基于PCA和KNN的碳酸盐岩沉积相测井自动识别
2017-05-08李艳华王红涛王鸣川廉培庆段太忠计秉玉
李艳华,王红涛,王鸣川,廉培庆,段太忠,计秉玉
(1.中国石化石油勘探开发研究院,北京 100083; 2.中国石油天然气勘探开发公司,北京 100083)
0 引 言
中东Y油田目的层为晚白垩纪海相碳酸盐沉积,主要沉积在阿拉伯板块被动大陆边缘的碳酸盐岩缓坡带上,包括从高能生物礁滩相到低能泻湖相和开阔海相。储集空间以孔、洞为主,其次是微裂缝,孔、洞、缝大约占全部孔隙总体积的52%、30%和18%,储层储集空间类型为孔隙、孔洞型。储层孔隙度分布5%~25%,平均14.83%;渗透率分布1~17 mD*非法定计量单位,1 mD=9.87×10-4 μm2,下同,平均6.33 mD。根据岩石组合特征、测井及地震特征并结合区域沉积背景可以划分出沉积亚相有浅滩、滩前、滩间、泻湖和开阔海。
在碳酸盐岩油藏地质建模和储量计算中,对于参与约束的井的沉积相精度要求越来越高,而岩心资料有限,人工判别未取心井沉积相的标准不统一,给传统方法识别碳酸盐岩沉积相带来了挑战。利用地质手段的沉积相研究方法必需通过观察岩心的岩石成分、结构和沉积学参数来鉴别沉积环境,这样的沉积相研究方法只能识别取心井段的沉积环境,对于非取心井段无法开展工作。在研究区成像测井资料较少的情况下,目的层的碳酸盐岩沉积亚相和常规测井曲线之间具有复杂的相关性和多解性,很难用统一、固定的门槛值区分不同沉积亚相,在大量的沉积亚相之间往往存在样本的交叉重叠。
在沉积相自动识别过程中,王玉玺等[1]利用Bayes逐步判别法建立了基于常规测井的北Rumaila油田Mishrif组碳酸盐岩沉积微相的测井判别模型;Lakzaie A等[2]利用人工神经网络对伊朗碳酸盐岩油田进行了储层相建模;高海焦[3]利用支持向量机(SVM)进行测井曲线的沉积相自动识别;安璐等[4]将自组织映射(SOM)用于数据分析的方法研究;刘爱疆等[5]利用主成分分析法研究了碳酸盐岩岩性识别,以减少复杂岩性存在的多解性和不确定性;谭学群等[6]在基于岩石类型约束的碳酸盐岩油藏地质建模方法研究中,用KNN算法建立了取心井岩石类型与测井曲线之间的关系,预测了未取心井的岩石类型;Aghchelou