点的影响概率之后超过阈值后,该节点即被激活(认为被影响到)。其传播过程如下所述。

在讨论全局影响力最大化之前,首先来看在一个领域内的影响力最大化。其实这个问题跟之前众多研究关注的全局网络的影响力最大化是同一个问题。可以采用其中任意一个现成的算法。为了便于后续讨论同时有效地说明问题,本文即采用最基础的贪心算法来寻找待求的K个种子。贪心近似算法(greedy approximation algorithm)[1]借用子模函数的性质,重复k次每次选取使得函数σ(S)增量最大的节点,并将它放入解集中。具体的伪代码如图2所示。

图2 单个领域内影响力最大化的贪心算法
Yu[7]等人在基于社区发现的影响力最大化研究中提出了一种动态规划算法来计算第i步(0 (1)n=k。 领域个数与种子个数相等,则直接在各个领域寻找影响力函数σ(S)增量最大的节点。 (2)n>k 领域个数比种子个数多,则直接在规模最大的前k个领域寻找影响力函数σ(S)增量最大的节点。 (3)n 领域个数比种子个数少,则首先在各个领域寻找影响力函数σ(S)增量最大的节点。剩余的k-n个节点套用文献[7]中的动态规划算法求解。递推如式(5)所示。 实验表明,这种贪心选取领域的算法结合基于领域的影响力最大化计算模型极大地降低了运算时间,同时与直接在全局网络上求解结果的差异性很小。具体实验结果将在4.4节进行讨论。 4.1 数据集 本实验基于中国流行的社交网站——新浪微博(http://weibo.com)。首先从不同行业人工选取了大约50个中层用户(约几千粉丝数),并爬取他们的1层关注列表和粉丝列表,去重后得到185 504个用户,并爬取每个用户最近的100条微博。为了避免来自僵尸用户和极端不活跃用户带来的噪声,本文对数据集进行了五层过滤,最终得到108 204个用户构成的稳定社区和超过一千万条的微博信息。这五层过滤是: (1) 个人信息页面当时无法获取的用户; (2) 拥有少于10个关注对象的用户; (3) 拥有少于30个粉丝的用户; (4) 拥有少于5条微博的用户; (5) 在截取的社区中拥有过少联系人的用户(即孤立点)。 4.2 话题维网络 经过Twitter-LDA对微博内容的处理,得到了20个话题的常见代表词和每个词语在每个话题上的概率分布值。图3是节选的一部分话题词表。容易看到话题1主要围绕做饭,话题2主要关于艺术,话题3关于软件,话题4关于经济。 图3 话题维网络结果 4.3 划分领域 整合社交关系维度和话题维的网络后,本文对该异质性网络分别按5类、10类、15类进行聚类。比较后采用10类(即10个领域)的结果进行后续分析。图4为10类聚类结果中每类用户总数占总体的百分比即10领域占比图。 图4 10领域占比图 4.4 影响力最大化 本文分别选取不同的种子用户集合大小k,来测量不同模型下的影响力传播范围和时间消耗。第一个模型是经典的全网络贪心算法(简称贪心模型)[1],第二个是Yu[7]等人提出的基于社区发现的影响力最大化模型(简称社会发现模型),最后一个就是本文的领域影响力最大化模型(简称领域模型)。 图5展示了三种模型在不同初始集合大小k取值情况下的时间消耗,经典的贪心模型由于其指数时间复杂度的特点,从k=10的数据点起已超过坐标轴的范围,相比之下,社区发现模型和领域模型具有较好的时间表现,除k=20这组实验外,领域模型均小范围领先社区发现模型的时间代价。 图5 三种模型的时间消耗 图6 三种模型的覆盖节点数 图6展示了LT模型下种子集最终覆盖的用户群体大小,经典的贪心模型以极高的时间复杂度为代价换来了更大的覆盖量,不过社区发现模型与领域模型最终覆盖的用户与之相差并不大。领域模型以更低的时间代价获取了与社区发现模型基本一致的覆盖范围。 影响力研究一直是社会计算领域的一项基础性研究,除了影响力本身的特征吸引了大量关注外,对信息传播和病毒营销有重要参考意义的影响力最大化研究也同样备受关注。然而传统的IM问题研究工作大多局限在对Kempe等人[1]最早提出的贪心算法的改良,从更少的时间代价换取更高的精度。近年来也有个别研究者另辟蹊径,有的从结构角度通过社交关系的社区发现来在子社区最大化影响力传播,另一个思路则是从内容维度分析话题影响力的传播。虽然都有显著的效果,但也缺乏对社交网络中丰富的结构和内容维度的异质性信息的充分利用。 本文提出一种基于领域的影响力最大化模型,首先对社交网络中的结构信息和内容信息进行预处理: 前者转换成一个由“是否关注对方”构成的0/1矩阵;后者则首先对用户微博内容进行分词和Twitter-LDA主题模型处理,从而得到每个用户在无监督学习出的20个话题上的向量维度值。随后使用效用整合方法将两个矩阵结合,并调用谱聚类算法将用户划分到不同的领域。最后,利用一种贪心-动态规划混合的算法来选取IM问题中的第k个初始节点应当选取的领域并确定实际的对象。 