Modeling and Analysis of Data Dependencies in Business Process for Data-Intensive Services
2017-04-08YuzeHuangJiweiHuangBudanWuJunliangChen
Yuze Huang, Jiwei Huang*, Budan Wu, Junliang Chen
State Key Laboratory of Networking and Switching Technology
Beijing University of Posts and Telecommunications, Beijing 100876, China
* The corresponding author, email: huangjw@bupt.edu.cn
I. INTRODUCTION
Data-intensive services are services which process large volumes of data to complete complex business goals. With the emergence of big data and the rapid development of services computing techniques, data-intensive services have been applied in several aspects,such as data analytics, IoT-based intelligent traffic control, multimedia processing, weather forecast, sensor-based monitoring systems,etc. A data-intensive service can be formulated by a business process, which composes a serial of atomic services in a pre-defined interaction relationship.
Most of the traditional research on business process modeling focused on the procedure of the activities, namely process-centric. It uses the process or graphical representation to describe the operation of the business process steps. Some process modeling language and workflow system has developed and also widely adopted. For instance, BPMN (Business Process Modeling Notation)[1] provides an easy understand notation language to create the graphical model of business process; BPEL(Business Process Execution Language)[2] , a kind of automation process language, has been widely used to describe services according to A prototype system based on jBPM for data-aware workflow is designed using our model, and has been deployed to Beijing Kingfore heating management system to validate the flexibility, efficiency and convenience of our approach for massive coding and large-scale system management in reality.
The remainder of this paper is organized as follows. Section 2 introduces the related work of this research. Section 3 presents the model and the architecture of data-aware business process system. Section 4 formulates data dependencies by LTL. Then we validate their satisfiability by an automaton-based model checking algorithm in section 5. Furthermore,we show our data-aware workflow prototype system in Section 6. Finally, we conclude this paper in Section 7.
In this paper, the authors jointly consider both the explicit control flow and the implicit data flow in business processes,and design a novel data-aware business process model called“DAWFlow”.a certain sequence to compose to the business process. Several workflow systems have also been developed based on this modeling approach. Such as the well-known open source business process management suite jBPM[3]and YAWL[4]. Although process-centric modeling approach is helpful to express process procedure, it rarely considers the data in business processes. With the growing popularity of data-intensive systems on the real-life, the traditional process modeling meets several challenges. In specific, (1) the lack of the specification of data semantics and data operations during the processes makes it very difficult to describe the business processes for guiding the design and implementation of the service systems; (2) it lacks of the ability to formulate the status of global data, resulting the difficulty in the analysis and evaluation of the process models; and (3) the model is not adaptive enough especially when the requirements on data analytics are changed. Therefore, with such process-centric models, a large amount of human work has to be involved to design and modify the codes and systems, which is time-consuming and error-prone.
To deal with such problems, one of the effective approaches is to model the processes from a data view point. Since business process is constantly consuming, operating and producing data throughout his whole lifecycle,the control flow and data flow should be jointly considered. Within the comprehensive business process modeling, dependency guarantee or validation on global data is a non-negligible problem in reality, and thus its related theories and techniques should be carefully studied accordingly.
In this paper, we make an attempt at filling this gap. Aiming at formulating data flows and data dependencies in business processes, we propose a novel data-aware business process model which is able to describe both explicit control flow and implicit data flow. Data dependencies are formulated by Linear-time Temporal Logic (LTL) at the modeling phase,and then their satisfiability is validated by an automaton-based model checking algorithm.
II. RELATED WORK
2.1 Data-aware /data-centric business process models
The traditional business process model emphasizes the control flow, and thus is called process-centric approach[5]. Although this process-centric method has been widely adopted in our real-life, it cannot reflect the importance of data entity in business processes, resulting in the difficulty of the mapping between process data and underlying database.
A typical data-aware modeling approach is artifact-centric produced by Nigam and Caswell in 2003[6]. This approach focused on augmented data records, known as “business artifacts” or simply “artifacts”, that correspond to key business-relevant objects, their lifecycles, and the operations of these artifacts invoked by services. Furthermore, some researchers explored artifact-centric workflow conceptual models. Hull[7] produced the design method of “artifact-centric” business process, and presented the BALSA framework (Business Artifacts, Macro Lifecycles,Associations and Services) . He designed the framework from four dimensions which are independent of each other during different design phases. Bhattacharya et al.[8] provided a formal model for artifact-centric business processes with complexity results. Damaggio et al.[9] also introduced an artifact-centric model, called GSM (Guard-Stage-Milestone),to specify the business entity lifecycles. Sun et al.[10] developed a framework called SeGA,which reduces the complexity in runtime management including runtime querying,constraints enforcement, and dynamic modification upon collaboration across possibly different BPM systems.
