基于云存储的网页归档方案的研究
2017-04-26徐飞郑秋生高艳霞
徐飞+郑秋生+高艳霞

摘 要: 目前美国、加拿大和澳大利亚等国的Web Archive(网页归档)技术和方案比较多,有些也比较成熟,部分已经成功应用。在我国也有网页归档的应用,但对采用的技术方案和具体工具的研究很少。结合国外的网页归档技术和最新的云存储技术,提出了一种适合我国的网页归档和存储的技术方案。
关键词: 网页归档; 云存储; Web采集; Heritrix
中图分类号:TP311 文献标志码:A 文章编号:1006-8228(2017)04-21-05
Abstract: At present, the United States, Canada and Australia possess the technology and scenarios of Web Archive, some of them are good enough to be put into practice. While China also has some application projects, which, however, contains very little about the technical scenarios and specific designing. This paper, based on the latest technology of Web Archive and the latest cloud storage technology, puts forward a new scenario suitable for the Web Archive and the storage technology of China.
Key words: Web archive; cloud storage; Web harvesting; Heritrix
0 引言
隨着计算机网络的普及,网页成为信息重要的载体,特别是一些重要的历史性的网页信息会随着网页的消失而丢失,这些信息一旦消失就难以找回或复原,这样就会给一些部门和机构造成难以估量的损失。因此,研究如何对网页归档、存储并回放就具有重要的社会意义。目前,美国、加拿大、澳大利亚和瑞典等国家的政府、档案馆和图书馆对网页归档的研究和实践应用比较多。国内对Web Archive(网页归档)进行研究的项目比较少,主要有:中国国家图书馆网络信息资源保存实验(Web Information Collection and Preservation,WICP)和中国Web信息博物馆(可访问http://www.infomall.cn)两个项目,且中国国家图书馆网络资源保存实验不完全针对网页归档,其主要研究是对电子资源的一个保存归档,只有“中国Web信息博物馆“是在国家973和985项目支持下由北京大学计算机系网络与分布式系统实验室开发建设的中国网页历史信息存贮与展示系统[1],国内对网页归档的研究与应用与国外差距比较大。而国内Web信息的特殊价值和作用使得国内对这方面的研究和实践日益重视。2014年11月国家档案局局长杨冬权在会见阿里巴巴集团副总裁兼“阿里云”总裁胡晓明及其团队时,表示将尽快启动为各级国家政府网站网页存档工作,其中阿里介绍了“阿里云”可以为国家电子档案归档做云存储方面的一些工作[2]。所以,云存储对网页归档有着非常重要的作用。
1 国外的网页归档研究
2012年11月,美国国家数字信息基础设施保存计划(NDIIPP)发布了一份《处于危险中的科学:构建在线科学内容保存的国家战略》报告[3],明确将在线科学内容保存提升成为美国国家战略。美国进行Web Archive(网页归档)最早的项目之一是IA(Internet Archive,因特网档案馆),这个项目是由一个非盈利组织领导建设的,其长期存储并对公众免费公开,所存储的资源类型比较多,有网页、音乐、动画和其他电子资源等。1996年其开始保存网页资源,2001年对公众开放,其开发了网页回放器(way back machine)。IA是目前美国最大的网页归档的项目,其在国际互联网保存联盟(International Internet Preservation Consortium,IIPC)的框架下,与许多政府和图书馆等进行紧密的合作。美国IA项目的采集策略是广泛采集,就是使用采集软件遍历URL,但有时它也对某些突发问题进行专项采集或广泛采集和专项采集相结合的方式进行[4]。其采用的采集软件是Heritrix,该软件是专门的网页采集归档软件,其采用JAVA语言开发,并且是开源的,我们可以从其官网下载(http://sourceforge.net/projects/
