面向套牌甄别的流式计算系统
2017-04-17赵卓峰丁维龙
乔 通,赵卓峰,丁维龙
(1.北方工业大学 数据工程研究院,北京 100144; 2.大规模流数据集成与分析技术北京市重点实验室(北方工业大学),北京 100144)
(*通信作者电子邮箱1790392536@qq.com)
面向套牌甄别的流式计算系统
乔 通1,2*,赵卓峰1,2,丁维龙1,2
(1.北方工业大学 数据工程研究院,北京 100144; 2.大规模流数据集成与分析技术北京市重点实验室(北方工业大学),北京 100144)
(*通信作者电子邮箱1790392536@qq.com)
套牌车的甄别具有时效性约束。针对现有计算检测方法中所出现的精度低、响应慢等局限,提出了一种基于实时车牌识别(ANPR)数据流的套牌车流式并行检测方法,设计了基于路段阈值表和时间滑动窗口的套牌计算模型,能够实时地甄别出交通数据流中的套牌嫌疑车。在Storm环境下,利用某市真实交通数据集模拟成实时交通流数据进行实验和评估,实验结果表明计算的准确率达到98.7%,并且一条车牌识别数据的处理时间为毫秒级。最后,在该计算模型基础上实现了套牌车稽查防控系统,能实时甄别并展现出当前时刻城市交通网中出现的所有套牌嫌疑车。
套牌车;车牌识别;流式计算;实时性;阈值表;Storm
0 引言
套牌车是指未按照交通法规的正常程序到交通部门办理合法的手续,通过套用别人合法车牌或者伪造虚拟车牌在道路上行驶的车辆。套牌车的出现严重扰乱了正常交通管理秩序和社会经济秩序,但由于缺乏有效的套牌车稽查方法,当前套牌车的发现还主要依赖于人工手段,其发现难度大,准确率低,时效性差,导致很多套牌车仍逍遥法外。不过随着车牌识别(Automatic Number Plate Recognition, ANPR)、RFID(Radio Frequency IDentification)[1]车牌等技术的推广应用,使得实时获取车辆的动态信息成为可能,为套牌车的实时甄别提供了条件。
本文结合基于车牌识别数据的车辆缉查防控系统这个实际应用,针对套牌车的实时自动甄别问题展开研究。车牌识别数据是由部署在城市道路上高清摄像头拍摄产生的,由识别摄像头ID、车牌号、时间戳和地点等22个属性值构成,具有时空特性。通过对城市范围内所有车牌识别数据的汇集,可通过时空矛盾规则自动发现有套牌嫌疑的车辆,即同一车牌号的车辆不可能在一定的时间阈值范围内出现在两个不同的地点。由于套牌车在道路上的出现具有随机性,随时都有可能出现,因此,只要道路上的高清摄像头处于正常工作状态,车辆识别数据就会一直持续产生,源源不断,套牌车的计算也就一直持续进行,是交通大数据上的流式计算。流式计算是大数据计算的一种主要计算模型[2-4],适用于对数据无需先存储,直接进行计算以及实时性要求严格的应用场景,可以对动态产生的数据直接进行实时计算并及时反馈结果,而且只要数据流一直产生,流式计算就不会停止,除非主动终止任务或者计算环境出现故障。
本课题在流式计算中进行基于车牌识别数据的套牌车自动甄别时,主要解决以下难点问题:1)实时性。套牌甄别出的结果数据具有时效性,套牌车出现后应该在较短的时间内甄别出来,才能协助交管部门进行交通执法,因此,本课题中面对高并发、连续不断到达的车辆识别数据,一条数据从识别出来至完成计算处理不应该超过3 s。2)准确性。套牌甄别的正确率越高,交管部门打击套牌现象力度越大,交通规范越好。本课题中大型城市道路上所部署摄像头多达几千个,在高峰期的采样频度为1 s/条,1 h就会产生上千万条数据,套牌车的计算是根据其时空矛盾规则来判定的,因此不仅仅是对实时数据的计算,部分历史数据和基础数据也需要参与计算,参与计算数据量大,而大数据量中套牌车的信息很少,非套牌车的数据大,增加了高精度计算的难度。为此,本文在对交通流式数据处理利用套牌车时空矛盾规则做实时计算时,提出了一种基于路段阈值表的套牌甄别流式计算模型,针对历史交通数据设计了时间滑动窗口,实现了对交通数据流中出现的套牌车的实时自动甄别。通过基于真实车牌识别数据集的测试,实验结果表明本系统能够持续不间断地计算识别数据流,能够准确地甄别出数据流中出现的套牌嫌疑车,并且每个数据项的计算处理是在毫秒级内完成。
