一种基于QoS历史记录的Web服务推荐算法❋
2017-07-17唐瑞春类兴振吴长昊许晓伟丁香乾
唐瑞春, 类兴振, 吴长昊, 许晓伟, 丁香乾
(中国海洋大学信息科学与工程学院,山东 青岛 266100)
一种基于QoS历史记录的Web服务推荐算法❋
唐瑞春, 类兴振, 吴长昊, 许晓伟, 丁香乾
(中国海洋大学信息科学与工程学院,山东 青岛 266100)
针对Web服务推荐时间和结果精确度方面存在的不足,本文提出一种基于QoS(Quality of Service)历史记录的Web服务推荐算法(Web Service Recommendation Algorithm based on Historical QoS,WSRAHQ)。首先,建立基于欧氏距离的Web网络用户兴趣度相似簇,提高Web服务推荐的精确度;然后,根据用户的QoS历史记录,利用多元线性回归,得到新用户的Web服务推荐结果,完成Web服务推荐。仿真结果表明了该方法有效性。
QoS历史记录;用户兴趣度;欧氏距离;多元线性回归;Web服务推荐
云计算的发展和成熟,为Web服务提供了强大的计算能力,使得Web服务在电子商务、数字家庭等方面的应用越来越广泛。然而,越来越多的Web服务提供的功能相同或相似,这导致了用户很难从海量数据中快速地选择自己所需要的服务。因此,如何提高服务推荐质量已成为相关领域的关键问题。
近年来,针对Web服务推荐过程中推荐精度不高以及时间复杂度过高的问题所开展的研究方兴未艾。具有较高预测精度的服务推荐系统,可以提升以体验为导向的产品应用质量,成为帮助消费者进行网上决策的有效途径[1]。Wei C等[2]为给移动设备寻找并推荐质量高的服务,提出了一个挖掘用户信息的在线角色挖掘算法,并提出了移动环境下的以问题为驱动的上下文感知服务推荐框架。研究信息过载问题,Sui H F等[3]提出了基于用户上下文本体驱动的推荐策略,使用本体来描述和整合资源,将用户的直接需求及其可能的偏好关联起来作为推荐系统中上下文的目标。文献[4]将基于内容推荐技术应用在数字家庭环境中,提出了一种基于流行度预测的媒体推荐算法可向用户推送新兴趣点。尽管上述文献为推荐系统提供了更加精确的预测,然而没有考虑到Web服务的分布和动态变化等特性。I Bartolini等[5]和D Bianchini等[6]引入服务质量QoS,进一步提高服务推荐的精确度。
基于QoS的Web服务推荐可分为两类:一类是把多QoS约束的服务选择建模为有向无环图最优路径问题,给出基于此模型的服务选择算法[7];另一类通过建立QoS本体,利用本体的描述及推演能力提高服务匹配的精度[8]。上述方法的前提是假设服务的QoS静态可知,然而大多数服务QoS的值是变化的,与服务运行时的状态密切联系,推荐效果不是很理想。用户通过使用一个Web服务,能够在真实的运行环境中获得其准确的QoS历史数据,因此将用户对服务的QoS历史记录引入到Web服务推荐中,能够提高服务推荐的精确度[9-10]。