archive-crawler/),它有封包好的程序可以直接使用,也可以根据需要在源代码的基础上二次开发。英国、加拿大和法国等国家的国家图书馆均采用此软件来采集网页。IA对保存的网页提供了URL的高级搜索功能,用户通过网页回放器(way back machine)可以把要访问的URL自动将结果显示出来[5]。IA在存储方面与SUN合作,采用了SUN的Modular Datacenter。而加拿大国家图书馆与档案馆于1997年开始建立并采集电子资源,加拿大国家图书和档案馆(LAC)2005年开始采集加拿大政府网页的资源。其采集的策略是加拿大域名范围内政府的资源,采集软件是Heritrix和索引查询的软件NUTCHWAX都是开源的,使用WAYBACK软件组织和重现网页[6]。瑞典皇家图书馆进行的网页归档项目是-Kulturarw3(Cultural Heritage Cubed,文化遗产保存)。该项目从1996年开始,其采用选择式的采集策略,主要采集。se域名的网页资源。采集软件是Heritrix,网页显示也使用WAYBACK软件来实现[7]。
我们分析这些国家的网页归档项目,可以发现,大多数国家的图书馆和档案馆都与国际互联网保存联盟IIPC进行合作。IIPC资助开发的一些开源的网页筛选、采集、保存和网页回放工具,这些工具已经在一些国家的图书馆和档案馆广泛应用。
由于国内开展的Web Archive项目较少,也没有技术文献和文章对这些开源工具在Web Archive的设计方案和应用进行介绍,目前只有中国国家图书馆和中国Web信息博物馆利用开源工具进行了大规模采集、归档和服务的案例,但依旧有许多环节和功能需要研究和扩展。国内对Heritrix研究应用比较多,主要用于网页进行采集和索引,进行舆情的监控。但对网页归档方面的应用研究比较少。
2 Web Archive过程及工具
根据国外的项目所提到的技术和方案,结合国内实际和计算机最新的技术,在此提出一种比较实际的网页归档技术方案。网页归档方案的设计和归档的过程相结合。IIPC根据开放档案信息系统(Open Archival Information System,OAIS)参考模型将网页归档的工作划分为摄取、存储、访问与检索四个阶段[8]。
2.1 网页摄取
网页归档的第一个任务是网页的摄取,有的文章也叫网页收集或收割。网页采集要依据一定的策略和采集软件工具进行。采集策略分为:选择性采集、批量采集和混合采集,选择性采集是选定采集对象和范围,以一定的频率进行网页对象的采集,目前已采用的选择标准包括主题或资源类型等。加拿大、日本和澳大利亚图书馆的PANDORA项目均采用这种采集策略。批量采集是没有指定具体的主题或资源类型,对全球的一些Web网页进行采集,比较有名的有美国的互联网档案馆(Internet Archive,IA)[9]。混合式采集是同时使用几种采集策略。如美国国会图书馆的MINERVA项目包含选择性存档和全域快照的收集方法;丹麦皇家图书馆采取多管齐下的方法,有三种不同类型的采集方法:对域名为“.DK”的一年四次的全域收割,对约80%的网站高质量的选择性收割,和每年两三个事件的专题性收割[7]。对于目前国内的情况来说,还是采用混合策略比较好。
确定采集策略后,就需确定采集的工具,分析目前国外的网页归档项目可知,主要采用网页采集工具Heritrix。Heritrix是一个开源的软件,可以根据实际的需要在源代码上进行定制性的修改,而且这个软件经过实践证明,是比较好的网页采集软件。
2.2 网页归档存储
存储是网页归档后的首要任务,是保证Web Archive后,可以現在和未来访问和使用的基础,这里最重要的工作就是讨论:归档后Web内容的存储格式及长期保存等问题。
2.2.1 Web Archive后保存格式
Web Archive后如何对文档进行保存和保存为何种格式,这特别重要。Web Archive中的文件存档格式有多种,如ARC、WARC、CDX等,IIPC推荐使用WARC。WARC格式于2009年6月被正式批准成为ISO标准(ISO28500:2009。WARC格式将多样化的网络资源采集结果连同相关描述信息一并整合到同一存档文件中。一个WARC格式的文件(file)由若干条记录(record)连接而成。每条记录以头标区(record header)开头,后跟内容块(record content block)[10]。WARC存档格式规定了一种将多种数字资源与其相关信息(如元数据)整合为一个存档文件的方法,用以更好支持Web Archive的采集、访问和信息的交换[11]。
WARC(Web ARChive)格式具有以下特点。
⑴ 软硬件生态环境完善。WARC格式用户较多,发展时间比较长,多种开源软件均支持WARC格式标准,且其支持网络存档流程中的采集、元数据抽取、索引、格式检查、内容回放和管理等各个环节,这样软件的支持使得网页存档为WARC比较容易,且保存后简单好用。
