基于神经网络的语义选择限制知识自动获取
2017-04-25贾玉祥许鸿飞昝红英
贾玉祥,许鸿飞,昝红英
(郑州大学 信息工程学院,河南 郑州 450001)
基于神经网络的语义选择限制知识自动获取
贾玉祥,许鸿飞,昝红英
(郑州大学 信息工程学院,河南 郑州 450001)
语义选择限制刻画谓语对论元的语义选择倾向,对自然语言的句法语义分析有重要作用,语义选择限制知识的自动获取也成为一个重要的研究课题。鉴于神经网络模型在自然语言处理的很多任务中都有出色的表现,该文提出基于神经网络的语义选择限制知识获取模型,设计了引入预训练词向量的单隐层前馈网络和两层maxout网络。在汉语和英语的伪消歧实验中神经网络模型取得了较好的效果,优于基于隐含狄利克雷分配的模型。
语义选择限制;词汇知识获取;神经网络;伪消歧
1 引言
谓语动词对其论元有选择倾向性,称为语义选择限制(Selectional Preference,SP)。例如,“吃”这个动词的主语倾向于选择表示“人或动物”的名词,宾语倾向于选择表示“食物”的名词。可以用函数spr(v,n)表示语义选择倾向,v表示谓语动词,r表示论元类型,n表示名词,sp值为实数,值越大,表示n越适合充当v的论元r。例如,“苹果”比“石头”更适合充当“吃”的“宾语”。语义选择限制知识获取就是学习函数spr(v,n),实现对任意(v,r,n)的打分。
语义选择限制知识对于分析句子语义有重要价值。例如,
1.判断句子是否合法。
人民的生活水平正在不断地改善。
此句不合法,主谓搭配错误。可以利用“水平”与“改善”之间的选择倾向来判断是否合法。
他统一安排现场会的内容、时间和出席人员,以及会议中应注意的问题。
此句不合法,动宾搭配错误。可以利用“安排”与“问题”之间的选择倾向来判断是否合法。
2.识别隐喻表达[1]。
山体滑坡 业绩滑坡
编织毛衣 编织梦想
根据在隐喻表达中具体动词倾向于选择抽象的名词作为主语或宾语这样的规律,可以识别出“业绩滑坡”与“编织梦想”为隐喻表达。
3.推测词义。
好莱坞特技车队驾驶凯迪拉克大秀车技。
爱她就请她吃哈根达斯。
通过“驾驶”倾向于选择“汽车”做宾语,可以推测“凯迪拉克”是一种汽车。通过“吃”倾向于选择“食物”做宾语,可以推测“哈根达斯”是一种食物。
语义选择限制知识可以用于自然语言处理的多个任务,例如,句法分析[2]、语义角色标注[3]、词义消歧[4]、机器翻译[5]等。语义选择限制是很多词汇知识库的重要组成部分,例如,英语的VerbNet、汉语的HowNet等。然而,手工构建的语义选择限制知识库很难满足自然语言处理的需求,因此要求从大规模语料中自动获取语义选择限制知识。
