基于Spark的并行化主题模型算法研究
2017-06-01邹小波詹敏
邹小波 詹敏
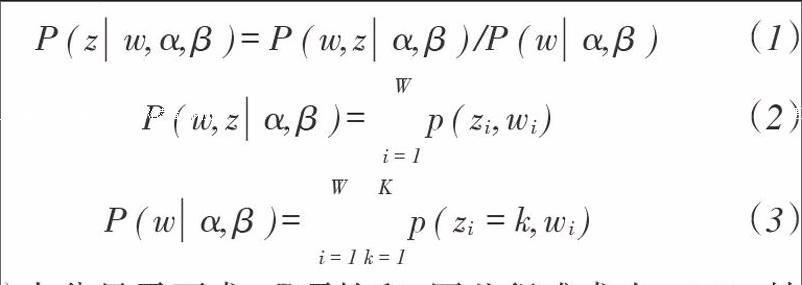
摘要:为应对大数据量处理的挑战以及更加有效地进行文本的语义挖掘,本文利用快速通用的计算框架Spark进行典型主题模型潜在狄利克雷模型的并行化研究。根据模型求解过程中利用吉布斯采样估计参数的特点,该文将模型的并行化实现分解为参数初始化、数据集分割以及吉布斯采样等过程,并利用Spark提供的丰富编程接口进行模型的训练设计。基于真实数据集上的实验表明,该文的并行化模型能够提取文本的主题分布。
关键词:主题模型;Spark;吉布斯采样;文本挖掘;大数据
中图分类号:TP391 文献标识码:A 文章编号:1009-3044(2017)08-0017-02
近年互联网的发展将信息时代带入了大数据时代,人们获取信息的方式不再是传统的PC端,而是扩展到了移动互联甚至是物联网等多样化的形式。越来越丰富的网络内容,使数据产生的速度、数据格式以及数据关系都变得难以再利用传统的数据处理技术进行数据的分析。因此,找到一种能够有效处理大数据的技术成为了数据时代的基本需求。
本文主要研究内存计算框架Spark平台下主题模型算法Latent Dirichlet Allocation(LDA)的并行化及实现。LDA是Da-vid Blei,Andrew坛等提出的基于贝叶斯方法的无监督概率生成主题模型,广泛应用在信息检索、主题抽取、信息推荐等,本文在Spark框架下进行LDA主题模型的文本挖掘研究。
1研究现状
LDA模型利用两个假设:(1)文档是多个主题的集合,符合多项分布;(2)主题也是词语的混合,同样符合多项分布。整个过程就是估计分布参数,在估计参数的方法中,Blei等使用变分贝叶斯方法估计先验分布参数,Gregor Heinrichm应用Gibbs采样方法对LDA进行参数估计。
关于LDA算法的改进,很多学者进行了深入而细致的研究,既有变分贝叶斯也有Gibbs采样。针对大数据集处理提出的并行LDA首次由DavidNewman等提出,该论文提出两种LDA改进模型:(AD-LDA)和(HD-LDA),AD-LDA模型分割数据集加快速度,而精度有损失,HD-LDA混合模型包含多个LDA,相比AD-LDA精度提升,但复杂度高,因此,都集中在AD-LDA基础上深入研究,Porteoas等提出了FastLDA。除了上述的早期并行化研究,La Wen等基于Mahout的CollapsedVariational Bayes(CVB)算法进行改进。由于Spark基于内存计算的优势,越来越多的大数据处理研究放在了该平台上,Spark下的LDA模型研究对文本处理的研究具有非常重要的指导作用。
2相关技术
2.1LDA模型
LDA模型中一篇文檔的生成方式过程如下:
1)通过Dirichlet分布采样得到文档i的主题分布θi;
2)从主题的多项式分布θi取样生成文档i词语j的主题Zi,j;
3)从Dirichlet分布β中取样生成主题Zi,j词语分布φz(i,j);
4)从词的多项式分布φz(i,j)中采样最终生成词Wi,j。
2.2 Spark内存计算框架
Spark是一种由加州大学伯克利分校AMP实验室开源的内存计算框架,相比Hadoop MapReduce模型具有快速、通用、容错的特点,由于MapReduce对中间结果处理落地磁盘,所以不适合具有迭代和实时条件下的计算,而Spark采用ResilientDistributed Datasets(RDD)数据集,非常适合在迭代情况下的应用,因此适合机器学习等迭代算法的部署,Spark自身也包括了SQL处理、流计算、MLlib、图计算等组件,因此在内存快速计算的前提下,还能适用在不同的应用场景下。
3基于Spark的LDA主题模型的实现
