基于RGB-D图像核描述子的物体识别方法
2017-04-17骆健,蒋旻
骆 健,蒋 旻
(1.武汉科技大学 计算机科学与技术学院,武汉 430065; 2.智能信息处理与实时工业系统湖北省重点实验室(武汉科技大学),武汉 430065)
(*通信作者电子邮箱345467866@qq.com)
基于RGB-D图像核描述子的物体识别方法
骆 健1,2,蒋 旻1,2*
(1.武汉科技大学 计算机科学与技术学院,武汉 430065; 2.智能信息处理与实时工业系统湖北省重点实验室(武汉科技大学),武汉 430065)
(*通信作者电子邮箱345467866@qq.com)
针对传统的颜色-深度(RGB-D)图像物体识别的方法所存在的图像特征学习不全面、特征编码鲁棒性不够等问题,提出了基于核描述子局部约束线性编码(KD-LLC)的RGB-D图像物体识别方法。首先,在图像块间匹配核函数基础上,应用核主成分分析法提取RGB-D图像的3D形状、尺寸、边缘、颜色等多个互补性核描述子;然后,分别对它们进行LLC编码及空间池化处理以形成相应的图像编码向量;最后,把这些图像编码向量融合成具有鲁棒性、区分性的图像表示。基于RGB-D数据集的仿真实验结果表明,作为一种基于人工设计特征的RGB-D图像物体识别方法,由于所提算法综合利用深度图像和RGB图像的多方面特征,而且对传统深度核描述子的采样点选取和紧凑基向量的计算这两方面进行了改进,使得物体类别识别率达到86.8%,实体识别率达到92.7%,比其他同类方法具有更高的识别准确率。
RGB-D图像;物体识别;局部约束线性编码;核描述子;空间池化
0 引言
基于机器视觉的物体识别是模式识别领域一个方兴未艾的研究方向。目标物体的特征提取是其中的关键技术之一。从物体的RGB图像中可以提取代表该物体的颜色、纹理和轮廓等特征,但那些从RGB图像中提取的特征易受光照变化、阴影、视角等因素的干扰[1]。现在,有很多相机能快速获取带深度信息的RGB(RGB-Depth, RGB-D)图像,其中,深度图像记录的是场景上各点与相机之间的距离信息,能直接反映物体表面的三维特征,是对RGB图像信息的有效补充。因此,基于RGB-D图像信息的RGB-D物体识别已成为计算机视觉领域近年来的一个研究热点。已有的相关研究大体可以归纳为以下两大类。
1) 基于特征自动学习的方法。
特征学习,采用深度学习[2]中的不同网络结构,通过无监督或有监督的训练,使得网络能自动学习图像的有效特征。其中,文献[3-5]虽在RGB-D物体识别方面都取得了比较好的识别效果,但此类基于特征自动学习的深度学习算法往往计算量很大,对计算机的硬件条件要求较高。
2) 基于人工设计特征提取及表达的方法。
根据先验知识进行人工设计特征提取,再采用词袋(Bag Of Feature, BOF)[6]和空间金字塔匹配(Spatial Pyramid Matching, SPM)[7]方法进行特征表达,是近年来的一个研究热点。Silberman等[8]同时提取RGB图像和对应深度图像的尺度不变特征变换(Scale-Invariant Feature Transform, SIFT)特征,在RGB-D场景分类中取得了不错效果。Bo等[9]提出的分层匹配追踪(Hierarchical Matching Pursuit, HMP)算法;Blum等[10]提出了卷积K均值描述算子;Jin等[11]结合人工设计特征及机器学习算法等,在RGB-D物体的目标识别方面均取得了很好的性能。
但是,上述大部分传统的人工设计特征提取的方法应用于RGB-D图像识别时,仍采用RGB图像的特征获取方法对深度图像进行底层特征提取,忽视了深度图像所特有的3D几何局部特性。为了克服这个缺点,本文采用核描述子方法[12]来提取深度图独有的底层特征。针对深度图像的底层特征提取,在文献[12]基础上,Bo等[13]提出了深度核描述子方法。该方法克服了传统深度特征依赖视角的缺点,大大提高了在单一视角的条件下对象的识别精度,但其深度核描述子的计算仍存在如下缺陷。
1) 等间隔采样导致某些采样点无效,从而影响该点局部特征向量的计算。
