面向中医临床现病史文本的命名实体抽取方法研究*
2017-04-10袁玉虎周雪忠张润顺李晓东
袁玉虎,周雪忠,2**,张润顺,李晓东
(1.北京交通大学计算机与信息技术学院 北京 100044; 2. 中国中医科学院中医药数据中心北京 100700;3.中国中医科学院广安门医院 北京 100053;4.湖北省中医院 武汉 430061)
面向中医临床现病史文本的命名实体抽取方法研究*
袁玉虎1,周雪忠1,2**,张润顺3,李晓东4
(1.北京交通大学计算机与信息技术学院 北京 100044; 2. 中国中医科学院中医药数据中心北京 100700;3.中国中医科学院广安门医院 北京 100053;4.湖北省中医院 武汉 430061)
目的:中医临床病历作为重要的临床数据,以文本的形式记录了医生和患者交互的整个过程。目前,在大数据的背景下,针对临床病历所涵盖的主体问题信息如现病史的分析利用相关研究仍有所欠缺。因此,本文针对中医临床病历中的现病史部分展开症状术语抽取方法研究,为临床病历的进一步使用奠定基础。方法:首先通过随机挑选与专家审核的方式获得了12 367份现病史数据,按照疾病种类分成了两组实验,其中糖尿病组包含了4 838份数据,脾胃病组7 529份数据,以及合并后的混合组12 367份数据。并整理出了一份涵盖22 996个词的症状术语字典。然后选取滑动窗口特征、词的前后缀特征、词典特征等5种特征模板,使用CRFs模型开展症状术语命名实体抽取实验。结果:在实验结果评价标准(准确率、召回率和F1值)上的表现:在开放测试上的评价结果为(0.83、0.8、0.82)、(0.9、0.9、0.89)和(0.88、0.87、0.87);在十重交叉验证上的评价结果为(0.83、0.82、0.83)、(0.95、0.95、0.95)和(0.93、0.92、0.92)。结论:CRFs模型作为一种优秀的序列标注算法,适用于现病史文本的症状术语命名实体抽取任务。
中医临床病历 现病史 条件随机场 特征模板 命名实体抽取
目前中医临床电子病历的使用已经十分普及。但是,针对中医临床病历相关的文本挖掘研究尚处于初级阶段[1]。作为自由文本的临床病历,承载着重要的文本信息,它具有非结构化、口语化、专业化的特点[2]。这使得利用临床病历信息变得尤为麻烦。作为文本挖掘的基础技术,命名实体抽取方法的研究就显得尤为的重要,它将为更加深入的研究奠定基础[3,4]。
Qin等[5]使用Bootstrapping方法在临床病历上使用抽取症状术语,F1值为81.4%。刘凯等[2]对命名实体抽取算法在临床病历上的使用进行了初步的研究,证实了与HMM和MEMM模型相比,CRFs模型具有更高的准确率和召回率。Feng等[6]使用CRFs和bootstrapping方法在临床病历的主诉部分进行了实验,证明了CRFs比Bootstrapping更适用于临床症状术语命名实体抽取工作。Wang等[7]使用CRF模型在临床病历的主诉部分进行的症状术语抽取工作得到了较好的结果。Lei等[8]使用CRFs在出院小结和住院笔记文本数据中进行了实验,也取得了不错的效果。
本文将简要介绍CRFs的相关概念,再详细介绍临床病历中现病史数据集的相关情况与规范化处理过程,以及形成症状术语字典相关的工作进展。此外,还将介绍一些与CRFs模型相关的特征模版。最后在不同的特征模板上进行症状术语命名实体抽取的实验,并对抽取结果进行评价和对比。
1 条件随机场
条件随机场模型(CRFs)是一种用于标注和切分有序数据的无向图学习模型[9]。CRFs在所有的特征上进行全局归一化处理,得到全局最优解;目前广泛应用于中文分词、词性标注、中文命名实体识别、歧义消解等自然语言处理任务中。
文中选用的是MALLET*http://mallet.cs.umass.edu.2002.(MAchine Learning for LanguagE Toolkit)工具中提供的CRFs方法。它不仅提供了添加上下文窗口特征、词的前后缀特征、构词模式特征、字典特征等的方法,而且可以根据不同的情况选择状态机的类型,还添加了对模型优化的模块。Feng等[6]在对主诉部分的症状术语抽取研究工作中,取得了良好的效果。
2 实验用数据集及相关处理
本文中使用的数据均来自于广安门医院、望京医院、长春中医药大学附属医院等多所医院的临床病历。通过随机抽样、人工筛选,最终经过专家审核的方式获得了12 367份临床病历数据。根据疾病种类的不同将数据集划分成了两个部分,其中糖尿病类型的病历4 838份,脾胃病类型的病历7 529份。
门诊病历信息主要包括主诉、现病史、既往史等部分。这几部分无论是从内容上,还是文本结构上来讲都有明显差别。主诉部分在内容上简明扼要,在结构组成上也比较简单。现病史部分在内容上涵盖的信息量比较大,表述的信息也比较完整。但是,句子结构复杂,不易处理(表1)。而且个性化差异大,具体表现在不同专家对病人信息的表述差异变化大,标点符号使用习惯各异,还包含有体格检查等信息。对命名实体抽取任务,提出了较大的挑战。
2.1 规范化处理
为了更好完成症状实体的抽取任务,针对上述问题,本文对现病史部分的文本内容进行了进一步深加工处理。本文首先使用(Java)正则表达式,对现病史中的数字、单位、日期和特殊符号进行了处理。如表2所示,我们分别用S、TU和DU来代替标点符号、日期、单位与特殊符号。这样就简化了现病史的句子结构,对症状实体抽取工作的开展提供了极大的帮助。
2.2 句子长度限制处理
由于专家书写习惯的不同,造成经常出现现病史文本的句子特别长,句子之间没有明显的界限。一段话可能只在这段话的末尾出现一个句号(表1)。为了进一步的简化处理,我们对字符串长度进行了限制,规定长度超过50的字符串。则把它分割成两个句子(如表3、表4)。这样的处理不仅可以简化句子结构,而且使得一个句子中不包含大量的症状术语。

