基于海量数据融合的设备状态评价方法*
2017-05-25陈永前李少波
陈永前,李少波,b
(贵州大学 a.现代制造技术教育部重点实验室;b.机械工程学院,贵阳 550025)
基于海量数据融合的设备状态评价方法*
陈永前a,李少波a,b
(贵州大学 a.现代制造技术教育部重点实验室;b.机械工程学院,贵阳 550025)
针对传统方法难以实现对海量数据环境下的设备状态评价的问题,提出了一种基于海量数据融合的设备状态评价方法。首先,利用擅长处理海量数据的分布式聚类算法K-means对海量状态数据进行预处理为多个簇,并求出各个簇的质心作为该簇的代表信息;然后对代表信息进行加权处理;最后利用证据理论对加权的代表信息进行融合,从而决断出设备的状态。通过仿真实验结果表明,该方法能对海量信息进行有效融合,并能更合理地决断出设备的状态信息。
证据理论;海量数据;聚类;状态评价
0 引言
机械设备的状态评价是指在设备运行中,通过对特征信号的监测、处理、分析、评价等来判断设备的运行状态的一个过程。对机械设备的状态评价有助于实时获知设备的运行状况,从而有助于减少因设备故障所带来的加工损失。数据融合技术作为状态评价的重要手段,在近年来在该领域得到很大的研究与应用。文献[1] 提出了一种利用组合数据融合方法,并用于无线传感网络中,提高了目标识别的精度,并降低了算法的复杂度;文献[2]提出了一种基于凸函数证据理论与BIRCH的数据融合方法,并将其用于环境舒适度状态评价中,解决了状态评价难的问题;文献[3]将 D-S证据理论和支持向量机结合,对多传感器信息进行有效融合,为结构损伤评价与检测提供高效的方法。
随着智能制造与智慧设备的发展趋势以及物联网、制造物联和移动互联等信息技术的快速发展,目前对机械设备的状态评价必须依托于更全方位与更实时的数据采集与分析,这决定了对机械设备的状态评价将面临海量数据的分析。虽然传统数据融合技术在状态评价领域获得很大的成就,但是面对海量数据融合问题时,传统方法的潜在复杂度会增加方法的开销,使融合效率低下,同时面对复杂多类型的数据,传统的数据融合方法往往会发生失效等问题。为此,本文提出一种基于海量数据融合的状态评价方法。该方法利用分布式聚类的方法对海量数据进行处理,将状态评价数据处理为具有代表性的数据,再利用证据理论对代表信息进行融合,从而决断出设备的状态,能有效地解决海量数据环境下的状态评价问题。
1 海量数据的分布式聚类处理
分布式处理是解决海量数据利用难的有效方法之一。利用分布式聚类方法对状态评价的海量数据进行处理,将海量数据转化为代表信息,可为后续的融合与决策做出基础。MapReduce是谷歌公司提出来的分布并行编程模型,十分擅长处理海量数据[4],本文将基于MapReduce编程模型,结合主流的数据聚类方法K-means进行海量状态数据的分布式聚类设计。
1.1 MapReduce编程模式
在MapReduce中,一个计算流程分为Map和Red- uce两个阶段。在Map阶段,输入文件会被划分为固定大小的数据块。每个块都会对应着一个Map任务,该Map任务中的Map函数会作用于数据块中的每一个记录,一个记录就是一个
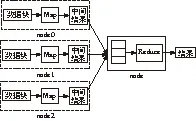
图1 MapReduce编程模式
1.2 基于MapReduce的分布式K-means聚类算法
K-means算法是一种基于距离的聚类算法,首先选择k个数据作为初始聚类中心,剩下数据作为聚类对象。将这些对象与k个聚类中心作比较后将其归类到最近的一个;然后再重新计算每个所获新聚类的聚类中心;重复这一过程,直到算法收敛。
利用MapReduce的编程模式来编辑K-means算法,可先利用Map函数实现K-means聚类算法的距离比较部分,再利用Reduce函数来实现数据归类。其伪代码设计如下[5]:
Map部分:
Map函数输入的key1为输入数据起始点的偏移量,value1是各维坐标值。输出Key2是当前聚类类别ID,value2是当前记录属性向量。
Void Map(key1,value1){
辅助变量min-Distance为可以取值的最大值;
For(i=0;i
if(第i个点到簇质心的距离distance[i]
-Distance){
min-Distance= distance[i];
聚类类别ID=i;}
}
输出中间值(Key2,value2);
}。
Reduce部分 :
Map函数输入的key3为聚类类别ID,value3记录属性向量集合。输出Key4是聚类类别ID,value4向量集合的均值向量。
Void Reduce(key3,value3){
