基于Kinect 3D节点的连续HMM手语识别
2017-07-07沈娟,王硕,郭丹
沈 娟, 王 硕, 郭 丹
(1.安徽新华学院 信息工程学院,安徽 合肥 230088; 2.合肥工业大学 计算机与信息学院,安徽 合肥 230009)
基于Kinect 3D节点的连续HMM手语识别
沈 娟1,2, 王 硕2, 郭 丹2
(1.安徽新华学院 信息工程学院,安徽 合肥 230088; 2.合肥工业大学 计算机与信息学院,安徽 合肥 230009)
文章提出了一种基于Kinect 3D节点的连续隐马尔科夫模型(hidden Markov model,HMM)手语识别方法。首先对Kinect 3D节点三维坐标采用距离换算的方法获取其骨架特征表达,转换后的特征维度减少为原来节点特征的2/3,降低了计算过程中的存储开销;再针对人体体型大小所带来的差异,设置最小-最大归一法及最大值归一化方法;在此基础上,为强化骨架特征变化的特征表达,文章进而提出了用来捕获对骨架动态变化度量的相对归一化法;最后,在最终所获得的骨架特征表达上,构建基于高斯混合的隐马尔科夫模型(hidden Markov model with Gaussian mixture models,GMM-HMM)进行手势识别。实验证明采用相对归一法能够消除原3D节点中坐标漂移、体型各异、动态手势变化导致难以表达的弊端,实现了有效的骨架特征表达,并在识别精度上有了较好的提升。
Kinect传感器;3D节点;归一化;手语识别;隐马尔科夫模型(HMM)
利用手语识别缓解与聋哑人沟通的阻力已成为近年来模式识别领域里学者们研究的热点。手语识别的本质是一个对连续动作信息的捕捉与识别的过程。目前对连续手语信息的获取主要有以下几种方式:① 用特质的手套传感[1]器获取手势位置及手指变化信息,该设备能够准确捕捉手型及手指的变化,但设备昂贵且佩戴不方便;② 可以通过让手语使用者佩戴速度传感器[2],并利用接收装置对速度传感器的运动轨迹、方向及速度等数据进行捕捉与处理,同样该方法对佩戴设备要求高,使用起来仍不方便;③ 采用微软公司的Kinect传感器[3-4],该传感器不再需要手语演示者佩戴任何设备,即可使用Kinect传感器同时采集视频完整的彩色信息、深度信息以及所标注关节点的坐标信息[5]。该设备使用简单,采集的信息多样化,因此也被越来越多地使用。
早期的研究中,研究者采用SVM算法对手语进行分类识别[6-7]。虽然该方法针对静态手语有一定的效果,但是对连续手语的信息不容易捕获和训练。DTW方法的提出能够处理连续变化信息[8-9]。该方法采用计算2个连续序列间距离的方式,在训练集空间中进行搜索,将找到最相近的样本的类别作为识别类别输出。该方法计算时间复杂,受限于训练集的规模大小和序列长度,尤其是训练集规模过大的情况,并不适合于真实世界里的应用。随后,基于隐马尔科夫模型 (hidden Markov model,HMM)对连续性信息进行内在隐状态的关联信息建模[10-11]。模型训练完成后,运算时间快且识别精度仅取决于模型内在隐状态的参数。HMM模型可以分为离散型HMM[12]与连续型HMM[11]。其中,离散HMM的每一个状态都是离散分布的;相反,连续HMM引入概率模型描述连续变化过程。HMM在语音识别等[13-14]应用领域取得了令人瞩目的成就。
除了各类研究方法的提出,在手语识别中,特征抽取与表达也起到了关键的作用。在视觉特征的表达上,早期较为普遍的是采用文献[15]中使用HOG特征,用于提取整幅图像或者局部区域(例如手部)的梯度信息。文献[16]使用基于运动变化的光流特征[17],来获取两帧之间的视觉差异,记录动态变化信息的演变。该方法容易受到光照等因素的影响,如采集视频的环境不理想或抖动过快等外在因素,可能导致视频本身光流信息提取的不准确。因此,由于Kinect产品的特质,能够准确获取人体关节的位置信息,更多的研究者采用了关节点坐标信息作为特征[10-11,18]。该特征处理简单,耗费时间短,占用存储资源小,不容易受到外在环境因素的影响。在识别精度上,节点信息较一般视觉特征能保持稍高的稳定性。