2) 对均匀密集采样的基向量执行核主元分析(Kernel Principal Component Analysis, KPCA)得到的紧凑基向量,无法获知其中最具代表性的样本,继而影响核描述子特征表示的能力。
为了克服以上缺点,本文首先对传统深度核描述子的采样点选取和紧凑基向量的计算这两方面均进行相应的改进,以强化核描述子的特征表示能力。其次,在此基础上,提出了一种基于核描述子编码的RGB-D物体识别方法,该方法从图像颜色、边缘、形状、大小等不同方面分别提取RGB图像及深度图像的核描述子底层特征,不同核描述子经局部约束线性编码(Locality-constrained Linear Coding, LLC)[14]和空间池化处理后形成图像特征,再通过串行融合,生成的最终图像描述更加鲁棒,更加具有区分性。因此,相较于已有的方法[10,13-16],本文提出的核描述子编码算法,在物体识别性能方面取得了显著性的提高。
1 核描述子的局部特征提取
在对象识别任务中,最关键的步骤之一是计算不同图像(块)的相似度。最常用的方法,是以图像小块(如8×8的patch)为单位,将图像块内像素的局部特征向量用直方图等量化方式统计出来,再通过计算两块之间的特征向量内积得到彼此的相似度,这种特征表达由于计算量小,简便易行,得到了广泛的应用,但此方式存在量化误差。
近年来,文献[12-13]提出在计算图像块相似度时引入核方法(称为匹配核),用连续空间的核函数来代替分箱的冲激函数,来避免上述方法在特征离散化时带来的量化误差。该方法用匹配核求出两个图像块上所有像素某连续特征值之间的距离,然后再求距离的平均值,得到的结果即为图像块的相似度[12]。
匹配核提供了一种能更精确计算图像块的相似度的方法,更重要的是该方法还提供了一种高效的策略从匹配核中直接计算单个局部特征,这种策略计算得到的局部特征称为核描述子。
计算核描述子有3个步骤:1)设计合适的匹配核,以某种测度(如梯度、颜色等)来测量图像块之间的相似度;2)计算匹配核的低维表达,得到能近似表达匹配核的低维基向量组;3)通过将局部特征向量投影到基向量组所表达的特征空间上,得到核描述子。
在此基础上,Bo等[13]提出深度核描述子,虽在RGB-D图像识别方面取得了不错效果,但其中尺寸核描述子(Size Kernel Descriptor, Size-KD)和Spin核描述子(Spin Kernel Descriptor, Spin-KD)的计算仍存在以下缺陷:1)在计算Size-KD或Spin-KD时,从对象点云中选择一定数量的点作为参考点,这些参考点组成一个子点云。子点云是原始对象点云的一种近似采样,这种采样应该尽可能地反映原始对象点云的分布。Bo等[13]对对象点云图进行等间隔均匀采样以生成子点云,当遇到采样点在深度值小于0时,将该点标记为“无效”,不对其进行采样。在实验中,研究发现,有大量样本在采样过程中标为“无效”,进而影响了该采样点局部特征向量计算的准确性。2)在计算Size-KD或Spin-KD时,需生成紧凑基向量组,Bo等[13]采取对均匀密集采样的基向量执行KPCA的方式获取紧凑基向量组,这种方法假定原始基向量空间中样本数据均匀分布,没有考察哪些样本最具代表性,因而导致无法更有效地降低核描述子特征维度。
针对以上缺陷,本文提出了一种改进的尺寸核描述子(Size-KD)和Spin核描述子(Spin-KD)描述子。与Bo等[13]相比,本文算法有两点改进:第一,将对象点云图等间隔划分若干个子区域,选取每个子区域中深度值最大的点作为参考点,以此方式生成子点云,既能满足均匀采样原则,又能在一定程度上降低生成无效采样点的概率。实验验证表明,本算法的无效采样点占有率较前者降低了5%~11%。第二,在计算紧凑基向量时,本文算法通过训练的方式学习特征空间中样本数据的分布规律,以便更有效地降低特征维度。
