基于情感距离和领域自适应的评论者声誉度
2017-07-07魏晓聪林鸿飞杨亮
魏晓聪, 林鸿飞, 杨亮
(1.大连理工大学 计算机科学与技术学院,辽宁 大连 116024; 2.大连外国语大学 软件学院,辽宁 大连 116044)
基于情感距离和领域自适应的评论者声誉度
魏晓聪1,2, 林鸿飞1, 杨亮1
(1.大连理工大学 计算机科学与技术学院,辽宁 大连 116024; 2.大连外国语大学 软件学院,辽宁 大连 116044)
为有效地从评论文本中评估消费评论者的声誉度,本文提出一种基于情感距离和领域自适应的评论者声誉度评估方法。通过度量待评估评论者发表的商品评论与该商品其他评论者的情感距离、情感倾向一致性,从而衡量该消费评论者在评价商品时的客观性以及与大众情感极性的一致性。最后,以亚马逊产品评论为实验语料,与亚马逊Reviewer ranking排序结果进行对比表明该方法的合理性。该方法对评论文本有效性研究以及规范电商平台消费者行为具有重要意义。
产品评论;声誉度;评论者;情感距离;情感倾向一致性;领域自适应
声誉是在商品交易过程中所形成的买卖双方的一种依赖关系,体现为赢得交易对方信任的能力。一个人的声誉越高,人们对他的信任程度就越高[1]。Sussman和Siegal指出消费者对信息的采纳来源于信息质量和信息源可信性两个因素[2]。郭国庆指出,评论者的资信度是影响评论信息感知可信度的重要因素之一[3]。随着电子商务和Web 2.0的迅速发展,越来越多的消费者需要从海量的、质量参差不齐的评论信息中获得真实可靠、值得信赖的消费者评论,从而降低信息搜索成本、快速做出购买决策。国外的电商平台—Amazon.com消费评论者声誉度评价机制Reviewer ranking主要考虑两个因素:1)其他消费者对该消费者所发表的全部评论的“有用”性投票数量;2)该消费评论者近期发布的产品评论数量。这种评价机制无法避免零投票导致的“有用”性投票机制失效问题,并且比较注重消费者近期发表的评论数量。国内的电商平台—淘宝网对于发布产品评论的消费者声誉度评估主要通过卖家对交易进行标记(好评、中评或差评)以及文字评价两种方式。然而,对交易进行标记是粗粒度的情感度量,无法有效的衡量卖家对消费者的情感。而且,为讨好消费评论者,通常情况下卖家都会给出好评。在文字评价上,由于卖家的日交易量很大,其没有精力针对每位消费评论者的交易一一给出客观的文字评价,通常都是统一的评价文本。在这种评价机制下,淘宝网的消费评论者诚信监管严重缺失。如果能够引入一种有效的、自动的消费评论者声誉度评估方法,那么卖家可以此为依据决定是否将自己的商品出售给声誉度低的消费评论者,其他用户可以此为参考决定是否根据该消费者的评论做出购买决策。这样,消费评论者在对商品做出评论时出于对失信的后果有所顾忌,会更倾向于给出真实、客观的评价。国内外现有的相关研究主要集中在消费者对卖家的信用评价机制上,对消费评论者信用评价方面,即消费评论者声誉度,邵婷等通过定性分析进行了讨论[4]。据了解,目前还没有相关工作从评论文本情感分析角度进行定量研究。本文借鉴文本情感分析相关研究成果,从定量客观的视角出发,将情感进行量化,以Amazon.com在线评论为例,同时考虑消费评论者与其他评论者对同一商品的情感距离、情感倾向一致性两个因素,提出一种基于情感距离和领域自适应的方法对消费评论者进行声誉度分析。
