基于Spark平台的大数据挖掘技术研究
2017-06-27王珣
王珣
(陕西学前师范学院 教学设备与实验室管理处, 西安 710061)
基于Spark平台的大数据挖掘技术研究
王珣
(陕西学前师范学院 教学设备与实验室管理处, 西安 710061)
大数据具备数据量大、富于多样性的特点。因此在大数据分析方面,无论是对处理速度还是实时性都具有较高的要求。数据挖掘技术是从海量数据里采用某种建模算法,用来寻找隐藏在数据背后的信息,从而让大数据产生更大的价值。Spark框架是一个针对超大数据集合的低延迟的集群分布式计算系统。本文基于该框架,对大数据挖掘技术进行了具体研究,首先完成了基于Yarn部署上Spark集群搭建,然后提出并实现了并行Apriori算法,该算法成功补充了Spark MLlib分布式机器学习库中所缺乏的关联分析问题的分布式算法。
大数据; 数据挖掘; Spark
0 引言
如今我国已进入大数据时代,每年都会产生海量的数据。预计到2020年,我们每年产生的数据总量将超过8.5ZB[1],涉及到金融,互联网,医疗等各个领域,这必然对大数据的挖掘和分析提出了更严峻的挑战。因此,在大数据时代,要进行各行各业、各种应用场景的天量数据挖掘,必然需要一个效率高、结果准确的计算平台来进行处理。
Spark由加州大学伯克利分校的AMP实验室出品,它是一个开源的计算框架,该框架可用于处理大数据的高性能分布式并行计算。Spark的主要优点在于:支持Python、Java等多语言编程,使用方便;可在大数据集上进行多种复杂查询;兼容性强,可以兼容Yarn,Mesos等多个框架;处理快速且结果精确。目前,Spark已经被应用或将要被应用到国内外很多公司的各类应用场景中。MLlib,作为Spark平台中的分布式机器学习库,承担着对机器学习算法实现的功能。它在经历过历次扩充改进后,正逐步完善。然而,在数据挖掘和分布式机器学习方面,传统的Spark MLlib库仍有一些缺陷,欠缺关于关联分析这类的算法内容,这给在需要应用关联分析处理众多应用场景的大数据时带来诸多不便,因此,我们有必要对相应的算法进行改进、扩充和定制,使其能够更加适用于数据挖掘和分布式机器学习技术。
1 Spark开发环境及其分布式集群构建
一般来讲,Spark是采用集群模式应用于实际生产场景中的,因此构建好Spark分布式集群是基于Spark进行大数据挖掘技术的研究与实现的关键。Spark开发环境及其分布式集群的构建,主要包括以下几个方面:
1.1 硬件系统要求
为了保证良好的运行性和兼容性,所有构建Spark分布式集群所用的物理主机均采用Linux 操作系统。本文采用的测试环境,由搭建在1台主机上的3台虚拟机组成。在此基础上搭建Spark分布式集群,包括2个Worker节点和1个Master节点。Master节点作为单机编写和调试Spark分布式应用程序的机器,配置必须高于Worker节点。Master节点的机器配置为4G内存和4核处理器,Worker节点机器配置为2G内存和2核处理器。各节点硬盘为基于PCIE[2]的SSD固态硬盘,这种硬盘读写速度快,可以有效提高工作及运行效率。上述集群构成形式,既可以减少Spark集群运行成本,降低环境构建失败概率,又可以根据需要随时对节点数量进行增减。
1.2 构造分布式Spark集群
本文选取Spark版本为Spark1.1。此版本下构造分布式Spark集群,首先需要安装Scala语言,然后将每台虚拟机上的slaves文件内容修改为集群上每个Worker节点的主机名,并修改集群每个节点的Spark安装目录下的Spark-env.sh文件;接着配置系统的jdk环境变量,修改系统Scala的安装路径为SCALA_HOME;集群中Master节点的主机名或IP地址采用SPARK_MASTER_IP的属性值,其他项默认;最后,确保该集群中的所有节点的Spark-evn.sh文件和slaves文件的内容完全相同。以上配置完成后便可通过jps命令查看集群的启动情况。
1.3 配置Spark的IDE开发环境
IDEA作为Scala语言开发环境,是良好支持Scala的IDE,故选择其为Spark应用程序的编程和开发环境。但为了避免IDEA在使用过程中产生的过量缓存文件过量占用和消耗I/O资源,选择SSD固态硬盘存储文件以提高性能。
马戴一生羁旅,东游江浙,南极潇湘吴越,西至汧陇,北抵幽燕大漠,跋山涉水,足迹甚远,尝尽仕途坎坷的悲苦辛酸,因此他的羁旅之作除了对山水的描摹和怀古伤今之愁以外,也有怀乡思归的深切悲痛,以及和着血泪的生活体验,这些诗歌不仅是其内心情感的集中写照,也是其政治命运的真实反映,在饱含深情的描绘中,呈现出了既同于中晚唐诗人写作的共性——精于五律,格律严整的艺术成就,也展现了其羁旅行役诗独特的典雅、清奇的艺术风格。
IDEA配置完成后,即可以开始进行Spark程序测试。
2 基于Spark的Apriori算法分布式实现
2.1 Apriori算法概念和核心步骤
Apriori算法是一种挖掘关联规则的频繁项集算法,Apriori算法多次扫描交易数据库,每次利用候选频繁集产生频繁集。它的主要步骤可分为定义最小支持度,筛选所有频繁项集和根据置信度产生关联规则。
2.2 Apriori算法基于Spark的分布式实现
Apriori算法基于Spark分布式集群的基本流程图,如图1所示。
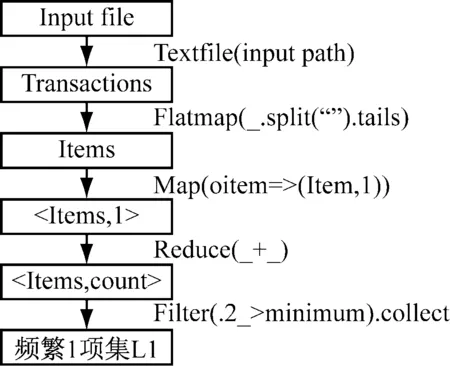
图1 分布式Apriori算法的实现流程图
算法的主要思路为:
(1) 产生频繁1项集L1。将事务集T以RDD
3 并行Apriori算法的核心步骤为:
(1) 得到频繁1项集F1并保存,以下为该步骤核心代码:

valfim1=transactions.flatMap(line=>line).Map((,1)).ReduceByKey(_+_).Filter(_._2>minSupport)savefim1(fim1,output+”result-1”,sum)defsavefim1(fim:RDD[(string,int)],path:string,count:double):Unit={fim.map(line=>{line._1+“:%.2f”.format(line._2/count)}).Coalesce(1,true).SaveAsTextFile(path)}
(2) 频繁1项集L1自连接产生C1,以C1作为对比,对数据库进行扫描以产生fim2,将fim2保存下来,以下为该步骤核心代码。

var(trans,newfim)=LItofim2(fimI.rnap(_._1).collect,transactions,minSupport)save(newfim,output+"result-2",sum)defL1tofim2(L1:Array[String],trans:RDD[(String,Int)],minSupport:Double):RDD[(List[String],Int)]={valL1c=Ll.sizevalcitems=scala.collection.mutable.ArrayBuffer[List[String]]()for(i<-0untilLlc){ for(j<-i+1untilLlc){ Citems+=List(L1(i),L1(j)).sortWith(_<_) }}valbccFI=sc.broadcast(citems)valtemp1=transflatMap(linc=>{) vartmp=scala.collection.mutable.Set[(List[String],Int)]() for(citem<-bccFLvalue){ valtc=isContain(line._l.split("").toSet,citem.toSet) if(tc=1){ tmp+=citem一>line._2 }}tmp})valnewfim=temp1.ReduceByKey(_+_).Filter(_._2>minSupport).cachebccFIunpersist()returnnewfim
(3) 循环产生3项集到8项集。以下为核心代码。

varfimk=newfim.collectfor(k<一3to8){ valtemp=mine(fimk.map(_._)1),trans,minSup-port) save(temp_2,output+"result-"+k,sum) fimk=temp.2.collect trans=temp._1}defisFrequent(orderitems:List[String],Lmap:scala.col-lection.mutable.Map[...]):Boolean valoCc=orderitems.sizefor(i<-0tooCc一3){ val11=orderitems.slice(0,i) val12}rderitems.slice(i+1,oCc) valkey=11.foldRight(12){(n:String,l2:List[String])=>n::12} valkeyl=key.slice(0,key.size-1)valvalues=Lmap.get(keyl)match{caseSome(n)=>ncaseNone=>List()if(!(values.exists(_=orderitems(oCc-1)))){returnfalse }}returntrue}defcombine(line,List[String]):scala.collection.mutable.ArrayBuffer[List[String]]={valCitems=scala.collection.mutable.ArrayBuffer[List[String]]()valtarray=line.2toArrayvaltc=tarray.sizefor(i<-0untiltc)foro(i<-1+1untiltc)} citems+=(tarray(j):aarray(i):aine._1).sortWith(_<_)}}citemsdefisContain():Int={varcontain=Iset.find(item=>{if(!trans.contains(item)){contain=0true}elseFalse})Contain}
3 基于Spark的Apriori算法实验
3.1 实验环境与条件
分布式Apriori算法的测试环境为由前面搭建好的Spark on Yarn集群。单机Apriori算法的测试环境为该集群中的Master节点。本文以chess标准数据集[3]作为待测数据集,每一个候选集的编号为该数据集每一行的第一个数字,最小支持度选为85%,频繁项集K设为8,然后将所设计的算法打包并以包的形式传到Spark上集群上运行,以进行数据挖掘。算法运行过程中需要依次输入数据集路径和输出文件夹路径。数据集路径用于输入数据的存储和管理,自身存放于HDFS上的data文件夹下;输出文件夹路径用于存放需要输入各项频繁项集的结果,共包含K个文件夹。每个文件中的内容的格式都为“项集:置信度”。
3.2 实验结果分析
输出结果存放于result-1至result-8这8个文件中,集群中Worker节点都打开的时候,程序总体运行时间为74 s。每个文件中的项集数依次为:984、690、517、358、177、105、32和15个,如图2所示。
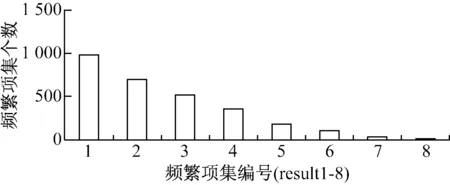
图2 各文件中频繁项集数
当最多只有一个Worker节点工作,其它条件不变时,测试结果,如图3所示。

