基于深度学习的铁道塞钉自动检测算法
2017-04-09杜馨瑜王胜春
杜馨瑜,戴 鹏,李 颖,程 雨,王胜春,韩 强,王 昊
(中国铁道科学研究院 基础设施检测研究所,北京 100081)
塞钉是安装轨道电路轨端连接线的关键部件,其性能好坏直接影响到轨道电路信号的传输质量,因此对塞钉的日常检查与维护在行车安全方面有重要的意义。目前,对塞钉的巡检依赖于人工上道作业的方式,在有限的天窗时间内检修效率也比较有限。鉴于此,采用在巡检车上安装专用线阵相机,对轨道图像进行连续采集存储,并对采集到的钢轨轨腰图像序列进行分析,实现对塞钉的高效检测。轨腰处线阵相机的安装位置如图1所示。经大量统计发现,轨腰图像序列中有塞钉的图像大约只占整个图像序列的3%,且实际分布无明显规律,因此,需要采用基于计算机视觉的目标检测算法实现对图像序列中所有塞钉的自动定位,从而实现塞钉的自动检测。

图1 轨腰处线阵相机的安装位置
深度学习是近年兴起的高性能大数据分析方法,在人工智能的各个领域产生了巨大的影响,如Alphago采用策略网络与价值网络在围棋上取得突破性成果[1]。其中,卷积神经网络(Convolutional Neural Networks,CNN)在图像识别、目标检测以及图像分割等计算机视觉研究方面,与传统方法相比,在处理结果上得到了很大的提升[2]。在计算机视觉领域,目标检测就是给定1幅图像或视频帧,找出特定目标的所在位置。已经有较多研究应用在人脸检测[3]、人体检测[4]等。因此,在轨腰图像序列中筛选出有塞钉的图像并准确定位到塞钉,其关键点在于待检测目标的外观,而由于类内差异、光照条件、成像清晰度、部分遮挡等的影响使得塞钉的外观有可能表现出很大的改变,从而增加了检测(或定位)的难度[5]。
目前,目标检测算法从解决思路上大致可分为两大类。一类目标检测算法采取分类策略,遵循的步骤依次是:区域选择、特征提取、分类器分类。对于区域选择阶段,可以采取基于穷举思想的滑动窗口法,即对整个图像进行遍历,其典型应用是经典人脸检测算法[6]。滑动窗口法的优点是选择合适的步长就可以包含图像中所有目标可能出现的位置,缺点是海量的冗余窗口极大增加了算法的时间复杂度,从而限制了后续算法的复杂多样性,以及有限的固定长宽比设置增加了目标丢失的可能性。近年出现的候选区域法(Region Proposal,RP)采用可变的长宽比预先找出目标可能出现的位置,从而很好地解决了滑动窗口法存在的问题[7]。候选区域法利用图像纹理、颜色、边缘的信息,可以保证在选取与滑动窗口法相比相对较少窗口(几千个或几百个)的情况下维持较高的召回率,从而降低了后续算法的复杂度。有代表性的区域选择法是Selective Search[8]和Edgebox[9]等。特征提取是对上一步得到的候选区域图像块进行某种表达,以克服目标形态、光照变化以及背景表示的多样性,使后端分类器的输入在分类意义上达到一定的鲁棒性[10]。目前常用到的经典特征提取算子有HoG[11],LBP[12],类Haar[13]和SIFT[14]等。