基于输入样本和主数据的编辑规则挖掘算法①
2017-05-17于守健陈少总东华大学计算机科学与技术学院上海201620
杨 辉, 于守健, 陈少总(东华大学 计算机科学与技术学院, 上海 201620)
基于输入样本和主数据的编辑规则挖掘算法①
杨 辉, 于守健, 陈少总
(东华大学 计算机科学与技术学院, 上海 201620)
基于编辑规则和主数据的数据修复技术能自动地、确切地修复不一致数据, 但目前编辑规则的获取主要依靠专业人员的定义. 为了实现数据清洗全自动化, 数据规则的挖掘技术近年来成为研究热点, 针对条件函数依赖提出的挖掘算法主要有CFDMiner, CTANE, FastCFD. 在此基础上, 扩展条件函数依赖(CFD)的定义, 在编辑规则的定义下提出了一种基于输入样本和主数据的编辑规则挖掘算法, 主要思路是从输入样本中挖掘出CFD, 然后根据输入样本与主数据在属性上的定义域相似性求出输入样本在主数据中的对应属性, 从而形成带模式组的编辑规则, 此算法能有效地挖掘编辑规则. 且所挖掘的编辑规则按照编辑规则语义能有效地进行数据修复.
编辑规则; 条件函数依赖; 数据清洗; 等价类划分
1 引言
基于编辑规则和主数据的数据修复[1]比基于CFD的数据修复[2]更有效, 主要体现在数据修复的精确性上, 且编辑规则不会引入新的错误. 基于编辑规则的清洗方案更有望被数据清洗工具所采用, 这样, 从输入样本自动挖掘编辑规则的技术是很有必要的. 事实上, 仅仅依靠领域昂贵的专业人员和漫长的手工来定义规则往往是不现实的. 正如Gartner所报道, 清洗规则的挖掘在商业数据质量工具中至关重要.
在实际中, 关于编辑规则挖掘关心的问题是: 给定关系模式R中的样本实例r, 找到满足实例r的所有编辑规则集Σ的正则覆盖. 即逻辑上等价于Σ的规则集cΣ. 挖掘编辑规则的关键任务是挖掘CFDs, 最后去匹配主数据中的属性, 匹配方法是将输入样本在每个属性上的定义域与主数据每个属性上的定义域进行比较, 定义域相似度满足定义的阈值即为对应的属性,并将对应的属性保存在哈希表中, 这样我们得到CFDs后, 从哈希表中找到对应的属性就可以得到我们所需的编辑规则了. 为了减少冗余, 应该使所挖掘的每个CFD是最小的, 即非平凡的和左约简的. 挖掘的难点是时间复杂度高, 从实例中挖掘出CFDs的正则覆盖集时间复杂度就已经达到指数级了. 再者, 编辑规则需要绑定主数据中的属性, 会遇到CFDs挖掘中不曾遇到的困难, 根据表1中的实例数据0r[3], 观察可以得到如下几个CFDs, 分别表示为:

从上面的CFDs规则可以看出, 国家编码(CC)和地区编码(AC)可以决定城市, 规则0φ表明在英国,邮政编码(ZIP)可以唯一决定街道(STR). 从上面观察所得的CFDs可以看出有两类CFD, 但规则左边不是最约简的, 因此通过算法能同时挖掘出这两类最小CFDs是具有挑战的; 另一个挑战是对CFDs扩展, 即确定编辑规则中来自主数据的属性集, 表2中的主数据, 与输入实例数据来源不同, 字段名不能一一对应起来, 例如电话号码可以表示成PN或TEL, 地址可以表示成STR或POST. 为了解决以上难点, 提出了能挖掘出最小的两类CFDs和匹配主数据形成编辑规则的算法.