Despite of the existing efforts, “Artifact”has always been a basic idea for modeling data flow in some data-centric business processes. However, the specifications as well as its detailed implementation are still largely unexplored. Theories, algorithms, tools, and engines could be further studied accordingly.Also, most of the existing researches on “Artifact” ignored the control flow, which makes it difficult for software engineers and system managers to understand or implement the basic procedures in business processes.
2.2 Modeling and analysis of data entity
Although researchers have developed some prototype system with artifact-centric workflow system, few of them studied the data entity model. Damaggio et al.[11] analyzed the artifact system with data dependencies and use formal method to verify whether the system satisfies the business rule. There have been also some research works, which paid their attention to data dependencies, presenting several contributions in this area[12, 13]. Sun et al.[14] introduced a rule of mapping process data to underlying database data. But they did not present the prototype system about the artifact-centric workflow.
Formal analysis of business processes is another hot issue in present research, which have been discussed in many papers, whose investigates include reachability[15] and deadlock checking[16], Liu et al.[17] proposed an ACOM model and translated it into Petri net to analyze and validate the business process.But most of them rarely consider the data dependencies at the modeling phase in business process.
III. MODEL AND FRAMEWORK
3.1 Data-aware business process model
It is widely acknowledged that business process execution needs at least three types of data, which are workflow control data, workflow relevant data and workflow application data[18]. Data entity records valuable information for business operations and process procedures. It is a key element in business process modeling, which consists of workflow relevant data and workflow application data,and workflow control data is out of the scope of the research on data-aware business process modeling[6].
The neglect of process data modeling with dependencies may lead to the incompleteness of process description, and the programmers have to realize data operations at the coding phase, which makes it very difficult to analyze the relationships among data entities.The business process system becomes largescale, the amount of process data will rapidly increase accordingly, thus the dependency relationship will become complex. Hence, it is quite time-consuming and error-prone for the system developers to implement all the data operations at the coding phase. In this paper,we model data with dependencies to decrease the workload of programmer, to fill this gap.
Data entities include numeric data and nonnumeric data, all of which are stored in the underlying relational database. The numeric data considered here are over domain Q. We denote an instance of database by DB, and let A represent a set of arithmetic relationship between different data entities. We next define the data-aware business process as follows.
Definition 3.1 A data entity D is defined by a 4-tuple D=(N,α,κ,ℜ), where,
● N is the name of data entity.
● α is the attribute of data entity.
● κ=f:α→K where κ is a function,K⊆{Unique,PrimaryKey,LocalKey} indicates whether the entity is unique, a primary key, or a local key.
In Definition 3.1, we borrow the basic definitions from database to describe the attributes of a data entity, as a mapping function κ. The Unique marking indicates that such attribute of each data record should be globally unique.The Primarykey attribute is used to uniquely identify each record in the data entity. The LocalKey indicator expresses that the value this key holds should be locally unique for only a group of data records.
Definition 3.2 A service is a triple S=(Σ,Γ,ο), where,
● Σ is a nonempty set of data entities, the elements of which is defined by Definition 3.1.
Definition 3.3 A data-aware business process system is a 2-tuple DF=(Π,Τ) where,
● Π is a nonempty set of service.
resents the transitions between services.
Definition 3.4 The transition is a 2-tuple Τ=where,
● ϕ(x) represents the pre-condition of the transition, which decide the routing between business processes. It is an FO formula with free variables x over
We take a Beijing Kingfore heating repair process as an example in this paper to illustrate how our approach can be applied in reality.According to the business processes, we name the involved services as “Fill_RepairForms”,“Assign_Repairperson”, “Repair”, “Choose_Components”, “Replace_Components”, “Upload_RepairInfo”, and “TelephoneReview”.To enable the services, five tables are built in the underlying database, as follows.
Repair_Form(aID, aDate, aReason, Repair_Addr)
Customer_Info(aCust_ID, aCust_Last_Name, aCust_First_Name, aCust_Phone,aCust_Addr)
RepairPerson_Info(aRP_ID, aRP_Last_Name,aRP_First_Name, aRP_Phone)
Components(aPartID, aPart_type, aPart_Availability, aRep_Cost, aPart_Info)
Review_Info(aReviewID, aRepID, aResult)
In these tables, some of them are generated by system, others are input by participants.For instance, the data generated by system include aID, aDate, aPartID, aReviewID, aPart_Availability, etc. Note that the data which are input by participants must be written at first. It is helpful to detail the operations of data entities. The database must satisfy the following constraint on foreign keys:
Review_Info [aRepID]⊆Repair_Form[aID]
The operations of data entities. We define the WRITE operation of data entities bywhich denotes that service s1writes the data entity µ, whereµ′ is the successor of µ and we use γ to denote the undefined variable. The READ operation is defined bywhich denotes that service s2reads the data entity ν.
3.2 Data-aware business process framework
We give detailed procedures for modeling a data-aware business process, as follows.
Step 1. The first major step in this data-aware approach is to extract the data entities from large-scaled process data. Then the data entity is modeled. We should note that,data dependency is carefully considered in our modeling.
