一种基于Hadoop平台的分布式数据检索系统
2017-06-20曹恒瑞曹展硕
曹恒瑞 +曹展硕


摘要:企业级检索不同于普通的数据检索和网站检索,它包括复杂结构的数据检索、安全检索、高可靠的查全和查准、智能化的数据检索服务和实时的数据更新服务等。虽然可以利用已有数据检索系统提供的站内数据检索功能来构建企业级数据检索系统,但这种站内检索功能难以满足绝大多数企业自身检索需求。随着大数据时代来临,为处理海量数据,建立大数据平台成为趋势,使用分布式文件存储系统,通过云计算技术来分析海量数据,开发企业级智能云检索系统是提高企业综合效益的关键。基于自然语言的智能云检索,研究开发了基于Hadoop平台的分布式数据检索系统,实现了分布式文件系统和传统关系数据库协同运行的高效数据检索系统。
关键词:智能云检索;Hadoop平台;数据检索;企业级检索
中图分类号:TP319
文献标识码:A
文章编号:16727800(2017)004011803
0引言
现代信息技术迅猛发展,企业面对海量数据存储的压力越来越大,导致用户很难找到所需要的信息[12],已有的传统数据库管理系统无法满足企业检索需求。 〖HJ*3/8〗Hadoop可建立分布式集群,企业能够建立属于自己的大数据平台并通过大数据平台处理超大数据集及存储海量数据。为此,本文设计了基于Hadoop平台的分布式数据检索系统。系统包括4个模块[3]:语言处理模块、中间语言处理模块、生成查询SQL模块和权限控制模块。语言处理模块主要负责语言本身的处理,包括切词、词性识别、同义词识别等。此模块提供智慧化的接口,用户可使用自然语言查询需要的信息,通过分词、词性识别等操作,输出结果,〖HJ〗提供给中间语言处理模块处理。中间语言处理模块主要负责将接收到的信息组合成伪SQL,然后通过SQL模块,生成能被数据库执行的SQL语句,得到查询记录集,最后格式化记录集返回给前台查询页面,完成自然语言查询过程。
1系统关键技术
1.1Hadoop技术
Hadoop是分布式处理PB级数据的开源框架,具有可靠性、高效性和可伸缩性,能维护多个工作数据副本,并针对失败节点重新分布处理,以并行工作方式来加速处理数据[4]。Hadoop的可伸缩性使其处理PB级数据得心应手,开源设计和廉价服务器配置使其得到广泛应用。HDFS内部的所有通信都基于标准的TCP/IP协议,HDFS内部机制如图1所示[5]。
1.2Lucene框架
Lucene是非常优秀、成熟且开源的纯Java语言全文索引检查工具包,Lucene拥有高性能、可伸缩的信息检索库IRL(Information Retrieval Library,IRL),可为应用程序添加索引和检索功能。Lucene不是纯粹的引擎,只是引擎框架,实现索引、查询和部分文本解析功能[6],如图2所示。
1.3Solr检索
Solr是基于Lucene Java的企业级检索服务器,易于加入到Web应用程序中。Solr提供层次化检索和高亮显示并支持多种输出文件格式,还有基于Http的管理页面。相对于Lucene的底层检索,Solr更专注于企业应用。 Solr对外提供标准的Http接口实现对数据索引的各项操作,用户可通过Solr部署在Servlet容器中的Web应用来发送命令,Slor接到命令后會以同样的方法回应,Solr特性如下:①高级全文检索功能;②可扩展的插件体系;③综合的HTML管理页面;④专对高通量网络进行优化;⑤使用XML配置达到灵活性和适配性;⑥基于开放接口(XML和HTTP)标准;⑦可伸缩性:能够有效复制到另一个Solr服务器[7]。
1.4Spark Streaming技术
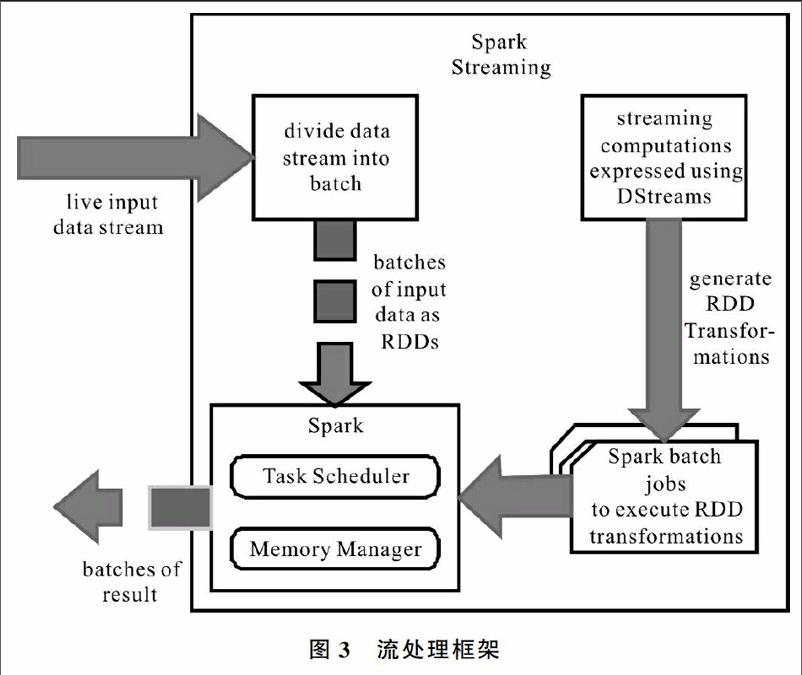
Spark Streaming是基于Spark处理数据的框架。在MapReduce中,由于其分布式特性——所有数据需要读写磁盘,启动Job耗时较大,难以满足时效性要求。Streaming能够在Spark上发展的原因是因为其内存特性、低延时的执行引擎和高速的执行效率。Streaming原理:将Stream数据分成小的时间间隔(比如几秒),即将其离散化(Discretized)并转换成数据集(RDD),然后分批处理RDD。所以Streaming很容易与mlib、Spark SQL等结合,做到实时数据分析处理。此外,Streaming继承RDD的容错特性。如果RDD的某些Partition丢失,可通过Lineage信息重新计算恢复,如图3所示。Streaming的数据源分两种类型: (1)外部文件系统,如HDFS、Streaming可以监控一个目录中新产生的数据并及时处理。如果出现fail,可以通过重新读取数据来恢复,绝不会有数据丢失。 (2)〖JP3〗网络系统:如MQ系统(Kafka、ZeroMQ、Flume等)。Streaming会默认在两个不同节点加载数据到内存,一个节点fail了,系统可通过另一个节点数据重算。正在运行InputReceiver的节点出现fail,可能会丢失一部分数据[8]。
