基于文档发散度的作文跑题检测
2017-04-25陈志鹏陈文亮
陈志鹏,陈文亮
(1.苏州大学 计算机科学与技术学院,江苏 苏州 215006;2.软件新技术与产业化协同创新中心,江苏 苏州 215006)
基于文档发散度的作文跑题检测
陈志鹏1,2,陈文亮1,2
(1.苏州大学 计算机科学与技术学院,江苏 苏州 215006;2.软件新技术与产业化协同创新中心,江苏 苏州 215006)
作文跑题检测是作文自动评分系统的重要模块。传统的作文跑题检测一般计算文章内容相关性作为得分,并将其与某一固定阈值进行对比,从而判断文章是否跑题。但是实际上文章得分高低与题目有直接关系,发散性题目和非发散性题目的文章得分有明显差异,所以很难用一个固定阈值来判断所有文章。该文提出一种作文跑题检测方法,基于文档发散度的作文跑题检测方法。该方法的创新之处在于研究文章集合发散度的概念,建立发散度与跑题阈值的关系模型,对于不同的题目动态选取不同的跑题阈值。该文构建了一套跑题检测系统,并在一个真实的数据集中进行测试。实验结果表明基于文档发散度的作文跑题检测系统能有效识别跑题作文。
跑题检测;文档发散度;文本相似度
1 引言
作文跑题指文章偏离了预先给定的主题。例如,现在有一个题目“on food safety”,要求写关于食品安全的文章。如果学生写的文章与此主题无关,而是关于其他主题,比如读书或者关于大学生活,我们就认为该作文跑题。作文的质量和是否跑题没有必然联系,有的文章虽然写的很短很差,但是并没有跑题。作文跑题的原因很多,可能是作者有意为之,也可能是无意间的提交错误[1]。
作文跑题检测用于判断文章是否跑题,是作文自动评分系统的重要组成模块。传统的作文跑题检测系统一般计算内容相似度,将其与一个固定的阈值进行比较,然后判断文章是否跑题。这种方法简单有效,但是没有考虑文章得分和题目类型之间的关系,而是简单假设所有题目下的跑题阈值都一样。
针对传统方法的不足,本文提出基于文章发散度设立动态阈值的方法。这种方法考虑不同类型的题目,研究题目下文章集合发散度的概念,挖掘跑题阈值与文档发散度之间的关系,根据文档发散度动态选取题目对应的阈值,实验证明此方法可以提高检测系统的性能。
本文的其余部分安排如下:第二节对相关工作进行介绍;第三节详细介绍我们提出的作文跑题检测方法。第四节介绍实验和结果分析,第五节是结论和下一步工作介绍。
2 相关工作
作文跑题检测的核心是文本相似度计算。文本相似度是表示两个文本之间相似程度的一个度量参数。除了用于文章跑题检测,在文本聚类[2]、信息检索[3]、图像检索[4]、文本摘要自动生成[5]、文本复制检测[6]等诸多领域,文本相似度的有效计算都是解决问题的关键所在。
