基于本体的家谱知识图谱模型及检索系统
2017-07-12朱玲萱
姜 赢,张 婧,朱玲萱
(北京师范大学 珠海分校,广东 珠海519087)
基于本体的家谱知识图谱模型及检索系统
姜 赢,张 婧,朱玲萱
(北京师范大学 珠海分校,广东 珠海519087)
基于更好地提供家谱知识管理与信息检索服务的目的,提出了建立基于本体的家谱知识图谱模型的方法。采了本体技术解决了家谱管理模型中宗族人物关系知识建模问题。利用了本体分子技术解决了家谱中动态知识和多粒度知识问题。通过基于Java EE框架B/S模式的家谱检索系统的开发与实验,实现了关于家谱检索的5大功能,对于我国家谱馆藏知识的挖掘与利用有积极意义,也为本体在复杂领域知识图谱的综合运用提供了新思路。
家谱;本体;本体分子;知识图谱
家谱是指以记载某一家族血缘世系为核心内容的,用以维系家族世次顺序的文献载籍,具有重要的历史资料价值。数量可观的家谱,不仅对家庭制度、婚姻制度、人口与替等研究有着不可替代的资料价值,即对历史学、民俗学、社会学、经济学、教育学等都能提供许多重要资料。如称雄一世的徽商研究,其中不少有价值的资料主要是从皖南徽商家谱中寻得的[1]。家谱也为寻家族根认同提供重要资料。随着改革开放的进一步发展,海内外游子过去梦想的寻根谒祖,早已成为现实。特别是香港回、澳门回归祖国之后,洗雪了百年民族耻辱,海外华人扬眉吐气,“一国两制”更增强了海内外中华民族子孙的向心力,于是访故里、访故旧、访祖国,掀起了更大的寻根认同热。浩如烟海的家谱资料则为寻根认同提供了保证。家谱对进行爱国主义教育、开展寻根认同、促时台湾回归祖国统一大业,有其他资料不能取代的重要作用。
研究建立家谱知识图谱模型的主要目的是支持家谱信息的查询,方便人们追根溯源,以发掘家谱的历史文化价值。家谱知识图谱系统的工作内容是通过对现有的家谱信息进行有效的收集、分析,在现有的技术基础上,描述家谱知识,建立宗族人物关系网络,并使用可视化的方式展示家族动态变化的过程,以方便人们了解其家族的繁衍过程以及姓氏来源。
1 研究现状分析
随着信息技术的普及化,家谱的电子化成为现实,而且电子家谱查询系统在人们的生活中也有了一定的应用[14]。国内外影响比较广泛的电子家谱系统有:1)寻根网[2]:寻根网以家谱为纽带介绍了全国近五百多个姓氏的源流及历史人物、历史典故、分布范围,家谱收藏研究等多方面的内容。寻根网立足从基本地情、人情出发,充分运用现存的家谱和当今的人口资料,追溯、探讨各姓氏的发端、由来,以及迁徙的状况、路线、当前的聚居点,同时收集、列举有关该姓氏中比较突出的人物及他们所做出的历史功迹。寻根网有一个寻根检索栏目。该栏目提供谱资料、百家姓、字辈派语、历史图片、历代年号、新老地名、地方志等家谱信息的查询。该查询通过关键词匹配实现,以文本的形式返回查询结果。2)中国家谱网[3]:中国家谱网介绍了与家谱相关的新闻、家谱总目、姓氏文化、谱文化等家谱 知识,帮助人们追本溯源。中国家谱网的检索栏目可以通过姓氏、分布地、堂号、名人等关键字的匹配进行寻根问祖方面的信息查询,姓氏拼音、中文姓氏等关键词的匹配检索百家姓信息,另外也支持其他关键词的匹配来检索古今地名、历史名人、历代年号等内容的查询。3)PhpGedView[4]:PhpGedView系统以直观的图表展现家谱信息,具有不同语言的版本。其用来传达信息的图表主要有一下几种:家谱结构树,以树形图的形式展现家谱的世系图,每个人物对应的节点包含有人物图像、出生日期和死亡日期等信息,并且包含链接到人物详细信息的超链接。关系图,通过输入两个人物的名字,展现这两个人物的相关关系。家系图,可以检索人物的父母、兄弟、子女、祖父母的信息。对应于每种关系,以一个树形图的形式展示出来。该系统用图表的形式展现信息,内容直观,但是依然是基于关键字的检索。
