基于词语关系的词向量模型
2017-07-18蒋振超李丽双黄德根
蒋振超,李丽双,黄德根
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
基于词语关系的词向量模型
蒋振超,李丽双,黄德根
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
词向量能够以向量的形式表示词的意义,近来许多自然语言处理应用中已经融入词向量,将其作为额外特征或者直接输入以提升系统性能。然而,目前的词向量训练模型大多基于浅层的文本信息,没有充分挖掘深层的依存关系。词的词义体现在该词与其他词产生的关系中,而词语关系包含关联单位、关系类型和关系方向三个属性,因此,该文提出了一种新的基于神经网络的词向量训练模型,它具有三个顶层,分别对应关系的三个属性,更合理地利用词语关系对词向量进行训练,借助大规模未标记文本,利用依存关系和上下文关系来训练词向量。将训练得到的词向量在类比任务和蛋白质关系抽取任务上进行评价,以验证关系模型的有效性。实验表明,与skip-gram模型和CBOW模型相比,由关系模型训练得到的词向量能够更准确地表达词语的语义信息。
词表示;词嵌入;词向量;神经网络;关系模型
1 引言
目前,机器学习方法已广泛运用于文本挖掘任务当中。然而,传统的机器学习算法,如支持向量机(support vector machine,SVM)、逻辑回归(logistic regression,LR)等,其输入往往是实值类型的向量或矩阵,因此,自然语言处理和文本挖掘中的一个重要的环节,就是将字符串或者符号形式的输入转换为实值类型的向量或矩阵,常见的转换方式如one-hot coding、向量空间模型(vector space model,VSM)[1]等。
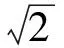
Bengio等借助语言模型的思想[2],使用句子中第t-n+1到第t-1个词作为回归神经网络的输入,第t个词作为回归神经网络的输出,利用语言模型的思想和回归神经网络方向传播算法,对词向量进行学习;Mikolov等[3-4]发布的word2vec工具,提供了skip-gram和continuous bag-of-word(CBOW)两种词向量训练模型,利用某个词的周围词来预测当前词,同时,顶层采用基于词频的hierarchical softmax形式,大大缩短了训练时间。Pennington等结合了矩阵分解和上下文窗口,能利用更多的统计信息,在越大的语料上越具有优势[5]。另外,Tian等人在skip-gram模型基础上,融合概率模型和EM算法解决一词多义的表示问题[6],Qiu等人从词形角度出发,利用神经网络框架联合训练词向量和词形向量[7]。以上方法均为无监督框架,无需借助标记语料便可完成词向量的训练,其出发点均是: 上下文越接近的词,其语义越接近。因此,上下文的局限性是制约词表达质量的重要因素之一。
Collobert和Western提出了一个由查表层、卷积层、hardtanh层、max层组成的神经网络框架来解决自然语言处理中的多种任务[8],同时,该框架能够借助相关任务的标记语料有监督地联合训练出词向量;Socher利用递归自编码器来解决情感分类问题[9],同样,该框架也可以联合训练出词向量。然而,由于以上两种框架与具体任务具有很强的耦合性,例如,Socher的递归自编码器无法运用到关系抽取任务当中,因此,联合学习的方式具有相对较差的普适性。
联合学习具有较强的耦合性,而基于上下文的方法受到了上下文信息的制约,合理地融合丰富的句法信息成为提升词向量性能的关键。在自然语言当中,一句话不仅是一个由词组成的序列,更是一个由依存句法关系连接起来的图状结构,如图1所示。尽管Levy等人引入了依存信息[10],但其思路是用依存标记简单地扩展上下文,而训练模型仍然是skip-gram,因此,该方法并没有以合理的方式将依存信息融合到训练模型当中。

