推特上中国形象的主题与情感分析
2017-05-04肖明易红发
肖明+易红发

国家形象是一个国家的综合实力(即硬实力和软实力的总和)和核心价值观的体现,是一个国家在国际社会中所展示的整体面貌,以及国际社会对其综合实力、核心价值观和整体面貌的感受和评价。
传统的国家形象研究有两种途径,一是对媒体上特别是主流报纸上有关中国的报道进行内容分析,二是针对民众进行调查,来了解外国民众对中国的评价。
自2006年推特(Twitter)诞生以来,自媒体或称社交媒体成了传统媒介机构与公众发表意见的新平台。本研究中,我们采用文本挖掘技术,对推特上涉及中国的英文热门推文进行了分析。研究目的是了解和描述推特英语用户在发布的热门推文中,涉及中国时关注的是哪些主题,呈现出来的态度及情感又是怎样的,以期对对外传播工作有所启示。
一、研究方法
推特平台上共有超过30种的语言版本,但主要语言为英语,本研究以英文版本为研究范围,研究对象是海外媒体及公众所发布的涉及中国、中国人的热门推文。采用新兴的文本挖掘方法,对非结构化的推文文本进行挖掘和处理,工作流程包括了文本的获取、分词与过滤、主题建模、情感分析四个步骤。
1.文本数据的获取
在获取文本数据过程中,我们不区分大小写,以“China”或者“Chinese”为关键词对热门推文进行了检索。热门推文是被转推或被收藏过的推文。搜索热门推文而不是全部推文,主要是考虑到了热门推文的影响力以及工作量问题。所搜索语言为英语,这主要是考虑到推特用户的主要语言为英语,用户所发布的推文也多为英文。推特是在2006年3月开始运营的,本研究的数据收集时间是在2014年初,所以搜索的时间周期为2006年3月到2013年12月。
利用爬虫软件GooSeeker对检索出来的热门推文进行了抓取。GooSeeker是火狐浏览器的插件,包括两个部分:定义提取规则的MetaStudio和用于信息采集DataScraper。利用爬虫技术获得的原始数据包括四个字段,分别是“用户名”“昵称”“推文发布日期”,以及“推文文本”。其中“用户名”和“昵称”是用户属性数据;“推文发布日期”是推文属性数据;“推文文本”属于内容数据,是文本形式的,“推文发布日期”是我们要进行分析的非结构化数据。
第一条含关键词“China”或“Chinese”的热门推文发布于2006年4月30日,推文内容如下:
picking up two out-of-state twitterers, heading out for the best Chinese in SF - Elizas.
因为本研究所关心的是外国人如何呈现中国形象,所以去除了中国人或中国机构所发布的推文。首先,我们认定“昵称”中含中文字符的用户是中国人,删除他们所发的推文,共计26,318条。其次,我们认定用户名或昵称中含“China”或“Chinese”的用户也与中国有关,去除他们所发的推文,共计53,212条。最终获得有效的热门推文一共是842,917条。
2.文本预处理
对推文的预处理包括了分词和过滤,主要运用自然语言处理技术(NLP),利用Python的nltk包进行了操作。
我們的研究对象是推特上的英文的涉华推文,分词方法就是简单的基于空格和标点符号的英文分词法。
过滤是指过滤掉文本中的html链接、@人名、标点符号,以及不必要的空格。同时过滤掉非英文字母、数字、小于或等于三个字符的词(这些词,如the、or、and等绝大多数为无意义的虚词),同时在停用词(Stop Words)表的基础上,过滤掉停用词。最后将所有英文字母转换为小写。
3.主题建模及主题命名