表1 现病史文本原始内容

表2 现病史文本规范化处理后内容

表3 糖尿病规范化后按长度处理过后结果

表4 脾胃病规范化后按长度处理过后结果
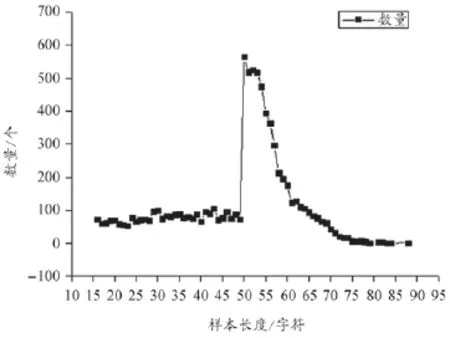
图1 糖尿病数据处理后样本长度分布

图2 脾胃病数据处理后样本长度分布
如图1、图2所示,糖尿病和脾胃病数据集样本长度分布,单个文本的长度得到了有效的控制。不仅可以增加数据集的数量,也使得单个文本包含的信息量和结构的复杂度也有所降低。
12 367份临床病历数据对应着同样数量的现病史文本。它在规范化和分句处理后一共包含了16 148个句子(糖尿病7 909句、脾胃病8 239句),涵盖了751 168个字(糖尿病384 228字、脾胃病366 940字)和253 633个症状术语(糖尿病182 288个、脾胃病71 345个)。
3 症状术语字典
目前为止,中医临床领域还没有完整的、系统的、专家普遍认可的临床症状术语字典。但是,与此项工作相关的课题组专家已经开展多年的研究,并尝试着制定相关规则,从以往名老中医的临床病历中整理出了22 996个的症状术语。
本次实验就使用上述症状术语作为特征模板来开展症状术语命名实体抽取的研究。由于我们对现病史数据集进行了进一步的处理,把所有的数字、单位、标点符号等内容进行了替换。因此,本文过滤掉了所有包含有数字部分的症状术语,剩余部分没有进行任何处理。
在使用的过程中,本文坚持的原则是尽量使用粒度更细的症状术语,即如果在现病史句子中的同一个位置出现两个以上的术语且存在包含关系,本文保留比较字符长度比较长的那个术语。详见表5。
4 CRFs模型特征选择
本节将详细介绍训练CRFs模型的相关特征,主要包括滑动窗口特征、词的前后缀特征、术语字典特征和构词模式特征。
4.1 滑动窗口特征
滑动窗口特征很好的利用了症状术语的上下文信息。有研究表明,在中文预料中,99%的词是由5个或者5个以下的字构成[10]。Feng等[6]研究表明,设置前后的窗口为2或者3,以及n-gram一般设置为Bigram或者Trigram时,效果比较好。如果窗口设置过大,计算效率比较低,而且容易造成过拟合现象。如果窗口设置过小,则上下文信息利用不充分,会丢失有用的信息。详见表6。
4.2 症状术语的前后缀特征
一般情况下症状术语的出现,总是伴随着一些前后缀特征,这也跟名老中医的门诊病历书写习惯有关。例如:“间断性”、“由”、“出现”、“伴随”等常常作为症状术语出现的前缀特征。“S”、“加重”等作为后缀特征。同时,我们发现前缀一般比较固定,后缀的变化比较多样,所以后缀特征选取的数量明显比前缀特征少很多。详见表7。
4.3 症状术语字典特征
现阶段,由于目前并没有较完整的、系统的症状术语集,本文使用课题组整理出来的症状术语字典。如果今后症状术语字典这方面工作有所突破,可以选用更权威的中医症状术语字典。详见表8。
4.4 症状术语构词特征
通过对中医门诊病历分析后,我们发现构成症状术语的字是相对固定的。例如:构成“口干”、“乏力”、“腹胀”、“口苦”等症状术语的字,“口”、“乏”、“胀”等在病历中常常作为症状术语的一部分出现。详见表9。