综上所述,一般的电子家谱主要基于关键词匹配进行查找,查询结果往往是原始的家谱文献或简单的家谱结构树,很少做进一步的智能化处理,不能进行深入的语义挖掘。这些问题正好是本体论及其相关技术能够解决的问题[13]。文中提出基于本体的家谱知识图谱模型研究,将本体的引进对于解决家谱问题的作用主要体现在3个方面:1)本体描述家谱概念。本体可以很好的描述家谱中的概念,让家谱信息成为机器可理解的知识,为进一步的推理做好准备。2)本体分子[5]理论和技术解决家谱中的动态知识和多粒度知识问题。3)本体推理实现家谱隐性知识的挖掘。本体推理利用推理公理和推理规则的使用,根据现有的本体模型中的三元组得出额外的本体三元组,实现了隐性知识的挖掘。
2 家谱知识图谱模型关键技术问题
2.1 宗族人物关系知识描述问题
作为家谱中最重要的内容,“世系表”就是说明一个家族成员,如:父子、兄弟间的相互关系,写清楚祖先后代每一个家族成员名字的图表[15]。它有4种基本的记述格式:欧式、苏式、宝塔式和牒记式[6]。这四种世系表形式都各有特色,这是一般族谱中比较常见的世系表,但也有其它的变化,在记述家族世系表时,可根据掌握材料的多少、家族成员的多少等灵活采用。笔者在分析其他家谱系统世系表基础之上,总结与提炼家谱知识中共性特征,提供最大限度兼容性以满足各种类型家谱中个性特征的管理要求,提出了基于本体的家谱世系表知识建模框架。世系表结构可以抽象为一个本体层次模型的树模型。如图1中的世系表为树形结构,节点以性别区别颜色,男性为浅色背景,女性为深色背景。
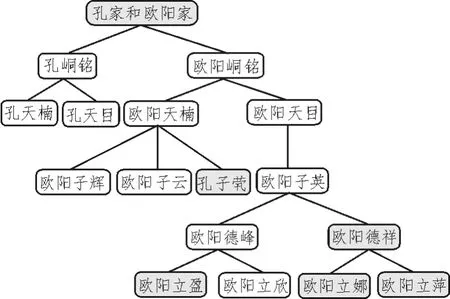
图1 世系表树形结构图
在家谱知识图谱中,宗族人物之间的关系描述是最重要而又最复杂的。如 “父母与子女”、“祖父母”、“曾祖父母”、“兄弟姐妹”、“妯娌关系”、“连襟关系”、“叔侄关系”、“姨甥关系”等等。笔者以本体RDF/OWL语言[7]作为家谱人物关系描述语言,能够通过统一的模式表达丰富的人物关系。人物用本体实例来描述(图中的节点),人物之间的关系用属性来描述(图中的边)。图中鼠标焦点所描述的是“宋庆龄”是“孔令杰”的“阿姨”,也就是一种“姨甥关系”。通过这种描述方式,可以建立复杂的家族人物关系网络。
但是如果人物之间关系过于复杂,家谱横跨的历史时期过于漫长,那么家族人物之间关系的建立会变得非常费时费力。笔者采取本体推理技术能够很好的解决这个问题。本体推理的思路是:只建立家族人物之间最直接的关系,而对于间接关系通过制定推理规则自动生成人物关系[7]。“宋庆龄”和“孔令杰”的“阿姨”关系并不需要在数据库中建立,而是通过制定“姨甥关系”推理规则自动生成的。“宋庆龄”之所以是“孔令杰”的“阿姨”,原因是以下3条规则:1)“宋霭龄”是“宋庆龄”的“姐妹”;2)“宋霭龄”是“孔令杰”的“母亲”;3)“宋庆龄”是“女性”。 本体通过RDF/OWL语言描述显性知识(宗族人物直接关系),通过规则推理挖掘隐性知识 (宗族人物间接关系),能够较好的解决家谱宗族人物关系问题。
2.2 家谱多粒度知识管理问题