主题建模(topic modeling)是本研究中最为关键的一步,利用Stanford TMT 0.4.0软件对涉华推文的主题进行LDA(狄利克雷分配模型)建模。Stanford TMT由斯坦福自然语言处理小组(The Stanford Natural Language Processing Group)开发,基于JAVA,用Scala编写,有完整的API文档。LDA建模方法是基于无监督的机器学习技术,不采用任何的主观方法去标识推文,能够更为客观地发现文本中是否存在着潜在主题。
经过了反复的测试,本研究最终选择最大迭代次数为1000,常见词过滤数量为20的结果,最终从80多万条推文中提取了30个主题。
对于所提取的30个主题,软件输出结果中会给出每个主题所对应的前20个关键词以及每个关键词的贡献度。根据各个主题所包含的关键词的特点,经过反复讨论,最终对各个主题进行了命名。
4.情感分析
本研究的情感分析(sentiment analysis)应用机器学习技术,采用朴素贝叶斯(Naive Bayes)算法,对每一条推文的极性与情感进行识别。具体的操作采用了R语言中的sentiment包。
R语言中的sentiment包在识别极性(polarity)时,会先为每条推文的每种可能极性打分。即每条推文都有两种可能性negative(消极、负向、否定)和positive(积极、正向、肯定)的得分。当两种极性得分相差较大时,则极性拟合为得分较高的极性类别。当两种极性得分相差不大时,则拟合一种新的极性类别,即neutral(中立)。
R语言中的sentiment包在识别情感时,共有六种情感:anger(愤怒)、disgust(厌恶)、fear(恐惧)、joy(喜悦)、sadness(悲伤)和surprise(惊奇)。在分析时会先为每条推文的每种可能情感打分。当六种情感可能性中有一种可能性的得分特别突出,那么该推文的实际情感就拟合为该类别。如果六种情感可能性得分相差不大时,则情感类别拟合为unknow(未知)。如此可知,如果某条推文被拟合得到某一类情感,则该情感一定是强烈的情感。
二、研究结果
1.涉华推文的主题分布
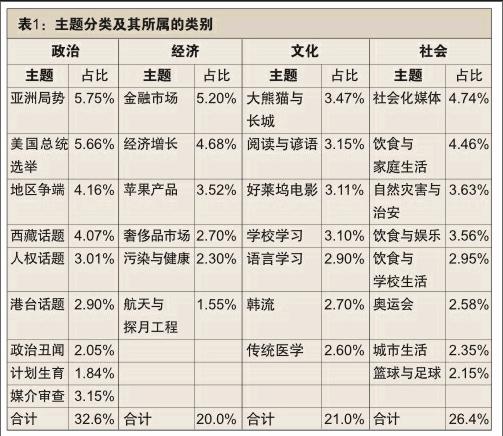
本研究采用LDA主题建模方法把80多万条涉华热门英文推文凝聚为30个主题,各个主题的名称及其占所有主题的百分比如表1所示。
可以看到,涉华热门推文中有关饮食的主题有三个,根据场景的不同分别为“饮食与家庭生活”“饮食与娱乐”,以及“饮食与学校生活”,三个主题合计为10.98%。即有关中华饮食的推文所占比例最高,推特用户中最关心的中国议题是饮食。
在饮食主题之后的占比数量多的五个主题依次是:“亚洲局势”“美国总统选举”“金融市场”“社会化媒体”,以及“经济增长”,这五个主题累计百分比为26%,超过了四分之一 。
在国家形象研究中,常见的主题分类是政治、经济、社会及文化的四分法,这也是传统调查法和内容分析方法比较经常采用的分类法。
按照政治、经济、社会及文化的四分法,本研究中利用主题模型生成的“亚洲局势”“美国总统选举”“地区争端”“西藏话题”“媒介审查”“人权话题”“港台话题”“政治丑闻”,以及“计划生育”等九个主题属于政治范畴,所占比例为32.6%。
属于经济类的主题包括“金融市场”“经济增长”“奢侈品市场”“苹果产品”“污染与健康”,以及“航天与探月工程”,共六项,所占比例为20%。
属于文化类的包括“大熊猫与长城”“阅读与谚语”“好莱坞电影”“学校学习”“语言学习”“韩流”,以及“传统医学”,共七个主题,所占比例为21%。
属于社会类的主题包括“社会化媒体”“饮食与家庭生活”“自然灾害与治安”“饮食与娱乐”“饮食与学校生活”“奥运会”“城市生活”,以及“篮球与足球”,共计八个,所占比例为26.4%。
2.不同年份及不同议题的极性分析
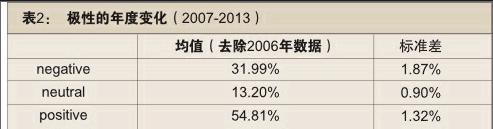
通过极性分析,我们发现所分析的80多万条英文涉华热门推文中,有54.81%的推文极性为积极正向的;消极负向的推文占31.99%;中立推文比例为13.20%。