Step 2. The second step of our approach is to map the process data into persistent data.We bridge the process data between persistent data according to a certain logical rule which is predesigned according to detailed requirement analysis.
Step 3. The third step is to bind atomic service to corresponding data entity. In this step,we detailed the specification of data operation,including writing and reading, to accomplish the certain business goal of the atomic service.
Step 4. Finally, we compose the atomic services to a new procedural business process.Similar to traditional process-centric approach.
The framework of our approach for data-aware business process modeling is illuminated by figure 1, which can be divided into four layers and two key operations, which are“Underlying Database”, “Data Entity Model”,“Atomic Service”, “Process”, “Mapping” and“Binding”, respectively.
This four-layer framework is referred to as“DAWFlow”. It provides a novel perspective to survey the data-aware business process. Our model is especially useful for designing the detailed data operation in business process.
IV. DATA DEPENDENCIES
4.1 Basic data dependencies of business process
In this section, we discuss the basic data dependencies of business process, which contains the pre-condition, post-condition, and the relationship between data entities.
The pre-condition and post-condition are two important factors that determine the transitions among services. Here we use existential first-order sentences to express the pre-condition and post-condition. The Example of pre-condition and post-condition formulation is given in the following Example 4.1
Example 4.1 Choose_Components: If the components were damaged after the examination by the repairman, new ones will be selected in order to replace them, where a and c denote available number and cost number,respectively
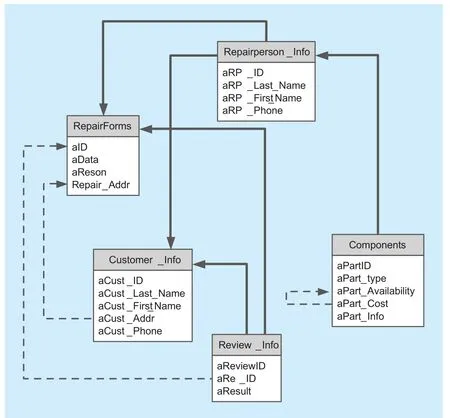
Fig. 2 Basic relationship between data entities for heating repair process

Besides the data dependency in an atomic service, the relationship between data in different services, which is also well-known as integrity constraints, has to be carefully considered during the design phase. The basic relationship among data entities can be classified into two types of relationship, which are sequence and correspondence. To express the basic idea, we build an acyclic graph to present the basic relationship of data entities,as figure 2. A solid line with arrow in figure 2 presents the sequence relationship of data entities. A dashed line with arrow denotes the correspondence of data entity.
4.2 Temporal properties of business process
In this part, we generalize our approach for modeling data dependencies from services to business processes. To specify the property of business process, we use LTL to specify the business rules of business process, which involve the data dependencies throughout the whole business process.
LTL is a modal temporal logic with modalities referring to time. It models time as a sequence of states, extending infinitely into the future[19]. It is universally acknowledged that temporal logic can be used to specify the requirements and characteristics of business process model, and thus we will use LTL to specify the data dependencies property of the data-aware business process. According to the characteristics of control flow, the business process can be divided into two types, which are Causal Type and Forbiddance Type. Their definitions as well as detailed formulations under LTL can be found as follows.
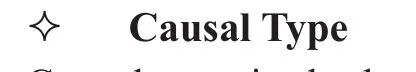
Causal type is the basic type of business process model, according to the sequence relationship of the atomic services, which means that whenever p holds, q must hold sometime in the future. It can be specified as the following forms as
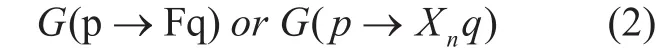
where F means q must hold in the future, and Xndefines that after exact n time steps q will hold.
✧ Forbiddance Type
Besides causal type, another popular property called forbiddance type has to be studied in order to formulate the data relationship in a business process. With LTL, we define G¬(p∧q) to indicate that service p and q will not occur together, and we let G(p→G(¬q ))mean that if service p holds, q must not hold always. Another example in our repair system is shown as below to specify this condition.
As aforesaid, we discuss the temporal property of business process, and use LTL to specify the property. Notice that, although LTL sentence focuses on the sequence of business process, we infuse the data dependencies into these properties, which gives us the whole perspective on data dependencies in a business process.
V. LTL SATISFIABILITY CHECKING
In order to check the correctness of the model we have designed, we should validate the satisfiability of these properties of data dependencies for business process before applying our model to system development. Here, we present an LTL satifiability checking algorithmic to automatically check whether the data-aware business process satisfy the given specification.
LTL satisfiability checking has been discussed for many years. Many researches focused on this problem, and proposed some valuable contribution on it. A systematic and authoritative research work was proposed by Rozier and Vardi[20, 21]. They considered that LTL checking can switch to the framework of model checking to complete the work. In this paper, we use such approach to check the LTL satisfiability.
