一种基于裸闪存的Key-Value数据库优化方法
2017-06-23秦雄军张佳程陆游游舒继武
秦雄军 张佳程 陆游游 舒继武
(清华大学计算机科学与技术系 北京 100084)
一种基于裸闪存的Key-Value数据库优化方法
秦雄军 张佳程 陆游游 舒继武
(清华大学计算机科学与技术系 北京 100084)
(qinxiongjun2010@163.com)
近年来,非关系型的key-value数据库得到越来越广泛的应用.然而,目前主流的key-value数据库或者是基于磁盘设计的,或者是传统的基于文件系统和闪存转换层FTL来构建的,难以发挥闪存存储设备的特性,限制了I/O的并发性能,且垃圾回收过程复杂.设计并实现了一种基于裸闪存的key-value数据管理架构Flashkv,通过用户态下的管理单元进行空间管理和垃圾回收,充分利用了闪存设备内部的并发特性,并简化了垃圾回收过程,去除了传统文件系统和FTL中的冗余功能,缩短了I/O路径.提出了基于闪存特点的I/O调度技术,优化了闪存的读写延迟,提高了吞吐率;提出了用户态缓存管理技术,降低了数据写入量和频繁系统调用所带来的开销.测试结果表明,Flashkv性能是levelDB的1.9~2.2倍,写入量减少60%~65%.
key-value数据库;闪存;裸设备;数据存储;使用寿命
基于键值对(key-value)的key-value数据库是一种非关系型数据库,同传统的关系型数据库相比,它仅支持对主键的检索查询,不需要维护不必要的开销,因而效率很高.随着Web2.0时代和大数据时代的到来,数据库等存储系统对可扩展性和可靠性的要求越来越高[1-2].传统的关系型数据库由于对SQL语句的严格支持和对事务的支持,性能表现不佳,且关系型数据库的这些特性在当前众多的网络应用中不是必需的.key-value数据库由于其内部松散的耦合性,使得其具有传统数据库不具有的扩展性[3].由于基于key-value的非关系型数据库具有良好的扩展性、可靠性以及较高的性能,使其在大数据时代得到了广泛的应用[4-5].另外,近年来,闪存(flash memory)由于其远高于磁盘的I/O性能和不断下降的成本也越来越普及[6-7],特别是闪存设备具有很多特性,比如其内部丰富的并发读写单元[8]、随机读写性能高,在闪存环境下部署key-value数据库就成为一种选择[9-10].然而,很多key-value数据库系统都是基于传统磁盘设计的,如levelDB,这些系统在设计之初就没有考虑到闪存设备的并发特性和垃圾回收特性,使得这些系统还不能充分发挥底层闪存设备的性能.
在闪存环境下,传统的基于文件系统和闪存转换层(flash translation layer, FTL)的key-value数据库存在4个问题:
1) 闪存设备的并发性能难以得到充分利用.在传统架构中,数据在闪存设备上的物理布局由文件系统和FTL共同决定,对上层数据库是透明的,这种情况下闪存设备内部的并发特性很难被充分利用.
2) 垃圾回收复杂.闪存具有2个重要特性:不能原地更新和读写与擦除的不对称性,因此闪存设备使用一段时间后需要垃圾回收.使用FTL的闪存设备进行垃圾回收时,需要先选择目标块,然后读出目标块中的有效页,写入到新的地址,修改映射表,最后才能擦除目标块.整个过程不仅复杂耗时,而且容易造成严重的写放大[11].
3) 文件系统和FTL中的某些功能重复冗余.文件系统和FTL中都有负责空间分配和垃圾回收的功能,这些功能存在冗余,带来额外开销.
4) I/O路径过长的问题.基于通用文件系统的数据库系统,其读写请求需要依次经过内核的虚拟文件系统(VFS)、页高速缓存、文件系统管理层、通用块层、驱动层才能到达物理设备,整个过程十分复杂且耗时.
传统的基于文件系统和FTL的key-value数据库系统没有考虑到闪存设备的特点,在闪存设备上性能表现不佳[12-13],因此,针对闪存的特点设计一种key-value数据库架构具有重要意义.
本文提出了一种基于裸闪存设备构建key-value数据库系统的方法,并基于该方法实现了一个key-value数据库Flashkv.Flashkv结合闪存设备的具体特点,综合考虑了文件系统和FTL与数据库的关系,克服了直接将传统数据库移植到闪存设备上的缺陷.Flashkv的主要思想是通过一个管理单元直接对裸闪存设备进行管理,包括空间分配、垃圾回收、I/O请求调度.这种实现能够使I/O请求绕过通用文件系统和闪存转换层,减少了软件栈带来的开销,去除了传统文件系统和FTL中的冗余功能,缩短了I/O路径.Flashkv能够充分利用闪存设备的并发特性,大大简化垃圾回收过程.本文还提出了基于闪存特点的I/O调度技术,优化了闪存的读写延迟,提高了吞吐率;提出了用户态缓存管理技术,降低了数据写入量和频繁系统调用所带来的开销.
1 相关工作
key-value型数据库是传统关系型数据库的一个简化,通过去掉很多不必要的特性,key-value数据库能使自己的性能优势最大,数据之间的耦合度最低.key-value数据库有3种流行的实现方式:1)通过B+树实现,例如Tokyocabinet[14].B+树通过增加每个节点的子节点数目来尽可能减小整棵树的高度,从而减少外存设备的读写次数.其优点是查询效率较高;缺点是大量随机写容易造成节点碎片化,导致性能下降.2)基于Hash表实现,例如redis[15],SkimpyStash[16],基于Hash表实现的优点是查询效率高,缺点是不能支持范围查询,当出现大量Hash值碰撞时会导致效率下降.3)基于Log-Structured-Merge tree[17](LSM tree)实现,例如levelDB[18],Hbase[19],其优点是写入性能很高,缺点是读性能表现不佳且容易造成严重的写放大.
基于SSD的key-value数据库,目前有很多工作.Shen Zhaoyan等人[12]提出了一种基于Hash表的key-value系统,消除了Hash表和FTL的地址映射表存在的冗余映射的问题.Flashkv消除了文件系统的空间管理和FTL的地址映射表的冗余.文献[12]还提出了将数据库的垃圾回收和FTL的垃圾回收过程相结合,但其垃圾回收过程仍然与传统FTL中的垃圾回收过程类似,而Flashkv由于其特殊的数据布局,其垃圾回收过程异常简单.王鹏等人提出的LOCS[13]把levelDB移植到了SSD设备上,并使用了I/O调度等策略加速写请求.LOCS把一个数据库文件存储在一个闪存通道中,不同的文件分布在不同的通道上,达到并发读写的目的.Flashkv采用的物理布局与LOCS不同,Flashkv把一个文件的数据分散在多个通道上,提高单个文件读写的并发度;此外,LOCS的I/O调度是为了保证所有通道的利用率尽量均衡,而Flashkv的I/O调度技术则是为了保证数据库中重要而紧迫的请求优先得到执行.
LSM tree数据结构采用日志更新的方式,将随机写操作顺序地写入磁盘.LSM tree具有良好的写入性能,但为了降低读性能的开销,LSM tree引入了compaction操作,对乱序写入的key-value对进行重新排序,这个操作会引起较大的写放大.Wu等人分析了LSM tree的写放大的特征,并提出了LSM-trie,可以极大地减少写入量,提升系统性能[20].Lu等人提出将key值和value值分离存放的策略[21],在每次compaction过程中只需要读取key值即可,极大地减小了LSM tree的写放大,有效提高了基于LSM tree的系统性能.
