基于GRA&BPNN的广西粮食产量预测研究*
2017-06-06戎陆庆欧阳浩
戎陆庆,陈 飞,欧阳浩
(1.广西科技大学管理学院,柳州 545006; 2.广西科技大学计算机学院,柳州 545006)
·粮食安全·
基于GRA&BPNN的广西粮食产量预测研究*
戎陆庆1※,陈 飞1,欧阳浩2
(1.广西科技大学管理学院,柳州 545006; 2.广西科技大学计算机学院,柳州 545006)
[目的]研究粮食产量的影响因素并以其相关性为基础预测粮食产量对实现广西粮食产业的“做强做优”具有重大意义。通常情况下粮食产量与种植技术发展水平、农田耕地面积、土地肥力、气候等诸多因素相关,但是在样本数据不足、数据间关联度不明显的情况下则无法采用回归分析、灰系统等常用预测方法。[方法]文章应用灰色关联分析方法得到水库水量、农田有效灌溉面积、第一产业从业人口、播种面积、除涝面积等5个与广西粮食产量关系最为密切的因子变量,同时取2004~2012年的数据作为学习、训练样本,以2013~2014年的数据为试报样本,并以此建立BP神经网络粮食预测模型。[结果]检验结果表明运用本模型预测粮食产量具有较高的精度和良好的泛化性。[结论]根据模型结果,该文提出提升广西粮食产业发展的可行性建议,即加强水库的管理、引导与粮食产业相关的产业、稳定粮食种植面积、加强洪涝灾害的防御和治理能力、推进农业信息化。
粮食产量 预测 灰色关联分析 BP神经网络 可行性建议 广西
0 引言
在“十二五”期间,广西粮食产业已经发展成为500亿元产业,但作为农业大省区,却大而不强,大而不优。广西自治区政府就此在“十三五”时期提出了将已经形成相当规模的粮食产业作为进一步“做强做优”的目标之一[1]。然后,由于粮食生产与生产技术水平、耕地面积、土地肥力等诸多因素相关,同时依据《广西水资源公报》在2004~2014年的资料数据显示,近年来广西气候长期处于异常,降雨时空分布不均,旱涝灾害比较频繁[2],这些因素都造成广西粮食产量呈现出波动性的变化,因此研究粮食产量的影响因素并对粮食产量的科学预测,对引导和促进粮食产业的进一步发展具有重大意义。
多年以来有很多著名学者致力于粮食产量的预测研究,邓聚龙利用“灰色理论”作了引申与发展,并在此基础上预测了我国1983~2004年粮食的产量[3]; 贾应贤通过分析拟合指数曲线的类型预测了1981~2000年的粮食产量[4]; 黄际民利用灰色理论中的GM(1, 1)预测了江西省1985~2000年的粮食产量[5]; 韦东方利用广西百色市1961~1984年共24年粮食单产资料和影响粮食产量的相关因素,建立了多元线性回归模式预测粮食产量[6]; 陈锡康、郭菊娥通过分析我国1980~1994年的粮食数据,同时使用了18类因素变量,拟合出预测模型,对2030年中国的粮食产量、粮食进口量及自给率进行了预测[7]; 王启平利用BP神经网络(BP neural networks,简称BPNN)模型对我国2001~2010年粮食产量进行了预测,提出BP神经网络对于处理单输入单输出的时间序列预测问题是一种更具优越性的方法[8]; 孙东升、梁仕莹通过HP滤波分析方法将我国1949~2008年的粮食产量数据进行了分离,建立了粮食产量预测的时间序列模型并预测了我国未来10年的粮食产量[9]; 龚波根据湖南省1995~2010年的粮食生产相关数据,利用基于灰色系统理论对湖南省2015年粮食产量数据进行拟合和预测粮食产量预测研究[10]; 周永生等人利用多元线性回归分析方法构建广西粮食产量预测模型对广西2012年的粮食产量进行了预测[11]; 邹璀借助1980~2011年的山东省农业生产的相关数据,使用ARMA和OLS方法相结合建立多个山东省粮食产量预测模型,并预测了2012年山东省粮食产量[12]; 张成才通过利用河南省1996~2011年粮食生产相关的主要影响因素指标数据,建立基于BP神经网络的河南省粮食产量的预测模型并对模型进行了检验[13]。
