利用主题内容排序的伪相关反馈*
2017-06-05高光来
闫 蓉,高光来
内蒙古大学 计算机学院,呼和浩特 010021
利用主题内容排序的伪相关反馈*
闫 蓉+,高光来
内蒙古大学 计算机学院,呼和浩特 010021
传统的伪相关反馈(pseudo relevance feedback,PRF)方法,将文档作为基本抽取单元进行查询扩展,抽取粒度过大造成扩展源中噪音量的增加。研究利用主题分析技术来减轻扩展源的低质量现象。通过获取隐藏在伪相关文档集(pseudo-relevant set)各文档内容中的语义信息,并从中提取与用户查询相关的抽象主题内容作为基本抽取单元用于查询扩展。在NTCIR 8中文语料上,与传统PRF方法和基于主题模型的PRF方法相比较,实验结果表明该方法可以抽取出更符合用户查询的扩展词。此外,结果显示从更小的主题内容粒度出发进行查询扩展,可以有效提升检索性能。
主题模型;主题内容;伪相关反馈
1 引言
查询扩展(query expansion,QE)技术[1]可以有效弥补用户查询信息不足造成的用户表达问题,通过在用户初始查询中增加与其语义相近词项的方式,将用户初始查询中未充分表达的内容展示出来。QE按照是否考虑初检结果文档集,分为全局和局部两种技术。在局部QE技术中,按照是否考虑初检结果文档集中与用户查询真正相关的文档,又可以分为相关反馈(relevance feedback,RF)和伪相关反馈(pseudo relevance feedback,PRF)两种方法。RF方法利用与用户查询真相关文档对用户查询进行重构。然而,这种方法要求用户将初检结果标注为相关或不相关,这在用户的真实检索过程中是很难实现的。相反,PRF方法[2]是一种与用户行为无关、简单有效的自动QE方法,其简单假设初检(first-pass)结果集中前k个文档与用户初始查询相关,构成伪相关文档集(pseudo-relevant set),并从中按照某种方式自动地抽取扩展词,然后将扩展词加入到初始查询中,优化初始查询后进行二次检索(second-pass)。影响PRF检索性能的直接和主要因素是伪相关文档集中的文档质量。PRF方法研究中有大量的工作,都是围绕如何提高伪相关文档集文档质量的,其本质就是如何提升扩展源质量。目前,相关研究[3-7]主要集中在对从词项空间(term space)[3-4]和主题空间(topic space)[5-7]中获取的统计信息提出的各种相关方法。这些研究工作中,大多数的工作都致力于找到一种有效二值判别方法,其主要策略是将伪相关文档集中的文档,利用判别方法区分为与用户查询相关和不相关,然后从判别为相关的文档中提取扩展词来重构用户初始查询,达到提高检索性能的目的。但以上这些方法均是以文档作为整体来判别其是否与用户查询相关,即将文档作为扩展词选取单元。显然,片面地将文档作为待区分单元,直接标定为与用户查询相关或不相关是不合适的,不能保证扩展源质量,增加了噪音量,导致“主题漂移”(topic drift)现象出现。本文认为,将文档作为扩展源的抽取基本单元过于简单和粗糙,不利于扩展词的选取。本文尝试从更细微的粒度——文档内容本身出发,不再以文档作为判别基本单元,利用主题分析技术,构建文档主题内容排序框架,将在主题空间抽象表示的文档内容作为待区分单元,将判别为与用户查询相关的文档内容作为扩展源。
2 相关工作