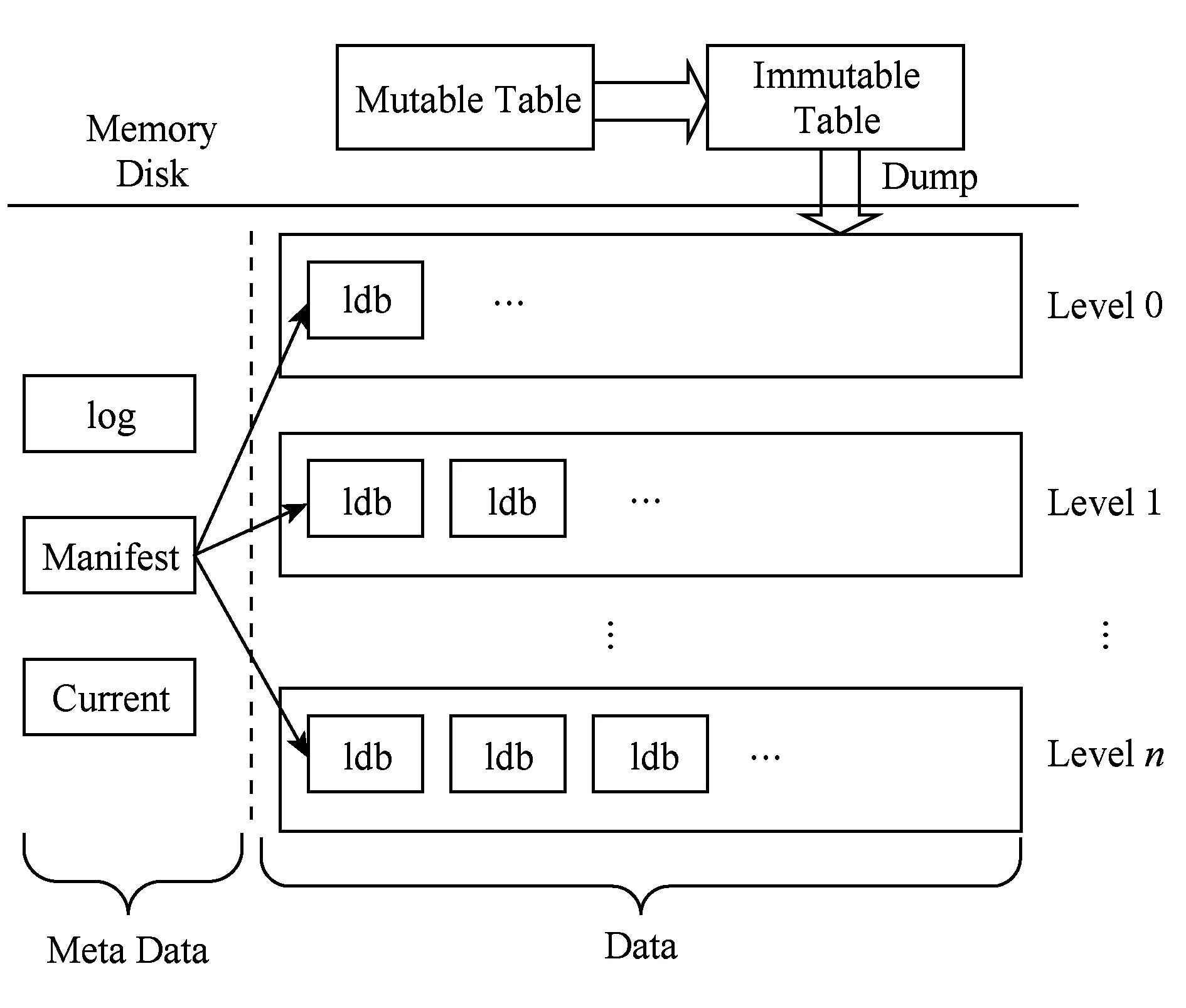
Fig. 1 levelDB illustration图1 levelDB示意图
levelDB[18]是一个开源的key-value数据库,其核心使用了LSM tree数据结构[17].在levelDB中,用户的插入首先写入到图1的可变内存表(mutable table)中,当可变内存表写满时,可变内存表转变为不可变内存表(immutable table),同时levelDB重新生成一张可变内存表,不可变内存表中的数据会在后台写入到磁盘的0层中.在levelDB的磁盘布局中,不同的数据文件分布在不同的层(level),如图1所示.当某一层文件过多时,levelDB会进行compaction操作,从该层选取若干文件,将这些文件中的key-value对读入内存,重新排序后再以文件的形式写入下一层.在处理查找请求时,levelDB首先在mutable table中查找,然后在immutable table中查找,若没有找到,则按照 level 0,level 1的顺序依次查找每层文件,在以上过程中任一步骤找到指定key值时即可返回.
和所有基于LSM的key-value数据库一样,levelDB是一个写友好的数据库,其写入操作只需直接写入内存的可变内存表中即可.但levelDB读操作较慢,最坏情况下需要多次查找,涉及到多次磁盘操作.
另外,levelDB是基于文件系统实现的,而文件系统运行在闪存设备的FTL之上,这种模型的架构如图2所示.在该模型下,levelDB使用文件系统提供的POSIX API进行文件读写等操作,文件系统负责空间管理、地址映射、垃圾回收等功能,FTL通过空间管理、地址映射和垃圾回收等功能模块,把裸闪存设备抽象成一个通用块设备提供给上层文件系统.
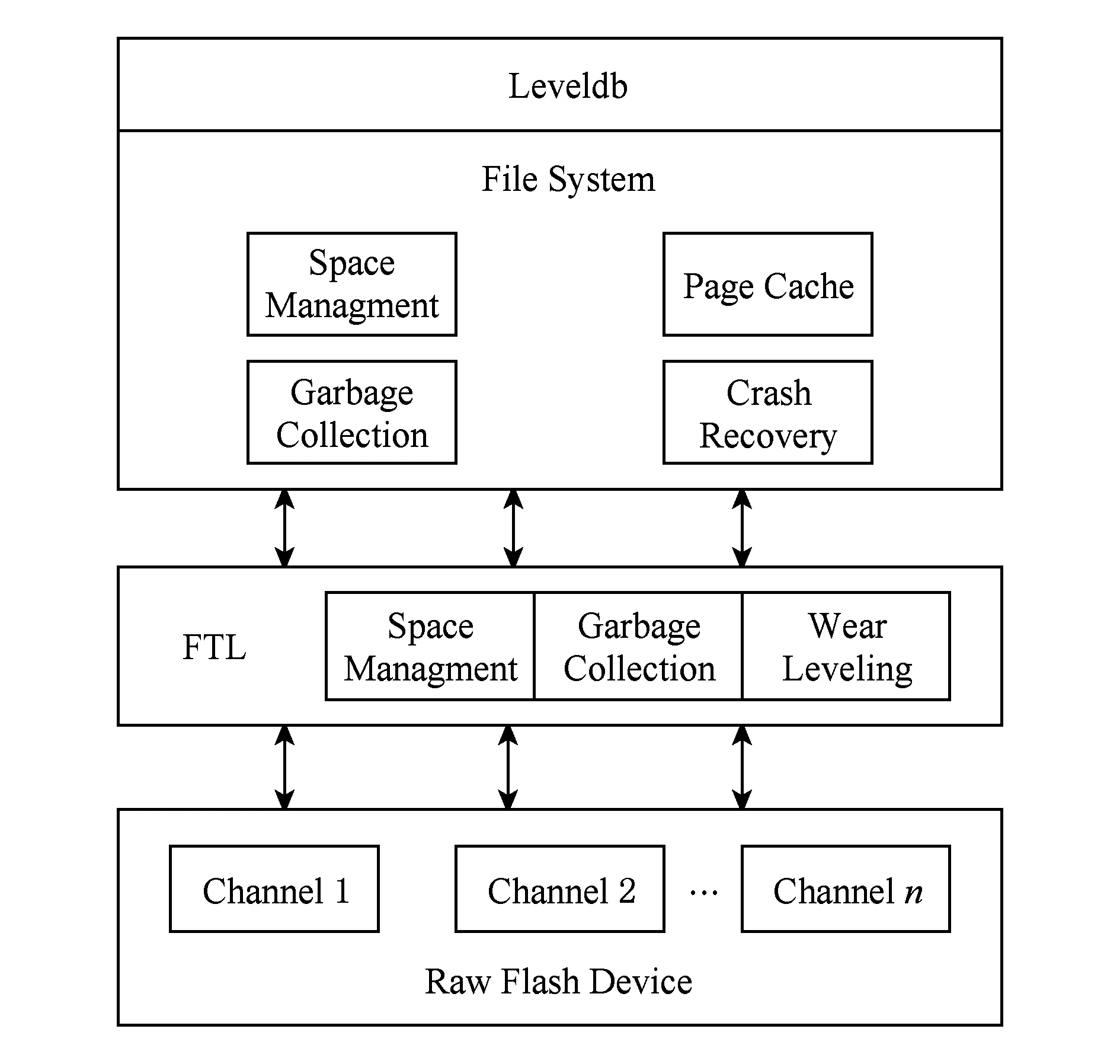
Fig. 2 Architectue of traditional key-value database图2 传统key-value数据库架构
这种存储架构存在着功能单元冗余、垃圾回收过程复杂、I/O路径长等缺点.闪存设备的并发特性也难以被充分利用.由文件系统和FTL进行空间分配,数据的物理布局对上层数据库软件是透明的,数据库无法自己控制数据的物理布局,因此,SSD设备的并发特性难以被充分利用.其次是复杂的垃圾回收.由于闪存设备的特点,导致这种传统存储架构下的垃圾回收过程非常复杂,造成严重的写放大,影响闪存设备寿命.此外,该架构下多个功能单元冗余.如图2所示,上层文件系统中的垃圾回收单元和FTL中的垃圾回收模块重复;文件系统中负责空间管理的模块和FTL中的空间管理模块重复;文件系统中的地址映射与FTL中的映射表也存在功能上的冗余.另外,该架构下I/O路径过长.从levelDB发出的读写请求经系统调用,依次经由VFS、具体文件系统、FTL,I/O路径较长,引入了不必要的软件开销.
总之,这些基于key-value的数据库或者是基于磁盘设计的,或者是传统的基于文件系统和闪存转换层FTL来构建的,难以发挥闪存存储设备的特性,限制了I/O的并发性能.
2 Flashkv架构设计
本文提出了一种基于裸闪存设备构建key-value数据库系统的方法,并基于该方法实现了一个key-value数据库Flashkv,架构如图3所示.该架构中,Flashkv绕过了文件系统层和SSD的FTL层,将levelDB直接构建于裸闪存设备上.Flashkv整体架构主要包含管理单元与I/O调度器两大模块,其中管理单元负责闪存空间管理、垃圾回收、读写接口和缓存管理.