采用深度学习的方法,如稀疏自编码[15],CNN[16-19]等类型的深度神经网络,可以通过训练的方式,自动提取适合于具体场景的特征,克服了上述经典特征提取算子手工设计的简单方式,使特征更具有适应性。分类器分类阶段主要是采取或改进分类器用以对上一阶段提取的特征进行分类。常用的分类器有支持向量机(Support Vector Machine,SVM)[20]、随机森林(Random Forest,RF)[21]、Adaboost方法[22]等。另一类目标检测算法是采取回归策略的方法。如文献[23]提出的YOLO方法,即对待检测图像预先划分固定的网格,然后采用特定的深度卷积网络直接在不同位置的网格上回归出目标的位置和类别信息,从而大大加快了检测速度。但由于该方法舍去了RP机制,往往不能得到精确的目标定位。文献[24]提出的SSD方法,结合了YOLO的回归思想以及Faster R-CNN[19]的锚点(anchor)机制,可以做出更为精确的定位。不难看出,采取分类策略的目标检测算法是目前主流的方法,但是算法的速度仍不能较好地满足实时性的要求。采取回归策略的目标检测算法在速度上有很大的提升,但在定位精度上又有所损失。
上述目标检测算法的研究对象均为国际标准库中的自然图像,而铁道塞钉序列图像是由线阵相机在激光作为触发光源下采集的特殊图像,其具有以下5个特点:①大部分图像的纹理结构具有相似性;②都是灰度图像;③因为线阵相机安装位置固定而导致图像具有单一的尺度特性;④塞钉在图像中作为小目标出现;⑤对识别而言,各种干扰具有特殊性,如锈迹、人工涂画、道岔锁框等。因此,针对铁道塞钉序列图像的特点,本文在传统(类Haar+adaboost)算法的基础上[25]提出基于深度学习的目标检测算法,即先用一种新的目标区域选择算法——余谱区域候选(Spectrum Residual Region Proposal,SRP)算法,快速提供图像的候选塞钉区域,再设计一种专用于塞钉检测的CNN结构——塞钉卷积神经网络(plug Convolution Neural Network,pCNN),实现对候选区域有效特征的提取,最后采用SVM分类器判断候选区是否含有塞钉,实现塞钉的自动定位。
1 自动检测算法
1.1 SRP算法
根据轨腰处塞钉图像的特点,借鉴文献[26]的显著性区域检测算法,提出了SRP算法。鉴于显著性检测的目的是提取与背景区域在纹理、颜色等方面有明显差异的前景(通常表现为高频信息)[27],而塞钉图像正好表现为有塞钉的前景区(高频纹理信息),与较为平坦的轨腰背景区(低频纹理信息)在纹理上存在显著性差异,因此,这里采用显著性检测的思路进行候选区域的提取。
将含有塞钉原图像(见图2(a))的轨腰区作为感兴趣区域,即视为输入图像(见图2(b))。观察含有塞钉的输入图像,发现塞钉凸显于平坦轨腰区,因此可以用该图像的幅度谱减去不含塞钉轨腰区的平均图像(用现有采集到的384 956张不含塞钉的轨腰图像做叠加平均得到,见图2(c))的平均幅度谱,并取其绝对值得到余谱图(见图2(e))后,再做保持相位的反傅里叶变换,得到的图像应该凸显显著性区域。最后,经过简单的阈值分割、各连通域中心坐标提取等后处理流程,可以得到候选目标区域(图2(d)中箭头所指小块)。
