一种局部聚合描述符和组显著编码相结合的编码方法
2017-05-16费宇杰吴小俊
费宇杰,吴小俊
(江南大学 物联网工程学院,江苏 无锡 214122)
一种局部聚合描述符和组显著编码相结合的编码方法
费宇杰,吴小俊
(江南大学 物联网工程学院,江苏 无锡 214122)
局部聚合描述符(vector of locally aggregated descriptors, VLAD)的特征编码方法在大规模图像检索上取得了较好的效果。但是,VLAD存在硬分配难以准确描述局部特征向量与视觉词汇隶属关系的问题,本文将两种软分配编码与VLAD相结合来增强局部特征向量与视觉词汇的隶属关系。新的编码方法在15 Scenes、Corel 10 和 UIIC Sports Event 数据库上的实验结果表明:1)在VLAD中加入局部软分配能够提高分类准确率,而且对比Fisher编码在分类准确率上也有一定的优越性;2)除了软分配,显著性对提高分类准确率也起到了一定的作用。
图像分类;特征编码;词袋;局部聚合描述符;软分配;显著性
图像分类是计算机视觉和模式识别中的一个重要的研究方向,它有广泛的应用,例如:视频监控[1]、图像检索[2]、网页内容分析[3]。从文本分析中的BoW(bag-of-words)模型[4]发展而来的BoF(bag-of-features)模型[5]是当前最有效的图像分类框架。
1 问题提出
如图1所示,BoF模型通常包含5个步骤,特征提取、字典生成、特征编码、特征池化和分类。所谓特征编码是用字典中的视觉词汇来表示图像中的局部特征向量,局部特征在视觉词汇上的响应被称为编码系数,将不同视觉词汇的编码系数组合在一起就是编码向量。特征编码是整个BoF模型的关键,编码的好坏会对分类效果产生巨大的影响。根据文献[6],我们将编码方法分为4类,如图2所示。编码方法中,最简单的方法是将局部特征向量指定到离它最近的视觉词汇上并设置其编码系数为非零的值,用这个视觉词汇来代表该特征向量,这种“硬指定(Hard-assignment)[5]”的编码方法没有考虑到特征向量隶属视觉词汇的模糊性[7],并且会产生巨大的量化误差。文献[8]提出一种“软指定(Soft-assignment)”的编码方法,通过指定特征向量到所有视觉词汇上从而减轻了“硬指定”编码带来的问题。