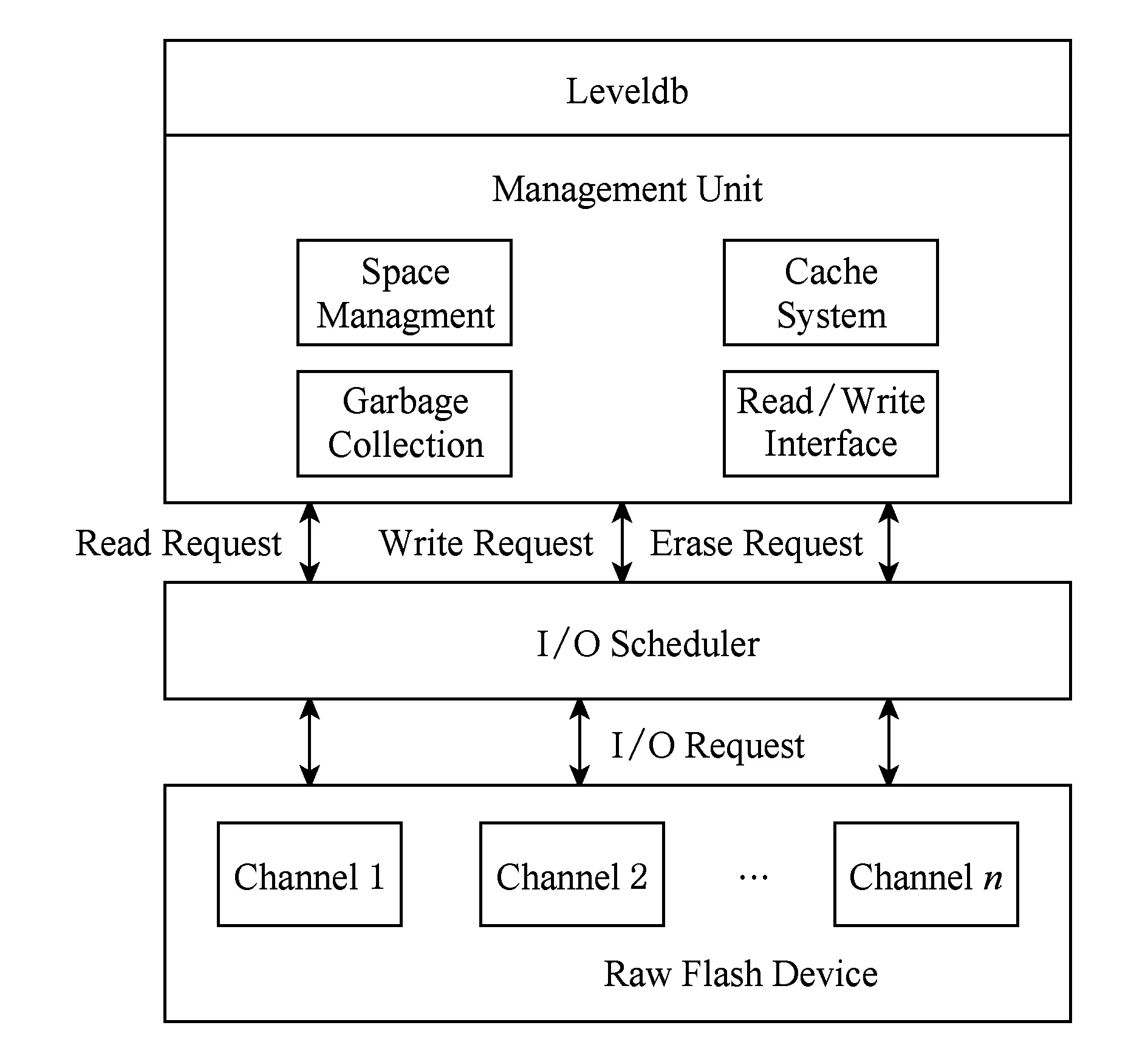
Fig. 3 Architecture of Flashkv图3 Flashkv架构图
在管理单元中,空间管理负责物理地址的分配和文件名到物理地址的映射.Flashkv采用了块对齐的分配方式,将文件以块为单位分布到闪存的每个通道中,保证闪存设备内部的并发特性得到充分利用.垃圾回收负责对无效的闪存块进行擦除与回收,由于物理地址的分配以块对齐的方式进行,因此垃圾回收过程十分简单.缓存系统是在用户态模拟了虚拟文件系统中的页高速缓存,对数据库的读写请求进行缓存,可以避免用户态和内核态的频繁切换.读写接口负责与I/O调度器进行交互,把数据库产生的读写请求交给内核态的I/O调度器处理.管理单元整合了原来分别位于文件系统和FTL中的空间管理、垃圾回收等模块的功能,避免了这些功能的冗余开销,缩短了I/O路径.
在管理单元之下,Flashkv使用一个I/O调度器,对I/O请求进行有效调度.Flashkv在运行过程中会产生很多读写和擦除请求,这些请求的重要程度和紧急程度不同,I/O调度器接收用户态的读写接口模块提交的读写请求,根据请求的紧迫程度赋予它们不同的优先级,并优先调度那些优先级较高的请求,从而加速读写过程,提升系统性能.
在新的架构下,Flashkv由管理单元和I/O调度器2部分组成.原来分别位于文件系统和FTL中的空间管理模块和垃圾回收模块得到整合,且SSD设备并发特性得到充分利用,垃圾回收过程大大简化.Flashkv的读写请求只需要经过管理单元和I/O调度器就可以到达裸闪存设备,I/O路径也大大缩短.
3 关键技术
Flashkv主要采用了LSM tree的数据结构,设计并实现了用户态的管理单元、I/O调度优化和双线程compaction三个关键技术.通过用户态管理单元,Flashkv可以在用户态对物理闪存设备进行空间管理和垃圾回收,从而能够更好地利用闪存设备的并发特性,简化垃圾回收过程;通过I/O调度技术,Flashkv可以优先处理前台的I/O请求,从而提高整体性能;通过双线程技术,Flashkv的compaction过程能够得到加速处理,避免大量文件堆积在level 0造成阻塞.
3.1 管理单元
在Flashkv中,管理单元负责空间管理、缓存管理、垃圾回收、读写接口等功能.LSM tree将用户的插入、查询请求转换成文件的读写请求,发送到管理单元上.管理单元通过空间管理对请求进行物理地址分配和映射;通过用户态的缓存对数据进行管理,并通过读写接口向I/O调度器发送读写请求.当levelDB发出删除文件的请求时,管理单元回收闪存设备上的物理地址,并向I/O调度器发送擦除请求擦除对应的物理闪存块.
和levelDB使用文件系统进行空间分配不同,Flashkv使用管理单元直接进行物理闪存空间的分配和管理.这样,Flashkv可以自己决定数据在闪存设备上的物理布局,从而可以更好地发挥设备内部的并发特性,提升读写速度;可以更有效率地进行垃圾回收,且显著减少写入量,延长设备寿命.
3.1.1 空间管理
传统数据库由文件系统进行逻辑空间管理,使用闪存转换层进行物理地址管理,上层数据库软件对底层的数据布局一无所知.在这种情况下,数据库软件很难根据自身的特点安排合理的数据布局.而数据布局的好坏对整个数据库系统的性能有重要影响.这种影响主要体现在2个方面:
1) 对并发度的影响,不恰当的数据布局无法充分利用设备的并行特性,容易造成一部分闪存通道读写繁忙、一部分闪存通道空闲的现象;
2) 对垃圾回收的影响,不恰当的数据布局会造成垃圾回收负担加重,从而影响前台的读写性能,还导致严重的写放大,严重影响设备寿命.
通过空间管理单元,Flashkv能够在用户态对物理空间进行分配和管理,而不借助于文件系统和闪存转换层.因为Flashkv能够完全感知和控制底层的数据布局,Flashkv能够克服上述2个缺点,即能够充分利用多个数据通道,从而加速读写过程;能够简化垃圾回收过程,进而减少后台垃圾回收对前台读写的影响且降低写放大.
现代SSD设备一般包含多个通道,通道之间可以并行执行指令,互不影响,称之为设备的内部并发度(internal parallelism)[9].为了充分利用闪存设备的这种特性,Flashkv采用了一种条带化的分配方式,文件的内容以闪存页大小(8 KB)为单位划分成若干逻辑页.如图4所示,文件的内容被划分为N=(k+1)n(k∈)个逻辑页,每个逻辑页大小均为8 KB.第1个逻辑页内容写入到通道1中,第2个逻辑页内容写入到通道2中,以此类推,第i个逻辑页被写入通道(i-1)%n+1中.
为了简化垃圾回收过程,Flashkv的地址分配以行(line)为单位,按块对齐.行是由每个通道内偏移值相同的块组成的,图4中灰度相同的一组块就称为一行.由于LSM tree产生的每个数据文件大小基本一致,我们把每个文件大小设为一个定值,使其能够以行为单位,分布在闪存的每个通道中.例如,Flashkv使用的裸闪存设备每个物理块大小为2 MB,有32个通道,每个文件的大小设置为64 MB.空间的分配以块对齐的方式进行,这种对齐体现在每个通道上分配给该文件的闪存块在各自通道上的偏移值都相同.