M等[7]将KNN与图像数字技术的结合,预测伊朗南帕斯天然气田碳酸盐岩岩相。
研究过程中先后尝试了传统的判别分析法、神经网络法、自组织映射法等识别碳酸盐岩沉积亚相,效果不甚理想。其中,传统的判别分析法过于依赖数学模型而忽略了地质专家的经验,不能处理好类域的交叉或重叠较多的情况,很难给出合理的判别公式或判别准则;神经网络方法要求学习样本数量不能太多,遇到几千个以上的学习样本时往往无法收敛、速度很慢;自组织映射法难以确定分组的含义,无法给出测井相和沉积相的转化关系,结果常导致识别结果准确率较低。
针对以上情况,研究了一套采用了以主成分分析和KNN算法分类为主,电阻率正演去流体影响、均值滤波去齿化和众数滤波确定边界为辅的碳酸盐岩沉积相识别技术,并制定了相应的技术流程。通过实际应用,取得良好效果。
1 PCA(主成分分析)
选取累积方差贡献率大于90%的主成分代表输入的多维测井信息,保证在原始信息损失最小的情况下,以少量综合变量取代原有多维测井信息,简化数据结构,从而解决复杂的碳酸盐岩沉积相识别的难题。利用测井资料识别沉积相,需要从原始测井曲线中构建与沉积相有关的主成分,用于建立沉积相知识库。多元线性回归有可能出现变量之间多重共线性,而主成分分析可以消除评价指标之间的相关影响。因为主成分分析在对原指标变量进行变换后形成了彼此相互独立的主成分,而且实践证明指标之间相关程度越高,主成分分析效果越好。它要比多元回归繁琐,但是结果会更可靠、更精确。主成分分析法可以起到降维的作用,将解释变量的个数进行归约,并不是删除。
选取与沉积相有关的无铀伽马GRc、总伽马GRs、光电吸收截面指数Pe、去油层电阻率Rt、声波时差Δt、密度DEN、中子CNL作为原始曲线进行主成分分析。
(1) 对原始曲线标准化处理
(1)