传统文本相似度计算一般基于向量空间模型VSM (Vector Space Model)。向量空间模型的基本思想是用向量形式来表示文本:vd=[w1,w2,w3……wn],其中wi是第i个特征项的权重,一般用词的TF-IDF值[7]作为特征权重*TF-IDF是常用的特征权重计算方法。除此之外,亦可采用二元特征或者以词频作为权重。。TF-IDF值表示该词对于文本的重要程度,它由词频和逆文档频率构成。
词频(Term Frequency),即一个词在文档中出现的次数:一个词在文章中出现的次数越多,它对这篇文章就越重要,它与文章的主题相关性也就越高。要注意的是停用词(stop words),像中文中的“的”、“了”,英文中的“a”、“the”,这些词并不具备这种性质,它们虽然出现的次数比较多,但是它们不能反映文章的主题。应该将它们过滤掉。
逆文档频率(Inverse Document Frequency),如果一个词在文档集合中出现的次数越多,说明这个词的区分能力越低,越不能反映文章的特性;反之,如果一个词在文档集合中出现的次数越少,那么它越能够反映文章的特性。例如,有100篇文档,如果一个词A只在一篇文档中出现,而词B在100篇文档中都出现,那么,很显然,词A比词B更能反映文章的特性。
将上面两个概念结合起来,可以计算出一个词项的TF-IDF值,对于一个词项wi:
TFIDF(wi)=tf(wi)×idf(wi)
(1)
其中TFIDF(wi)表示当前词项wi的TF-IDF值,tf(wi)表示wi的词频,idf(wi)表示wi的逆文档频率。很显然,词频就等于一篇文档中该词项出现的次数除以文章的总词数,而逆文档频率的计算如式(2)所示。
(2)
N表示的是文档集合中文档的总数,df(wi)是包含词项wi的文档的总数,加1是为了保证分子大于0。
对于文本D,基于向量空间模型,我们可以将D表示为向量[a1,a2..ak..an],其中ak为词表中第k个单词对应的TF-IDF值。将文章表示为向量后,便可使用余弦公式计算向量间的相似度,以此来度量文本之间的相似度,如式(3)所示。
(3)
其中D1和D2表示两篇文本,假设词表中一共有n个词,a1k表示第一篇文本D1中单词的TF-IDF值,a2k表示第二篇文本D2中单词的TF-IDF值。
基于向量空间模型的文本相似度计算方法简单有效,但是这种方法忽略了文本中词项的语义信息,没有考虑到词与词之间的语义相似度。例如“笔记本”和“手提电脑”这两个词在向量空间模型中被认为两个独立的特征而没有考虑这两个词在语义上的相近性。针对这一问题,很多研究人员进行了研究,其中词扩展是最常见的一种策略。现有词扩展方法主要采用基于词典的方法,比如使用WordNet[8]、HowNet等词典。Yan[9]提出了基于WordNet词扩展计算英语词汇相似度的方法。Zhu[10]提出了基于HowNet计算词汇语义相似度的方法,并将其用于文本分类。这些方法严重依赖于人工构造的词典资源,在新语言和新领域应用中会遇到很多问题。近年来,随着深度学习的兴起,词向量获得了越来越多重视,许多研究者研究尝试将其融入文本相似度计算,Chen[1]提出利用词向量快速构建词项之间语义关系并进行词扩展,不需要依赖人工构造的字典,面对不同领域的作文检测也有较好的效果。