PRF算法假设简单,实现机制通俗,是一种有效的提高检索系统整体性能的方法[3-7]。然而,传统的PRF方法并不是针对所有查询都有效,某些查询经过反馈处理后,检索效果反而会很差[8-9],这也是制约PRF方法不能在实际检索中应用的根本原因。为了提高PRF检索的鲁棒性,研究者们提出了很多解决方法和策略[9-12]。文献[9]提出了一种带有约束的优化方法,用于降低反馈行为带来的负面影响;文献[10]提出利用EM算法减少PRF模型对于反馈文档数量的敏感性;文献[11]利用多种反馈模型提出一种启发式的非监督方法;文献[12]综合几种伪反馈方法,研究如何既保证PRF的鲁棒性,同时又兼顾整体性能有效性的方法。
但上述诸方法研究和扩展处理的对象,均是以文档作为基本处理单元和粒度,未从更细微的文档内容本身考虑与用户查询的相关性,会直接导致主题偏移现象,影响检索性能。
近年来,潜在主题模型[13]这种主题分析(topic analysis)技术被用于文本内容的分析处理。文献[7]尝试通过对整个伪相关文档集上建立与用户查询相关的主题模型TopicRF,抽取与用户查询相关的主题信息,来提高PRF的检索性能。但其本质上还是以文档作为扩展源单元。
本文的研究工作也并没有直接区分伪相关文档集中各文档的相关性。但与文献[7]工作不同的是,本文所关注的伪相关文档集质量是文本本身内容的质量。本文认为在伪相关文档集中包含的若干主题中,只有部分是与用户查询相关联,对反馈行为有效。在对用户实际查询需求不明确的情况下,在伪相关文档集中,如何利用多样化思想,彰显文档中与用户查询相关的那部分主题内容来进行扩展词的选取,就是本文关注的核心和重点。具体实现可以描述为:首先对整个文档数据集建立主题空间,然后对伪相关文档集中每个文档进行主题分析,从浅层语义角度出发,充分挖掘这些文档内容中与用户信息需求相关的潜在语义信息,突显刻画主题特性的描述词,并从中抽取扩展词实施伪反馈。
3 基于主题内容排序的伪相关反馈
3.1 主题内容排序
概率主题模型(probabilistic topic model,PTM)是一种利用贝叶斯方法,通过构造词项-主题-文档三层结构,对数据进行抽象建模的方法。通过引入主题变量(latent topic)概念,将数据集中共同隐含的信息描述出来。本质上,对数据集进行主题建模其实就是构建合适的文档语义描述空间。假设对有M个文档,存在V个不同词项(keyword)的数据集进行主题建模,每个文档会被表示成K个主题变量的概率分布(topic distribution),记为θ∈RM×K,每一个θj,i表示第j个文档中主题i所占比重,它是从文档角度获得的语义信息。同时,主题变量被表示成各词项的概率分布(word distribution),记为Φ∈RK×V,每一个ϕi,m表示在主题i中生成第m个词项的概率值,它是从数据集角度获得的语义信息。通常,上述两种语义信息可以认为是数据集的特征信息,这些特征信息不仅包含丰富的语义,而且还具有很强的区分性[14]。但面对结构复杂多样和信息量巨大的Web信息资源时,这两个分布获得的过程抽象,最终结果也抽象,用户很难理解数据集的主题分析结果。另外,常常会发生同一词项在多个主题中出现的情况,各主题并不是孤立的存在,这会进一步增加用户理解主题结果的负担。因此在实际应用中,为了有效利用数据集的主题建模结果的特征区分特性,非常有必要对主题建模结果进行排序。通常意义下,对主题建模结果的排序,即是对主题内容的排序。一般的,主题内容排序[15]的方式有两种,包括主题分布中的词项排序和主题分布排序。
Cao等人[16]研究表明,PRF选取的扩展词数目并不是越多越好,过多的扩展词反而会降低检索性能;文献[17]分别对8个不同的检索系统,针对查询扩展中词项数目的选择进行了详细实验,其结果表明,针对主题对象来选择扩展词项将有助于提升检索的性能。本文提出的PRF方法,目的是通过浅层语义信息来改善反馈扩展词质量,提高查询效率。因此,本文对于伪相关文档集中文档的主题内容排序,主要完成以下三方面工作:
(1)文档主题分布中的词项排序。实现用突显刻画主题特征的特征词项来表示主题。
(2)文档的主题分布排序。按照与用户查询的相关程度,将各个主题进行排序,实现用有限有效主题表达文档,使得这些主题中的特征词项可以分别具有将主题之间相互区别和文档之间相互区别的特性。
(3)从文档内容的主题表达结果中,针对判别为用户查询相关的内容,抽取扩展词项进行二次反馈。
下面将分别对这三方面工作进行详细阐述。
3.2 文档主题分布中的词项排序
对数据集进行主题建模得到的词项-主题分布Φ中的各词项,已经按照其对所描述主题的概率值大小进行排列,但概率排列分布与各词项对于描述其所在特定主题语义的贡献分布描述是不一致的[18]。文献[15]为了使文档的Φ分布表达更易于理解,提出类似TF-IDF(term frequency-inverse documentation frequency)方法,计算每个词项描述特定主题的权重(weight),来重新衡量描述主题中各词项的重要程度。文献[14]提出用词项显著度(term significance)来定义主题与文档中包含的各词项分布间的距离,用于特定领域的主题推荐和自动文摘。尽管这些方法计算权重的角度不同,但其目的都是将每个主题描述为有限有效词项,即将描述Φ分布中那些对主题语义描述差或贡献度低的词项过滤掉。本文沿用文献[15]计算各词项权重的方法,将描述主题含义的各个词项,按照计算得到的词项权重值进行排序,并依此排序结果,过滤掉那些使得主题间语义区分度小的词项,获得更能描述主题的有限词项组成的集合。各词项权重值的计算如式(1)[15]所示:
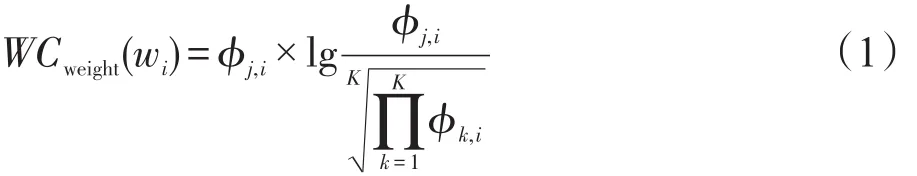
其中,wi表示主题 j(j∈[1,K])中第i个词项,i∈[1,V]。
本文采用标准的主题建模方式LDA(latent Dirichlet allocation)[13]对数据集建模。LDA假设主题变量服从Dirichlet分布,即主题之间是相互独立的。但事实上,利用LDA对文本建模的结果,存在同一词项同时出现在多个不同主题分布中的情况,这使得词项信息不能很好地完成刻画主题特征的任务,即影响主题间的差异性。本文关注的是如何利用主题信息来区分文本内容与用户查询的相关性,保持词项信息对主题内容刻画的互异性,也就是保证在主题数目确定的情形下,不降低LDA表示数据的能力。这里对式(1)做了适当的变型,如式(2)所示:
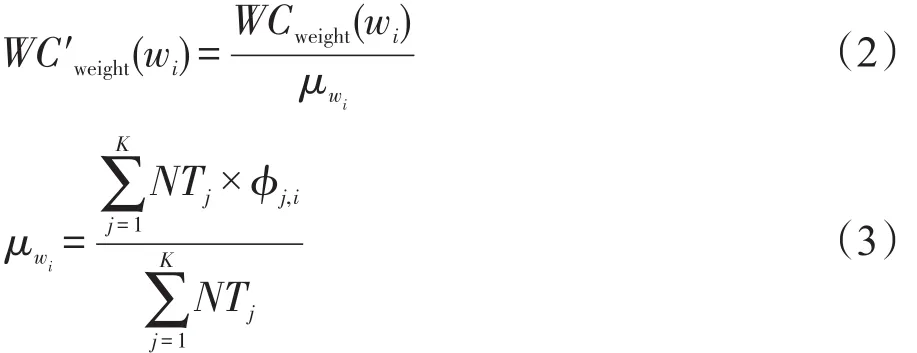
通过上述方法,实现了用突显刻画主题特征的特征词项来表示主题的目的,文中将有限词项集记为keyword_set。
3.3 文档的主题分布排序
由于主题建模过程中的“词袋”假设,即不考虑词项在文档中的出现顺序,主题间的差异仅限于各词项对其描述的概率值大小的差异,主题之间并没有明显的区分特性。要从主题分析的角度,将伪相关文档集的主题内容区分为与用户查询相关或不相关,就有必要对其中的文档主题分布进行区分。在给定用户查询的情况下,按照与用户查询相关程度,将无序的文档-主题分布按照其与用户查询的相关程度进行排序标定。由于主题信息已经被表示为有限词项集,那么用户查询与文档主题分布中各主题之间的相关程度,就可以利用用户查询与表征主题信息的词项集的相关程度来衡量,可以分别通过式(4)和式(5)得到:
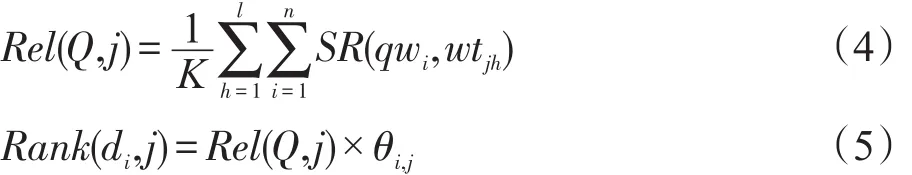
其中,Q表示用户查询,记为Q={qw1,qw2,…,qwn},由n个不同词项qwi组成。Rel(Q,j)表示用户查询Q与主题 j的相关程度。给定包含有M个文档的文档集C,有V个不同的词C={d1,d2,…,dM},每个文档di由Ni个不同的词项构成di={w1,w2,…,wNi},wi表示文档di中第i个词。假设文档集C存在K个主题,主题j(j∈[1,K])的描述词集 keyword_setj={wtj1,wtj2,…,wtjl}由l个不同词项wtji组成,i∈[1,l],θi,j表示文档di在主题j上的概率分布。SR(wi,wj)表示两个词语wi和wj之间的语义相关度[19]。Rank(di,j)表示文档di的文档-主题分布中主题j与用户查询的相关程度。本文对词语间语义相关度计算方法SR(w1,w2),由于篇幅关系不再赘述,详细信息参阅文献[19]。
文档的主题分布排序算法描述如下:
算法1 Topic_distribution_ranking
输入:(1)用户查询Q和文档集C中所有文档di的K个无序主题的描述词集keyword_setj,j∈[1,K];(2)文档-主题分布θ。
输出:所有文档di的K个有序主题分布。
步骤1对Q进行预处理;
步骤2利用式(4),计算Q中各词项和每个主题j的描述词集keyword_setj中各词项的语义相关度;
步骤3利用式(5)计算文档di的主题分布中各主题 j与Q之间的相关度,并按相关度大小对各主题进行排序。
3.4 基于主题内容排序的伪相关反馈
另外,相对于其他产业,体育产业具有较强的灵活性。结合当地社会文化环境对体育产业进行相应的调整和改进,有助于突出当地产业发展的特色。
综上所述,基于主题内容排序的伪相关反馈方法实现过程如图1所示。
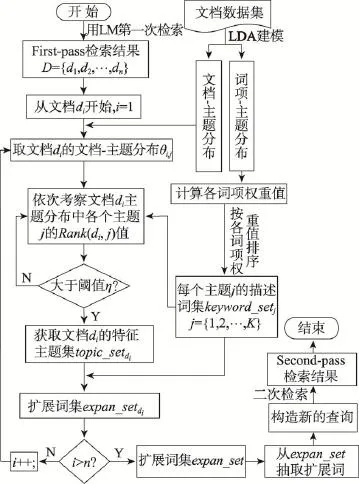
Fig.1 Procedure of PRF based on topic content ranking图1 基于主题内容排序的PRF过程
本文对于描述文档di的特征主题集中各主题的抽取,采取设定阈值η的方式来进行。若文档di中主题 j的Rank(di,j)值超过阈值η,则认为该主题是与用户查询是相关的,将该主题设定为topic_setdi集合中的元素。反之,则认为该主题与用户查询是不相关的。文档di扩展词集expan_setdi的获取,是通过将topic_setdi中各主题的特征词项集keyword_setj进行集合的合并操作完成的。特别的,在对文档主题分布中的词项排序过程中,本文利用式(2)通过重新计算每个词项对其描述主题的权重大小,可以在一定程度上减少同一词项在不同主题中出现的情况,或是增加同一词项在不同主题中出现的特异性,即同一词项在主题描述中的概率值差别显著。但事实上,LDA建模的本质及语言描述文本的特殊性,决定了不同主题的描述词项信息一定会出现交集,因此在特征词项合并过程中,当出现有词项重复的状况时,实验中会将该词项在expan_setdi中仅保留一次,并设置其权重值为合并前的最大权重值。同样,初检集合的扩展词集expan_set的获取,是将排序靠前的各文档的扩展词集expan_setdi中的词项进行集合的合并操作完成的。
4 实验与分析公式
4.1 实验设置
(1)实验数据集及预处理