基于重构的编码方法是选择一些视觉词汇来重构局部特征向量。例如:稀疏编码[9](sparse coding)是使编码向量稀疏,而LLC[10](local-constraint linear coding)是选择局部的视觉词汇来重构特征向量。高维的编码方法,像Fisher核编码[11](fisher kernel coding)和SVC[12](super vector coding)只需少量的视觉词汇就能获得较好的分类结果。VLAD编码[13]可以看作是Fisher核编码的简化版,下一节将对它详细介绍。最近,由于显著编码的高效性和有效性,它得到了很多关注。显著编码认为显著性是特征编码的重要特性。SaC[14](salient coding)将显著系数作为编码系数,显著系数是通过局部特征到不同视觉词汇间的距离计算得来的。GSC[15](gruop salient coding)是SaC的改进版,它的思想是将视觉词汇分成不同的组,不同的组得到不同的编码系数。
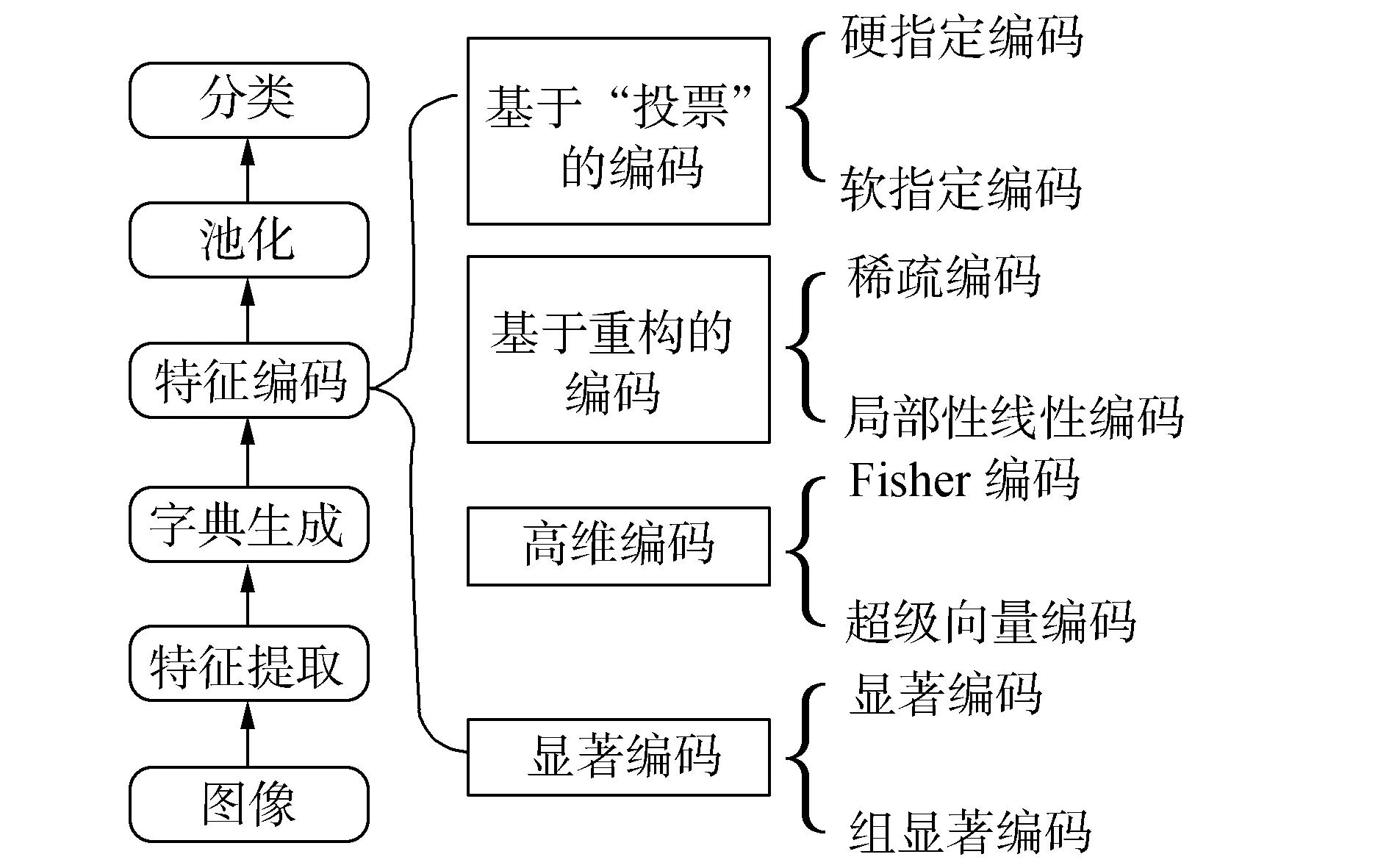
图1 BoF模型流程图 图2 编码方法分类Fig.1 The general pipelineof the BoF framework Fig.2 A taxonomy ofcoding methods
通过对编码方法的回顾可以发现,无论是从Hard-assignment到Soft-assignment,还是从SaC到GSC都是通过软分配的思想来增加局部特征与视觉词汇之间的隶属关系信息,从而提高了分类的正确率。我们将软分配的思想加入VLAD中来改进原始的VLAD。在不同的数据集上的实验结果表明:1)软分配能够提高原始VLAD的分类准确率,并且对比Fisher核编码在分类正确率上也有一定的优越性。但是,并不是任意的软分配都能提高分类正确率,只有局部的软分配(这里局部的意思是特征向量只有在离它最近的几个视觉词汇上有响应系数)才能提高VLAD的分类正确率;2)除了软分配,显著性对提高分类正确率也起到了一定的作用,我们认为这是因为显著编码考虑到了不同视觉词汇之间的联系。
2 相关工作
1)Harding-assignmentCoding。局部特征xi只在离它最近的视觉词汇上有编码系数。
(1)