1 相关工作
目前,针对套牌车检测的研究越来越多,成为智能交通领域的一个研究热点,采用的技术手段和识别方式也越来越多样化。
文献[1]提出基于RFID技术的检测方法,该方法将RFID电子标签植入车辆内,标签内保存这辆车的车型、车辆颜色、车牌号等车辆相关信息,通过交通路口放置的电子标签读写器读取标签中存放的车牌号等信息,然后与实际车辆的信息进行对比,从而判读出该车辆是否是套牌车。此方法虽然可行有效,但是需要交管部门增加投入资金,花费成本高,难以大范围推广;而且RFID标签需要经过车主同意配合才能实施;此外RFID电子标签还面临着被“克隆”的危险且标签里面的信息容易被非法篡改,导致无法准确地判断出套牌车。文献[5]提出的基于光学隐码的检测方法是利用在车牌上采用特殊的光学材料制作的防伪信息条形码来判断车辆是否是套牌车。此方法虽然一定程度上克服了RFID电子标签易被修改的缺点,降低了被“克隆”的风险,但是仍面临的问题还是成本高、难以推广,导致无法全面有效地甄别套牌车。文献[6]采用基于车型识别的检测方法,在道路上放置车牌识别工具,将识别出的车牌号和车型与车辆信息库中的车辆信息进行比较,进而判定是否是套牌车。但是由于当今车辆车型比较单一,导致套牌识别率比较低。本文利用城市交通路网上部署的高清摄像头实时拍摄道路上过往行驶的车辆,提取车牌识别数据,利用套牌车的时空矛盾规则对拍摄到的每一辆进行套牌车的实时甄别计算,在大大降低了检测成本的同时提高了检测的准确率。
文献[7]提出一种基于MapReduce与K最近邻搜索算法来对海量历史数据进行短时间交通流预测的方法,虽然针对的并不是套牌车甄别的问题,但对并行处理交通数据流有一定借鉴意义。文献[8]介绍了一种基于TP-Finder方法的套牌车查询系统,在MapReduce框架上提出基于历史车牌识别数据集的并行检测方法TP-Finder,解决了大规模车牌数据集在并行处理时所出现的数据倾斜问题。文献[9]提出了一种基于Hadoop的套牌车识别方法,将交通流数据迁移到HBase中并消减经纬度,然后初始化以监测点作为顶点集和两两监测点之间距离作为边权值的带权图,通过计算监测点之间的最短距离以及校正因子获取套牌嫌疑车。上述这两种方法虽然正确率都很高,但是都是通过对大规模历史数据进行并行计算,从而挖掘出历史数据中的套牌车,针对的是历史交通数据,时效性太低,无法及时地检测出城市当前道路交通网上正在行驶的套牌车。本文实现的套牌车流式计算系统是对城市道路上摄像头所实时识别出的车牌识别数据流进行实时接入,然后通过计算模型进行实时计算,计算结果实时反馈并进行交通布控,大大提高了套牌车甄别的时效性,能够帮助交管部门对道路上出现的套牌车进行及时有效的处理。
如今面向大规模交通数据进行的套牌车计算都是批量计算[3],参与计算的大都是历史数据,采用的是MapReduce计算框架[10],利用“分而治之”的思想进行分布式计算,适用于大规模历史数据的处理,处理的都是静态数据,无法对流数据进行处理。本课题中的套牌稽查面向的是交通流数据,进行的是流式计算,现有的大数据流式计框架有Twitter的Storm(https://en.wikipedia.org/wiki/Storm)、Spark的Spark Streaming[11]、Yahoo的S4[12]、Hadoop之上的数据分析平台HStreaming[13],其中的主要代表是Storm和Spark Streaming。Spark Streaming是核心Spark API(Application Programming Interface)的一个扩展,数据在处理前按时间间隔保存至弹性内存数据结构——弹性分布式数据集(Resilient Distributed Dataset, RDD),通过微小批量的数据集合进行聚集运算,响应时间为亚秒级;而套牌车甄别的单条数据的处理时间是毫秒级,实时性高,因此Spark Streaming不适合用于流上的套牌甄别。Storm的计算单元是一个封装好的元组,是一次对一条数据的计算,响应时间是毫秒级,实时性高。本文套牌车的甄别就是在Storm框架上进行实现的。