基于新浪微博10万多用户社交关系与微博内容构成的新浪微博数据集的实验效果表明,领域影响力最大化模型相比传统影响力模型具有极低的时间代价,并具有很高的精度。 虽然划分领域的做法符合人们社会生活中和网上社交中的行为特点,然而另一方面由于人们兴趣和专业知识的多样性,一个用户归属于一个领域的实验假设难免有违实际。如何将本文的领域影响力最大化模型推广到有重叠领域的情况将会是一个非常有趣的研究方向。 [1] D Kempe, J Kleinberg, E Tardos. Maximizing the spread of influence through a social network[C]//Proceedings of the 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York: ACM, 2003: 137-146 . [2] J Leskovec, et al. Cost-effective outbreak detection in networks[C]//Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York: ACM, 2007: 420-429. [3] W Chen, C Wang, Y Wang. Scalable influence maximization for prevalent viral marketing in large-scale social networks[C]//Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York: ACM, 2010: 1029-1038. [4] M Gomez Rodriguez, B Scholkopf. Influence Maximization in Continuous Time Diffusion Networks[C]//Proceedings of the 29th International Conference on Machine Learning, New York: Omnipress , 2012. [5] Y Li, W Chen, Y Wang, Z Zhang. Influence Diffusion Dynamics and Influence Maximization in Social Networks with Friend and Foe Relationships[C]//Proceedings of the 6th ACM International Conference on Web Search and Data Mining, New York: ACM,2013. [6] W Chen, Y Wang, S Yang. Efficient influence maximization in social networks[C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York: ACM,2009: 199-208. [7] Y Wang, G Cong, G Song, K Xie. Community-based Greedy Algorithm for Mining Top-K Influential Nodes in Mobile Social Networks.[C]//Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York: ACM, 2010: 1039-1048. [8] N Barbieri, F Bonchi, G Manco. Topic-aware social influence propagation models[J]. Knowledge and information systems,2013,37(3):555-584. [9] C Aslay, N Barbieri, F Bonchi, R Baeza-Yates. Online topic-aware influence maximization queries[C]//Proceedings of the 17th International Conference on Extending Database Technology,2014. [10] W Chen, T Lin, C Yang. Efficient Topic-aware Influence Maximization Using Preprocessing[J].The Computing