本文采用Kinect 获取的3D节点连续坐标信息,基于高斯混合的隐马尔科夫模型(hidden Markov model with Gaussian mixture models,GMM-HMM)进行连续手语序列信息的识别,模型结构如图1所示。
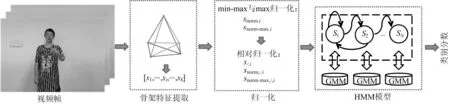
图1 基于Kinect 3D节点的连续HMM模型
1 GMM-HMM模型
本文采用基于高斯混合模型(GMM)的连续隐马尔科夫模型(HMM):λ=(N,M,A,B,π),其中,N为HMM隐状态的个数;M为GMM中高斯核函数的个数;A为状态转移概率矩阵;B为隐状态的输出概率密度参数;π为状态分布。
1.1GMM模型
GMM通过引入概率模型,利用多个高斯模型进行混合叠加拟合出连续信号。GMM模型如图2所示,图2中实线表示连续信号,虚线分别表示对应不同均值和方差的高斯函数,混合GMM的概率密度函数p(x)为:
(1)

GMM在本文HMM模型中的意义是描述在所有训练集中各帧在各个隐状态下GMM的聚类分布,服从正态分布。本文设置GMM的经典参数为M=3。
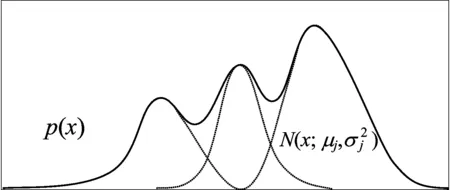
图2 GMM模型
1.2 HMM模型
HMM模型是用来描述其N个隐状态S={S1,S2,…,SN}之间相互转移过程的模型。它能够用来描述连续手语随时间维度推进,一直沿着隐状态转移概率最大的方向演变的过程。该模型中,状态转移概率矩阵A={an,n′},1≤n≤N,其中an,n′为Sn′到状态Sn′的转移概率;隐状态的输出概率参数记为B={bn,m},1≤m≤M,其中bn,m为状态Sn下的第m个高斯函数的概率密度,bn,m可以表示为:
(2)
本文使用Viterbi算法[19]对HMM模型进行训练,利用已知的观察序列和状态间的转移概率,结合前一个状态计算出最可能的状态转移路径,从而实现最优隐藏状态序列求解以及HMM模型参数的优化。本文设置的HMM经典状态个数参数N=3。
2 算法介绍
2.1 骨架特征提取
手语的语义表达主要由手型变换、手以及胳膊位置变换得到。本文数据集是由Kinect采集的节点位置信息,每帧采集多个关节部位的节点。手语运动集中在上半身,因此选用头部、左手、左肘、右手、右肘5个节点的3D坐标di,j(di,j,x,di,j,y,di,j,z)作为原始坐标特征,其中,i表示视频中第i帧;di,j,x、di,j,y、di,j,z分别表示第i帧第j节点在图像平面上轴x、y以及三维深度坐标,1≤i≤K,1≤j≤5,K为视频帧数。
2.2 骨架特征归一化
在数据的采集过程中,由于Kinect采集设备自身的原因,会导致节点漂移,例如头部信息可能并没有动,在前后两帧间会出现位置偏差。因此,本文首先对坐标位置的信息进行变换,采用文献[10]中方法提取每帧内各骨架点间相对距离以适用于获取其稳定的动态变化。即如图1所示,通过5个节点之间的相对距离,得到每帧10-dim的骨架特征si为:
(3)
因此,得到整个视频的骨架特征s=[s1,…,si,…,sK]。
因人体体型各异导致节点距离的大小各异。为了避免因体型大小各异带来的骨架特征不统一的现象,本文提出如下几种归一化方法。
(1)snorm,i计算。归一化的好处在于可以消除量纲的影响,将不同的数据统一到一个参考系之下,间接地缓解了体型带来的骨架特征不统一的影响。本文首先定义了一种常规的归一化方法,如(4)式所示。将骨架特征si映射到一个取值与[0,1]的标准向量上去。
(4)
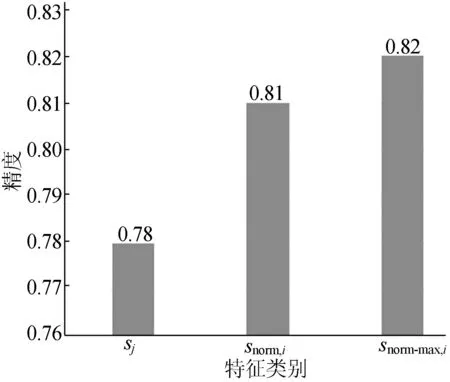
(2)snorm-max,i计算。考虑手语演示者骨骼大小的特殊性,本文又提出了一种基于骨架大小度量的归一化方法,如(5)式所示。该方法以si中最大值为标准,将骨架特征映射到(0,1]。由于si反映的是骨架距离函数,方法snorm,i中最小值为0并不合理,snorm-max,i的提出消除了此弊端。
