XGBoost在超短期负荷预测中的应用*
2017-05-15杨修德王金梅张丽娜
杨修德,王金梅,张丽娜
1 引言
负荷预测作为电力系统拓展规划、实时控制和调度规划的重要依据,预测的准确性将直接影响电力系统的可靠性和智能程度。为了更好地预测负荷变化趋势,目前已有自回归综合移动平均模型(ARIMA)[1,2]、人工神经网络(ANN)[3,4]、支持向量机(SVM)[5,6]、随机森林回归(RF)[7,8]和梯度增强回归树(GBRT)[9]等综合方法被广泛研究和使用。
文献[10]对 United Arab Emirates比赛的小时负荷数据进行预测分析,结果表明虽然神经网络能够在训练集取得较好的拟合效果,但在预测集中其表现比ARIMA差。文献[11]进行了GBRT、RF以及ARIMA的电荷预测比较,发现SARIMA和SARIMAX表现比GBRT与RF等集成树模型表现差。综上所述,根据现有的文献及研究可以发现在大多数情况下,超短期负荷预测精准度排序结果为:GBRT≥RF>ARIMA≥ANN。
随着机器学习及计算机技术的发展,XGBoost应运而生,它是基于渐变Boosting的集成学习算法,在大多数问题上比GBRT和RF有更快的运算速率和准确性[12]。该模型的优势在一些机器学习和数据挖掘竞赛中得到了广泛认可,表明XGBoost具较强的优越性和较广泛的适用性[13]。
随着国家智能电网的发展,短期负荷预测具有以下特点:①数据来源广泛,数据可以从成千上万的电网监控端获得;②数据量巨大;③影响数据的因素众多、关系复杂。为了满足短期负荷预测快速且精准额的要求,本文将符合当前电网负荷预测发展趋势的XGBoost应用到实际预测中来,为保证数据的可靠性和有效性本文选用第九届电工数学建模A题数据[14]进行超短期负荷模型训练和预测,同时为验证XGBoost的有效性,将其预测结果与现有的GBRT、RF进行对比分析。
2 算法原理
2.1 RF 算法原理
随机森林算法(Random Forest)是Bagging算法和随机抽样算法的组合,基本构成单元是决策树,通过组合多棵决策树提高分类的准确性,此时得到随机森林分类器,通过最终投票对未知的样本进行分类。