2)Soft-assignmentCoding。uij可以理解为局部特征xi在视觉词汇bj上的隶属度。
(2)
3)SaliencyCoding。显著编码(SaC)是将局部特征与离它最近的视觉词汇和其他视觉词汇的距离的比值作为该局部特征的编码结果。
(3)
(4)
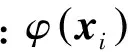
4)GroupSaliencyCoding。GSC可以看做SaC的“软分配版本”,它把视觉词汇分成不同的组,局部特征在不同组上得到不同的响应系数,图3描绘了组显著编码的思想。
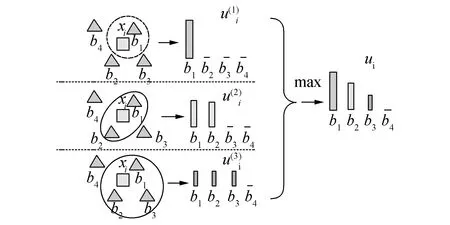
图3 组显著编码Fig.3 Group saliency coding
(5)
(6)
(7)

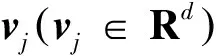
(8)
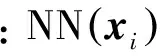
3 改进的VLAD编码方法
根据上一章节的介绍,我们发现原始的VLAD存在硬分配难以准确描述局部特征向量与视觉词汇隶属关系的问题。在这一章节中,提出3种新的VLAD编码方法,分别是SA_VLAD编码方法,GSC_VLAD编码方法以及SaC_VLAD编码方法。
1)SA_VLAD。SA_VLAD编码是将Soft-assignment编码中解决局部特征与视觉词汇隶属关系的方法加入到原始VLAD编码中。Soft-assignment编码中是用高斯核函数的值来表示局部特征向量与视觉词汇的隶属度。
(9)
(10)
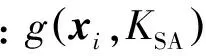
2)GSC_VLAD。GSC_VLAD编码是将GSC编码中组显著性的思想加入到原始VLAD中来解决局部特征向量与视觉词汇的隶属关系问题。GSC编码中用显著性来表示局部特征向量与视觉词汇的隶属度,同时显著性考虑到了不同视觉词汇之间的联系。
(11)
(12)
(13)
(14)
式中:KGSC表示有编码系数的视觉词汇的个数,即KGSC个视觉词汇会有响应系数。
3)SaC_VLAD。SaC中用显著系数作为编码系数,显著系数是指局部特征与离它最近的视觉词汇和其他视觉词汇的距离的比值,显著系数考虑到了不同视觉词汇之间的联系。将SaC与原始VLAD相结合,使VLAD在编码过程中考虑不同视觉词汇之间潜在的联系。