通过对文献的深入研究发现,学者们主要采用了灰色系统理论、统计学中的回归分析与时间序列、神经网络等数学与计算机模型,这些方法模型各有特点,一方面,采用经济统计分析方法进行预测只要指标选择合适,就能拟合出比较好的预测结果,同时指标具有可解释性,但是这种方法往往又会因有限时间内无法采集到足够的数据或者数据的分布特征不明显,造成预测结果精度不高、指标缺乏连贯的可解释性[3]; 采用灰色预测方法,最大的优点是不需要大量的数据就能进行预测,但若进行中长期预测则必须要满足其发展系数小于等于0.3,一步预测精度为98%,两步和五步高于97%[14]; 采用神经网络模型人工干预少,不需充分了解模型内部结构、不必事先假设前提条件和确定因子权重的情况下,即可较为准确的仿真模型和预测结果[15],但在选择网络隐含层的层次和单元数方面一直缺少相关理论,特别是输入层节点不合理会造成网络的冗余性和局部最优,在一定程度上增加网络的学习负担。另一方面,考虑到农业生产中,由于自然环境的变化因素不可控,同时生产力水平发展较快,新技术、新方法不断涌现,单纯应用传统的统计分析、灰系统理论等方法很难有效地分析得出造成农业投入与产出模式之间的非线性增长关系的动因,若能将上述方法结合则有助于解决预测模型使用的局限,更好的实现对广西粮食产量的分析与预测。因此,文章重点研究了在无法获取大量(服从特定分布)历史数据的前提下,采取灰色关联分析方法(Grey Relational Analysis,简称GRA)确定影响广西粮食产量的主要关联因素,利用2004~2012年的所搜集的文献资料及《广西统计年鉴》的相关数据作为学习、训练样本,以2013~2014年的数据为试报样本,并以此建立BP神经网络的广西粮食产量预测模型。
1 相关理论介绍
1.1 灰色关联度分析
灰色关联度分析是灰色系统理论的一种主要方法,即在有限数据的情况下,通过一定的方法明确系统内各个要素之间的主要关系,寻找影响最大的那些因素,把握矛盾的主要方面。它最大的特点在于,不同于传统的统计方法,对样本的数据量和规律性没有要求,它的基本思想是根据数据序列曲线的几何形状的相似度来判定其联系的紧密程度。一般地,曲线越接近,相应数据序列间的关联度就越大,反之就越小。
进行灰色关联度分析的计算过程和处理步骤可以分解如下,首先对原始数据序列进行变换,可以采用初值法、均值法和区间值法都可以将系统行为数据序列化为无量纲且数量级相同的序列,在实际操作中,一般采用初值法进行无量纲化处理。
设母因素序列数据为X0,子因素序列数据为Xi(i=1, 2,…,m),即
X0=(x01,x02,x03,…x0n),Xi=(xi1,xi2,xi3,…xin)
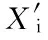
(1)
算出序列间的绝对差Δ0i(k)、绝对差最大值Δmax和最小值Δmin,获得求解灰色关联系数L0i(k),即
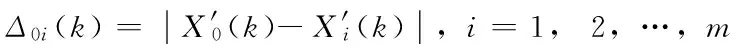
(2)
(3)
(4)

(5)
式中,ρ称为分辨系数,该系数的引入可以在很大程度上削弱最大绝对差数值太大引起的失真,提高关联系数之间的差异显著性,一般情况下可取0.1~0.5; 同时,因为是比较序列数据相交,一般取Δmin=0。
最后求出子因素序列数据与母因素序列数据的关联度,即
(6)