式中,yij为标准化后曲线;xij为标准化前曲线;
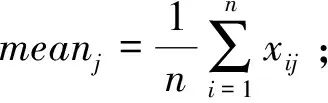
标准方差
i为样本维数,i=1,2,…,n;j为曲线维数,j=1,2,…,p。

(2) 计算样本的相关系数矩阵R(表1为计算得到的相关系数矩阵)
(2)
(3) 用雅可比方法求出矩阵R的特征值λj(λj=1,2,…,p)和特征向量P=(pij)p×p。
表2为计算得到的特征值、特征向量、方差贡献率。

表1 相关系数矩阵

表2 特征值、特征向量、方差贡献率
根据累计方差贡献率大于90%,可得到中东Y油田目的层沉积亚相的4个主成分变量的方程式

0.5261CNL′
(3)

0.1041CNL′
(4)
0.0488CNL′
(5)
0.2231CNL′
(6)
对10口井5类沉积亚相的4个主成分变量分别作了密度函数图(见图1)。从曲线的重叠相似性看出,在主成分1上5类沉积亚相反映互相独立,表明权系数较大的孔隙度曲线对碳酸盐岩沉积亚相反映最为敏感,其中浅滩的主成分1的变量值最大,频率分布最宽,滩前的频率最高,开阔海和泻湖主成分1的变量值最低,出现频率较低。在主成分2上有3类区分度较大,1类为滩前,1类浅滩和滩间,另1类为开阔海和泻湖,由此表明权系数较大的伽马曲线(去铀伽马、总伽马)在浅滩和滩间之间、开阔海和泻湖之间具有相似的伽马射线强度。主成分3的情况和主成分2类似。主成分4上可分为4类,开阔海和泻湖为1类,其余互相独立。通过以上分析,利用4个主成分可以区分5类沉积亚相。
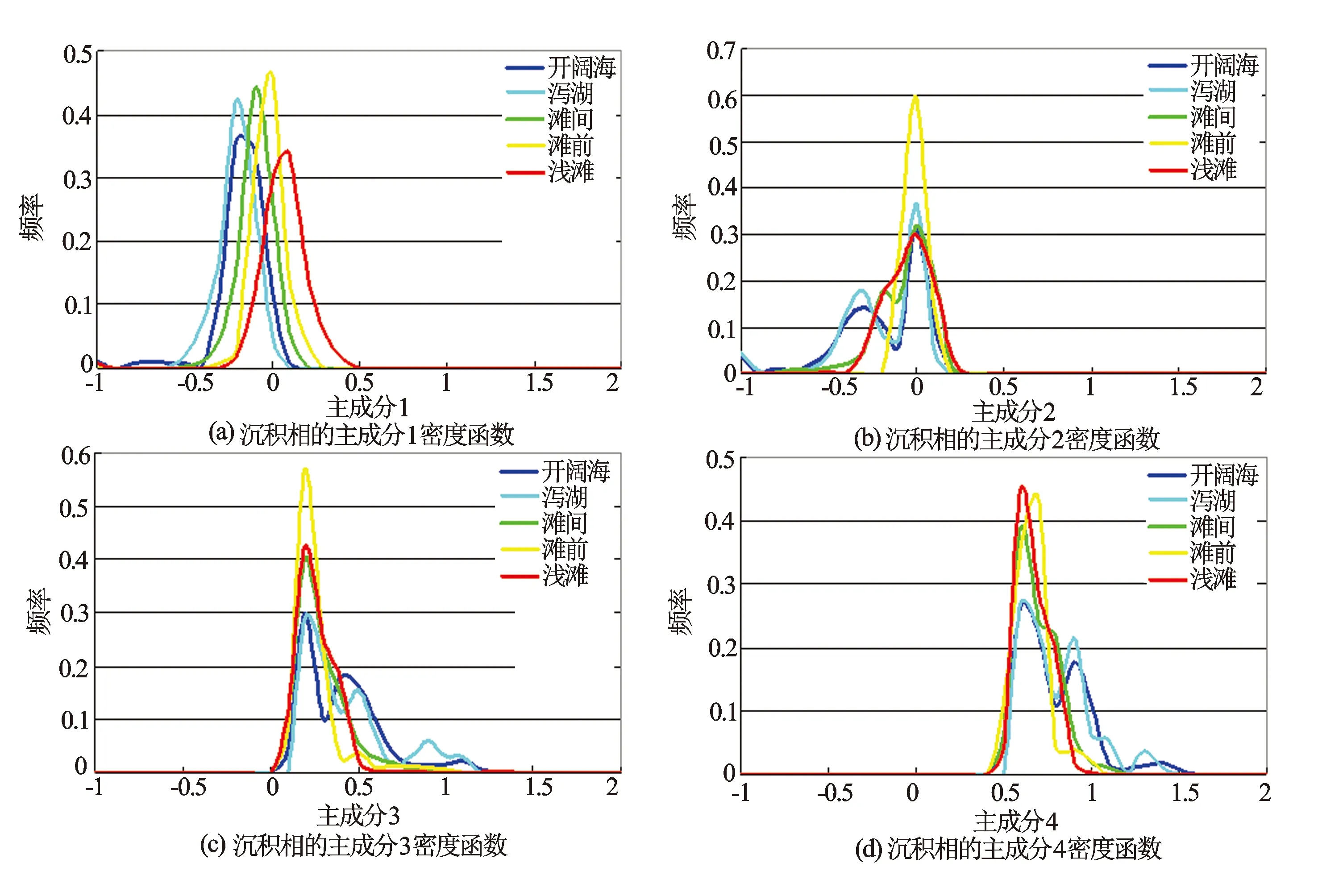
图1 4个主成分变量的密度函数图
2 KNN(K最邻近分类算法)
K最近邻分类算法是理论上比较成熟的方法。该方法思路是如果1个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。计算1个点A与其他所有点之间的距离,取出与该点最近的k个点,然后统计这k个点里面所属分类比例最大的,则点A属于该分类。通过KNN算法,可以建立沉积相类型和测井曲线的联系。