Storm是一款支持分布式、开源、实时、主从式大数据流式计算系统[4,14-15],由一个主控节点(运行nimbus服务)和多个工作节点(运行supervisor服务)构成。Storm做实时计算时,首先创建一个拓扑(Topology),计算逻辑被封装在一个拓扑对象中,一个拓扑是一个由多个Spout和Bolt节点连接成的有向图,拓扑中的每一个节点包含处理逻辑,节点之间的连接显示数据应该如何在节点进行传输。Storm开源后在互联网领域和金融银行领域的实时监控[16]场景中得到充分应用,例如,淘宝的虫洞系统以Storm实时流处理为引擎,进行个性化推荐、热门话题统计等;在银行中处理系统内部各子系统实时信息,实现对全局的监控和各种优化;除此之外在分布式远程调用、在线机器学习、数据抽取转化和加载等领域[17]也得到广泛的应用。
2 问题描述
本课题来源于某市智能交通项目,该市区交通网中的多个关键路口部署高清摄像头用于自动识别过往的车辆,摄像头每秒会拍摄多辆机动车并识别出其车牌,日常交通高峰时段每小时会产生上千万条识别数据,识别数据项包含时间戳、监测点和拍摄照片等在内的22个属性,本系统的套牌甄别计算涉及拍摄时间、监测点ID、识别车牌号等时间空间和实体属性。系统对这条识别数据进行实时分析,用于甄别套牌车,整个计算过程除非系统故障或者人为中断,否则计算一直持续进行。
2.1 相关定义
定义1 监测点。城市道路中摄像头监控所在的位置,定义为Pi=(Id,lon,lat),Id为监测点Pi唯一标识,lon和lat为其所在经纬度。
定义2 路段。从一个监测点Pi到另一个监测点Pj之间的交通路线,可以理解为一个方向向量:Rk(Pi,Pj),路段的上游监测点为Pi,下游监测点为Pj。
定义3 旅行时间。T=(Cno1,Pi,t),表示车牌号为no1的车辆C正常情况下行驶通过路段Pi所花费的时间为t。
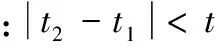
2.2 Storm下实现套牌甄别计算的挑战
Storm自从Twitter开发出来主要用于解决其大量的实时统计类应用,正式开源后,其分布式实时计算性能非常高,容错性良好,保证到达的每条消息都能得到处理,并且某些数据挖掘算法已经很好地在Storm系统中得到移植实现[15],快速准确地处理流数据,实时进行结果反馈。
尽管Storm已应用于智能交通上,但由于交通数据具有时空特性,解决的问题比较单一,例如用于处理黑名单车辆缉查和假牌车等这一类进行数据比较的问题。在套牌车的稽查时,根据套牌车的时空矛盾规则,其计算不仅需要实时数据还需要车牌历史数据和业务数据,在Storm中缺乏对非实时数据合理有效组织的数据结构,仅支持对实时传递的数据的管理组织。在数据存储方面,Storm只能在内存中短期存储少量数据,无法长期存储数据。如何在分布式环境下结合交通数据流的时空特性实时计算套牌车是当前一大挑战。在接入数据源方面,Storm作业Topology的数据源Spout是直接从外部数据源源源不断地读取数据的,而交通数据流的数据源是城市道路上部署的各个高清摄像头采集的车辆识别数据,摄像头的数量有数千个,Spout无法直接和前端摄像头建立连接并获取车牌识别数据,因此需要接入消息中间件来承上启下,将外部各个摄像头采集的识别数据汇集成交通数据流以便Spout组件读取数据流。
因此,本文研究的重点在于面对大规模实时交通数据流,应用分布式编程框架,结合车牌识别数据的时空特性和套牌车的时空矛盾规则,有效组织和管理非实时数据,准确高效地计算出路段上出现的套牌车。
3 面向套牌甄别的流式计算模型