神经网络可以实现函数spr(v,n),网络输入为代表v和n的值(如,词向量),输出为spr(v,n)。神经网络模型在自然语言处理的很多任务上都取得了很好的效果,本文提出基于神经网络的语义选择限制知识获取模型,尝试不同的网络结构,并与基于LDA(Latent Dirichlet Allocation)的模型进行比较。本文的章节安排如下:第二节介绍相关研究工作;第三节介绍语义选择限制获取的神经网络模型;第四节给出实验结果与分析;第五节给出总结和展望。
2 相关研究
从训练语料中抽取句法搭配(v,r,n),形成训练集,当然可以对搭配做一些过滤,如限制搭配必须至少出现多少次,或v、n至少出现多少次。对于训练集中出现过的搭配,spr(v,n)的计算比较直观,可以简单地用共现次数count(v,r,n)或条件概率p(n|v,r)来表示。关键是训练集中没有出现过的搭配(v,r,n′)如何计算spr(v,n′),即如何根据v的已知论元计算未知论元的sp值,称之为论元扩展。根据论元扩展是否使用语义分类体系可以将语义选择限制获取方法分为两大类:基于语义分类体系的方法与基于分布的方法(见表1)。
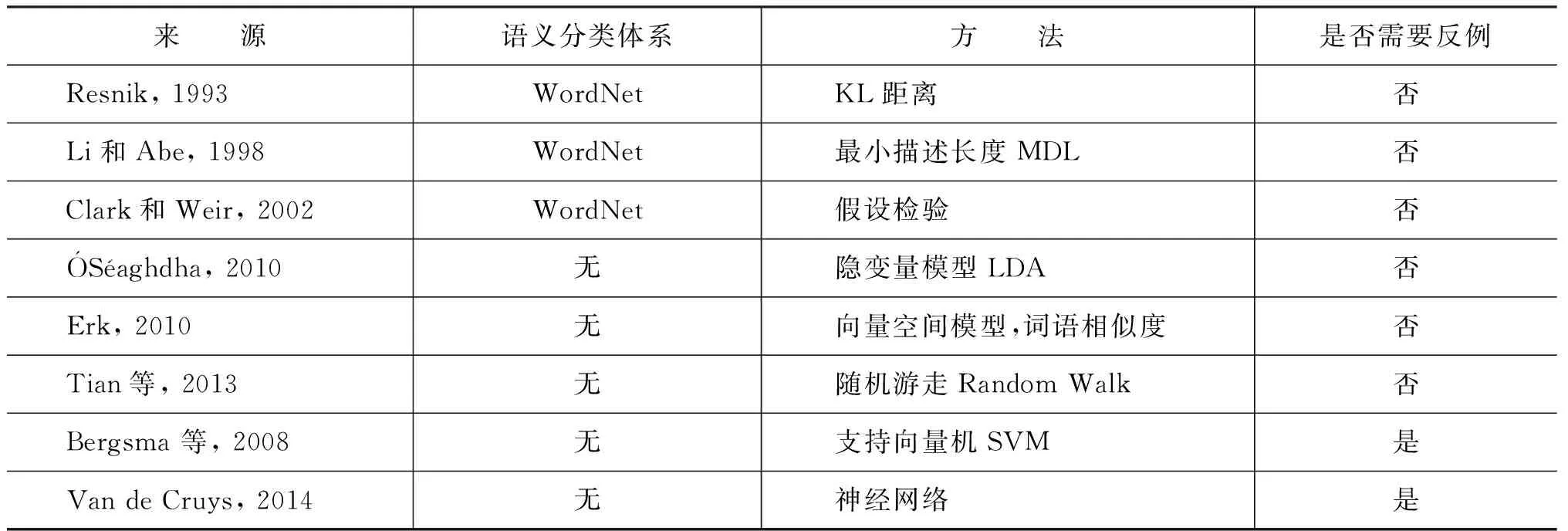
表1 SP自动获取的代表性方法
基于语义分类体系的方法。该方法借助语义分类体系(如WordNet),计算谓语对论元语义类的sp值,那么对于未知论元,只要它出现在某一个语义类中,就可以给它一个sp值。对于语义类sp值的计算,Resnik[6]使用一个基于KL距离的统计指标,Li和Abe[7]基于最小描述长度(Minimum Description Length,MDL)模型,Clark和Weir[8]则采用基于假设检验的方法。这类方法的优点是可以学习出关于语义类的选择限制知识,易于人类理解,便于集成到词汇知识库中。缺点是需要一个语义分类体系,由于词典收词有限会导致论元覆盖率比较低,并且不能很好地处理一词多义的问题。这类方法主要面向语言学研究和词汇知识库构建。
基于分布的方法。该方法不需要语义分类体系,而是根据词语在语料中的分布来实现论元的扩展。隐变量模型[9](如LDA)是一种基于概率的模型,隐变量可以看成一个个隐含的语义类,把谓语和未知论元联系起来。基于向量空间的模型[10]利用大规模语料构建一个向量空间,通过在该空间里计算未知论元和已知论元的相似度,把谓语和未知论元联系起来。Tian等[11]通过在谓语论元搭配图上的随机游走算法来解决未知论元sp值的计算问题。Bergsma等[12]使用SVM(Support Vector Model)直接对论元进行二分类:合适的论元和不合适的论元,把分类器给论元的打分作为sp值。Van de Cruys[13]首次使用神经网络进行选择限制知识的获取,设计了一个单隐层前馈网络,输入v、n的词向量表示,输出sp值。基于分布的方法优点是不依赖语义分类体系,论元覆盖率高,对一词多义问题能更好地处理,易于和其他自然语言处理任务结合。缺点是学习出的知识是词语层面的,与语义类层面的知识相比,概括性差,不易于人类理解。这类方法主要面向自然语言处理,也是SP获取的主流方法。