(5)
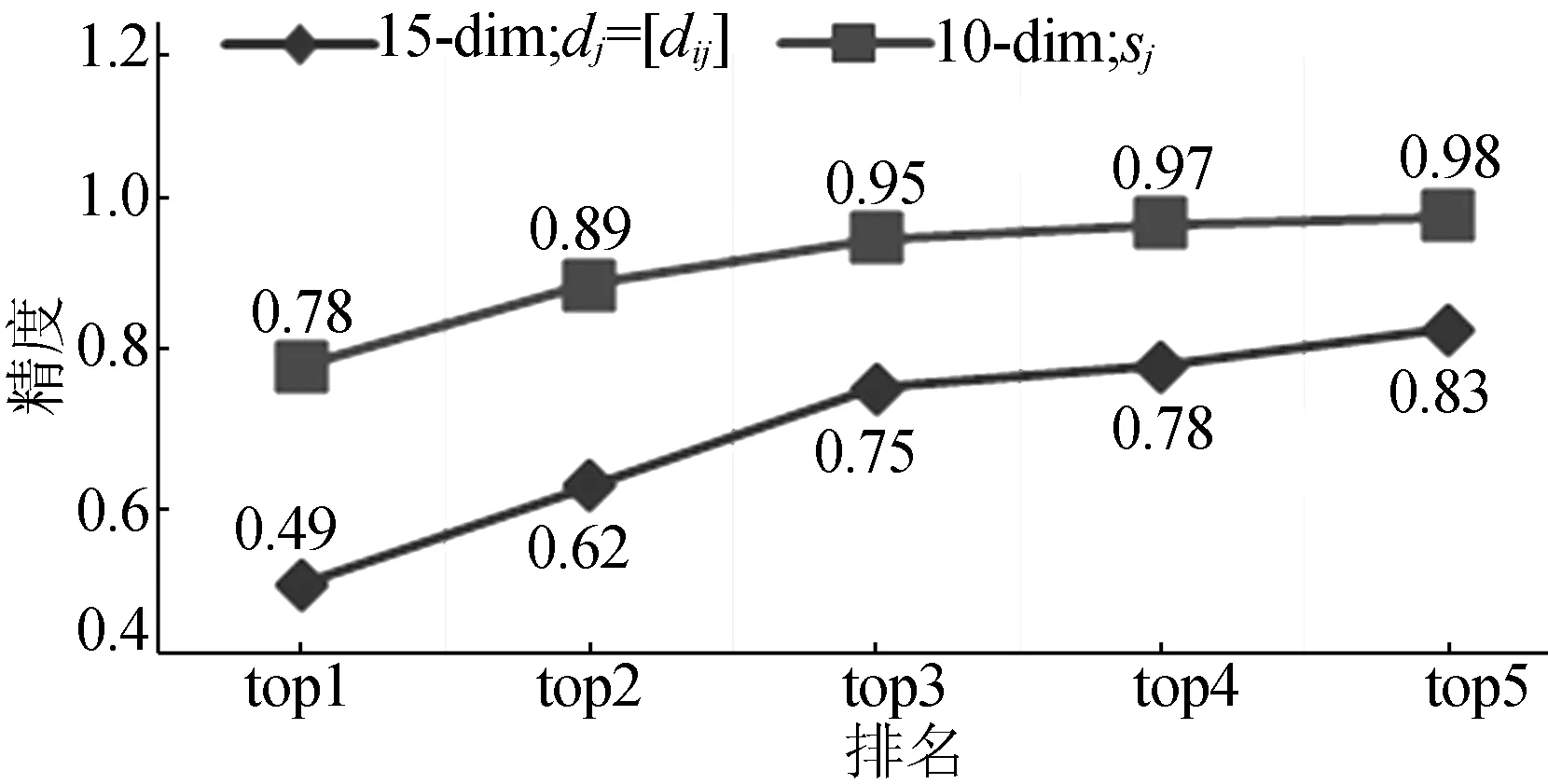
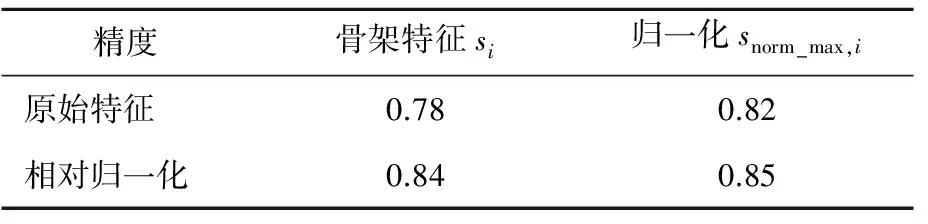
(3) 相对归一化计算。为了进一步更准确地表达相对变化,本文还在snorm,i或snorm-max,i的基础上提出了相对归一化的方法,以视频中第1帧数据作为标准帧,将其他每帧对应除以该标准帧,量化其他帧的相对变化,如(6)式所示,(6)式中,1 (6) 2.3 算法伪码 本文算法分为如下2个部分:① 利用Viterbi算法[19]对训练数据集学习生成HMM模型,对每个手语单词而言,建立一个HMM模型,1≤h≤H,H为手语单词的词汇量大小;② 利用已构建的各个HMM模型{λ1,λ2,…,λH}来计算新的手语序列V的概率,判断概率最大的 HMM模型λ*所对应的手语单词为识别类型。λ*为: (7) 其中,P(λ|V)为手语序列V由当前模型λ所求得的概率得分。 算法:HMM模型训练。 输入:H个手势下各自训练集{video-seth,1≤h≤H}。 输出:H个GMM-HMM模型。 for each video vid in video-seth: for each framefiin vid: 提取骨架特征si; min-max归一化采用(4)式;//snorm,i or max归一化采用(5)式;//snorm-max,i 相对归一化采用(6)式; //s/,iors/,norm,i //ors/,norm-max,i 将归一化后特征序列存至当前vid的vid-s end for 依次保存各vid的特征序列s-seth={vid-s} end for for signh: 输入signh下训练集骨架特征集合s-seth,用Viterbi算法训练GMM-HMM模型: λh=(N,M,Ah,Bh,πn)|s-seth, 其中,HMM中第n个(1≤n≤N)隐状态的GMM中高斯函数概率函数为: end for 3.1 实验数据 本文数据集为30个手语单词,每个手语单词分别由50个人演示,一共1 500个视频。数据集及其划分见表1所列。 表1 数据集及其划分 3.2 实验分析 3.2.1 原节点特征与骨架特征 节点特征与骨架特征的精度比较如图3所示,骨架特征较节点特征维度减少为原来的2/3,且骨架特征在top1上得到的精度比节点特征高出29%;给定前5个查询的情况下,利用骨架特征已能给出一个准确结果。结果表明骨架特征si优于利用原始的节点特征,原因在于减轻了节点飘移、节点抖动等误差。 图3 节点特征与骨架特征的精度比较 3.2.2 归一化对比 对骨架特征进行归一化改进的实验结果如图4所示,由图4可看出,改进后有相对3%~4%的提高。表明针对骨架的归一化是有效的,不同的归一化方法本质上都对骨架数据做了变换,利用归一化消除了手语者体型各异的不一致性。snorm-max,i比snorm,i较优在于其避免了snorm,i中相比距离的特征表达最小值为0的不合理性。 图4 2种归一化方法的比较 3.2.3 相对归一化分析 此处选取了骨架特征si及上述归一化较好的snorm-max,i,进而验证相对归一化法。实验结果表明仅利用骨架特征si加相对归一化就能将精度提升6%;如果基于归一化snorm-max,i再次执行相对归一化,也能将精度提升3%。这说明相对归一化可以独立于常规归一化方法就能起到有效作用,进而也说明相对归一化对保留特征的动态信息上较常规归一化方法更有优势。基于snorm-max,i的相对归一化使检测效果达到最优,比原始的节点特征提升了36%,见表2所列。 表2 相对归一化对比实验结果 本文针对手势节点坐标的特性,提出基于距离换算的相对归一化的有效骨架特征表达,进而基于GMM-HMM实现了手势识别。文中所使用的距离归一化方法提高了检测的精度,降低了特征表达的维度。本文基于特征的相对归一化方法对类似连续时序信息的学习也同样适用。今后的工作将引入手势的视觉特征展开研究。 [1] HURLOCK T,MURPHY W,RUDDER R.Safety glove:U.S.Patent Application 14/139,794[P].2013-12-23. [2] 谢仁强,曹俊诚.基于加速度传感器的可扩展手势识别[J].传感技术学报,2016,29(5):659-664. [3] HAN J,SHAO L,XU D,et al.Enhanced computer vision with microsoft kinect sensor:a review[J].IEEE Transactions on Cybernetics,2013,43(5):1318-1334. [4] REN Z,YUAN J,MENG J,et al.Robust part-based hand gesture recognition using kinect sensor[J].IEEE Transactions on Multimedia,2013,15(5):1110-1120. [5] XIAO Z,MENGYIN F,YI Y,et al.3D human postures recognition using kinect[C]//2012 4th International Conference on.Intelligent Human-Machine Systems and Cybernetics (IHMSC).[S.l.]:IEEE,2012:344-347. [6] RASHID O,AL-HAMADI A,MICHAELIS B.Utilizing invariant descriptors for finger spelling american sign language using svm[C]//International Symposium on Visual Computing Berlin Heidelberg:Springer,2010:253-263. [7] CHARLES J,PFISTER T,EVERINGHAM M,et al.Automatic and efficient human pose estimation for sign language videos[J].International Journal of Computer Vision,2014,110(1):70-90. [8] JANGYODSUK P,CONLY C,ATHITSOS V.Sign language recognition using dynamic time warping and hand shape distance based on histogram of oriented gradient features[C]//Proceedings of the 7th International Conference on PErvasive Technologies Related to Assistive Environments.[S.l.]:ACM,2014:50. [9] WANG H J,CHAI X J,CHEN X L.Sparse observation (so) alignment for sign language recognition[J].Neurocomputing,2016,175:674-685. [10] WANG H J,CHAI X J,ZHOU Y,et al.Fast sign language recognition benefited from low rank approximation[C]//2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG).[S.l.]:IEEE,2015:1-6. [11] GUO D,ZHOU W G,WANG M,et al.Sign language recognition based on adaptive HMMS with data augmentation[C]//2016 IEEE International Conference on Image Processing (ICIP).