Definition 5.1 LTL satisfiability. We call the LTL formula ϕ satisfiable, if and only if there is an infinite uniform sequence
Definition 5.2 Infinite uniform sequence.We call the infinite sequenceuniform, if and only if ωi(i≥ 0) is uniform.

How to construct the nondeterministic Büchi-automaton is one of the most important issues in our LTL satisfiability checking. Many researches have studied on this problem for more than thirty years with fruitful results[22].Among them, a typical algorithm named GPVW[23], which aimed at simplifying LTL formula to reduce the redundant edge of Büchi-automaton is integrated into our algorithm.The detailed procedures are shown by Algorithm 1.
The presentation of complete detailed procedures of the satisfiability checking of our model in the repair system is omitted due to the limitation of the context. However, the checking has been passed, proving that our model satisfies the data dependencies property formulated by LTL.
VI. PROTOTYPE SYSTEM
With all the definitions and algorithms presented above, we design a prototype system in order to advance our approach from theory to engineering application. Since there is no concrete concept of data-aware/data-centric business process model, we believe that the implementation of our prototype system may provide both researchers and engineers with better understandings about the developmentprocedures with our model, and further experiments may provide insights about the effectiveness and convenience of our approach.

Algorithm 1 Automaton-based LTL Satisfiability Checking
6.1 Design and implementation
We develop a data-aware workflow prototype system based on jBPM for data-intensive services, which we call “DatajBPM”. In order to support data flow that comes together with the traditional control flow, we remold the jBPM architecture, making it possible for software engineers to map the process data to persistent data.
The detailed architecture of our prototype system is illustrated by figure 3, the architecture of “DatajBPM” can be divided into three layers, i.e., resource environment layer(including business database, jBPM process engine, jBPM database and tomcat server),process platform layer (including data entity model and workflow parsing engine) and view layer. Process platform layer is the most important layer of this prototype system, which includes the data entity building module, data entity mapping module and binding module.All of the modules must be parsed by workflow parsing engine.
After comprehensive analysis of the requirements in business processes, we firstly construct the data entity, and then bridge the process data between database data. Figure 4 shows the detail view of data entity mapping.
We apply our “DatajBPM” to the maintenance section of Beijing Kingfore heating system. The system is a real-life household heating supply system that has been widely applied in Beijing, Hebei and Jilin provinces in china, covering 20 million square meters of houses and offices. The maintenance section of the system, which can be regarded as a subsystem, is an IT-based system supporting repair declaration and remote maintenance.
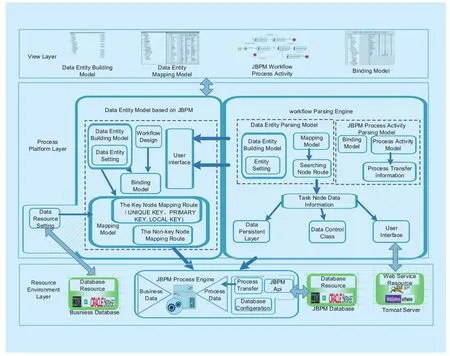
Fig. 3 Architecture of DatajBPM

Fig. 4 Detail view of data entity mapping
The data entities for repair process are shown as figure 5. Each repair has a unique ID (aID), repair information (aRepair_Info),customer information (aCustomer), repair address (aRepair_Addr) and several services information (aService_Info). Each service has a serviceID (aServiceID), several repair person information (aRepairperson), several replacement parts (aReplacement_Components)and review information (aReview_Info). The aID is indicated by UNIQUE. The aServiceID is indicated by Primary Key. The aCust_ID,aRP_ID, aPartID and aReviewID are indicated by Local key.
Figure 6 shows the business process,where the dashed frame shows the traditional process-centric business process. The solid frame shows the data entity model with the dependencies. The dashed line without arrow between the service and the data entity shows the operation of data entity for each service.
6.2 Functional evaluation
After developing the Kingfore repair system based on our data-aware approach, we compare it with the traditional approach. It is easy to know that our approach can reduce the development cycle of the system. Table 1 shows the detail data of development. From table 2,we can see that our data-aware approach can reduce the amount of code and the time of development by more than 60% due to the code automatic generation.
6.3 Performance evaluation
After evaluating the functionalities of our prototype system, we conduct an empirical performance evaluation on our system. We deploy our system on servers equipped with Intel Dual-Core CPU and 4GB memory and software environment of JDK 6.0, Eclipse 3.5, and MySQL 5.1. The performance of the system is evaluated by three metrics, which are booting time, resource consumption, and concurrency.6.3.1 Booting time
Booting time indicates the efficiency of the system to initialize basic hardware and soft-ware components. In our experiment, we cold start our system for ten times, and record the time of the system to initialize the business process, and the overall booting time when the system is ready to accept user requests. The specific data is shown by table 2 and 3. The release time of process initialization is 353.4 ms on average and can be strictly bounded in the range of 331 ms to 411 ms. The booting time of server is 5257.6 ms on average and can be stabilized at the range of 5007 ms to 5897 ms. For a business process management system, the booting time of our system is quite acceptable, and can be kept relatively stable.