(15)
(16)
(17)
式中:KSaC表示有KSaC个视觉词汇用来计算局部特征的显著系数。
算法1 改进的VLAD编码方法
输出VLAD向量。
%计算每个局部特征向量在各个视觉词汇上的编码系数
fori=1,2,…,N
根据式(9)或者式(11)或者式(15)计算相应的uij
end
%计算VLAD向量
%根据文献[17],对最终的VLAD向量进行能量范数和L2范数归一化
V=V/‖V‖2
4 实验结果与分析
本实验为了证明以下3点:1)软分配能提高VLAD的分类正确率,甚至对比Fisher编码在分类正确率上有一定的优越性;2)只有局部软分配才能有效提高分类正确率;3)除了软分配,显著性对提高分类正确率也起到了一定的作用。
本文在3个数据集(15 Scenes[18]、Corel 10[19]和UIUC Sports Events[20])上进行了实验。对于15 Scenes和Corel 10数据集,我们指定每张图片的最大单边像素为300。UIUC Sports Events数据集中图片的分辨率较高,因此指定每幅图片的最大单边像素为400。我们采用Dense SIFT算法[21]来提取每幅图像的sift特征向量,采样的步长是6个像素,每个采样块的大小为16×16。采用K-means[22]聚类算法生成视觉字典。分类器采用Lib-linearSVM[23],并指定SVM的惩罚系数为1。我们将数据集分为5组,每组随机生成训练样本和测试样本,最后的分类正确率是5组实验的平均值。对于式(9)中的β和KSA,分别设置其值为10和10。对于式(11)中的KGSC设置其值为10。关于KSA和KGSC对实验结果的影响,将在4.2节中详细讨论。
4.1 新的编码对比原始的VLAD和Fisher编码
将4种编码方法SA_VLAD、GSC_VLAD、VLAD和Fisher编码进行对比。
1)15Scenes。 该数据集由15个场景类别构成,总共4 485张图片。每个类别都是相似场景图片的一个集合,大约包含200~400张图片,每张图片的平均尺寸为300×250。我们采用Lazebnik等[21]的实验设置,从每类场景中随机选择100张图片作为训练集,其余图片作为测试集。分别在不同的视觉字典大小下进行了实验,实验结果如图4。