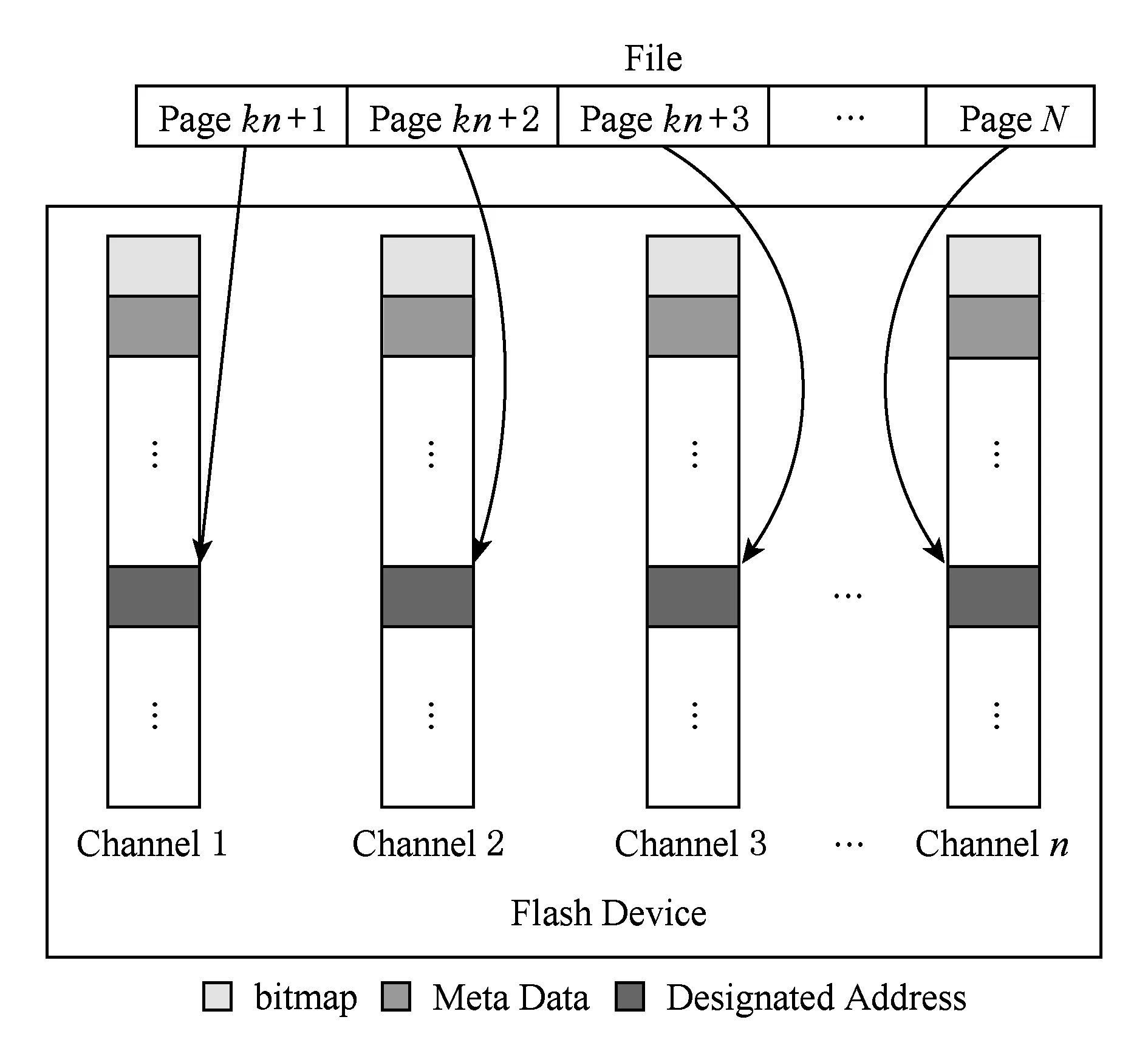
Fig. 4 Data layout of Flashkv图4 Flashkv数据布局
采用这种块对齐的方式,记录物理地址时只需记录一个偏移量值即可,大大减少了元数据的大小.且数据内容顺序分布在不同通道上,读取和写入时所有通道能够并行进行处理,最大限度利用闪存设备内部的并发特性.采用块对齐分配方式的另一个好处是垃圾回收过程大大简化.由于以行为单位进行空间分配,同一个块内的所有页面都属于同一个文件,因此它们要么同时为无效页,要么同时为有效页.当该文件删除时,Flashkv只需直接擦除相应的闪存块即可.
3.1.2 用户态缓存系统
在传统的文件系统中,页高速缓存(page cache)有十分重要的作用.由于访问的局部性原理,最近访问过的页面未来有很大的概率会再被访问.因此只需要使用少量的内存作为缓存,即可大大提升文件系统的性能.
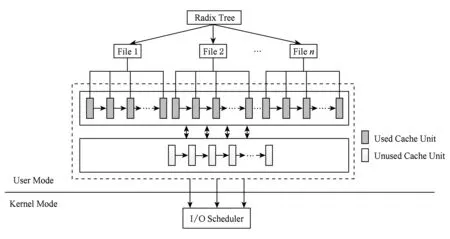
Fig. 5 Cache system of Flashkv图5 Flashkv缓存系统
Flashkv在用户态实现了一个缓存系统,以降低读写延迟.和页高速缓存类似,Flashkv缓存系统中每个缓存单元大小为4 KB.如图5所示,虚线框中的部分即为Flashkv的缓存系统.缓存单元共分为2部分,未使用的缓存单元和已使用的缓存单元.未使用的所有缓存单元链接在一个链表中.每个文件以一棵基树组织属于该文件的所有缓存单元,以加速索引过程.每个文件从空闲缓存单元链表中获取缓存单元,插入自己所管理的基树中,当内存不足时,动态地选择一些已经使用的缓存单元进行替换,将其内容写入闪存中.
使用用户态缓存的好处之一在于避免频繁地陷入内核.levelDB的每次读写请求都要经过系统调用陷入内核态,然后在页高速缓存中查找;而Flashkv的缓存系统实现于用户态下,减少了不必要的系统调用开销,在大量读写请求的情况下,避免了用户态和内核态的频繁切换.使用用户态缓存而不是系统页高速缓存的另一个好处在于可以根据数据库本身的特点自由选择合适的缓存算法.
3.1.3 垃圾回收
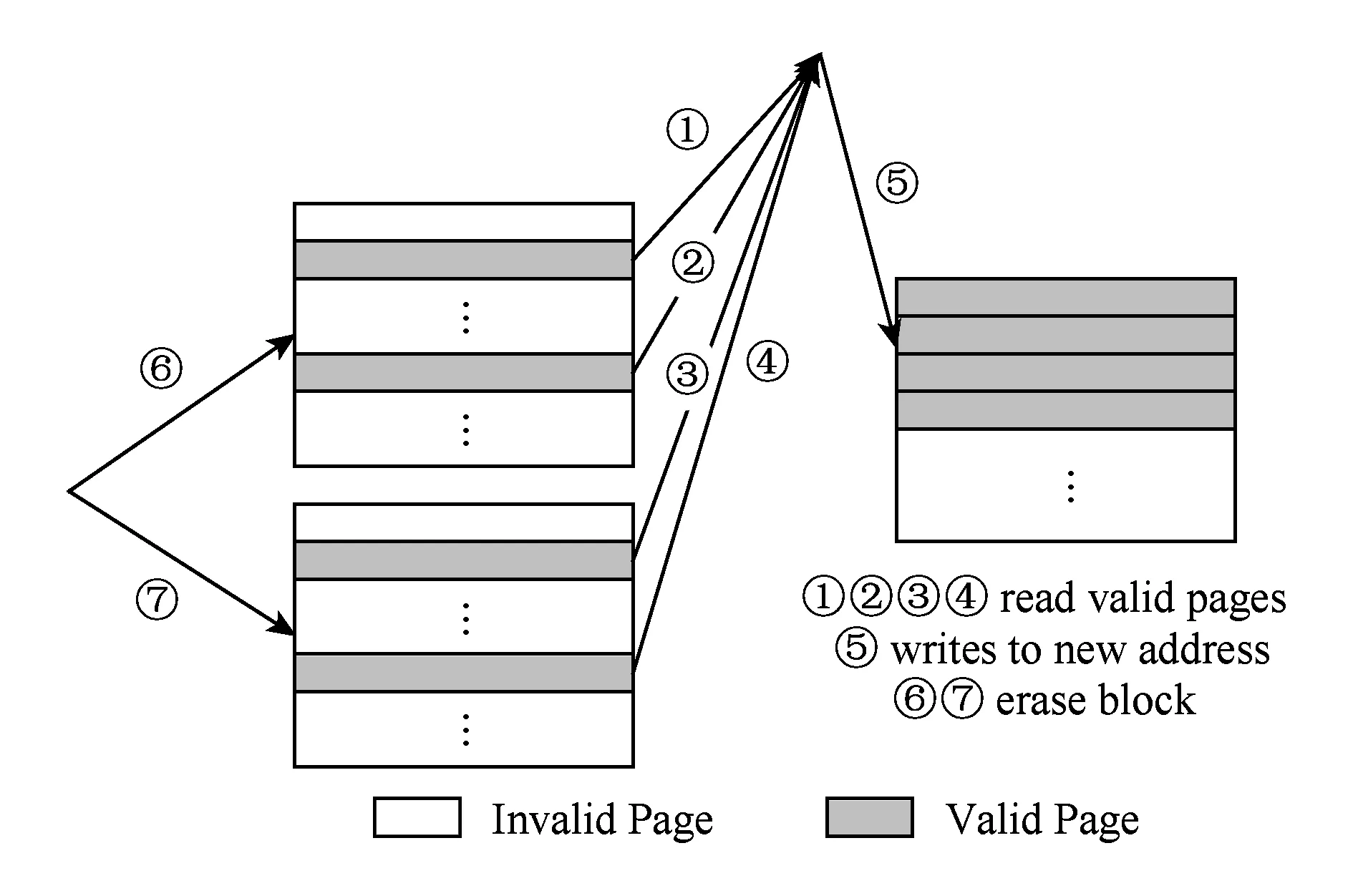
Fig. 6 The process of garbage collection图6 垃圾回收示意图
SSD设备具有不能原地更新、读写请求和擦除请求不对称的特点,这导致SSD设备的垃圾回收过程十分复杂.垃圾回收一般由闪存转换层(FTL)完成.如图6所示,在垃圾回收过程中,FTL会先读入目标块中的有效页;然后将它们写入到新的地址,改变映射表;最后才能擦除目标块.整个过程引入了额外的读写操作,在垃圾回收负担重时会严重阻碍前台的读写请求,不仅开销巨大,而且造成严重的写放大,影响闪存寿命.