知识管理的粒度指的是知识组织和检索过程中的基本知识单元的范围的大小以及描述程度的粗细。在知识粒度划分方面,家谱知识管理面临者两难的局面:一方面以家族人物为知识单元,显得粒度太细;另一方面,如果以整个家谱作为知识单元,又显得粒度太粗而且缺乏知识揭示、演化、管理与利用的灵活性。因而,目前迫切需要一种粒度适中的知识单元作为知识管理的基础。
解决家谱多粒度知识管理问题将采取本体分子技术:同时采用两种粒度的本体分子,建立两者之间的关联。如图2所示,按照“人”作为粒度划分本体分子,则关于这个人的家传、艺文著录、家谱图像、所对应的家谱可以作为静态信息,即为本体分子的 “核子”,婚配情况等动态信息则作为“离子”;按照“家谱”作为粒度划分本体分子,则将这个家族的姓氏源流、堂号、家训看成本体分子的“核子”,可能包含的动态信息则看成本体分子的“离子”。在“人”和“家谱”这两种知识粒度的基础之上,可以根据需要创建新的知识粒度,如“张三的兄弟关系”、“李四的婚姻关系”等等。
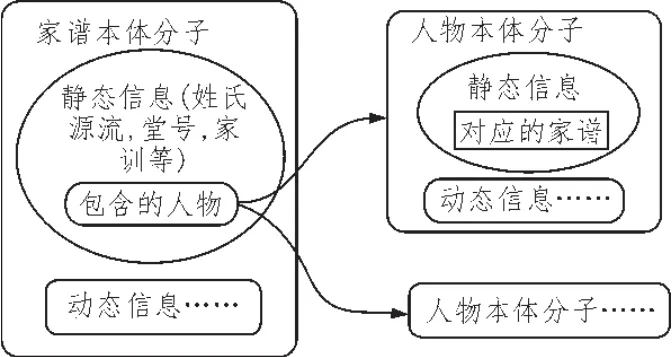
图2 基于本体分子的家谱多粒度知识示意图
2.3 家谱动态知识演化问题
动态知识的特点在于,随时间或情境的延续或变化,用于揭示知识内涵的特征属性的状态以及这些特征属性之间的关系都会随之演化。家谱中存在的动态知识主要有以下几种[8]:1)家族的姓氏的起源。比如说诸这个姓,是五代十国的时候,后周有个贵族叫诸葛十朋,赵匡胤发动陈桥兵变建立宋朝后,又不愿别人打听到他,诸葛十朋就改姓名诸十朋,隐居在会稽山中,他的后代于是改姓单姓诸,成为诸姓的一个来源。2)家族的姓氏的变化。总的说来原因有:避祸改姓、避讳改姓古代帝王的名字不准别人使用、同一姓因异体字写法不同,以及少数民族汉化以将原来的部落改为汉姓。3)家谱中人物的婚姻配偶关系、人物仕途历程等等都是随时间和情境的变化动态演变的。
解决动态知识问题也采取本体分子技术[9]。本体分子按照一定粒度划分知识语义片段,如人物本体分子和家谱本体分子,主要包括“核子”和“离子”两个部分。“核子”是本体分子中静态不变的知识,如家谱人物本体分子中关于人物的 “性别”、“出生时间”等等。“离子”是本体分子中可以动态变化的知识,如家谱人物本体分子中人物的“姓名”、“婚配关系”、“仕途历程”等等。
对于家谱中家族本身,它的“家族姓氏”可能由于各种原因不断变化,但是家族还是那个家族。比如春秋战国时期,陪赵太子赴秦的蔺相如,因太子途中得急症而亡被处极刑,割头挖心,蔺氏的家族因此受其株连,为逃避这场灾难,蔺字去头,挖心(“佳”),改姓为门;清朝由于文字狱,个别姓氏如“查”成了忌讳,于是家谱改成了“香”,随后,文字狱的平反,姓氏又改了回来。“家族姓氏”的这种变化不能说是家族本身的变化,它的核还是没有变。对于本体分子的控制,最重要的是要抓住本体分子的核子。不管本体分子如何动态变化,它的核是不会变化的。
由于本体分子中还存在着“离子”在不断演变,本体分子的形态可以随之改变,比如一个人的仕途历程盛衰表现为各个时期人的经历与境遇的不同变化。针对这些动态变化的知识,可以建立各种家谱本体分子演化的模型。
3 基于本体的家谱知识图谱检索系统
3.1 系统总体架构