综上所述,本文提出了可有效提高服务推荐精确度的服务推荐算法WSRAHQ。首先,将与网络新用户兴趣度相似的用户划分为一个簇;然后,利用同一簇中用户的QoS历史记录,确定对同一服务的各个QoS属性值,将其作为自变量,对应的服务质量QoS值作为因变量,利用多元线性回归求解出每个服务QoS属性的权重预测值,进而得到其QoS预测函数,据此为新用户推荐服务。
1 相关研究
1.1 基于QoS的web服务推荐方法中的主要问题
服务质量QoS描述了服务的非功能属性,其中包括响应时间、可用性、成功率、吞吐量等,反映了一个服务满足用户需求的能力,是Web服务性能评价的重要指标。以往的QoS值是由服务提供商提供的一个假设常数,没有考虑到服务实际的执行情况,参考性不高,为了得到真实的QoS值,服务的运行情况应进行监测、管理和查询。由于存在大量的候选Web服务,让消费者体验所有服务然后做出决定是不可行的,可以通过使用其他用户的QoS历史记录来进行服务推荐,而现有的服务推荐方法大多采用所有用户的QoS历史记录来进行Web服务推荐[11],这在现实中可行性不高。因为:
(1)大量的QoS数据会导致服务推荐的时间复杂度过高,实时性不强。
(2)不同的用户拥有不同的兴趣,兴趣的不同可能导致用户不会去访问一些服务,但是这些服务可能恰好满足用户对QoS性能的要求,从而导致推荐的精确度下降。
针对上述问题,本文提出的WSRAHQ算法在利用QoS历史记录进行Web服务推荐之前,根据兴趣度对用户进行分簇,过滤掉与新用户兴趣度相差较大的用户QoS历史记录,在提高Web服务推荐精确度的同时,降低了推荐运行时间。

图1 基于QoS历史记录的Web服务推荐过程
1.2 研究环境
如图1所示,在Web服务环境中,首先根据用户兴趣度,将兴趣度相似的用户分成一个簇。然后,将用户的服务请求提交给Web服务分配中心的服务搜索模块,由服务搜索模块得到相应的候选服务列表并提交给服务的QoS预测模块,基于候选服务的QoS历史信息建立QoS多元线性回归预测模型,计算候选服务QoS预测值。最后基于QoS预测值进行排序,根据QoS预测值由大到小的顺序,将服务交由服务分配模块完成服务的推荐。
2 相关定义
2.1 用户兴趣度
Web服务中,不同网页的内容存在差异,用户对不同网页的内容感兴趣的程度也不一样,通过对网页内容进行提取I=(I(i1),I(i2),…,I(in)),与用户提供的兴趣I′=(I′(i1),I′(i2),…,I′(in))相比较可以定义用户的兴趣度。
定义1 用户兴趣度。 在Web服务中,用户兴趣度定义为用户对多个网页内容感兴趣的程度,用Ij(ik)表示,Ij(ik)∈[0,1],其中ik表示用户j的第k个感兴趣网页内容。兴趣度是用来计算用户相似性的重要指标,也是用户分簇的重要依据。
2.2 用户的QoS历史记录
