基于Web医疗数据的互联网医疗用户研究
2017-04-26冯洪海孙远灿李利敏宋舒晗黄俊辉
冯洪海+孙远灿+李利敏+宋舒晗+黄俊辉
摘 要: 互联网医疗的蓬勃发展带来了大量的数据积累,如何有效的利用这些数据是当前面临的问题。通过开发爬虫软件,获取了截至2017年2月寻医问药网中内科和外科的131894条咨询数据。针对这些数据,用统计学方法调查用户的性别和年龄分布,通过程序识别咨询数据中的症状和疾病,统计了现阶段互联网医疗用户症状和疾病的分布。
关键词: 互联网医疗; 网页爬虫; 症状分布; 疾病分布
中图分类号:TP391 文献标志码:A 文章编号:1006-8228(2017)04-41-03
Abstract: The rapid development of the Internet medical has brought a lot of data, and how to make effective use of these data is the problem currently faced. In this paper, a crawler is developed to have acquired 131,894 internal and surgical medicine enquiry data by February 2017, from medicine websites. According to these data, the distribution of users' gender and age are investigated by the statistical methods, and the distribution of the symptoms and diseases of the Internet medical users at this stage are counted by the identification.
Key words: Internet medical; Web crawler; symptom distribution; disease distribution
0 引言
醫疗一直是人们关注的热点话题,与人们的生活紧密相关,随着互联网的发展,越来越多的人选择在网上咨询医生关于健康的问题。中国互联网络信息中心(CNNIC)发布的《第37次中国互联网络发展状况统计报告》显示,2015年,中国互联网医疗用户数量为1.52亿。网络医疗咨询提供了一个新的方式,让用户可以不用实地见到医生,就可以咨询病情[1],能够帮助用户方便快捷的了解自身的健康信息。互联网医疗行业积累了大量的用户疾病数据,如何有效的利用这些数据是现阶段面临的主要问题。目前已有一些学者从不同角度对在线医疗咨询数据的信息挖掘进行了研究。Silver MP[2]研究了患者在线健康信息搜索的相关问题。石思优[3]应用Med-LDA 模型研究医疗数据中病症和用药的独立关系和相互联系。Ullah Z[4]等人认为使用数据挖掘算法可以提高预测、诊断和疾病分类的质量,研究了数据挖掘技术的成本、性能、速度和准确性。魏强[5]通过研究医疗数据存储与分析系统,对疾病间关联关系进行分析。Walczak等人[6]研究了病人的医疗检查信息在提高计算机诊断准确性方面的应用。陈迁[7]研究了医疗数据在分析糖尿病住院患者基本信息、治疗医嘱、生化指标、费用明细等方面的应用。闫茜[8]提出了一种用于数据处理的基于统计树和增量计算的海量医疗数据快速统计查询方法。许杰[9]提出了一种基于数据不一致率的新型数据分类方法。李萍[10]研究了医疗数据质量的特点,如统一性、可靠性、“多粒度”级别、高可用性、高适用性。蒋良孝[11]对医疗数据挖掘的主要特点、基本过程、关键技术、计算智能方法以及发展方向进行了探讨。