本文在Storm环境下通过利用套牌车的时空特性进行计算,合理组织利用业务数据,对实时到达的车牌识别数据进行分析,根据当前车辆的地理位置(监测点),找出此车牌车辆过去一段时间内经过的所有监测点,结合基础路段信息构建路段并计算出车辆经过这些路段的旅行时间,利用基础路段阈值表中的路段阈值判断车辆在所经过路段上是否出现了套牌。架构设计如图1,数据的输入分为两类:经过消息中间件传输的实时数据流和数据库中的基础数据。流式数据是前端设备实时发送的车牌识别数据,通过消息中间件实现事件触发,推送至系统。基础数据是通过数据库读取接口读取到处理系统的,为实现基础数据更新后的业务连续性,每隔一段时间对加载的基础数据进行定时更新,丢弃已有的基础数据,重新读取以保持数据的新鲜度。运行时环境用于维护数据结构和完成数据处理,包括对实时数据的接入、对具有时空特性的流式数据以滑动时间窗口形式进行维护,基础数据在内存中的Hash结构、对流式数据的划分策略、计算并行度的配置,以及监控和日志等基础功能。数据的输出主要是对计算的套牌嫌疑车直接进行实时布控以帮助交管部门进行执法以及将计算结果写到数据库用于长期存储。
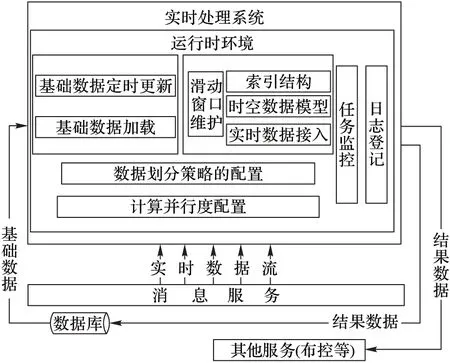
图1 系统架构设计
3.1 混合数据
套牌车在交通数据流中的表现形式为正常行驶的车辆在短时间内不可能出现在相同的监测点或者不可能出现在不应该出现的两个监测点,即车辆行驶过该路段的旅行时间小于该路段的套牌阈值,因此,参与计算的数据并不仅仅是前端摄像头拍摄到的实时数据。参与计算的数据共分为以下三类。
实时数据 前端高清摄像头产生的车辆识别数据,每秒会有2 000多条。系统对接收数据流中的每一条车牌识别数据都会进行实时计算。
业务数据 套牌阈值表,该表中存储着城市道路的路段旅行时间,即此路段的套牌阈值。
历史数据 历史数据存储的是当前接入的实时数据。历史数据的存储时间和大小是根据业务数据中最大的套牌阈值决定的,假设套牌阈值表中存储的旅行时间阈值最大为1h,即从该路段的上游监测点出发行驶到下游监测点的最短时间为1h。假设当前到达的实时数据是某辆车在该路段的下游监测点被拍摄到的,判断这辆车在该路段是否出现了套牌现象,则需要这辆车在该路段上游监测点被拍摄到的车辆识别数据,结合上下游监测点的时空属性进行计算,因此,在历史数据中应该存有这条车辆识别数据。所以历史数据的时间长度不能小于业务数据中最大的套牌阈值。
3.2 数据组织
本文的目的是利用Storm计算框架实时计算出大规模交通流式数据中存在的套牌车嫌疑车,核心思想是进行实时并行计算,将计算任务分配到多个计算节点,最后对计算出的套牌嫌疑车进行布控。通过任务分配和对实时数据、业务数据及历史数据这三类数据的有效组织管理达到提高计算性能、降低内存消耗的目的。
实时数据 组件Spout是Storm整个框架中的数据源,计算套牌车的数据源Spout组件以队列连接的形式从实现JMS协议的消息中间件接收车牌识别数据。由于识别数据是一个由拍摄的照片、时间和车身颜色等22个属性整合成的数据结构,蕴含信息比较庞杂,包括比如车身颜色等对套牌车计算无用的信息,称这种类型的数据为冗余数据项,需要剔除冗余数据项以减少内存消耗,最后将识别数据中的识别车牌号、时间、地点等属性封装成一个Tuple元组。Spout通过追踪每个元组树来确保每一个元组被可靠地处理,成功处理则调用ack方法,失败则调用fail方法,保证了数据处理的完整性。
历史数据 本文所用业务数据中最大的套牌阈值为1h,因此需要维护历史数据的时间长度为1h,将最近1h活跃的数据对象存储在内存中。需要维护一种不但能够对当前识别数据保存1h而且能在时间过后对数据进行删除的数据结构。RotatingMap是Storm用来保存最近活跃对象和可以自动删除已过期对象的数据结构,是由多个HashMap组成的一个LinkedList集合。本文借助RotatingMap这个数据结构作为基础,进而构建滑动时间窗口,用于存储历史数据并删除过期无效数据,数据存储时间长度为1h,时间窗口更新频率设定为10s(要小于套牌阈值表中最小的旅行时间阈值),则共有360(60min×60s/10s)个窗口,每个窗口都是一个HashMap,窗口每10s向前滑动一次,如图2所示,时间长度始终保持为1h。

图2 滑动时间窗口
业务数据 用两个哈希表(HashMap)进行存储,一个哈希表以路段上游监测点作为键值Key,Value为一个由以此键值Key作为上游监测点的所有路段的下游监测点组成的集合;另一个哈希表以路段下游监测点作为Key,Value为一个由以此键值作为下游监测点的所有路段的上游监测点组成的集合。
3.3 算法设计