用户通过使用某一个Web服务,能够切实体验到其真实的QoS值,用户的QoS历史记录是通过使用不同的Web服务获得的,该值从用户的角度给出了Web服务性能的评价结果。用S={S1,S2,...,Sn}表示一组Web服务,选取k个QoS属性来衡量每个Web服务的QoS性能;服务Si的QoS属性集为Qi={qi1,qi2,...,qik},其中Si∈S,qik,表示服务Si的第k个QoS属性(如:响应时间,可用性和吞吐量等)。

2.3 QoS预测函数
越来越多的Web服务提供的功能相同或相似,导致了很难从海量数据中快速地选择用户所需要的服务。QoS作为Web服务性能的评价标准,QoS的预测值在用户选择Web服务时可以提供有价值的信息。
本文采用多元线性回归方法对QoS进行预测有两个原因,一是由于候选服务的QoS值在服务前是不可能获得的,所以希望对候选服务的QoS进行预测,利用多元线性回归可以达到这一目的;其二,多元线性回归模型中的参数可以通过求解线性方程获得,所以这类算法具有较低的时间复杂度和较强的可执行性。
定义3 QoS预测函数。 对服务Si用同一簇内其他用户的QoS历史记录作为训练样本,通过建立多元线性回归模型得到其QoS性能预测函数。服务Si的QoS预测函数可表示为:
Qi=α0+θ1qi1+…+θkqik+ε,
ε~N(0,σ2),
(1)
其中:α0为常数项,表示当qi1,qi2,…,qik为0时服务Si的QoS总体平均值;θk是QoS属性qik对应的权重值,表示其他QoS属性的值保持不变时,qik变化一个单位,QoS加权变化的单位数;ε是QoS真实值与按多元回归方程预测值的差值,服从分布ε~N(0,σ2)。
3 基于QoS历史记录的Web服务推荐算法
3.1 用户兴趣度的求解
在Web访问领域,获得用户兴趣度的方法主要有两种,一是用户在访问Web服务时主动提供,二是通过用户的操作信息来分析得到用户兴趣度。对于初次访问Web服务的新用户通过前者来得到用户兴趣度,而对于已有的用户,通过公式化的度量方法将用户的访问行为转化为用户的兴趣度。
设新用户在访问Web服务时提供的兴趣度为I′=(I′(i1),I′(i2),…,I′(in));
设BW=[ω1,ω2,ω3,ω4,ω5]T表示用户访问Web服务的权重矩阵,其中ω1,ω2,ω3,ω4,ω5分别表示访问时间、阅读次数、回滚次数、阅读时长、保存或复制操作权重。在用户访问页面时,用户对页面做的操作越多,文档权重越高,意味着对该页面越感兴趣。
ωid表示已有用户对所访问页面的偏好值,如公式(2)所示:
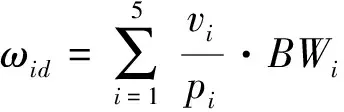
(2)
其中:V={v1,v2,v3,v4,v5}为访问事务集合,v1,v2,v3,v4,v5分别为阅读次数、阅读时长、回滚次数、阅读频次、是否执行复制或保存操作;P={p1,p2,p3,p4,p5}为页面信息,p1,p2,p3,p4,p5分别为参考阅读次数、参考阅读时长、参考回滚次数、参考阅读频次,页面操作参考信息,p5=1表示对页面执行了复制或保存操作。