图1 文本“a particular segment of DNA is copied into RNA”经过依存解析后得到的依存图
本文提出了一种新的基于关系的无监督词向量表示模型。该模型能够合理地融合上下文关系和依存关系,克服了联合学习普适性较差的弱点,并且该方法能同时利用上下文信息和深层依存信息,使词向量的分布更加充分地考虑词语在依存结构中的角色。实验结果表明,相比skip-gram和CBOW,关系模型词向量对自然语言处理性能的提升更加显著。
2 基于神经网络的关系模型
2.1 关系的表示
语义的本质在于关系,不与任何其他词产生关系的词不具有任何实际意义。本文将关系看作三元组,包括: (1)关联单位,即某关系关联了哪两个词;(2)关系类型,即某关系为何种关系;(3)关系方向,即哪个词是关系的施加方,哪个词是关系的承受方。另外,不同的关系对词向量训练具有不同程度的影响力,因此我们在三元组的基础上对关系引入权重属性,表示该关系的重要程度,权重可以人工指定或由关系模型自动学习。
关联单位、关系类型和关系方向是关系的基本要素,三者完整地描述了一条关系,缺一不可。如图1所示,当训练词为“is”时,假如不考虑关系类型,“segment”和“copied”对“is”产生的作用将完全一致,这与事实不符。假如不考虑关系的方向,则无法区分“segment”和“is”究竟谁是主语。本文通过建立神经网络框架,使用所有与目标词相关的关系对目标词的词向量进行训练,从而构建基于词语关系的词向量模型。具体框架如图2所示。
为了加快训练速度以适应大规模训练的要求,该框架只保留了输入层和顶层两层: 输入层为目标词(即关联单位)的词向量,词向量最初是随机初始化的维度固定的向量,而后使用大规模的训练数据进行学习;而顶层分为三个部分,分别对应关系类型、关系方向和关联单位。其中关系类型和关系方向部分的训练采用softmax。由于大规模文本中的词汇量极大,因此关联单位2部分的训练采用hierarchical softmax。
2.2 关系模型的数学表达
在skip-gram模型中,当窗口(假设窗口大小为2)滑动到某个词t的时候,skip-gram会使用t对t周围的词w-2、w-1、w+1、w+2进行词向量训练。关系模型则首先找到与词t相关的关系l,然后如图2所示,使用l中的关联单位2、关系方向和关系类型对关联单位1进行训练。表1给出了图1例句中以“t=is”时的所有关系。本文的关系模型中,不同的关系类型具有不同的重要度,例如在图1当中,冠词a、形容词particular和介词of都以NMOD的类型来修饰segment,体现出了segment可作名词的事实;而segment以SUB的方式修饰is,体现出了segment可作主语的事实。由此可见,不同的关系类型对目标词词向量的学习产生不同程度的作用,可以通过人为设置或自动学习的方式获得类型的权重。因此,本文在经典softmax的基础上引入了关系权重来表示关系l的关系类型所对应的权重。

图2 基于神经网络的关系模型框架
在真实数据中,关系类型和关系方向的种类相对较少,数量远小于关联单位的种类,softmax足以胜任, 但语料的巨大词汇量对关联单位的训练带来了极大的负担,因此,顶层关联单位部分选用hierarchical softmax[11]。如图2所示,根据词语的词频构建哈夫曼树,首先利用堆排序算法按照词频构建大顶堆,而后依次取出当前堆中词频最大的两个词作为叶子节点,创建词频大小为两者之和的父节点,并将此父节点加入到堆中,重复该过程直到所有词都被加入到树中。训练过程中,hierarchical softmax并不像softmax那样对整个权重矩阵W做计算和更新,而是只对哈夫曼树中关联单位词到根节点的路径上的所有单位所对应的部分做计算和更新,如图2中虚线部分所示,即为hierarchical softmax对应的权重。