1 评论者声誉度分析
基于评论文本情感距离和领域自适应的评论者声誉度研究总体框架如图1所示。首先,根据给定消费评论者,在商品库中搜索该消费评论者评论过的商品。从商品评论库中将上述商品的该消费者评论和其他评论检索出来分别进行情感距离和情感极性一致性计算,最后根据上述两个分值进行消费者声誉度分析。
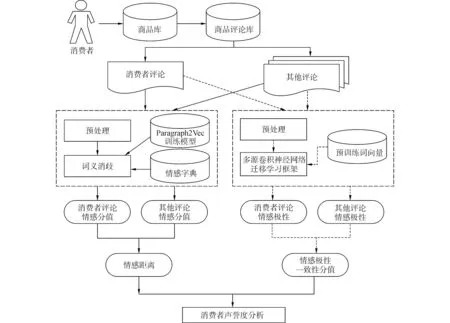
图1 消费者声誉度研究总体框架Fig.1 The architecture of consumer reputation research
1.1 情感距离计算
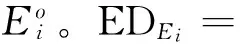
1.1.1 情感量化
SentiWordNet 3.0[6]是一个面向情感分类和观点挖掘应用的开源词典资源,它是在WordNet同义词集的基础上建立起来的。它为每个同义词集分配包含褒、贬、中性3个维度的打分,每个维度得分介于[0, 1.0],3个维度得分总和为1。对于情感词wi,可以通过SentiWordNet字典获得情感词在褒、贬、中性三个维度上的情感分值sen(wi)=(Poswi,Negwi,Objwi),从而量化每条评论的情感。
1.1.2 词义消歧
字典中存在着大量一词多义的情况,例如:“terrible”总共有四种词义。在SentiWordNet情感字典中,多义词可能具有不同的维度得分。当处理一条评论文本时需要对多义词进行词义消歧,确定其词义后在情感字典中找到对应的情感分值。例如“I was very hesitant to purchase this set due to the terrible reviews regarding the packaging”,其中的“terrible”需要确定是四种词义中的哪种词义,然后在SentiWordNet中查找对应词义的情感分值。
词义消歧是指根据多义词所处的上下文环境来确定词义。本文采取基于词典的Lesk[7]词义消歧算法。该算法认为:一个词在词典中的词义解释与该词所在句子具有相似性。如给定上下文“I was very hesitant to purchase this set due to the terrible reviews regarding the packaging”,指定歧义词“terrible”,Lesk算法给出的语义解释为“intensely or extremely bad or unpleasant in degree or quality”。
由于Lesk算法和SentiWordNet情感字典是基于同一英语词典WordNet,存在一部分词的解释(定义)描述是相同的。针对这部分词,只需根据Lesk算法给出的多义词解释在SentiWordNet中寻找相同解释的同义词集,并采用其对应的情感分值即可。因此,上述句子中“terrible”情感分值sen(“terrible”)=(0,0.875,0.125)。而对于描述不相同的解释,需要计算句子相似度找出最相似的解释(定义)。
1.1.3 句子相似度计算