拓扑逻辑如图3所示,主要由三部分组成:数据源(spout)、套牌计算(T_bolt)和数据存储(DB_bolt)。在作业Topology中,数据源Spout为作业从外部的数据源获取车牌识别数据并剔除无效数据项(如摄像头编号等),封装成元组(Tuple),向计算组件不间断地emit(发射)Tuple形成Stream。套牌计算是分布式并行计算,因此有多个计算组件Bolt独立存在,它们的计算互不干扰,每个Bolt都会接收上游送达的Stream作为数据输入,合理组织基础数据和接收的数据,进而根据时空矛盾规则进行套牌车的计算,将计算出的套牌信息封装成Tuple发射到下一个Bolt(命名为DB_bolt),作为DB_bolt的数据输入。DB_bolt接收所有进行套牌计算组件的计算结果,把接收的数据存储到数据库中。

图3 套牌计算Topology
作业Topology中Spout按Tuple中指定域的值——车牌号码进行分组来进行数据划分,向下游目标组件Bolt发送Tuple,即同一车牌的识别数据发送到同一个计算组件中。如图4所示,这样设计能够确保具有相同车牌号的Tuple被发送到同一个Bolt,即同一个车牌号的识别数据会一直被确定Bolt处理而不会分散到其他Bolt上,保证了同一车牌号的计算中不会出现数据丢失现象。按车牌号划分的这种数据划分方式使计算水平扩展到多个节点,多个节点同时进行套牌车甄别,实现了分布式计算。
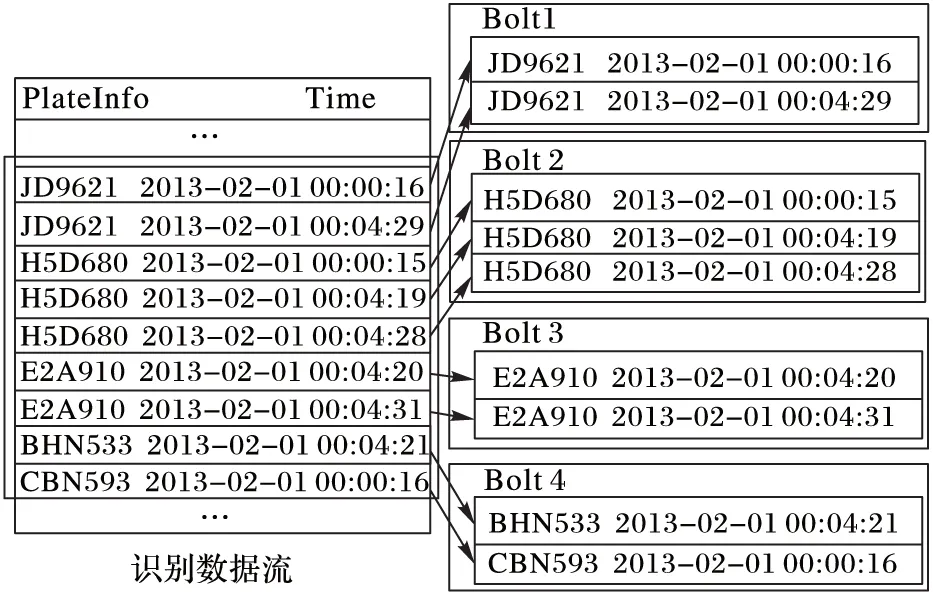
图4 数据划分
下游多个Bolt并行计算接收到的数据流中是否出现套牌车辆,并且将发现的套牌车辆信息都emit(发射)到同一个Bolt中,在该Bolt中将套牌嫌疑车的信息存储到数据库并对套牌嫌疑车进行布控。
套牌车计算的程序流程如图5所示,由于Storm中的进程以服务的形式存在,除非人为主动停止或集群故障,这些进程将会一直运行,所以该流程只有开始标记而没有结束标记。
第1步 对于来到的每一条数据获取其监测点、车牌号以及时间戳,判断路段基础信息表中是否有此监测点:如果没有则废弃此条数据;如果有则进行下一步。
第2步 取出以此监测点作为路段上游监测点的所有路段及其路段阈值,以此监测点Id为Key,所有下游监测点组成的集合作为Value,组成HashMap;取出以此监测点作为路段下游监测点的所有路段及其路段阈值,以此监测点Id为Key,所有上游监测点组成的集合作为Value,组成HashMap。共有两个哈希表。
第3步 找出当前车牌号行驶过的路段。循环遍历以此监测点Id为上游监测点Key的HashMap的Value值,将当前识别数据的车牌和遍历Value所得的一个下游监测点组合成键值Key,获取时间窗口中缓存的信息,用来判断是否有通过这个下游监测点的车辆(具有当前车牌号的车辆)。
第4步 计算当前车牌车辆所行驶过的路段的旅行时间,并判断旅行时间是否小于套牌阈值,如果是则将此套牌嫌疑车信息封装为Tuple传递给下一个Bolt。
第5步 将另一个HashMap中的数据按照第3步和第4步作同样的处理。
第6步 将当前交通信息的车牌号和其监测点作为Key,时间戳作为Value存入时间窗口中。
第7步 将上一个Bolt的传递过来的套牌嫌疑车信息存入数据库并对套牌嫌疑车加以布控。

图5 程序流程
4 实验
4.1 实验环境
实验是在6台搭建了Storm环境的Linux虚拟机下进行的,Storm集群由1个Nimbus节点、5个Supervisor节点构成,配置均为4核CPU、8GB内存。ActiveMQ作为消息中间件,LoadRunner模拟摄像头采集车辆数据,CCS(ConcurrentConnectionStream)[18]是一款用C++语言设计的,用于接收LoadRunner发送的车牌识别数据并转发给ActiveMQ消息中间件,充当ActiveMQ和LoadRunner之间的通信服务器。
4.2 实验数据
实验中采用的数据是来自于某市2012-10-17到2013-01-04这80天420多个监测点产生的上百亿条车牌识别数据,通过LoadRunner模拟成实时数据。
4.3 实验用例