实验的数据集包括文本集和查询集(均为简体中文)两部分。其中,文本数据集是Xinhua语料,共包含308 845个文档,涉及多种主题2002年至2005年4年的新闻语料,最长的文档长度为1 824,最短的文档长度为4。查询集为ACLIA2-CS-0001~ACLIA2-CS-0100,共100个查询。在检索过程中,本文将查询中的主题描述作为用户查询。利用Lemur(http:// www.lemurproject.org)工具对文本数据集建立索引和进行查询操作。实验中,由于采用的是中文语料,首先对建立索引的文本数据集和查询集都进行了预处理,包括分词和去停用词。主题建模过程中,对文本数据集还进行了去除低频词操作。
(2)实验参数设置
初检的相关度排序方法选用一元语言模型LM(language model)方法。实验中统一采用Dirichlet平滑方法,设置固定平滑参数为1 000,设定初检结果集中选取top-50个结果作为伪相关文档集。主题建模过程中,采用吉布斯采样(Gibbs sampling)[20]来实现模型估计和求解。设定每个主题返回NT=30个词项信息,Gibbs采样的迭代次数设定为100次。文档di主题集topic_setdi中各特征主题的抽取实现中,设定阈值η为0.18,实验效果最好。文献[17]研究表明,扩展词个数设定为10~20时,效果最佳。实验中统一设定固定值 feedbackTermCount=20。
因为用户在检索过程中主要关注排名靠前的检索结果,所以实验中主要从查询准确率角度进行评价。分别采用前n个结果的查准率Precision@n和平均查准率MAP(mean average precision)来衡量。
4.2 实验结果与分析
表1列出了部分主题初始建模的部分词项集合和重新计算词项权重后的部分词项集合。
从表1中可以看出,通过对词项-主题分布中的各词项按照其权重值进行重新排序,不仅做到了主题内容的进一步压缩和抽象,同时降低了那些对主题内容区分能力描述弱的词项的重要程度,使得描述主题的各词项的重要程度差别更加明显,从而主题间区别更加明显。
为了实现用浅层语义指导检索过程,本文设计并实现了如下实验,并对实验结果进行了分析。
首先,将本文方法(OurMethod)与基本的基于主题的PRF方法(LDA)进行比较,两种方法Precision-Recal(l精度-召回率)对比分析结果如图2所示。
从图2中可以看出,本文方法好于基于主题的PRF方法检索性能,说明对文本内容进行主题分析,将有助于提高检索性能。
其次,将本文方法与未进行主题内容排序的基本PRF方法进行比较,表2给出了伪相关文档集数量为50和100时的检索结果,其中No_Trank和Trank分别表示没有进行主题内容排序的PRF方法和进行主题内容排序的PRF方法。
从表2的结果中可以看出,选取那些丰富的、能表达语义的主题中的词项集信息作为扩展词,要比直接从伪相关文档集中选取单个的词项信息作为扩展词,可以进一步地提升检索性能,而且随着伪相关文档集中文档数目的增加,MAP值增加明显,MAP(100)比MAP(50)增加14.9%。分析其原因,在于随着伪相关文档集中文档数目的增加,抽取出相关主题内容的可能性也增加了,其中包含了更多能够体现用户查询需求中未能体现的上下文语义信息。
最后,为了进一步验证本文方法的科学性,考察将PRF抽取基本单元由文档转变到文档内容粒度是否真实有效,设计了如下实验。将本文方法与传统的伪反馈方法——TF-IDF和BM25进行比较,3种方法的Precision-Recal(l精度-召回率)对比分析结果如图3所示。
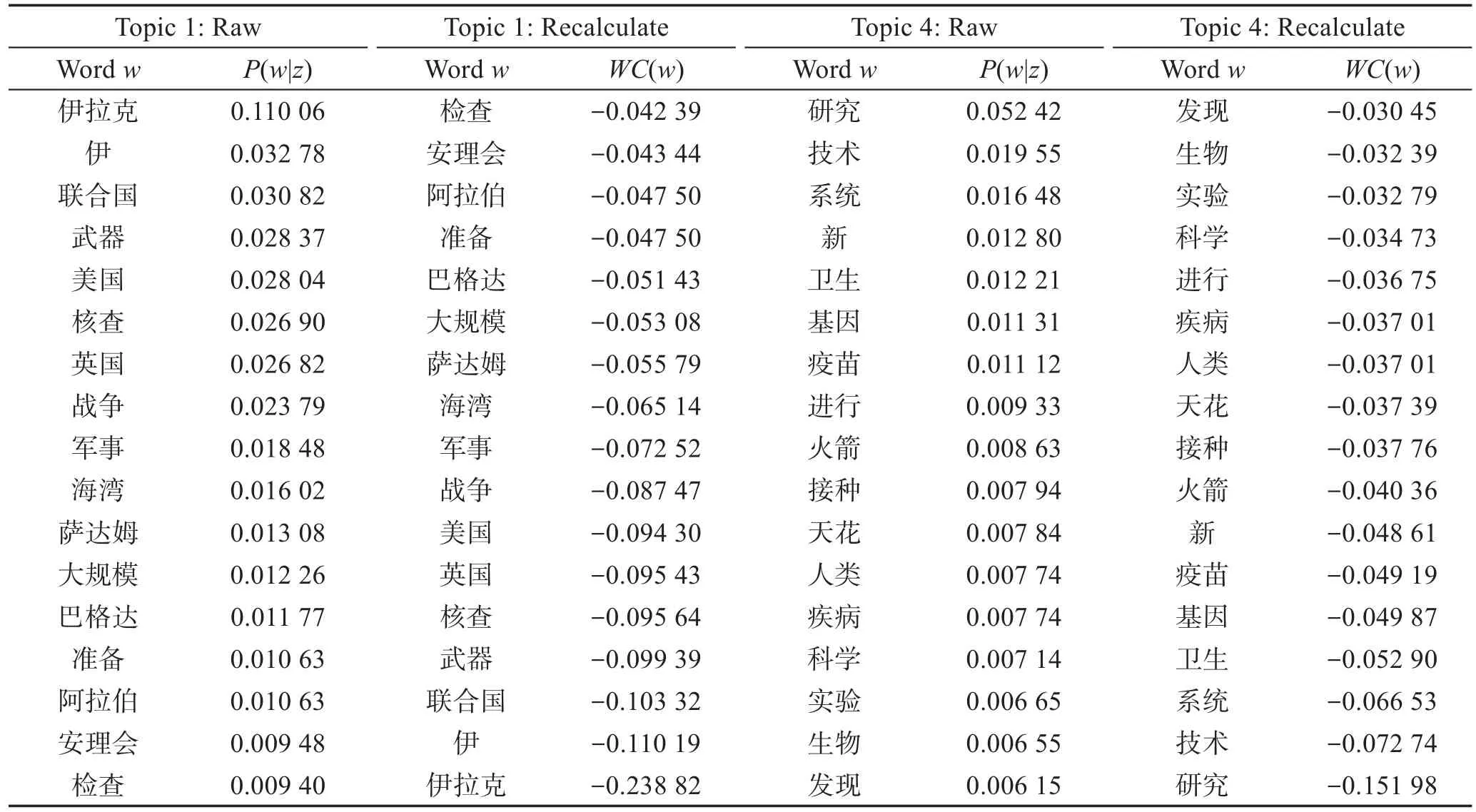
Table1 Example of effective word sets in Topic 1 and Topic 4表1 Topic 1和Topic 4中部分有效词项集合