作文跑题检测源于对作文自动评分系统的研究。传统的作文评分系统,如PEG[11]、IEA[12]、E-rater[13]等并未直接判断文章是否跑题,而是将内容相关度作为文章特征之一,利用分类或者回归的方法计算新文章的得分。这种方法直接给出文章总体得分,用户无法从中判断出文章是否跑题。针对这种不足,通用的方法是设定一个阈值,将内容相关度与阈值进行对比,以此来判断文章是否跑题。Louis[14]提出了利用主题描述来检测作文跑题的方法,通过计算文章与主题描述的相似性并与阈值进行对比来判断文章是否跑题。Ge[15]提出一种利用文本聚类来判断文章是否跑题,同样是设定相似度阈值作为聚类终止条件。这些方法相较于传统方法的优点是可以显示判断文章是否跑题,但是传统方法设置的都是固定阈值,即所有题目的阈值都相同,没有考虑不同题目的特点。
与上述方法不同,本文在研究题目发散性的基础上,提出一种设立动态阈值的方法。研究文本集合发散性值的概念和度量方法,分析发散性值和跑题阈值的关系,构建二者的线性关系模型。通过这种方法,我们可以动态计算出每一个题目下的跑题阈值。实验表明,相对于固定设定阈值,基于发散性的阈值设定方法有更好的性能。
3 基于文档发散度的作文跑题检测
本部分3.1、3.2节详细阐述本文的创新点:文档发散度和基于文档发散度的跑题检测。3.3节介绍基于词扩展的文本相似度计算方法[1],实验中用此方法计算文章和范文的相似度。
3.1 文档发散度
文档的发散度指的是某一题目下文章集合的发散程度。例如,有两个题目:“一场足球赛”和“一次难忘的经历”。相对而言,后者的作文集合会更加“多种多样”,不仅仅会有写足球赛的,可能还会有写旅游、料理等主题的作文。这些文章所叙述的事情没有统一的主题,不同文章的内容之间也没有太多相似性,但是它们却没有跑题。像这样的题目,我们认为其发散度就比较高。这个题目也被称为发散性题目。
由于发散性题目下文章之间的相似性不高,差异较大,本文用文章之间两两相似度均值来表示文章集合的发散程度。假设某一题目下有M篇文章{D1,D2…D…m},文章之间两两相似度的均值称为文章发散度值,为div,则有式(4):
(4)
其中,Num指1,2,3…m个数的组合数目,Sim(Di,Dj)表示文章D1和D2的相似度,使用TF-IDF方法(即式(3))计算。如果一个题目的发散度越高,则它的发散度值div就越低。
我们挑选了十个真实的题目,每个题目下都有100篇文章。计算出每个题目下文章集合的发散度值,按发散性值从低到高排序,如表1所示。
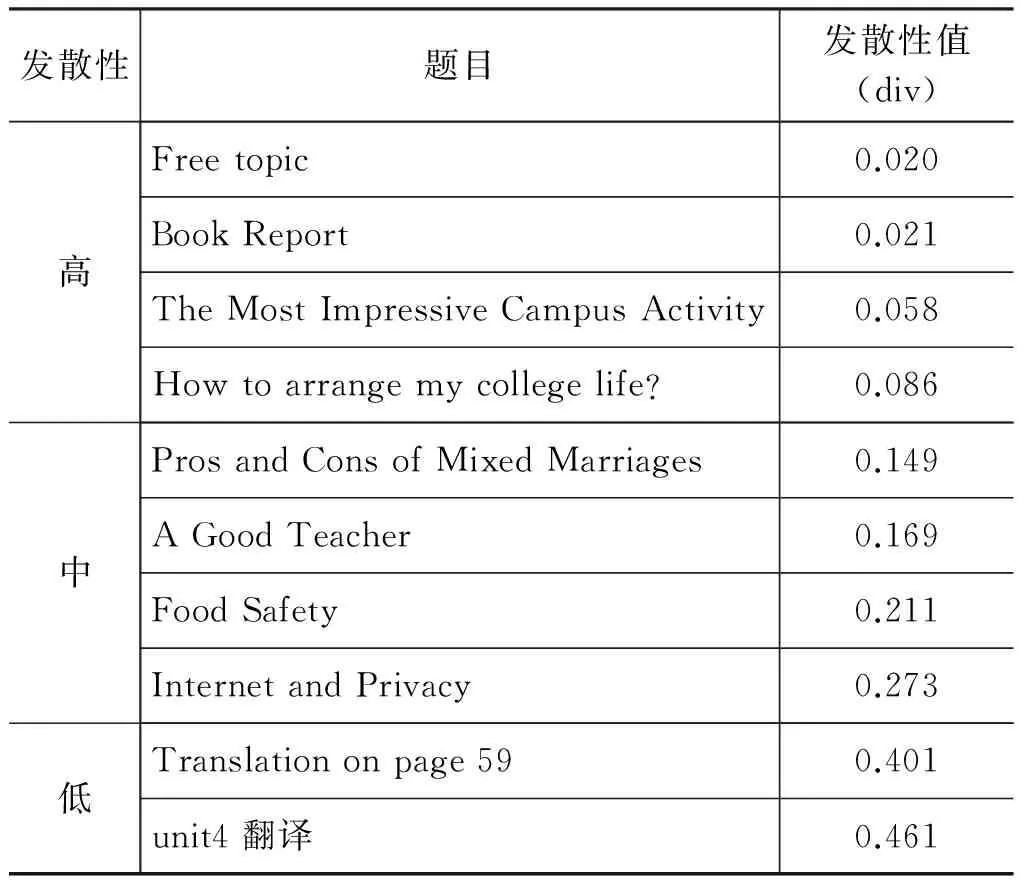
表1 不同发散性值的题目及其发散性值