5 实验设计及结果分析
根据疾病种类的不同,划分为两组的中医临床病历现病史文本标准数据集,以及两者混合后的数据集一共三组数据,选取不同的特征模板训练CRFs模型。然后利用生成的模型对不同类型的测试集数据进行症状术语命名实体抽取实验。最终,对不同的数据集和特征模板实验结果进行分析与评价。
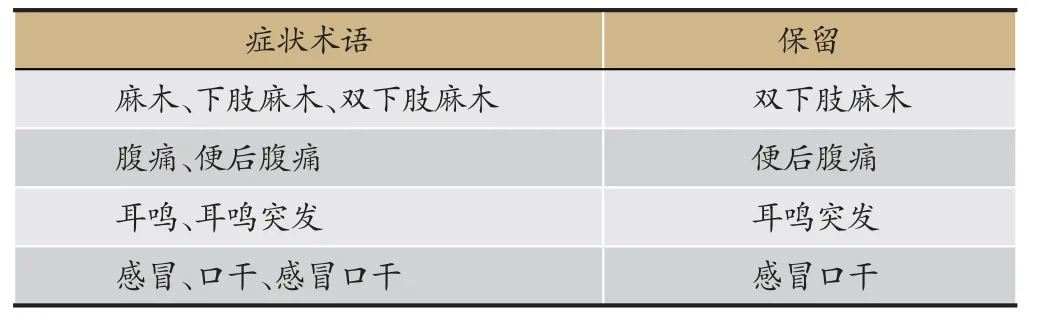
表5 保留更细力度的症状词术语

表6 滑动窗口特征

表7 词的前后缀特征

表8 症状术语词特征

表9 症状术语字特征
5.1 实验设计
针对不同类型的数据集,选择5种类型的特征模版组合训练CRFs模型,并对CRFs模型的抽取效果进行对比和分析。
5.2 实验分组
本次实验我们把滑动窗口特征作为基础特征进行实验,用B来表示。词的前后缀特征、术语字典特征、术语构词特征分别用MT1、MT2、MT3来表示。分析不同的特征模板对生成的CRFs模板的影响。详见表10。

表10 不同特征模板组合

表11 开放测试结果
由于专家的研究领域不同,我们将处理后的中医临床病历数据集分成3个部分,分别为糖尿病数据(1 200)、脾胃病数据(1 200)、混合数据(2 400)。基于上述不同的特征模板组合,对3种数据集进行症状术语的抽取实验,然后对抽取结果进行评价和对比。这里我们选用常用的评价方法:准确率、召回率和F1值。
5.3 开放测试及结果分析
由表11所示,由于现病史文本的结构复杂程度不同,CRFs模型的抽取效果也呈现出较大的差异。文本结构的复杂程度由大到小依次为糖尿病、混合、脾胃病,CRFs模型的抽取结果也是按照这个顺序。这也从侧面证明了命名实体抽取算法的抽取效果跟文本的结构正相关。
同时,本文发现不管使用哪种数据集,基于G1的CRFs模型抽取结果是最差的,而添加了所有特征的G5取得的效果最好。基于G2的抽取结果跟G1比并没有明显的提升,可能跟前后缀特征的选取数据量小有关,而且术语后缀的变化比较大,选取的难度比较大。基于G3和G4的结果比较相近甚至一样,可能与他们使用的都是症状术语字典有关,一个利用的是词特征,一个利用的是字的特征。
从表中可以看出,在开放测试中,糖尿病数据集处理后的最佳效果为0.83、0.80、0.82,而脾胃病类型的数据集的最好效果更是达到了0.90、0.90、0.89,混合后的结果为0.87、0.87、0.87。
5.4 十重交叉验证及结果分析
刘凯等[2]在糖尿病数据集上进行的十重交叉验证抽取实验,取得的结果准确率、召回率和F1值分别为:0.8、0.74、0.63。本文在基于G5特征组合下,在糖尿病数据上进行的十重交叉验证结果为0.83、0.82、0.82(图3)。对比发现,在准确率上有一定的提升,在召回率和F1值上有了较大的提升。如图4、图5其他的类型数据上的十重交叉验证结果分别为:在脾胃病数据集上为0.95、0.95、0.95,在混合数据集上为0.93、0.92、0.92。实验结果证明了本文对数据集的处理(单位、日期、标点的替换以及对数据长度的控制)是有效的。
5.5 编辑距离