式中,r0i表示第i个子因素序列数据与母因素序列数据0的关联的密切程度,n代表子因素序列数据的长度,即该数据序列数据的个数。
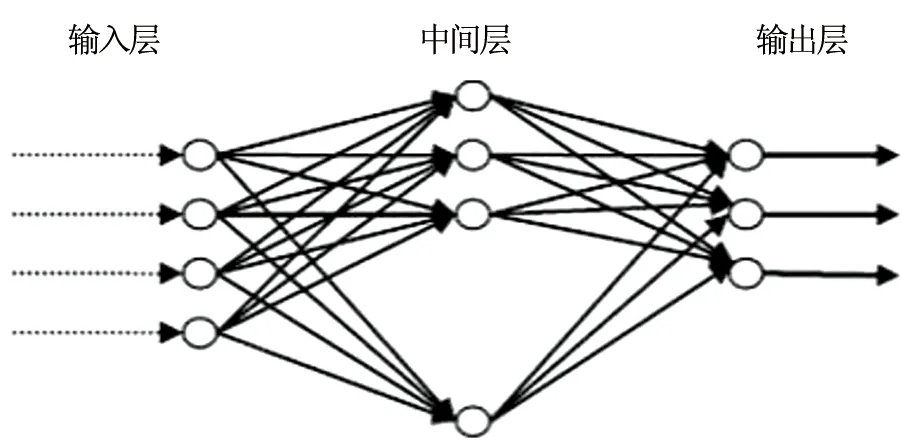
图1 BP神经网络模型
1.2BP神经网络概述
人工神经网络是20世纪80年代开始逐渐受到研究学者重视的一种新式人工智能算法,它能够模拟人脑的思维模式(具备一定的智能特征),被用以解决大量传统方法难于解决的大型或者复杂问题。该算法通过模仿人的大脑神经细胞的结构展开,并由此思路设计出了许多不同的模型,其中BP(BackPropagation,向后传播)神经网络是人工神经网络中最具代表性的模型[15]。该模型网络的训练学习采用了误差反向传播算法,即可以依据实际输出结果与理想输出结果的差值来调整和修正权值,在进行反复训练的过程中缩小其差别,最终使得实际输出结果与理想输出结果趋向于接近或者一致。
BP神经网络模型采用三层结构:输入层、输出层及含有一个或多个隐含层节点的中间层(图1),包括节点输出模型(包括隐节点和输出节点)、作用函数模型、误差计算模型和自学习模型[16],它的工作原理为:对于输入信号,要先向前传播到隐含层节点,经过作用函数后,再将隐节点的输出信号传播到输出节点,最后给出输出结果[15](具体计算公式如公式7~11)。
Oj=f(∑WijXi-q)
(7)
Yk=f(∑TkjOj-qk)
(8)
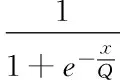
(9)
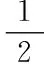
(10)
自学习模型:ΔWij(n+1)=h×Φi×Oj+a×ΔWij(n)
(11)
其中,f为非线性作用函数,q为神经元阈值,tpi为期望输出值,Opi为节点计算输出值,h为学习因子,φi为输出节点的计算误差;Oj为输出节点的计算输出,a为动量因子。同时,由于BP网络的初始化权值和阈值是随机取得,它的训练过程是一个不断更新迭代的过程,因此每次运行计算结果不一致,可取多次运算结果中误差最小的网络作为研究所需要的神经网络模型。
2 广西粮食产业与其相关因素的灰色关联效应分析
进行广西粮食产业预测,一般需要首先确定对粮食产量具有主要影响的因素。特别是采用BP神经网络建立预测模型,为了避免网络输入层神经元节点(也称为系统的特征因子或者自变量)个数过多,造成网络训练时间延长及使得训练陷入局部最优而得无法获得神经网络的最优[15],因此有必要首先从众多可能的影响粮食产量的因素中寻找最主要的指标变量,参考已发表的文献可以发现,学者们对于影响粮食产业的相关因素有较多的看法,如张素文、李晓青在《湖南省粮食生产变化趋势及影响因子研究》中使用了粮食播种面积、有效灌溉面积、自然灾害成灾面积、化肥施用量、粮食价格指数、农机总动力、年降水量等9个因素[17]; 周永生等在《基于多元线性回归的广西粮食产量预测》中应用了粮食种植面积、粮食单产、年平均降水量、劳动力数量等4个因素[11]; 张浩在《基于AIGA-BP神经网络的粮食产量预测研究》选取了粮食播种面积、有效浇灌面积、化肥的使用量、农村生产用电量、农机化动力、粮种品质等8个影响产量的因素[18]。