基于SVM和神经网络的方法把选择限制的学习当做机器学习的分类和回归问题,属于有监督的学习,需要正例和反例,即合适的论元和不适合的论元。其他方法只需要正例,训练集中都是正例,以这些正例为种子,通过语义分类体系或语料分布实现论元的扩展。反例并非由人工构建,而是自动产生,思想是使正例发生的可能性尽量大,反例发生的可能性尽量小。例如,对于每一个正例(v,r,n),采用某一种策略将n替换为n′,只要(v,r,n′)不在训练集中出现或某一个统计指标小于阈值(如出现次数、互信息值),则把(v,r,n′)当做反例。
本文在神经网络[13]中引入预训练的词向量来改进模型的效果,并提出基于maxout网络的模型。作为实验对比的LDA模型[14],把每个谓语动词v看做一篇文档,文档内容由训练集中该动词特定论元r的所有名词n构成,隐含主题z为名词语义类,则语义选择倾向定义为公式(1),其中参数p(n|z)与p(z|v,r)由模型训练得到。
(1)
3 基于神经网络的SP获取模型
本文主要考察动词对宾语的语义选择限制,因此论元类型r为动词宾语,为了表述方便,在后面的符号表达中将r省去。下面对选择限制获取的单隐层前馈网络、maxout网络及模型训练方法作一介绍。
3.1 单隐层前馈网络
网络由输入层、隐藏层、输出层三层构成(如图1所示)。输入层节点数为2N,隐藏层节点数为H,输出层节点数为1。输入x为动词v的词向量v与宾语n的词向量n的拼接(concatenation),即得到公式(2)。
x=[v,n]
(2)
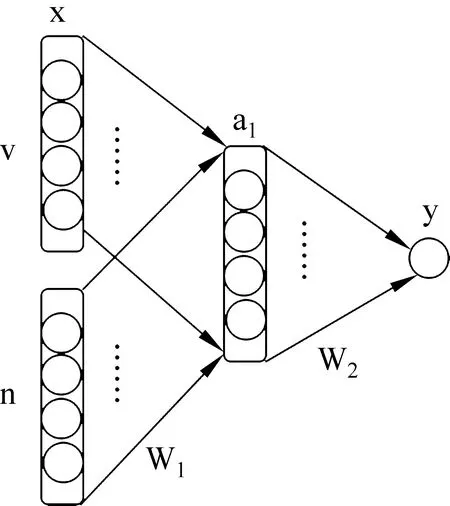
图1 单隐层前馈网络结构
词向量的维度为N,因此x的维度为2N。动词和名词的词向量分开学习,学习之前可以进行随机初始化或引入预训练的词向量,在模型训练过程中通过反向传播进行更新。W1为输入层与隐藏层之间的权值矩阵,W1∈RH×2N,b1为偏置项,b1∈RH,隐藏层节点的激活函数为tanh,a1为隐藏层节点的输出值,见公式(3),a1∈RH。W2为隐藏层与输出层之间的权值矩阵,W2∈R1×H,输出y为隐藏层输出的线性组合,为一个实数,见公式(4),偏置项b2为实数,y即为所求的动词v对宾语n的语义选择倾向sp。
单隐层前馈网络结构简单,为了提高网络的性能,我们在词向量初始化时引入预训练的词向量,加入了额外的语言资源,并与随机初始化词向量的方法做对比。
3.2 两层maxout网络
Maxout[15]可以看作神经网络中的一种激活函数,与通常的非线性函数直接作用在输入的线性组合上以实现非线性变换不同,maxout对每个输入进行k(k≥2)次线性组合,从中选择最大的值作为变换后的输出,达到非线性变换的目的。也就是说,对于一个输入,根据多组参数同时线性计算多组输出,然后取多组输出中对应位置的最大值构成最终输出。这样maxout会增加网络参数,但学习能力也得到了增强。理论上,maxout可以拟合任意凸函数;在实践中,maxout网络在多个机器学习任务上也取得了很好的效果。