在Flashkv中,垃圾回收过程十分简单.如图4所示,Flashkv的地址分配以闪存块为单位,因此在每个通道中,分配给文件的都是一个完整的闪存块.当删除文件时,需要回收物理地址空间,此时不再需要读入有效页,重新写入新的地址,改变映射表等冗余步骤,只需直接擦除目标块即可.与构建于FTL之上的levelDB系统相比,Flashkv中的垃圾回收过程不仅高效,且避免了不必要的写放大.
3.2 I/O调度器
Flashkv中,I/O调度器处于内核态,I/O调度器接收由上层管理单元发送的读、写、擦除请求,经过优先级调度后,把这些请求发送到闪存设备上.如图7所示,对于读请求和写请求,I/O调度器中各有3个优先级队列,分别对应优先级高、中和低的读写请求.对于擦除请求,Flashkv中仅有一个请求队列,对优先级不做区分.
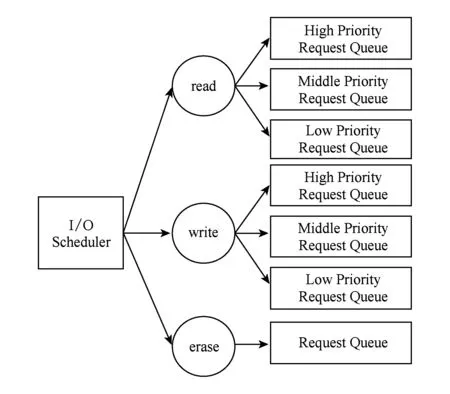
Fig. 7 The I/O scheduler of Flashkv图7 Flashkv I/O调度器
在Flashkv中,存在2种读请求:1)用户查找的key而出发的读请求,我们称之为前台读请求;2)为了compaction而进行的读请求,我们称之为后台读请求.我们给前台读请求最高优先级,因为用户的查找请求应当尽可能快地得到响应,这类读请求会插入高优先级队列中;把level 0的后台读请求设置为中等优先级,因为当level 0文件过多会引起整个数据库阻塞,所以对level 0的compaction请求设置为中;其余的后台读请求会插入低优先级队列中.
同样,Flashkv中存在2种类型写请求:1)把内存中的不可变内存表(immutable table)写入到level 0产生的写请求;2)进行compaction产生的写请求.从内存的immutable table写入level 0的写请求,Flashkv给予最高优先级,因为内存中的immutable table不宜过多,否则会造成阻塞,这类写请求会插入高优先级队列中;对于compaction操作要写入到level 1的写请求,Flashkv给予中度优先级,因为level 0的文件数目不能过多;其余的写请求会插入低优先级队列.
Flashkv中,擦除请求不做区分.Flashkv会优先调度优先级更高的请求.为了防止低优先级的请求饥饿,Flashkv每隔一段时间会对中优先级和低优先级的请求单独处理,全部处理完成后再执行正常调度策略.
3.3 双线程技术
在levelDB中,内存中最多只能有2张表,即1张正在插入的可变内存表(mutable table)和1张不可变内存表(immutable table),immutable table由mutable table转化而来.由于内存写入速度和外存之间存在数量级的差距,当客户端的插入请求频繁时,2张内存表都会很快填满,造成插入操作阻塞.因此只能有一张immutable table的条件严重限制了levelDB的性能.在Flashkv中,我们把这一限制放宽,即内存中可以有多个immutable table同时存在.
为了平衡读写性能,levelDB会在适当的条件下触发compaction操作.levelDB的compaction过程涉及到大量的文件读写操作,是levelDB的瓶颈所在.而levelDB中的compaction操作是单线程的,因此极易造成性能恶化.
Flashkv修改了levelDB的compaction逻辑,使用了双线程进行compaction.Flashkv首先对每一层compaction的优先级进行评估,然后选择优先级最高且互不影响的2层进行并行compaction.所谓互不影响是指2个compaction不涉及相同的文件.
4 实验测试
4.1 测试环境
实验在Linux 2.6.32内核环境下进行,所用服务器内存为4 GB,CPU为Intel®Xeon E5-2620,2.10 GHz,12核,并配置有一块PCIE裸闪存设备.该闪存设备的闪存块大小为2 MB,页大小为8 KB.实验环境配置如表1所示:

Table 1 Experiment Configuration表1 实验环境配置
测试工具采用了目前流行的YCSB benchmark[22],是由雅虎提出的一个测试框架,它提供了6种不同的负载来评估非关系型数据库的性能.YCSB的测试过程分为load阶段和run阶段,load阶段向数据库中插入给定数量的key-value记录,run阶段完成给定数量的操作,这些操作包含读取(read)、更新(update)、插入(insert)、读后写(read modify write)等,不同负载各操作所占比例不同,如表2所示.我们使用YCSB的5种负载:a,b,c,d,f,分别对Flashkv和levelDB进行了测试.由于YCSB的负载e涉及scan操作,而LSM tree数据结构scan操作开销较大,因此没有对负载e进行测试.5种负载的特点如表2所示.其中,zipfian分布表示齐夫分布,latest分布表示最近插入的数据更可能被读取.
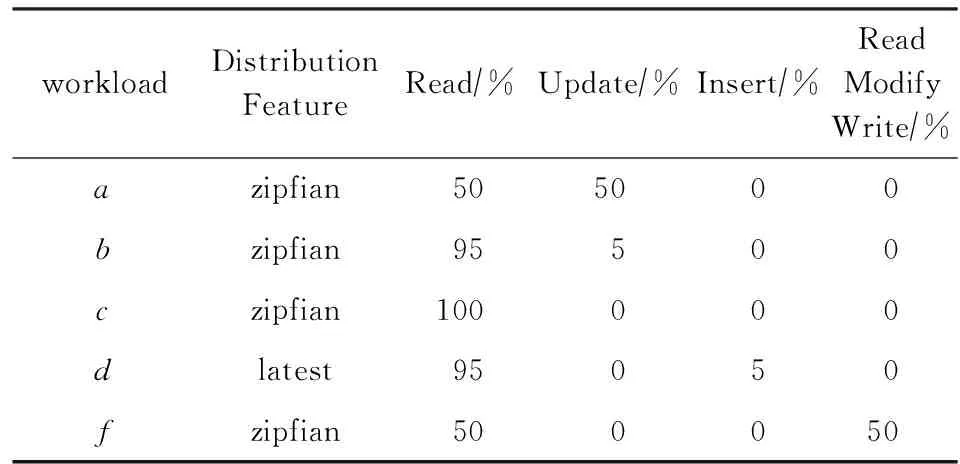
Table 2 YCSB Workloads Features表2 YCSB的5种负载特点
4.2 Flashkv整体、架构测试
本节实验将测试Flashkv的整体性能和Flashkv在架构上的优势.YCSB的设置参数如表3所示,在load阶段先向数据库中插入10×106条记录,run阶段再完成10×106次操作.使用双线程有I/O调度的Flashkv版本测试整体性能,使用单线程没有I/O调度的Flashkv版本测试架构优势.以下表达中,双线程Flashkv表示使用双线程和I/O调度版本的Flashkv,用以测试Flashkv整体性能;单线程Flashkv表示使用单线程且没有I/O调度的Flashkv,用以测试Flashkv的架构优势.作为对比,levelDB分别运行在ext3和ext4文件系统之上.我们还实现了一个闪存转换层oftl,oftl采用页级映射,并缓存最近使用的部分映射表.