初始化一个数组,用于记录各属性向量的累加值,每个分量初始值为0;
初始化变量num,用于记录同类簇的样本个数,初始值为0;
White(value。hasNext()){
从value。next中解析出一个样本的位置坐标值和样本个数num;
将各维坐标值累加到数组相应的分量中;
NUM+=num;}
将数组中的每个分量除以NUM,得到新质心坐标;
输出(key4,value4)
}。
2 证据理论数据融合方法
证据理论是一种使用最为广泛的数据融合技术,在处理不确定推理以及不确定信息融合方面有很好的优势,故而在各个行业都得到了很大的应用。通过分布式聚类方法将设备状态数据经常处理为多个簇的质心,得到状态数据的代表信息后,便可对应用证据理论数据融合方法对代表信息进行融合处理,从而可决断出设备状态情况。
证据理论的详细叙述可参考文献[6-8],此处仅对其融合规则加以说明。
对∀A⊆Θ,设mi(i=1,2,…,n)为Ai(i=1,2,…,n)的n个基本概率分配,则合成规则:
(1)
式(1)便为证据理论的合成规则,式中:
(2)
为证据间的冲突程度,k越大,冲突程度就越大;m(A)表示在机械设备状态评价中,每种可能出现的状态的信度值;mn(An)表示某个传感器测得某种状态的信度值。
3 基于海量数据融合的状态评价方法
3.1 方法设计
基于以上步骤,本文提出一种基于证据理论与聚类处理的海量数据融合方法,方法思想:首先利用基于MapReduce编程模式设计的分布式数据聚类算法K-means对海量状态数据进行聚类处理为多个簇,并计算各个簇的质心作为该簇数据的代表;然后利用证据理论组合规则对各个簇代表信息进行融合,并决断出设备的状态信息。算法主要步骤如下:
(1)根据机械设备状态评价的数据规模和数据特点,选择聚类算法K-maens的聚类数目k和最大迭代次数;
(2)将状态评价的所有数据进行聚类处理,得到k个簇Ci,1
(3)求取k个簇的质心Qi,1
(4)根据实际问题,确定状态评价的辨识框架Θ:{F1,F2,…,Fr},即设备所有可能出现的状态;
(5)根据传感器采集的数据和融合目标的特点,确定数据的所有属性Ai,例如利用加速度传感器和位移传感采集的数据为两个属性A1和A2;
(6)求取各个簇质心的BPA,即证据mi。可利用区间数理论、模糊数学等方法对进行求取[9-10]。若采集的状态数据有多个属性,应先求取各个属性Ai的BPA,再融合为代表簇的BPA;若数据只有一个属性,可直接求取各个簇质心的BPA;
(7)对各个簇质心的BPA进行加权。证据理论认为越多的证据体支持某个问题,则信任度就越高,故应对各个簇质心所获得证据进行加权处理。
(8)由(6)、(7)得到每个簇对目标的证据μimi,用组合公式(1)进行融合,得到机械设备的状态情况。整个方法流程如图2所示。
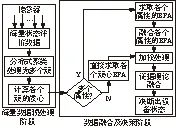
图2 海量数据融合的状态评价流程图
3.2 算法分析
本文方法对海量状态数据进行融合时,对全局数据进行了考虑,避免过早得到融合结果而出现不合理问题。
在算法时间复杂度上,本文方法的时间复杂度由分布式聚类、BPA求取和融合三部分组成,其中分布式聚类算法的时间复杂度为O(Nkt/P)[11],N为数据量,k为簇数量,t为迭代数,P为计算机群集数;融合部分时间复杂度为O(kSr)[2],S为数据属性数,r为辨识框架中元素的个数;在BPA求取部分,有k条数据,每条数据包含S个属性,每个属性对辨识框架的r个元素进行一次计算,其时间复杂度为O(kSr)。综上,本文方法时间复杂度为O(Nkt/P+kSr+kSr),其中N≫k,t,S,r,故复杂度接近为O(Nkt/P),为线性复杂度,优于传统方法,且P值越大,复杂度就越低。
4 案例仿真分析
本文将模拟对某机床刀具状态监测数据进行融合实验,可将刀具的状态分为正常、轻度磨损、一般磨损、重度磨损和刀具破裂五个等级,本文主要对刀具的切削力、刀具温度和声发射三个状态指标数据进行模拟实验。
本实验所涉及的数据聚类部分所选择的计算平台是由4台台式机组成,每台电脑安装2个虚拟机。台式机的配置:Intel(R)Core(TM)i3-6140、CPU3.60GHz、内存4GB;并且采用Vmware10.0.1虚拟机环境,Ubuntu12.10.X, 32位操作系统以及采用jdk1.7.0和Hadoop1.2.1环境。实验数据融合部分均在MATLAB2011B环境下完成。
首先对1000-10000条数据进行实验,主要目的是验证算法的时间性能指标。实验与传统方法及文献[1]方法进行比较,其运行时间结果如图3所示。
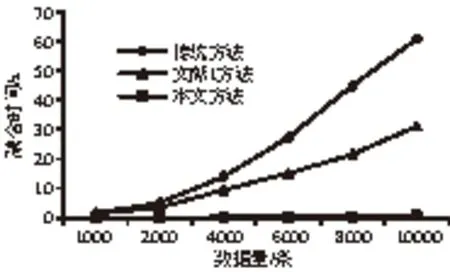