决策树包含根节点、内部节点、叶子节点3类节点。学习与训练数据从根节点开始,经过决策树内部节点并按某种特定的属性将原始数据划分为多个训练数据子集,终止于叶子节点处。每个叶子节点处表示1个学习训练数据子集,节点是唯一确定,即数值或者分类标签唯一,使得决策树能进行分类或者回归。
随机森林算法建模流程如图1所示。
(1)对于给定的训练数据集,进行随机取样,可重复取样形成新的子样本数据;
(2)从新的子样本数据中的M个特征变量随机抽取(m<M)个特征,构成完整的决策树;
(3)重复(1)、(2)得到K个决策树,形成随机森林;
(4)每个决策树分别进行投票,选出最优分类[15]。
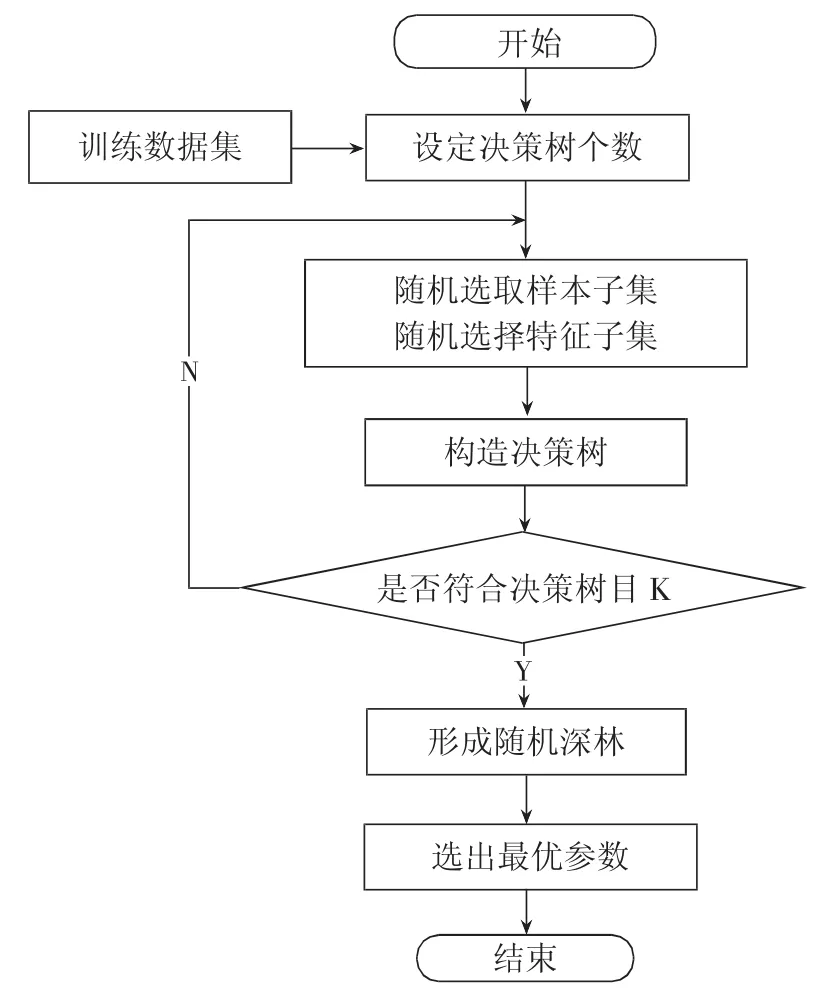
图1 基于RF的电网超短期负荷预测流程
2.2 GBRT 算法原理
梯度增强回归树(GBRT)也可称为渐进梯度决策树(GBDT),是一种迭代的决策树算法,由多棵决策树组成,所有树的结论累加起来做最终答案[16]。
GBRT建模流程如图2所示。
输入:训练数据集
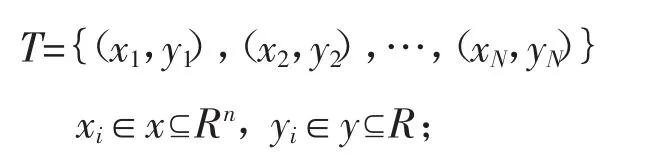
输出:提升树 fM(x)。
(1)初始化 f0(x)=0;
(2)对 m=1,2,…,M;
计算残差:
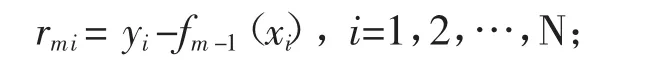
拟合残差 rmi学习一个回归树,得到 T(x;θm);
更新 fM(x)=fm-1(x)+T(x;θm)。
(3)得到回归问题提升树:
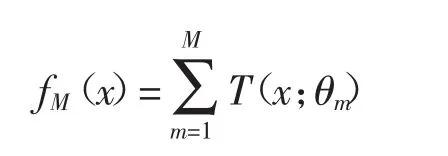
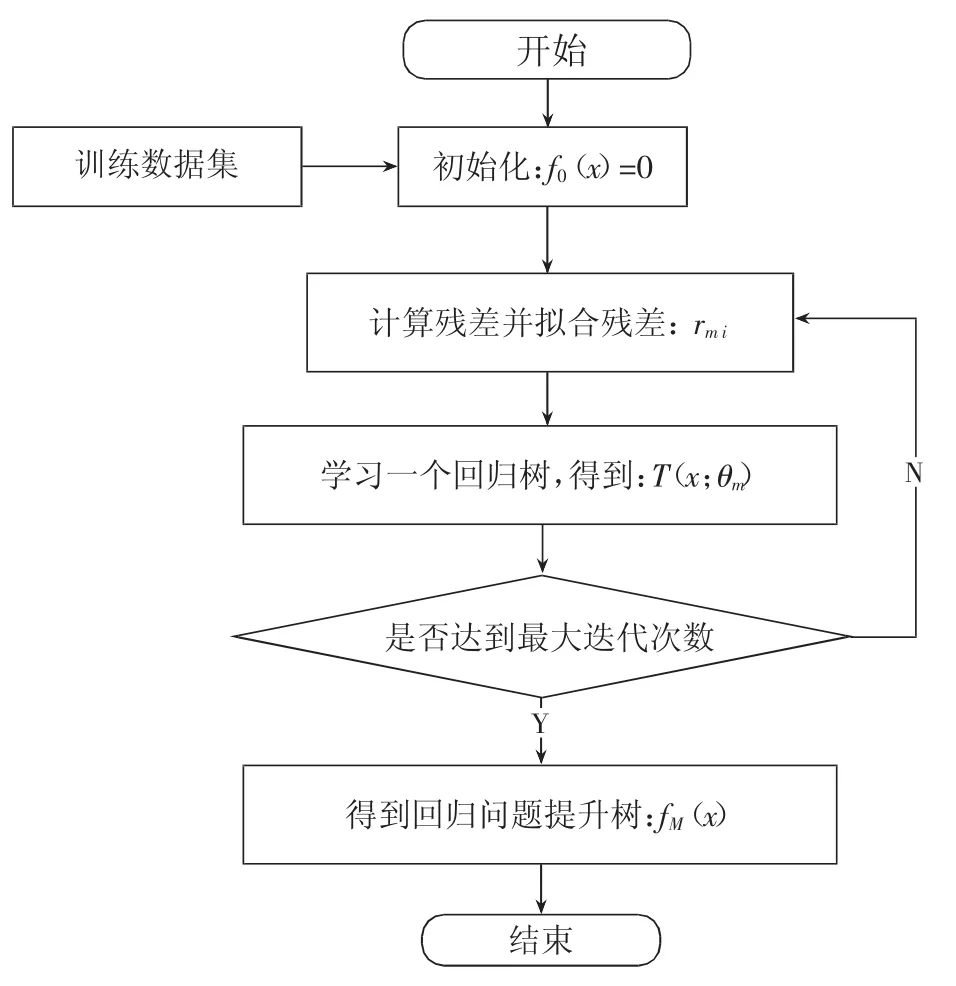
图2 基于GBRT的电网超短期负荷预测流程
2.3 XGBoost算法原理
XGBoost是一种集成学习算法。其原理是通过弱分类器的迭代计算来实现准确分类。计算过程如下。
(1)首先对样本权重和模型参数进行初始化,即将所有训练集样本赋予相同权重;
(2)进行第m次迭代,每次迭代采用分类算法进行分类,采用式(1)来计算分类的错误率:
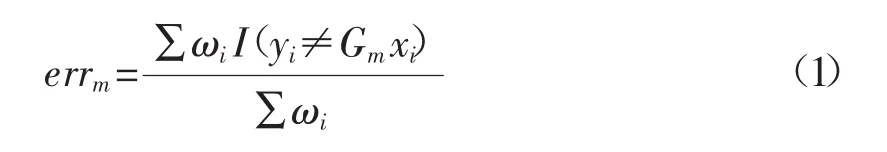
式中ωi代表第个样本的权重,
Gm代表第m个分类器;
(3)计算
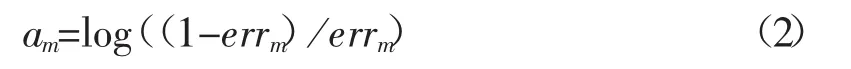
(4)对于第m+1次迭代,根据误差更新权重。将第i个样本的权重ωi重置为
(5)完成迭代后得到多棵树分类器,采用投票方式得到每个样本的最终分类结果。其核心思想在于每次迭代后,分类错误的样本都会被赋予更高的权重,而已经分类正确的样本权重会降低,从而提高分类正确率[17]。XGBoost建模流程如图3所示。
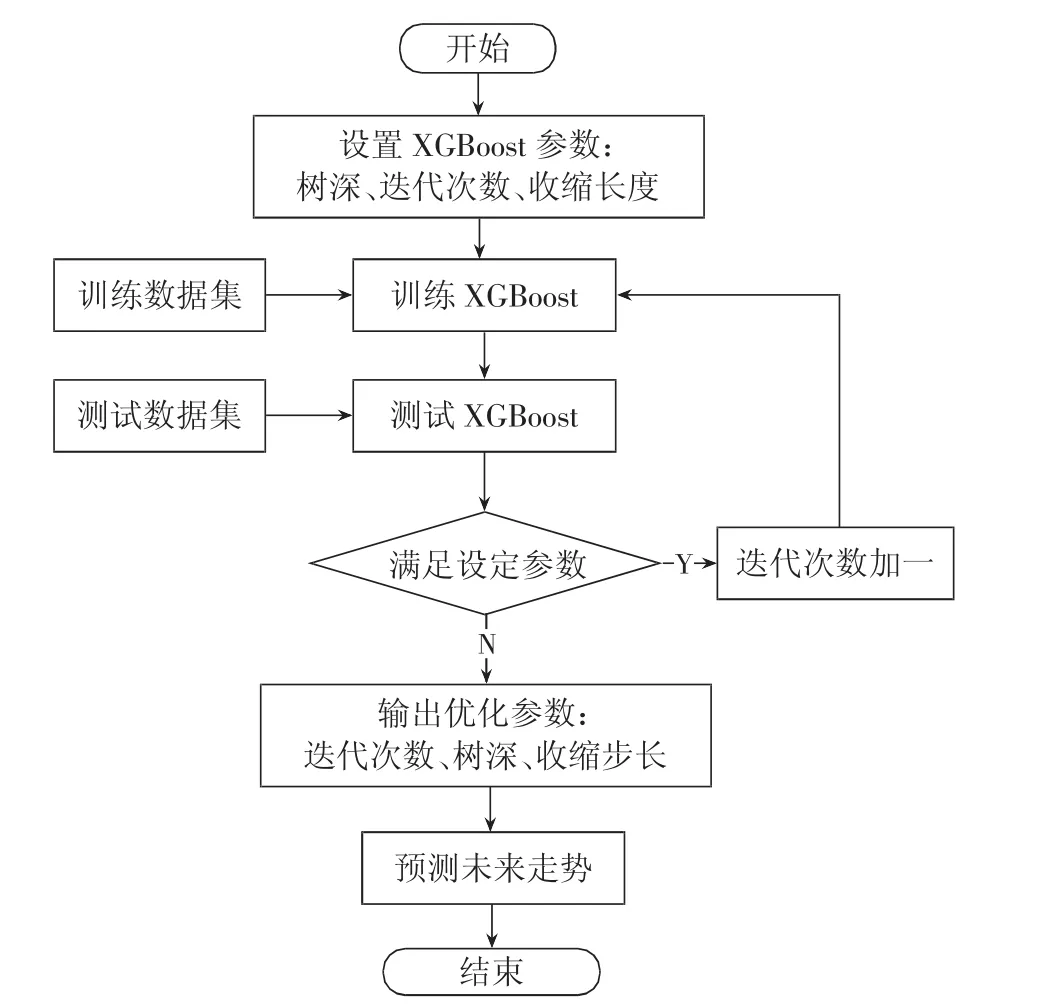
图3 基于XGBoost的电网超短期负荷预测流程
2.4 XGBoost与 GBRT、RF 的比较
XGBoost与传统 RF、GBRT相比存在以下特点。
(1)RF模型每棵树之间互相独立,而GBRT和XGBoost均在上一棵树学习的残差上进行学习;
(2)传统GBRT在优化时只用到一阶导数信息,XGBoost则对误差函数进行了二阶泰勒展开,同时利用了一阶和二阶导数;
(3)XGBoost和RF均对特征进行列抽样,来选择训练使用的特征比例,有效地防止过拟合,而GBRT没有;
(4)XGBoost将树模型的复杂度作为正则项加在优化目标上;
(5)XGBoost的特征分裂增益计算的可并行以性及可并行的近似直方图算法,能够充分利用多核CPU进行并行计算。
和大多数组合预测模型一样,XGBoost和RF、GBRT的预测结果来自于分类树和回归树,确保其具有良好的拟合能力,还不会导致过度拟合。而XGBoost通过列采样和两阶泰勒展开以及正则项,使XGBoost具有比RF和GBRT更好的性能。同时由于采用并行学习和优秀的程序设计,XGBoost的运行速度比大多数模型都要快。
3 数据分析及结果
3.1 参数寻优
本文采用第九届电工数学建模竞赛A试题的数据进行电网超短期负荷预测研究,对比XGBoost、GBRT和RF。本文选用某地2009-01-01日至2015-01-09日的电力负荷数据(每15min采集一个点,每日96个,量纲为MW)为训练集训练模型,并利用2015-01-10日内96个时刻的负荷为检验集检验模型。