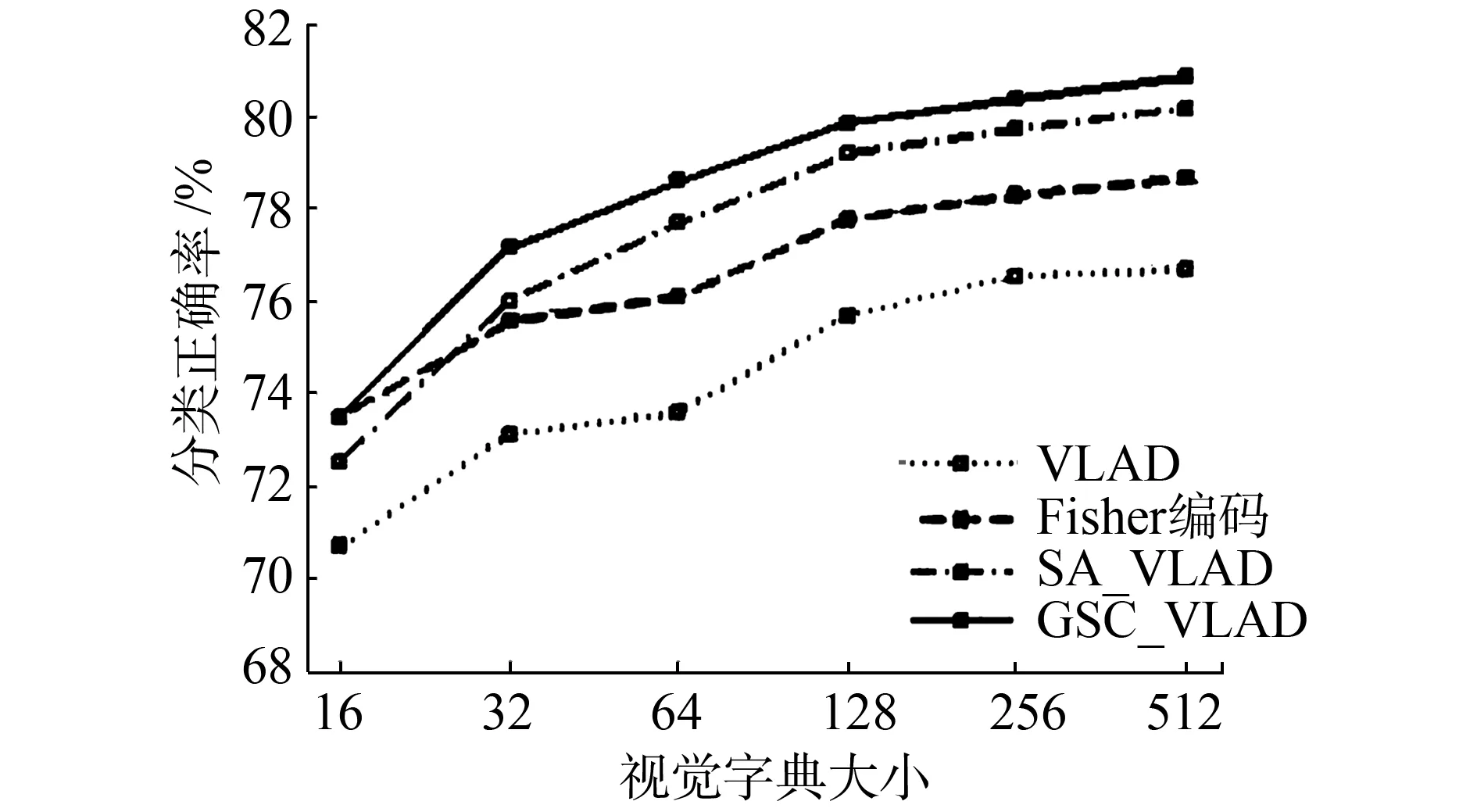
图4 4种不同编码方法在15 Scenes上的分类结果Fig.4 Performance comparison on the 15 Scenes
从图4中可以看出,软分配的VLAD比原始的VLAD编码有显著的提升,当视觉字典的大小为512时,VLAD的分类正确率为76.66%,SA_VLAD和GSC_VLAD的分类正确率分别为80.18%和80.84%,有4%~5%的提升。对比Fisher编码的78.66%的正确率,也有2%的提升。同时GSC_VLAD的分类正确率在不同的视觉字典大小下均高于SA_VLAD,表1显示了4种编码各自的最佳分类正确率。
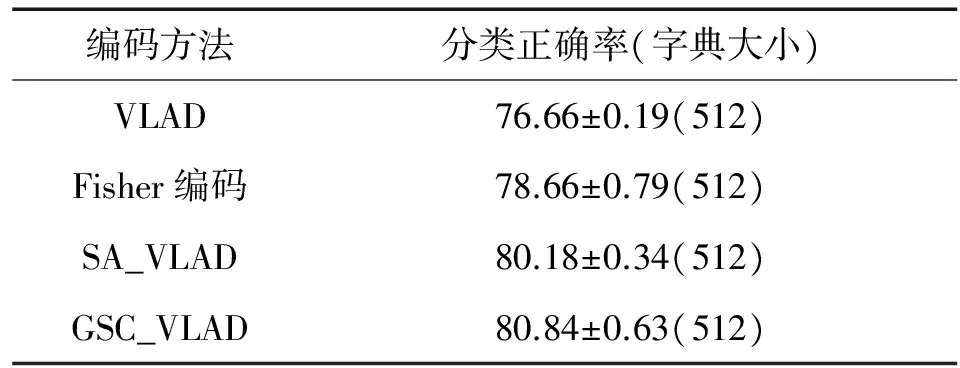
表1 15 Scenes数据集上的最佳分类正确率
2)Corel 10。该数据集共有10个类别,每类共有100张图片,每张图片的平均尺寸为384×256。本文从每类场景中随机选择50张图片作为训练集,剩下的50张作为测试集。实验结果如图5所示。
实验结果基本和15Scenes数据集上的结果类似,从图4中可以看出,SA_VLAD和GSC_VLAD对比原始的VLAD在分类正确率上有明显的提升,并且对比Fisher编码有一定的可比性。值得注意的是GSC_VLAD的分类正确率在不同的视觉字典大小下还是均高于SA_VLAD。表2显示了4种编码各自的最佳分类正确率。

图5 4种不同编码方法在Corel 10上的分类结果Fig.5 Performance comparison on the Corel 10
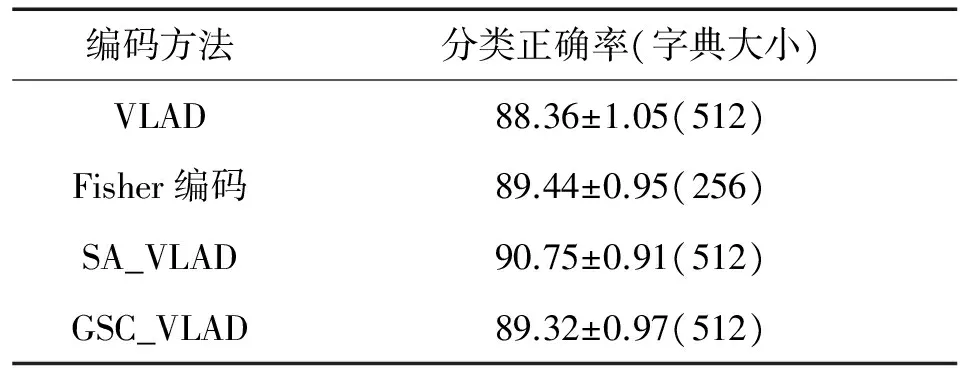
编码方法分类正确率(字典大小)VLAD88.36±1.05(512)Fisher编码89.44±0.95(256)SA_VLAD90.75±0.91(512)GSC_VLAD89.32±0.97(512)
3)UIUC Sports Event。该数据集包含8个类别,总共1 579张图片,每类大约有137~250张图片。本文从每类中随机抽取70张图片作为训练集,从余下的图片中随机抽取60张作为测试集。实验结果如图6所示。
