基于改进二部图与专家信任的混合推荐算法
2017-07-12黄熠姿
黄熠姿
摘要:针对传统协同过滤算法出现的稀疏数据、用户冷启动等问题以及复杂网络结构的广泛应用,本文提出结合改进的二部图与改进的专家信任算法来提高推荐准确度。基于普通二部图算法,将用户对项目的评分作为节点之间的分配资源权重,不仅关注用户与项目之间的联系,同时体现用户对项目的喜好程度;其次,本文根据用户的评论数和与该用户对项目评分相同的数目来判断该用户的专家信任度,改进传统系统过滤算法。为了提高推荐准确度,改进缺点,我们将两者算法进行加权混合,加权因子根据实验中最小MAE值对应的权值来确定,形成混合推荐算法。最后针对基于用户的协同过滤、传统二部图以及本文提出的混合算法计算MAE值和平均Hamming距离,对比分析本文算法的推荐准确度与多样性,实验表明本文方法推荐效果较好,准确率高,个性化强,有研究和应用价值。
Abstract: In view of the limitations like data sparseness, new users with little record of traditional collaborative filtering recommendation algorithm and the wide application of complex network structure, this paper argues to coalesce the recommendation algorithm based on expert trust and the modified bipartite graph recommendation algorithm. First of all, we proposed an improved recommendation algorithm based on weighted networks, not only pay attention to the connection between users and projects, but also reflect the users' preferences in projects. Secondly, the degree of expert trust is determined by user comments and project reviews. And in order to improve the accuracy of recommendation, we coalesce this two kinds of algorithm and give them weight. Finally, we determine the weights and calculate MAE and the average Hamming distance of the traditional collaborative filtering, the traditional bipartite graph and the hybrid recommendation algorithm through experiments, which shows that the hybrid recommendation algorithm has higher accuracy, stronger individuation, and more research and application value.
關键词:推荐算法;二部图;专家信任;加权混合
Key words: recommendation algorithm;bipartite graph;expert trust;weighted mixture
中图分类号:TP391.3 文献标识码:A 文章编号:1006-4311(2017)19-0160-05
0 引言
信息时代的迅速发展使人们能够方便快速地通过互联网获取各种电影资源,海量的电影资源及相应的用户评分信息很容易造成信息过载。已有很多研究证明电影的评分会对观影者的观影行为产生影响。以评分信息能够影响用户的观影行为为逻辑基础,研究者开始利用推荐技术对评分信息进行处理挖掘。既有的推荐算法包括:基于内容的推荐[1]、基于相似用户的协同过滤推荐[2]、基于知识的推荐[3]以及混合方法推荐[4]。
但是,传统的推荐方法不能有效解决数据稀疏性问题与数据冷启动问题,这会影响到数据的准确性和可信度。数据稀疏性问题指的是可以利用的数据相对于整个用户物品空间比较少。推荐系统冷启动问题指的是用户或项目没有历史行为信息或者只有少量的历史行为信息,这时就无法对用户或者项目精确地建模,进而造成推荐效果比较差。近几年将复杂网络应用于推荐系统的研究日益增多,并能提供相对有效的解决数据稀疏、扩展性等问题,基于网络结构的算法是根据物质的扩散、热传导[5-6]原理,将用户与项目看成抽象的节点,发现他们之间潜在的联系,Zhou等提出了NBI(Network-Based Inference)算法[7],利用二部图分配资源,从而预测用户感兴趣的项目,得到了更好的推荐效果。研究者们也在将信任引入推荐系统,缓解数据稀疏性和冷启动问题来提高推荐准确度,目前已取得不少进展。Papagelis[8]等人在协同过滤推荐系统中使用信任推荐,Ma King和Lyu[9]提出集成信任网络的这些方法都为缓和数据稀疏问题提供了解决途径。Jamali[10]等人介绍了一种在信任网络随机游走算法,根据随机游走概率选择项目,为冷启动问题提供了解决办法。
基于此,本文以图论和基于信任的协同过滤的建模思想为基础,试将二部图和专家推荐相结合的混合推荐算法对传统推荐算法进行改进,以有效地解决数据稀疏性和冷启动问题。
1 既有方法回顾
1.1 传统二部图结构的推荐算法