本文利用5折交叉验证及网格搜索的方法进行参数寻优得到以下数据。
RF模型训练集上得到最优参数为:树的最大深度为10;迭代计算次数100;最大特征数设置为auto;
GBRT模型训练集上得到最优参数为:树的最大深度为10;迭代计算次数100;收缩步长为0.1;
XGBoost模型训练集上得到最优参数为:树的最大深度为15;最优迭代次数50;收缩步长为0.4。
3.2 预测结果分析
三种模型分别利用上面3.1节中得到最优参数进行预测。
首先从整体数据来看,在整个预测周期内RF、GBRT、XGBoost均能较好的预测电网超短期负荷的整体发展趋势。在电荷量波动明显的区域(15:45至21:00),XGBoost预测结果更为贴近真实负荷。结合表1中平均相对误差(MAE),可知XGBoost相对误差离散程度最低;由均方根误差(RMSE)来分析三者之间预测值的离散程度,RF的RMSE为7.614%,GBRT的 RMSE 为 3.531%,XGBoost的 RMSE 为1.951%,RMSE数值说明XGBoost预测值偏差更小,预测精准度更高。
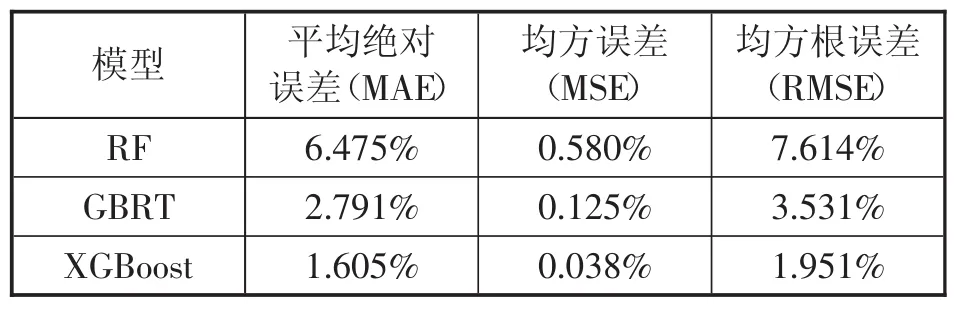
表1 XGBoost和GBRT、RF误差对比
其次,为更好地对比RF、GBRT、XGBoost的差异,本文选择了3个具有差异性的局部数据段进行分析。
如图4所示,在3:00到8:00的这个时间段内,电网负荷量平稳上升,波动量小,故三种模型都相对较好的预测了电网超短期的负荷。
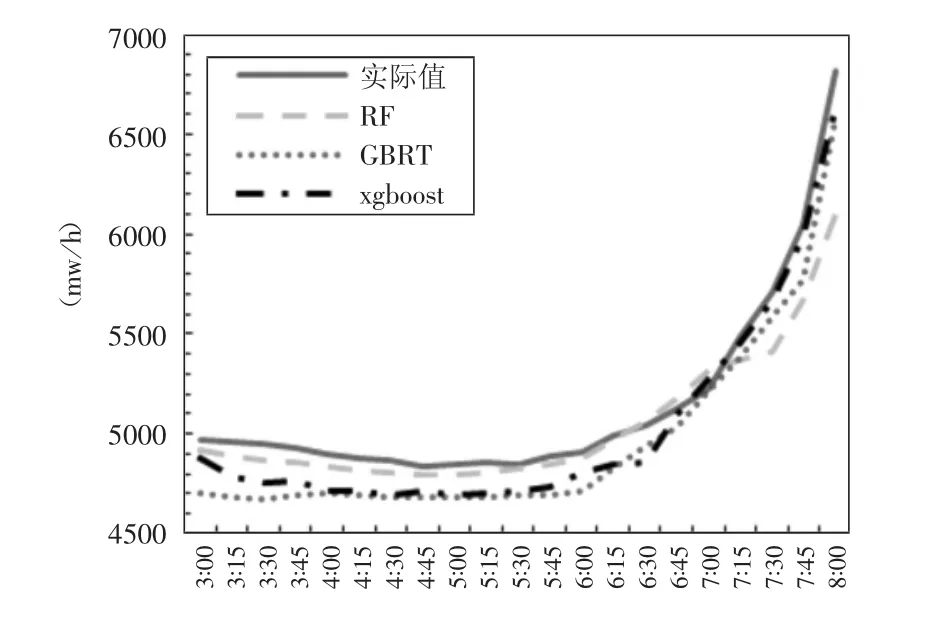
图 4 XGBoost和 GBRT、RF 模型在 3:00至8:00时段内预测与真实负荷对比
如图5所示,在10:00到15:00的这个时间段内电网负荷量由原来的平稳上升,开始出现低频率的波动,RF预测出现较大偏差,XGBoost和GBRT预测误差较小。
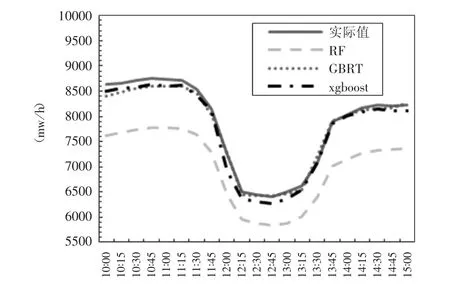