KNN方法靠周围有限的邻近样本,而不是靠判别类域的方法确定所属类别的,对于类域的交叉或重叠较多的待分样本集,KNN方法较其他方法更为适合。该算法比较适用于样本容量比较大的类域的自动分类。那些样本容量较小的类域采用这种算法比较容易产生误分。
根据主成分分析得到的4个主成分变量和岩心分析得到的沉积亚相,建立了KNN学习样本参数(见表3)。为了对学习样本的沉积亚相和最终预测的沉积亚相实施基本的质量监控,表3中引入了测井解释孔隙度。表3中,总体上浅滩和滩前对应的孔隙度较高,开阔海对应的孔隙度较低,符合碳酸盐岩沉积相分布的基本特点,表明样本中对于亚相的划分具有一定的可信度。相应地,预测的沉积亚相和孔隙度也应符合上述规律。
任意选取k的初始值为9,意为从每组学习样本中,取与某一预测样本最相似(即各主成分参数值相差最小)的9个样本点,组成样本集。预测时,在筛选的最相似的9个样本中,取占多数的亚相类型作为所预测样本的亚相类型。如果和岩心分析的亚相结果一致,即为符合。
通过实验,当k=1~10时,预测精度在85%~90%;当k=11时,预测精度达到90%以上;当k>11时,预测精度相对稳定。故取k=11作为KNN预测参数。
3 辅助技术
3.1 电阻率正演去油层
考虑到利用油层的学习样本预测油水同层、水层等其他非油层的数据可能带来误差,需要在主成分分析前对储层中的流体进行处理,避免不同流体对沉积相预测的影响。研究采用了将流体统一替换为水层的方法,具有较好效果。由于电阻率受流体影响最大,只对电阻率作了去油层处理。从岩石物理角度出发,要正演得到地层电阻率,可从地层水电阻率、孔隙度、饱和度等推导出电阻率。利用阿尔奇公式,假定全部地层都为水层,即Sw=100%,反推或正演去油层后的电阻率
(7)