考虑到指标的通用性、可理解性及可量化等方面因素,文章综合选取了7方面可能影响粮食产量的因素,分别是土地资源、生产条件投入、农田水利设施、防寒除涝投入、水土保持情况、人力投入、自然条件,进一步将这7个影响因素细分为15个指标(表1),具体为播种面积(X1)、农业生产用电量(X2)、化肥施用量(X3)、农业机械总动力(X4)、水库数量(X5)、水库库容量(X6)、农田有效灌溉面积(X7)、农用水泵(X8)、节水灌溉面积(X9)、除涝面积(X10)、水土流失治理面积(X11)、堤防总长度(X12)、堤防保护耕地面积(X13)、第一产业从业人口(X14)、年平均降雨量(X15),该文中所用数据均来自《广西统计年鉴》及《广西水资源公报》中2004~2014年的公开数据[19],为了便于进行广西粮食产量与影响因子变量的灰色关联分析,使用广西2004~2014年历年粮食总产量(Y)作为母序列数据,其它指标变量的历年数据作为子序列数据,分辨系数设为0.5,利用公式1~6运算后得到下表的最终结果(表2)。
表1 广西粮食产业影响因素

粮食产量影响因素指标计量单位土地资源播种面积(X1)万hm2生产条件投入农业生产用电量(X2)亿kW·h化肥施用量(X3)万t农业机械总动力(X4)亿W农田水利设施水库数量(X5)座水库库容量(X6)亿m3农田有效灌溉面积(X7)万hm2防旱除涝投入农用水泵(X8)台节水灌溉面积(X9)万hm2除涝面积(X10)万hm2水土保持情况水土流失治理面积(X11)万hm2堤防总长度(X12)km堤防保护耕地面积(X13)万hm2人力投入第一产业从业人口(X14)万人自然条件年平均降雨量(X15)mm

表2 广西粮食产量的灰色关联结果
从表2可知,ri≥0.6(i=1, 2,…, 15)即所有变量都与粮食产量存在较好相关性,但是ri的值越接近1,子序列数据与母序列数据之间的相关性越好,由计算可知r5>r7>r14>r1>r10>0.9,故水库水量、农田有效灌溉面积、第一产业从业人口、播种面积、除涝面积等5个因子变量与广西粮食产量的关系最为密切,而变量堤防保护耕地面积、年平均降雨量、节水灌溉面积、堤防总长度、化肥施用量、水土流失治理面积、水库库容量、农用水泵、农业机械总动力、农业生产用电量等9个因子变量与广西粮食产量的密切程度依次差一些。因此,选择排名在前5的变量作为神经网络输入层的系统特征因子。
3 广西粮食产量的BP神经网络预测模型
一般情况下,BP神经网络的网络层数设为3层就可以满足需要,利用灰色关联分析获得的系统特征因子,由公式7~11即可建立的预测模型。算法模型发展至今已经非常成熟,但是过程中计算量较大,目前绝大多数都可以通过数学软件实现该过程,比较有代表性的是Matlab神经网络工具箱或者DPS系统。通过播种面积(X1)、水库水量(X5)、农田有效灌溉面积(X7)、除涝面积(X10)、第一产业从业人口(X14)等5个因子变量与广西粮食产量(Y)构建BP神经网络,取2004~2012年数据作为学习、训练样本,将2013年和2014年的数据作为试报样本,网络设计的参数具体为:隐含网络层数为1,输入层节点数为5,最小训练速率为0.3,动态参数为0.7,Sigmoid参数为0.9,允许误差设为0.00001,最大训练次数为1000次,通过利用DPS进行标准化数据处理(图2),整理后的结果如图3~4、表3~5。
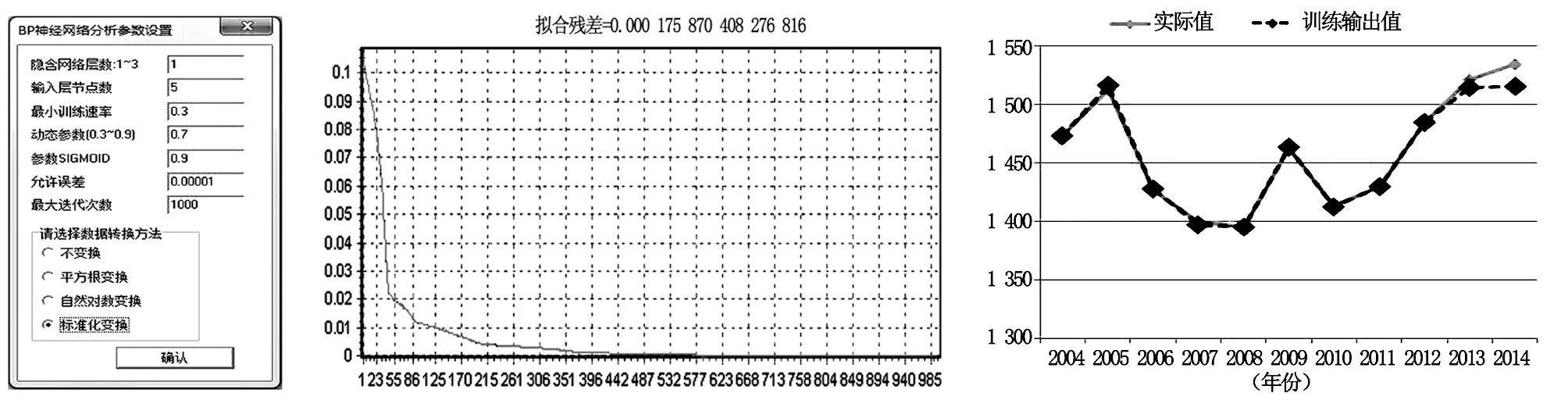
图2 神经网络参数设置对话框 图3 神经网络的拟合误差 图4 广西2004~2014年粮食产量趋势注:图4,虚线数据中2004~2012年为训练输出值,2013~2014年为试报结果
表3 BP网络的权重矩阵
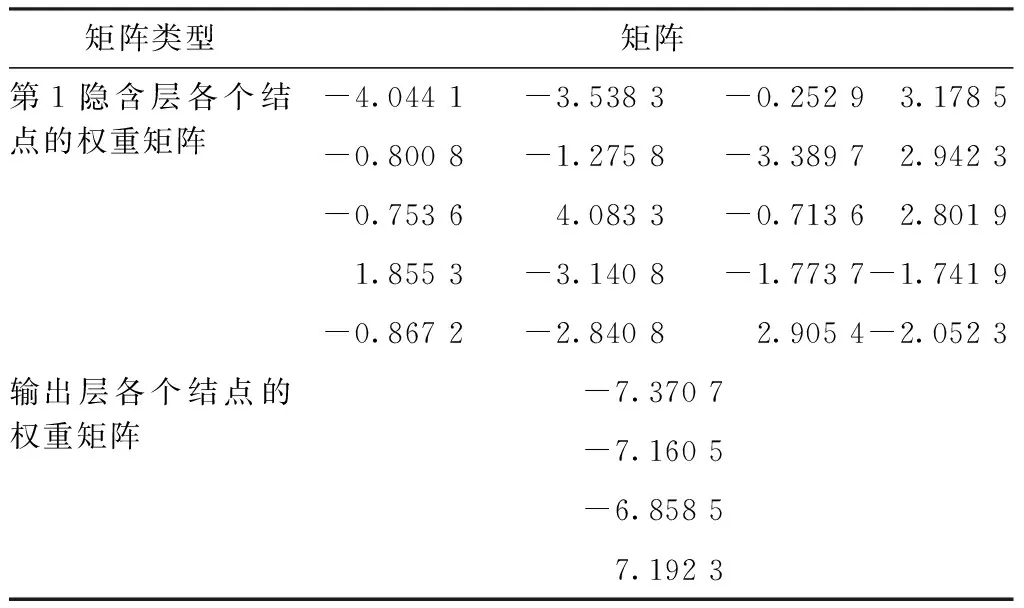
矩阵类型矩阵第1隐含层各个结点的权重矩阵-4.0441-3.5383-0.25293.1785-0.8008-1.2758-3.38972.9423-0.75364.0833-0.71362.80191.8553-3.1408-1.7737-1.7419-0.8672-2.84082.9054-2.0523输出层各个结点的权重矩阵-7.3707-7.1605-6.85857.1923