6.3.2 Resource consumptionIn order to validate the efficiency of our approach, we monitor the system when it processes daily request from users, and record data of resource consumption, including CPU utilization, memory usage and the number of calling classes. Figure 7 shows the evaluation results. More Specifically, the CPU utilization can be stable at the range of 1% and 2%, and the number reaches 3.5% in some burst. Figure 7(b) shows the memory usage of the system, which is at the range of 20 MB ~ 40 MB,and the volatility of curves caused by Java garbage collection which is executed in every 2 minutes. As figure 7(c) shows, the number of calling classes during the execution of the system is stabilized about 6000. All of these results are satisfactory to the basic requirement of resource consumption for running the prototype system.

Table I Efficiency of the development

Table II Release time of process initialization

Table III Booting time of server
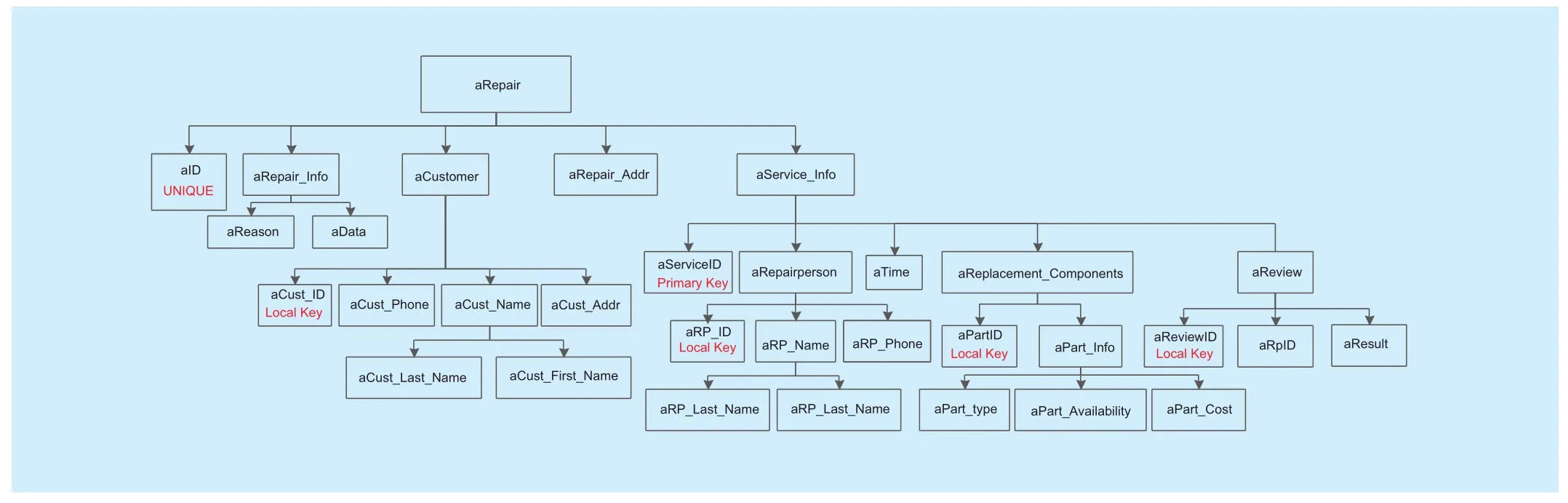
Fig. 5 Data entities for repair process
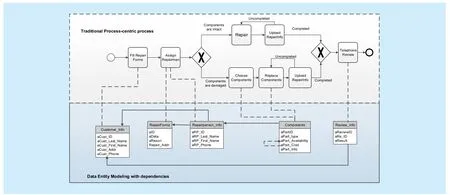
Fig. 6 Heating repair process
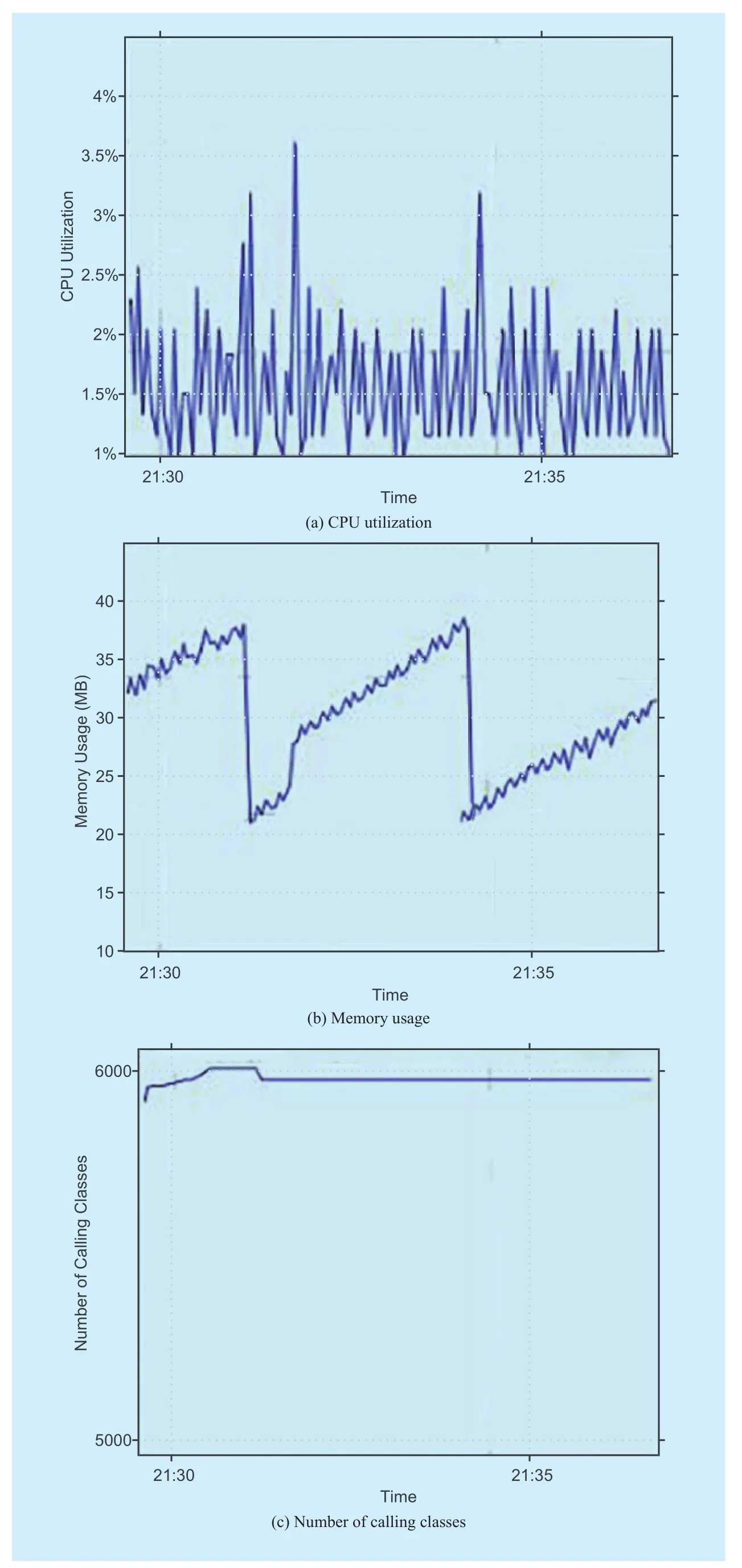
Fig. 7 Evaluation Result of Resource Consumption
6.3.3 Concurrency
We use Loadrunner to evaluate the concurrency of the prototype system. According to the statistics from reality, the total number of users in the maintenance system is about 6,000,and the burst rate of users arrival is 1000 per week. In order to represent the concurrency,we set the login users are 50 for per second at the same time, which satisfies the number of burst of user traffic.
Figure 8 and figure 9 show the throughput and the response time, respectively. In figure 8, the red line indicates the throughput and green line represents the number of concurrent users. The throughput is 51,947,302.593 bytes on average and can be strictly bounded in the range of 45 million to 85 million bytes after the system is stable from the 5th second.Figure 9 shows the average response time of the system. The response time is about 0.45 seconds on average and can be strictly in the range of 0.23 ~ 0.85 seconds.
In summary, based on “DatajBPM”, we can develop the workflow system with high flexibility and efficiency. According to our model, some data operation codes for the business process system can be automatically generated, which can improve the degree of standardization of project development and management, and avoid several human errors in programming, and save much time for system development.