[S.l.]:IEEE,2016:2876-2880. [12] CHERIFA S,MESSAOUD R,NARIMA Z,et al.Performance study of vector quantization methods (k-means,GMM) for arabic isolated word recognition system based on DHMM[C]//2013 World Congress on Computer and Information Technology (WCCIT).[S.l.]:IEEE,2013:1-4. [13] PERCYBROOKS W,MOORE E,MCMILLAN C.Phoneme independent hmm voice conversion[C]//2013 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP).[S.l.]:IEEE,2013:6925-6929. [14] NAKAMURA K,OURA K,NANKAKU Y,et al.HMM-based singing voice synthesis and its application to Japanese and English[C]//2014 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP).[S.l.]:IEEE,2014:265-269. [15] 陈小柏.基于视觉的连续手语识别系统的研究[D].上海:东华大学,2014. [16] DONAHUE J,ANNE HENDRICKS L,GUADARRAMA S,et al.Long-term recurrent convolutional networks for visual recognition and description[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.New York:IEEE Computer Society,2015:2625-2634. [17] WEINZAEPFEL P,REVAUD J,HARCHAOUI Z,et al.Deepflow:large displacement optical flow with deep matching[C]//Proceedings of the IEEE International Conference on Computer Vision.[S.l.]:IEEE,2013:1385-1392. [18] LIU T,ZHOU W,LI H.Sign language recognition with long short-term memory[C]//2016 IEEE International Conference on Image Processing (ICIP).[S.l.]:IEEE,2016:2871-2875. [19] MAGNUSSON K E G,JALDEN J,GILBERT P M,et al.Global linking of cell tracks using the viterbi algorithm[J].IEEE Transactions on Medical Imaging,2015,34(4):911-929. (责任编辑 张 镅) Continuous HMM based on Kinect 3D joint nodes for sign language recognition SHEN Juan1,2, WANG Shuo2, GUO Dan2 (1.School of