我们对单隐层前馈网络结构进行调整,形成两层的maxout网络(如图2所示)。在原网络的隐藏层和输出层分别增加一倍的节点,形成两组节点(k=2),每一组节点个数与原网络该层节点个数相同,两组节点分别对所有输入进行线性组合,然后通过max函数选择两组节点中对应位置节点的最大值构成输出。公式(5)和公式(6)分别是隐藏层的输出a1和输出层的输出y,a1∈RH且y是实数,表示动词v对宾语n的语义选择倾向sp。相比于单隐层前馈网络,maxout网络增加了参数W1′、b1′、W2′与b2′。
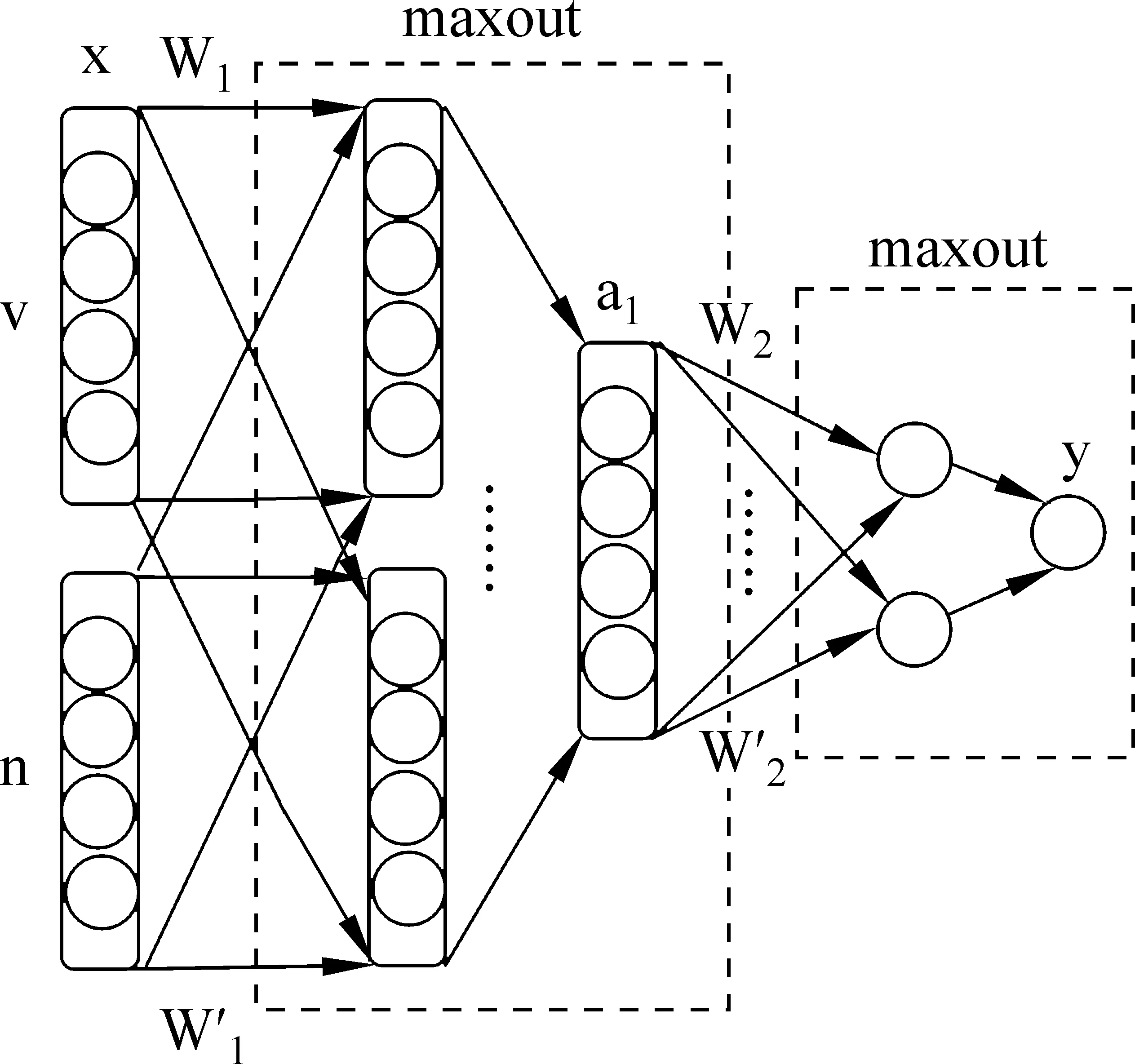
图2 两层maxout网络结构
3.3 网络训练
语义选择限制知识获取的任务要求通过大规模无标注语料进行神经网络参数的训练。Collobert和Weston[16]提出一种基于无标注语料训练神经网络语言模型的方法,即将语料中正常出现的ngram序列视为正例,随机替换其中某一个词后得到的序列为反例。与之类似,把训练集中出现的搭配(v,n) 视为正例,而把n随机地替换为n′后形成的搭配 (v,n′) 视为反例。我们关心的是模型对正例和反例打分的大小关系,期望正例的打分至少要比反例的打分大l(l的取值可以调整,这里取l=0.1),于是对于每一对搭配(v,n)定义以下排序目标函数,如式(7)所示。
∑n′∈Jmax(0,l-g[(v,n)]+g[(v,n′)])
(7)
表示正例(v,n)与所有反例的分差之和。其中J为名词词表,g[()]是模型的打分。可见,当g[(v,n)]-g[(v,n′)]>=l时,max取值为0。否则,max取值大于0。模型训练的目标就是使公式7的值最小。
我们在训练时,总是给每一个正例随机生成一个反例,作为一对训练样本,由网络输出正例的打分和反例的打分,计算目标函数关于模型参数的导数,借助反向传播更新模型参数及输入词向量。
4 实验与分析
实验考察中英文两种语言中动词对宾语的选择限制情况,模型包括随机初始化词向量的单隐层前馈网络、引入预训练词向量的单隐层前馈网络、两层maxout网络及基于LDA的模型,使用伪消歧(pseudo-disambiguation)[17]的方法进行评价。
4.1 模型的实现
单隐层前馈网络输入词向量维数N=50,输入层节点个数为100,隐藏层节点个数H=50。两层maxout网络使用一个100维输入50维输出的maxout网络和一个50维输入1维输出的maxout网络串联组成,每个maxout网络中都包含两个线性层。