表1 图1中词is涉及的关系的形式化表示
关系模型的三个顶层V、F、D分别对应关联单位、关系类型和关系方向,关系权重α则能令不同类型的关系得到不同程度的对待,这使得关系的重要度能够以细粒度的级别对词向量的学习产生不同程度的作用。因此,相比起skip-gram、CBOW等模型,关系模型能够充分利用关系中的丰富信息,从而获得更高质量的词向量。在训练过程中,依次遍历关系图中的所有节点。当遍历单词t时,t即作为图2中的关联单位2。首先找到所有与t相关的关系集合,遍历集合中的每一条关系l,使用t、关系类型和关系方向对关系l中关联单位1所对应的向量x进行训练。
记V为语料中所有词的集合,其基数为n;L为语料中所有关系的集合;X为词向量矩阵,X∈Rn×d,d为词向量维度,语料中的第t个词的词向量对应为x=Xt;令Pl,t=P(y=l|x),表示第t个词涉及关系l的概率总和,即
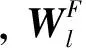
词向量x的更新也包含三个部分,如式(5)所示。
3 实验
目前词向量的验证方法尚无统一标准。一方面, Mikolov提出了用类比(word analogy)任务来验证词向量的质量,成为大多数研究者认可的评价方式,因此,本文将采用该类比任务来评价关系模型。另一方面,由于词向量的终极目的是服务于自然语言处理和文本挖掘领域的相关任务,因此,本文还将词向量融合到蛋白质关系抽取任务(protein-protein interaction extraction, PPIE)中,以该任务来评价关系模型,对关系模型进行更完整的评价。由于联合学习词向量模型往往需要在特定的有监督自然语言处理任务才能学习词向量,具有很强的任务耦合性,因此本文方法不与联合模型做比较。
3.1 类比任务
Word analogy任务用词向量的余弦相似度来衡量词之间的类比,共14类,其中五类为语义类比,比如“king”-“queen”=“man”-“woman”,“China”-“Beijing”=“U.K.”-“London”,九类为句法类比,比如“write”-“writing”=“read”-“reading”。在实验中,以word2vec工具提供的text8语料为训练集,以Mikolov整理的19 544个类比关系为测试集,以精确率的方式衡量词向量质量。
3.2 蛋白质关系抽取任务
蛋白质关系抽取的目标是从生物医学文本当中挖掘出具有交互作用的蛋白质对,可以看作是一个二元分类问题。例如,根据描述“The binding of hTAFII28 and hTAFII30 requires distinct domains of hTAFII18”,算法需要自动识别出hTAFII28和hTAFII30是具有交互关系的蛋白质对。在实验中,以5.8 GB的生物医学文献为训练集,以目前该任务上的五个公共的评测数据集: AIMed[12]、BioInfer[13]、HPRD50[14]、IEPA[15]和LLL[16]为测试集,采用十倍交叉验证计算F值和AUC值的方式衡量词向量的质量。
4 结果与分析
4.1 类比任务
表2给出了Word Analogy任务上skip-gram模型、CBOW模型和关系模型的表现。可以看到,在语义任务上,关系模型具有明显的优势(33.17%),比skip-gram高7.12个百分点;在句法任务上,关系模型达到了23.32%,比skip-gram模型低2.52个百分点。总体考虑,关系模型具有最高的精确率26.41%。可以看出,关系模型在语义表达方面更具有优势,而这一优势得益于关系模型能够充分挖掘依存关系和上下文关系。
值得一提的是,句法任务中的类比大都是动词时态、形容词形式等,例如,“dance之于dancing如同fly之于__?”而在实际应用中常常更关心词的语义信息而非时态、形式,例如,词干特征;另外,从人的角度出发,当面对词语时态和形式存在错误的句子时,我们往往也能明白句子的意思,例如,“He is dance”,这是因为语义信息足以表达句子的含义。因此,尽管关系模型在句法任务上表现略低于skip-gram,关系模型在语义任务上的突出表现更应当受到关注。
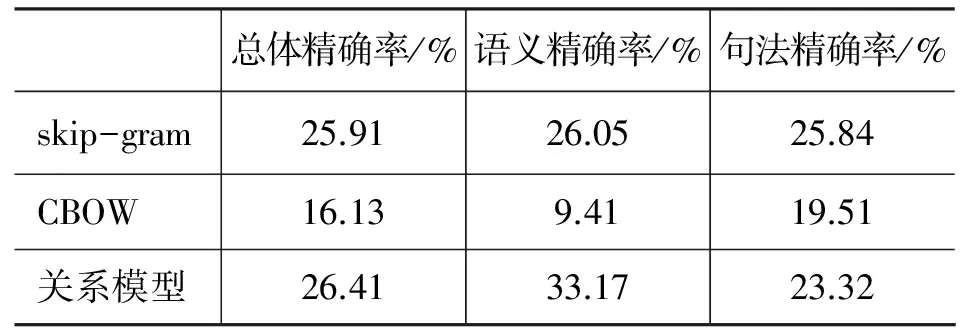
表2 Skip-gram、CBOW和关系模型在类比任务上的比较
4.2 蛋白质关系抽取
本文使用Li等提出的蛋白质关系抽取统一框架进行蛋白质关系抽取[17]。该框架采用的特征包括: 蛋白质名特征、前后词特征、中间词特征和句子特征,通过词向量映射的方式将原始特征向量转换为数字型的输入向量,然后通过四种向量组合方式和向量拼接,将基于词的特征向量转换为实值型的输入向量,最终采用SVM对蛋白质关系实例进行分类。
表3将关系模型与CBOW和skip-gram模型进行了比较。在训练词向量过程中,三者的训练参数均保持一致,例如,使用相同的初始化权重、学习率等。可以看到,在五个语料上,skip-gram模型要优于CBOW模型,而关系模型要优于skip-gram模型。关系模型在AIMed、BioInfer、HPRD50、IEPA和LLL上的F值比skip-gram分别高出了1.4%,0.4%,1.9%,1.5%和0.3%,而AUC值分别高出了0.9%,0.0%,4.9%,2.1%,2.1%。
AIMed、BioInfer、HPRD50、IEPA和LLL这五个语料具有不同的实例个数、正负例比例和标注风格,可以看到,不论在哪个语料上,关系模型的表现总要优于skip-gram和CBOW,而且每组实验均采用十倍交叉验证,因此,该实验结果受过拟合的影响非常小。