在实验中,存在Lesk算法给出的歧义词解释在SentiWordNet情感字典中没有相匹配的解释。例如“I honestly believe the stories are the best stuff Tad′s written so far”中的歧义词“best”, Lesk算法给出的解释为“in a manner affording benefit or advantage”,但在SentiWordNet情感字典“best”的各种解释中没有与之相匹配的解释。这时,需要计算Lesk算法给出的解释与SentiWordNet字典“best”的各种解释的句子相似度,将相似度最大的解释对应的情感分值作为“best”的情感分值。
传统的句子相似度计算很多都是基于词袋模型(bag-of-words, BOW)的。但是,词袋模型会丢失词序信息并且忽略词的语义信息。n-gram词袋模型虽然可以通过窗口捕捉词序信息,但是其会产生高维稀疏问题。因此,需要一种句子的表示方法既可以保留上下文词序信息又可以捕捉到词语之间的语义信息,并且避免高维稀疏问题。Paragraph2Vec[8]算法是Le等2014年提出的。该算法是一种句子、段落和文档的连续分布式向量表示方法。它从可变长度的文本中,通过滑动的、固定大小的上下文窗口为每个句子、段落或文档学习一个稠密的向量表示。由于该算法可以从无标注数据中无监督的学习到这种向量表示,因此非常适合没有足够标注数据的训练任务。同时,该算法能够克服词袋模型的缺点,避免n-gram词袋模型的高维稀疏和推广能力差等问题。例如,在本实验,针对上述上下文中的“best”,SentiWordNet情感字典中与Lesk算法给出的解释句子相似度最大的同义词集语义解释为“in a most excellent way or manner”,因此该上下文中的“best”情感分值为sen(“best”)=(0.5,0,0.5)。
1.1.4 评论情感分值
将一条评论表示为P{wi|i∈n},其中wi为该条评论中的情感词,n为该评论包含的情感词数量,那么,该条评论的情感分值:
例如“I honestly believe the stories are the best stuff Tad′s written so far”,经过词义消歧后各情感词的情感分值如表1所示。经过计算,上述例句的情感分值E=(0.14,0.03,0.83)。
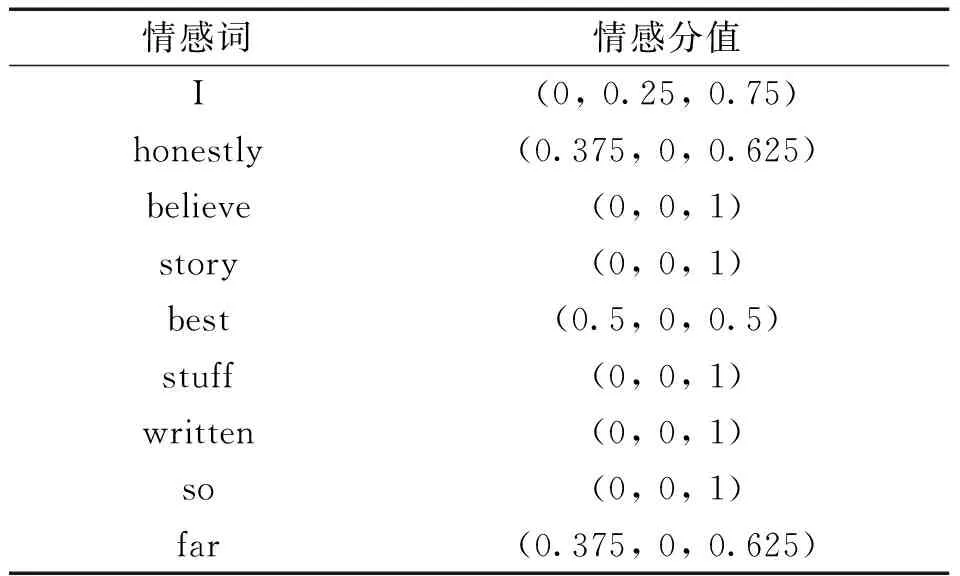
表1 各情感词情感分值
1.2 情感极性一致性计算
1.2.1 计算方法
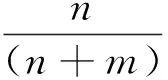
1.2.2 领域自适应情感极性自动识别方法
以Amazon.com上的评论为例,消费者在发表文字评论的同时会给该商品赋予一个打分,该打分范围为[1,5]。这些属于评论的弱标签。然而,有时消费者发表的评论与其给出的打分并不一致。为了弥补上述问题带来的不足并检测本文提出方法的有效性,本工作从挖掘评论文本情感的角度,利用Amazon网站已有的、大量的、带有弱标签的评论文本进行机器学习训练,用训练得到的模型去自动判断每条评论的情感极性。