Table 3 YCSB Parameter表3 YCSB参数
4.2.1 时间
run阶段时间测试结果如表4所示,单位为s.除负载d外,单线程Flashkv的时间为使用ext4文件系统levelDB的50%~60%,为使用ext3文件系统levelDB的50%~60%.仅从架构角度看,Flashkv性能是使用ext4文件系统levelDB的1.65~2.0倍,是使用ext3文件系统levelDB的1.66~2.0倍.
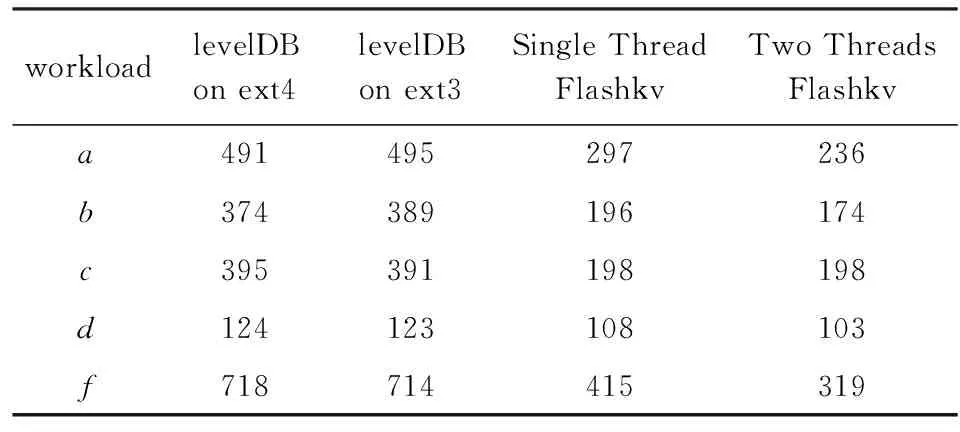
Table 4 Runtime of Flashkv and levelDB表4 Flashkv和levelDB运行时间对比 s
除负载d外,双线程Flashkv的时间为使用ext4文件系统levelDB的45%~50%,为使用ext3文件系统levelDB的44%~50%.Flashkv整体性能是使用ext4文件系统levelDB的1.99~2.25倍,是使用ext3文件系统levelDB的1.97~2.23倍.
负载d采用了latest分布,访问最近写入的数据,由于这些数据大部分在缓存中,所以Flashkv的提升不多.
Flashkv和levelDB时间对比如图8所示,可以看出,Flashkv的性能高于levelDB,有以下4点原因:
1) Flashkv不借助于文件系统和FTL进行空间分配,而是由管理单元采用块对齐的方式来进行物理地址分配,闪存设备的并发性能得到了充分利用;
2) Flashkv特殊的块对齐分配方式,使得垃圾回收过程大大简化;
3) Flashkv整合了levelDB中分别位于文件系统和FTL中的空间分配模块和垃圾回收模块,避免了冗余;
4) Flashkv绕过了通用文件系统和内核的I/O路径,减少了I/O软件栈的开销.
Flashkv性能较levelDB有明显提高,证明了Flashkv架构上的优势.
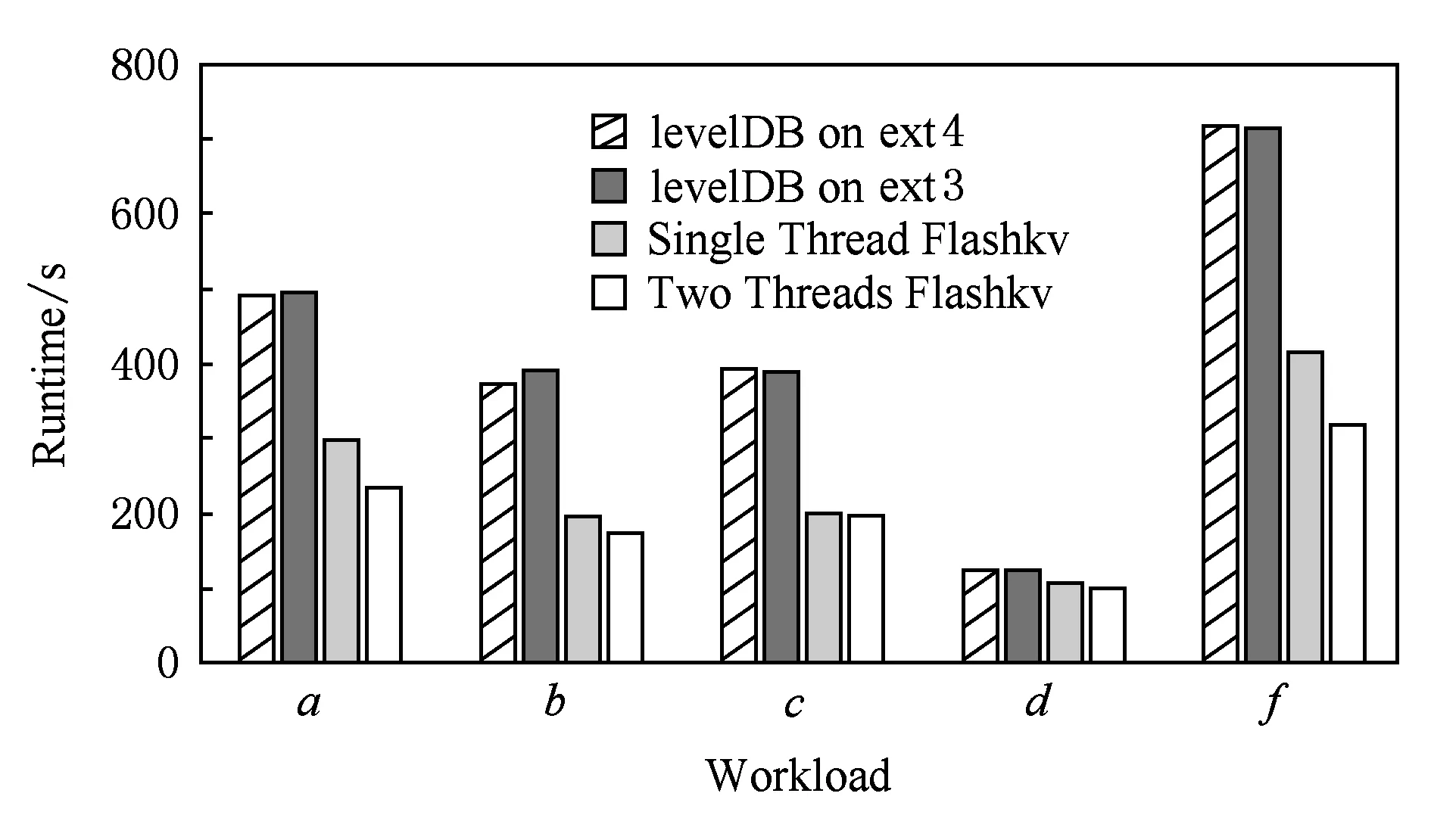
Fig. 8 Flashkv and levelDB runtime comparison图8 Flashkv和levelDB运行时间对比
4.2.2 写入量
在YCSB的5种负载下,我们分别测试了Flashkv和基于ext3,ext4文件系统的levelDB的写入量.结果如表5所示,单位为GB,该结果为load阶段和run阶段总的写入量.
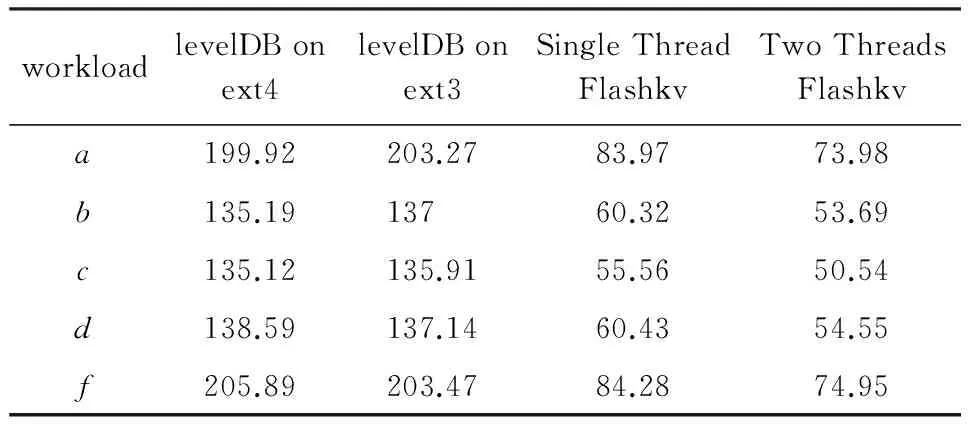
Table 5 Write Amount of Flashkv and levelDB表5 Flashkv和levelDB写入量对比 GB
Flashkv和levelDB写入量对比如图9所示,从图9中可以看出,双线程Flashkv的写入量比基于ext4,ext3文件系统的levelDB减少60%~65%;单线程Flashkv写入量比基于ext4,ext3文件系统levelDB减少55%~60%,写入量明显减少.由于采用了块对齐的物理地址分配方式,Flashkv的垃圾回收过程十分简单,只需要直接擦除无效地址即可,不再涉及读出有效页重新写入新的地址这一步骤,不会带来额外的写放大,因此写入量较依赖FTL进行垃圾回收的levelDB有明显减少.