LDA模型使用贝叶斯推理方法,中间需要三个参数:每个词对应的主题Zi,j,文档的主题分布θi,每个主题的词语分布z(i,j),在估计参数时,只需要计算Zu,其他两个参数可以通过似然估计得到。Zi,j的计算公式如下:
(1)
(2)
(3)
公式(1)中分母需要求KW项的和,因此很难求出,Gibbs抽样就是要完成式(1)的抽样,再利用抽样结果完成其他两个参数的似然估计。
在进行了数据集分割和预处理后,通过对每个数据集进行一次Gibbs采样然后进行相关矩阵和数组的合并,以求平均值的方式得到新的状态变化。接下来使用新的状态集合应用到各个数据集中进行下一次采样,重复这一过程,直到得到稳定的结果。
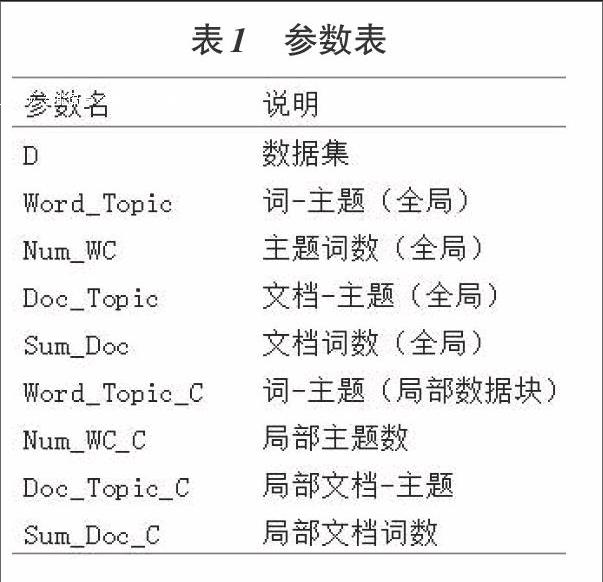
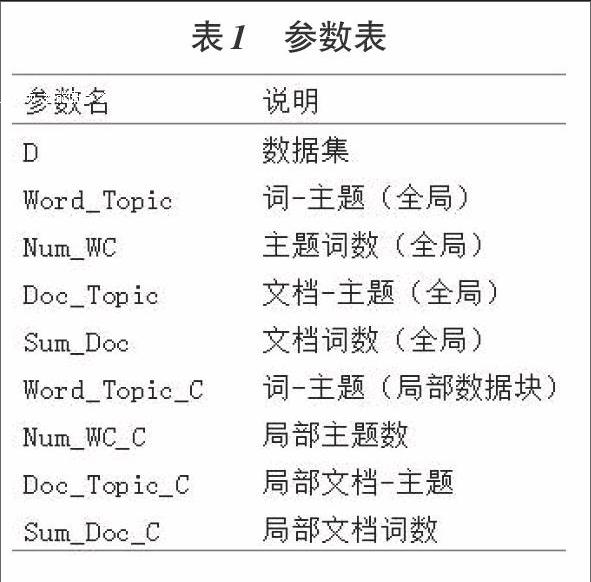
LDA吉布斯采样在并行化实现时需要更新多个统计量,如果将数据并行化处理,则需要将一些全局统计量进行每次采样的更新。数据以矩阵的形式存储,在进行数据集的子划分时,按照从上到下、从左到右的顺序进行数据块划分,并行计数时对每个数据块的局部统计量进行更新,每次采样完毕后将局部统计量进行合并至全局统计量中,作为下次采样的先验分布。并行吉布斯采样的参数表如下表J所示(共享全局变量已在表中给出):
3.1算法参数初始化
相关的计数矩阵和数组初始化为0,然后将数据读入RDD(RDD的数据主要是文档一主题一词汇)。
3.2采样
采样是LDA算法的核心,的采样过程可以细致分为三个步骤:
1)首先是采样参数中各计数数组的初始化,这些计数数组主要是文档主题数,文档词数以及某个主题的词数;
2)针对不同数据块生成的RDD进行并行采样;
3)将更新后的计数矩阵传输到下一个采样作业。
3.3Spark下LDA训练流程
1)数据导入:直接调用Spark导入本地数据或者将数据存入相应的Nosql数据库;
2)数据预处理:包括分词、去停用词、相关词频统计等工作,主要目的是为了向量化进行模型的训练;
3)转换为RDD:主要是为了将数据进行分割,从而实现后续的并行化模型训练;
4)模型训练:模型的训练过程是本文并行化实现的核心,按照两个过程:参数初始化和采样过程进行迭代。
4实验设计与结果分析
使用的数据集为斯坦福大学的Topic Modeling Toolbox(TMT)测试数据集,实验环境为三台内存为4g的主机组成的Spark集群,使用Spark2.0,分别测试主题模型的困惑度以及主题挖掘结果中的词数分布。
4.1困惑度
困惑度是评测主题模型常用的一种测评参数,其计算方式如下:
(4)
困惑度越小模型越好,随着迭代的进行,模型的迷惑度会逐步收敛。初始参数为α=β=0.01,主题数设置为(5,10,15,20,25,30),迭代次数为500次。由于每次采样计算的结果都会有差别,因此本文进行了多次测试并取均值,如下图1所示。
可知,在图中当主题数为30时困惑度Perplexity最小,表示模型最优,所以为了进行下一步主题分布的采样结果测试,选用主题数为30最好。
4.2主题分布采样结果
根据选择的主题数以及参数的设置,采样测试将迭代次数增加为1000次,得到对文档集的主题挖掘结果,整个主题的词分布都相对均匀,随机选择某个主题词语分布中频率最高的1个词语进行分析,得到词语分布直方图,如图2所示。可见,抽取出的主题词具有一定的表现力。
5总结
本文对主题模型LDA进行了简要的概述,并對其相关的并行化工作做了理论介绍,重点对其在Spark平台上实现并行化的一些思路进行了分析与实现,相关的实验测试其困惑度以及主题抽取结果。实验表明,LDA算法可以在Spark上进行较好的主题抽取,其抽取结果可以为进一步的文本分类以及个性化推荐等应用提供良好的帮助,但是本文的算法还存在一些问题,例如迭代次数增加导致的算法运行效率问题,这也是后期的研究工作。