为了验证去油层电阻率是否合理,需要保证在水层处该电阻率和原始地层电阻率重合,且测井解释的Sw正演拟合地层电阻率必须接近原始地层深电阻率。对比原始电阻率、去油电阻率和正演拟合的模型电阻率(见图2),在整个显示井段其模型电阻率和原始电阻率基本重合,表明模型可靠;在深度3 040 m以下纯水层去油层电阻率和原始电阻率基本重合,表明置换为水的去油电阻率较为合理。
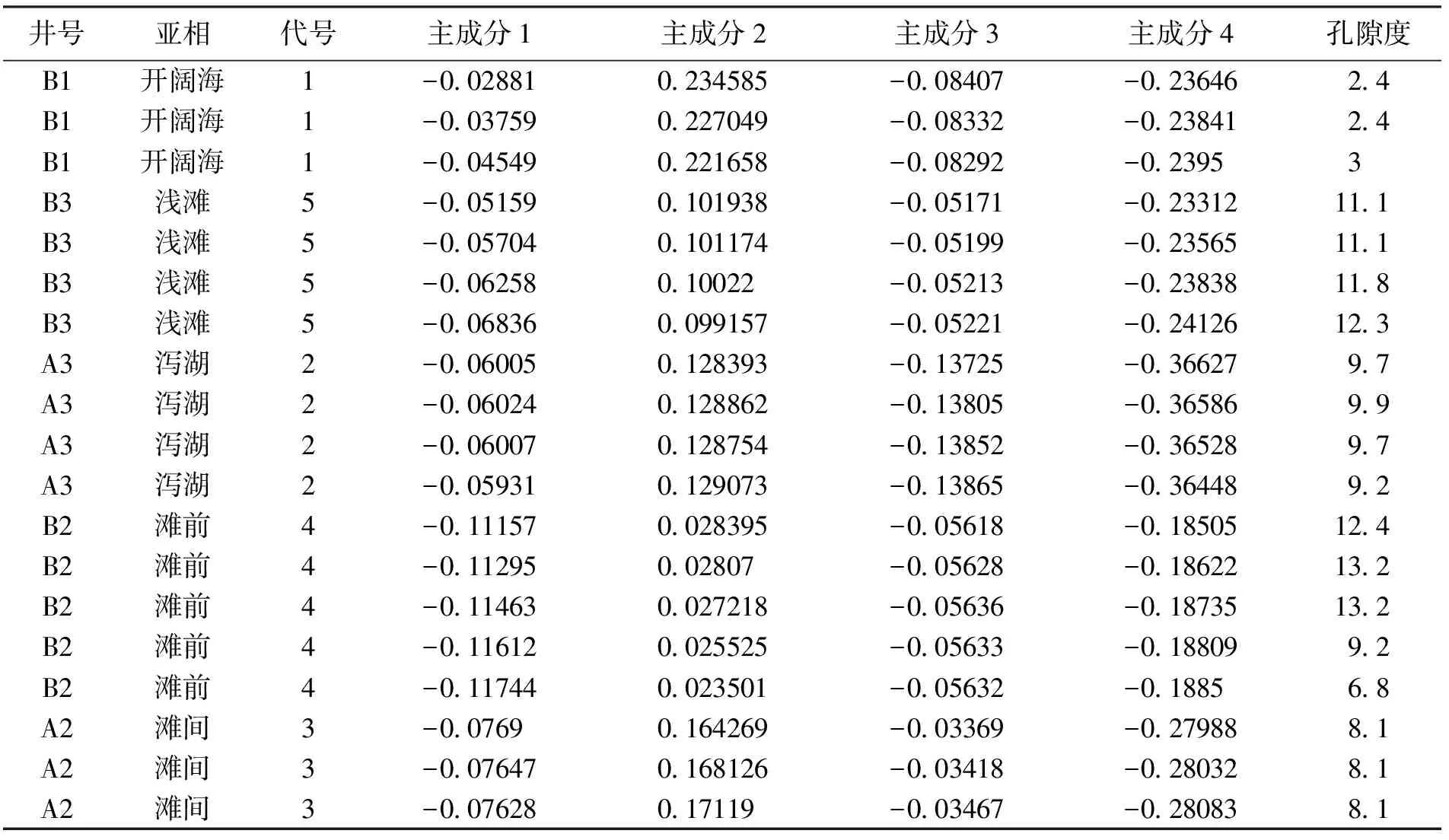
表3 KNN学习样本参数及其孔隙度
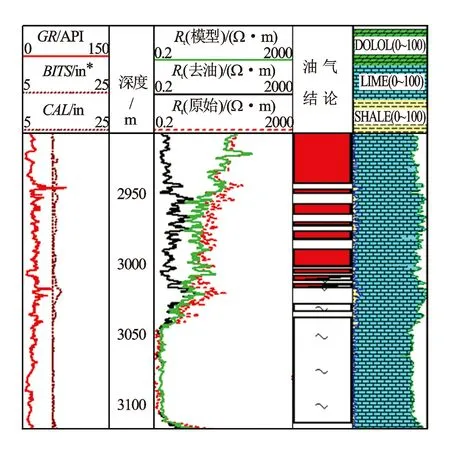
图2 电阻率正演去油层影响图*非法定计量单位,1 in=25.4 mm,下同
3.2 均值滤波去齿化和众数滤波确定边界
王瑞雪等[8]利用均值滤波等对川西×井的电导率数据进行滤波处理;郑明国等[9]运用众数滤波对监督分类训练样本纯化;刘淑荣等[10]将众数滤波用于改善图像质量。
本文对主成分采取了均值滤波去齿化技术以消除高频带来的影响,对沉积亚相的预测结果采取了众数滤波确定边界技术。
沉积亚相具有一定的厚度,主成分中的高频成分势必给沉积亚相的划分带来不稳定性,需要对4主成分进行一定窗长的均值滤波,以消除主成分中的锯齿状。其中窗长的选择依据是窗长采样点数=最小沉积亚相厚度/采样间距;也可以在此基础上根据沉积亚相的划分精度进行优化调整。通过计算,得到研究区窗长采样点数是60。
利用KNN对沉积亚相进行预测,在最小沉积亚相厚度内仍可能有少数不稳定值,需要进一步对该结果滤波。考虑到沉积亚相为离散的整数代号,研究采用了在前述窗长的基础上提取众数的方法滤波。经试验,这样得到的沉积亚相在厚度、顶底边界上与实际样本较好吻合。
在对岩心井的预测结果检验合格后,窗长参数保持固定,将用于预测非取心井。
4 沉积相自动识别技术流程
以岩心刻度沉积亚相为基础建立标准,通过一系列相转化为代号、电阻率正演去油层影响、曲线标准化、提取主成分、滤波、建立学习样本和预测样本、KNN预测、盲井检验等方法,建立了碳酸盐岩沉积相的测井自动识别技术流程(见图3)。

图3 沉积相测井自动识别技术流程图
5 应用分析