为了使RGB-D物体的图像特征表示更加全面,本文除了采用改进的Size-KD以及Spin-KD外,还结合了文献[12-13]中提出的梯度核描述子(Gradient Kernel Descriptor, Gradient-KD)、局部二值模式核描述子(Local Binary Pattern Kernel Descriptor, LBP-KD)、颜色核描述子(Color Kernel Descriptor, Color-KD),分别从边缘、颜色、尺寸和形状多个方面表达RGB图像(深度图像)的局部特性。再对上述核描述子采取LLC特征编码,即可得到不同的图像表述,进而完成RGB-D图像物体的识别。
由于篇幅所限,本文只对改进的尺寸核描述子的计算过程进行全面的阐述,对于其他核描述子,只介绍匹配核的设计过程,它们匹配核的低维表达和特征向量映射的过程和尺寸核描述子相似,所以不加赘述。
1.1 尺寸核描述子
尺寸核描述子(Size-KD)根据深度图像转化的3D点云获取对象的物理尺寸大小信息。由于不同对象实体都有特定的大小,因此对象的物理尺寸信息对于物体识别非常重要。为此,需要先将深度图像的每个像素投影到对应的三维坐标向量中以此形成3D点云,再计算每个点到点云中给定参考点之间的距离,以此获取对象的尺寸大小信息。其尺寸相似度匹配核函数:
(1)
由此,改进的尺度核描述子的计算流程如下。
步骤1 采样生成子点云。根据式(2)对深度图进行间隔采样,生成子点云r。其中:ri、Pi分别为第i个正方形网格中子网格内的采样点和所有点集合,Nsub为子网格数,z(x)为x点的深度坐标。
r={ri|z(ri)=max{z(Pi)},i∈[1,Nsub]}
(2)

Dri={dj|dj=DistC(qj,ri),j∈[1,N],i∈[1,Nsub]}
(3)
步骤3 计算尺度特征向量均值Fsize(ri)。计算Dri中每个尺度元素的尺度匹配核,并由式(4)求出均值Fsize(ri)。其中尺度匹配核函数ksize(·)见式(1)定义,bd=[b1,b2,…,bNd]为尺度属性值域上均匀密集采样后得到的尺度基向量。

(4)
步骤4 计算紧凑基向量组Esize。根据式(5),计算Esize,其中Fsize为训练集中每张点云图获取的采样点经式(4)得到Fsize(ri)的集合,紧凑基向量组Esize是通过对Fsize执行KPCA,然后选取前Dim个主元后得到的特征向量。
Esize=Kpca(Fsize,Dim)
(5)
步骤5 计算采样点ri的尺度核描述子SIZE_KD(ri)。由式(6),将采样点ri的Fsize(ri)投影到Esize所表达的特征空间上,即得SIZE_KD(ri):
SIZE_KD(ri)=Esize×Fsize(ri)
(6)
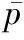
1.2 梯度核描述子
梯度核描述子(Gradient-KD)获取RGB图像(深度图像)的边缘信息。主要由使用梯度幅值来权衡每个像素影响的归一化线性核、计算梯度方向相似度的方向核以及衡量像素间空间紧密度的位置高斯核构成,两个图像块间相似度函数由式(7)给出:
(7)
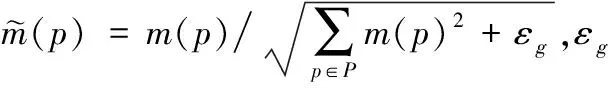
ks(p,q)=exp(-γs‖p-q‖2)
(8)
1.3 局部二值模式核描述子
局部二值模式核描述子(LBP-KD)获取RGB图像(深度图像)的局部边缘信息。在3×3的窗口内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3×3邻域内的8个点可产生8维的二进制的列向量b(p),结合衡量其边缘相似度的高斯核函数kb,得到核函数:
(9)
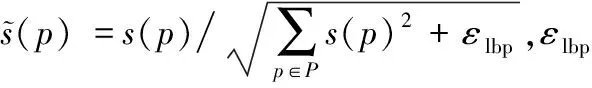
1.4 颜色核描述子
颜色核描述子(Color-KD)获取RGB图像的外观颜色信息。在像素值基础上,构造的颜色匹配核函数如下:
(10)
其中:c(p)表示位置p像素的颜色值;kc与ks为衡量像素值相似度及像素点位置的高斯核函数。
1.5 Spin核描述子