实验在Torch7平台上进行,使用mini-batch梯度下降方法进行训练。每采样一个正例,随机生成一个反例,构成一个正反例对,每批抽取512个正反例对,每256批为一个周期,训练过程中记录每个周期内误差的均值,如果连续20个周期内没有出现更小的误差,认为网络收敛,停止训练。网络参数的初始学习速率为0.000 25,词向量的初始学习速率为0.000 125,开始训练时先以初始学习速率训练八个周期,来预热模型,使之快速地收敛到一定位置,然后学习速率开始随训练周期数下降(初始学习速率/当前训练的周期数,未包含预热的八个周期)。
随机初始化词向量把词向量元素赋值为[0,1]之间的随机浮点数。中文的预训练词向量采用word2vec[18]在Chinese Gigaword上训练出的词向量,词向量维数为50,模型采用Skip-gram,上下文窗口大小为5,负采样,负样本个数为5。英文预训练词向量采用Glove*http://nlp.stanford.edu/projects/glove/在Wikipedia 2014与English Gigaword 5上训练出的词向量,词向量维数为50。
作为比较的LDA模型采用GibbsLDA++*http://gibbslda.sourceforge.net/来实现,中文模型隐含主题个数设为200,迭代训练2 000次;英文模型隐含主题个数也设为200,迭代训练1 000次。其他参数均采用缺省设置。
4.2 评价方法
语义选择限制获取模型对动宾搭配打分,合理的搭配得分要高于不合理的搭配,伪消歧方法就是利用这种思想对选择限制获取模型进行评价。对于测试集中的每一个正例(v,n),构造反例(v,n′),如果spr(v,n) >spr(v,n′),则判断正确,记做correct;如果spr(v,n) =spr(v,n′),则记作tie;否则,判断错误。正确率accuracy的计算公式如式(8)所示。
(8)
中文测试数据使用1998年1月的人民日报语料,从中抽取动宾搭配,并通过人工校对选取1 289个作为正例,包括365个动词和379个名词。从Penn Treebank中选取动宾搭配2 500个作为英文测试数据中的正例。

表2 正反例举例
反例中替代词n′的选择有不同的策略,例如,随机选择(按训练集中名词的真实分布)、选择词频相近的词等。我们采用三种选择策略,分别为:名词按词频降序排列,选择直接前驱词(pre);名词按词频降序排列,选择直接后继词(post);随机选择(rand)。表2分别给出中英文测试集中正反例的例子。verb是动词v,pos是正例中的n,pre、post与rand是三种策略下的反例中的n′。可见,正例的搭配较合理,而反例大多不合理,但也可能存在合理的情况,例如,“reject change”,因此要进行更准确的评价,还需要对测试集中自动生成的反例进行过滤或人工校对。
中文训练语料为人民日报1995、1997~2005共十年的语料,使用NiuParser[19]进行分词、词性标注、依存句法分析,抽取动宾搭配,选择动词出现30次以上、名词出现五次以上的搭配。去掉测试集中出现的搭配(包括正例和反例),最后得到动宾搭配8 877 091对(去重后搭配1 709 168对)。