表4 神经元网络训练结果

年份200420052006200720082009201020112012实际值1473.11516.291427.581396.61394.71463.21412.321429.931484.9训练输出值1473.561512.821427.291399.631395.391462.531413.3214301484.75相对误差(%)0.0310.2290.0200.2170.0490.0460.0710.0050.010
由上图可以看出,将网络隐层的神经元个数设为4个,设置BP数据网络模型运行1000次,在网络模型运行到985次时样本拟合误差MSE等于0.00017587,已达到误差要求,此时BP数据网络模型对2013年及2014年广西粮食产量的预测值分别是1514.18万t、1516.01万t,通过对结果进行绘制折线图处理,得出广西在2004~2014年粮食产量的趋势图(图4)训练及试报的结果及误差分析充分说明了BP模型被应用于广西粮食产量的预测,不仅对历史资料拟合的结果精确率较高,而且最近两年的试报结果也比较准确,相对误差不足2%,具有良好的泛化能力。
4 结语
通过对广西粮食产量灰色关联度以及BP神经网络预测的分析可知,选取与广西粮食产量的关系最为密切的水库水量、农田有效灌溉面积、第一产业从业人口、播种面积、除涝面积等5个灰色关联变量作为BP神经网络的系统特征因子开展训练实例学习,足以建立自变量与因变量之间的非线性映射关系[15],并且能够拟合得出较为准确的粮食产量预测模型。对拟合数据及预测结果进行研究表明,该文应用灰色关联与BP神经网络建立广西粮食产量预测模型是一种有效、拟合精度相对较高的预测方法。
灰色关联的分析结果(表2)及BP神经网络模型预测结果(表4~5)表明,由于目前影响广西粮食产量的灰色关联因素历年取值偏低,使得预测拟合值偏小,这也进一步说明未来广西粮食产业潜力还有待进一步挖掘及发挥。
表5 神经元网络试报结果
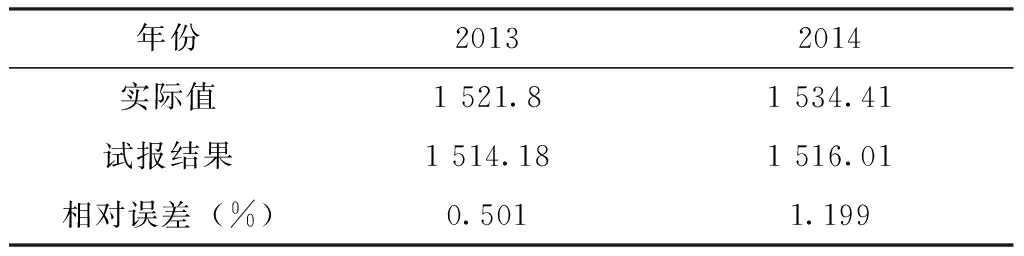
年份20132014实际值1521.81534.41试报结果1514.181516.01相对误差(%)0.5011.199
因此,文章拟结合水库水量、农田有效灌溉面积、第一产业从业人口、播种面积、除涝面积等5个与广西粮食产量高度灰色关联的因素,围绕如何提高粮食产量、提升粮食产业在广西国民经济中的影响地位提出以下的可行性建议。
(1)加强水库的管理,加大广西水库工程的资金投入。截止2014年末,广西有4545座水库,其中大型水库39座,中型水库169座,剩余均为小水库[2],它们的修建时间绝大多数都是在1958年前后,由于当时建筑质量标准较低[20],经过多年运行,很多质量方面的问题逐渐凸显,依据《广西水资源公报》报告当前有30%以上的水库(特别是中小水库)坝体存在质量问题,由于长期资金短缺,很多中小水库除险加固无法得以完成,多年来只能控制在低水位运行,使得水库防洪能力减弱,农田的有效灌溉面积减少[21]。因此有必要在政策上建立制度,强化对水库的管理,着力保障对水库工程的修缮和维护,同时在合理使用中央政府专项维修基金的基础上,拓展水库运营资金的来源渠道,以保证广西的水库正常运转,最终有利于水库水量增加,实现水资源充分有效利用及扩大农田有效灌溉面积。