图3 糖尿病十重交叉验证结果

图4 脾胃病十重交叉验证结果
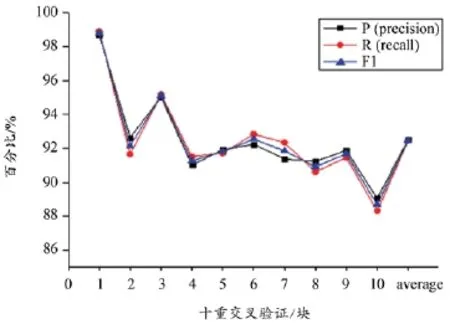
图5 混合数据十重交叉验证结果
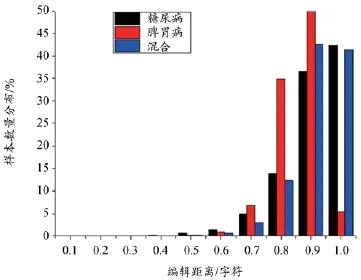
图6 样本对编辑距离分布
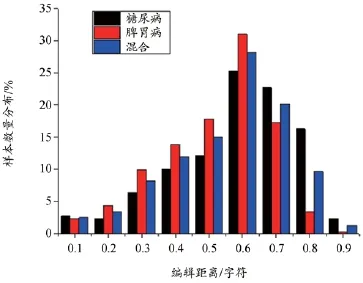
图7 样本最小编辑距离分布
编辑距离[11]常被用来计算文本之间的相似性[12],它的值越大表明两个文本的内容差异就越大。如图6所示脾胃病、糖尿病和混合数据集内部文本之间的差异很大,显示出现病史文本结构的复杂性。由图7所示样本最小编辑距离的分布临近高斯分布,即选取的样本是符合现实中的现病史文本,内容具有一定的代表性。实验表明,CRFs模型能够在结构和内容较复杂的现病史文本情况下,依然能够获得较好的表现。
总结,以上的实验结果表明,在基于G5的CRFs模型能够取得的抽取效果最好。同时,病历文本的规范化、长度限制处理对抽取效果的提升也是十分有帮助的。最后,CRFs算法的抽取效果跟文本的结构复杂程度是逆相关的。文本结构越复杂,抽取效果就越差。CRFs算法在现病史文本内容差异比较大的情况下,也能取得较好的结果。
6 小结
通过疾病种类的不同对临床病历进行划分,然后在对病历文本数据集进行规范化,长度限制处理,最后根据不同的特征模板训练CRFs模型。该流程能够适用于基于临床病历现病史文本的症状术语抽取任务并取得了较好的结果。同时,这将对后续针对临床病历开展更加深入的研究奠定基础。另外,我们注意到目前还没有完整的、系统的症状术语字典。同时,需要构建涵盖更广阔领域的临床病历的现病史语料库。最后,在CRFs模型的基础上,探索更加优秀高效的症状术语命名实体抽取方法。解决以上几个方面的问题,将成为我们在中医临床命名实体抽取研究未来工作的重点。
1 周雪忠.文本挖掘在中医药中的若干应用研究.杭州:浙江大学博士学位论文,2004:1-12.
2 刘凯,周雪忠,于剑,等. 基于条件随机场的中医临床病历命名实体抽取. 计算机工程, 2014, 40(9): 312-316.
3 Zhou X, Liu B, Wang Y,et al. Building clinical data warehouse for traditional Chinese medicine knowledge discovery.2008 International Conference on BioMedical Engineering and Informatics.IEEE, 2008, 1:615-620.
4 Zhou X, Peng Y, Liu B. Text mining for traditional Chinese medical knowledge discovery: a survey.J Biomed Inform, 2010, 43(4):650-660.
5 Qin T, Guan Y. A bootstrapping approach to symptom entity extraction on Chinese electronic medical records. Chinese computational linguistics and natural language processing based on naturally annotated big data. Boston: Springer US, 2016:413-423.
6 Feng L, Zhou X, Qi H,et al. Development of large-scale TCM corpus using hybrid named entity recognition methods for clinical phenotype detection: An initial study. Computational Intelligence in Big Data.IEEE, 2014:1-7.
7 Wang Y, Yu Z, Chen L,et al. Supervised methods for symptom name recognition in free-text clinical records of traditional Chinese medicine: an empirical study.J Biomed Inform, 2014, 47(2):91-104.
8 Lei J, Tang B, Lu X,et al. A comprehensive study of named entity recognition in Chinese clinical text.J Am Med Inform Assoc, 2014, 21(5):808-814.
9 Lafferty J, McCallum A, Pereira F. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. Proceedings of the eighteenth international conference on machine learning,ICML, 2001, 1:282-289.
10 Kim J D, Ohta T, Tsuruoka Y,et al. Introduction to the bio-entity recognition task at JNLPBA. Proceedings of the international joint workshop on natural language processing in biomedicine and its applications.Association for Computational Linguistics, 2004:70-75.
11 Navarro G. A guided tour to approximate string matching.Acm Computing Surveys, 2001, 33(1):31-88.
12 Kukich K. Techniques for automatically correcting words in text.ACM Conference on Computer Science, 1993:515.