英文训练语料为English Gigaword语料中的Agence France-Presse(AFP,2001—2010年)和New York Times(NYT,2001—2010年),从中抽取动宾搭配,选择动词出现30次以上、名词出现五次以上的搭配。去掉测试集中出现的搭配(包括正例和反例),最后分别得到动宾搭配25 004 475对(去重后搭配1 912 264对)、28 133 369对(去重后搭配3 274 509对)。
从训练数据中去掉测试样本中的所有搭配,包括正例和反例,这样做是为了保证所有的测试样本对模型来说都是没有见过的,以使实验结果更能反映模型的泛化能力,将重点放在谓语动词对未见论元的选择限制的预测上。
4.3 实验结果及分析
中英文语义选择限制获取结果分别见表3、表4(粗体表示测试集上的最好结果)。方案SHL为单隐层前馈网络,词向量随机初始化。方案SHL+wv为单隐层前馈网络,词向量初始化为预训练词向量。方案Maxout+wv为两层maxout网络,词向量初始化为预训练词向量。方案LDA为基于LDA的选择限制获取模型。方案wv+cos利用预训练的词向量直接计算v和n的相似度,作为sp值,相似度计算公式使用夹角余弦cos(v,n),该方案用作baseline与其他方案相比较。为了考察语料规模的影响,我们在中文人民日报语料上做了三个实验,分别把十年(x10)、两年(x2,2004、2005年)、一年(x1,2005年)的语料作为训练集。英文nyt训练集中的样本数多于afp。
实验结果显示:(1)预训练词向量比随机初始化词向量的结果有大幅度的提升; (2)Maxout网络比单隐层前馈网络的结果又有所提升; (3)引入预训练词向量的神经网络模型结果优于LDA模型; (4)直接使用词向量计算相似度的方案wv+cos是一个很强的baseline,超过了LDA模型的结果,但是神经网络模型仍然能取得更好的结果; (5)模型可以在较小规模的训练集上取得不错甚至更好的结果,因此不必一味增加训练集的规模。
中英文的测试结果相差很大,中文的结果明显好于英文。原因分析如下:(1)中文测试数据和训练数据都来自人民日报语料,而英文的测试数据Penn Treebank语料来源于Wall Street Journal,不同于训练语料Agence France-Presse与New York Times,这种语料的差异是典型的领域迁移问题,会带来性能的损失; (2)中文测试集中的正例和反例均经过了人工验证,而英文测试集没有经过人工验证,随机选择Penn Treebank中出现的动宾搭配作为正例,生成的反例只要没有出现在Penn Treebank中即可。这样可能会造成英文出现“正例不正,反例不反”的情况,即反例虽然在测试语料中不存在,但有可能在原始训练语料(剔除测试样本之前)中出现的很多,甚至比正例还多,从而使测试结果变差。如表5所示,post策略下三个反例在原始训练集afp中出现的次数均高于正例。在选择测试样本的时候可以使用共现频率、互信息等统计指标进行过滤(如,要求反例不在训练集中出现),来保证样本的质量。