从表1中我们可以看到:发散性较高的题目,如 “Free topic”、“Book Report”,对应文章集合的发散性值比较低,而发散性较低的题目,如“Translation on page 59”和“unit4 翻译”的发散性值相对来说比较高。
3.2 基于文档发散度的跑题检测
在本文跑题检测任务中,对于每一篇学生提交的文章,需要与范文计算相似度,然后与阈值对比。如果相似度小于阈值,则判断为跑题作文;反之,则为不跑题作文。显然,阈值的选取很关键,本文使用基于文档发散度的方法动态选取阈值。
每个题目下的跑题阈值是不同的,所以很难选取一个固定的经验值作为阈值。通过观察可知:发散性题目下,文章与范文相似度较低,阈值较低。而非发散性题目下,文章与范文的相似度较高,阈值相对而言较高。这意味着跑题阈值和发散性值之间是有联系的,我们假设二者之间存在着线性关系。
本文使用线性回归模型来构造文档发散度值与跑题阈值的关系。线性回归模型反应两种或者两种以上变量之间相互依赖的定量关系,应用十分广泛。
根据以上分析,本文假设发散度值和跑题阈值的关系如式(5)所示。
thresholder=a×div+b
(5)
其中,thresholder表示该题目的跑题阈值,div为该题目下文章的发散度值,a和b是模型的参数。线性回归是一种有监督的学习方法,所以我们需要搜集一定量的样本,对模型进行训练,得到模型参数a和b。构建好线性回归模型后,我们只需要计算出题目下面文章集合的发散性值,就可以根据已经构建好的模型动态地计算出每个文章下面的跑题阈值。
3.3 基于词扩展的文本相似度计算
在计算文章与范文相似度的时候,本文使用基于词扩展的文本相似度计算方法。该方法由chen[1]等人提出,在计算文本相似度的时候利用单词的语义信息,快速有效。
传统的文本相似度计算方法如之前所述,采用基于向量空间模型的TF-IDF方法。基于词扩展的相似度计算方法是对于传统方法的改进:对于某一个文本单词集合,找出其扩展的相似词集合,将其加入到原来的文本集合中,得到新的文本表示集合。在这个新的文本表示集合的基础上,使用TF-IDF方法计算相似度。具体来说:
对于文章D,有文本单词集合d:{w1,w2,w3…wi…wn}。对于任一单词wi,找出与其语义上相近的k个单词集合{vi1,vi2,vi3……vik}。对于d中所有单词,我们都找出它们的相似词集合,得到一个总的相似词集合E={v11,v12…v1k…vi1,vi2……vik}。去除集合E中重复的扩展词,得到最终的扩展集合E′。最后将E′加入到原文本单词集合中,得到最终用于计算的文本表示单词集合。
在计算文章和范文之间相似度的时候,对两篇文章都进行词扩展,然后使用TF-IDF方法计算相似度。
4 实验
4.1 实验数据
本次实验中,我们向合作机构申请了30 111篇不同的文章用于实验,一共400个不同的题目。平均每个题目下有75篇文章。这些题目下文章的平均长度分布如图1所示。

图1 题目下文章的数量的分布