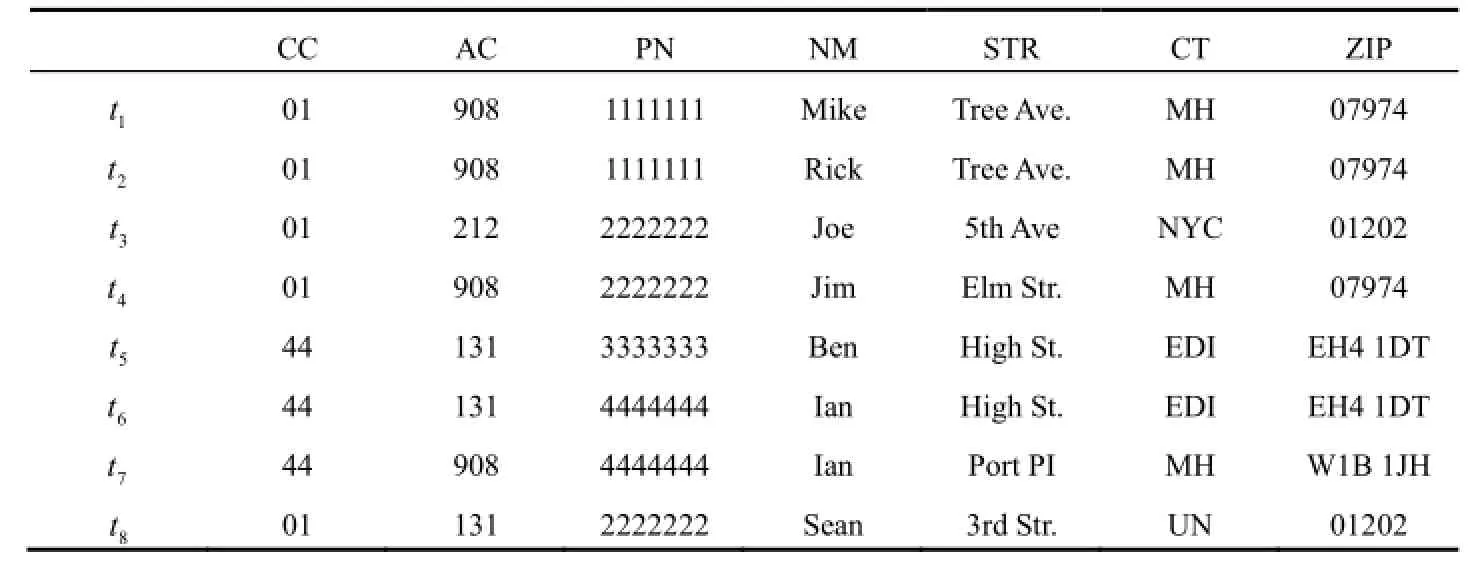
表1 Customer Relation schema R

表2 Relation schemamR
2 相关概念
2.1 CFDs相关概念
2.1.1 CFDs定义
在关系R上的条件函数依赖φ的形式为(R: X→A, tp), 其中X→A是标准的FD形式, X∈attr( R), tp是属性X和A上的模式组[4]. 规则的左边属性集记为LHS(φ), 右边记为RHS(φ). 例如φ0中, ([CC,ZIP]→STR)为FD形式, (44,_||_)为模式组, LHS(φ0)为[CC,ZIP], RHS(φ0)为STR.
2.1.2 CFDs分类
如果tp[A]等于常数, 且任意B∈X上的属性值tp[B]也都等于常数, 则该φ为常CFD. 如果tp[A]=_且X中存在属性B有tp[B]=_, 则该φ为变CFD[3].例如前面提到的φ0为变CFD, φ1, φ2, φ3为常CFDs.
2.1.3 CFDs语义[5]
为了说明CFD的语义, 我们先在属性值上定义一个关系符≤, 如果η1=η2或者η1为常数, η2为“_”, 则有η1≤η2. 例如表1中元组, (44,"EH4 1DT","EDI)≤(44,_,_). 如果t1≤t2我们就说t1匹配t2; 如果t1≤t2, t2≤t1记为t1≪t2. 例如(44,"EH4 1DT","EDI)≪(44,_,_). 给定规则φ, 如果对于实例r中的每对元组t1, t2当t1[ X]=t2[ X]≤tp[X ]时, 都有t1[ A]=t2[ A]≤tp[A]成立, 则r|=φ. 如果定义满足φ的一个r子集为rφ={t| t∈r, t[ X]≤tp[X ]}, 那么只需考虑rφ中的任意两对t1, t2当t1[ X]=t2[X]时,是否有t1[ A]=t2[A]和t1[ A]≤tp[A]成立, 而不用考虑整个r. 如果r满足规则集Σ中的每个φ, 则r|=Σ.对于(X→Y, tp)中Y为多属性集合的规则, 等价于多个规则右边只有一个属性的规则. 这里我们只考虑RHS(φ)为单一属性集的规则.
