一种基于Spark的高光谱遥感图像分类并行化方法
2017-07-12朱耀琴
刘 震,朱耀琴
(南京理工大学 计算机科学与工程学院,江苏 南京210094)
一种基于Spark的高光谱遥感图像分类并行化方法
刘 震,朱耀琴
(南京理工大学 计算机科学与工程学院,江苏 南京210094)
为了实现大数据量遥感图像的分类,提出了一种Spark平台下高光谱遥感图像稀疏表示分类并行化方法PSCSRC,首先设计五元组形式的中间数据存储结构,其次在每次迭代中只是将稀疏矩阵中与中间矩阵各分块对应的子矩阵分发到各节点,这就减少了中间数据Shuffle和数据传递的时间消耗。实验结果表明,PSCSRC分类方法与SCSRC分类方法相比,在保证分类精度的同时,执行速度有了明显的提升。
高光谱;云计算;Spark平台;分类;稀疏表示
目前,全球有超过1000颗卫星实现对地观测的任务[1]。伴随着遥感技术的快速发展,遥感图像的空间和光谱分辨率也越来越高,可以获取的遥感数据量也迅猛增长。遥感数据量的爆炸性增长给传统分类方法带来了巨大的挑战。为了解决该问题,目前常用的方法有基于GPU加速的高性能计算系统和基于云计算平台的分布式集群。
GPU在浮点运算和并行计算方面相对于CPU有着巨大的优势,因此有学者利用GPU技术进行并行计算。王启聪[2]提出了基于GPU的空谱联合核稀疏表示高光谱分类并行优化算法。Santos L[3]等人基于高并行GPU框架实现了机载有损高光谱图像压缩算法,得到了显著的加速效果。不过,GPU技术对于数据密集型的计算效率却不高,而且代码编写调试复杂。
遥感图像分类算法在云计算平台上的应用多处在研究阶段。Li Y[4]等人设计了Spark[5-6]平台下基于主成份分析的高光谱解混方法,在保证精度的同时,取得了很好的性能提升。Mohamed H.Almeer[7]在Hadoop[8]云平台下实现了高容量遥感数字图像的索贝尔滤波、锐化、对比度增强等算法。常生鹏[9]等人利用Hadoop技术设计改进了Meanshift图像边缘分割算法,实验结果表明,在Hadoop环境下的高分辨率卫星图像数据处理速度有了明显的改善。
文中将云计算引入到高光谱遥感图像分类中,在Spark平台上实现了基于空间相关性正则化的稀疏表示分类并行化方法 (Parallel Spatial Correlationregularized Sparse Representation Classification,PSCSRC),进行遥感图像的分类,并通过实验验证了Spark处理高光谱遥感图像的可行性和高效性。
1 PSCSRC算法设计
1.1 Spark云计算平台介绍
Spark是一个快速、易用的分布式大规模数据计算框架,其核心是弹性分布式数据集(Resilient Distributed Datasets,RDD),RDD 是对集群上并行处理数据的分布式内存抽象,通过在集群中的多台机器上进行数据分区实现并行计算。RDD有转换算子和动作算子两类操作,通过转换算子生成新RDD,形成阶段(Stage),最终通过动作(Action)提交 Spark程序。
1.2 稀疏表示分类方法简介
分类是高光谱图像处理中最重要的内容之一。随着压缩感知和稀疏表示理论的发展,越来越多的学者提出采用稀疏表示进行分类[10],其假设条件是测试样本能够由一些训练样本所组成的结构化字典进行线性组合稀疏表示。该方法首先通过求解稀疏性约束的最优化重构模型,得到字典原子权值组成的稀疏向量,然后根据恢复稀疏向量的特征,确定测试样本的类别。
1.3 基于空间相关性正则化的稀疏表示分类方法