本文通过开发爬虫软件获取截至2017年2月寻医问药网中内科和外科的131894条医疗咨询数据。针对这些数据,用统计学的方法调查用户的年龄分布、性别分布。通过识别医疗数据中的症状和疾病,对不同年龄段、不同性别的用户的症状和患病情况进行调查,得出了现阶段我国互联网医疗用户的特征和分布。
1 获取数据
通过分析网站的结构,本文采用多级网页爬虫的方式获取数据,首先获得一级科室的链接,然后获取每个一级科室下属的二级科室链接。每个一级和二级科室的页面中都有用户的问题咨询列表,本文获取了内科和外科中的所有问题集合,并对集合进行去重操作,最后共得到网页链接131894个。针对每一个网页,我们获取的用户信息包括性别、年龄、咨询的内容和医生的回复内容。
在具体的爬虫代码中,为了防止频繁访问网站导致的爬虫被网站限制,本文采用用户代理(User Agent)和程序随机休眠相结合的方法。User Agent是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等,如("User-Agent","Mozilla/4.0(compatible; MSIE 5.0; Windows NT; DigExt)"。
程序的最大获取连接时间。为了保证程序不在某一个页面花费过多的时间甚至导致程序长期处于连接获取的等待阶段,本文对程序的最大连接获取时间进行限制,如果程序在m毫秒内不能获取到网页的连接,程序将跳过此网页,经过反复实验,我们设置m为6000,即允许每个网页的等待时间为6秒,以此来应对网页不可获取和网络不稳定带来的问题。
程序随机休眠。如果获取的网页内容为空,那么程序将休眠,,休眠时间在0-n毫秒之间随机生成。如果休眠后仍然不能获取到数据,那么将跳过此页面,以此来保证爬虫的效率,在经过多次实验后,本文设置n为200。
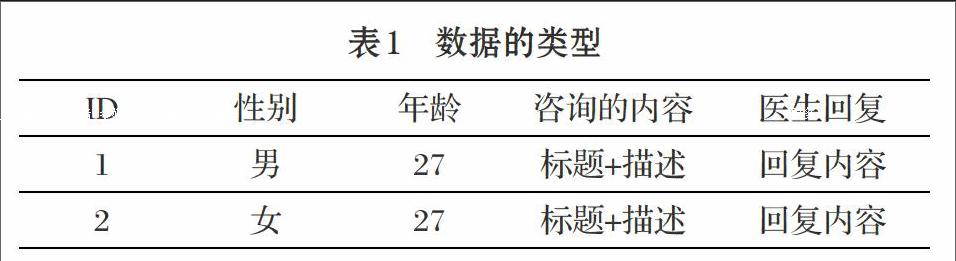
采用SQLite数据库存储数据,其中用户咨询的内容可以表示为:用户的提问即提问标题和咨询内容的描述。数据的类型如表1所示。
2 症状和疾病识别
2.1 症状识别
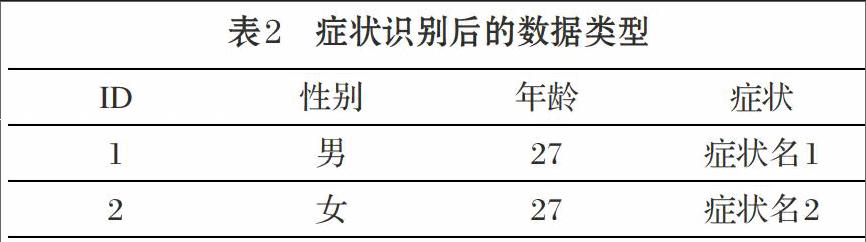
通过网页爬虫,从39健康网和寻医问药网收集症状总数7632种,为了准确匹配用户的口语化表达词语,比如用户使用“肚子痛”、“肚子疼”等词来描述症状,本文构建了用户的口语表达词语与规范词汇对应列表,如“肚子痛”和“肚子疼”对应为“腹痛”。通过这样的方式统一用户的口语化表达。通过人工浏览咨询数据,本文共获得606种症状中的用户口语表达词语716种。识别用户症状以后的数据类型如表2所示。
2.2 疾病识别
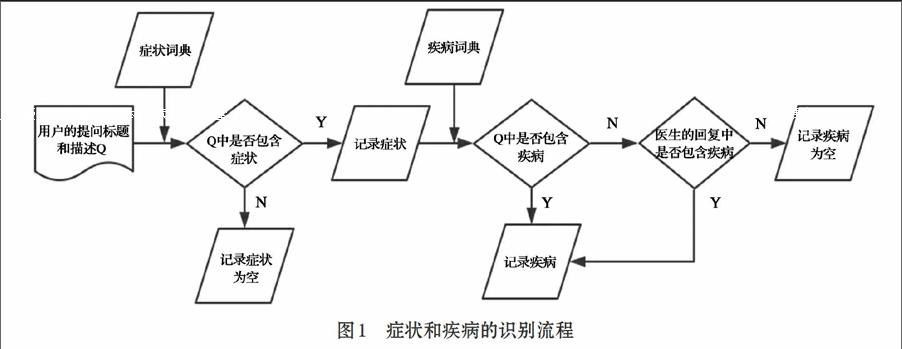
本文通过网页爬虫从互联网收集疾病21464种;从39健康网和寻医问药网收集疾病9095种;两个疾病集合去除重复的疾病,本文构建的疾病词典Ddict中共包含疾病28143种。医疗咨询分为用户的提问与医生的回复,考虑到用户缺乏相应的医学专业知识,在对疾病进行识别的过程中,如果不能识别出用户提问中涉及的疾病,程序将在医生的回复中继续进行疾病匹配,程序对症状和疾病的识别流程为图1所示。
在疾病匹配时,把疾病词典按照疾病的字符长度从大到小进行排序,按照最大匹配原则对数据中的疾病进行识别,如,先匹配“丙型肝炎”如果没有匹配到,继续匹配“肝炎”等,精确用户的咨询内容和医生的回复内容,得到用户的疾病数据。识别疾病以后的数据类型如表3所示。
3 实验结果
3.1 性别和年龄分布
在131894条咨询数据中,男性用户数量为61338,占所有用户数量的46.51%;女性用户数量为70556,占所有用户数量的53.49%。