(2)引导与粮食产业相关的产业,为农民提供更多就近务工的机会,开拓渠道促进农民创收。2014年广西农民人均纯收入为7565元,而广西城镇居民人均可支配收入为2.466 9万元[19],收入差距造成农村的青壮年劳动力流入城市或者经济发达的其他省区,这必然造成广西农村从事粮食生产的劳动力减少。因此,广西地方政府应当适时出台政策,一方面鼓励与农业生产(特别是粮食生产)相关各类产业企业到广西落户,吸引剩余劳动力就业; 另一方面,加强农村劳动力的创业就业培训[22],鼓励农民在农村市场创业,如建立现代特色农业(核心)示范区、“互联网+现代农业”、特色种植、乡村特色旅游等[1],并为其提供资金及技术支持; 同时,持续加大从事粮食生产的补贴力度和资金投入强度[1]。这些措施一旦施行,将会在很大程度上稳定广西第一产业的从业人口,避免因收入差距而出现流失。
(3)稳定粮食种植面积,提高土地肥力。一方面,当前广西农业土地稀缺、粮食播种面积增加有限,为了增加粮食产量,应当在制度上严格实施耕地保护,避免出现农用地被流转改变其用途的现象[23],特别是要控制建筑及工业生产用地对农用地的侵蚀行为,与此同时构建土地节约集约利用新模式,在广西粮食种植区大力加强田、水、路、林村的综合整治,有计划有步骤地建成一批高标准农田; 另一方面,在广西有限的粮食种植土地上着力推进“沃土工程”,实现耕地的全面保护与其质量的提升,通过采取测土施肥、地力培肥(如冬种绿肥、秸秆还田技术、有机肥应用)、酸化土壤改良、节水节肥、完善耕地质量监测网络等主要方式[22],逐步地提升现有耕地的内在质量。
(4)加强洪涝灾害的防御与治理能力,大力发展民生水利,扩大治涝面积。广西位于中国南疆,南临北部湾,雨量丰沛,水系发达,但由于降雨时空分布不均,80%的降雨都集中在每年的4~9月,依据气象资料统计,每年约有3~4个台风和热带风暴影响,是一个洪涝灾害频繁、灾情较重的省区[24]。因此,通过工程措施(如修建防洪堤、大型水利设施)、非工程措施(预警预报、风险评估、科学调度、灾后再生产等)、重视植物措施(水土保持、防风林建设、营造海上红树林等)三方面配合加强洪涝灾害的防御与治理能力,实现易涝耕地免除淹涝,这将有利促进粮食产量稳中有升。
(5)推进广西农业信息化,加快广西农村信息化的普及。一方面,通过政策鼓励区内的高等院校和培训机构深入农村,建立适合于广西农业特别是粮食产业发展所需要的信息人才培养模式,并为广大农村提供实现信息化的智力支撑[25]; 另一方面,政府及相关行业应当加大经费投入,加强农村基础通信设施的建设与普及,同时免费为广西农民特别是青壮年开展信息技术培训,从整体上提升第一产业从业人口信息素养和信息能力,以知识信息进一步促进广西粮食产业“做强做优”。
[1] 覃泽林,李耀忠,秦媛媛.等.“十三五”广西现代农业面临的挑战与发展思路.南方农业学报, 2015, 46(5): 943~950
[2] 广西壮族自治区水利厅. 广西水资源公报.http://www.gxwater.gov.cn/Web/ArticleList.aspx?CategoryID=25
[3] 邓聚龙. 粮食的灰色模糊预测与控制.华中工学院学报, 1983,(2): 1~8
[4] 贾应贤, 周利国.粮食产量的预测.预测, 1985,(1): 46~54
[5] 黄际民. 江西省粮食产量灰色系统预测模型的建立.江西师范大学学报(自然科学版), 1985,(3): 47~52
[6] 韦东方. 运用多元线性回归模式预测粮食产量.预测, 1986,(4): 47~48
[7] 陈锡康, 郭菊娥.中国粮食生产发展预测及其保证程度分析.自然资源学报, 1996,(11): 197~202
[8] 王启平.BP神经网络在我国粮食产量预测中的应用.预测, 1996,(3): 79~80