基于空间相关性正则化的稀疏表示分类方法[11](Spatial Correlation regularized Sparse Representation Classification,SCSRC)是一种基于空间相关性正则化稀疏表示的迭代型分类算法,该方法首先建立高光谱图像分类的稀疏表示模型,通过添加像元间的光滑性正则项和训练样本的空间位置信息,用以提高分类精度,用ADMM[12]求解模型,最终进行分类。
1.4PSCSRC算法
算法分为数据准备阶段和计算阶段,数据准备阶段的主要工作是读入高光谱图像数据,再分块存储在HDFS中。计算阶段的主要工作是从HDFS读取矩阵文件,迭代计算稀疏矩阵和若干中间矩阵,若达到指定迭代次数,则迭代结束,使用稀疏矩阵对测试样本进行分类,否则,使用稀疏矩阵更新中间矩阵,继续迭代。
1.4.1 数据准备阶段
数据准备阶段就是一个数据预处理的过程。首先将高光谱遥感图像读入内存以三维数组形式存放,为了处理方便将其转化为二维数组X并归一化,其中 X=[X1,X2,…,XN],Xi=[x1,x2,…xL]T,Xi表示一个像元在各个波段上的光谱响应,N为总样本数量,L为波段数。从X中随机取得若干列向量作为训练样本存入 A 中,A=[A1,A2,…,AM],其中 Ai=[a1,a2,…aL]T,M为训练样本数量。利用A和X进一步计算,得到F和B,预处理过程的伪代码如下所示:

预处理之后得到了矩阵F和矩阵B。B=[B1,B2,…,BM]T,其中 Bi=[b1,b2,…bN],将矩阵 B 使用 HDFS的SequenceFile以
1.4.2 计算阶段
根据RDD提供的算子以及自定义的函数设计PSCSRC算法,其具体流程如下所示。
1)PSCSRC算法首先将矩阵F作为广播变量F_broadcast发送到各个Worker节点,再利用RDD提供的SequenceFile函数读取矩阵B并转换成RDD数据模型B_RDD,同时使用partition参数设置分块数目,记分块数量为partitions。接着filterWith算子将B_RDD每个分块转换成新的RDD,再分别调用count函数得到行向量的数量,由于矩阵B在HDFS上按照行号顺序存储,因此可以得到B_RDD中每个分块中行向量的起始行号和终止行号
2)接下来对B_RDD使用mapValues算子创建五元祖group_RDD,分块中元素键值对具体形式为
3)group_RDD使用mapValues算子将分区中的五元组相加得到plus_RDD。接着,plus_RDD使用map Partitions算子,通过外积法[13]与广播变量F_broadcast相乘得到中间矩阵,然后使用reduceByKey算子将中间矩阵按照key累加得到S_RDD。
4)使用collect函数将S_RDD汇总到Driver端并稀疏化得到SArray,如果已达到指定迭代次数,转5,否则,由于P、Q、R、T各分块与B的各分块结构相同,所以根据P、Q、R、T中的各个分块的起始行号和终止行号,将SArray中对应的子矩阵发送到各分块所在的Worker节点更新分块,其中对P的分块使用Gauss-Seidel[14,15,16]方法更新,对 Q 的分块使用软阈值方法更新,对R、T的分块使用线性方法更新,更新完成后转3继续迭代。这种首先计算各中间矩阵每个分块对应的子矩阵,然后再把子矩阵分发到各分块所在节点的方法,相比于直接将稀疏矩阵分发到各节点之后再提取出子矩阵更新分块的方法来说,将集群中移动的数据量降低为1/partitions。
5)复用SCSRC算法中根据稀疏矩阵SArray计算OA和Kappa系数的部分,总精度(OA)反映了一个随机样本的分类结果与真实标记类型相一致的概率,其可以表述为如下形式:

为了更能体现图像分类的整体误差,使用Kappa系数k来评价分类精度。Kappa系数计算公式表述为如下形式:
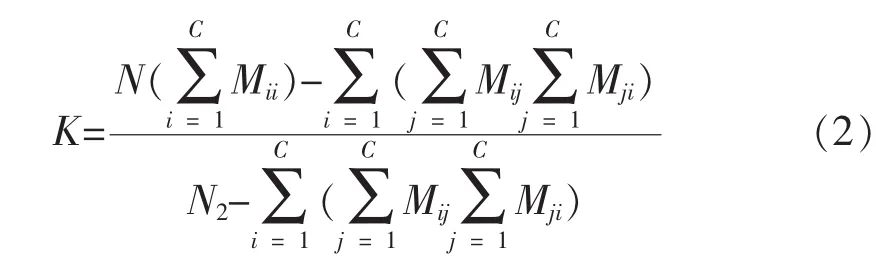
这里C表示类别数量,M为一个C×C的混淆矩阵,N表示测试样本数量。
2 实验结果及分析
本实验使用机载可见红外成像光谱仪采集的美国印第安纳州Indian Pines实验区的高光谱遥感图像。该图像共包含220个波段,空间分辨率为20米,图像大小为145×145(数据大小为6 MB)。并使用ENVI软件的Mosaicking功能将此数据上下镶嵌为29 000×145 (数据大小为 1.21 GB)、116 000×145(4.83 GB)的数据。
实验运行在由9台服务器组成的Spark集群上,各节点配置为Intel Xeon E7-4807,6核,内存24 GB,Spark版本为1.4.1,操作系统为Ubuntu12.04。
相同的执行环境下基于CPU的SCSRC程序运行结果(分片数为1)和基于Spark的PSCSRC并行程序运行结果如表1所示,结果为实验重复执行10次后的平均值。图1给出了两种方法的视觉比较,其中(a)是各类地物的真实分布,(b)是SCSRC分类结果,(c)是 PSCSRC 分类结果。
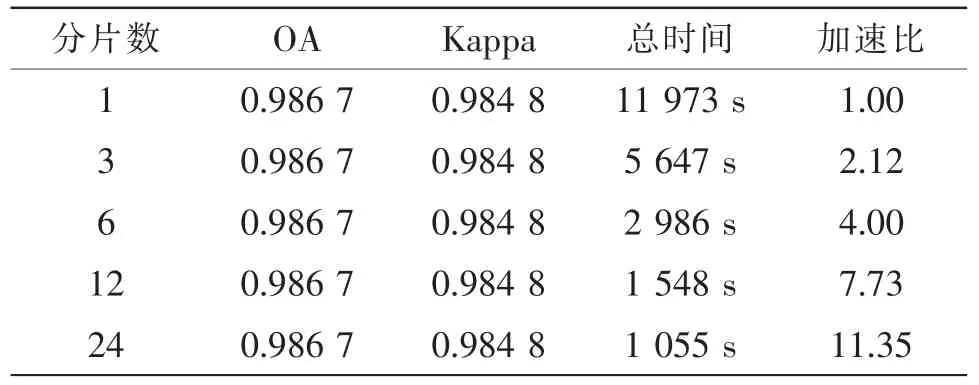
表1 Spark下不同分片数处理结果
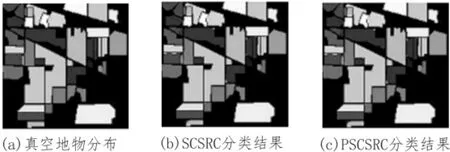
图1 Indian Pines数据集
由表1可知,PSCSRC算法在保证分类精度的同时,随着分块数量的增加执行时间不断降低,只是加速比效果不太理想。并行算法下能保证分类精度是因为SCSRC算法分类时使用极大似然估计的思想使用稀疏矩阵来分类,虽然Spark平台下得到的稀疏矩阵与串行平台下有微小的差别,不过并不影响分类效果。加速比效果不太理想是因为Spark会为每个分块启动一个线程来处理该分块的数据,而本实验中每个分块数据量太小,创建线程的系统开销相对分片数据的计算时间占较大比重,因此加速效果不明显。
由图1的b和c可以看出,PSCSRC算法的分类结果与SCSRC的分类结果完全相同。
分别使用 29 000×145、116 000×145 的数据作为实验数据集重复以上实验,实验结果如图2所示。
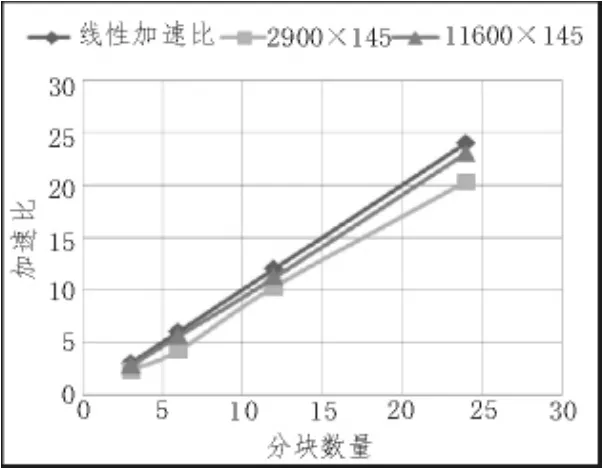
图2 加速比性能测试结果
从图2可知,当数据量变大时,加速效果越来越明显,数据量越大,实际的加速比越接近线性加速比,并且分块数量越大,加速效果越好。原因有两个:1)算法中尽量避免了会导致shuffle操作的RDD转换算子,大大减少了集群中数据的跨节点流动;2)每次迭代过程中使用稀疏矩阵SArray更新P、Q、R、T时,只是将各分块对应的子矩阵分发到各个节点,而不是整个稀疏矩阵,同样是减少了数据在集群中的流动。
3 结 论
SCSRC中涉及到多个矩阵相加再相乘的部分可能由于单机尺度的限制而无法运行,因此本文提出了基于Spark的PSCSRC算法,将多个矩阵以行向量的形式存储至五元组,再分发到集群中各个Worker节点。结合高速缓冲存储器Cache的特性,采用利于分布式下矩阵并行计算的外积法来提升矩阵相乘效率,其中对于大矩阵与小矩阵相乘的情况,通过采用广播变量将小矩阵分发到各Worker节点进行快速计算。利用Spark中数据本地性的任务分配策略,将迭代中常用的RDD进行缓存,利用Spark内存计算的特点进行快速迭代计算。最后,通过分块中行向量的起始行号和终止行号,使用大矩阵的对应子矩阵更新4个中间矩阵,而不是将整个大矩阵分发到各Worker节点,大大减少了节点间的流量传输,加快程序的执行速度。
[1]姚禹,向晶.全球在轨卫星数量突破1000颗大关[J].中国无线电,2012(11):77-77.