2.1.4 最小CFDs
给定了模式R中的样本实例r, 挖掘算法的目的是找到所有r满足的CFDs. 为了得到的规则集是非冗余的, 仅包含最小CFDs, 首先给出最小CFDs的形式化定义.
对于R上的CFDφ=(X→A, tp), 如果A∈X,则为平凡的CFD. 因为这样的规则, 当tp[AL]=tp[AR]时, 所有的实例都能满足, 当tp[AL],tp[AR]为不同的常数时, 所有的实例都不能满足. 故我们只考虑非平凡的CFDs. 对于常CFDs, 如果Y⊄X, r|≠(Y→A,( tp[ Y]||a ))则为左约简的. 对于变CFDs, 如果Y⊄X, r|≠(Y→A,( tp[ Y ]||_))且对任意tp≪的有r|≠(Y→A,[Y ]||_))则为左约简的.非平凡的, 左约简的CFD称为最小CFD. 例如, 第一部分中φ0是最小CFD; φ1不是最小CFD, 因为从LHS(φ1)可以删掉属性CC后, 仍有r0|=(AC→CT,(908||MH)).
2.1.5 频繁CFDs
现实中的数据往往包含一些脏数据, 为了排除包含错误的CFD, 只考虑那些模式组的支持度不小于阈值的CFDs. φ=(X→A, tp) 在r中的支持度记为sup(φ,r), 表示r中满足规则φ的元组数. 对自然数k≥1, 如果sup(φ,r)≥k, 则CFD为k-频繁的. 例如φ1是3-频繁的, φ2是2-频繁的.
2.2 编辑规则相关概念
2.2.1 编辑规则定义
定义在(R, Rm)上的编辑规则是一对((X, Xm)→(A, Am),tp[X ]), 其中:
(1)X和Xm分别来自模式R和Rm,X=Xm;
(2)A∈R X, Am∈RmXm;
(3)tp是属性X上的模式组, 对每一个B∈X 的属性, 其值为定义域dom( B)中的某个常数a, 或者任意值, 用"_" 表示.
根据表1得出的四个CFDs, 我们只取LHS(φ)对应的属性值 , 结合主数据表2, 可以得到如下四个编辑规则:
ψ0:(([CC,ZIP],[CC,ZIP])→(STR,POST),(44,_))
ψ1:(([CC,AC],[CC,AC])→(CT,CT),(01,908))
ψ2:(([CC,AC],[CC,AC])→(CT,CT),(44,131))
ψ3:(([CC,AC],[CC,AC])→(CT,CT),(01,212))
从上面的四个编辑规则可以看到来自不同数据源的模式表, 代表同一实体的属性命名是存在差异的,不一定与样本模式表R中的属性对应. 再者, 输入样本可能存在少量脏数据, 为此, 我们只能通过它们的定义域相似度来确定映射关系.
2.2.2 编辑规则语义
编辑规则除了具有静态语义还具有类似于匹配依赖[6](MDs)的动态语义, 根据上面得到的四个编辑规则ψ0-ψ3, 如果t[ X]≤tp[X]且t[ X]=tm[Xm]则t[ A]:=tm[Am], 意思是说如果待修复元组能匹配模式组且能在主数据中找到LHS(ψ)上相等的元组, 则用该元组Am属性上的值修改待修复元组A属性上的值.
2.2.3 等价类划分[7]
定义在属性集X上的等价类为一类在属性X上值相等的元组集, 表示成[t]X={u∈r| t[ A]=u[ A],∀A∈X }. 属性X上所有的等价类组成的集合为属性X上的划分, 记为πX={[t]X,t∈r} . 所有等价类的并集等于实例r. 例如对于表1中的数据, [t1]{AC}=[t2]{AC}=[t4]{AC}=[t7]{AC}={t1, t2, t4, t7}, π{AC}={{t1, t2, t4, t7},{t3},{t5, t6, t8}}.