Spin核描述子(Spin-KD),根据深度图像转化的3D点云获取对象的3D形状信息。而“SpinImage”[17]是一种影响较大的三维物体局部形状描述子,已成功应用于三维目标识别、表面匹配等多项任务。若给定三维目标表面的一个有向点p*,过该点的法向量为n*,切平面为T,以(p*,n*)表示该点属性,则目标表面上的其他任意点p∈P的属性表示(p,n)可以通过[ηp,ξp,βp]给出,则有:
(11)
其中:ηp表示点p到切平面T的有向垂直距离;ξp表示p到法向量n*的垂直距离;βp为法线n与n*之间的角度。通过式(12)旋转核函数将像素点属性[ηp,ξp,βp]转化图像的局部形状特征。
(12)
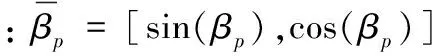
2 局部约束线性编码
用X表示从一幅图像中提取的D维的特征描述子集合,如X=[x1,x2,…,xN]∈RD×N,其中xi∈RD是X中第i个描述子。B为字典,包含M个元素,即B=[b1,b2,…,bM]∈RD×M。利用字典B对每个特征描述子xi进行重构,可以表示为:xi≈Bci,可采用不同编码方式得到对应的ci∈RM。
局部约束线性编码(LLC),是在稀疏编码(SPMbasedonSparsecodes,ScSPM)[18]、局部坐标编码(LocalCoordinateCoding,LCC)[19]等线性编码方法的基础上的再次改进,利用局部约束将每个描述子投影到其局部坐标系统中,在保证稀疏性的同时又解决了ScSPM方法计算复杂度高等问题。其基本思想为:对于待编码的特征描述子xi,使用距离xi最近的k个字典元素的线性组合表达该特征描述子,其中k远小于字典元素的个数M(k≪M),其优化目标函数为:
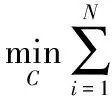
(13)
s.t. 1Tci=1,∀i
其中:B为学习得到的字典;ci为待优化的特征的编码系数;λ为LLC中的惩罚因子;⊙表示对应元素相乘;di表示可为每个基向量分配不同自由度的局部性适配器,所分配的自由度与其和输入描述子xi的相似性成正比。1表示全部元素为1的向量,约束条件1Tci=1保证编码的平移不变性,局部正则化项‖di⊙ci‖2能够确保相似的特征描述子具有相似的编码。Yu等[19]理论上认为,在某些情况下局部性比稀疏性更重要,因为满足特征的局部性约束必然能够满足特征的稀疏性,反之却未必。稀疏性约束旨在保证重构性的前提下使编码系数L0范数尽可能小,而LLC的局域性约束则是使用距离特征最近的字典元素表达特征,因此该特征的稀疏表达具有更强的区别力。
3 基于KD-LLC的RGB-D物体识别
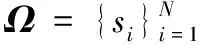
此外,为了获取物体类的不同数据结构,本文采取最常用的K-means聚类算法对训练图像集特征聚类,生成LLC中的视觉字典B。
本文算法的训练阶段的流程简述如下(由于各个描述子的处理过程类似,所以训练过程中1)~3)步骤以尺寸核描述子(Size-KD)为例说明),对应图1中的实线步骤①②③④⑤⑥。

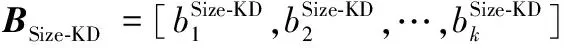
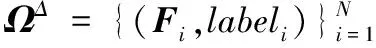
5)训练分类器(对应图中实线步骤⑥)。基于训练集ΩΔ,用SVM算法训练得到图像分类器。

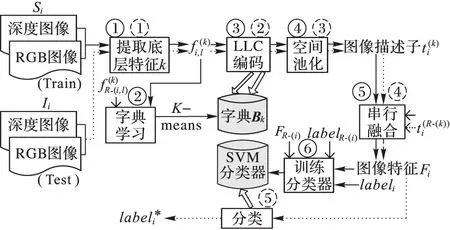
图1 基于核描述子编码的RGB-D图像物体识别方法流程
4 实验及结果分析
4.1 RGB-D数据库
本文实验采用Lai等[15]公布的具有多分类多层次多视角的RGB-D数据库。其中,该数据库包含51个不同类别的家用物品和300个这些类别的实体,每个对象实体均含有从3个不同的水平视角高度(30°、45°和60°)进行360°旋转获取的图像,使得数据集包含将近250 000张RGB-D图像。通过对每个实体中的图像以每5帧的间隔进行抽样,最终得到41 877张RGB图像以及对应的深度图像。图2展示了用于实验的RGB-D数据集中每个类别的物体。

图2 RGB-D数据库中实体图像
4.2 实验过程