然而,机器学习的一个重要假设:训练数据和测试数据必须在同一特征空间下并且分布相同。但是不同产品的评论很难保证这一点。目前,领域自适应学习解决的就是这些问题[9-11]。然而大量文献提出的领域自适应学习方法过度依赖于领域,而对于本文的任务,领域是随机的,领域的种类同商品种类一样,数量很大且不确定。前人的方法很难实施到本文的任务中。因此,需要训练一个在很多领域都能很好完成领域自适应学习任务、具有较强泛化能力的模型。
近年来文献表明,深度神经网络能够从源输入变量的所有因素中捕捉到具有一般性的因素,能够在不同领域之间自动的学习被不同领域共享的、对任务具有辨别力的特征表示,因此适合解决跨领域自适应学习问题。深度神经网络在文本领域已开展了少量的工作,如Xiao Ding等提出了一种基于卷积神经网络的领域自适应学习方法识别电影领域用户消费意图[12]。该工作验证了卷积神经网络在文本领域挖掘消费意图任务上的领域自适应学习能力。本文提出了一种基于卷积神经网络的多源领域自适应学习框架,该框架如图2所示。
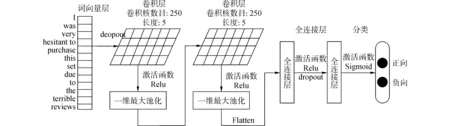
图2 基于卷积神经网络的多源领域自适应学习框架Fig.2 The architecture of multi-source domain adaptation based on convolutional neural network
层1:词向量层。构建一个字典,将各评论中的每个词用其对应的索引值表示并作为该层输入,对应的Word2Vec[13]训练的词向量初始化该层的权重。这样该层在进行训练时权重值会根据任务进行微调。接下来为了防止训练的模型过拟合,引入dropout机制。本层的输出作为下一层的输入。
层2:由一维卷积操作和一维最大池化操作组成。卷积操作将滑动窗口大小为n的文本区域转化为特征向量。向量m∈Rn是一个卷积核,也叫权重向量。大小为n的卷积核通过捕捉一个词的上下文特征从而学习内部特征表达。对于一个词向量vi,首先将词向量vi周围的n个词向量串联起来,然后通过卷积操作与权重向量m∈Rn进行点乘。
fi=mTvj-n+1:j
(1)
最后进行激活函数计算:
O=σ(fj+b)
(2)
式中:σ为非线性激活函数,b∈Rn为偏置向量。在同一层,m∈Rn和b∈Rn权值共享,它们通过训练学习得到。然后应用一个一维最大池化操作来捕捉对本任务有用的局部特征。本层的输出作为下一层的输入。
层3:层3的结构与层2相同,也是由一个一维卷积操作和一个最大池化操作组成。层3的输出经过Flatten函数“压平”,即把多维的输入一维化从而作为下一层的输入。
层4:该层为全连接层,其输出作为下一层的输入。
层5:该层为全连接层,最后进行情感极性二元分类。
2 实验与结果分析
2.1 实验数据集
本文实验语料采用McAuley等[14]收集的Amazon产品评论语料。该语料包含了消费评论者的商品信息及打分。打分范围介于[1,5]。其中1分为最低分,5分为最高分。从上述语料中随机抽取5位评论者,这些评论者评价产品次数需满足大于等于5次,语料统计如表2所示。
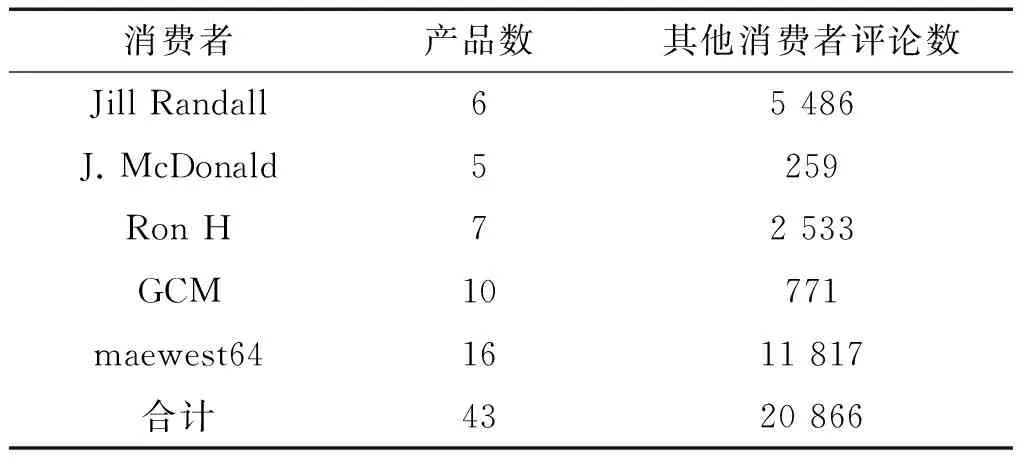
表2 语料统计表
2.2 Paragraph2Vec模型训练
将SentiWordNet情感字典中所有同义词集的解释及例句共114 076个句子,以及2.1实验数据集中的每个歧义词的Lesk算法给出的解释,共同作为Paragraph2Vec模型训练语料。经过实验选择训练模型最优参数组合为特征向量维数300维、预测词与上下文单词最大距离为8、保留低频词汇,其余参数如表3所示。采用gensim工具包[15]实现的Paragraph2Vec算法。