Information Engineering, Anhui Xinhua University, Hefei 230088, China; 2.School of Computer and Information, Hefei University of Technology, Hefei 230009, China) This paper presents a continuous hidden Markov model(HMM) method based on Kinect 3D joint nodes for sign language recognition. Firstly, the skeleton feature of each frame is obtained by distance calculation among five Kinect joint nodes, namely head, left elbow, right elbow, left hand and right hand. The dimension of skeleton feature is reduced to 2/3 of the original coordinate feature, and the storage cost is also reduced. Then the minimum-maximum and the maximum normalization methods are used to eliminate the diversity of different signers’ shape and habitus. In order to capture dynamics among skeleton gestures in a video, a relative normalization approach on above normalized skeleton feature is proposed. Finally, the hidden Markov model with Gaussian mixture models(GMM-HMM) based on above normalization approaches on skeleton features for sign language recognition is constructed. Experimental results show that the relative normalization method can solve shortcomings of the drift of 3D coordinates of joint nodes, diversity of signers’ shape and habitus and complexity of dynamic gesture changes. The method is effective and improves the recognition accuracy. Kinect sensor; 3D joint node; normalization; sign language recognition; hidden Markov model(HMM) 2017-03-30; 2017-04-20 国家自然科学基金资助项目(61305062);安徽新华学院自然科学重点研究资助项目(2016zr007) 沈 娟(1984-),女,安徽宿州人,安徽新华学院讲师,合肥工业大学硕士生; 郭 丹(1983-),女,湖北潜江人,博士,合肥工业大学副研究员,硕士生导师. 10.3969/j.issn.1003-5060.2017.05.013 TP301.6 A 1003-5060(2017)05-0638-05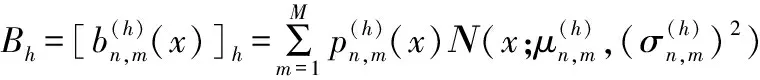
3 实验结果与分析

4 结 论