1)将LoadRunner并发数量分别设置为2 000,4 000,6 000,8 000,发送频率为1条/s,用来模拟前端摄像头数目分别为2 000,4 000,6 000和8 000,拍摄频率为1条/s。集群计算组件Bolt的并行度设置为5,即计算并行度为5。启动集群进行计算,集群正常工作后监控系统并记录观察一条识别数据从传输到计算完成所花费的平均时间。
如图6所示:横坐标为并发数量,纵坐标为时间(ms),可以看到处理时间在0.64ms~0.67ms波动,变化幅度很小,处理时间都近似于0.6ms,说明一条识别数据从传输到计算完成所花费时间是毫秒级的,验证了本系统处理识别数据流的实时性,完全可以在大规模高并发的数据流下进行实时计算。通过图6可以清晰看到,虽然LoadRunner并发度不一样,即模拟摄像头的数目有多有少,但一条识别数据的处理时间基本都一样,这是因为本系统设计的滑动时间窗口长度固定为1h,计算所需历史数据的时间长度不变,即使LoadRunner并发量增加,数据增多,但套牌车的甄别是根据其时空矛盾规则来计算的,即同一车牌号的车辆不可能在一定的时间阈值范围内出现在两个不同的地点,与数据量的多少没有直接关系,因此,一条识别数据的处理时间基本一致。

图6 不同数据量下的计算时间
2)为验证系统高正确率,随机抽取5d数据分别进行模拟实时计算和基于历史车牌识别数据的并行计算[18]。基于历史车牌识别数据的并行计算是在Hadoop平台上对历史车牌识别数据进行套牌车的并行检测,是一种批量计算。根据计算结果,即计算出的套牌嫌疑车,与交通部门所提供套牌车对比并计算正确率。如图7所示,分别计算出两种方法的平均正确率,本系统的正确率为99%,高于批量计算98.3%的正确率。验证了根据套牌车时空矛盾规则所设计的流式计算模型的高正确率。本系统的正确率之所以高,是因为采用的是基于路段阈值表的计算,路段阈值表中的路段阈值是在该城市道路中依照车辆正常行驶情况而得出的一个平均旅行时间作为该路段的套牌阈值,符合正常规律。而另一种批量计算是根据两个监测点的经纬度,利用数学公式计算两个监测点之间物理距离,然后根据车辆经过这两个监测点的时间差,计算车辆的平均行驶速度VA,车辆最大速度阈值为VM,若VA>VM,即车辆已超出最大阈值,说明该车辆不可能在这个时间段内出现在这两个地方,从而断定此车辆的车牌在这两个监测点出现了套牌。这种根据经纬度计算两点之间的物理距离看似很合理,但是实际生活中,这两个监测点之间的路段并不一定是一条直线,很有可能是一条弯曲或者倾斜的路,这就造成了误差,降低了计算的正确率。因此,采用本文提出的方法计算出的套牌车的正确率更高。

图7 实验结果的正确率对比
3)对布控信息以可视化形式展示计算出的套牌嫌疑车信息:图8中的监测点1和监测点2表示此车辆的车牌在这两个监测点出现了套牌,交通部门的管理人员可通过此布控信息侦查套牌车。
5 结语
针对当前套牌车泛滥以至影响正常交通秩序的现状,提出了一种基于车牌识别数据的流式计算套牌车主动识别的方法。提出了针对套牌车主动识别的基于路段阈值表的计算模型,结合套牌车的时空特性创建时间滑动窗口以处理交通历史数据,对参加计算的混合数据进行了合理有效组织并加以实时计算;对结果数据——套牌嫌疑车及时有效地进行布控并加以存储,从而实时地发现套牌车。面对城市道路连续不断实时产生的数据流,能够将数据流在线接入并进行实时计算。在Storm环境下,实验结果验证了本文方法的准确性和实时性,能够帮助交通管理部门实现对违法套牌车的实时布控和现场处罚,满足交通管理部门的需要。

图8 本文算法结果展示
在下一步的研究工作中,将进一步地探索和研究基于交通数据流的套牌车实时甄别。本文所设计的计算模型虽然相对于现有方法,其计算套牌车的准确性和实时性有较大幅度提升,但是由于基础路段阈值表较大,在存储方式上仍有不足,导致计算性能没有达到最优。因此在下一步的研究中将继续对基础路段阈值表的加载、存储和查询进行研究,降低内存使用率,提高对阈值表的查询速度,提升计算性能。
)