2系统设计
本系统模型及框架由页面展示组建、权限控制组件、自然语言处理组件、企业级数据检索、数据集接口组件组成。页面展示组件就是用户界面,用于用户数据以及反馈结果页面给用户;权限控制组件用于在反馈结果页面添加权限控制,以确保用户数据安全;自然语言处理组件对自然语言进行分词处理,并标注词性,用于后续对应索引库获取参数字段;企业级数据检索,用于对用户输入进行分词处理,并建立索引库;提供接口组件连接文档库、HBase数据库、Web页面等。
系统整合Hadoop分布式数据库和DB2关系数据库实现分布式协同计算框架,通过Spark Streaming流处理技术实现实时索引提高检索效率,通过Lucene和Solr搭建分词服务器并实现词库的自我完善与更新,通过Apache和Tomcat搭建Web服务器。智能云检索系统架构如图4所示。
企业级数据检索引擎是基于全文检索技术实现的,就是系统索引程序基于词库解析文本数据,每一个分词后得到的词语均建立索引,用户可根据索引进行查询并将查询结果呈现。企业数据检索引擎由索引引擎和检索引擎构成,数据检索引擎基于分词工具实现分词并根据分词结果产生多个请求,如图5所示。
3系统实现
数据检索要求实现高性能、高稳定性、高可扩展性,针对数据检索的核心设计包括Web存储集群、索引计算集群、索引服务集群。 Web存储集群(Web Storage Cluster)[9]:主要存放资源文件如网页等,根据系统查询的文件类型如Word、PDF、图片等,都可以存放在Web存储集群中;索引计算集群(Indexing Cluster)[10]:主要用于计算Web存储的文件,生成索引数据和文件,为后续工作做准备;索引服务集群(Index Service Cluster):主要用于存放索引文件并进行查询工作,如图6所示。
数据检索的前端页面并不需要华丽的外表和复杂的界面设计,简洁的页面反而更受用户青睐。对系统前端页面设计沿用常规设计风格,有一个主页标签、检索输入框、检索功能按钮,根据业务需求提供指标、标签、知识、页面、表、翻译等功能候选项。 良好的查询界面对检索系统也是非常重要的,整个查询过程都需要保证页面的整洁有序。如用户查询全省费用户数分布,以及选择TD客户分布情况,查询结果页面效果如图7所示。
4结语
本文对基于大数据平台的智能云检索系统关键技术作了详细介绍。目前大数据技术基本成熟,分布式文件系统对海量数据的存储和处理能力很强,各种大数据开源框架的出现让大数据处理技术变得不再遥不可及,企业可以在低投入的情况下建立自己的大数据平台,根据自身特点研究大数据处理技术,建立企业级数据检索系统,充分利用数据资源为企业创造效益。
参考文献:[1]孟小峰,慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展,2013,34(1):146169.
[2]高明.大数据企业应用探索[J].合作经济与科技,2014,21(3):106107.
[3]艳琳.大数据应用之道[J].科学大观园,2013,12(2):7576.
[4]WU D P ,HOU Y T ,ZHU W W,et al.Streaming video over the internet:approaches and directions[J].IEEE Transactions on Circuits and Systems for Video Technology,2011,21(3):282300.
[5]TRAN D A ,HUA K A ,DO T T.A peertopeer architecture for media streaming[J].IEEE Journal on Selected Areas in Communications,2014,22(2):114.
[6]許波,陈晓龙.UML结合软件工程教学改革探讨[J].计算机教育,2013,25(2):239244.
[7]肖汉,车葵,石艳芳.软件工程[M].北京:国防工业出版社,2013:1020.
[8]冯慧林,朱树人.基于开源技术的Web应用架构研究[J].计算机技术与发展,2015,38(5):2729.
[9]史长民.软件工程:原理、方法与应用[M].北京:高等教育出版社,2014,3660.
[10]Microsoft Media Server.Protocol specification[M].Microsoft Corp,USA,2013:110.
[11]向世静.大数据关键技术及发展[J].软件导刊,2016,15(10):2325.
[12]刘卓,崔忠伟.大数据技术在高校智慧校园中的应用[J].软件导刊,2015,14(8):224225.
(责任编辑:杜能钢)