研究过程先后尝试了判别分析法、SOM(自组织映射)方法、ANN(人工神经网络)、KNN等方法。根据应用效果,最终确定了基于PCA和KNN为主的碳酸盐岩沉积相测井自动识别技术。
5.1 KNN和ANN(人工神经网络)预测结果比较
通过岩心刻度,以基于岩心的人工地质分析沉积亚相为样本,分别采用KNN方法和ANN方法进行了沉积亚相预测,对预测结果进行了比较。
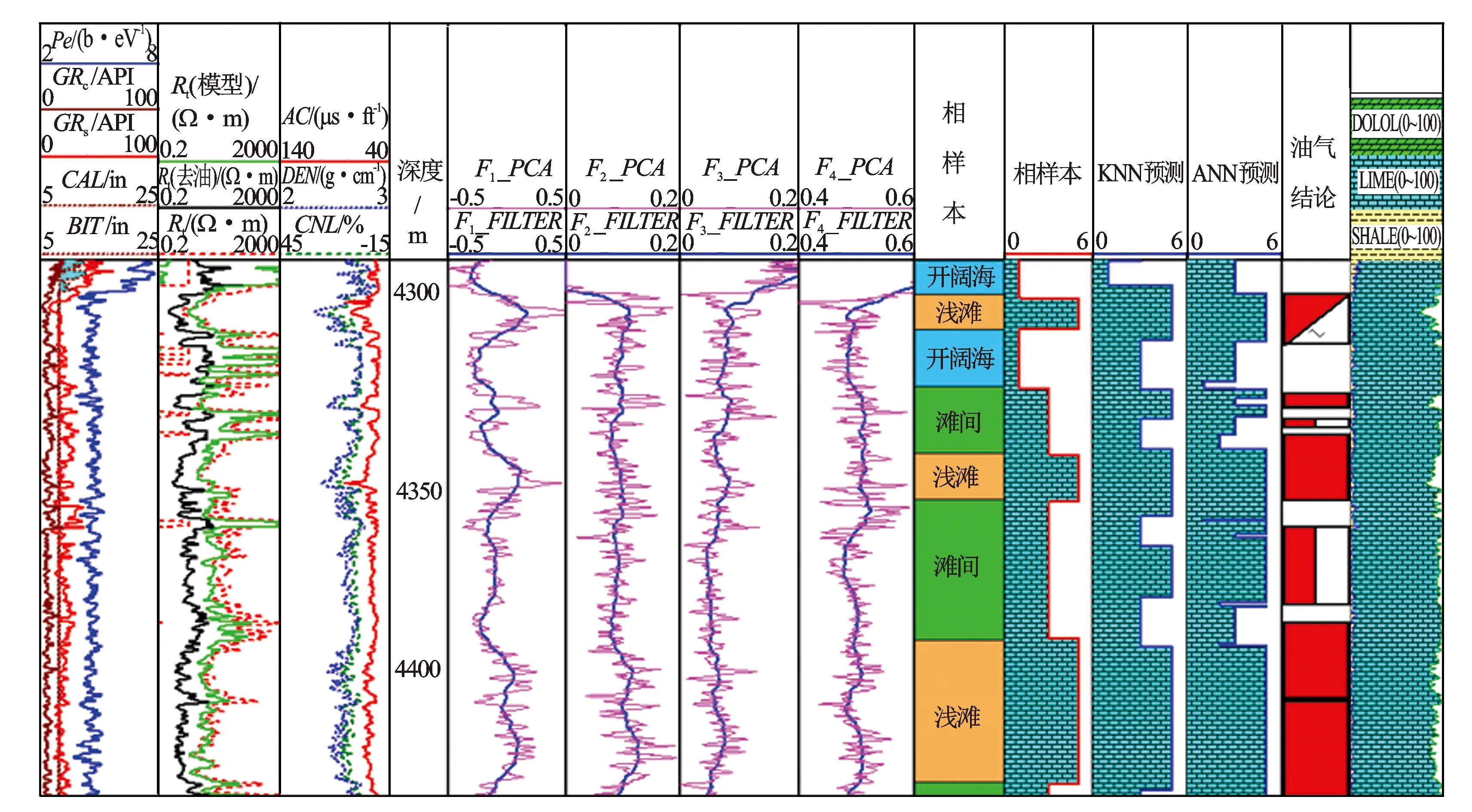
图4 KNN预测结果和岩心样本、神经网络(ANN)预测结果比较图
以5 262个岩心数据作为学习样本,利用基于主成分分析的KNN分类算法对研究区的1口岩心井作了盲井试验,即该井不作为学习样本,仅用来检验(见图4)。图4中,KNN预测结果和沉积相样本基本吻合,且KNN纵向预测精度上有了提高。该方法不需要反复调整参数,具有稳定性和可重复性,多次运行结果完全一致;不用独立的学习过程,学习和预测同时进行,整个过程运行速度只需15 s左右。
对于ANN方法仍用上述同样的样本进行学习,网络结构为输入层1层4个节点,隐含层1层3个节点,输出层1层为模式识别,学习效率0.7,运行40万次。得到结果是无法收敛,学习过程约为20 min。经多次试验,当训练样本大于500个时收敛较慢甚至不收敛。当ANN训练样本在204个时,由于样本有限,仅对少数井具有一定预测效果,但稳定性和精度不如KNN预测结果,可重复性差。
通过比较可以发现,ANN训练样本数量不能太大,其预测稳定性、精度仍有待提高,学习速度较慢。而KNN预测对学习样本的数量基本没有限制,运行速度快,预测结果稳定、可靠,特别适合岩心样本多、井点多的油田开发区块,能很好地满足研究区碳酸盐岩油藏地质建模及储量计算的高要求。
利用KNN方法对全区10余口样本井逐一进行盲井检验,总体上沉积亚相的的预测符合率达到90%以上。在此基础上,对其余40余口井进行了预测。
5.2 SOM(自组织映射)预测结果分析