[1] 黄银龙,王占斌,徐旭,等.基于ISO/IEC18000—6B标准的RFID车卡防伪问题研究[J].射频世界,2008(5):39-42.(HUANGYL,WANGZB,XUX,etal.Researchonanti-counterfeitingproblemofRFIDvehicletagsbasedonthestandardofISO/IEC18000—6B[J].RadioFrequencyIdentification, 2008(5): 39-42.)
[2] 孟小峰,慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展,2013,50(1):146-169.(MENGXF,CIX.Bigdatamanagement:concepts[J].JournalofComputerResearchandDevelopment, 2013, 50(1): 146-169.)
[3] 覃雄派,王会举,杜小勇,等.大数据分析——RDBMS与MapReduce的竞争与共生[J].软件学报,2012,23(1):32-45.(QINXP,WANGHJ,DUXY,etal.Bigdataanalysis——CompetitionandsymbiosisofRDBMSandMapReduce[J].JournalofSoftware, 2012, 23(1): 32-45.)
[4] 孙大为,张广艳,郑纬民.大数据流式计算:关键技术及系统实例[J].软件学报,2014,25(4):839-862.(SUNDW,ZHANGGY,ZHENGWM.Bigdatastreamcomputing:technologiesandinstances[J].JournalofSoftware, 2014, 25(4): 839-862.)
[5] 刘学静,李崇,郝飞,等.含光学隐码的汽车牌照防套牌技术研究[J].大连理工大学学报,2011,51(z1):77-80.(LIUXJ,LIC,HAOF,etal.Researchonanti-fakevehiclelicensetechnologywithopticalimplicitcode[J].JournalofDalianUniversityofTechnology, 2011, 51(z1): 77-80.)
[6]IQBALU,ZAMIRSW,SHAHIDMH,etal.Imagebasedvehicletypeidentification[C]//Proceedingsofthe2010InternationalConferenceonInformationandEmergingTechnologies.Piscataway,NJ:IEEE, 2010: 1-5.
[7]CHENC,LIUZ,LINWH,etal.DistributedmodelinginaMapReduceframeworkfordata-driventrafficflowforecasting[J].IEEETransactionsonIntelligentTransportationSystems, 2013, 14(1): 22-33.
[8] 李悦,刘晨.基于历史车牌识别数据的套牌车并行检测方法[J].计算机应用,2016,36(3):864-870.(LIY,LIUC.Paralleldiscoveryoffakeplatesbasedonhistoricalautomaticnumberplaterecognitiondata[J].JournalofComputerApplications, 2016,36(3): 864-870.)
[9] 俞东进,平利强,李万清,等.一种基于Hadoop的套牌车识别方法:CN201410100491.7[P].2014-03-18.(YUDJ,PINGLQ,LIWQ,etal.Hadoop-basedrecognitionmethodforfake-licensedcar:CN201410100491.7 [P].2014-03-18.)
[10]DEANJ,GHEMAWATS.MapReduce:simplifieddataprocessingonlargeclusters[J].CommunicationsoftheACM, 2008, 51(1): 107-113.