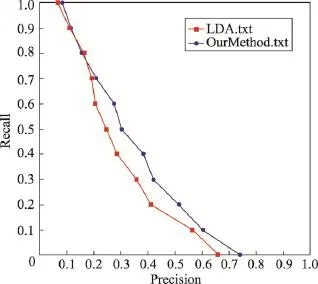
Fig.2 Precision-Recall curve of two methods图2 两种方法的Precision-Recall曲线图
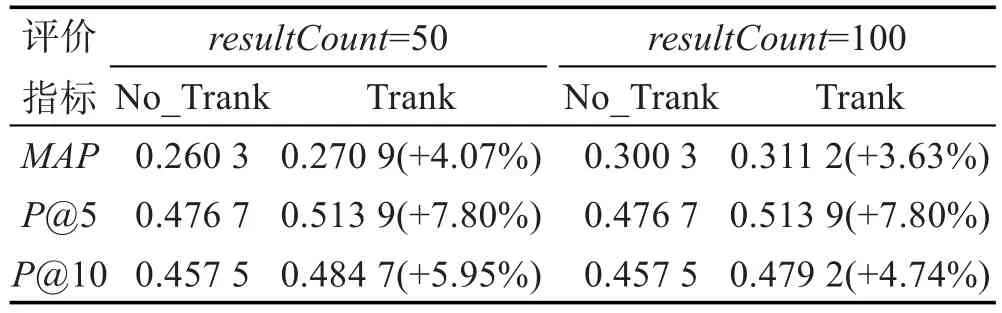
Table 2 Comparison of retrieval performance表2 检索评价指标对比
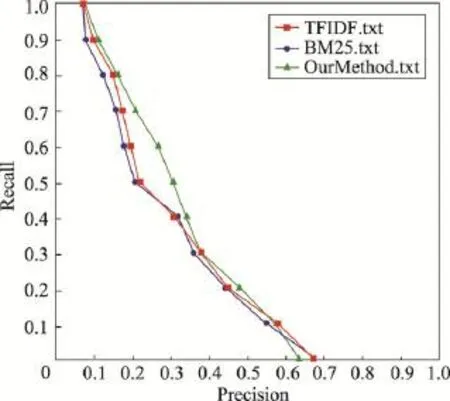
Fig.3 Precision-Recall curve of 3 methods图3 3种方法的Precision-Recall曲线图
从图3中可以看出,与两种传统PRF方法比较,本文方法可以更有效地提高检索性能,说明了本文方法的有效性。
5 结束语
主题模型是用来抽象地表示无标记文本的一种无监督建模方法。为了保证PRF的鲁棒性,本文提出了一种基于浅层语义的自动查询扩展方法。实验结果表明,这种将文档内容作为扩展词抽取的方法是切实可行的。但是随着文本数据集规模的增大,主题建模之后的主题数目会进一步增加,通过主题学习到的特征描述知识就更为抽象,如何利用这些越来越抽象的主题特征,使其更适合描述用户初始查询意图,将是进一步工作的方向。
[1]Arguello J,Elsas J L,Callan J,et al.Document representation and query expansion models for blog recommendation [C]//Proceedings of the 2nd International Conference on Weblogs and Social Media,Seattle,USA,Mar 30-Apr 2, 2008.Menlo Park,USA:AAAI,2008:11-18.
[2]Xu Jinxi,Croft W B.Query expansion using local and global document analysis[C]//Proceedings of the 19th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,Zurich,Switzerland,Aug 18-22,1996.New York:ACM,1996:4-11.
[3]He Ben,Ounis I.Finding good feedback documents[C]// Proceedings of the 18th ACM Conference on Information and Knowledge Management,Hong Kong,China,Nov 2-6, 2009.New York:ACM,2009:2011-2014.
[4]Parapar J,Presedo-Quindimil M A,Barreiro Á.Score distributions for pseudo relevance feedback[J].Information Sciences,2014,273:171-181.
[5]Yi Xing,Allan J.Evaluating topic models for information retrieval[C]//Proceedings of the 17th ACM Conference on Information and Knowledge Management,Napa Valley, USA,Oct 26-30,2008.New York:ACM,2008:1431-1432.