从图1中我们可以看出,这些题目下文章数量都大于50篇,文章数在60~70篇和90~100篇这两个区间的题目占了绝大多数。这些题目下文章的平均字数见图2。
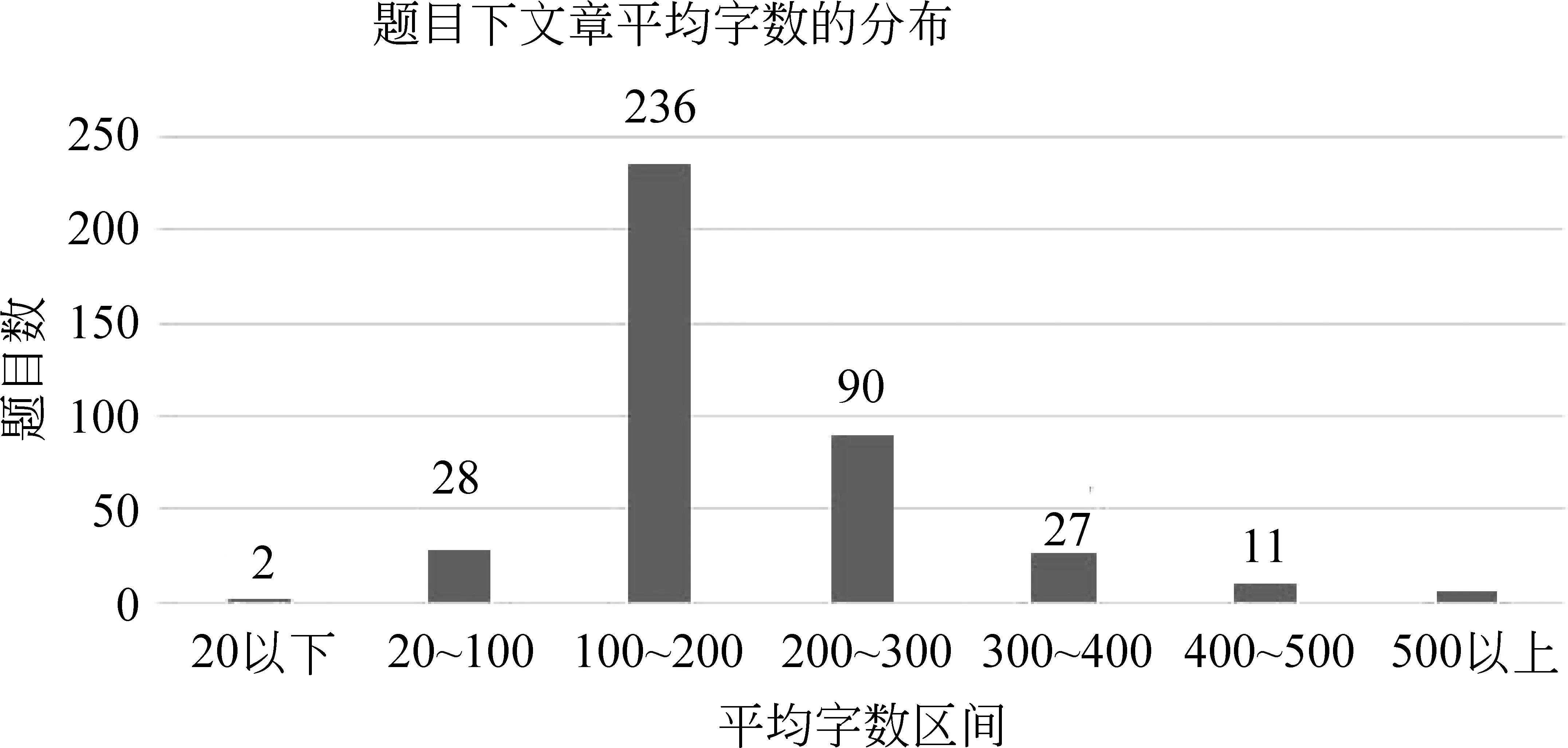
图2 题目下文章平均字数的分布
从图2中可以看出,这些题目下文章的平均字数集中在100~200字的区间。
对于每个题目,我们都进行人工标注,找出其中的跑题文章。为了减少工作量,先用中心向量法找出每个题目下的范文,再计算每篇文章与范文计算相似度。按照评分从低到高进行标注,直到大部分文章都不跑题。不同题目下作文发散性值与跑题文章比例的关系如图3所示。
从图3中可以看出:如果题目下文章的发散性较强或者较弱,即处于上图横轴的两端,这些文章中跑题作文的比例都不高;而发散性中等的(0.2-0.3左右)题目下,跑题文章占的比例相对较高。这符合我们标注时发现的规律:发散性题目下跑题文章的较少。同一性较高的题目下,比如文章翻译,跑题作文的比例也不高。
另外,我们还统计出了发散性值与题目下文章数量的关系,如图4所示。
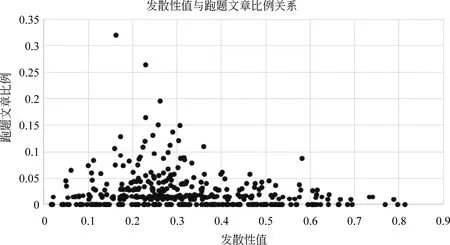
图3 发散性值与跑题文章比例关系
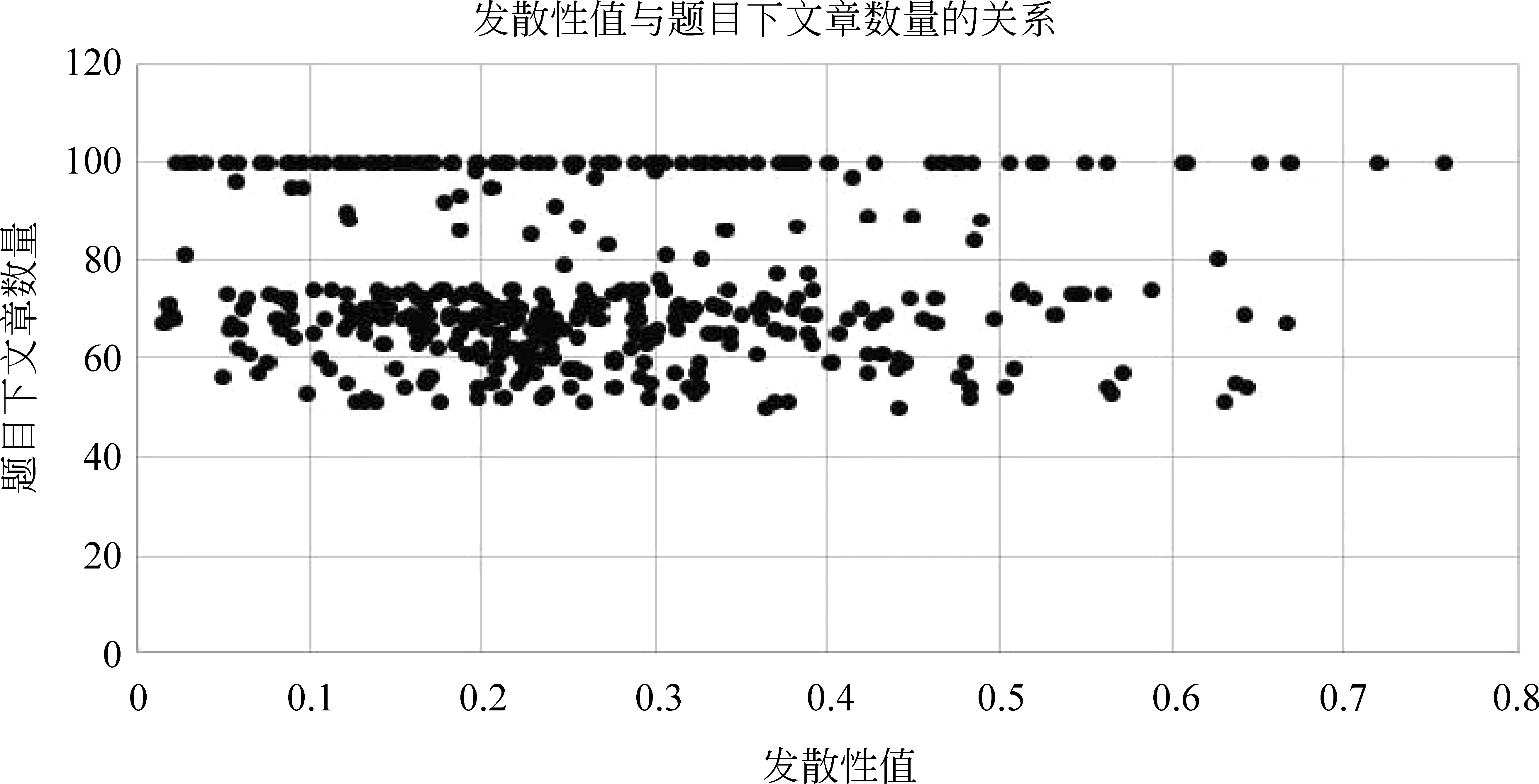
图4 发散性值与题目下文章数量的关系
实验中使用了Google开源的word2vec[16-18]工具包*https://github.com/NLPchina/Word2VEC_java。这个工具包可以根据给定的语料库,通过训练后的模型将词表示成向量形式,并能找出与某个词语义上相近的词。为此,我们又申请了3 209 128篇学生作文作为word2vec的训练语料。同时,这3 209 128篇文章还用来生成词表,以及训练单词的idf值。在生成词表的时候,我们过滤掉了出现次数低于五次的单词,主要是为了过滤掉拼写错误的单词。
为了学习每个题目下跑题阈值和文章发散度的关系,需要一个训练集。每个训练实例为一个题目下的文章发散度和跑题阈值,发散度用之前所述的方法计算,跑题阈值根据人工标注的结果来选取:对题目下所有文章按照系统得分从低到高排序,选取跑题文章中得分最高的文章和它下一篇不跑题文章的得分的均值作为阈值。例如,一个题目下,跑题文章中得分最高的文章分数为0.1,它下一篇文章为不跑题文章,得分0.2,那么阈值就等于(0.1+0.2)÷2=0.15。如果一个题目下没有跑题作文,那么阈值就选取最低得分的一半。
4.2 选取范文
由于实验所使用的题目数量较多,很难人工选取每个题目下的范文。因为这会耗费大量的时间和人力。为此我们采用了中心向量法自动选取范文。
首先,基于向量空间模型,将所有文章表示成向量。同样,使用TF-IDF值作为权重。假设有M篇文章,词表中有n个词,每篇文章表示成如下向量形式:
其中,等号左侧V(Dm)表示第m篇文章的向量形式,右侧是其向量的具体表示,共n维,每一维都是相应单词的TF-IDF值。我们定义中间向量为所有向量相加后和的均值。使用式(6)计算。
(6)
如果把一个文章向量看成向量空间中的一个点,那么中心向量就是这些点的中心。离中心向量的距离最近的文章就可以作为范文。即:

(7)
4.3 实验评价
我们利用准确率(Precision)、召回率(Recall)和F1值来评价系统。将400个题目按照题目分为十份,做十倍交叉验证。每次取其中的一份,共40个题目,作为测试集,其余九份作为训练集。通过训练集训练出阈值和发散度的回归关系模型。测试时,首先计算出每个题目下的文章发散度,然后根据学习好的回归模型求出阈值,找出系统评分小于阈值的文章,假设有N篇,其中K个是正确的判断(即和人工判断一致),设这个题目下所有跑题文章数为M,则:
如果M=0,K=0,说明题目下没有跑题文章,而且预测出结果也是没有跑题文章,那么R=1。每一次测试都计算出测试集的准确率,召回率和F1值。最后求十次实验结果的平均。
4.4 系统实现
在本文提出的方法中,我们使用weka开源工具包*http://www.cs.waikato.ac.nz/ml/weka/学习跑题阈值和文章发散度的线性回归模型参数。
除了本文提出的方法,本次试验还实现了其他两种阈值选取方法用于对比:
• 固定阈值法 该方法来自于陈志鹏等[1]。我们使用训练集选取固定阈值。和其他方法一样,首先用中心向量法找出每个题目下的范文。再使用词扩展方法计算出每篇文章与范文的相似度,作为系统评分。接着选取固定阈值,我们构造一个预测集用于选取阈值。首先按照系统评分对所有文章排序。我们按照得分从低到高选取文章作为预测集。一开始选取得分最低的文章加入到预测集中,然后选取得分第二低的文章加入……以此类推,得到一个个预测集。我们计算出预测集召回率为0.1,0.2,0.3…1.0时的F1值,F1值最大时说明这时候预测集判断的效果最好。取此时预测集中跑题文章得分的最大值作为固定阈值。找到固定阈值后,对测试集中所有文章均使用此阈值进行判断。
• 估计阈值法 这个方法和本文提出的动态选取阈值的方法大体一致。唯一的不同点是训练时没有通过人工标注来获得每个题目的阈值,而是采用了一种估计的方法判断文章是否跑题。首先在训练集中随机选取20个题目进行人工标注,得到里面跑题文章的集合。计算出跑题文章所占的百分比,比如0.01。假设所有题目下跑题文章都占该比例,计算出题目下跑题文章的数量,以此估计出跑题的文章。例如,题目下有100篇文章,那么估计有100×0.01=1篇文章跑题,即认为系统得分最低的一篇文章是跑题作文。用这个方法估计出训练集中每个题目下文章的阈值。然后和动态选取阈值的方法一样,训练出阈值与发散度的关系曲线,使用测试集进行测试。这个方法的优点是省时省力,不需要标注太多题目。
4.5 实验结果