历时来看,2006年的数据因为数量很少,忽略不记。从2007年到2013年各年度的极性变化是不大的。负面评价的标准差为1.87%,正面评价的标准差为1.32%,中性评价的变化范围最小,标准差不到1%。
从变化的情况来看,2008年的推文积极正面的评价比例最低,为52%;消极负面评价的比例为35.65%,是历年来最高的。2008年中国发生的重大事件包括北京奥运会、汶川地震、毒奶粉事件,以及全球性的金融危机。
按照政治、经济、文化、社会四个大类别来看,在政治类议题中,积极正面的评价为54.73%,略低于经济、社会及文化议题中正面评价的比例。
3. 不同年份及不同议题的情感分析
总体来看,只有25.54%的推文表现出了强烈的情感。近四分之三的推文都没有表现出强烈的情感,情感拟合为unknown。
历时来看,随着时间的推移,涉华热门推文表现出强烈情感的比例越来越多。在2007年,只有20.1% 表达出了强烈的情感,而2013年,这个比例已经提升到26.5%。这表明,就中国议题而言,推特用户越来越倾向于表达出强烈的情感。
從所表达出来的情感来看,比例最高的情感是喜悦,占比14.19%;其次为愤怒,占3.49%;排在第三位的情感是难过,比例为3.07%。
从居前两位的情感joy和anger的变化来看,joy呈现出逐年提高的趋势,这说明涉华热门推文中,含有喜悦情感的比例越来越多;而anger呈现出小幅上下波动的态势。
从议题来看,社会类和文化类议题中表现出强烈情感的比例都在27%上下;而经济、政治类议题中具有强烈情感的比例都不足25%。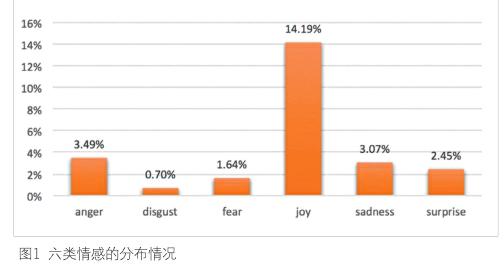
三、结论
本研究着眼于推特上英文用户对有关中国议题的呈现,采用爬虫程序获取数据,利用NLP技术对数据进行预处理,采用主题建模和情感分析两种技术对数据进行处理,得到以下结论:
1.从数量上看,英文涉华热门推文的数量在逐年增加。表明世界对中国及中国相关事物的关注度在持续提高。
2.“饮食”成为英文涉华热门推文中关注度最高的主题,超过十分之一的推文都与中国饮食有关。
3.从政治、经济、文化和社会四大类议题来看,英文涉华热门推文中政治类主题所占比例最高。
4.英文涉华热门推文总体上的极性以积极正向为主。总的来看,推文中只有四分之一表现出了明显的情感,从表现出来的情感的情况来看,喜悦高居第一位,然后依次是生气和难过。从各年度历时来看,表现出喜悦情感的比例有上升的趋势。
(本研究为中国传媒大学亚洲传媒中心资助项目“西方自媒体中的中国形象研究”的阶段性成果)
「参考文献」
1.张培晶、宋蕾:《基于LDA的微博文本主题建模方法研究述评》,《图书情报工作》,2012年第12期。
2.赵妍妍等:《文本情感分析》,《软件学报》,2010年第8期。
3.Hofmann T. (2001). Unsupervised learning by probabilistic latent semantic analysis [J]. Machine Learning, 42(1): 177-196.
4.Blei D, Ng A, Jordan M.(2003). Latent Dirichlet allocation [J]. Journal of Machine Learning Research, 2003(3):993-1022.
5.OConnor, Brendan; Balasubramanyan, Ramnath; Routledge Bryan R.; and Smith, Noah A.. ‘ From Tweets to Polls: Linking Text Sentiment to Public Opinion Time Series(2010).Tepper School of Business. Paper 559.