文献[26]提出的算法是建立在对自然图像进行显著性检测上,不可能得到背景图像集,因此采用对原图像幅度谱取滑动均值的方法,得到近似的背景图像幅度谱图,即图3(a)的余谱图。比较2种方法得到的余谱图,发现SRP算法余谱图的方差大于文献[26]算法余谱图的方差,这说明SRP算法余谱分布更为离散,统计差异性更强,即反变换后图像的显著性候选目标区域较多[27],不容易丢失目标。显而易见,塞钉候选区在图3(b)中已经丢失,而在图2(d)中仍存在(箭头所示小连通区)。

图2 SRP算法原理图
SRP算法流程如图4所示。
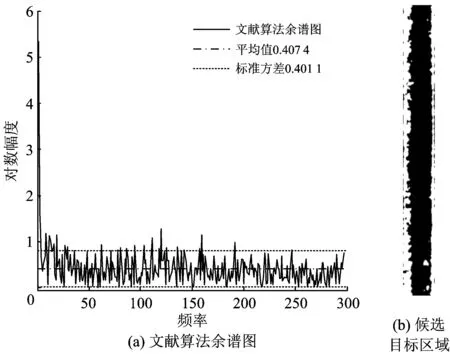
图3 文献[26]算法
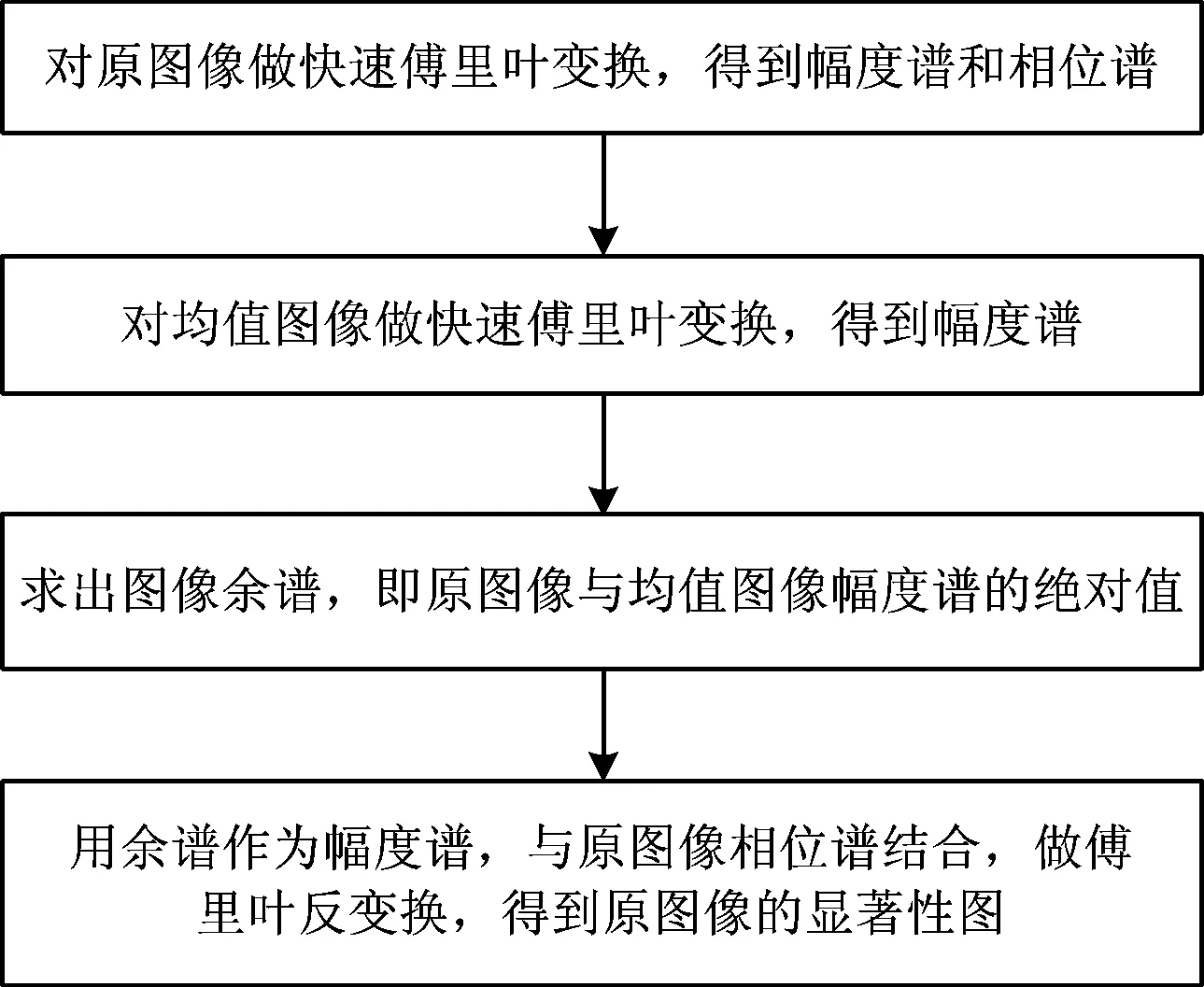
图4 SRP算法流程图
1.2 pCNN
对采用SRP算法得到的图像候选目标区域方块,采用pCNN提取相应特征,并输入到SVM分类器进行分类,判断是否为塞钉图像块。pCNN的基本结构如图5所示。
首先,输入的图像块被调整为(32×32)像素大小,外周填充2像素,用于卷积。
在第1层卷积(conv1)中,感受野大小为(5×5)像素,维数为32,步长为1像素。进而对卷积结果进行非线性变换,变换函数为取极大值变换,相当于1个非线性变换层(relu1,在图5中略去),以加快收敛速度;然后,对非线性变换结果进行局部响应规范化[2],以提高网络的泛化能力,可以认为是1个规范化层(norm1,在图5中略去);最后,经池化层(pool1)取局部最大值,感受野大小为(3×3)像素,步长为2像素。
在第2层卷积(conv2)中,感受野大小为(5×5)像素,维数为64,步长为1像素,外周填充为2像素。同上,经非线性变换层(relu2)、规范化层(norm2)和池化层(pool2)后,取局部均值,感受野大小为(3×3)像素,步长为2像素。
在第3层卷积(conv3)中,感受野大小为(5×5)像素,维数为256,步长为1像素,外周填充为2像素。同上,后面是非线性变换层(relu3)以及规范化层(norm3)。接下来是池化层(pool3),取局部均值,感受野大小为(1×1)像素,步长为2像素。
在第4层卷积(conv4)中,感受野大小为(1×1)像素,维数为1 024,步长为1像素。同上,后面是非线性变换层(relu4)以及规范化层(norm3)。
在第1全连接层(ip1)中,实现内积运算,输出维数为4 096。后接泄漏层(drop1,在图5中略去),泄漏率为0.5,以更好地增加网络的泛化能力。
最后是全连接层(ip2),输出判断结果,即判断图像块是否为塞钉,是塞钉时输出“1”,不是塞钉时输出“0”。