本文实验的设置与Lai等[15]保持一致,包括类别和实体的识别。首先,对于类别识别,从数据集的每一个类别中随机抽取1个实体对象用作测试,保留下来的作为训练集。随机实验10次,取其平均值作为类别识别精度和标准偏差的最终结果。其次,对于实体的识别,数据集中的所有实体对象选取30°和60°图像作为训练集,45°作为测试集。实验中对于提取Gradient-KD、LBP-KD和SIFT,需先将图像都转换为灰度图([0,1]),对于Color-KD图像的RGB值也需标准化([0,1]),并在保持原图像的高宽比例不变的前提下调整每幅图像的大小在300像素×300像素内,将图像按照每8像素划分为16像素×16像素的patch块。从每个patch块中分别提取描述子,得到每个Gradient-KD、LBP-KD及Color-KD特征是D=200维的向量,SIFT特征为D=128维向量。对于Size-KD提取,其中每个参考点,在3D点云中与之计算的采样点的数量不超过256,而Spin-KD则设定参考点的周围局部区域半径为0.4 cm并且采样的邻近点的数目不超过200。得到每个Size-KD特征是D=50,Spin-KD是D=200向量。紧接着在字典学习的过程中,字典大小设置为M=256,由于从整个数据集上提取的各个描述子的特征数目庞大,全部用于字典学习耗费时间太长,实验中分别对每种描述子随机采样20万个特征作为训练数据。进行LLC操作,在获得每个描述子的编码后,应用SPM将每幅图像在空间划分为三层,每层的子区域数目分别为4×4、2×2、1×1。然后,每层子区域使用最大池化算法[12]后拼接起来获得该层的编码,最后在层与层之间同样使用拼接的操作,这样就得到每幅图像在该核描述子下池化后的编码向量表示,即为:M×L=256×21维的向量。将此些向量进行相应串联融合得到RGB特征、Depth特征以及融合二者的RGB-D特征,最终使用liblinear工具包[20]对RGB-D特征进行线性分类。
4.3 实验结果比较
Bo等[13]通过采用金字塔高效匹配核(Efficient Match Kernel,EMK)[21]将核描述子聚集成对象级的高级特征,在RGB-D图像分类问题上已经取得了不错分类结果。针对Bo等[13]计算Size-KD与Spin-KD存在的缺陷,本文提出了改进的Size-KD与Spin-KD,以及在此基础上的核描述子编码算法。对于核描述子改进前后,本文与Bo等[13]识别结果如图3所示。
从图3(a)和(b)可以看出,相较于Size-KD与Spin-KD,改进的Size-KD与Spin-KD在类别及实体识别上均可取得更好的识别效果。对于单独的深度图核描述子特征、将深度图的核描述子特征融合及将RGB图核描述子融合后的特征的识别结果如表1所示。
从表1的实验效果对比可以看出,对于深度图像,本文提出的方法虽在某些单独核描述子的识别率上稍低于Bo等[13],但总体而言,融合这些特征后的深度图像的识别与其相差不大。关键是在RGB图像识别方面,有了较大的提升,尤其是在实体识别方面更加地明显。与Bo等[13]相比,在融合RGB图像的边缘和颜色特征后,本文在类别识别方面提高了3.09%,实体识别方面提高了17.05%。额外加入SIFT特征后,识别效果还能得到进一步提升。表2显示了本文及传统的基于人工设计特征提取算法在RGB图像、深度图像和结合二者特征的RGB-D图像方面的物体识别准确率。
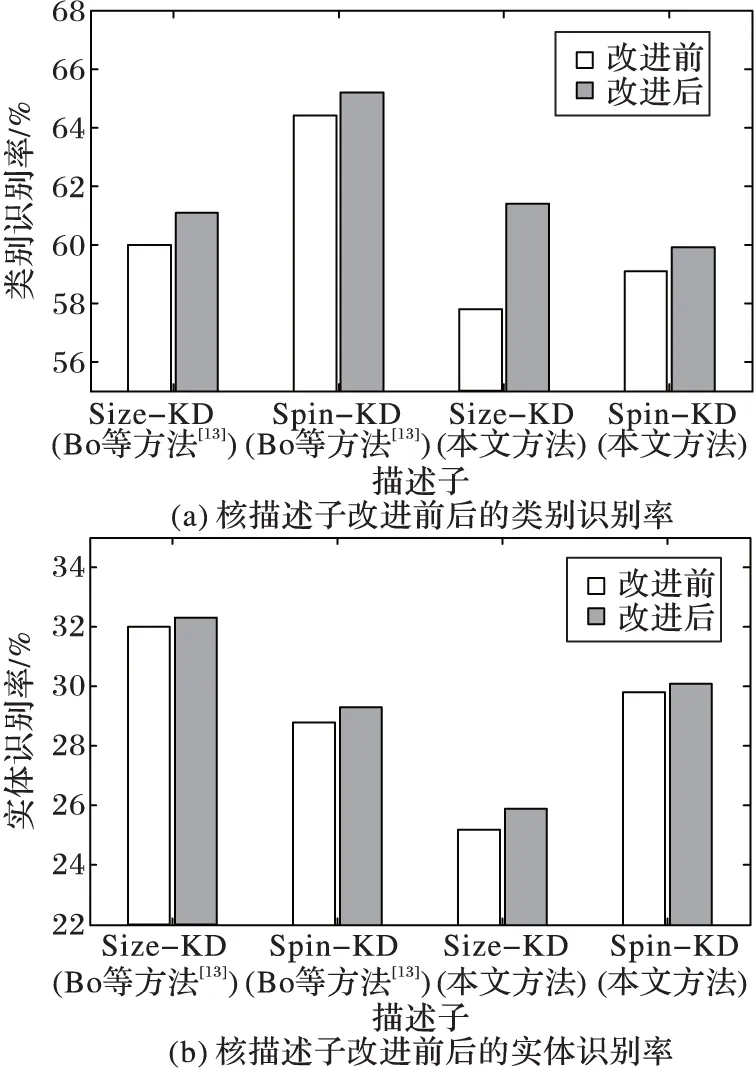
图3 核描述子改进前后识别率对比
表1 核描述子识别效果对比 %
Tab.1 Recognition accuracy comparison of different kernel descriptors %
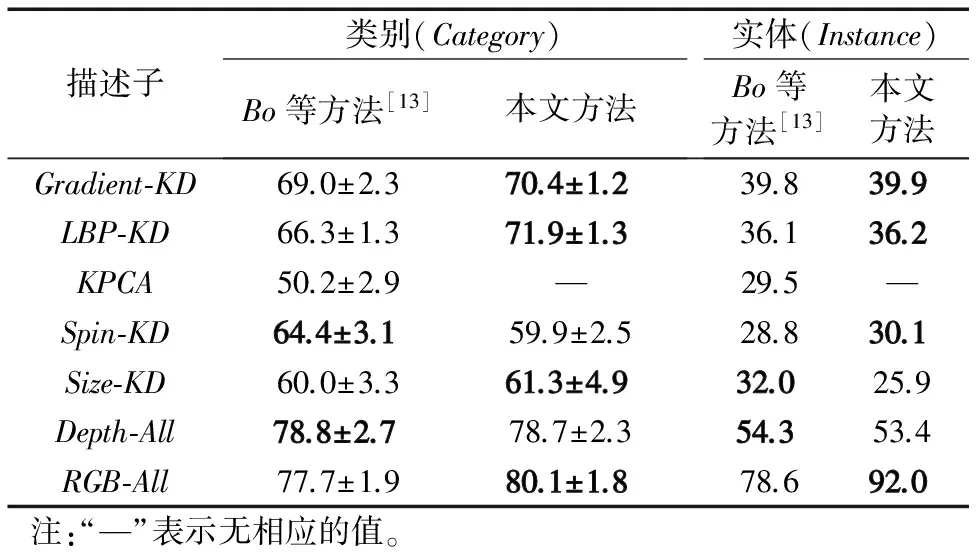