公式(2)可推出:
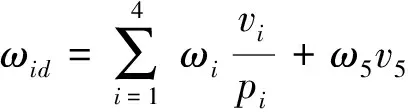
(3)
用户对页面的偏好会随时间产生遗忘,为了使用户偏好更准确,我们需要对用户偏好进行调整与更新。德国心理学家艾宾浩斯(Ebbinghaus)首先对遗忘现象作了系统的研究,得到的遗忘规律表明遗忘过程是先快后慢,是非线性的。研究表明渐进遗忘法能较好地拟合遗忘曲线[12]。为了更好地对用户偏好进行建模提高用户偏好的准确性。本文引入的渐进遗忘函数[13]h(t)如公式(4)所示:

(4)
公式(4)中,tmin,tmax分别为遗忘的最小间隔时间和最大间隔时间;γ表示遗忘系数,即遗忘的快慢,γ∈[0,1],当γ=0时,没有发生遗忘,当γ=1时,完全非线性遗忘。
interest(j,p)为经过渐进遗忘法更正后的用户j对页面p的兴趣值,计算方法如公式(5)所示:

(5)
把内容相似的页面归结为用户的同一兴趣,用户对某一兴趣的兴趣度如公式(6)所示,本文用T(ik)表示同一兴趣内容ik的页面的集合,|T(ik)|为用户感兴趣的内容ik的页面数量。

(6)
Ij(ik)即为用户j对ik的兴趣度,通过公式(6)计算产生的第j个用户兴趣度矩阵为[Ij(i1)Ij(i2)…Ij(ik)]T。
3.2 基于用户兴趣度的Web服务用户分簇
在求解出用户兴趣度的基础上,对用户进行分簇。由于分到同一簇内的用户兴趣度相近,其要访问的Web服务也会相似,因而可以通过同一簇内的用户QoS历史记录对新用户进行Web服务推荐。而用户分簇的精确度会影响后续服务推荐的精确度,因此采用较好的分簇算法非常重要。本文首先利用了Matlab软件对比分析了机器学习中几个计算用户相似性的方法,有欧氏距离(Euclidean)、曼哈顿距离(Manhattan)和切比雪夫距离(Chebyshev),仿真采用用户的兴趣度作为输入,其仿真比较结果如图2所示。
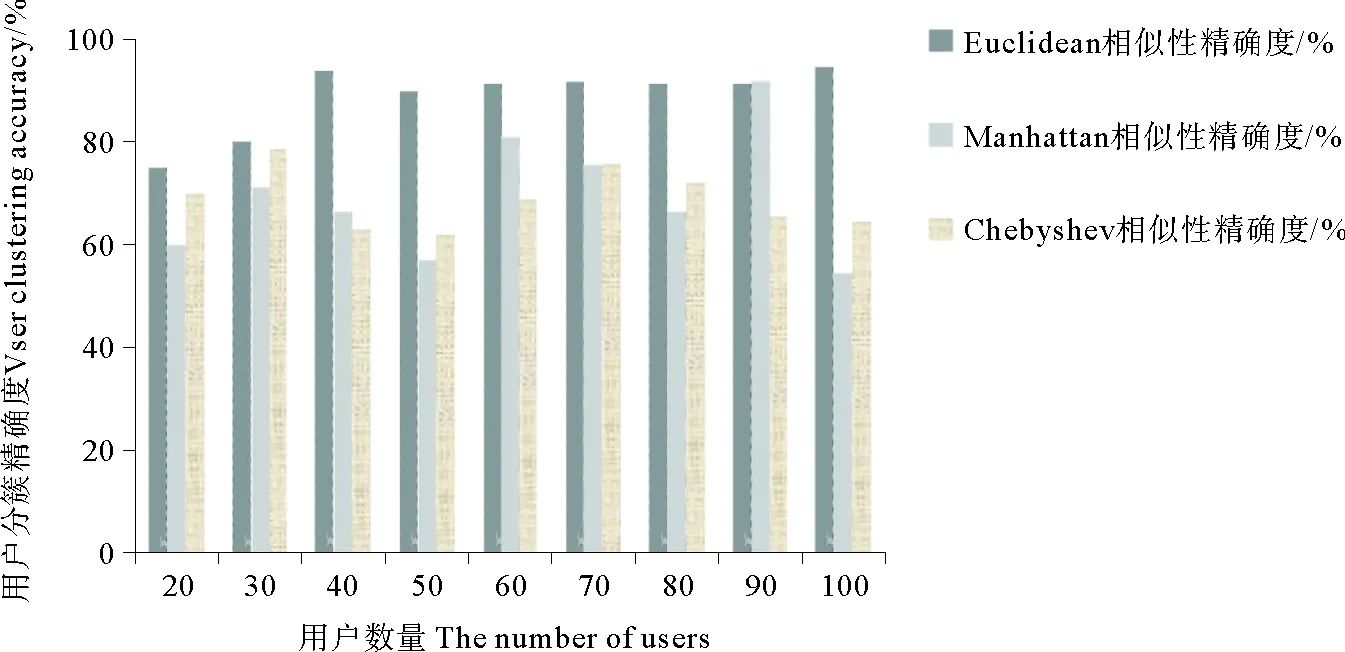
图2 用户分簇算法比较
图2说明了欧氏距离在对用户分簇时相对其他两种方法,用户相似性精确度更高。
利用欧氏距离公式分别计算新用户与用户Uj之间的距离dj,公式如下所示:
(7)
利用公式(7)得到m维向量D=(d1,d2,…,dm),其中,dj(j∈[1,m])表示新用户与已有用户之间的欧氏距离。
通过给定的分类阈值T,将兴趣度相似的用户划分为一个簇类,即对∀dj≤T,都有Uj∈R,R表示与新用户兴趣度相似的用户组成的簇类。其中分类阈值T定义为欧氏距离的平均值,保证了簇类中的用户兴趣度与新用户更相似:

3.3 基于用户QoS历史记录的Web服务推荐