图 5 XGBoost和 GBRT、RF 模型在 10:00至15:00时段内预测与真实负荷对比
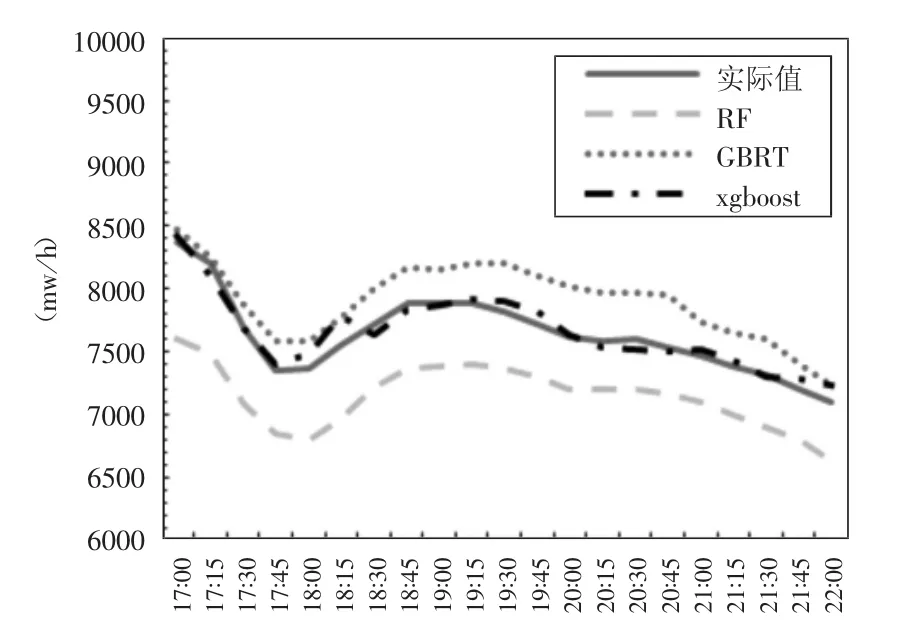
图 6 XGBoost和 GBRT、RF 模型在 17:00至22:00时段内预测与真实负荷对比
如图6所示,在17:00到22:00的这个时间段内电网负荷量变化频繁。由于RF是由多棵树投票输出结果,因此没能快速跟上电荷的复杂变化。与此同时二阶泰勒展开和正则项使得XGBoost展现出明显优于GBRT的拟合能力,所以在17:00到22:00这个电网负荷量变化频繁的时间段内只有XGBoost可以较好拟合电荷的变化趋势。
结合图4、图5、图6,无论电网负荷量波动大小,以及波动频率高低,XGBoost均能进行有效拟合,并且表现出优于GBRT、RF的准确性。
4 结论
适用于大数据、可并行学习的XGBoost模型,在2015-01-10每隔15分钟的96个实际电荷预测时刻中,XGBoost模型不但预测速度优于传统模型,而且预测精度更高于传统模型,XGBoost以RMSE为1.95%的误差率远低于 RF和 GBRT的 7.61%和3.51%。表明XGBoost是符合电网超短期负荷预测发展趋势的,是具有实用性和应用前景的预测方法。
参考文献:
[1]Moghram I,Rahman S.Analysis and evaluation of five short-term load forecasting techniques[J].IEEE Transactions on power systems,1989,4(4):1484-1491.
[2]李 妮,江岳春,黄 珊,等.基于累积式自回归动平均传递函数模型的短期负荷预测[J].电网技术,2009,33(8):93-97.
[3]Hippert H S,Pedreira C E,Souza R C.Neural networks for short-term load forecasting:A review and evaluation[J].IEEE Transactions on power systems,2001,16(1):44-55.