[9] 孙东升, 梁仕莹.我国粮食产量预测的时间序列模型与应用研究.农业技术经济, 2010,(3): 97~106
[10]龚波, 肖国安,张四梅.基于灰色系统理论的湖南粮食产量预测研究.湖南科技大学学报(社会科学版), 2009,(5): 62~65
[11]周永生, 肖玉欢,黄润生.基于多元线性回归的广西粮食产量预测.南方农业学报, 2015, 42(9): 1165~1167
[12]邹璀, 刘秀丽.山东省粮食产量预测研究.系统科学与数学, 2013, 33(1): 97~109
[13]张成才, 陈少丹.BP神经网络在河南省粮食产量预测中的应用.湖北农业科学, 2014, 53(8): 1969~1971
[14]刘思峰, 谢乃明.灰色系统理论及其应用.北京:科学出版社, 2013: 48~65
[15]王庚, 王敏生.现代数学建模方法.北京:科学出版社, 2009: 151~200
[16]赵书兰.MATLAB建模与仿真.北京:清华大学出版社, 2013: 454~469
[17]张素文, 李晓青.湖南省粮食生产变化趋势及影响因子研究.国土与自然资源研究, 2005,(1): 30~31
[18]张浩. 基于AIGA-BP神经网络的粮食产量预测研究.中国农机化学报, 2016, 37(6): 205~209
[19]广西壮族自治区统计局. 广西统计年鉴.http://www.gxtj.gov.cn/tjsj/tjnj/
[20]谭宝辉, 黄勇.浅谈广西水库工程管理现状与对策.广西水利水电, 1999,(2): 64~66
[21]陈长生. 广西小型水库安全运行管理对策研究.广西水利水电, 2016,(3): 93~95
[22]欧阳浩, 戎陆庆,黄镇谨,等.基于粗糙集方法的广东省粮食产量影响因素分析.中国农业资源与区划, 2014, 35(6): 100~107
[23]欧阳浩, 戎陆庆,王智文,等.广东省农林牧渔业与其他产业的关联效应分析.中国农业资源与区划, 2015, 36(1): 96~101
[24]胡志东, 胡锦钦.浅议广西城乡洪涝灾害及防范措施.珠江现代建设, 2011,(6): 25~27
[25]戎陆庆, 欧阳浩,韦克脉.广西信息产业的关联效应分析.广西工学院学报, 2013, 24(4): 91~97
PREDICTING GRAIN YIELD OF GUANGXI PROVINCE BASED ON GRA&BPNN*
Rong Luqing1※, Chen Fei1,Ouyang Hao2
(1. Management School, Guangxi University of Science and Technology, Liuzhou 545006, China; 2. Computer School, Guangxi University of Science and Technology, Liuzhou 545006, China)
It plays a great significance for Guangxi grain industry to be getting stronger and more excellent by studying the relevant factors of the grain yield and predicting yield based on its correlation. Generally,grain production is relevant to the development level of planting technology, the amount of agricultural cultivated