本文利用QoS预测函数为新用户推荐QoS值高的服务,而预测函数性能的好坏取决于QoS属性权重θ。由于QoS预测函数中θ是未知的,所以推荐的关键就是利用同一簇内其它用户的QoS历史记录得到最佳的θ,使得QoS预测函数的预测输出值和真实值之间的差异最小化。
对服务Si,其QoS值的历史记录为yi,yi受到k个QoS属性值qi1,qi2,...,qik和随机因素ε的影响。Web服务推荐的多元线性回归数学模型为:
yi=θ1qi1+…+θk-1qik-1+θkqik+ε,
ε~N(0,σ2)。
(8)

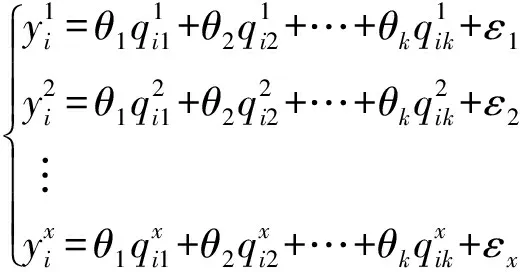
(9)
公式(9)可表示为:
Yi=θq+εε~N(0,σ2)。
(1)初始化θ的值(例如,令θ=0)。
(2)重复执行如下公式更新θ的值。

(10)
其中:α表示学习速率,用于调节θ的收敛速度。由于
因此,公式(10)可表示为:

(11)
又由于和新用户在同一簇内,且对服务Si有QoS历史记录的用户有x个,因此公式(11)可表示为:

(12)
把通过BGD算法求出的θ带入到公式(1)QoS预测函数中,这时每个服务Si的QoS预测函数其QoS性能预测值和真实值之间的差异是最小的。然后把新用户对服务的QoS属性要求带入到各个服务的QoS预测函数中,即可得到各个服务的QoS性能预测值,然后按QoS性能预测值由高到低的顺序将服务推荐给新用户。
3.4 基于QoS历史记录的Web服务推荐算法

WSRAHQ算法如下:输入:用户Uj对某一Web服务Si的QoS历史记录Qji,新用户对该Web服务的QoS属性要求值,已有用户的兴趣度集Ij(ik),新用户兴趣度集合I′。输出:针对新用户的QoS性能预测值从高到低的Web服务集合S。初始化:m个用户,每个用户有n个兴趣内容;分类阈值T=0,学习速率α=0.5,权重θ=0。S1:for(j=1;j≤m;j++) //对m个已有用户执行循环{ 根据公式(6)计算用户Uj的兴趣度; 根据公式(7)计算新用户与用户Uj之间的欧氏距离dj;}T=1m∑mj=1dj; //分簇阈值为欧氏距离的平均值S2:for(i=1;i≤n;i++){ for(j=1;j≤m;j++) //对每个服务Si计算其QoS属性权重θ{ if(dj≤T){ 将用户Uj对服务Si的QoS历史记录Qji代入到公式(9)中,作为训练样本;}else;}根据公式(12)来不断更新权重θ,直到收敛;将求出的θ代入公式(1),并结合新用户对服务QoS属性的要求,得到服务Si的QoS预测值;}S3:将S2得到的QoS预测值从大到小排序,得到推荐给新用户的服务集S。
4 仿真实验
本文采用VS 2010作为仿真环境,利用模拟网络中用户兴趣度和用户的QoS历史记录作为输入,评估WSRAHQ算法在提高Web服务推荐精确度和降低时间复杂度方面的性能。
4.1 仿真参数设置