3 编辑规则挖掘算法
关于函数依赖、条件函数依赖、关联规则挖掘算法的研究, 文献[8]和文献[9]将其统一为数据质量规则, 并提出了数据质量规则挖掘算法QRMiner. 考虑到输入的样本数据本来就可能存在脏数据, 文献[10]还对所挖掘的数据质量规则从3个角度进行了评估.本文主要是对挖掘条件函数依赖算法FastCFD[3]的扩展与改进, 得到编辑规则挖掘算法BEFastER. FastCFD是一种基于深度优先, 能挖掘最小的, k-频繁的CFD算法.
3.1 算法准备
FastCFD的目的是对每一个属性A∈attr( R) 作为规则的右边, 找到所有可能对应的规则左边Y, 形成最小的φ=(Y→A, tp), 其中Y⊆attr( R)A , sup(φ,r)≥k. 我们把这样的规则集记为Cover(A, r, k),显然所有的k-频繁最小CFDs可以由∪A∈attr(R)Cover(A, r, k)组成. 这样我们的任务主要是计算 Cover(A, r, k). 而差集的覆盖与Cover(A, r, k)是有关系的, 差集的最小覆盖对应于最小CFD的LHS(φ).
3.1.1 差集
为了计算Cover(A, r, k), 我们需引入差集的概念[11], 定义在一对元组t1, t2的差集表示为:

得到最小差集后, 需要找到其最小覆盖. 由此, 我们引入覆盖的概念: 令Z⊆attr( R) , X⊆P( attr( R)), P( attr( R))为集合attr( R)的幂集, 如果对每个Y∈X, Y∩Z≠Ø , 则Z覆盖X; 如果不存在Z的真子集也能覆盖X, 则Z为最小覆盖. 这样可以得到Dm(r)的最小覆盖为:
{CT}
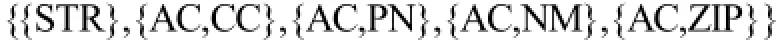
3.1.2 验证CFDs
我们找最小差集的最小覆盖是从模式组(X, tp)开始的, 即从满足模式tp的元组记为rtp中计算出(r), 其最小覆盖Y⊂attr( R)X∪{A}与X组成tp最小CFD φmin=([X, Y]→A,( tp,_,,,_||a)). 对于模式组(X, tp)的获取可以使用文献[12]中GCGROWTH算法得到, 这里只考虑开集, 所谓开集指的是在保持支持度不变的情况下, 不存在Y⊂X, sp=tp[ Y ] 这样的模式组(Y, sp), 则(X, tp)为开集. 对常CFD和变CFD的验证可以根据如下引理[3]来判断.


3.1.3 剪枝策略
剪枝策略告诉我们没有必要考虑所有的k-频繁开集(Xc,tc), 即如果([Xc,Xv]→A,( tc,tv||_))满足要
p pp求, 则所有作为Xc的超集X′, 形成的开集(X′, t′p)就不用考虑了. 这样可以提高挖掘CFD的效率. 下面的引理[3]告诉我们开集作为CFD的常模式部分是充分的.
引理2. 对于变CFDφ=(X→A,( tp||_)), 且r|=φ, sup(φ,r)≥k, 如果φ是最小的, 则(Xc,tc)是
p k-频繁开集.
3.2 算法描述
为了挖掘出有效的编辑规则, 挖掘编辑规则的算法采用改进的FastCFD. FastCFD的主要两个步骤是FindCover和FindMin. 根据引理2, FindCover首先要得到在r上的所有k-频繁开集Frk(r), 并按开集大小升序排序, 即优先考虑开集中包含属性少的开集.为了有效地检索Frk(r)中的元素, 用哈希表存放这些元素. 对F(r)中的每个项集(X, t), 计算Dm(r)的
rkp Atp
最小覆盖, 在该计算过程中会调用FindMin. 下面给出BEFastER的详细过程.

?

?

?
从过程FindCover可以发现, 其中调用了两个方法,分别为genDiffSets和FindMin. genDiffSets方法的作用是根据满足模式tp的元组, 设定的支持度阈值和属性A得到Dm(r). FindMin方法是个递归函数, 主要按Atp深度优先的方式搜索一个按属性字母顺序生成的枚举树, 从根到某个节点的路径可以形成Dcurr的所有子集,然后判断子集Y是否是Dm(r)的最小覆盖, 在该方法Atp中还用Dcurr保存当前还没被Y覆盖的差集, 最后返回所有X与最小覆盖Y形成的CFD规则. 下面详细介绍这两种方法.