模型系统的整体设计采用B/S模式,是采用Java EE框架的系统体系结构实现的。客户端使用浏览器访问服务器提供的Web接口或Web页面;服务器端采用多层体系架构设计,包括:基于Web服务器的表现层、基于应用服务器的中间层、基于数据库系统的数据存储层等,系统的整体结构如图3所示。视图表现层为用户通过浏览器访问信息检索系统提供了一个基于Web的接口,该层所采用的主要技术包括客户端的Prefuse[10]技术,以及服务器端的JSP、Servlet技术。应用服务器中间层采用中间件技术,由JavaBean技术实现,运行在应用服务器中。本体查询组件和本体构建组件是整个系统的核心部件,使用了Jena[11]的API来实现。数据存储层是家谱本体库和家谱本体分子库,采用AllegroGraph[12]系统实现数据存储,是整个系统的基石。
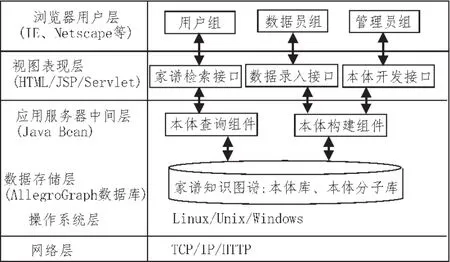
图3 系统结构图
3.2 系统功能
如图4所示,家谱查询系统主要包括:家谱检索,人物检索,字辈排行,追根溯源,家族名人,家族迁徙,家族辉煌等功能。字辈排行,追根溯源,家族名人和家族辉煌,家族迁徙是该系统的特色栏目,通过这些栏目的使用,用户可以获得非常良好的体验,更加方便快捷地获取他想获取的信息。
系统主要功能包括:
1)家谱检索:家谱检索栏目主要实现检索一个家族的基本信息,如姓氏源流,堂号家训,世系图,家传,家谱图像,家族关系等。在世系图中,用户输入姓氏“奇渥温”,年代“1167-1292”,并指定为“精确查询”后,点击“搜索”按钮,图6的下半部分的结果显示展现出了奇渥温家族1167年到1292年的世系图。其中,加了框框的表示的是有官位,框框里面是橙色表示这个人曾经是帝王。最上层的“铁木真”出生于1167年,最下层的“真金”死于1292年。
2)人物检索:人物检索栏目用于检索人物以及人物之间的关系。下面再分个人查询和两人关系查询这两种功能。两人关系又可以具体定位到婚姻,兄弟姐妹,平辈,祖孙等关系。在这里我们使用具名图来表示不同粒度知识的检索及动态知识的表示。
3)字辈排行:字辈排行栏目提供对一个家族中某一字辈的人物及其附近几代的人物进行检索的功能。例如,用户输入姓氏“欧阳”,字辈“子”,选择“精确查询”后点击“搜索”按钮,可检索出“欧阳”家族中,与“子”字辈上下相邻3个字辈的宗族人物排行。
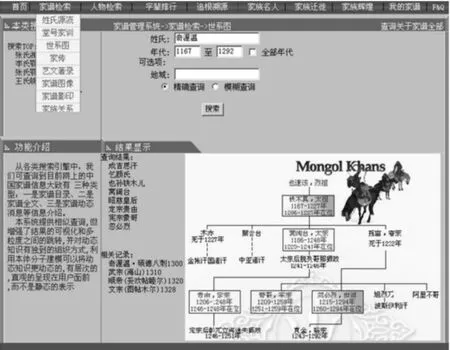
图4 基于本体的家谱知识图谱检索系界面
4)追根溯源:追根溯源栏目是我们的一个特色栏目。用户可以借助于此系统,追根溯源,查询自己所在的家族以及该家族的迁徙信息。我们可以简单地输入自己或自己的长辈的姓名、字辈信息,有选择地输入所在的地域信息,实现或精确或模糊的查询。
5)家族名人:提供对某个家族的著名人士的查询。输入家族姓氏即可查询到这个家族中的所有名人,点击名人可查看其详细信息。也可限制某一时期的名人查询。例如,用户输入姓氏“李”、起始年代没有明确限制,表示查询李家有记载的所有家谱,选择“精确查询”后点击“搜索”按钮,结果即会显示在页面下半部分。系统给出了李家从唐朝开始所有的名人志士的列表,点击人名后可查看此人物的详细信息。
4 结 论
制定家谱知识管理标准,建立家谱知识图谱模型,开发家谱知识检索系统,解决家谱管理模型中静态知识的描述问题与动态知识的演化问题,它对于我国家谱馆藏知识的挖掘与利用有积极意义。文中提出采取基于本体的知识图谱技术路线,综合应用本体推理、本体分子和本体演化等技术,具有较强的可行性。
[1]徐彬.论明清徽州家谱编修与徽商的互动[J].学术研究,2011(6):107-111.