自组织映射(SOM)是无监督模式识别方法,在没有已知样本的情况下直接对未知样本进行分析,根据样本间的关系自动完成分类。该方法判别出的是反映沉积相的测井相类别,具体对应地质上哪种沉积相或沉积微相仍需结合其他信息最终判定,以实现测井相到地质相的转换。
研究中样本数量为4 476,输入节点数为4,网络结构为9×8,学习效率为0.2。运行时长约1 h,分类结果如图5所示。比较SOM分类结果和沉积亚相后发现,二者相关性不强,很难找到规律对SOM分类结果进行合并。
分析认为,大数据量时SOM方法预测研究区碳酸盐岩沉积相运行时间长,预测结果与沉积相关联不强。因此,该方法可能并不适合研究区碳酸盐岩沉积相的预测。
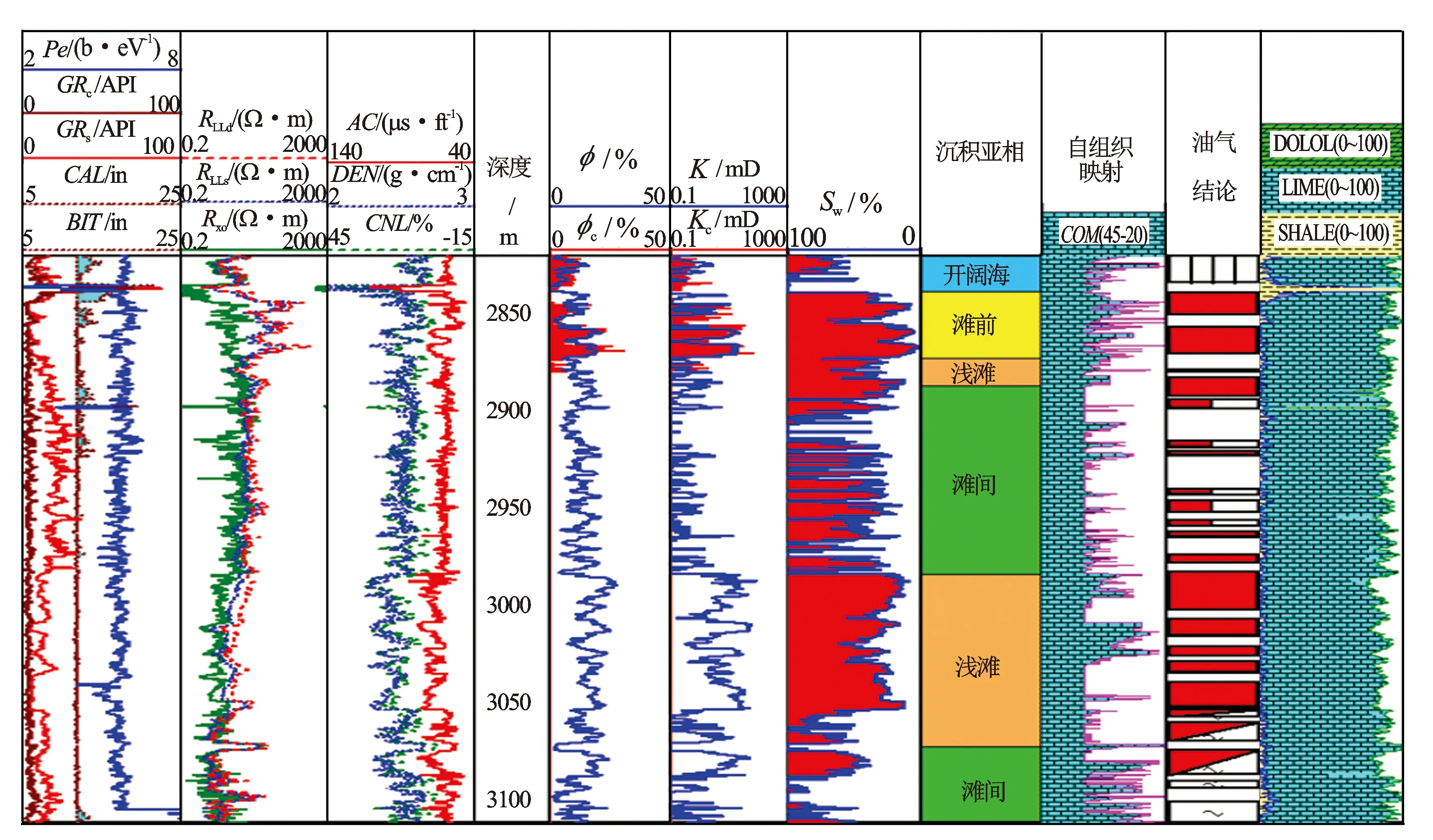
图5 自组织映射(SOM)预测结果图
6 结 论
(1) 碳酸盐岩油藏地质建模和储量计算中存在岩心资料有限、人工判别未取心井沉积相的标准不统一的问题。提出的基于PCA和KNN的沉积相自动识别技术较好地解决了学习样本量大、类域交叉多的难题,且运行速度快,分类结果可靠、稳定。
(2) 利用主成分分析从原始测井曲线构建主成分变量,消除了曲线之间的多重共线性。通过对主成分变量的密度函数分析,构建的4个主成分对5个类沉积亚相能较好地区分。
(3) 采用将流体统一替换为水层的方法,利用阿尔奇公式,反推或正演去油层后的电阻率,有效避免了流体对沉积相预测的影响。对主成分采取了均值滤波去齿化技术,对沉积亚相的预测结果采取了众数滤波确定边界技术,得到的沉积亚相在厚度、顶底边界上与实际样本吻合较好。
(4) 采用岩心刻度方法,以岩心井的测井数据和沉积亚相建立学习样本,对未取心井使用KNN分类技术进行沉积亚相预测。结果表明,KNN预测允许大数据量学习样本,运行速度快,预测结果稳定、可靠,适合岩心样本多、井点多的油田开发区块。
参考文献:
[1] 王玉玺,田昌炳. 常规测井资料定量解释碳酸盐岩微相: 以伊拉克北Rumaila油田Mishrif组为例 [J]. 石油学报,2013,34(6): 1088-1097.