?

?
上面生成差集的方法是基于等价类划分的, 只保留等价类中元素个数大于1 的等价类, 且尽量取大集合等价类. 第3 行计算所有属性在tp r 中的划分; 第4行合并所有等价类大小大于1 的等价类; 第6-9 行求MC 中所有等价类中所有元组具有相同值的属性集;与文献[3]中的计算差集的方法相比, 减少了元组对的比较次数. 下面介绍FindMin .

?
算法BEFastER首先计算了两个全局变量, 一个存放属性对的哈希表, 将CFD规则中的属性与主数据中的属性关联起来; 另一个为存放所有k-频繁开集Frk( r)的哈希表, 并作为FindCover的参数.
3.3 算法应用
为了验证算法的有效性, 将其应用于表1和表2,过程如下:
(1) 根据文献[12]提供的算法可以得到所有的3-频繁开集为:
Fr3(r)={(CC,01),(CC,44),(AC,131),(PN,2222222),(ZIP,07974), (CT,MH),(AC,908),([CC,AC],[01,908]),([CC,CT],[01,MH])}
(2) 从Fr3中取一个开集(CC,01)为例, 展开下面的计算.
(3) 扫描表1中的数据, 找出满足t[CC]=01的元组有rCC=01={t1, t2, t3, t4, t8}.
(4) 调用genDiffSets方法, 计算每个属性的划分取等价类中元素大于1的等价类, 得到如下结果:
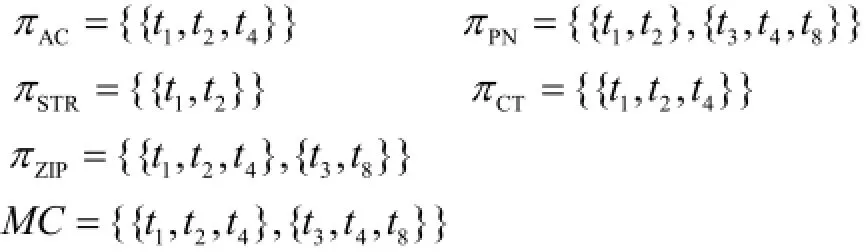
这里不妨把规则右边定为STR, NM在每个元组中都不一样, 这里不考虑该属性则Dm(r)={[PN],[AC,CT]}.
STRcc=01
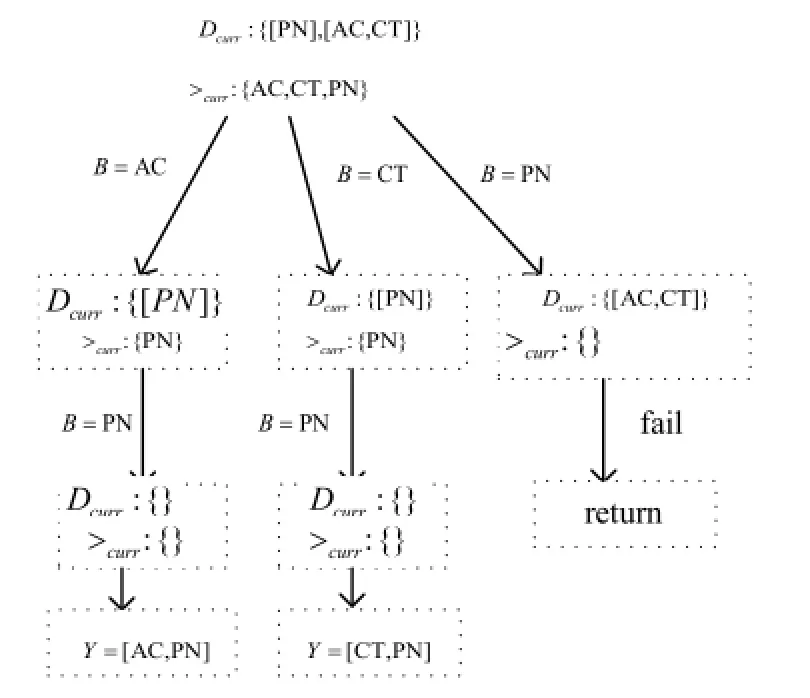
图1 方法的部分过程
(6) 根据(5)中得到Y, 可以得到两个最小变CFDs, 分别为:
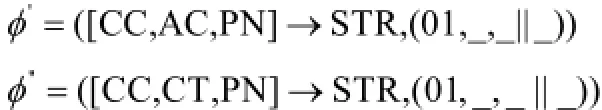
(7) 由于表1中存在脏数据且表1和表2的记录分别只是模式表R和mR的部分, 这里我们设定相似度阈值为0.5, 存在于哈希表有(CC,CC), (AC,AC), (CT,CT), (PN,TEL), (STR,POST).