⑵ 记录信息量大,保存当时环境。WARC格式本身就是用于存储网络资源的格式,存储了大量信息。这些信息主要包括:①网络资源保存系统环境,如爬虫信息、服务器信息、协议控制信息及响应信息等相关内容;②网络资源相互联通的信息,即锚信息和URL;③网络资源的元数据信息,这些信息记录了当时的网络环境,这些信息有利于网络资源的长期保存和使用。
⑶ 支持数据打包和压缩,便于管理和保存网络资源。WARC格式支持压缩和打包操作,可以将所采集下来的零散的文件进行打包压缩并保存,降低了长期保存的空间开销和处理小文件的计算开销,便于对资源进行管理。
⑷ 支持大容量资源的保存,WARC格式中的continuation 类型的记录支持将大容量的网络资源进行分割以便保存,并且可以控制分割块的大小,使用灵活方便,且可以应用于网络资源外的其他类型数字资源的长期保存。
⑸ 易于扩展,WARC标准预留了扩展的空间,如记录类型、截断原因等,易于在不破坏现有功能的基础上进行扩展。所以,建议网页归档保存为WARC格式。
2.2.2 Web Archive后长期存储
目前存储技术正从原始的纸张、光盘以及磁介质和数据存储中心向云存储发展,云存储是综合运用原有的分布式技术、集群化技术、网格化技术和虚拟化技术等,将网络中的不同的异型存储设备通过应用软件管理在一起协同进行工作,来对外提供高扩展性的海量存储和访问[12]。云存储分为公有云、私有云和混合云。①公有云存储。公有云存储可以由专业的公司负责,以低成本提供大存储空间。云服务商可以为每个客户划分单独的存储空间、每个客户的应用都是私有的、独立的,且公有云存储也可以根据需要划出一部分存储空间,用作私有云存储。②私有云存储。私有云存储时,图书馆或档案馆自身可以拥有或控制基础架构,并可以针对不同应用进行部署。私有云存储时可以根据需要,部署在政府部门、图书馆或档案馆数据中心等。私有云进行存储管理时,可以由图书馆或档案馆的技术部门负责,也可以由专业的云管理服务商负责。③混合云存储。就是把公有云和私有云相结合。按客户需求进行访问,特别应用于需要临时配置比较大容量的时候。这时可以从公共云上划出一部分容量配置为私有云[13]。
云存储结构图如图1所示,分析图1可知,云存储有一系列的优势。①灵活方便。对于比较小的图书馆和档案馆,可以将数据的创建与维护委托给专业的云服务提供商,而只需要租用云服务提供商的服务即可,用户不必考虑存储容量、存储设备类型和存储位置,只需要关注数据的可用性、可靠性和安全性等方面即可。避免了购买硬件设备及技术维护而投入大量的的物力和精力,可以把节省的资源用于更多专业的业务上来。②高度可靠。目前比较专业的云存储设备和云存储服务商具有数据快照、数据镜像以及数据自动同步等技术,这些技术保障了云存储服务的高可靠性,避免了数据丢失。为了确保数据的安全可靠,可以利用数字加密等技术防止数据被篡改和被攻击,所以,采用云存储技术比本地存储更加安全可靠。③存储容量大。专业的云存储服务商可以根据需要随时提供大容量存储服务器,而一般比较大的企业或图书馆等云存储也有几十、上百的存储服务器,这些服务器提供了海量的存储空间,而且还可以根据需要快速方便的增加存储服务器,用户不用担心存储空间不足的问题[14]。④成本较低。图书馆或档案馆可将大部分数据迁移至云存储上,所有的运行维护工作均由云存储服务提供商来完成。因此,可以将数据存储与管理的成本以及人力成本降到最低,同时,还能获得良好的数据存储服务。⑤量身定制。当大量归档网页数据出现时,传统的存储模式已不再适应大数据存储的需要,私有云即可满足图书馆和档案馆这种个性化需求。图书馆或档案馆可以部署一套私有云服务架构,这样不仅量身定做需求,还能在一定程度上降低安全风险。由于云存储的这些优点特别适合对网页归档的大数据进行存储。所以,对于一般的档案馆和图书馆可以采用云存储结构来保存网页归档内容。
2.3 网页访问
网页归档存储后的最终目地是网页以后的使用,即网页的访问。为了加快对归档后网页的访问速度,需要对归档后的网页建立索引,实际就是对归档后的WARC文件进行索引。Nutch不单可以对网络资源进行采集还可以进行回放,最新的Nutchwax是在Nutch基础上增加了对WARC文档进行全文索引的功能。但Nutch的主要功能还是类似Heritrix主要功能是对网页的采集。对网页的索引工作主要有solr完成,Apache Solr是基于Lucene开发的开源企业级搜索平台,支持全文索引、分面检索等功能。将Solr 应用于网络存档中的工作仍处在初步实践阶段,但IA 在2011年发布的一个报告中对比nutchwax和Solr在网络存档资源索引与检索中的表现,认为Solr 的表现相对于Nutchwax更加优异。所以建议使用solr来进行所引[15]。国外常用的回放软件工具是Wayback Machine。Wayback Machine是由IIPC主导开发并采用Java语言专门开发的WARC文档索引和回放软件。它支持对WARC文档中的URL进行索引和回放,并提供可视的检索界面。