A Study on the Named Entity Recognition Method on Symptom Names in the History of Present Illness in Traditional Chinese Medical (TCM) Clinic
Yuan Yuhu1, Zhou Xuezhong1,2, Zhang Runshun3, Li Xiaodong4
(1. College of Computer Science and Information Technology Beijing Jiaotong University, Beijing 100044, China; 2. National Data Center of Traditional Chinese Medicine, China Academy of Chinese Medical Sciences, Beijing 100700, China; 3. Guang'anmen Hospital, China Academy of Chinese Medical Sciences, Beijing 100053, China; 4. Hubei Hospital of Traditional Chinese Medicine, Wuhan 430061, China)
Clinical cases of TCM are used as important clinical data to record the whole process of the interaction between doctors and patients in the form of text. However, in the context of big data, there is a lack of research on the use of information covered in clinical cases. Therefore, we studied the method of extracting the symptom term from the history of present illness in TCM clinic in this paper, in order to lay the foundation for the further use of clinical cases. First, twelve thousand, three hundred and sixty-seven history data of present illness were obtained by random selection and expert review. According to the different disease types, they were divided intothe two groups of the experiments: 4,838 data in the diabetes group, 7,529 data in the spleen and stomach disease group and 12,367 data in the mixed or combined group. A glossary of symptom terms covering 22,996 words were compiled. Then, five feature templates, such as sliding window feature, prefix and suffix character and lexical features, were selected. CRFs model was adopted to carry out named entity extraction experiment. As a result, in the open test, the performance of diabetes, spleen and stomach disease and mixed group were (0.83, 0.8, 0.82),(0.9, 0.9, 0.89) and (0.88, 0.87, 0.87), respectively, while the results were (0.83, 0.82, 0.83), (0.95, 0.95, 0.95) and (0.93, 0.92, 0.92) in the ten-fold cross validation. In conclusion, the results showed that the CRFs algorithm was an excellent sequence labeling algorithm and applied to the named entity extraction task of symptom history.
Traditional Chinese medical clinical data, medical history of present illness, conditional random field, feature template, named entity recognition
10.11842/wst.2017.01.010
R29
A
(责任编辑:朱黎婷,责任译审:朱黎婷)
2016-12-30
修回日期:2017-01-03
* 国家中医药管理局2015年度国家中医临床研究基地业务建设第二批科研专项(JDZX2015171):肝病回顾性病例表型信息抽取方法与分析研究,负责人:周雪忠;国家中医药管理局2015年度国家中医临床研究基地业务建设第二批科研专项(JDZX2015170):慢性肝病病案资料数据审编方案设计、质量控制关键技术研究,负责人:张润顺;国家自然科学基金委青年科学基金项目(61105055):表型与基因型功能关联的数据整合和网络分析方法研究,负责人:周雪忠。
** 通讯作者:周雪忠,本刊编委,教授,主要研究方向:复杂网络、数据仓库、数据挖掘;李晓东,主任医师,主要研究方向:中西医结合治疗慢性肝炎、肝硬化、重型肝炎及脂肪肝研究。