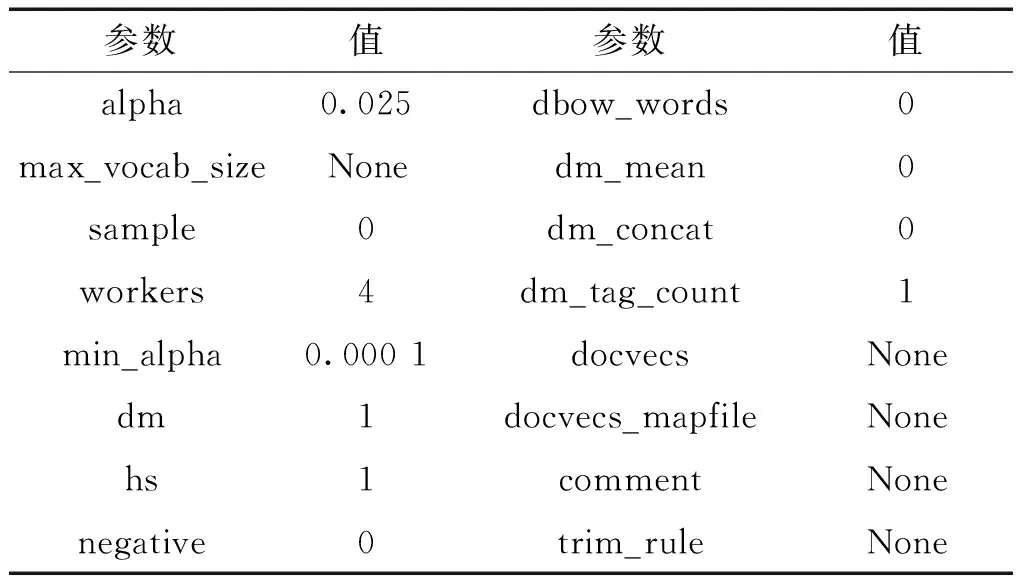
表3 Paragraph2Vec模型训练参数
2.3 领域自适应情感极性自动识别实验
2.3.1 词向量训练
本文从McAuley等[14]收集的Amazon产品评论语料中抽取了2014年Books, Movies & TV, Electronics 和 Home & Kitchen 四个领域的所有评论作为Word2Vec训练语料。该语料包含696万条产品评论、38 600万个单词。将语料中的单词全部变换为小写并去除标点符号之后进行Word2Vec词向量训练,词向量维数为300维。
2.3.2 多源领域自适应学习的情感极性自动识别
为了验证本文提出的深度神经网络领域自适应学习框架在跨领域产品评论情感分类上的有效性,本文进行如下实验。本文从McAuley等[14]收集的Amazon产品评论语料中抽取了2014年Books(B)、Movies & TV(D)、Electronics(E) 和 Home & Kitchen(K) 四个领域的所有评论(不包含2.1中的评论),去除中性评论(打分为0)。与文献[16]相同,将每条评论的用户打分作为该条评论的情感极性标签,打分为1分、2分的认为其情感极性为负向,打分为4分、5分的为正向。对语料进行预处理,去除标点符号、将每个单词转化为小写形式。分别从上述四个领域中抽取1万条正向评论和1万条负向评论。将其中三个领域作为源领域,余下的一个领域作为目标领域进行实验,例如:将Books(B)、Movies & TV(D)、Electronics(E)三个领域共6万条语料作为源领域训练语料,对本文提出的领域自适应学习框架进行模型训练,训练后的模型对Home & Kitchen(K)领域进行预测,此任务表示为BDE→K。由此,构建了四组领域自适应学习任务BDE→K、BDK→E、BEK→D、DEK→B。本文的实验评价标准为准确率。在对多源领域进行训练时,训练集为5.4万,验证集为0.6万。由于卷积神经网络要求输入序列为固定长度,因此本实验将每条评论组织为长度为100个单词。若原评论长度超过100个单词则截断,不足100个单词时则将不足部分填充数字0。训练神经网络时batch size设置为128,卷积核数量为250,卷积核窗口大小为5,卷积层边界模式为same,激活函数为relu,最大池化长度为2,所有dropout都为0.1。第一个全连接层激活函数为relu,隐层单元数为250。第二个全连接层激活函数为sigmoid,隐层单元数为1。一共训练15轮。每轮训练都对数据重新shuffle。损失函数为binary cross-entropy,测试性能取决于最后一轮验证准确率,实验结果如图3所示。实验表明本文提出的多源领域自适应情感极性自动识别学习框架在四个任务都能很好的完成分类,平均准确率达到了89.75%。该框架能够从多个不同且相关的源领域自动学习对分类任务有用的特征,无需手工构造特征,模型可以广泛的用来预测各种领域的商品评论情感极性,比较适合本文的任务。因此,本文采取该领域自适应学习框架进行2.1实验语料的情感极性自动识别。情感极性一致性分值计算方法如1.2.1节所示。