(8) 最后得到的编辑规则为:

3.4 算法复杂度分析
BEFastER算法的时间主要消耗在genDiffSets方法和FindMin上, genDiffSets中最耗时的是计算等价类所花的时间, 在最坏的情况下, 由关系属性数目和满足模式tp的元组数决定, 故此方法的时间复杂度为O(|R|); FindMin是个递归方法, 会占用一定的栈空间, 但可以减少遍历R{A}所有子集的时间, 栈空间由递归次数决定, 递归次数越多, 程序结束越迟,相应的时间开销就越大, 在最坏情况下, 时间复杂度为O(|>curr|log(|>curr|)), >curr为最开始传入的>curr. 对比genDiffSets所花的时间, 这点时间可以忽略. 如果不考虑GCGROWTH计算开集的时间, 则BEFastER的总的时间开销为O(|Frk(r)||R||, |Frk(r)|为开集数目.
4 实验
本节主要通过来自医院的真实数据HOSP[13]来进行实验研究, 将从响应时间和挖掘的规则数目两个指标来验证算法的有效性. 并比较了改进算法与扩展的文献[3]算法. 主要改进在计算差集的方法上和判断常CFDs的条件上.
4.1 实验数据和环境
实验数据: 由于主数据的获取比较难, 假设以处理的HOSP为主数据HOSPM, 即去除HOSP中的空值和异常值记录, 得到干净的主数据进行模拟. 这样一来匹配主数据属性这步基本可以忽略. HOSP包括七个属性和9455条记录.
实验环境: 我们用java语言在window7操作系统, Mysql数据库管理系统, Intel Core i5-2400 3.10GHz CPU和4G内存下实现了本文的算法. 每次实验重复了5次, 取平均结果.
4.2 实验结果
在数据集HOSP和HOSPM下, 随着支持度阈值的变化, 本文改进的算法BEFastER和基于文献[3]的FastER的响应时间如图2所示.

图2 关于支持度阈值k的时间变化
从上面的结果可以知道, 两种算法基本对支持度的敏感程度都不大, 和文献[3]的结论一致, 但在所得规则数一样的情况下, 我们改进后的算法比直接扩展的性能更好.
另一个实验结果是BEFastER随支持度的变化,挖掘的规则数的变化情况, 如下图3所示, 规则数随支持度的加大, 不管是常规则数还是变规则数都在明显地减少.
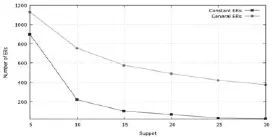
图3 关于支持度阈值k的规则数变化
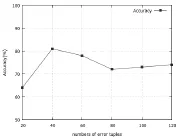
图4 数据集D中包含错误元组数对修复正确率的影响
为了验证所得的编辑规则是否能修复数据, 我们根据编辑规则语义进行了修复实验, 将支持度为20得到的编辑规则应用于添加了错误的数据集HOSP. 由图4 的结果可以知道, 修复准确率能稳定达到70%-80%, 不能达到100%的主要原因是我们不能确定t[LHS(φ)]的值是否正确, 如果待修复的元组中错误的t[LHS(φ)]匹配了tm[LHS(φ)], 那么将会导致错误的修复. 另一个原因是在存在错误样本情况下, 我们挖掘的编辑规则很难做到完全正确.