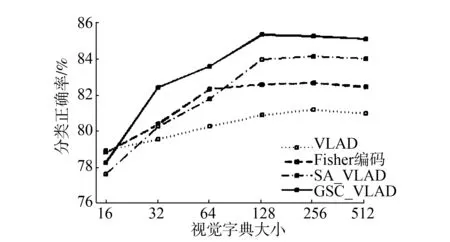
图6 4种不同编码方法在UIUC上的分类结果Fig.6 Performance comparison on the UIUC
从图6中可以看出,随着视觉字典大小的增加,SA_VLAD和GSC_VLAD对比原始VLAD在分类正确率上有显著的增加,对比Fisher编码也有一定的优越性。与上两个实验相同,GSC_VLAD的分类正确率在不同字典大小下都超过了SA_VLAD。表3显示了4种编码各自的最佳分类正确率。

表3 UIUC数据集上的最佳分类正确率
4.2 算法中参数的影响
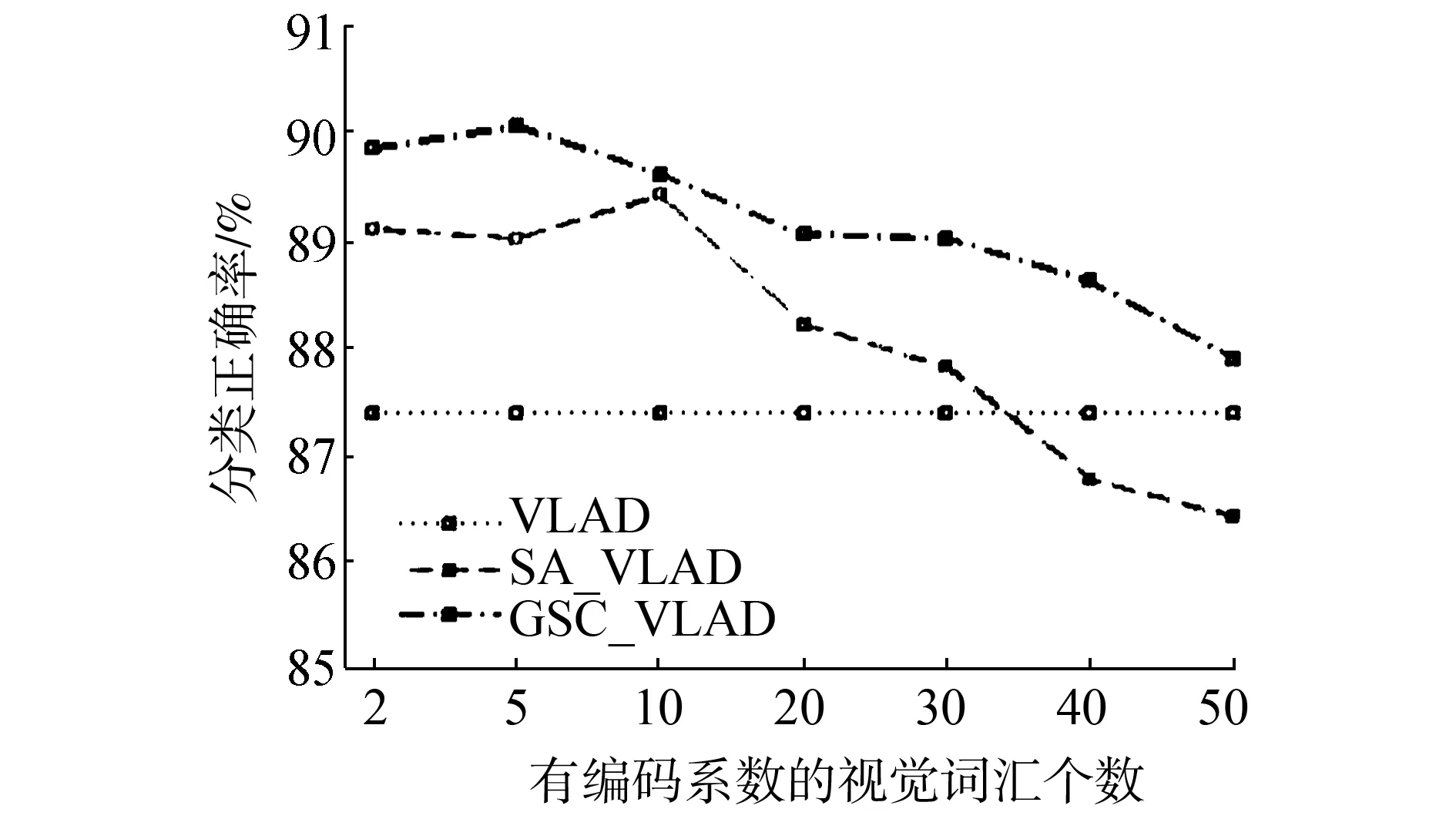
这一节中,我们讨论式(9)和式(11)中的KSA和KGSC这两个参数对实验结果的影响。这两个参数表示有编码系数的视觉词汇的个数。实验中这两个参数都用K来表示,当视觉字典大小为128时,实验结果如图7所示。

(a) 15 Scenes
(b)Corel 10
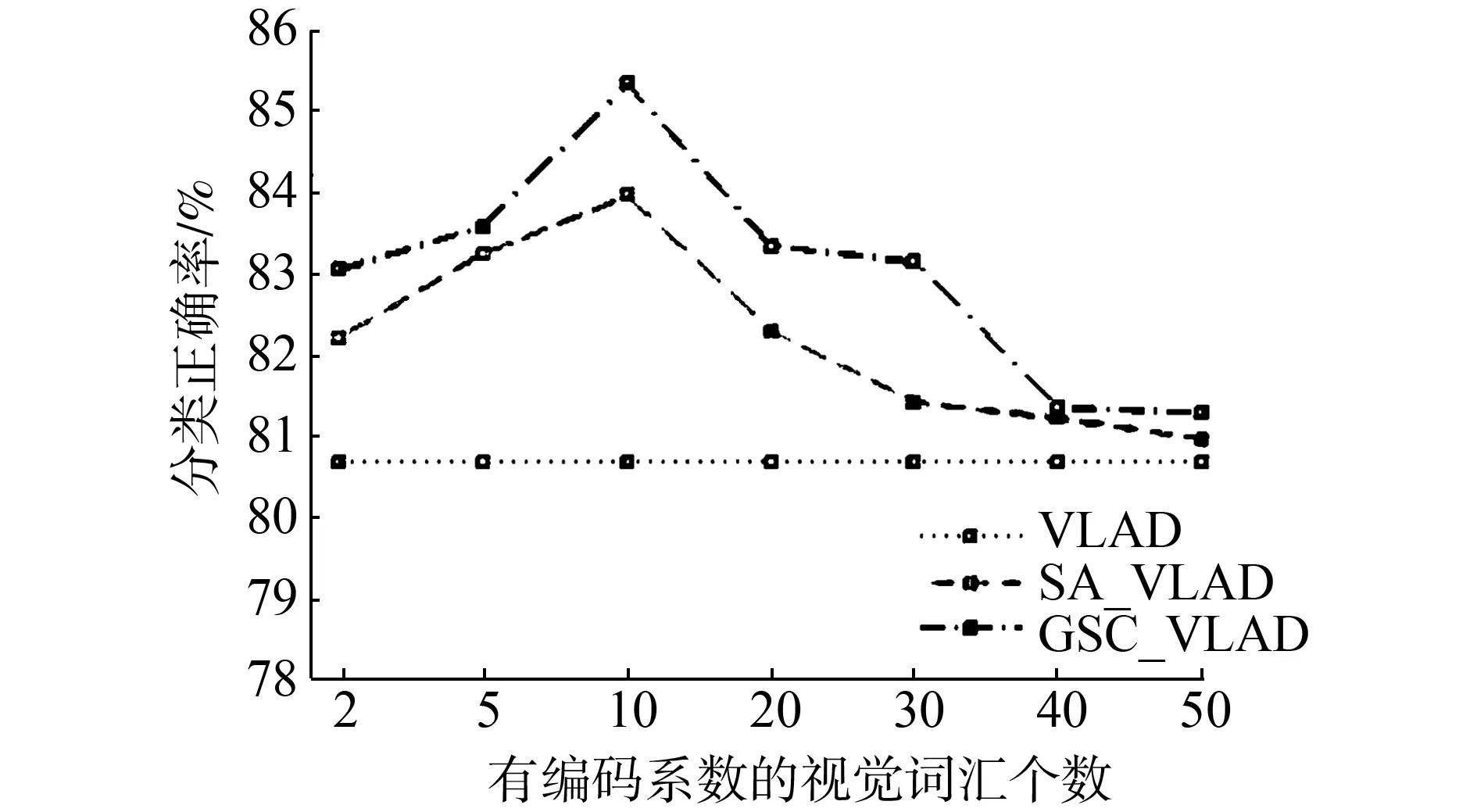
(c)UIUC图7 参数K在不同数据集上的影响Fig.7 The effect of parameterKon different dataset
图8中,我们加入了原始的VLAD以便比较。从图中可以看到随着K的递增,SA_VLAD和GSC_VLAD的分类正确率逐渐减小,只有在K较小时才能达到比较高的分类正确率。这说明了并不是响应局部特征的视觉词汇越多越好,只有局部的软分配才能有效地提升VLAD的分类正确率。
(a) 15 Scenes

(b)Corel 10
(c)UIUC图8 显著性对实验结果的影响Fig.8 The effect of saliency
3.3 显著性对结果的影响
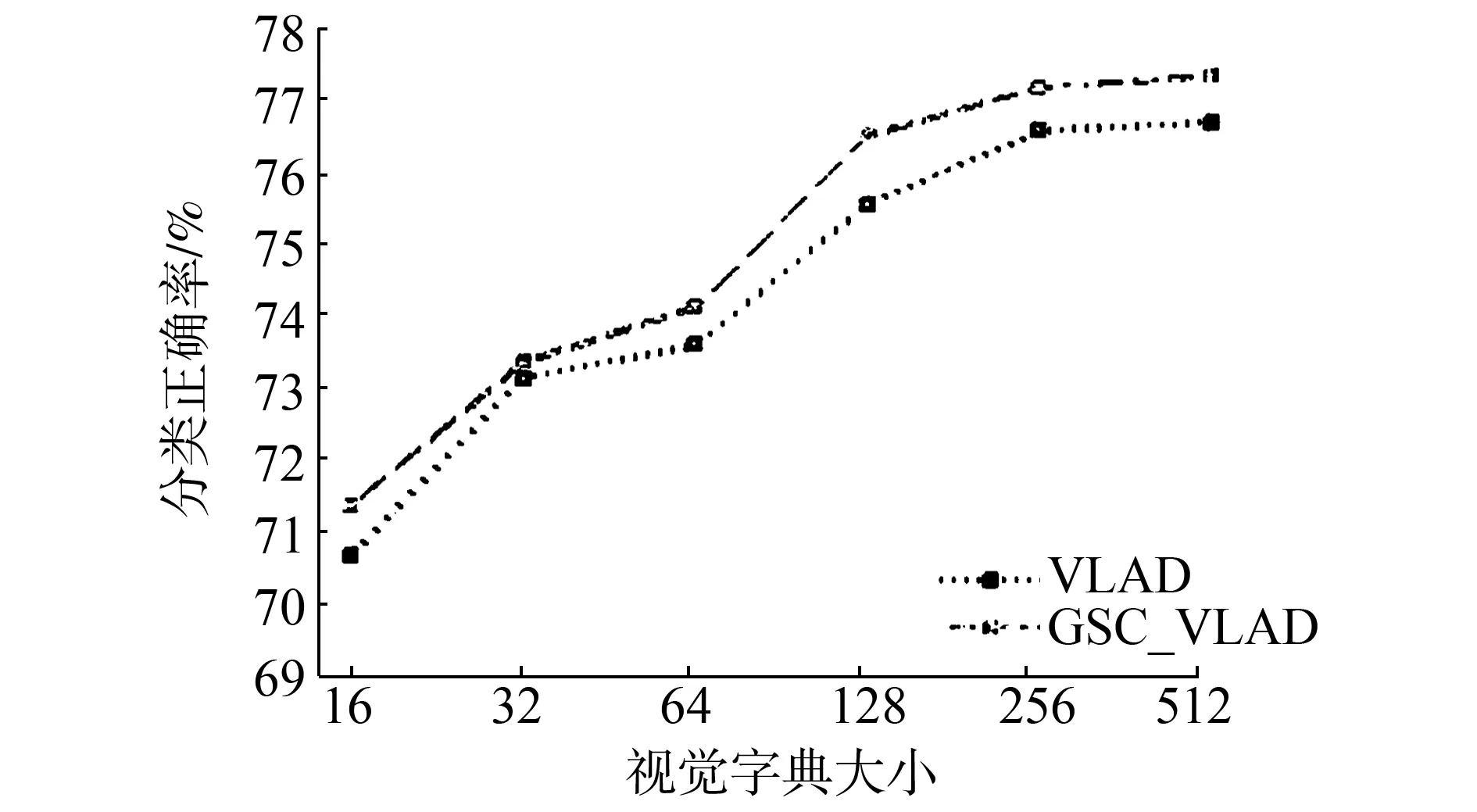
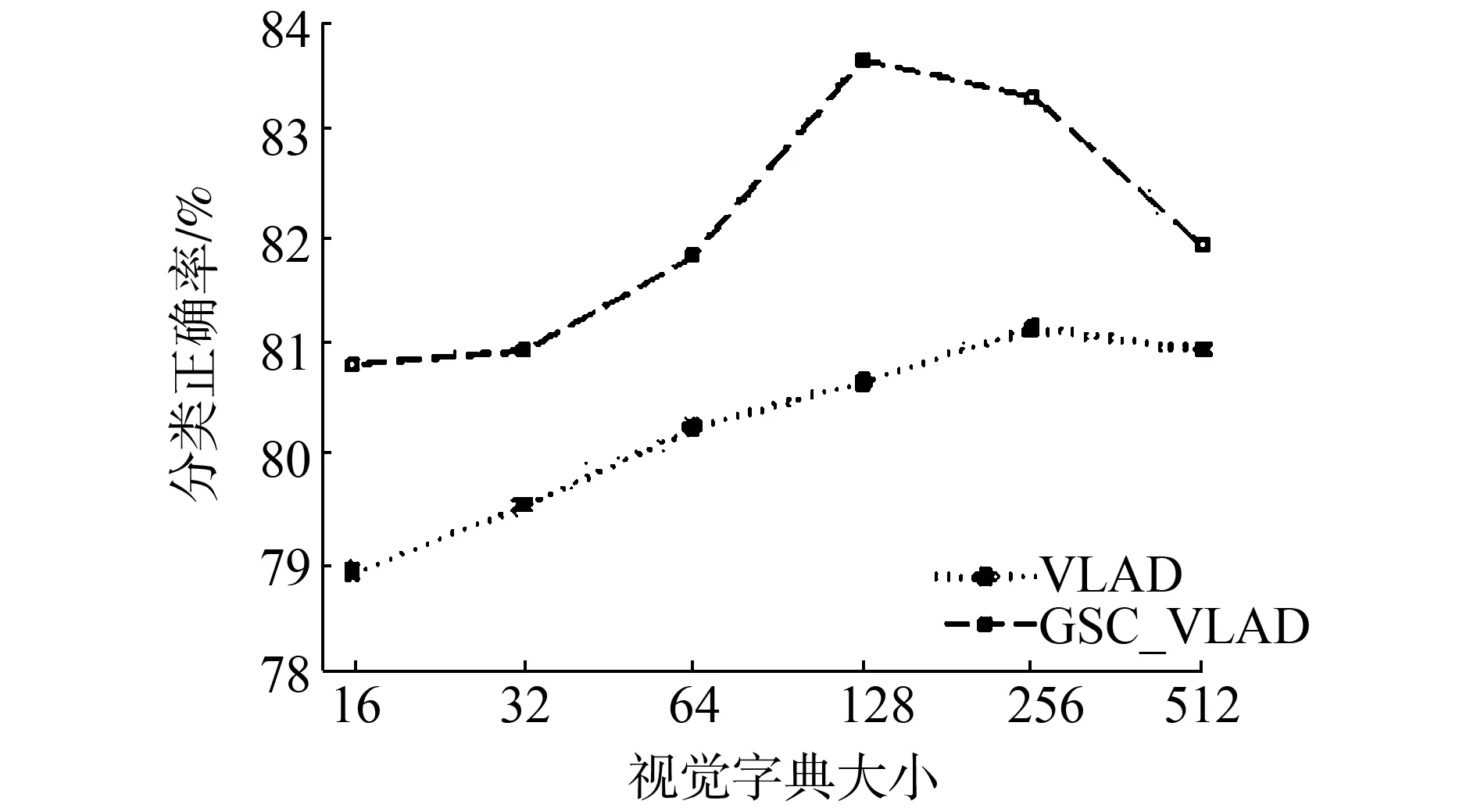
根据上面两节的介绍,我们发现GSC_VLAD的分类效果要略好于SA_VLAD,我们认为这是显著性带来的影响,因为显著性考虑了不同视觉词汇间的联系。为了排除软分配对实验结果的影响,我们用新的编码算法SaC_VLAD与VLAD编码进行比较。图7是视觉字典大小不同时,SaC_VLAD算法在3个数据集上的结果。