图3 三种方法计算时间比较
由图3的实验结果可以看出,在对同样数量的数据进行融合时,当数据量小于1000条时,三种方法所需时间相差不大;随着数据量的增大,传统的数据融合方法在时间上明显急剧增大,文献[1]方法虽然优于传统计算方法,然而也以很快的速度增长;当数据量到达10000条时,传统方法所需时间为60.715s、文献[1]方法时间为31.105s,而本文方法所需时间为0.735s,本文所花时间仅为传统方法的1.2%,为文献[1]所花时间的2.4%。
当继续加大数据量时,发现数据量到达10万条以上后,传统方法和文献[1]方法都发生“卡死”现象,无法对数据融合,此时本文方法的运行时间如图 4所示,整体趋于线性。
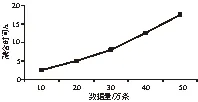
图4 本文方法融合时间
表2是利用传统方法、文献[1]方法和本文方法分别对1000~10000条数据的融合结果(本实验的10000条数据中,前2000条偏向于支持“正常”,后8000条偏向于支持“轻微磨损”)。由实验结果可以看出,传统方法在1000~10000条数据融合中的结果都显示为“正常”,且支持度都为1,这显然与实际情况相矛盾。分析其原因主要在于:当传统方法对前100个数据融合时,融合结果对“正常”的支持度已达到1,此时无论后面有多少个数据,无论是否支持“正常”,其融合结果都为“正常”,出现后续数据失效的情况。文献[1]方法思想是先分组融合得到中间结果,再对中间结果进行最终融合。在分组融合中,前2000个数据分组融合结果完全支持“正常”的,后8000个数据分组融合结果完全支持“轻微磨损”,这是明显的全冲突问题,故在最终融合时会出现证据理论失效的现象。本文方法从数据的全局出发,利用擅长海量数据分析的分布式聚类方法将海量数据处理为代表信息,然后再用证据理论对其融合,最后得到的结果合理,与实际情况相符。
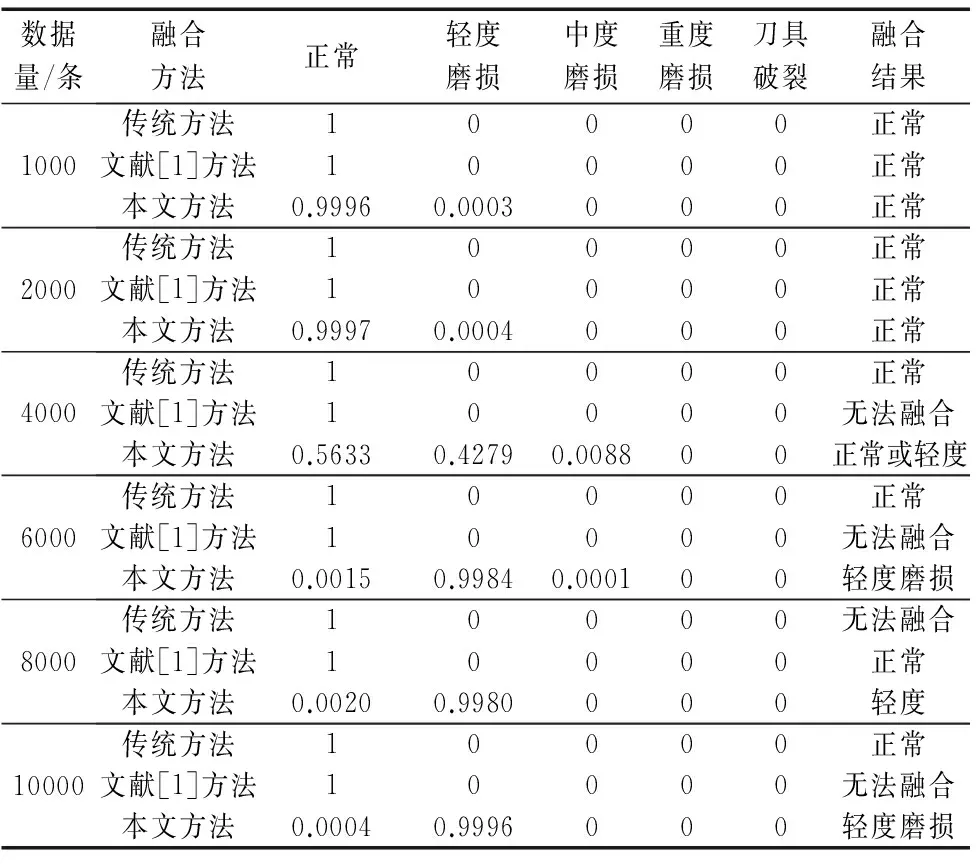
表2 三种方法融合结果比较
综上所述,本文所提出的融合方法无论是在融合时间上,还在融合结果上,都明显优于前两种方法,能有效解决海量数据情况下的状态评价的问题.本文方法操作简答,易于实现,当面临更大规模的状态数据时,只需增大计算机群集即可。同时,本文方法是对全局状态数据进行分析,故能有效过滤掉由于外界环境所引起的错误信息,为状态评价结果提供保障。
5 结论
本文提出了一种能处理海量信息的设备状态评价方法,该方法将善于处理海量数据的分布式聚类算法与证据理论相结合,将海量数据融合问题化为对代表信息融合,解决了对海量设备状态数据难以利用的问题,为设备状态评价提供了一种合理高效的方法;通过仿真实验,本文方法在处理时间上远优于其他两种方法,在计算结果也较其他两种方法更加合理,是一种有
效的状态评价方法,可为海量数据环境下的设备状态评价提供参考。
[1] 陆兰兰,程铭东.基于D-S证据理论的组合数据融合算法[J].微电子学与计算机,2011,28(1):95-98.
[2] Li JF, Zhou B,Liu DY, Hu L,Wang F. Massive Information Fusion Algorithm and Its Application in Status Evaluation[J]. Journal of Software, 2014,25(9):2026-2036(in Chinese).
[3] Zhou Q, Zhou H, Zhou Q, et al. The structural damage detection based on posteriori probability support vector machine and Dempster-Shafer evidence theory [J].Applied Soft Computing, 2015, 36 (C):368-374.
[4] Dean J, Ghemawat S. MapReduce: A Flexible Data Processing Tool[J]. Communications of the Acm,2010,53(1):72-77.
[5] 江小平, 李成华, 向文等. k-means聚类算法的MapReduce并行化实现[J]. 华中科技大学学报:自然科学版, 2011, 39(S1):120-124.
[6] Parikh C R,Pont M J,Jones NB.Application of Dempster-Shafer theory in condition monitoring applications: acasestudy[J].Pattern Recognition Lett,2001,22( 6 /7) : 777-785.