表3 Skip-gram、CBOW和关系模型在AIMed、BioInfer、HPRD50、IEPA和LLL语料上的结果
关系模型可以像skip-gram和CBOW一样利用上下文中的词,同时,关系模型更能够利用依存信息,并且合理的考虑了关系的类型和方向,这是skip-gram模型和CBOW模型做不到的。关系模型能够充分利用更丰富的依存信息和上下文信息,相比skip-gram和CBOW模型,由关系模型训练得到的词向量在空间中的分布更加合理,可更准确地刻画词语的语义信息,从而使得蛋白质关系抽取的性能得到进一步的提升。
4.3 关系权重α的影响
(1)α自动学习。
当α自动学习时,如果α取值接近0,会出现权值w和词向量x的更新接近于0的“不学习”的现象;相反,如果α取值很大,会出现“步长过大”的现象而不利于收敛,甚至是梯度趋于无穷大的现象。因此,本文将α初值设置为1,限定其最大值为1.5,最小值为0.5,使模型的优化保持稳定。在α自动学习策略中,α的取值随着梯度下降对模型的优化而不断变化,表4按照训练时间轴对α取值进行了均匀采样,由此得到每一种关系的平均权重。从表4可以看出, 不同关系类型对词向量训练起到了不同程度的作用,最大权重和最小权重之间相差0.34。在人工设置权重时,可参考表4列出的权重进行设置。

表4 词表示训练过程中关系类型的平均权重
(2)α自动学习和固定权重的比较。
表5比较了两种不同的关系权重策略,α自动学习和α恒为1。表5显示,固定α和自动调整α两种策略各有优势: 从AUC的评价角度看,在AIMed(实例数5 834)和BioInfer(实例数9 660)这两个规模相对较大的语料上,后者表现较好,AUC值分别高出了0.7个百分点和0.3个百分点;在HPRD50(实例数443)、IEPA(实例数817)和LLL(实例数330)上,前者在AUC值上分别高出3.9,0.1和2.2个百分点。而从F值的角度来说,在AIMed、HRPRD50、LLL上权重自动调整的策略更具优势。