描述子类别(Category)Bo等方法[13]本文方法实体(Instance)Bo等方法[13]本文方法Gradient⁃KD69.0±2.370.4±1.239.839.9LBP⁃KD66.3±1.371.9±1.336.136.2KPCA50.2±2.9—29.5—Spin⁃KD64.4±3.159.9±2.528.830.1Size⁃KD60.0±3.361.3±4.932.025.9Depth⁃All78.8±2.778.7±2.354.353.4RGB⁃All77.7±1.980.1±1.878.692.0注:“—”表示无相应的值。
不难看出,在类别识别和实体识别中,RGB特征相对而言比深度特征更为有用。此外:由于深度特征能直接描述物体的外在轮廓信息,因此在物体的类别识别中效果较好;RGB特征能突出物体的细节信息,所以在更为详细的实体识别中,表现明显优于深度特征;而RGB-D特征综合了二者的优势,识别的准确率最高。
相较于先前的传统方法,本文提出的方法,虽在深度特征识别方面,准确率稍低于Bo等[13],但在RGB以及RGB-D特征识别方面,均达到最好的识别效果。而且在实体识别方面优势更加地明显。
4.4 误差分析
图4展示了本文方法在RGB-D数据集上类别分类时产生的混淆矩阵。其中混淆矩阵的y轴表示数据集的真实类别标签,x轴表示预测的类别标签。混淆矩阵对角线上元素的值代表本文方法在各类别上平均分类识别率,第i行j列的元素表示的是将类别i的图像误分类到j类别上的百分比。从图4中不难看出,本文提出的基于核描述子编码,从RGB-D图像中提取多个互补特征进行融合的分类识别方法取得了非常好的效果。其中,唯有球类(2-ball)与蘑菇类(32-mushroom)分类错误,误将球类(2-ball)、蘑菇类(32-mushroom)识别为大蒜类(21-garlic)。

表2 方法识别结果比较 %
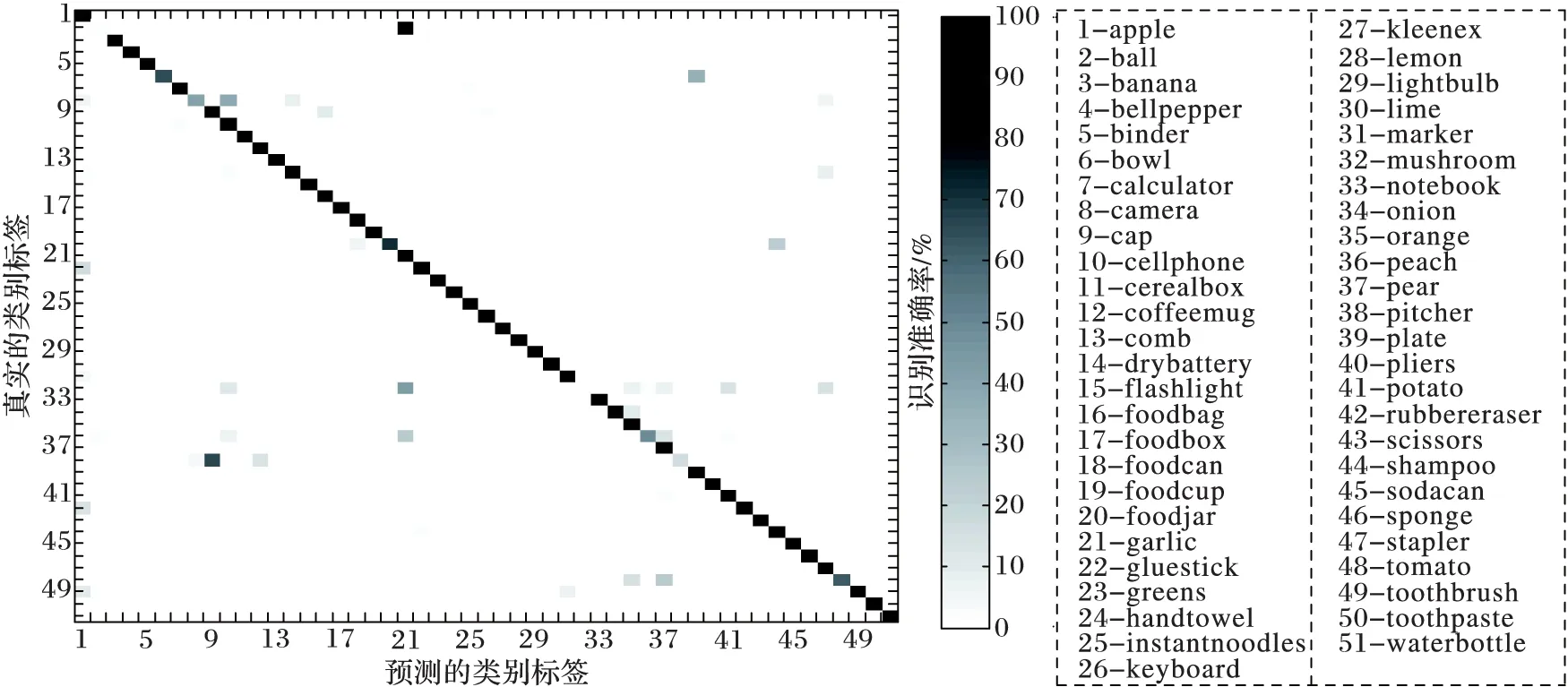
图4 基于核描述子编码的RGB-D图像物体识别模型的混淆矩阵
图5(a)展示了本文方法识别效果差且容易混淆的类别。其中,球与大蒜、帽子(9-cap)与水壶(38-pitcher)、大蒜与蘑菇它们在颜色和外形轮廓等方面都非常相似,从而导致分类出现了偏差。而在实体识别方面,虽取得了很好的效果,但仍存在细微的识别误差,如图5(b),可以看出,对于在颜色、大小、轮廓等特征极度相似,肉眼也不能清晰地分辨同一类别不同实体对实验的识别效果产生了影响,如能加以改进,识别率将在此基础上可进一步提高。

图5 易混淆的类别及实体
5 结语
本文采用RGB-D数据库,结合物体的RGB图像和深度图像信息,提出了基于核描述子编码的RGB-D图像物体识别方法。该方法生成的图像表示融合了RGB-D图像多方面特征信息,可有效解决因图像特征学习不全面而带来的识别效果差等问题。实验结果分析表明,与单独使用RGB图像和深度图像相比,结合RGB图像特征和深度图像特征能有效提高物体识别的准确率,有效地完成多分类物体的识别。同时,该方法在单个核描述子的识别精度方面仍需进一步改进,如何设计更加合理、有效的匹配核函数将是下一步研究的方向。
)
[1] 黄晓琳,薛月菊,涂淑琴,等.基于压缩感知理论的RGB-D图像分类方法[J].计算机应用与软件,2014(3):195-198.(HUANGXL,XUEYJ,TUSQ,etal.RGB-Dimageclassificationbasedoncompressedsensingtheory[J].ComputerApplicationsandSoftware, 2014(3): 195-198.)
[2] 余凯,贾磊,陈雨强,等.深度学习的昨天、今天和明天[J].计算机研究与发展,2013,50(9):1799-1804.(YUK,JIAL,CHENYQ,etal.Deeplearning:yesterday,today,andtomorrow[J].JournalofComputerResearchandDevelopment, 2013, 50(9): 1799-1804.)
[3]SOCHERR,HUVALB,BHATB,etal.Convolutional-recursivedeeplearningfor3Dobjectclassification[C]//NIPS’12:Proceedingsofthe25thInternationalConferenceonNeuralInformationProcessingSystems.WestChester,OH:CurranAssociatesInc., 2012: 665-673.