我们首先用测试集中所有文章来进行测试,十倍交叉验证,取平均值作为最后结果。表2是实验结果,所有实验中词扩展的数目为3,即每个词扩展三个词。

表2 实验结果(测试集中所有题目)
从结果中我们看到基于发散度的动态阈值法效果最好;固定阈值法效果次之,十次实验中固定阈值平均在0.1附近;效果最不好的是估计阈值法。估计阈值法是动态阈值法的简化版本,比较简单,效果和我们的方法比有明显差距。
测试集有一些题目没有跑题作文,这部分题目占题目总数的31%。我们针对这个情况做了具体分析。如果考虑测试集中有跑题文章的题目,而不考虑没有跑题文章的题目,实验结果如表3所示。
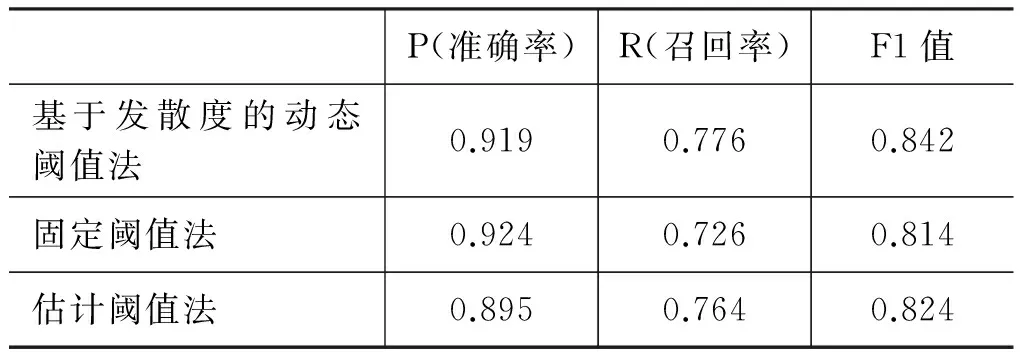
表3 实验结果(只考虑有跑题文章的题目)
从表3可以看出,只考虑有跑题文章的题目时,选取动态阈值的方法效果要比选取固定阈值的方法好。基于发散度的动态阈值法比固定阈值法高出3个百分点,效果最好。固定阈值法和估计阈值法效果差不多。固定阈值的方法准确率较高,估计阈值法召回率较高。
结合表2和表3还可以看出,固定阈值方法的变化幅度较大,F1值降低了四个百分点;而选取动态阈值的方法变化却不是很大,这说明动态选取阈值的方法有着较好的稳定性。在判断有跑题文章的题目时,动态选取阈值的方法性能要明显优于固定选取阈值的方法。
最后,我们对实验结果做进一步分析,研究题目发散性和F1值之间的关系。我们将所有题目按照文章的发散性值由低到高排序,分为五份,每份80个题目,第一份到第五份的平均发散性值依次增高。在发散性最强的1区间中,有31个题目没有跑题文章,占区间总体的38%。计算每份的平均F1值。结果如图5所示。
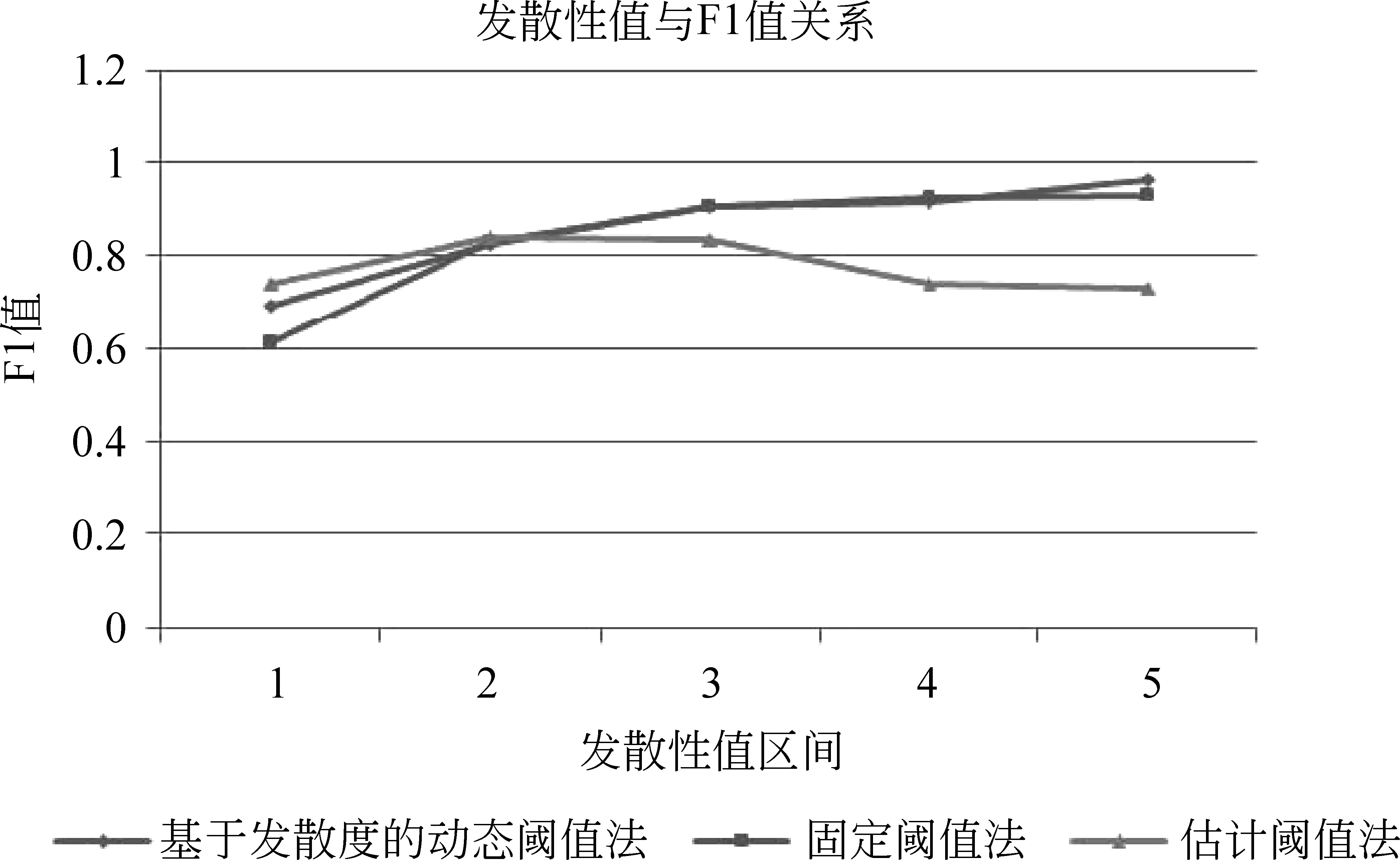
图5 发散性值与F1值关系
从图中可以看出,在面对发散性较强的题目时选取动态阈值的方法比固定阈值法的性能好。随着题目发散性逐渐变弱,估计阈值法的F1值明显下降,其他两种方法的F1值都不断上升。总体来看,对于发散性较强和较弱的两种题目,基于发散度动态选取阈值的方法要好于固定阈值的方法,而对于发散性一般的题目,两种方法差距并不明显。
综上所述,基于发散度选取动态阈值的方法性能最好。处理有跑题作文的题目时,该方法明显好于固定阈值的方法。面对发散性较强的题目时,该方法性能也优于固定阈值的方法。
5 总结和展望
本文构造了一个跑题检测系统,相对于传统选取固定阈值的方法,该方法的创新之处是基于文档发散度动态地选取阈值,从而判断文章是否跑题。经过实验比较,该方法在面对有跑题文章的题目时,尤其是发散性较强的题目时,性能明显优于固定选取阈值的方法。作文跑题检测还有许多研究空间,比如如何更加准确地对发散度较高的题目进行检测等,还有许多方向可以进一步研究。
[1] 陈志鹏,陈文亮,朱慕华.利用词的分布式表示改进作文跑题检测[J].中文信息学报,2015,29(5):178-184.