2.4 声誉度计算及结果分析
2.4.1 声誉度计算
每位消费评论者对其发表的商品评论与大众的平均情感距离Ave(EDEi)、平均情感极性一致性分值Ave(PolarityScorePi)如表4第2、3列所示。可以看出,情感距离与情感倾向性分值并没有在同一个数据范围。情感距离分值范围介于[0.004 9,0.035 0],情感倾向性分值介于[0.314 8,1]。为了便于计算,采取与文献[17]相同的方法将情感距离分值取值范围按比例增加到和情感倾向性分值相同范围,计算方法为
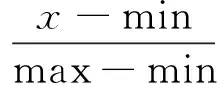
(3)
式中:min和max为x的原始最小值和最大值,minnew和maxnew为新的最小值和最大值。f(x)函数将x由原始的取值范围按比例增加到新的取值范围minnew和maxnew中。例如,按比例增加到新的取值范围之后,消费者Ron H的情感距离为
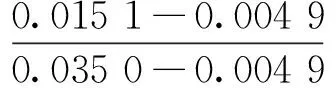
所有评论情感距离按比例增加后的结果如表4第4列所示。声誉度得分Score计算方法如下:
Score=αAve(EDEi)+
(1-α)Ave(PolarityScorePi)
(4)
分数越高代表声誉度越高。其中α∈(0,1)为平衡Ave(EDEi)和Ave(PolarityScorePi的调解因子。本文邀请一些专家对α的经验值进行讨论,最后给出α经验值为0.4。最终声誉度排名如表4第五列所示。表4中第6列列出了亚马逊Reviewer ranking给出的排名,如:消费者评论者GCM在Amazon.com网站上排名为第627 765名。第7列为其他用户认为该消费者所发表的评论有用的票数以及总投票数,第8列为该消费者第一次发表评论的时间。
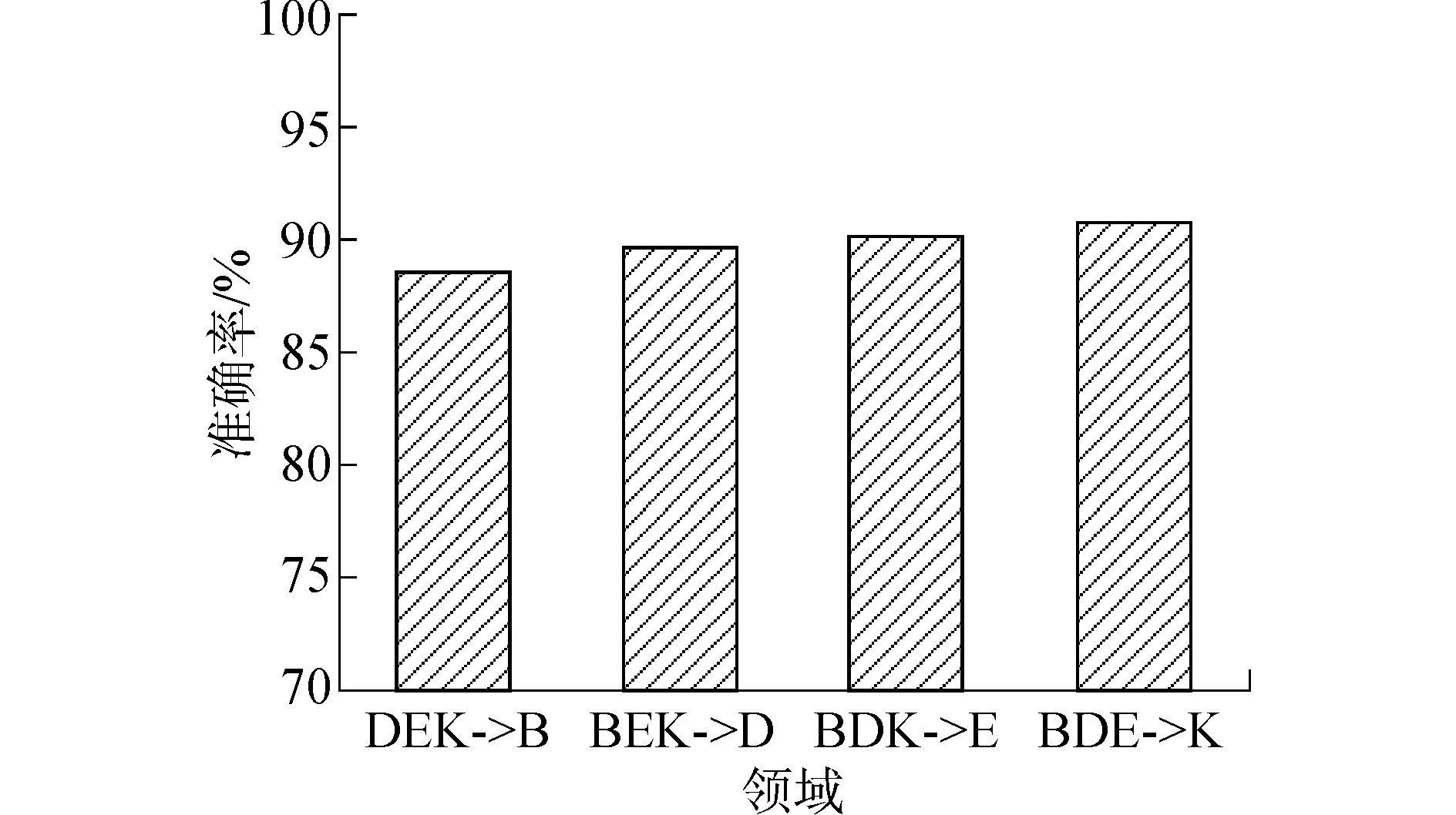
图3 多源领域自适应学习的情感极性自动识别实验结果Fig.3 Results of sentiment polarity recognition based on multi-source domain adaptation
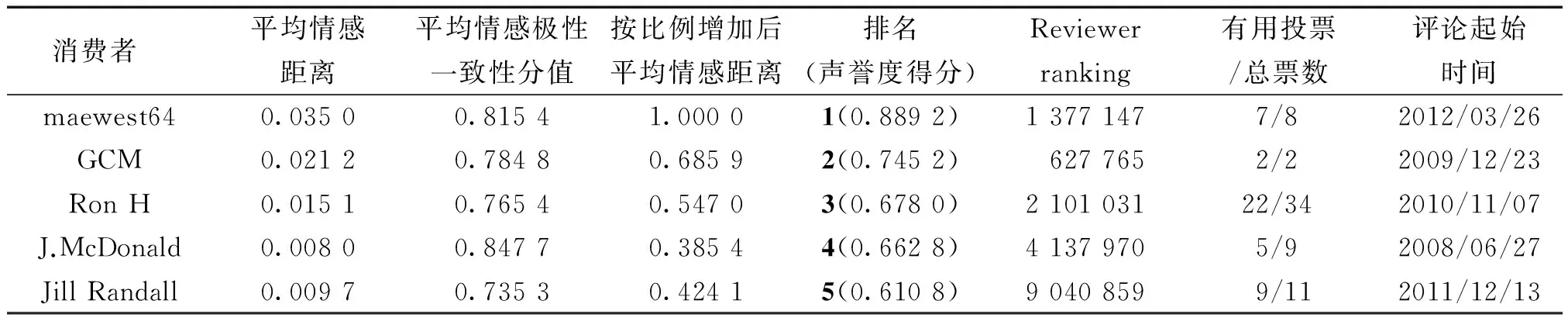
表4 情感距离、情感倾向一致性分值及声誉度排名对比
2.4.2 结果分析
从表4可以看出,排名为第2~5名的消费者排列顺序与Reviewer ranking的排名相一致,这说明本文提出的方法具有一定的合理性。但是本文排名第1名的消费者maewest64和排名第2名的消费者GCM排名顺序与Reviewer ranking不一致。从第一条评论发表时间来看,maewest64晚于其他消费者,而且maewest64发表的其余15条评论全部集中在2013年和2014年。而Reviewer ranking排序机制考虑的因素之一为其他消费者对该消费者所发表的全部评论的“有用”性投票数量,考虑到评论的累积性,越是近期发表的评论得到关注的几率越小,越容易出现零投票现象。因此,在Reviewer ranking中maewest64排名落后于GCM。而本文提出的声誉度排序方法是从情感距离和情感极性一致性角度出发,不依赖于其他用户给出的有用性投票,因此能够避免零投票现象带来的机制失效所导致的排序不稳定问题。