5 结语
本文提出了基于条件函数依赖挖掘的编辑规则挖掘算法, 从编辑规则的形式化定义来看, 与CFD相比,只是多了主数据中的属性, 所以本文的第一个工作是重点挖掘最小CFDs包括常CFDs和变CFDs, 此工作的主要耗时任务是计算差集和最小覆盖, 而本文计算差集的方法大大减少了元组对的比较, 在得到差集为空时, 考虑到输入样本中存在错误, 我们降低了值非得唯一的要求, 从而可以得到更多的常CFDs. 对得到的CFDs只利用其模式组的左边部分, 用于匹配待修复的元组; 第二个工作是在主数据中找对应的属性,由于来自不同数据源的表结构存在差异, 我们采用了基于定义域的简单计算模型, 理想状态下对应属性定义域应该是一样的. 但由于输入样本中存在脏数据,定义域只能近似匹配. 本文通过实验验证了我们所提算法的有效性, 能在有限的时间里挖掘出编辑规则,并对所得的编辑规则按照编辑规则语义进行了质量评估, 进一步验证了我们的算法确实实用有效.
1 Fan W, Li J, Ma S, et al. Towards certain fixes with editing rules and master data. Proc. of the VLDB Endowment, 2010, 3(1-2): 173–184.
2 Cong G, Fan W, Geerts F, et al. Improving data quality: Consistency and accuracy. Proc. of the 33rd international conference on very large data bases. VLDB Endowment. 2007. 315–326.
3 Fan W, Geerts F, Li J, et al. Discovering conditional functional dependencies. IEEE Trans. on Knowledge and Data Engineering, 2011, 23(5): 683–698.
4 Fan W, Geerts F, Jia X, et al. Conditional functional dependencies for capturing data inconsistencies. ACM Trans. on Database Systems (TODS), 2008, 33(2): 6.
5 胡艳丽,张维明.条件依赖理论及其应用展望.计算机科学, 2009,36(12):115–118.
6 Fan W, Ma S, Tang N, et al. Interaction between record matching and data repairing. Journal of Data and Information Quality (JDIQ), 2014, 4(4): 16.
7 Huhtala Y, Kärkkäin J, Porkka P, et al. TANE: An efficient algorithm for discovering functional and approximate dependencies. The computer journal, 1999, 42(2): 100–111.
8 刘波,耿寅融.数据质量检测规则挖掘方法.模式识别与人工智能,2012,25(5):835–844.
9 Medina R, Nourine L. A unified hierarchy for functional dependencies, conditional functional dependencies and association rules. Lecture Notes in Computer Science, 2009, 5548: 98–113.
10 Chiang F, Miller R J. Discovering data quality rules. Proc. of the VLDB Endowment, 2008, 1(1): 1166–1177.
11 Wyss C, Giannella C, Robertson E. Fastfds: A heuristicdriven, depth-first algorithm for mining functional dependencies from relation instances extended abstract. Data Warehousing and Knowledge Discovery. Springer Berlin Heidelberg. 2001. 101–110.
12 Li H, Li J, Wong L, et al. Relative Risk and Odds Ratio: A Data Mining Perspective (Corrected Version). Pods, 2005: 368–377.
13 http://www.hospitalcompare.hhs.gov/.
Method for Discovering Editing Rules From Sample Inputs and Master Data
YANG Hui, YU Shou-Jian, CHEN Shao-Zong
(School of Computer Science and Technology, Donghua University, Shanghai 201602, China)
Data repairing based on editing rules and master data can automatically and exactly fix inconsistent data, but editing rules mainly relies on the definition by professional staff at present. To achieve data cleaning automatically in the whole process, the techniques for discovering data rules become a hot research topic in recent years. The algorithms for mining CFDs mainly involve CFDMiner, CTANE, FastCFD. Based on the above techniques, we provide a mining algorithm for editing rule, which is based on sample inputs and master data under the extension definition of CFD and the definition of edit rules. The main ideas is as below: Mining CFD from sample inputs firstly; then according to the domain similarity between input samples and master data, we can get the corresponding properties of input samples from the master data, forming editing rules with pattern group. The algorithm can effectively discover edit rules. And the mined edit rules can effectively repair the data in accordance with the semantic of the rules.
editing rules; conditional functional dependency; data cleaning; equivalence classes partitions
2016-07-17;收到修改稿时间:2016-09-13
10.15888/j.cnki.csa.005728