[2]寻根网.[EB/OL][2018-06-02].http://xungen.so/.
[3]中国家谱网.[EB/OL][2018-06-01].http://www.chinajiapu.com/view/index.asp.
[4]PhpGedView.[EB/OL][2018-05-21].http://www.phpgedview.net/.
[5]董慧,陈文樵,罗忆,等.数字档案本体分子论及其应用研究[J].中国档案,2010(3):57-60.
[6]丁红.浙江家谱版本特征分析 [J].图书馆理论与实践, 2006(1):104-107.
[7]董慧,余传明,徐国虎,等.基于本体的数字图书馆检索模型研究 (Ⅳ)——历史领域知识推理机制[J].情报学报, 2006(6):666-678.
[8]周远成,夏群芳.汉族姓氏演变源流述略[J].湖南城市学院学报, 2005(1):75-80.
[9]董慧,王菲,姜赢,等.基于数字图书馆的本体应用环境研究.中国图书馆学报[J],2009(5):52-58.
[10]肖明,栗文超,夏秋菊 .基于Prefuse和层次聚类的信息检索主题知识图谱研究[J].现代图书情报技术, 2012,V28(4):35-40.
[11]Apache Jena.(2010-12-11)[2011-12-23].http://jena.apache.org/.
[12]袁莹.基于AllegroGraph的空间数据语义查询研究[J].厦门理工学院学报, 2011(4):50-54.
[13]夏翠娟,刘炜,陈涛,等.家谱关联数据服务平台的开发实践[J].中国图书馆学报,2016(3):27-38.
[14]陈智兵.家谱档案及其管理工作探析[J].兰台世界,2015(S5):95-97.
[15]陈国军,张庭玉.二叉树电子家谱设计[J].信息与电脑(理论版),2015(4):88,94.
Ontology based knowledge graph model of genealogical record and retrieval system
JIANG Ying,ZHANG Jing, ZHU Ling-xuan
(Beijing Normal University, Zhuhai 519087, China)
In order to provide better service of genealogical record knowledge management and information retrieval,it presents a method of creating ontology based knowledge graph model of genealogical record.It uses ontology technology to solve the problems of person relations in a family tree.Ontology molecule technology is adopted to resolve the problems of dynamic and multi-granularity of knowledge in genealogical record.A genealogical record retrieval system is developed and experimented based on Java EE framework and B/S model,with 5 major system functions.It puts forwards a new method of comprehensively applying ontology to knowledge graph in the complex domain,which is of great significance of knowledge mining and utilizing of genealogical record in store in China.
genealogical record; ontology; ontology molecule; knowledge graph
TN99
A
1674-6236(2017)12-0161-05
2016-08-22稿件编号:201608159
文化部科技创新项目(201505);广东省科技计划项目(2014A080804001)
姜 赢(1981—),男,湖北武汉人,博士,副教授。研究方向:自然语言处理,语义分析。