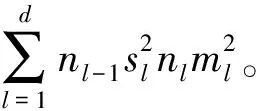
以含塞钉的轨腰图像为例,采用pCNN提取特征各中间结果如图6所示。由图6(f)可以看出:经采用SRP算法提取塞钉候选区及第1—第4卷积层和第1全连接层处理后,得到输入图像块的特征图具有稀疏性,可用于SVM分类。
1.3 SVM分类
pCNN提取的图像块具有4 096维特征,将其输入SVM工具箱LIBSVM[29]进行分类。因样本数较多,该SVM采用线性核分类。最后根据得到的分类结果判断该图像块是否包含塞钉。
2 试验结果分析
因为研究对象是钢轨的轨腰图像,无论成像条件还是分析目的都具有行业特殊性,所以在进行试验测试和方法比较时,为保证自动检测方法在行业内应用的有效性以及评价的客观性,不会选择国际通用的自然图像目标检测测试库,如PASCAL VOC 2007/2012[30],MS COCO[31]。本文试验代码是构建在Ubuntu14.04与Caffe框架[32]下的,同时使用NVIDIA K4200 GPU。

图6 pCNN特征提取图示
2.1 训练阶段
自动检测算法分为2个阶段训练,首先是对pCNN进行训练,然后将该网络ip1层提取的特征作为输入,对分类器SVM进行训练,具体说明如下。
对于pCNN训练,通过大量挑选和剪裁,找出具有代表性的各类塞钉图像块6 000个,缩放为(32×32)像素,作为正样本;同理,挑出不含塞钉的图像块6 000个,同样缩放为(32×32)像素,作为负样本,如图7所示。为了使训练得到的网络更具有泛化性能,还挑选出验证集,包括正样本3 000个、负样本3 000个。设置训练参数如下:基础学习率(base_lr)=0.01, 动量(momentum)=0.9, 权重衰减惩罚项(weight_decay)=0.004, 衰减系数(gamma)=0.1, 衰减步长(stepsize)=20 000, 最大迭代次数(max_iter)=150 000次。
采用上述训练集提取的ip1层特征,用SVM进行训练,设置为10重交叉验证。采用线性核分类,惩罚因子C=2。
2.2 测试阶段
因为同一巡检区段内的图像大多数表现为无目标(无塞钉),且具有几乎相同的纹理与光照,但不同区段间的图像由于检测时段、检测条件、检测环境不同而有所差异,所以在现有工作的基础上(类Haar+Adaboost算法)[25],挑选有代表性的图像作为测试集,能更加客观、准确地反映算法的性能。本文挑选有代表性的236张图像进行测试,部分有代表性的测试图像及测试结果如图8所示。
从图8可以看出:图8(a)为正常条件下无塞钉的轨腰图像,检测结果也为无塞钉(无定位框);图8(b)为有锈迹等干扰情况下无塞钉轨腰图像,检测结果为无塞钉(无定位框);图8(c)为正常条件下有塞钉轨腰图像,检测结果为有塞钉且准确定位(有定位框);图8(d)为道岔区有锁框、锈迹干扰情况下的有塞钉轨腰图像,检测结果为有塞钉且准确定位(有定位框);图8(e)为塞钉头超出图像边界情况下的有塞钉轨腰图像,检测结果为有塞钉且准确定位(有定位框);图8(f)为光照不足且有锈迹、划痕干扰情况下的有塞钉轨腰图像,检测结果为有塞钉且准确定位(有定位框);图8(g)为塞钉尾部人工处理并标记后的有塞钉轨腰图像,检测结果为有塞钉且准确定位(有定位框);图8(h)为模糊干扰情况下的有塞钉轨腰图像,检测结果为有塞钉且准确定位(有定位框)。