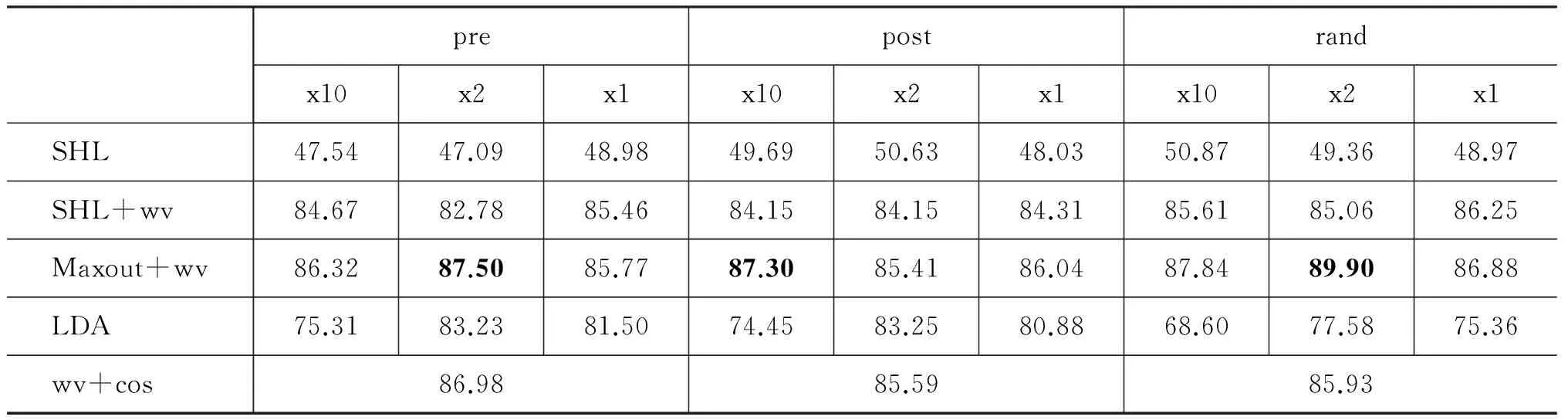
表3 中文语义选择限制获取实验结果

表4 英文语义选择限制获取实验结果
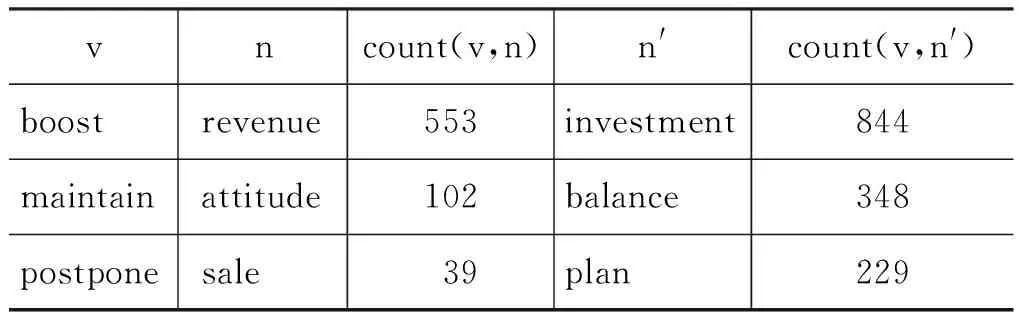
表5 正反例(post)在原始训练集(afp)中的共现次数
5 总结与展望
本文提出基于神经网络的语义选择限制自动获取模型,包括引入预训练词向量的单隐层前馈网络和两层maxout网络模型,在中文和英文两种语言上的伪消歧实验中,两个模型的结果都优于LDA模型,引入预训练词向量的神经网络模型也可以取得比基于词向量的词语相似度方法更好的结果。
深度神经网络在语义选择限制知识获取上的应用还比较初步,我们下一步会对模型参数进行调优,深入分析实验结果,对模型进行改进,尝试其他的神经网络结构。在模型的对比方面,我们只是与前期工作中的LDA模型作了比较,由于数据获取及实验细节方面还存在一些问题,尚未与其他模型进行全面的比较,这将是下一步的工作重点。我们对中英文语义选择限制知识的获取进行了初步的实验,研究跨语言的语义选择限制知识获取,探索不同语言中的语义选择限制规律也是将来的工作之一。
致谢
感谢Zhenhua Tian分享的英文数据:从Agence France-Presse语料、New York Times语料及Penn Treebank中提取的动宾搭配。感谢北京大学计算语言学研究所的李天时提供的中文预训练词向量。
[1] 贾玉祥,俞士汶.语义选择限制的自动获取及其在隐喻处理中的应用[C]//第四届全国学生计算语言学研讨会(SWCL 2008),2008:90-96.
[2] Guangyou Zhou,Jun Zhao,Kang Liu,et al.Exploiting Web-Derived Selectional Preference to Improve Statistical Dependency Parsing[C] //Proceedings of ACL2011,2011:1556-1565.
[3] Shumin Wu and Martha Palmer.Can Selectional Preferences Help Automatic Semantic Role Labeling?[C] //Proceedings of Lexical and Computational Semantics (*SEM 2015),2015:222-227.