[11]ZAHARIAM,DAST,LIH,etal.Discretizedstreams:anefficientandfault-tolerantmodelforstreamprocessingonlargeclusters[C]//HotCloud’12:Proceedingsofthe4thUSENIXConferenceonHotTopicsinCloudComputing.Berkeley,CA:USENIXAssociation, 2012: 10-10.
[12]NEUMEYERL,ROBBINSB,NAIRA,etal.S4:distributedstreamcomputingplatform[C]//ICDMW2010:Proceedingsofthe2010IEEEInternationalConferenceonDataMiningWorkshops.Piscataway,NJ:IEEE, 2010: 170-177.
[13]STOESSJ,STEINBERGU,UHLIGV,etal.AlightweightvirtualmachinemonitorforBlueGene/P[J].InternationalJournalofHighPerformanceComputingApplications, 2012, 26(2): 95-109.
[14] 郑纬民.从系统角度审视大数据计算[J].大数据,2015(1):17-26.(ZHENGWM.Gazeatthecalculationofbigdatafromasystematicpointofview[J].BigData, 2015, 1(1): 17-26.)
[15]LEIBIUSKYJ,EISBRUCHG,SIMONASSID.GettingStartedwithStorm[M].Sebastopol:O’ReillyMedia, 2012: 4-20.
[16]ANDERSONQ.StormReal-TimeProcessingCookbook[M].Birmingham,UK:PacktPublishing, 2013: 4-8.
[17]DINGW,HANY,ZHAOZ,etal.Stream-orientedavailabilityservicesforendpoint-to-endpointdatatransmission[C]//Proceedingsofthe2012InternationalConferenceonCloudandServiceComputing.Washington,DC:IEEEComputerSociety, 2012: 212-218.
ThisworkispartiallysupportedbytheBeijingMunicipalNaturalScienceFoundation(4162021),theR&DGeneralProgramofBeijingEducationCommission(KM2015_10009007),theKeyYoungScholarsFoundationfortheExcellentTalentsofBeijing(2014000020124G011).
QIAO Tong, born in 1991, M.S.candidate.His research interests include real-time data processing, intelligent transportation.
ZHAO Zhuofeng, born in 1977, Ph.D., associate professor.His research interests include cloud computing, mass data processing, intelligent transportation.
DING Weilong, born in 1983, Ph.D., lecturer.His research interests include real-time data processing, distributed system.
Stream computing system for monitoring copy plate vehicles
QIAO Tong1,2*, ZHAO Zhuofeng1,2, DING Weilong1,2
(1.InstituteofDataEngineering,NorthChinaUniversityofTechnology,Beijing100144,China;2.BeijingKeyLaboratoryonIntegrationandAnalysisofLarge-scaleStreamData(NorthChinaUniversityofTechnology),Beijing100144,China)
The screening of the copy plate vehicles has timeliness, and the existing detection approaches for copy plate vehicles have slow response and low efficiency.In order to improve the real-time response ability, a new parallel detection approach, called stream computing, based on real-time Automatic Number Plate Recognition (ANPR) data stream, was proposed.To deal with the traffic information of the road on time, and plate vehicles could be timely feedback and controlled, a stream calculation model was implemented by using the threshold table of road travel time and the time sliding window, which could access real-time traffic data stream to calculate copy plate vehicles.On the platform of Storm, this system was designed and implemented.The calculation model was verified on a real-time data stream which was simulated by the real ANPR dataset of a city.The experimental results prove that a piece of license plate recognition data can be dealt with in milliseconds from the time of arrival to the calculation completion, also, the calculation accuracy is 98.7%.Finally, a display system for copy vehicles was developed based on this calculation model, which can show the copy plate vehicles from the road network on the current moment.
copy plate vehicle; Automatic Number Plate Recognition (ANPR); stream computing; real-time; threshold table; Storm
2016-07-25;
2016-08-08。 基金项目:北京市自然科学基金资助项目(4162021),北京市教育委员会科技计划面上项目(KM2015_10009007);北京市优秀人才培养资助青年骨干个人项目(2014000020124G011)。
乔通(1991—),男,山东泰安人,硕士研究生,主要研究方向:实时数据处理、智能交通; 赵卓峰(1977—),男,山东济南人,副研究员,博士,CCF高级会员,主要研究方向:云计算、海量数据处理、智能交通; 丁维龙(1983—),男,山东泰安人,讲师,博士,CCF会员,主要研究方向:实时数据处理、分布式系统。
1001-9081(2017)01-0153-06
10.11772/j.issn.1001-9081.2017.01.0153
TP274
A