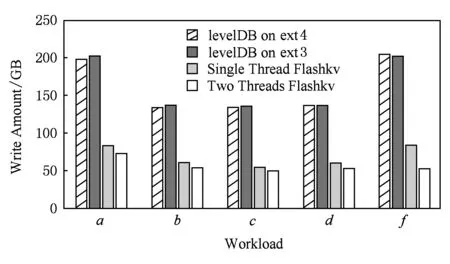
Fig. 9 The write amount of Flashkv and levelDB图9 Flashkv和levelDB写入量对比
4.3 I/O调度测试
本节我们将测试I/O调度技术对Flashkv的影响,作为对比的两者分别是使用了I/O调度技术的Flashkv和没有使用I/O调度技术的Flashkv,为了排除双线程技术的影响,二者均采用了双线程技术.
本节仍然使用YCSB作为测试集,由于I/O调度技术主要在run阶段起作用,因此我们考察run阶段.测试采用50个线程,我们首先向数据库中插入2 000万条记录,然后进行2 000万次操作.实验结果如表6所示:
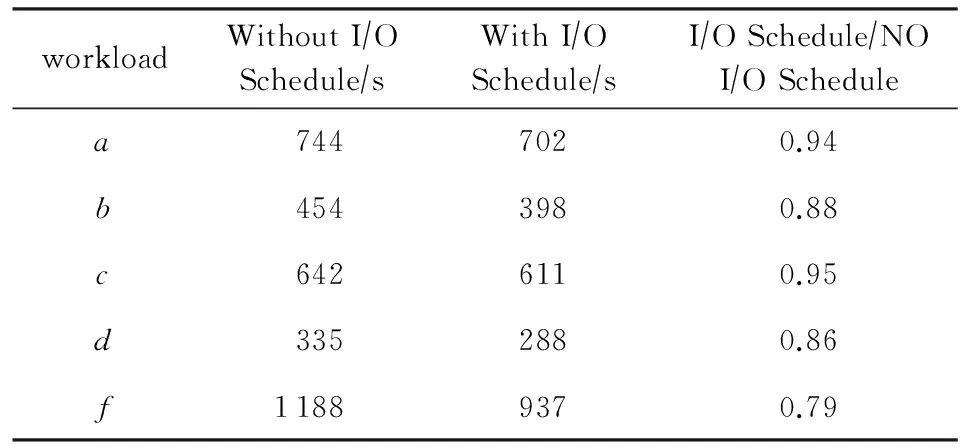
Table 6 Impact of I/O Schedule on Flashkv表6 I/O调度对Flashkv时间的影响
I/O调度对Flashkv时间的影响如图10所示,从图10中看出,使用了I/O调度器的Flashkv比没有使用I/O调度器的Flashkv性能提升5%~21%,证明I/O调度技术的作用.I/O调度器优先调度前台和compaction的请求,保证前台访问的低延迟的同时,避免了整个数据库因level 0层文件过多导致的频繁阻塞,因此Flashkv整体性能得到提升.
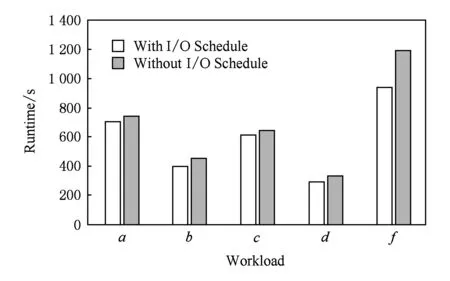
Fig. 10 Runtime comparison with and without I/O schedule图10 有无I/O调度Flashkv时间对比
4.4 双线程技术测试
本节我们将测试双线程技术对Flashkv的影响.作为对比的两者分别是没有使用双线程技术和使用了双线程技术的Flashkv,为了排除I/O调度的影响,二者都没有采用I/O调度.由于双线程技术仅加速Flashkv的写入过程,因此我们仅考察数据load阶段.测试用50个线程,我们分别向数据库中插入500万、800万、1 000万、1 500万、2 000万条记录.表7为单线程版本Flashkv和双线程版本Flashkv的运行时间对比结果.
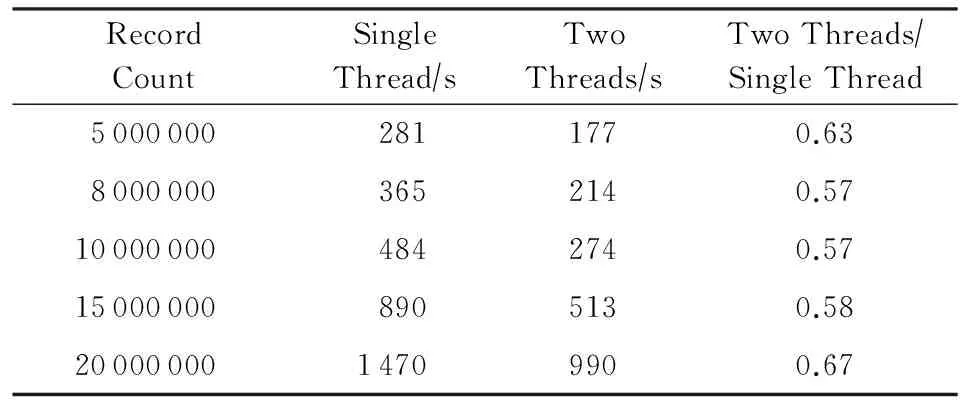
Table 7 Runtime of Flashkv with Single Thread and Two Threads
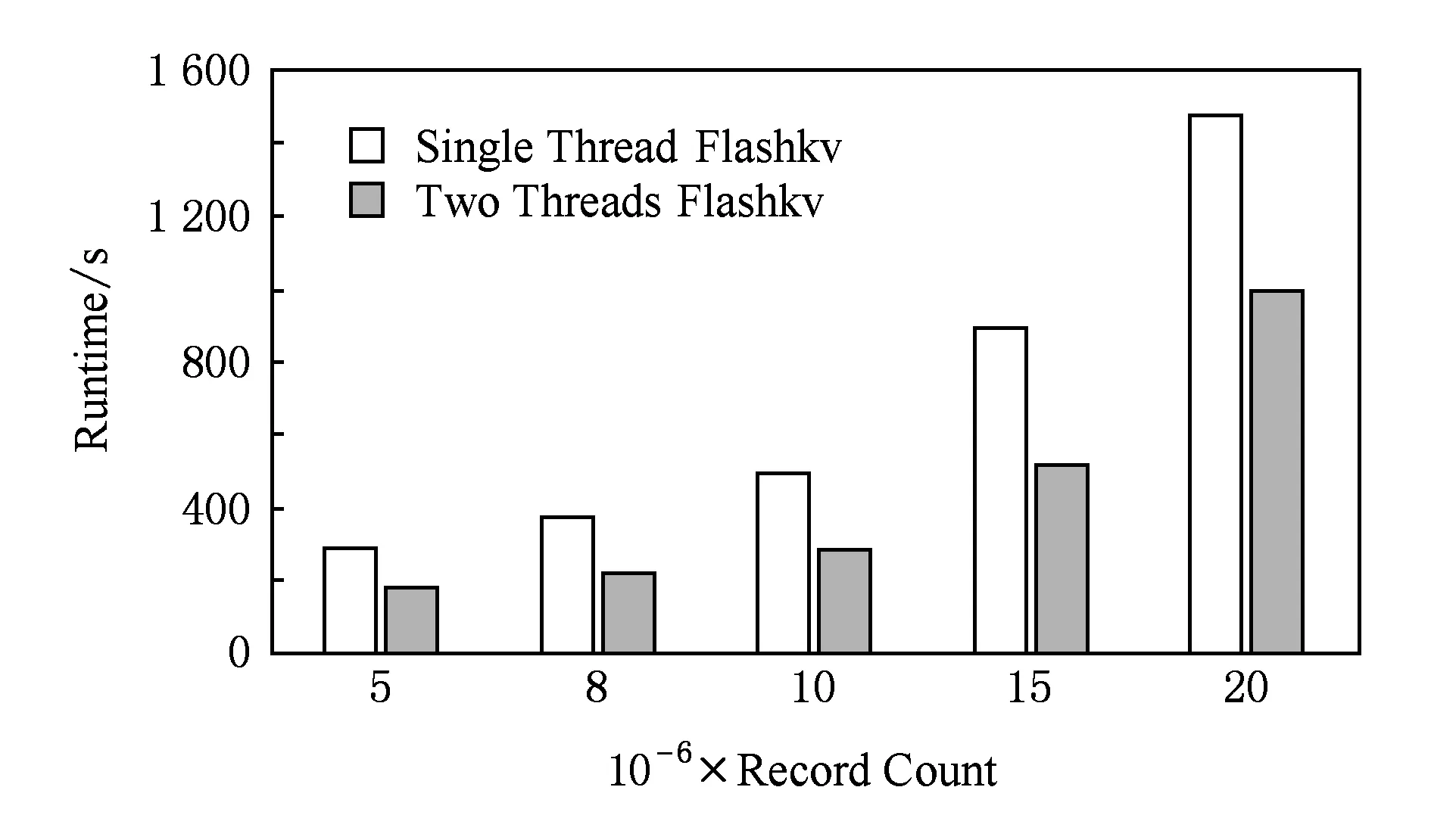
Fig. 11 Time comparison between Flashkv with two threads and one thread图11 双线程和单线程下Flashkv时间对比
双线程版的Flashkv和单线程版的Flashkv时间对比如图11所示,可以看出,在插入相同数量记录的情况下,使用双线程的Flashkv时间为单线程版Flashkv的57%~67%.双线程技术使得compaction操作加速,避免了大量文件堆积在level 0,从而避免了插入操作的阻塞,起到了性能提升的作用.