仿真中的用户数量m由20增至100,每次增加10个用户来更新网络。其中,设置用户兴趣类型数量为5,其兴趣度由系统在0-1范围内随机生成;QoS属性数量设置为5,分别是响应时间、可用性、吞吐量、成功率和成功调用次数,用户的QoS历史记录来自Eyhab AI-Masri的QWS数据集[13-14],Eyhab AI-Masri的QWS数据集是一个公开的Quality of Web Service(QWS)数据集。提供了365个网络上真实的web服务,每一个web服务对应着9个QWS属性,这些web服务质量属性已经经过了测试。在仿真实验中,选取了其中的10个服务,并且假设服务S5,S6,S7,S8,S9提供用户感兴趣的相似的功能,通过改变用户数量对比分析不同算法的性能。
4.2 WSRAHQ算法性能分析
从两个方面来评价WSRAHQ算法性能,首先是Web服务推荐的精确度对比分析,然后是Web服务推荐的运行时间对比分析。
4.2.1 服务推荐精确度对比分析 将WSRAHQ算法与ANQP算法[10]、QPA算法[16]进行了对比,由于服务S5,S6,S7,S8,S9提供的是用户感兴趣的服务,所以对于不同算法在相同用户数量情况下,S5,S6,S7,S8,S9推荐顺序更靠前的算法精确度更高。从服务推荐顺序表1、表2、表3可以发现利用本文提出的WSRAHQ算法进行Web服务推荐时,用户感兴趣的服务S5,S6,S7,S8,S9其推荐顺序更靠前。在用户数量为60的时候,WSRAHQ算法和ANQP算法精确度相近,要比QPA算法好,而其他情况下,WSRAHQ算法的精确度明显高于另外两种算法。
产生这种结果的原因是WSRAHQ算法首先将用户根据其兴趣度进行分簇,然后利用同一簇内的用户为Web网络新用户推荐Web服务,由于其感兴趣的服务相似,因此推荐的结果中Web网络新用户想要访问的服务顺序更靠前。而ANQP算法是用全部用户的QoS历史记录进行服务推荐,其推荐的服务顺序靠前的不一定是新用户感兴趣的服务;QPA算法虽然也对用户进行了分簇,但是根据用户的位置来划分的,分簇的效果准确性不高导致了其服务推荐结果有失准确性。
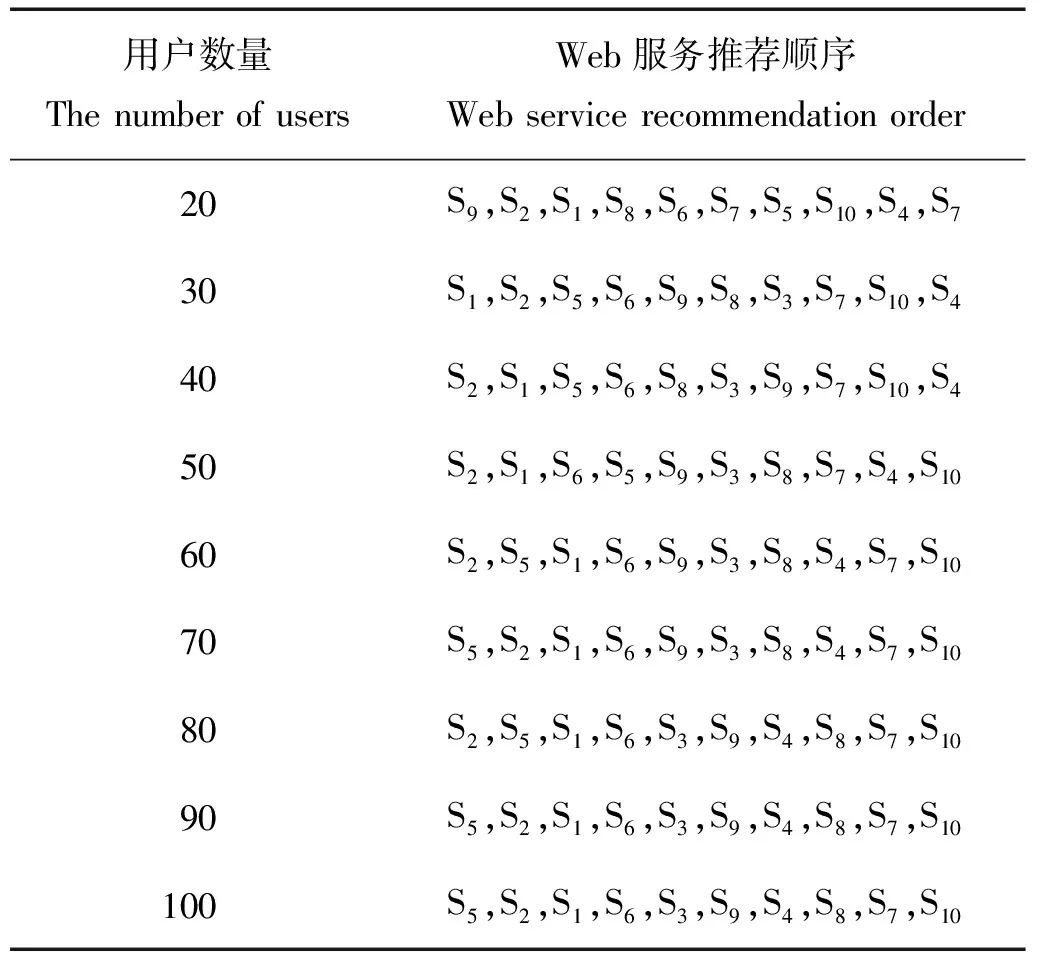
表2 ANQP算法Web服务推荐结果
4.2.2 服务推荐运行时间对比分析 能够在较短的时间内给用户推荐QoS性能更好的Web服务是一个很重要的问题。我们对比分析了WSRAHQ算法、ANQP算法以及QPA算法的服务推荐运行时间。运行时间对比分析如图3所示:

表3 QPA算法Web服务推荐结果
图3说明随着用户数量的不断增加,ANQP算法的运行时间增长的比较快;用户数量小于60时,QPA算法与WSRAHQ算法的运行时间相差无几,但在用户数量超过60以后QPA算法运行时间相对WSRAHQ算法有了明显的增长,而本文提出的WSRAHQ算法随用户数量的增多,其运行时间增长平缓。

图3 Web服务推荐运行时间对比图