[2] A.Huang.Similarity measures for text document clustering[C]//Proceedings of the New Zealand Computer Science Research Student Conference,2008:44-56.
[3] Kumar N.Approximate string matching algorithm[J].International Journal on Computer Science and Engineering,2010,2(3):641-644.
[4] Coelho T A S,Calado P P,Souza L V,et al.Image retrieval using multiple evidence ranking[J].IEEE Trans on Knowledge and Data Engineering,2004,16(4):408-417.
[5] Koy,Park J,Seo J.Improving text categorization using the importance of sentences[J].Information Processing and Management,2004,40(1):65-79.
[6] Theobald M,Siddharth J,SpotSigs:robust and efficient near duplicate detection in large web collection[C]//Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.New York:ACM Press,2008:563-570.
[7] Christopher D Manning,Prabhakar Raghavan,Hinrich Schütze,Introduction to Information Retrieval[M].Cambridge University Press,2008:83-84.
[8] Miller G.Wordnet:An On-line Lexical Database[J].International Journal of Lexicography,1990,3(4):235-244.
[9] 颜伟,荀恩东.基于WordNet的英语词语相似度计算[C].计算机语言学研讨会论文集.2004:89-97.
[10] 朱嫣岚,闵锦,周雅倩,等.基于HowNet的词汇语义倾向计算[J].中文信息学报,2006,20(1):14-20.
[11] Page E B.Project Essay Grade:PEG[A].In Shermis M D &Burstein J C (eds.).Automated Essay Score:A Cross-Disciplinary Perspective[C]//Proceedings of the NJ:Lawrence Erlbaum Associates,2003:43-54.
[12] Landauer T K,Laham D,Foltz P W.Automated essay scoring and annotation of essays with the Intelligent Essay Assessor.Shermis M D,Burstein J C (eds.).Automated Essay Scoring:A Cross-Disciplinary Perspective[C]//Proceedings of the NJ:Lawrence Erlbaum Associates,2003:87-112.
[13] Burstein J.The E-rater Scoring Engine:Automated essay scoring with natural language processing.In Shermis M D,Burstein J C (eds.).Automated Essay Scoring :A Cross-Disciplinary Perspective[C]//Proceedings of the NJ:Lawrence Erlbaum Associates.2003 :113-121.
[14] A Louis,D Higgins.Off-topic essay detection using short prompt texts[C]//Proceedings of the NAACL HLT 2010 Fifth Workshop on Innovative Use of NLP for Building Educational Applications,Los Angeles,California,2010:92-95.
[15] 葛诗利,陈潇潇.文本聚类在大学英语作文自动评分中应用[J].计算机工程与应用,2009,45(6):114-121.
[16] Tomas Mikolov,Kai Chen,Greg Corrado,et al.Efficient Estimation of Word Representations in Vector Space[C]//Proceedings of Workshop at ICLR,2013.
[17] Tomas Mikolov,Ilya Sutskever,Kai Chen,et al.Distributed Representations of Words and Phrases and their Compositionality[C]//Proceedings of NIPS,2013.
[18] Tomas Mikolov,Wen-tau Yih,Geoffrey Zweig.Linguistic Regularities in Continuous Space Word Representations[C]//Proceedings of NAACL HLT,2013:746-751.
Off-topic Essays Detection Based on Document Divergence
CHEN Zhipeng1,2,CHEN Wenliang1,2
(1.School of Computer Science and Technology,Soochow University,Suzhou,Jiangsu 215006,China; 2.Collaborative Innovation Center of Novel Software Technology and Industrialization,Suzhou,Jiangsu 215006,China)
Off-topic detection is important in the automated essay scoring systems.Traditional methods compute similarity between essays and then compare the similarity with a fixed threshold to tell whether the essay is off-topic.In fact,the essay score is heavily dependent on the type of topic,e.g.the essay score for divergent topic ranges very different from that of non-divergent topic.This prevents fixed threshold to identify off-topic for all essays.This paper proposes a new method of off-topic detection based on divergence of essays.We study the divergence of essays,and establish the linear regression model between divergence and threshold.Our method is featured by a dynamic threshold for each topic.Experimental results show that our method is more effective than baseline systems.
off-topic detection; document divergence; document similarity

陈志鹏(1991—),硕士研究生,主要研究领域为自然语言处理。E-mail:chenzhipeng341@163.com陈文亮(1977—),博士,通信作者,主要研究领域为自然语言处理。E-mail:wlchen@suda.edu.cn
1003-0077(2017)01-0023-08
2016-09-10 定稿日期:2016-10-20
国家自然科学基金(61572338)
TP391
A