[4] Diana McCarthy and John Carroll.Disambiguating nouns,verbs,and adjectives using automatically acquired selectional preferences[J].Computational Linguistics,2003,29(4):639-654.
[5] 唐海庆,熊德意.基于选择偏向性的统计机器翻译模型[J].北京大学学报 (自然科学版),2016,52(1):127-133.
[6] Philip Resnik.Selection and Information:A Class-Based Approach to Lexical Relationships[D].Ph.D.thesis,University of Pennsylvania,Philadelphia,PA,1993.
[7] Hang Li,Naoki Abe.Generalizing case frames using a thesaurus and the MDL principle[J].Computational Linguistics,1998,24(2):217-244.
[8] Stephen Clark,David Weir.Class-based probability estimation using a semantic hierarchy[J].Computational Linguistics,2002,28(2):187-206.
[9] Diarmuid 'O S'eaghdha.Latent variable models of selectional preference[C] //Proceedings of ACL2010,2010:435-444.
[10] Katrin Erk,Sebastian Pado,Ulrike Pado.A Flexible,Corpus-driven Model of Regular and Inverse Selectional Preferences[J].Computational Linguistics,2010,36(4):723-763.
[11] Zhenhua Tian,Hengheng Xiang,Ziqi Liu,et al.A Random Walk Approach to Selectional Preferences Based on Preference Ranking and Propagation[C] //Proceedings of ACL2013,2013:1169-1179.
[12] Shane Bergsma,Dekang Lin,Randy Goebel.Discriminative Learning of Selectional Preference from Unlabeled Text[C] //Proceedings of EMNLP2008,2008:59-68.
[13] TimVan de Cruys.A Neural Network Approach to Selectional Preference Acquisition[C] //Proceedings of EMNLP2014,2014:26-35.
[14] 贾玉祥,王浩石,昝红英,等.汉语语义选择限制知识的自动获取研究[J].中文信息学报,2014,28(5):66-73.
[15] Ian J Goodfellow,David Warde-farley,Mehdi Mirza,et al.Maxout networks[C] //Proceedings of ICML2013,2013:1319-1327.
[16] Ronan Collobert,Jason Weston.A unified architecture for natural language processing:Deep neural networks with multitask learning[C] //Proceedings of ICML2008,2008:160-167.
[17] Nathanael Chambers,Dan Jurafsky.Improving the use of pseudo-words for evaluating selectional preferences[C] //Proceedings of ACL2010,2010:445-453.
[18] Tomas Mikolov,Kai Chen,Greg Corrado,et al.Efficient estimation of word representations in vector space[DB].arXiv preprint,arXiv:1301.3781,2013.
[19] Jingbo Zhu,Muhua Zhu,Qiang Wang,et al.NiuParser:A Chinese Syntactic and Semantic Parsing Toolkit[C] //Proceedings of ACL-IJCNLP 2015,2015:145-150.
Neural Network Models for Selectional Preference Acquisition
JIA Yuxiang,XU Hongfei,ZAN Hongying
(School of Information Engineering,Zhengzhou University,Zhengzhou,Henan 450001,China)
Selectional preference describes the semantic preference of the predicate for its arguments.It is an important lexical knowledge for the syntactic and semantic analysis of natural languages.Neural network models have achieved state-of-the-art performance in many natural language processing tasks.This paper deploys neural network models for selectional preference acquisition,including a one-hidden-layer feedforward network with pre-trained word vectors and a maxout network.In the pseudo-disambiguation experiments on Chinese and English,neural network models both outperform a LDA-based selectional preference acquisition model.
selectional preference; lexical acquisition; neural network; pseudo-disambiguation

贾玉祥(1981—),博士,讲师,主要研究领域为自然语言处理。E-mail:ieyxjia@zzu.edu.cn许鸿飞(1994—),硕士研究生,主要研究领域为自然语言处理与深度学习。E-mail:hfxunlp@foxmail.com昝红英(1966—),博士,教授,主要研究领域为自然语言处理。E-mail:iehyzan@zzu.edu.cn
1003-0077(2011)00-0155-07
2016-09-08 定稿日期:2016-10-25
国家自然科学基金(61402419);国家社会科学基金(14BYY096);国家高技术研究发展计划863课题(2012AA011101);国家重点基础研究发展计划 973 课题(2014CB340504)
TP391
A