[4]SCHWARZM,SCHULZH,BEHNKES.RGB-Dobjectrecognitionandposeestimationbasedonpre-trainedconvolutionalneuralnetworkfeatures[C]//Proceedingsofthe2015InternationalConferenceonRoboticsandAutomation.Piscataway,NJ:IEEE, 2015: 1329-1335.
[5] 卢良锋,谢志军,叶宏武.基于RGB特征与深度特征融合的物体识别算法[J].计算机工程,2016,42(5):186-193.(LULF,XIAZJ,YEHW.ObjectrecognitionalgorithmbasedonRGBfeatureanddepthfeaturefusing[J].ComputerEngineering, 2016, 42(5): 186-193.)
[6]CSURKAG,DANCECR,FANL,etal.Visualcategorizationwithbagsofkeypoints[C]//ECCV2004:ProceedingsofECCVInternationalWorkshoponStatisticalLearninginComputerVision.Berlin:Springer, 2004: 1-22.
[7]LAZEBNIKS,SCHMIDC,PONCEJ.Beyondbagsoffeatures:spatialpyramidmatchingforrecognizingnaturalscenecategories[C]//Proceedingsofthe2006IEEEComputerSocietyConferenceonComputerVisionandPatternRecognition.Washington,DC:IEEEComputerSociety, 2006: 2169-2178.
[8]SILBERMANN,HOIEMD,KOHLIP,etal.IndoorsegmentationandsupportinferencefromRGBDimages[C]//ECCV’12:Proceedingsofthe12thEuropeanConferenceonComputerVision.Berlin:Springer, 2012: 746-760.
[9]BOL,RENX,FOXD.UnsupervisedfeaturelearningforRGB-Dbasedobjectrecognition[C]//Proceedingsofthe13thInternationalSymposiumonExperimentalRobotics.Berlin:Springer, 2013: 387-402.
[10]BLUMM,SPRINGENBERGJT,WULFINGJ,etal.AlearnedfeaturedescriptorforobjectrecognitioninRGB-Ddata[C]//Proceedingsofthe2012IEEEInternationalConferenceonRoboticsandAutomation.Piscataway,NJ:IEEE, 2012: 1298-1303.
[11]JINL,GAOS,LIZ,etal.Hand-craftedfeaturesormachinelearntfeatures?togethertheyimproveRGB-Dobjectrecognition[C]//Proceedingsofthe2015IEEEInternationalSymposiumonMultimedia.Piscataway,NJ:IEEE, 2015: 311-319.