采用国际通用的定量评价指标,对本文自动检测算法(SRP+pCNN+SVM)、文献[26]显著性检测+本文卷积网络算法(SR (文献[26])+pCNN+SVM),LBP+SVM算法和类Haar+Adaboost算法[25]这4种方法进行比较,得到根据定量评价指标描绘出的4种算法的准确率—召回率(Precision-Recall)特性曲线[33],如图9所示。
从图9可以看出:本文算法表现的性能最优,其次是SR+pCNN+SVM算法,再次是类Haar+Adaboost算法,最后是LBP+SVM算法;通过本文算法(SRP+pCNN+SVM算法)与SR+pCNN+SVM算法的比较,说明本文算法在性能上比文献[26]的SR算法在性能上有所提升,而这2种算法与其余2种算法比较,又说明pCNN在特征提取方面具有优势,能进一步提升目标检测性能。
3 结 语
传统的人工智能方法已经在铁路基础设施检测领域有所应用[34-37],深度学习是近年人工智能领域取得的突破性成果,本文针对钢轨轨腰图像的特点,将深度学习引入铁路基础设施检测领域。基于深度学习的铁道塞钉自动检测算法包括如下几个阶段:首先借鉴显著性检测的思路,在目标检测的区域选择阶段,用给出的SRP算法能更有效地提取出候选目标区域;其次,在目标检测的特征提取阶段,用设计的pCNN深度卷积神经网络能更准确地提取相应的目标特征;最后由SVM进行分类,完成目标检测功能。在各种成像环境和外界干扰下对采集到的轨腰图像测试,并经对比试验,验证提出的基于深度学习的铁道塞钉自动检测算法表现得比目前实际使用的传统算法更为优秀,且与深度学习在其他图像分析领域的表现效果相一致。下一阶段的目标是使用更为有效的编程技巧和性能更为强劲的硬件,进一步提升算法的计算速度。

图9 采用不同算法得到测试集图像的准确率—召回率曲线
[1]SILVER D, HUANG A, MADDISON C J, et al. Mastering the Game of Go with Deep Neural Networks and Tree Search [J]. Nature, 2016, 529(1):484-489.
[2]KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet Classification with Deep Convolutional Neural Networks [J]. Advances in Neural Information Processing Systems, 2012, 25(2): 1097-1105.