[2] LAKZAIE A,GHASEM-ALASKARI M K,et al. Reservoir Facies Modeling Using Intelligent Data Gathering in an Iranian Carbonate Field [C]∥SPE 121247,2009: 1-4.
[3] 高海焦. 测井曲线的沉积相自动识别 [D]. 武汉: 武汉工程大学,2014.
[4] 安璐,张进. 自组织映射用于数据分析的方法研究 [J]. 情报学报,2009,28(5): 720-726.
[5] 刘爱疆,左烈. 主成分分析法在碳酸盐岩岩性识别中的应用: 以YH地区寒武系碳酸盐岩储层为例 [J]. 石油与天然气地质,2013,34(2): 92-196.
[6] 谭学群,廉培庆. 基于岩石类型约束的碳酸盐岩油藏地质建模方法: 以扎格罗斯盆地碳酸盐岩油藏A为例 [J]. 石油与天然气地质,2013,34(4): 558-563.
[7] AGHCHELOU M,NABI-BIDHENDI M,et al. Lithofacies Estimation by Multi-resolution Graph-based Clustering of Petrophysical Well Logs: Case study of south pars gas field of Iran [C]∥SPE162991,2012: 1-15.
[8] 王瑞雪,张晓峰. 基于成像测井资料多种滤波方法在裂缝识别中的应用 [J]. 测井技术,2015,39(2): 155-159.
[9] 郑明国,秦明周. 利用众数滤波对监督分类训练样本纯化的研究 [J]. 信阳师范学院学报(自然科学版),2003,16(3): 309-313.
[10] 刘淑荣,杜相文. 一种有效的图像质量增强算法——基于众数滤波的梯度滤波算法 [J]. 长春工程学院学报(自然科学版),2004,5(3): 68-69.