[2]王启聪,吴泽彬,刘建军,等.基于GPU的空谱联合核稀疏表示高光谱分类并行优化[J].计算机工程与科学, 2014,36(12):2321-2330.
[3]Santos L, Magli E, Vitulli R,et al.Highlyparallel GPU architecture for lossy hyperspectral image compression[J].IEEE Journal of Selected Topics in Applied Earth Observations&Remote Sensing, 2013,6(2):670-681.
[4]Li Y, Wu Z, Wei J, et al.Fast principal componentanalysis for hyperspectralimaging based on cloud computing[C]//IEEE International Geoscience and Remote Sensing Symposium.IEEE,2015:513-516.
[5]HOLDEN KARAU.Spark快速数据处理[M].余璜,译.北京:机械工业出版社,2014.
[6]夏俊鸾.Spark大数据处理技术[M].北京:电子工业出版社,2015.
[7]Almeer M H.Cloud hadoop map reduce for remote sensing image analysis[J].Journal of Emerging Trends in Computing& Information Sciences,2012,3(4):637-644.
[8]蔡斌.Hadoop技术内幕[M].北京:机械工业出版社,2013.
[9]常生鹏,马亿旿,蔡立军,等.一种基于Hadoop的高分辨率遥感图像处理方法[J].计算机工程与应用,2015,51(11):167-171.
[10]Chen Y,Nasrabadi N M,Tran T D.Hyperspectral image classification using dictionary-based sparse representation[J].IEEE Transactions on Geoscience&Remote Sensing,2011,49(10):3973-3985.
[11]刘建军.高光谱图像非负矩阵分解解混与稀疏表示分类研究[D].南京:南京理工大学,2014.
[12]Yang J,Zhang Y.Alternating direction algorithms for l1-problems in compressive sensing[J].Siam Journal on Scientific Computing, 2011,33 (1):250-278.
[13]孙远帅,陈垚,官新均,等.基于Hadoop的大矩阵乘法处理方法 [J].计算机应用,2013,33(12):3339-3344.
[14]Li S, Zhang B, Li A, et al.Hyperspectral imagery clustering with neighborhood constraints[J].IEEE Geoscience&Remote Sensing Letters,2013, 10(3):588-592.
[15]Rakotomamonjy A.Surveying and comparing simultaneous sparse approximation (or group-lasso) algorithms[J].Signal Processing, 2011, 91(7):1505-1526.
[16]Iordache M D,Bioucas-Dias J M,Plaza A.Total variation spatial regularization for sparse hyperspectralunmixing [J].IEEE Transactions on Geoscience&Remote Sensing, 2012, 50 (11):4484-4502.
A kind of hyperspectral image classification parallel method based on Spark
LIU Zhen,ZHU Yao-qin
(College of Computer Science and Engineering,Nanjing University of Science and Technology,Nanjing 210094,China)
In order to achieve the classification of large amounts of hyperspectral image,proposed a hyperspectral sparse representation classification parallel method on Spark,designing a 5-tuple intermediate data storage structure and then distributing sub-matrix of spare matrix corresponded to each block of intermediate matrices to each node in each iteration,which reduce time consumption caused by intermediate data Shuffle and data transmission.Experiment results show that execution speed of sparse representation classification parallel method under Spark platform has been significantly improved.
hyperspectral; cloud computing; spark platform; classification; sparse representation
TN919
A
1674-6236(2017)12-0019-04
2016-10-18稿件编号:201610087
国家重点实验室开放研究基金,复杂产品智能制造系统技术国家重点实验室开放基金资助(QYYE1603)
刘 震(1990—),男,河南睢县人,硕士研究生。研究方向:云计算。