以上仿真结果表明,本文提出的WSRAHQ算法在提高Web服务推荐精确度的同时降低了推荐运行时间。
5 结语
本文研究在Web网络环境中进行Web服务推荐时如何提高服务推荐的精确度和降低服务推荐运行时间的问题,提出一种基于QoS历史记录的Web服务推荐算法。利用基于用户兴趣度的欧氏距离将用户进行分簇,然后利用同一簇类内已有用户对服务的QoS历史记录,通过多元线性回归为新加入簇类的用户推荐Web服务,实验结果表明该方法的有效性。
[1] ZHANG Y S, ZHANG B, SUN R N. Service execution environment oriented service selection approach[J]. Journal of Chinese Computer Systems, 2014, 35(1): 1-5.
[2] WEI C, KHOURY R, FONG S. Web 2. 0 recommendation service by multi-collaborative filtering trust network algorithm[J]. Information Systems Frontiers, 2013, 15(4): 533-551.
[3] SUN H F, ZHENG Z B, CHEN J L, et al. Personalized web service recommendation via normal recovery collaborative filtering[J]. IEEE Transactions on Services Computing, 2013, 6(4): 573-579.
[4] Feng Y Q, Tang R C, Zhai Y L, et al. Personalized media recommendation algorithm based on smart home[C].//Kuala Lumpur, Malaysia: The Second International Conference on e-Technologies and Networks for Development, 2013: 63-67.
[5] BARTOLINI I, CIACCIA P, PATELLA M. Efficient sort-based skyline evaluation[J]. ACM Transactions on Database Systems. 2008, 33(4): 1-49.
[6] BIANCHINI D, ANTONELLIS·V D, MELCHIORI M. Flexible semantic-based service matchmaking and discovery[J]. World Wide Web, 2008, 11(2): 227-251.