[3]LI H, LIN Z, SHEN X, et al. A Convolutional Neural Network Cascade for Face Detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2015. Boston: IEEE Computer Society, 2015: 5325-5334.
[4]RIBEIRO D, NASCIMENTO J C, BERNARDINO A, et al. Improving the Performance of Pedestrian Detectors Using Convolutional Learning [J]. Pattern Recognition, 2017, 67(1): 641-649.
[5]GAL J, LEMPITSKY V. Class-Specific Hough Forests for Object Detection[C]//In Proceedings IEEE Conference Computer Vision and Pattern Recognition 2009. Miami: IEEE Computer Society, 2009: 1022-1029.
[6]VIOLA P, JONES M. Robust Real-Time Face Detection [J]. International Journal of Computer Vision, 2004, 57(2):137-154.
[7]CHAVALI N, AGRAWAL H, MAHENDRU A, et al. Object-Proposal Evaluation Protocol is ‘Gameable’ [C] //Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2015. Boston: IEEE Computer Society, 2015: 835-844.
[8]UIJLINGS J R R, SANDE van de K E A, GEVERS T, et al. Selective Search for Object Recognition [J]. International Journal of Computer Vision, 2013, 104(2):154-171.
[9]ZHU Gao, PORIKLI Fatih, LI Hongdong. Tracking Randomly Moving Objects on Edge Box Proposals [OL]. 2015. https://arxiv.org/pdf/1507.08085.pdf.
[10]NIXON M, AGUARDO A S. Feature Extraction and Image Processing [M]. 2nd ed. Amsterdam: Elsevier, 2010.
[11]DALAL N, TRIGGS B. Histograms of Oriented Gradients for Human Detection[C]//IEEE Conference on Computer Vision & Pattern Recognition 2005. San Diego: IEEE Computer Society, 2005: 886-893.
[12]OJALA T, PIETIKINEN M, MENPT, et al. Multiresolution Gray-Scale and Rotation Invariant Texture Classification with Local Binary Patterns [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(7): 971-987.
[13]HIROMOTO M, SUGANO H, MIYAMOTO R, et al. Partially Parallel Architecture for AdaBoost-Based Detection with Haar-Like Features [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2009, 19(1): 41-52.
[14]ZHOU Huiyu, YUAN Yuan, SHI Chunmei, et al. Object Tracking Using SIFT Features and Mean Shift [J]. Computer Vision and Image Understanding, 2009, 113(3): 345-352.
[15]JIANG Jielin, ZHANG Lei, YANG Jian. Mixed Noise Removal by Weighted Encoding with Sparse Nonlocal Regularization [J]. IEEE Transactions on Image Processing, 2014, 23(6): 2651-2662.
[16]GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]// IEEE Conference on Computer Vision & Pattern Recognition 2014. Columbus: IEEE Computer Society, 2014: 580-587.
[17]GIRSHICK R. Fast R-CNN[C]//Proceedings of the International Conference on Computer Vision 2015. San Diego: IEEE Computer Society, 2015: 1440-1448.
[18]HE K, ZHANG X, REN S, et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916.
[19]REN Shaoqing, HE Kaiming, GIRSHICK Ross, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[C]//Advances in Neural Information Processing Systems 2015. Montréal: Curran Associates Inc., 2015: 91-99.
[20]SUYKENS J A K, VANDEWALLE J. Least Squares Support Vector Machine Classifiers [J]. Neural Processing Letters, 1999, 9(3): 293-300.
[21]LIAW A, WIENER M. Classification and Regression by Random Forest [J]. R News, 2002, 2/3: 18-22.
[22]RATSCH G, ONODA T, MULLER K R. Soft Margins for AdaBoost [J]. Machine Learning, 2001, 42(3): 287-320.
[23]REDMON J, DIVVALA S, GIRSHICK R, et al. You Only Look Once: Unified, Real-Time Object Detection[C] // IEEE Conference on Computer Vision & Pattern Recognition 2016. Las Vegas: IEEE Computer Society, 2016: 779-788.