[7] Guo K, Li W. Combination rule of D-S evidence theory based on the strategy of cross merging between evidences [J]. Expert Systems with Applications, 2011, 38(10):13360-13366.
[8] Zhu J L, Zhang W G, Qiu Y H, et al. Multi-sensor Target Identification Based on Improved Evidence Theory[J]. Fire Control & Command Control, 2013, 38(8):107-110.
[9] 康兵义,李娅,邓勇,等.基于区间数的基本概率指派生产方法及应用[J].电子学报,2012,40(6):1092-1096.
[10] 兰蓉,范九伦.梯形模糊数上的完备度量及其在多属性决策中的应用[J].工程数学学报,2010,27(6):1001-1008.
[11] 康兵义,李娅,邓勇,等.基于区间数的基本概率指派生成方法及应用[J].电子学报,2012,40(6):1092-1096.
(编辑 李秀敏)
The Equipment State Evaluation Method Based on Massive Data Fusion
CHEN Yong-qiana,LI Shao-boa,b
(a.Key Laboratory of Advanced Manufacturing Technology, Ministry of Education;b.School of Mechanical Engineering, Guizhou University, Guiyang 550025,China)
In view of the Traditional method is difficult to realize the evaluation of equipment state in massive data environment, this paper proposes a method of equipment state evaluation based on massive data fusion. First, Using the distributed clustering algorithm K-means, which is good at dealing with massive data, to pre-process the massive data., and calculating the centroid of each cluster as the cluster representative information; Then, it is imperative to weighted processing for representative information; finally, it uses the evidence theory to fuse the weighted representation information, and then the state of the device is determined. The simulation results show that the method can fuse massive information effectively, and can make more reasonable decision for the state information.
evidence theory; massive data; clustering; state evaluation
1001-2265(2017)05-0142-04
10.13462/j.cnki.mmtamt.2017.05.038
2016-08-18
国家自然科学基金资助项目(51475097);贵州省基础研究重大项目(黔科合JZ字[2014]2001)
陈永前(1991—),男,贵州毕节人,贵州大学硕士研究生,研究方向为数字化设计制造;李少波(1973—),男,湖南岳阳人,贵州大学博士生导师、博士,研究方向为制造物联、智能制造,(E-mail)lishaobo@gzu.edu.cn。
TH164;TG506
A