[6]Huang Shu,Zhao Qiankun,Mitra P,et al.Hierarchical location and topic based query expansion[C]//Proceedings of the 23rd National Conference onArtificial Intelligence,Chicago,USA,Jul 13-17,2008.Menlo Park,USA:AAAI,2008, 2:1150-1155.
[7]Zheng Ye,Huang Xiangji,Lin Hongfei.Finding a good queryrelated topic for boosting pseudo-relevance feedback[J]. Journal of the American Society for Information Science and Technology,2011,62(4):748-760.
[8]Harman D,Buckley C.The NRRC reliable information access(RIA)workshop[C]//Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,Sheffield,UK,Jul 25-29,2004.New York:ACM,2004:528-529.
[9]Collins-Thompson K.Reducing the risk of query expansion via robust constrained optimization[C]//Proceedings of the 18th ACM Conference on Information and Knowledge Management,Hong Kong,China,Nov 2-6,2009.New York: ACM,2009:837-846.
[10]Tao Tao,Zhai Chenxiang.Regularized estimation of mixture models for robust pseudo-relevance feedback[C]//Proceedings of the 19th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,Seattle,USA,Aug 6-11,2006.NewYork:ACM,2006: 162-169.
[11]Soskin N,Kurland O,Domshlak C.Navigating in the dark: modeling uncertainty in ad hoc retrieval using multiple relevance models[C]//Proceedings of the 2nd International Conference on Theory of Information Retrieval:Advances in Information Retrieval Theory,Cambridge,UK,Sep 10-12,2009. Berlin,Heidelberg:Springer,2009:79-91.