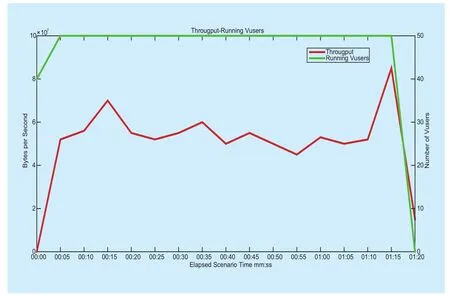
Fig. 8 Throughput of the system
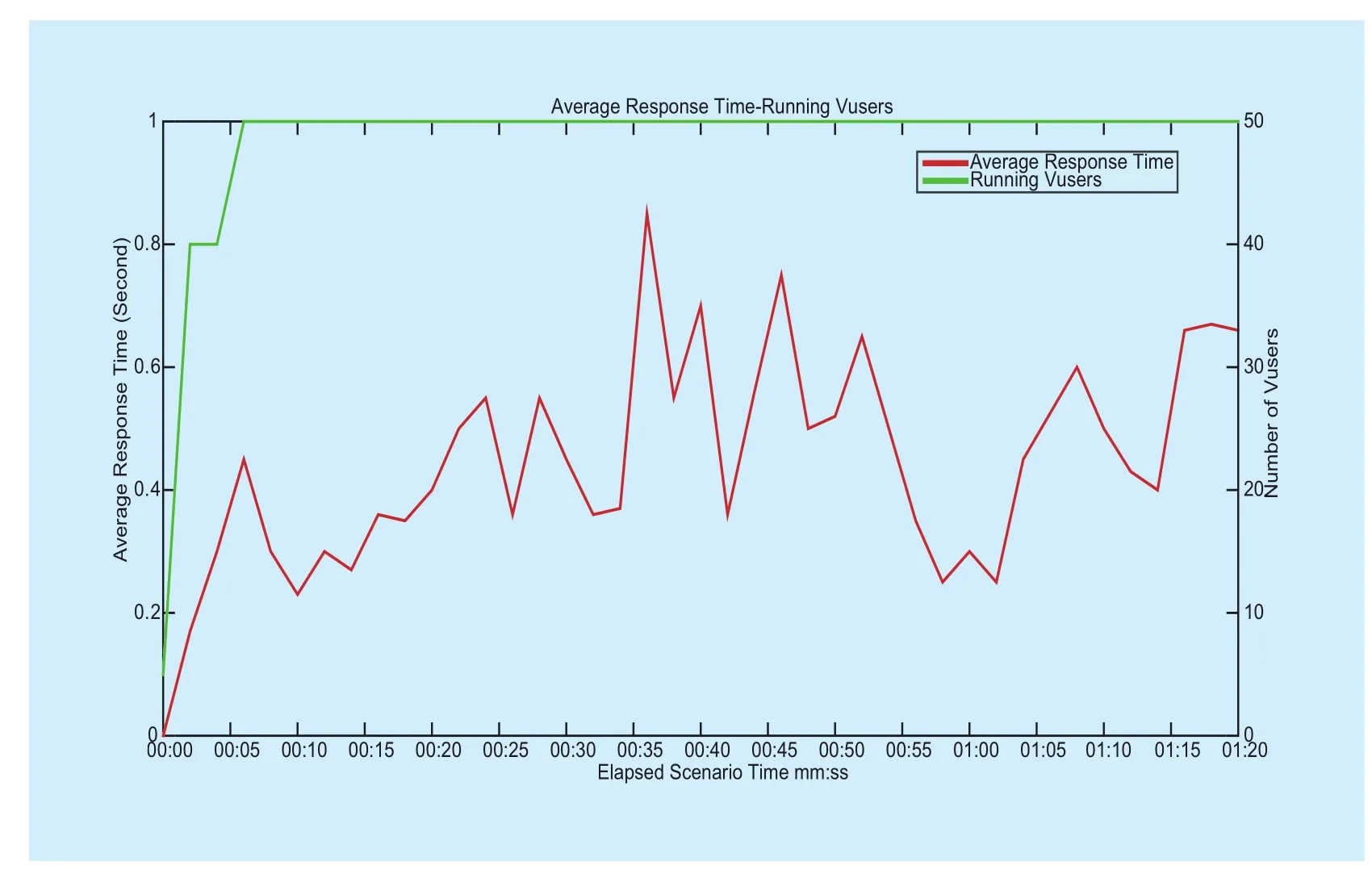
Fig. 9 Average response time
VII. CONCLUSION
In this paper, we jointly consider both the explicit control flow and the implicit data fl ow in business processes, and design a nov-el data-aware business process model called“DAWFlow”. Besides modeling the data entities themselves, we provide detailed specifications of the data operations, which bring the ability of our model to formulate data dependencies. LTL is employed to specify temporal properties of business process, and an automaton-based model checking algorithm is applied to validate its satisfiability. A data-aware workflow prototype system based on jBPM(called “DatajBPM”) is developed, which has been deployed in the Beijing Kingfore heating management system to validate the flexibility,efficiency and convenience of our approach.We believe that our approach can improve the automaticity of code generation and the adaptively of process execution, which is helpful in massive coding and large-scale system management in reality.
ACKNOWLEDGEMENTS
This work is supported by the National Natural Science Foundation of China (No. 61502043,No. 61132001), Beijing Natural Science Foundation (No. 4162042), and BeiJing Talents Fund (No. 2015000020124G082).
[1] O. OMG., “Business Process Model and Notation (BPMN) Version 2.0,” Object Management Group, Available: http://www.omg.org/spec/BPMN/2.0/
[2] D. Jordan et al., “Web services business process execution language version 2.0,” OASIS WSBPEL Technical Committee, OASIS 2007,Available:http://docs.oasis-open.org/wsbpel/2.0/Primer/wsbpel-v2.0-Primer.pdf.