2.4 网页归档综合管理软件
网页归档综合管理软件集成了采集、管理、索引和发布等主要流程,便于保存机构快速开展网络存档活动。其中较知名的软件是新西兰图书馆和英国图书馆合作开发的Web Curator Tools(WCT)[16]和荷兰图书馆开发的NetArchiveSuite。WCT是一款基于Java的開源软件,主要面向图书馆等非技术型用户快速开展网络存档工作。WCT集成了Heritrix爬虫、支持权限控制、任务管理、采集、质量检查以及元数据编目等主要的网络存档工作流程。NetArchiveSuite是丹麦皇家图书馆和国家与大学图书馆联合开发的网络存档软件平台。NAS主要的功能是安排、规划网络存档任务,并对网络资源进行长期保存。NAS集成了Heritrix爬虫,支持比特保存功能,且支持分布式部署和协同工作。采集管理平台WCT虽然有一系列的特点和优势,但其也有很多的功能限制,满足不了实际工作中的很多需求,建议在WCT的基础,开发一个适合实际需要的采集综合管理平台[3]。
3 具体网页归档方案设计
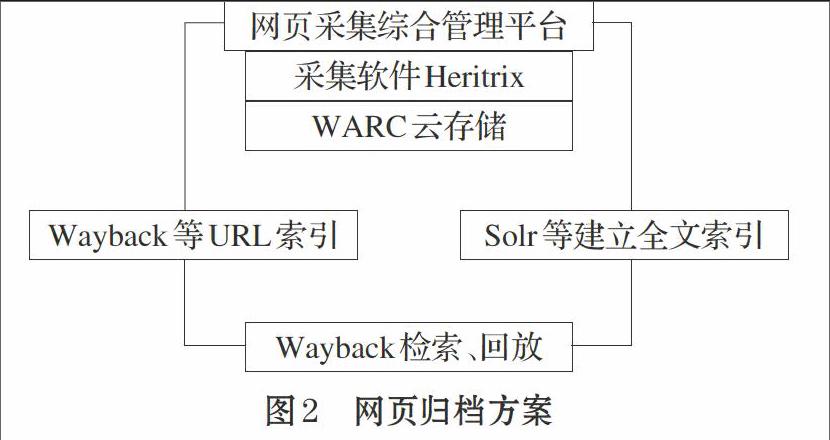
根据对国内外网页归档方案的分析和研究,结合国内的情况,设计出来一个适合我国国情并具有应用价值的一个网页归档方案,如图2所示。
首先通过网页综合管理平台设置采集策略和采集任务等,调用网页采集工具Heritrix进行网页采集,网页采集后存为WARC格式,保存在云存储服务器上,然后采用Wayback Machine和Solr对网页进行索引,最后通过Wayback对网页进行检索和回放。
4 结束语
国内对网页归档的研究较少,随着网络办公和网络管理的日益频繁,网页归档是一个刻不容缓的工作,目前国家档案局等单位已经对此项工作重视起来,但我们的有关研究还比较薄弱,希望在此方案基础上,有更多的研究机构对此进行更多的研究和实践。从而为我国的网页归档工作提供一些参考和启示。
参考文献(References):
[1] Toward a National Strategy for Preserving Online Science[EB/OL].[2014-08-05].http://www.digitalpreservation.gov/meetings/documents/othermeetings/science-at-risk-NDIIPP-report-nov-2012.pdf.
[2] http://www.zjda.gov.cn/jgzw/zwgk/snxx/201412/20141202_325721.html
[3] 吴振新,张智雄,谢靖,胡吉颖.基于IIPC开源软件拓展构建国际重要科研机构Web存档系统[J].现代图书情报技术,2015.257(4):1-9
[4] 王芳,史海燕.国外WebArchive研究与实践进展[J].中国图书馆学报,2013.204(39):36-45
[5] 王烁.美国网页归档项目-InternetArchive发展研究[J].兰台世界,2012.17:18-19
[6] 王烁,丁宇.加拿大图书馆网页归档项目研究[J].档案学研究,2012(6):83-85
[7] 王烁,丁宇.瑞典皇家图书馆网页归档项目研究[J].办公室业务,2013,24(23):111-113
[8] 向菁,吴振新.网络信息资源保存发展现状及趋势分析[J].中国图书馆学报,2009.180(2):34-41
[9] Internet Archive[EB/OL].[2012-06-10].http://archive.org/.
[10] 李睿,韩毅,郭世明.WARC格式对描述与组织网络收割结果的支持[J].图书馆理论与实践,2010.7:38-41
[11] 曲云鹏.网络存档文件格式WARC研究[J].图书馆学研究,2014.24(24):20-28
[12] 王伟.存储的进化:云存储解决方案[J].通讯世界,2012.12(9):54-55
[13] 王刚.计算机网络存储技术[J].计算机系统应用,2015.24(1):14-20
[14] 刘思得.基于网络的云存储模式的分析探讨[J].科技通报,2012.28(10):206-209
[15] 蔡学锋.基于Solr的搜索引擎核心技术研究与应用[D].武汉理工大学硕士论文,2013.
[16] The Web Curator Tool Project [EB/OL]. [2014-08-05].http://Webcurator.sourceforge.net/.