对比原始的VLAD,SaC_VLAD对分类正确率有一定的提升。当视觉字典的大小是128时,在15 Scenes数据集上,VLAD的分类正确率是75.52±0.61%,SaC_VLAD的分类正确率是76.47±0.33%。在Core 10数据集上,VLAD的分类正确率是87.36±1.28%,SaC_VLAD的分类正确率是89.12±1.11%。在UIUC数据集上,VLAD的分类正确率是80.67±1.50%,SaC_VLAD的分类正确率是83.63±1.76%。实验结果证明,在VLAD中加入显著性能提高原始VLAD的分类正确率。
5 结束语
本文提出的GSC_VLAD编码方法能对原始的VLAD在分类正确率上带来有效的提升,同时对比Fisher编码也有一定的优越性。这种提升的原因是:1)在VLAD中加入了局部的软分配,解决了原始VLAD中硬分配难以准确描述局部特征向量与视觉词汇隶属关系的问题;2)显著性编码考虑了不同视觉词汇之间潜在的联系,对提升分类效果也起到了一定的作用。
在实验的过程中,我们发现新的编码方法在图像有噪声的情况下分类效果要好于原始的VLAD,但是正确率对比没有噪声时下降得很厉害,因此如何提升新的编码方法的鲁棒性将是未来的研究重点。
[1]COLLINS R T, LIPTON A J, KANADE T, et al. A system for video surveillance and monitoring[R]. CMU-RITR-00-12. Pittsburgh, Penn: Carnegie Mellon University, 2000.
[2]VAILAYA A, FIGUEIREDO M A T, JAIN A K, et al. Image classification for content-based indexing[J]. IEEE transactions on image processing, 2001, 10(1): 117-130.
[3]KOSALA R, BLOCKEEL H. Web mining research: a survey[J]. ACM SIGKDD explorations newsletter, 2000, 2(1): 1-15.