5 结 论
本文设计实现了一种基于裸闪存的key-value数据库系统Flashkv,通过用户态下的管理单元,Flashkv绕过了文件系统和闪存转换层(FTL),能够在用户态进行高效的空间管理和垃圾回收,从而充分利用了闪存设备内部的并发特性,大大简化垃圾回收过程,缩短I/O路径;提出了基于闪存特点的I/O调度技术,通过I/O调度器对I/O请求按其优先级进行调度,保证优先级高的请求优先得到执行,并用双线程加速了数据库内部的压缩(compaction)操作,优化了闪存的读写延迟,提高了吞吐率;提出了用户态缓存管理技术,降低了数据写入量和频繁系统调用所带来的开销,提升了系统性能.测试结果表明,Flashkv性能是levelDB的1.9~2.2倍,写入量比levelDB减少了60%~65%,Flashkv表现出了明显的性能优势,且写入量也大大减少.
[1]Lu Jiaheng. Big Data Challenge and NoSQL Technology[M]. Beijing: Publishiing House of Electronics Industry, 2013: 45-46 (in Chinese)
(陆嘉恒. 大数据挑战与NoSQL数据库技术[M]. 北京: 电子工业出版社, 2013: 45-46)
[2]Shen Derong, Yu Ge, Wang Xite, et al. Survey on NoSQL for management of big data[J]. Journal of Software, 2013, 24(8): 1786-1803 (in Chinese)
(申德荣, 于戈, 王习特, 等. 支持大数据管理的NoSQL系统研究综述[J]. 软件学报, 2013, 24(8): 1786-1803)
[3]Leavitt N. Will NoSQL databases live up to their promise?[J]. Computer, 2010, 43(2): 12-14
[4]DeCandia G, Hastorun D, Jampani M, et al. Dynamo: Amazon’s highly available key-value store[J]. ACM SIGOPS Operating Systems Review, 2007, 41(6): 205-220
[5]Chang F, Dean J, Ghemawat S, et al. Bigtable: A distributed storage system for structured data[C] //Proc of the 7th USENIX Symp on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2006: 205-218
[6]Lu Youyou, Shu Jiwu. Survey on flash-based storage systems[J]. Journal of Computer Research and Development, 2013, 50(1): 49-59 (in Chinese)
(陆游游, 舒继武. 闪存存储系统综述[J]. 计算机研究与发展, 2013, 50(1): 49-59)
[7]Zheng Wenjing, Li Mingqiang, Shu Jiwu. Flash storage technology[J]. Journal of Computer Research and Development, 2010, 47(4): 716-726 (in Chinese)
(郑文静, 李明强, 舒继武. Flash存储技术[J]. 计算机研究与发展, 2010, 47(4): 716-726)
[8]Chen Feng, Lee Rubao, Zhang Xiaodong. Essential roles of exploiting internal parallelism of flash memory based solid state drives in high-speed data processing[C] //Proc of the 17th IEEE Int Symp on High Performance Computer Architecture. Piscataway, NJ: IEEE, 2011: 266-277
[9]Andersen D G, Franklin J, Kaminsky M, et al. FAWN: A fast array of wimpy nodes[C] //Proc of the 22nd ACM SIGOPS Symp on Operating Systems Principles. New York: ACM, 2009: 1-14
[10]Lee S W, Moon B, Park C, et al. A case for flash memory SSD in enterprise database applications[C] //Proc of the 2008 ACM SIGMOD Int Conf on Management of data. New York: ACM, 2008: 1075-1086
[11]Hu Xiaoyu, Eleftheriou E, Haas R, et al. Write amplification analysis in flash-based solid state drives[C] //Proc of the 2nd Int Systems and Storage Conf. New York: ACM, 2009: 10-19
[12]Shen Zhaoyan, Chen Feng, Jia Yichen, et al. DIDACache: A deep integration of device and application for flash based key-value caching[C] //Proc of the 15th USENIX Conf on File and Storage Technologies. Berkeley, CA: USENIX Association, 2017: 391-405
[13]Wang Peng, Sun Guangyu, Jiang Song, et al. An efficient design and implementation of LSM-tree based key-value store on open-channel SSD[C] //Proc of the 9th European Conf on Computer Systems. New York: ACM, 2014: 16-29
[14]FAL Labs. Tokyo Cabinet: A modern implementation of DBM[OL]. [2017-02-20]. http://fallabs.com/tokyocabinet/
[15]Redis Labs. Redis[OL]. [2017-02-20]. http://redis.io/, 2009
[16]Debnath B, Sengupta S, Li J. SkimpyStash: RAM space skimpy key-value store on flash-based storage[C] //Proc of the 2011 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2011: 25-36
[17]O’Neil P, Cheng E, Gawlick D, et al. The log-structured merge-tree (LSM-tree)[J]. Acta Informatica, 1996, 33(4): 351-385
[18]Ghemawat S, Dean J. LevelDB, v1.14.0[OL]. [2015-03-20]. https://github.com/google/leveldb,http://leveldb.org
[19]Apache Software Foundation. Apache HBase[OL]. [2017-02-20]. http://hbase.apache.org/
[20]Wu Xingbo, Xu Yuehai, Shao Zili, et al. LSM-trie: An LSM-tree-based ultra-large key-value store for small data[C] //Proc of the 2015 USENIX Annual Technical Conf. Berkeley, CA: USENIX Association, 2015: 71-82
[21]Lu Lanyue, Pillai T S, Arpaci-Dusseau A C, et al. WiscKey: Separating keys from values in SSD-conscious Storage[C] //Proc of the 14th USENIX Conf on File and Storage Technologies. Berkeley, CA: USENIX Association, 2016: 133-148
[22]Cooper B F, Silberstein A, Tam E, et al. Benchmarking cloud serving systems with YCSB[C] //Proc of the 1st ACM Symp on Cloud computing. New York: ACM, 2010: 143-154

Qin Xiongjun, born in 1991. Master candidate. His main research interests include file system and key value database.

Zhang Jiacheng, born in 1991. PhD candidate. His main research interests include file and storage systems and non-volatile memories.

Lu Youyou, born in 1987. PhD, assistant researcher. Member of CCF. His main research interests include nonvolatile memories and file systems.

Shu Jiwu, born in 1968. PhD, professor and PhD supervisor. Distinguished member of CCF. His main research interests include network storage system, cloud storage system, and big data storage system, storage security and reliability.
A Key-Value Database Optimization Method Based on Raw Flash Device
Qin Xiongjun, Zhang Jiacheng, Lu Youyou, and Shu Jiwu
(DepartmentofComputerScienceandTechnology,TsinghuaUniversity,Beijing100084)
In recent years, NoSQL key-value databases have been widely used. However, the current mainstream key-value databases are based either on disk, or on traditional file system and flash translation layer, which makes it difficult to utilize the characteristics of flash devices, and also limits I/O concurrency of flash devices. Moreover, garbage collection process under such kind of architecture is complex. This paper designs and implements Flashkv, a key-value data management architecture based on raw flash device. Flashkv doesn’t use file system and flash translation layer, instead, it’s space management and garbage collection are done by the management unit in the user mode. Flashkv makes full use of the concurrent features inside the flash device, and simplifies the garbage collection process and removes redundant function modules which exist in both traditional file system and flash translation layer, and also shortens the I/O path. This paper proposes I/O scheduling technology based on the characteristics of flash memory, which reduces read and write latency of flash memory and improves throughput. The user mode cache management technology is proposed, which reduces write amount and also the cost of frequent system calls. Test results show that Flashkv’s performance is 1.9 to 2.2 times that of levelDB and the write amount reduces by 60% to 65%.
key-value database; flash memory; raw device; data storage; lifespan
2017-02-17;
2017-04-13
国家自然科学基金项目(61327902,61433008);北京市科委课题(D151100000815003) This work was supported by the National Natural Science Foundation of China (61327902, 61433008) and Beijing Municipal Science and Technology Commission of China (D151100000815003).
舒继武(shujw@tsinghua.edu.cn)
TP333