表5 两种不同关系权重取值策略的比较
综上所述,关系权重自动学习策略对大规模的文本挖掘应用场景具有相对较大的AUC提升效果。在语料较小的情况下,将权重固定为1不失为一种简单高效的选择。
5 结论
本文针对自然语言处理和文本挖掘任务中的词表示问题,提出了一种能够充分利用依存关系和上下文关系,从大规模文本中无监督地学习词向量的方法。不同于skip-gram、CBOW等模型,该方法合理地利用了依存关系和上下文关系,具有一个输入层和一个由三个部分组成的顶层,分别对应关系中的关联单位、关系类型和关系方向。同时,该方法能够自动的学习关系类型的权重,进而利用依存关系和上下文关系对目标词进行训练。传统的词向量模型仅仅考虑了上下文窗口中的单词,而关系模型能够更好地将语义信息融合到词向量当中。
词向量的终极目标是服务于自然语言处理和文本挖掘领域的相关任务,本文分别以类比任务和蛋白质关系抽取任务作为评价集合,较完整的评价了词向量的语义表达能力。实验表明,不论是在语义信息占主导作用的应用场境,还是将词向量当作额外特征或者输入向量,相比skip-gram和CBOW,关系模型对系统性能的提升具有更显著的作用。
在下一步工作中,我们将考虑引入外部语义资源,如WordNet本体等,进一步提高词向量的语义表达能力。
[1] Salton G, Wong A, Yang C S. A vector space model for automatic indexing[J]. Communications of the ACM, 1975, 18(11): 613-620.
[2] Bengio Y, Ducharme R, Vincent P, et al.A Neural Probabilistic Language Model[J].The Journal of Machine Learning Research.2003,3: 1137-1155.
[3] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv: 1301.3781, 2013.
[4] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[C]//Proceedings of the Advances in Neural Information Processing Systems. 2013: 3111-3119.
[5] Pennington J, Socher R, Manning CD. GloVe: Global Vectors for Word Representation[C]//Proceedings of the Empiricial Methods in Natural Language Processing (EMNLP 2014), 2014.
[6] Tian F, Dai H, Bian J, Gao B. A Probabilistic Model for Learning Multi-Prototype Word Embeddings[C]//Proceedings of Coling 2014, 2014: 151-160.
[7] Qiu S, Gao B. Co-learning of Word Representations and Morpheme Representations[C]//Proceedings of Coling 2014, 2014: 141-150.
[8] Collobert R, Weston J, Bottou L, et al. Natural language processing (almost) from scratch[J]. The Journal of Machine Learning Research, 2011, (12): 2493-2537.
[9] Socher R, Pennington J, Huang E H, et al. Semi-supervised recursive autoencoders for predicting sentiment distributions[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2011: 151-161.
[10] Levy O, Goldberg Y. Dependency-based word embeddings[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. 2014.
[11] Mnih A, Hinton G E. A scalable hierarchical distributed language model[C]//Proceedings of the Advances in neural information processing systems. 2009: 1081-1088.
[12] Bunescu R, Ge R, Kate R J, et al. Comparative experiments on learning information extractors for proteins and their interactions[J]. Artificial intelligence in medicine, 2005, 33(2): 139-155.
[13] Pyysalo S, Ginter F, Heimonen J, et al. BioInfer: a corpus for information extraction in the biomedical domain[J]. BMC bioinformatics, 2007, 8(1): 50.
[14] Fundel K, Küffner R, Zimmer R. RelEx—relation extraction using dependency parse trees[J]. Bioinformatics, 2007, 23(3): 365-371.
[15] Ding J, Berleant D, Nettleton D, et al. Mining MEDLINE: abstracts, sentences, or phrases[C]//Proceedings of the pacific symposium on biocomputing. 2002, (7): 326-337.
[16] Nédellec C. Learning language in logic-genic interaction extraction challenge[C]//Proceedings of the 4th Learning Language in Logic Workshop (LLL05). 2005: 7.
[17] Li L, Jiang Z, Huang D. A general instance representation architecture for protein-protein interaction extraction[C]//Proceedings of International Conference on Bioinformatics and Biomedicine, 2014: 497-500.
WordRepresentationBasedonWordRelations
JIANG Zhenchao, LI Lishuang, HUANG Degen
(School of Computer Science and Technology, Dalian University of Technology, Dalian,Liaoning 116024, China)
In natural language processing tasks, distributed word representation has succeeded in capturing semantic regularities and have been used as extra features. However, most word representation model are based shallow context-window, which are not enough to express the meaning of words. The essence of word meaning lies in the word relations, which consist of three elements: relation type, relation direction and related items. In this paper, we leverage a large set of unlabeled texts, to make explicit the semantic regularity to emerge in word relations, including dependency relations and context relations, and put forward a novel architecture for computing continuous vector representation. We define three different top layers in the neural network architecture as corresponding to relation type, relation direction and related words, respectively. Different from other models, the relation model can use the deep syntactic information to train word representations. Tested in word analogy task and Protein-Protein Interaction Extraction task, the results show that relation model performs overall better than others to capture semantic regularities.
word representation; word embedding; word vectors; neural network; relation model

蒋振超(1988—),博士研究生,主要研究领域为自然语言处理。

李丽双(1967—),教授,博士,主要研究领域为自然语言理解、信息抽取与文本挖掘。

黄德根(1965—),教授,博士生导师,主要研究领域为自然语言理解与翻译。
1003-0077(2017)03-0025-07
2015-09-23定稿日期: 2016-02-18
国家自然科学基金(61672126、61173101)
TP391
: A