从消费者maewest64和GCM已有的“有用投票/总票数”来看,这两位消费者发表的评论几乎所有参与投票用户都认为是有用的,这也说明这两位消费者发表的评论得到了几乎所有参与投票者的认可,他们的评论质量、客观性也一定比较高,因此在本文提出的声誉度排序中名次靠前。另外,由于经验丰富的消费者其评价更为客观,而经验较少的消费者,常常对商品充满幻想,当商品与想象存在落差,会给出一些极端的评论。这两位消费者在Amazon.com上购买并评价过的商品数量皆多于其他消费者,购物经验较之其他消费者更丰富,这也可能致使他们在评价产品时更客观,因此声誉度排名更高。以上两方面分析这也验证了认同理论,高级别发帖者在发布平台中的行为更积极,主要体现于发布更多、准确性更高的信息。
3 结论
1)本文根据消费者对所购买商品的情感与大众越一致,其评价方式越客观,可信度越大,声誉度越高这一常识,采用自然语言处理技术和文本领域自适应技术量化情感,衡量待评估声誉度消费者与大众对同一产品的情感距离以及情感极性一致性,进行了评论者声誉度方法研究。
2)实验结果表明,该方法与亚马逊Reviewer ranking排名大体相一致,具有一定的合理性。而该方法不依赖其他用户给出的有用性投票,可以有效避免零投票导致的声誉度评估失效问题。
3)本文提出的方法为评论信息质量研究、评论文本有效性研究以及改善电商平台信用评价机制提供了定量分析的新思路。
下一步工作会考虑加入更多声誉度相关特征,如评论者是否实名等,从而进一步提高声誉度分析的评估能力。
[1]杨晓梅.基于C2C电子商务网站的声誉评价机制研究[J]. 山西大学学报:哲学社会科学版, 2009(2): 116-120.
YANG Xiaomei.Research on the reputation mechanism of the C2C-based E-commerce sites[J]. Journal of Shanxi University: Philosophy & Social Science, 2009(2): 116-120.
[2]SUSSMAN S W, SIEGAL W S. Informational influence in organizations: an integrated approach to knowledge adoption[J]. Information systems research, 2003, 14(1): 47-65.
[3]郭国庆,陈凯,何飞.消费者在线评论可信度的影响因素研究[J]. 当代经济管理, 2010, 10: 17-23.
GUO Guoqing, CHEN Kai, HE Fei.An empirical study on the influence of perceived credibility of online consumer reviews[J]. Contemporary economy & management, 2010, 10: 17-23.
[4]邵婷,林建宗.B2C平台买家诚信约束机制探析[J]. 厦门理工学院学报, 2013, 04: 83-86.