图3 不同数量节点运行时间
从图3中可以看出,第1类:当Spark集群中只有一个Master节点和一个Worker节点时,节点运行所消耗的时间为108s;第2类:当Spark集群中的两个Worker节点同时运行时,所花费的时间为60 s;第3类:单机模式下,也就是当Spark集群只打开Master节点,两个Worker节点都被关闭时,算法运行所消耗的时间为195 s。可以看出,不同模式下的分布式并行Apriori算法运行具有较大的差异。在算法运行过程中会产生大量的候选集,频繁与HDFS进行交互,导致时间的消耗。另外图中第4类情况反映的是当Master节点运行java编写的单机Apriori算法时的运行情况,所消耗时间长达759 s。
对于Apriori算法处理相同数据集时,Spark集群中的所有节点在都打开的情况下所消耗的时间远远少于单机模式或只有一个Worker节点和Master节点打开时所花费的时间,主要原因在于集群中的工作节点越多使得集群总体配置越高,处理速度自然也就越快。同时Spark支持可伸缩计算的特性也很多提高了原有的大数据集的效率。另外,我们也还发现,不同的编程语言也对算法运行结果有着很大的差别。这是因为Spark框架还支持内存计算,部分算法被放入内存中计算,使得Apriori算法的效率在原有的基础上得到极大提高,这也正是Spark框架的优势之一。但Spark集群运行分布式并行Apriori算法一般更适用于处理较大规模型的数据集,在处理小型数据集时,Spark集群运行分布式并行Apriori算法的效率要比单机模式下低。原因在于Spark集群在处理数据集时,需要频繁地与HFDS交互,对数据进行RDD分块和封装,还有DAG备份恢复等一系列工作。所以Spark集群模式更适用于较大型数据集情况。
4 总结
本文对基于Spark的大数据挖掘技术进行了研究,并提出了基于Spark平台分布式Apriori算法,有效弥补了MLlib化中的不足,即缺少的关联分析类算法,该算法可以应用到关联分析大规模数据的场景当中。本文首先搭建起Spark on yarn的分布式Spark生产测试环境,即由3个以上节点构成的集群,然后再在所搭建好的集群上对文中算法进行了实验。实验以经典算法Apriori为测试算法,测试对象为GB级别的大数据集,采用了Scala语言和Spark RDD的分布式算子分别对其进行编码并运行,同时还比较了其与Apriori算法在运行Java语言所编写的单机模式下运行结果及效率。
[1] 中国产业调研网.2015年中国大数据行业现状研究分析与市场前景预测报告[EB/OL].http://www.cir.cn/2015-01/DaShuJuHangYeYanJiuFenXi219.html,2017-01-13.
[2] 道客巴巴.基于Spark的大数据挖掘技术的研究与实现[EB/OL].http://www.doc88.com/p-7758265704891.html,2017-01-14.
[3] 道客巴巴.基于Spark的大数据挖掘技术的研究与实现[EB/OL].http://www.doc88.com/p-7758265704891.html,2017-01-14.
Research on Technology of Big Data Mining Based on Spark
Wang Xun
(Section of Teaching Equipment & Lab Management, Shaanxi Xueqian Normal University, Xi’an 710061, China)
Because big data have the characteristics of large amount of data and rich diversity, it must be demanding large data analysis both in processing speed and real-time requirements. Data mining technology is to use some modeling algorithm from massive data, to look for hidden information behind the data, so that big data can produce greater value. Spark framework is a low latency cluster distributed computing system for super large data sets. Based on the framework, this paper studies the big data mining technology. This paper designs and implements the Yarn deployment on the Spark cluster firstly, and then proposes and implements parallel Apriori algorithm. This algorithm successfully adds to the distributed algorithm of association analysis by the lack of Spark MLlib distributed machine learning repository.
Big data; Data mining; Spark
王珣(1982-),男,汉中人,工程师,经济学硕士,研究方向:信息管理与信息技术。
1007-757X(2017)06-0064-03
文献标志码:
2017.02.05)