[4]JOACHIMS T. Text categorization with support vector machines: learning with many relevant features[C]//Proceedings of the 10th European Conference on Machine Learning. Berlin Heidelberg: Springer, 1998.
[5]DANCE C, WILLAMOWSKI J, FAN Lixin, et al. Visual categorization with bags of keypoints[C]//Proceedings of ECCV International Workshop on Statistical Learning in Computer Vision. Prague, CZ, 2004.
[6]HUANG Yongzhen, WU Zifeng, WANG Liang, et al. Feature coding in image classification: a comprehensive study[J]. IEEE transactions on pattern analysis and machine intelligence, 2014, 36(3): 493-506.
[7]VAN GEMERT J C, VEENMAN C J, SMEULDERS A W M, et al. Visual word ambiguity[J]. IEEE transactions on pattern analysis and machine intelligenc, 2010, 32(7): 1271-1283.
[8]VAN GEMERT J C, GEUSEBROEK J M, VEENMAN C J, et al. Kernel codebooks for scene categorization[C]//Proceedings of the European Conference on Computer Vision. Berlin Heidelberg: Springer, 2008: 696-709.
[9]YANG Jianchao, YU Kai, GONG Yihong, et al. Linear spatial pyramid matching using sparse coding for image classification[C]//Proceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, FL: IEEE, 2009: 1794-1801.
[10]WANG Jinjun, YANG Jianchao, YU Kai, et al. Locality-constrained linear coding for image classification[C]//Proceedings of 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA: IEEE, 2010: 3360-3367.
[11]PERRONNIN F, DANCE C. Fisher kernels on visual vocabularies for image categorization[C]//Proceedings of 2007 IEEE Conference on Computer Vision and Pattern Recognition. Minneapolis, MN: IEEE, 2007.
[12]ZHOU Xi, YU Kai, ZHANG Tong, et al. Image classification using super-vector coding of local image descriptors[C]//Proceedings of the 11th European Conference on Computer Vision. Berlin Heidelberg: Springer, 2010: 141-154.
[13]JÉGOU H, DOUZE M, SCHMID C, et al. Aggregating local descriptors into a compact image representation[C]//Proceedings of 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA: IEEE, 2010: 3304-3311
[14]HUANG Yongzhen, HUANG Kaiqi, YU Yinan, et al. Salient coding for image classification[C]//Proceedings of 2011 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI: IEEE, 2011.
[15]WU Zifeng, HUANG Yongzhen, WANG Liang, et al. Group encoding of local features in image classification[C]//Proceedings of the 21st International Conference on Pattern Recognition. Tsukuba: IEEE, 2012.
[16]LIU Lingqiao, WANG Lei, Liu Xinwang. In defense of soft-assignment coding[C]//Proceedings of 2011 IEEE International Conference on Computer Vision. Barcelona: IEEE, 2011.
[17]PERRONNIN F, SANCHEZ J, MENSINK T. Improving the fisher kernel for large-scale image classification[C]//Proceedings of the 11th European Conference on Computer Vision. Berlin Heidelberg: Springer, 2010: 143-156.
[18]LI F F, PERONA P. A Bayesian hierarchical model for learning natural scene categories[C]// IEEE Computer Society Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2005: 524-531.
[19]LI Jia, WANG J Z. Automatic linguistic indexing of pictures by a statistical modeling approach[J]. IEEE transactions on pattern analysis and machine intelligence, 2003, 25(9): 1075-1088.
[20]LI Lijia, LI Feifei. What, where and who? Classifying events by scene and object recognition[C]//Proceedings of the 11th International Conference on Computer Vision. Rio de Janeiro: IEEE, 2007: 1-8.
[21]LAZEBNIK S, SCHMID C, PONCE J. Beyond bags of features: spatial pyramid matching for recognizing natural scene categories[C]//Proceedings of 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York, NY, USA: IEEE, 2006: 2169-2178.
[22]LLOYD S. Least squares quantization in PCM[J]. IEEE transactions on information theory, 1982, 28(2): 129-137.

费宇杰,男,1992年生,硕士研究生,主要研究方向为图像分类、特征编码。

吴小俊,男,1967年生,教授,主要研究方向为模式识别,计算机视觉,模糊系统,神经网络,智能系统。
A new feature coding algorithm based onthe combination of group salient coding and VLAD
FEI Yujie, WU Xiaojun
(School of IoT Engineering, Jiangnan University, Wuxi 214122, China)
The vector of locally aggregated descriptors (VLAD) has achieved good results in addressing large-scale image retrieval problems; however, VLAD has a defect in that the relationship between local descriptors and visual words cannot be accurately described using hard assignments. In this paper, we therefore combine two kinds of soft assignment coding methods with VLAD to enhance the relationship between local feature vectors and visual words. We applied our method to 15 scenes from the Corel 10 and UIUC Sports Event datasets, with our experimental results showing that our combined partial soft assignment coding method and VLAD was able to enhance classification accuracy and achieve better classification accuracy than the well-known Fisher Coding approach. In addition to soft assignment, saliency also plays an important role in enhancing classification accuracy.
image classification; feature coding; bag-of-features; VLAD; soft assignment; saliency
2016-03-01.
日期:2017-01-16.
国家自然科学基金项目(61373055, 61672265); 江苏省教育厅科技成果产业化推进项目(JH10-28).
吴小俊. E-mail:xiaojun_wu_jnu@163.com.
10.11992/tis.201602010
http://www.cnki.net/kcms/detail/23.1538.tp.20170116.1115.002.html
TP391
A
1673-4785(2017)02-0172-07
费宇杰,吴小俊. 一种局部聚合描述符和组显著编码相结合的编码方法[J]. 智能系统学报, 2017, 12(2): 172-178.
英文引用格式:FEI Yujie, WU Xiaojun. A new feature coding algorithm based on the combination of group salient coding and VLAD[J]. CAAI transactions on intelligent systems, 2017, 12(2): 172-178.