二部图是图论中一种特殊的网络,它包含两类节点,在推荐系统中,一类是用户集合U={u1,u2,…,un},一类是项目集合Y={y1,y2,…,yn},用户与项目之间的关系组成连边e(ui,yj),这样,节点集合U,Y与边的集合E构成了一个二部图网络G=(U,Y,E)。
1.3 既有方法综述
从上述的描述中发现,基于二部图的推荐算法则可以在一定程度上解决常见的数据稀疏、扩展性等问题[12],同时可以增大冷门商品的推荐比例,增加了推荐的多样性。但该算法仍存在缺陷,只考虑了用户选择或者没有选择商品,没有考虑用户对不同商品的喜好情况不同。传统的协同过滤算法,在确定最近邻时,通常只考虑用户的评分相似性,没有考虑近邻近用户的身份属性,研究学者在此基础上引入了近邻用户的信任值作为相似度,但也没有有效地解决问题。所以基于以上不足,本文能够将以上两种算法进行改进以解决上述问题,同时将两种算法混合推荐给用户,使推荐的准确性增加。
2 改进二部图与专家信任的混合算法
2.1 基于二部图的改进推荐算法
2.1.1 用户评分标准化
在现实生活中,每个人的评分标准和分数高低偏好会有差异,例如对于评分范围为1-5分的商品来说,有的用户可能习惯性评分偏高,将认为一般的商品评4分,认为满意的商品评5分,而有的用户则打分较苛刻,将认为一般的商品普遍评3分,认为满意的评4分,只有极其满意的少数商品才评5分,这样可能会因为两个用户对某件商品满意度相似而评分不同导致相似度降低,推荐不准确,为了尽量消除用户之间这种评分标准的误差,本文将用户评分比上该用户所有评分的平均值作为新的标准化评分矩阵,即:
2.1.2 加权的二部图算法
普通二部图节点之间的边值只有0和1,即选择与不选择,这只考虑了用户与项目之间是否有联系[14],而未考虑用户对项目的喜爱程度,而实际中,如用户看过某部电影并不代表他喜欢该部电影,可能对电影评分很低,但二部图中无法体现,所有用户看过的电影在图中所占权重一样(都为1),这并不符合用户的真实评价与推荐力度,所以本文将用户对某个项目的评分(标准化转换之后的)作为“用户”—“项目”的权重,评分高的项目自然在推荐算法中占得更大权重,也更倾向于推荐给相似用户,符合用户期望。假设三个用户对四部电影的评分标准化之后的评分矩阵为:
2.1.3 加权的二部图算法特点分析
加权后的二部图算法能够更好地体现用户对项目的喜好程度,对于用户评分高的项目会加大被推荐的机会,对于用户不喜欢的项目将降低其推荐权重,使得所推荐的项目更加符合用户偏好,提高推荐准确率。但是加了权重之后可能会降低冷门项目的推荐度,如某冷门项目被选择的次数很少但评分都很高,则其权值之和仍會偏高,只要该项目的连边比其他热门项目少很多,高评分并不会有太大影响。
2.2 基于改进协同过滤的专家信任算法
Goldbaum.D[15]提出Follow the Leader模型,认为用户都倾向于接受专家的观点。Reichiling等[16]将专家推荐系统定义如下:专家推荐系统是为了满足用户在特定场景下对专家的需要,帮助他们及时准确找到相关的专家来解决问题的推荐系统。本文认为,专家信任度表示的是用户在网络中向其他用户提供可靠信息的可信度。利用专家信任可以有效改善新用户的冷启动问题。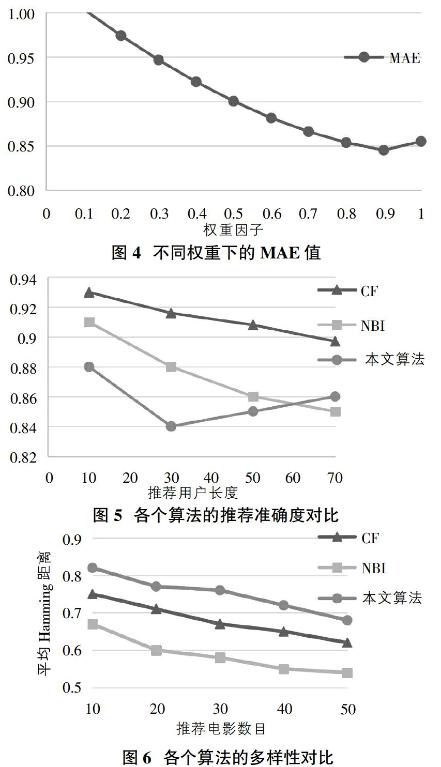
2.2.1 专家信任
3 实验结果及分析
本文采用的实验数据是由美国明尼苏达大学的GroupLens研究小组建立的电影数据集MovieLens,来源网站http://www.grouplens.org。该数据集包含900个用户(每个用户评论电影数量大于20)对1526部电影的52万条评分数据,评分范围1-5,1为不喜欢,5为很喜欢。本算法将选取的数据划分为训练集(90%)和测试集(10%),首先根据本文算法中不同权值下的最小MAE确定权重因子γ,接着将基于用户相似度的协同过滤(CF)、传统二部图算法(NBI)及本文推荐算法在不同推荐长度下的平均绝对误差值和平均Hamming距离进行对比分析,总结本文算法的推荐准确度和个性化程度。
3.1 混合权重因子γ的确定
由图4可以看到,随着权重因子的增加MAE逐渐降低,当γ为0.9时MAE到达最低值0.845,之后当γ=1时,即完全由改进二部图算法得出的MAE增大,从该趋势可以看出,权重因子的取值变化对推荐准确率影响较大,γ为0.9左右时准确率最高,所以在接下来的实验中我们以γ=0.9作为最终的权重。
3.2 推荐准确度对比实验分析
本实验基于权重因子γ=0.9的条件下,分别对比各个算法在不同推荐用户长度下的MAE值,比较用户相似度的协同过滤、传统二部图算法及本文推荐算法的推荐准确度,实验结果如图5。
根据对比图表可以看出,在推荐用户长度小于60之前,文本算法都优于其他算法,推荐准确率有较大提高,因为本算法引入信任度,对邻居用户的选取有双重标准,专家可以提高推荐的可信度,缩小预测评分和实际评分之间的差距。但当推荐用户大于30之后混合算法的MAE值增大,并在之后精确度要低于NBI算法,可能加入专家信任度较低的用户无法进行精准推荐,以及排名靠后的用户对目标用户的贡献度下降,从而影响了推荐的准确度。
3.3 推荐多样性对比实验分析
由图可以明显看出本文算法又大幅度提高了推荐的多样性,因为考虑了用户与项目的度的影响,有效抑制了大众流行电影的推荐程度,使对目标用户有贡献的用户更加精准,提高了推荐的个性化,满足了不同用户的多兴趣需求。
5 总结与展望
针对基于用户的协同过滤和传统二部图推荐算法的优缺点,本文将基于用户的协同过滤改进为基于专家信任的推荐算法,将传统二部图的资源分配规则改进为以评分为权重的带权二部图,提出将二部图与专家信任度调和权重,形成综合推荐方法。实验结果表明,将评分引入二部图并将二部图与专家算法结合是可行的,推荐结果精度得到了较大程度的改善,冷门电影的推荐使多样性增加,且该方法在新用户冷启动和数据稀疏条件下也能比较灵活地实施推荐策略。但是,该算法在推荐用户数量增加到一定程度时准确度降低,且算法的时间和空间复杂程度还需要考虑,笔者将在今后的工作中对这些内容作进一步研究和探讨,不断优化推荐算法,改善算法执行性能。
参考文献:
[1]Lop sP, de Gemmis M, Semeraro G. Content-based recommender systems: State of the art and trends[M]//Recommender Systems Handbook. Springer US, 2011: 73-105.
[2]Schafer J B, Frankowski D, Herlocker J , et al. Collaborative filtering recommender system [M]// The adaptive web. Springer Berlin Heidelberg.2007:291-324.
[3]Burke, Robin. Knowledge based recommender systems.[J] Encyclopedia of library and information systems 69,no.supplement 32 (2000):175-186.
[4]Burke, R. Hybrid recommender systems: Survey and experiments. User Modeling and User-Adapted Interaction 12(4), 331-370 (2002).
[5]Liu Jianguo, Wang Binghong, Guo Qiang. Improved collaborative filtering algorithm via information transformation [J]. International Journal of Physics C, 2009,20(2):285-293.
[6]Zhang Yicheng, Blattner M. Heat conduction process on community networks as a recommendation model [J]. Physical Review Letters, 2007,99(15):154301.
[7]Zhou Tao, Ren Jie, MedoM, et al. Bipartite network projection and personal recommendation[J]. Physical Review E, 2007, 76(4): 046115.
[8]Papagelis M, Plexousakis D, Kutsuras T. Alleviating the sparsity problem of collaborative filtering using trust inferences[M]//Trust management. Springer Berlin Heidelberg, 2005: 224-239.
[9]Ma Hao, King I, Lyu MR. Learning to recommend with social trust ensemble[C]//Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval. ACM, 2009: 203-210.
[10]Jamali M, Ester M. Trustwalker: a random walk model for combining trust-based and item-based recommendation[C]//Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2009: 397-406.
[11]王茜,段雙艳.一种改进的基于二部图网络结构的推荐算法[J].计算机应用研究,2016,30(3):771-774.
[12]Adomavicius G, Tuzhilin A. Toward the Next Generation of Recommender Systems: ASurvey of the State-of-the-art and Possible Extensions[J]. IEEE Transactions on Knowledge and Data Engineering, 2005,17(6): 734-749.
[13]马骏康.基于改进协同过滤与二部图网络的加权混合推荐技术研究[D].华东师范大学,2013.
[14]张新猛,蒋盛益.基于加权二部图的个性化推荐算法[J]. 计算机应用,2012,32(03):654-657.
[15]REICHLING T, SCHUBERT K, WULF V. Matching Human Actors Based on Their Texts: Design and Evaluation of an Instance of the Expert Finding Framework[C]// Proceedings of GROUP, New York, 2005.
[16]Goldbaum D.Follow the leader: Simulations on a dynamic social network[EB/OL].[2011926].http://www.business.uts.edu.au/finance/research/wpapers/wp155.pdf.
[17]Donovan J O,Smyth B. Eliciting trust values from recommendation errors[C] //Proceedings of the 18th International Florid Artificial Intelligence Research Society Conference,Clearwater Beach: AAAI Press,2005: 289-294.