[24]LIU W, ANGUELOV D, ERHAN D, et al. SSD: Single Shot MultiBox Detector [C] //European Conference on Computer Vision 2016. Amsterdam: Springer, 2016: 21-37.
[25]杜馨瑜. 基于计算机视觉技术的铁道塞钉自动定位算法 [J]. 铁道通信信号, 2016, 52(9): 68-72.
(DU Xinyu. Automatic Location Algorithms for Railway Plugs Based on Compute Vision Technology [J]. Railway Signaling & Communication, 2016, 52(9): 68-72. in Chinese)
[26]HOU Xiaodi, ZHANG Liqing. Saliency Detection: A Spectral Residual Approach[C]// IEEE Conference on Computer Vision and Pattern Recognition 2007. Minneapolis: IEEE Computer Society, 2007:1-8.
[27]ZHANG J, SCLAROFF S, LIN Z, et al. Unconstrained Salient Object Detection via Proposal Subset Optimization[C]//IEEE Conference on Computer Vision & Pattern Recognition 2016. Las Vegas: IEEE Computer Society, 2016: 5733-5742.
[28]HE Kaiming, SUN Jian. Convolutional Neural Networks at Constrained Time Cost[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2015. Boston: IEEE Computer Society, 2015: 5353-5360.
[29]CHANG C C, LIN C J. LIBSVM: a Library for Support Vector Machines [J]. ACM Transactions on Intelligent Systems and Technology, 2011, 2(3): 1-27.
[30]EVERINGHAM M, VAN G L, WILLIAMS C K I, et al. The Pascal Visual Object Classes (VOC) Challenge [J]. International Journal of Computer Vision, 2010, 88(2): 303-338.
[31]LIN T Y, MAIRE M, BELINGIE S, et al. Microsoft COCO: Common Objects in Context[C]//European Conference on Computer Vision 2014. Zurich: Springer, 2014: 740-755.
[32]JIA Yangqing, SHELHAMER Evan, DONAHUE Jeff, et al. Caffe: Convolutional Architecture for Fast Feature Embedding[C] //Proceedings of the 14th ACM International Conference on Multimedia 2014. Orlando: ACM New York, 2014: 675-678.
[33]DUDA R O, HART P E, STORK D G. Pattern Classification [M]. 2nd ed. Hoboken N J; Wiley, 2000.
[34]任盛伟, 李清勇, 许贵阳, 等. 鲁棒实时钢轨表面擦伤检测算法研究[J]. 中国铁道科学, 2011, 32(1): 25-29.
(REN Shengwei,LI Qingyong,XU Guiyang, et al. Research on Robust Fast Algorithm of Rail Surface Defect Detection [J]. China Railway Science, 2011, 32(1): 25-29. in Chinese)
[35]周威, 孙忠国, 任盛伟, 等. 基于多目立体视觉的接触网几何参数测量方法[J]. 中国铁道科学, 2015, 36(5): 104-109.
(ZHOU Wei, SUN Zhongguo, REN Shengwei, et al. Measurement Method for Geometric Parameters of Overhead Contact Line Based on Multi-View Stereovision [J]. China Railway Science, 2015, 36(5): 104-109. in Chinese)
[36]李清勇, 章华燕, 任盛伟, 等. 基于钢轨图像频域特征的钢轨波磨检测方法[J]. 中国铁道科学, 2016, 37(1): 24-30.
(LI Qingyong, ZHANG Huayan, REN Shengwei, et al. Detection Method for Rail Corrugation Based on Rail Image Feature in Frequency Domain [J]. China Railway Science, 2016, 37(1): 24-30. in Chinese)
[37]杜馨瑜. 电务轨旁设备外观巡检图像增强算法[J]. 中国铁道科学, 2016, 37(6): 97-105.
(DU Xinyu. Algorithm for Appearance Inspection Image Enhancement of Trackside Communication and Signal Equipment [J]. China Railway Science, 2016, 37(6): 97-105. in Chinese)