SHAO Ting, LIN Jianzong.Buyers′ trust constraint on B2C platform: a case study on Tmall[J]. Journal of Xiamen University of Technology, 2013, 04: 83-86.
[5]孟摇欢.大众传播心理距离的嬗变[D].长春:吉林大学, 2011: 7-8.
MENG Yaohuan.Evolution of psychological distance in mass communication[D]. Changchun: Jilin University, 2011: 7-8.
[6]BACCIANELLA S, ESULI A, SEBASTIANI F. SentiWordNet 3.0: an enhanced lexical resource for sentiment analysis and opinion mining[C]//Proceeding of the 7thInternational Conference on Language Resources and Evaluation, Malta, 2010(10): 2200-2204.
[7]LESK M. Automatic sense disambiguation using machine readable dictionaries: how to tell a pine cone from an ice cream cone[C]//Proceeding of the 5thAnnual International Conference on Systems Documentation, Canada, 1986: 24-26.
[8]LE Q V, MIKOLOV T. Distributed representations of sentences and documents[C]//Proceeding of the 31thInternational Conference on Machine Learning, China, 2014(14): 1188-1196.
[9]BLITZER J, Mcdonald R, PEREIRA F. Domain adaptation with structural correspondence learning[C]//Proceeding of the 2006 Conference on Empirical Methods in Natural Language Processing, Australia, 2006: 120-128.
[10]PAN S J, NI X, SUN J T, et al. Cross-domain sentiment classification via spectral feature alignment[C]//Proceeding of the 19thInternational Conference on World Wide Web, USA, 2010: 751-760.
[11]PAN J, HU X, LI P, et al. Domain adaptation via multi-layer transfer learning[J]. Neurocomputing, 2016, 190: 10-24.
[12]DING X, LIU T, DUAN J, et al. Mining user consumption intention from social media using domain adaptive convolutional neural network[C]//Proceeding of the 29thAAAI Conference on Artificial Intelligence, USA, 2015: 2389-2395.
[13]MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[C]//Proceeding of Advances in Neural Information Processing Systems, USA, 2013: 3111-3119.
[14]MCAULEY J, PANDEY R, LESKOVEC J. Inferring networks of substitutable and complementary products[C]//Proceeding of the 21thACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Australia, 2015: 785-794.
[15]REHUREK R, SOJKA P. Software framework for topic modeling with large corpora[C]//Proceeding of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Malta, 2010: 45-50.
[16]KOTZIAS D, DENIL M, De FREITAS N, et al. From group to individual labels using deep features[C]//Proceeding of the 21thACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Australia, 2015: 597-606.
[17]HU N, KOH N, REDDY S. Rating lead you to the product, reviews help you clinch it? the mediating role of online review sentiments on product sales[J]. Decision support system, 2014, 57: 42-53.
本文引用格式:
魏晓聪,林鸿飞,杨亮. 基于情感距离和领域自适应的评论者声誉度[J]. 哈尔滨工程大学学报, 2017, 38(6): 907-913.
WEI Xiaocong, LIN Hongfei, YANG Liang. Reviewer reputation based on emotion distance and self-adaption[J]. Journal of Harbin Engineering University, 2017, 38(6): 903-917.
Reviewer reputation based on emotion distance and self-adaption
WEI Xiaocong1,2, LIN Hongfei1, YANG Liang1
(1.School of Computer Science and Technology, Dalian University of Technology, Dalian 116024, China; 2.School of Software Engineering, Dalian University of Foreign Languages, Dalian 116044, China)
In order to evaluate a reviewer′s reputation effectively from his or her written reviews, we propose a method for evaluating reviewer reputation based on emotional distance and domain self-adaption. By calculating the emotional distance and the consistency of emotional tendency between the reviews written by the target reviewer and those by other reviewers, the review objectivity and the emotional consistency between the target reviewer and the public are measured. Finally, by using product reviews on Amazon.com as the experimental data, we compare the results of the proposed method with the sequencing results of the Amazon Reviewer ranking to show the rationality of the method. The proposed method would be of great significance to research on text effectiveness and regularizing the behavior of consumers on e-commerce platforms.
product review; reputation; reviewer; emotion distance; sentiment orientation consistency; domain self-adaption
2016-04-26. 网络出版日期:2017-03-30.
国家自然科学基金项目(61572102,61562080); 大连外国语大学科研基金项目(2014XJQN14).
魏晓聪(1982-), 女, 讲师,博士研究生; 林鸿飞(1962-), 男, 教授,博士生导师.
魏晓聪,E-mail:weixiaocong@dlufl.edu.cn.
10.11990/jheu.201604078
http://www.cnki.net/kcms/detail/23.1390.u.20170330.1503.022.html
TP391
A
1006-7043(2017)06-0907-07