Research Repository, volume abs/1403.0057, 2014 . [11] Q Liu, C Wang, M Zhang. Measuring Domain Influence in Heterogeneous Networks[C]//Proceedings of the of the 7th ACM International Conference on Web Search and Data Mining works, New York: ACM,2014. [12] W Zhao, J Jiang, J Weng, et al. Comparing twitter and traditional media using topic models[C]//Proceedings of the 32nd European Conference on IR Research, Heidelberg: Springerpages,2011 , 338-349. [13] L Tang, X Wang, H Liu. Community detection via heterogeneous interaction analysis[J]. Data Mining and Knowledge Discovery, 2012,25(1):1-33. DomainBasedInfluenceMaximizationandViralMarketing LIU Quan, ZHANG Ming (School of EECS,Peking University, Beijing 100871,China) With the evolvement of social media like Sina Weibo and Renren, online influence maximization has attracted more and more attention from both industry and research institutions. It’s very crucial for the healthy development of marketing strategies like viral marketing to maximize the influence scope given the constraints of resources. If we can specify the domain that a user belongs to more accurately with the heterogeneous information from social networks, and further maximize influence spread based on domains, traditional influence research from the general perspective as well as single perspective of structure or content will be hugely benefitted. In this paper we proposed a domain influence maximization model, which first divided users into different domains utilizing users’ social relations and weibo contents, and then maximized domain influence based on a greedy-dp hybrid algorithm. Experiments on Sina Weibo show that our model greatly improved the time cost of traditional models, with little errors. influence maximization; domain discovery; domain influence 刘泉(1992—),学士,主要研究领域为数据挖掘和社交计算。 张铭(1966—),通信作者,教授,博士生导师,主要研究领域为文本挖掘、社会网络分析、大规模在线教育研究等。 1003-0077(2017)03-0118-07 2014-12-27定稿日期: 2015-02-24 国家自然科学基金(61472006,91646202) TP391 : A
4 实验



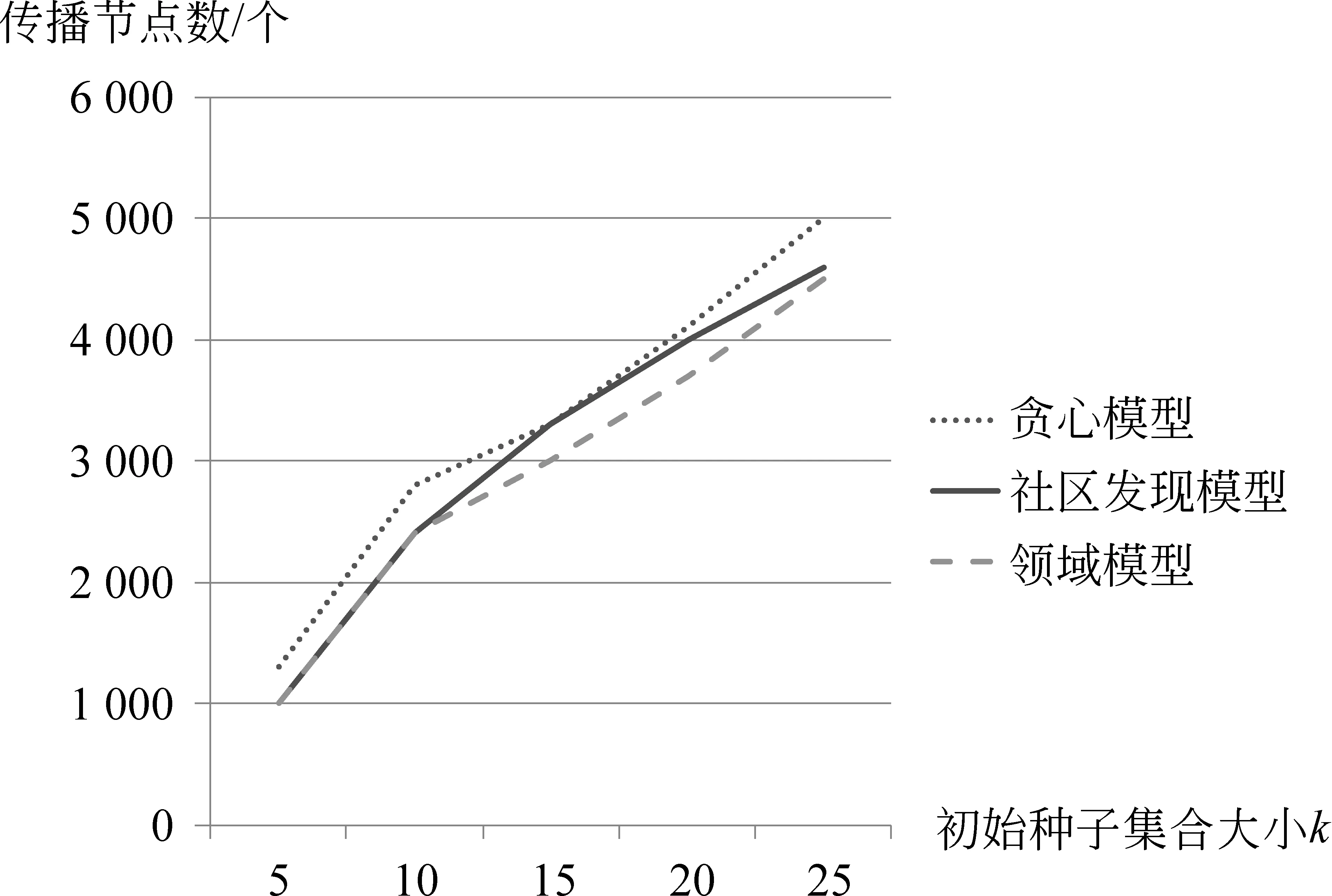
5 结论