[3] J. Koenig, “JBoss jBPM white paper,” JBoss Labs,Available: http://www.jboss.org/jbpm
[4] W. M. P. van der Aalst and A. H. M. ter Hofstede,“YAWL: yet another workflow language,” Information Systems, vol. 30, no. 4, 2005, pp. 245-275.
[5] W. M. P. Van der Aalst, A. H. M. Ter Hofstede, B.Kiepuszewski, and A. P. Barros, “Workflow patterns,” Distributed and Parallel Databases, vol.14, no. 1, 2003, pp. 5-51.
[6] A. Nigam and N. S. Caswell, “Business artifacts:An approach to operational specification,” IBM Systems Journal, vol. 42, no. 3, 2003, pp. 428-445.
[7] R. Hull, “Artifact-centric business process models: Brief survey of research results and challenges,” Proc. of OTM 2008 Confederated International Conferences CoopIS, DOA, GADA,IS, and ODBASE 2008, pp. 1152-1163.
[8] K. Bhattacharya, C. Gerede, R. Hull, R. Liu, and J.Su, “Towards formal analysis of artifact-centric business process models,” Proc. of 5th International Conference on Business Process Management, BPM 2007, pp. 288-304.
[9] E. Damaggio, R. Hull, and R. Vaculin, “On the equivalence of incremental and fixpoint semantics for business artifacts with Guard-Stage-Milestone lifecycles,” Information Systems, vol.38, no. 4, 2013, pp. 561-584.
[10] Y. Sun, J. Su, and J. Yang, “Universal Artifacts: A New Approach to Business Process Management (BPM) Systems,” ACM Transactions on Management Information System, vol. 7, no. 1,2016, pp. 1-26.
[11] E. Damaggio, A. Deutsch, and V. Vianu, “Artifact Systems with Data Dependencies and Arithmetic,” ACM Transactions on Database Systems, vol.37, no. 3, 2012, pp. 1-36.
[12] R. Khalaf, O. Kopp, and F. Leymann, “Maintaining data dependencies across BPEL process fragments,” International Journal of Cooperative Information Systems, vol. 17, no. 3, 2008, pp. 259-282.
[13] A. Meyer, L. Pufahl, D. Fahland, and M. Weske,“Modeling and enacting complex data dependencies in business processes,” Proc. of 11th International Conference on Business Process Management, BPM 2013, pp. 171-186.
[14] Y. Sun, J. Su, B. Wu, and J. Yang, “Modeling data for business processes,” Proc. of 30th IEEE International Conference on Data Engineering, ICDE 2014, pp. 1048-1059.
[15] D. Borrego, R. M. Gasca, and M. T. Gomez-Lopez, “Automating correctness verification of artifact-centric business process models,” Information and Software Technology, vol. 62, no.Jun, 2015, pp. 187-197.
[16] C. E. Gerede and J. Su, “Specification and verification of artifact behaviors in business process models,” Proc. of 5th International Conference on Service-Oriented Computing, ICSOC 2007,pp. 181-192.
[17] R. Liu, K. Bhattacharya, and F. Y. Wu, “Modeling business contexture and behavior using business artifacts,” Proc. of 19th International Conference on Advanced Information Systems Engineering, CAiSE 2007, pp. 324-339.
[18] “WfMC Standards: The Workflow Reference Model, Version 1.1,” Available: http://www.wfmc.org/standards/docs/tc003v11.pdf.
[19] C. Baier and J.-P. Katoen, Principles of model checking. MIT Press, 2008.
[20] K. Y. Rozier and M. Y. Vardi, “LTL satisfiability checking,” Proc. of 14th International SPIN Workshop: Model Checking Software, 2007, pp.149-167.
[21] K. Y. Rozier and M. Y. Vardi, “LTL satisfiability checking,” International journal of Software Tools for Technology Transfer, vol. 12, no. 2, 2010, pp.123-137.
[22] T. Babiak, M. Ketinsky, V. ehak, and J. Strejek,“LTL to Buchi automata translation: Fast and more deterministic,” Proc. of 18th International Conference on Tools and Algorithms for the Construction and Analysis of Systems, TACAS 2012,pp. 95-109.
[23] R. Gerth, D. A. Peled, M. Y. Vardi, and P. Wolper,“Simple on-the-fly automatic verification of linear temporal logic,” Proc. of International Symposium on Protocol Specification, Testing and Verification, 1995, pp. 3-18.
杂志排行

China Communications的其它文章
- Migration to Software-Defined Networks: the Customers’ View
- Software Defined Traffic Engineering for Improving Quality of Service
- Towards a Dynamic Controller Scheduling-Timing Problem in Software-Defined Networking
- Efficient Virtual Network Embedding Algorithm Based on Restrictive Selection and Optimization Theory Approach
- A Fast and Memory-Efficient Approach to NDN Name Lookup
- Energy-Efficient Joint Content Caching and Small Base Station Activation Mechanism Design in Heterogeneous Cellular Networks