通过划分年龄阶段对每个年龄段的用户数量进行统计,结果显示年龄在21-30之间的用户最多,数量为35412,占所有用户数量的26.84%;年龄在31-40之间的用户数量为16917,占所有用户数量的12.82%。各年龄阶段的用户数量分布如图2所示。
3.2 症状和疾病分布
通过对用户提问数据的症状识别,对识别结果进行统计,结果显示用户的咨询数据中 “头痛”出现的次数最多,为4585,占所有咨询数量的3.47%;“胃气上逆”出现的次数为4554,占所有咨询数量的3.45%。出现次数最多的前十种症状如图3所示。
通过对医疗咨询数据的疾病识别,对识别结果进行统计,结果显示医疗咨询中出现“肢端肥大症”的次数最多,为11171,占所有咨询数量的8.47%;“感染”出现的次数为5377,占所有咨询数量的4.07%。出现次数最多的前十种疾病如图4所示。
4 结束语
本文通过开发爬虫软件获取了寻医问药网中的131894条医疗咨询数据,在程序中采用用户代理和程序随机休眠的方法提高爬虫的效率。针对这些医疗数据,通过统计学方法调查用户的性别和年龄分布;通过获取症状词典和疾病词典对医疗咨询中的症状和疾病进行识别,加入了对用户口语表达词汇的提取,统计了现阶段互联网医疗用户的症状和疾病分布。未来的研究可以从以下几方面着手:①对更多的咨询数据进行调查;②对医生的回复特征进行研究;③移动医疗APP。
参考文献(References):
[1] Umefjord G, Petersson G, Hamberg K. Reasons for Consulting a Doctor on the Internet: Web Survey of Users of an Ask the Doctor Service. Journal of Medical Internet Research,2003.5(4):e26
[2] Silver MP. Patient perspectives on online health
information and communication with doctors: a qualitative study of patients 50 years old and over. Journal of Medical Internet Research,2015.17(1):e19
[3] 石思优.基于主题模型的医疗数据挖掘研究[D].广东技术师范学院硕士学位论文,2015.
[4] Ullah Z, Fayaz M, Iqbal A. Critical Analysis of Data MiningTechniques on Medical Data[J]. International Journal of Modern Education & Computer Science,2016.
[5] 魏强.基于云计算的医疗数据处理技术研究[D].贵州大学硕士学位论文,2015.
[6] Walczak, Paczkowski A /, Micha?. Medical data prepro-cessing for increased selectivity of diagnosis[J]. Bio-Algorithms and Med-Systems,2016.12(1):39-43
[7] 陈迁.糖尿病医疗数据处理及药物利用研究[D].第二军医大学硕士学位论文,2014.
[8] 闫茜.海量醫疗数据挖掘平台的研究与设计[D].武汉理工大学硕士学位论文,2014.
[9] 许杰.基于医疗数据挖掘的在线病情分析系统研究与开发[D].浙江工业大学硕士学位论文,2013.
[10] 李萍.医疗数据质量的问题探索和解决模式[J].计算机应用与软件,2013.8:217-219
[11] 蒋良孝.基于神经网络的医疗数据挖掘研究[D].中国地质大学硕士学位论文,2004.