[4]马建伟,张国立.人工鱼群神经网络在电力系统段期负荷预测中的应用[J].电网技术,2005,29(11):36-39.
[5]LI Y,FANG T,YU E.Study of support vector machines for short-term load forecasting[J].Proceedings of the Csee,2003,6:010.
[6]Chen B J,Chang M W.Load forecasting using support vector machines:A study on EUNITE competition 2001[J].IEEE transactions on power systems,2004,19(4):1821-183.
[7]Dudek G.Short-term load forecasting using random forests[M].Intelligent Systems'2014.Springer International Publishing,2015:821-828.
[8]吴潇雨,和敬涵,张沛等.基于灰色投影改进随机深林算法的电力系统短期负荷预测[J].电力系统自动化,2015,39(12):50-55.
[9]Taieb S B,Hyndman R J.A gradient boosting approach to the Kaggle load forecasting competition [J].International Journal of Forecasting,2014,30(2):382-394.
[10]Liu N,Babushkin V,Afshari A.Short-term forecasting of temperature driven electricity load using time series and neural network model[J].Journal of Clean Energy Technologies,2014,2(4):2014.
[11]Papadopoulos S,Karakatsanis I.Short-term electricity load forecasting using time series and ensemble learning methods [C].Power and Energy Conference at Illinois(PECI),2015 IEEE.IEEE,2015:1-6.
[12]Chen T,Guestrin C.XGBoost:Reliable large-scale tree boosting system[C].Proceedings of the 22nd SIGKDD Conference on Knowledge Discovery and Data Mining,San Francisco,CA,USA.2016:13-17.
[13]Song R,Chen S,Deng B,et al.eXtreme gradient boosting for identifying individual users across different digital devices[C].nternational Conference on Web-Age Information Management. Springer International Publishing,2016:43-54.
[14]http://shumo.nedu.edu.cn/index.php/Home/Index/index.html
[15]许勇刚,张建业,龚小刚,等.基于改进随机森林算法的电力业务实时流量分类方法[J].电力系统保护与控制,2016;44(24):82-89.
[16]孙克雷,邓仙荣.一种改进的基于梯度提升回归算法的O2O电子商务推荐模型[J].安徽建筑大学学报,2016,(4):87-91.
[17]张敬谊,张亚红,李 静.基于词向量特征的文本分类模型研究[J].信息技术与标准化,2017,(5):71-75.