[7] ZENG L Z, BENATALLAH B, NGU A, et al. QoS-aware middleware for web services composition[J]. IEEE Transactions on Software Engineering, 2004, 30(5): 311-327.
[8] PAPAIOANNOU I V, TSESMETZIS D T, ROUSSAKI I G, et al. A QoS ontology language for web-services[C].//Vienna, Austria: 20th International Conference on Advanced Information Networking and Applications(AINA), 2006: 1-6.
[9] Lin W M, Dou W C, Luo X F, et al. A history record-based service optimization method for QoS-aware service composition[C].//Washington, USA: 2011 IEEE International Conference on Web Services (ICWS), 2011: 666-673.
[10] SHI Y L, ZHANG K, LIU B, et al. A novel QoS predication approach based on regression algorithm[C].//Huhehot, China: Web Information Systems and Applications Conference (WISA), 2010: 208-211.
[11] Jula A, Sundararajan E, Othman Z. Cloud computing service composition: A systematic literature review[J]. Expert Systems with Applications, 2014, 41(8): 3809-3824.
[12] HU S G, LIU Y, CHEN T P, et al. Emulating the ebbinghaus forgetting curve of the human brain with a NiO-based memristor[J]. Applied Physics Letters, 2013, 103(13): 1-4.
[13] 郑先荣, 汤泽滢, 曹先彬. 适应用户兴趣变化的非线性逐步遗忘协同过滤算法[J]. 计算机辅助工程, 2007, 16(2): 69-73. ZHENG Xianrong, TANG Zeying, CAO Xianbin. Non—lineal gradual forgetting collaborative filtering algorithm capable of adapting to users’ drifting interest[J]. Computer Aided Engineering, 2007, 16(2): 69-73.
[14] Al-MASRI E, MAHMOUD Q H. Discovering the best web Service[C].//Alberta, Canada: Proceedings of the 16th International Conference on World Wide Web, 2007: 1257-1258.
[15] Al-MASRI E, MAHMOUD QH. Qos-based discovery and ranking of web services[C].//Hawaii, USA:16th International Conference on Computer Communications and Networks, 2007: 529-534.
[16] SHI Y L, ZHANG K, LIU B. A new QoS prediction approach based on user clustering and regression algorithms[C].//Washington, USA: IEEE International Conference on Web Services, 2011: 726-727.
Abstract: Aiming at the accuracy problem of Web service recommend time and result, a Web Service Recommendation Algorithm based on the Historical QoS record(WSRAHQ)is proposed in this paper. First, based on the Euclidean distance, the similar cluster of Web network users' interest degree is built to improve the accuracy of Web service recommendation. Then, the new user's Web service recommend result is given to finish the Web service recommendation based on the users' QoS Historical record and multiple linear regression. The simulation results show its efficiency.
Key words: QoS historical record;users’ interest degree;Euclidean distance;multiple linear regression;Web service recommendation.
责任编辑 陈呈超
The Recommendation Algorithm of Web Services Based on QoS Historical Record
TANG Rui-Chun, LEI Xing-Zhen, WU Chang-Hao, XU Xiao-Wei, DING Xiang-Qian
(College of Information Science and Engineering, Ocean University of China, Qingdao 266100,China)
国家科技支撑计划项目(2015BAF28B01)资助 Supported by National Science and Technology Support Program Project (2015BAF28B01)
2015-06-16;
2016-04-17
唐瑞春(1968-),女,教授。E-mail:tangruichun@ouc.edu.cn
TP37
A
1672-5174(2017)09-134-07
10.16441/j.cnki.hdxb.20150217
唐瑞春, 类兴振, 吴长昊, 等. 一种基于QoS历史记录的Web服务推荐算法[J]. 中国海洋大学学报(自然科学版), 2017, 47(9): 134-140.
TANG Rui-Chun, LEI Xing-Zhen, WU Chang-Hao, et al. The recommendation algorithm of Web services based on QoS historical record[J]. Periodical of Ocean University of China, 2017, 47(9): 134-140.