land acreage, soil fertility, climate and other factors, the general methods of regression analysis and grey system can hardly be used for the prediction at the background of limitations of sample size and correlational data. This paper got 5 variables which were the most close related to the Guangxi grain yield, including the amount of reservoir water, effective irrigation area, working population of the first industry, planting area, and drainage area of waterlogged elimination using grey relational analysis (GRA) method, and established BP neural networks(BPNN) prediction model of grain yield based onthe data in 2004~2012 as training samples and the data in 2013~2014 as test report samples. The results showed that the model using in the prediction of grain yield had high precision and good generalization. At last, it put forward the feasible proposals in the interest of promotion and development of grain industry in Guangxi based on the model results, including strengthening the management of the reservoir, guiding the relevant industries of the grain industry, keeping the amount of grain acreage, improving the defensing and processing abilities of flood disaster, and promoting agricultural information technology.
grain yield; prediction;GRA; BPNN; feasible proposals; Guangxi province
10.7621/cjarrp.1005-9121.20170215
2016-08-24 作者简介:戎陆庆(1982—),男,重庆人,硕士、实验师。研究方向:系统优化与决策分析、农产品物流。Email:rongluqing@tom.com *资助项目:国家社科基金项目“新型城镇化背景下西部地区城市少数民族民生问题研究”(15XMZ078); 广西哲社规划课题项目“广西先进制造业服务化技术支持体系研究”(15DGL001)
S126; F326.11
A
1005-9121[2017]02105-07