[12]BOL,RENX,FOXD.Kerneldescriptorsforvisualrecognition[C]//Proceedingsofthe2010ConferenceonNeuralInformationProcessingSystems2010.WestChester,OH:CurranAssociatesInc., 2010: 244-252.
[13]BOL,RENX,FOXD.Depthkerneldescriptorsforobjectrecognition[C]//Proceedingsofthe2011IEEE/RSJInternationalConferenceonIntelligentRobotsandSystems.Piscataway,NJ:IEEE, 2011: 821-826.
[14]WANGJ,YANGJ,YUK,etal.Locality-constrainedlinearcodingforimageclassification[C]//Proceedingsofthe2010IEEEConferenceonComputerVisionandPatternRecognition.Piscataway,NJ:IEEE, 2010: 3360-3367.
[15]LAIK,BOL,RENX,etal.Alarge-scalehierarchicalmulti-viewRGB-Dobjectdataset[C]//ICRA2011:Proceedingsofthe2011IEEEInternationalConferenceonRoboticsandAutomation.Piscataway,NJ:IEEE, 2011: 1817-1824.
[16]BOL,LAIK,RENX,etal.Objectrecognitionwithhierarchicalkerneldescriptors[C]//Proceedingsofthe2011IEEEConferenceonComputerVisionandPatternRecognition.Piscataway,NJ:IEEE, 2011: 1729-1736.
[17]JOHNSONAE,HEBERTM.Usingspinimagesforefficientobjectrecognitionincluttered3Dscenes[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 1999, 21(5): 433-449.
[18]YANGJC,YUK,GONGYH,etal.Linearspatialpyramidmatchingusingsparsecodingforimageclassification[C]//Proceedingsofthe2009IEEEConferenceonComputerVisionandPatternRecognition.Piscataway,NJ:IEEE, 2009: 1794-1801.
[19]YUK,ZHANGT,GONGYH.Nonlinearlearningusinglocalcoordinatecoding[C]//NIPS2009:AdvancesinNeuralInformationProcessingSystems22.WestChester,OH:CurranAssociatesInc., 2009: 1-9.
[20]FANRE,CHANGKW,HSIEHCJ,etal.LIBLINEAR:alibraryforlargelinearclassification[J].JournalofMachineLearningResearch, 2010, 9(12): 1871-1874.
[21]BOL,SMINCHISESCUC.Efficientmatchkernelbetweensetsoffeaturesforvisualrecognition[C]//NIPS2009:AdvancesinNeuralInformationProcessingSystems22.WestChester,OH:CurranAssociatesInc., 2009: 135-143.
ThisworkispartiallysupportedbytheNationalNaturalScienceFoundationofChina(41571396),theNationalTrainingProgramofInnovation(201410488017).
LUO Jian, born in 1991, M.S.candidate.His research interests include computer vision, machine learning.
JIANG Min, born in 1975, Ph.D., professor.Her research interests include computer vision, robot automatic navigation.
Object recognition method based on RGB-D image kernel descriptor
LUO Jian1,2, JIANG Min1,2*
(1.CollegeofComputerScienceandTechnology,WuhanUniversityofScienceandTechnology,WuhanHubei430065,China;2.HubeiProvinceKeyLaboratoryofIntelligentInformationProcessingandReal-timeIndustrialSystem(WuhanUniversityofScienceandTechnology),WuhanHubei430065,China)
The traditional RGB-Depth (RGB-D) image object recognition methods have some drawbacks, such as insufficient feature learning and poor robustness of feature coding.In order to solve these problems, an object recognition method of RGB-D image based on Kernel Descriptor and Locality-constrained Linear Coding (KD-LLC) was proposed.Firstly, based on the kernel function of image block matching, several complementary kernel descriptors from RGB-D images, such as 3D shape, size, edges and color, were extracted using Kernel Principal Component Analysis (KPCA).Then, the extracted feature from different cues, were processed by using LLC and Spatial Pyramid Pooling (SPP) to form the corresponding image coding vectors.Finally, the vectors were combined to obtain robust and distinguishable image representation.As a hand-crafted feature method, the proposed algorithm was compared to other hand-crafted feature methods on a RGB-D image dataset.In the proposed algorithm, multiple cues from depth image and RGB image were used, and the sampling points selection and basis vectors calculation schema for depth kernel descriptor generation were proposed.Due to above-mentioned improvements, the category and instance recognition accuracy of the proposed algorithm for objects can respectively reach 86.8% and 92.7%, which are higher than those of the previously hand-crafted feature methods for object recognition from RGB-D images.
RGB-D image; object recognition; Locality-constrained Linear Coding (LLC); kernel descriptor; Spatial Pyramid Pooling (SPP)
2016-07-04;
2016-08-12。
国家自然科学基金面上项目(41571396);国家创新训练项目(201410488017)。
骆健(1991—),男,湖北黄冈人,硕士研究生,主要研究方向:计算机视觉、机器学习; 蒋旻(1975—),女,湖南隆回人,教授,博士,主要研究方向:计算机视觉、机器人自动导航。
1001-9081(2017)01-0255-07DOI:10.11772/j.issn.1001-9081.2017.01.0255
TP
A