[12]Lv Yuanhua,Zhai Chengxiang,Chen Wan.A boosting approach to improving pseudo-relevance feedback[C]//Proceedings of the 2011 ACM International Conference on Research and Development in Information Retrieval,Beijing, China,Jul 24-28,2011.New York:ACM,2011:165-174.
[13]Blei D M,Ng A Y,Jordan M I.Latent Dirichlet allocation[J]. Journal of Machine Learning Research,2003,3:993-1022.
[14]Xiao Zhibo.Research on ranking topic models and their applications[D].Dalian:Dalian Maritime University,2014.
[15]Song Yangqiu,Pan Shimei,Liu Shixia,et al.Topic and keyword re-ranking for LDA-based topic modeling[C]//Proceedings of the 18th ACM Conference on Information and Knowledge Management,Hong Kong,China,Nov 2-6,2009. New York:ACM,2009:1757-1760.
[16]Cao Guihong,Nie Jianyun,Gao Jianfeng,et al.Selecting good expansion terms for pseudo-relevance feedback[C]// Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,Singapore,Jul 20-24,2008.New York:ACM, 2008:243-250.
[17]Ogilvie P,Voorhees E,Callan J.On the number of terms used in automatic query expansion[J].Information Retrieval, 2009,12(6):666-679.
[18]Xia Yunqing,Tang Nan,Hussain A,et al.Discriminative biterm topic model for headline-based social news clustering [C]//Proceedings of the 28th International Flairs Artificial Intelligence Research Society Conference,Hollywood,USA, May 18-20,2015.Menlo Park,USA:AAAI,2015:311-316.
[19]Yan Rong,Gao Guanglai.Word sense disambiguation based on word semantic relevancy computation[J].Computer Engineering andApplications,2012,48(27):109-113.
[20]Griffiths T L,Steyvers M.Finding scientific topics[J].Proceedings of the National Academy of Sciences of the United States ofAmerica,2004,101(S1):5228-5235.
附中文参考文献:
[14]肖智博.排序主题模型及其应用研究[D].大连:大连海事大学,2014.
[19]闫蓉,高光来.面向词义消歧的词语相关度计算[J].计算机工程与应用,2012,48(27):109-113.

YAN Rong was born in 1979.She is a Ph.D.candidate and lecturer at College of Computer Science,Inner Mongolia University.Her research interests include natural language processing and information retrieval.
闫蓉(1979—),女,内蒙古鄂尔多斯人,内蒙古大学计算机学院讲师、博士研究生,主要研究领域为自然语言处理,信息检索。

GAO Guanglai was born in 1964.He is a professor and Ph.D.supervisor at Inner Mongolia University.His research interest is intelligent information processing.
高光来(1964—),男,内蒙古扎赉特旗人,内蒙古大学教授、博士生导师,主要研究领域为智能信息处理。
Using Topic Content Ranking for Pseudo Relevance Feedback*
YAN Rong+,GAO Guanglai
College of Computer Science,Inner Mongolia University,Hohhot 010021,China
+Corresponding author:E-mail:csyanr@imu.edu.cn
YAN Rong,GAO Guanglai.Using topic content ranking for pseudo relevance feedback.Journal of Frontiers of Computer Science and Technology,2017,11(5):814-821.
Traditional pseudo relevance feedback(PRF)algorithms use the document as a unit to extract words for query expansion,which will increase the noise of expansion source due to the larger extraction unit.This paper exploits the topic analysis techniques so as to alleviate the low quality of expansion source condition.Obtain semantic information hidden in the content of each document of pseudo-relevant set,and extract the abstract topic content information according to the relevance of the user query,which is described as a basic extraction unit to be used for query expansion.Compared with the traditional PRF algorithms and the PRF based on topic model algorithm,the experimental results on NTCIR 8 dataset show that the scheme in this paper can effectively extract more appropriate expansion terms.In addition,the results also show that the scheme in this paper has a positive impact to improve the retrieval performance on a smaller topic content granularity level.
topic model;topic content;pseudo relevance feedback(PRF)
10.3778/j.issn.1673-9418.1603068
A
TP391.3
*The National Natural Science Foundation of China under Grant No.61263037(国家自然科学基金);the Natural Science Foundation of Inner Mongolia under Grant Nos.2014BS0604,2014MS0603(内蒙古自然科学基金).
Received 2016-02,Accepted 2016-04.
CNKI网络优先出版:2016-04-01,http://www.cnki.net/kcms/detail/11.5602.TP.20160401.1614.014.html
