一种基于时序的层次轨迹聚类算法
2017-04-05冷泳林鲁富宇
冷泳林, 鲁富宇
(渤海大学 a.信息科学与技术学院; b.教务处,辽宁 锦州 121000)
一种基于时序的层次轨迹聚类算法
冷泳林a, 鲁富宇b
(渤海大学 a.信息科学与技术学院; b.教务处,辽宁 锦州 121000)
聚类相似的运动轨迹,获取对象主要运动特征是轨迹路径聚类的目标之一。本文针对轨迹路径数据量大、传统整体轨迹聚类算法效率低等问题,提出了一种基于时序的层次轨迹聚类算法(hierarchical trajectory clustering algorithm based on time series,HTCTS)。算法首先将完整的轨迹数据按一定的时间间隔进行分割,然后对分割的子路径分别聚类,最后在对聚类子集进行二次聚类,生成最终的聚类结果。实验结果表明:HTCTS算法在聚类效率和聚类质量上高于整体轨迹聚类算法。
轨迹聚类;轨迹路径;相似性;AP算法
目前,物联网技术日趋成熟,他由物联网采集的数据无处不在。 轨迹数据就是其中一种重要的数据,其来源非常广泛,如动物移动路径、车辆运行路线、用户购买路线等等。 这些轨迹数据通常包括活动的时间、速度、位置等基础信息。通过对这些轨迹数据的分析,可以获取移动对象个体或群体运动的模式,如超市用户习惯路线图,鸟类迁徙时间、路线,道路交通情况等,辅助研究者和管理者做出决策分析[1-3]。
轨迹聚类是一种有效的分析轨迹数据的方法。 针对不同的轨迹数据,人们研究了大量轨迹聚类算法。如Caffney等提出的基于模型的轨迹聚类算法[4-7]。Lee等提出的TRACLUS,一种执行在全部子轨迹集合上的基于密度的聚类算法[7]。Ahmed Kharrat 等提出的NETSCAN,一种在路网空间下的基于密度的轨迹聚类方法。NETSCAN先是根据移动对象经过的道路计算出繁忙路径,然后根据用户设置的密度参数对子轨迹进行聚类[8]。Xia Ying等[9]提出了一种在路网约束下综合考虑时间和空间约束的轨迹相似性度量方法,并应用于轨迹聚类。
由于采集的轨迹数据量越来越庞大,传统的聚类算法不能有效地聚类大规模的轨迹数据。本文提出了一种基于时序的层次轨迹聚类算法(HTCTS)。 算法首先将一个完整的轨迹数据按一定的时间间隔进行分割,然后对每一个时间间隔内的数据分别进行聚类,形成聚类子集。最后在对聚类子集进行二次聚类,生成相应的聚类结果。
1 相关概念
1.1 轨迹聚类


1.2 AP聚类算法
仿射传播(affinity propagation,AP)聚类通过计算N个数据点间的相似度进行聚类。这N个数据点间的相似度可以用一个N×N的矩阵S表示。不同于其它聚类算法,AP聚类不需要指定聚类中心,在聚类的过程中,AP聚类算法将所有的数据点都作为潜在的聚类中心(exemplar),第k个数据点能否成为聚类中心的评判标准是判断该点在矩阵对角线上对应的值S(k,k),S(k,k)的值越大,k点成为聚类中心的可能性就越大, 这个值又称为参考度p(preference)。AP聚类的数目受p的影响。初始时,如果认为每个数据点都有可能成为聚类中心,则令p取相同的值,如果p取输入相似度的均值,则产生的聚类数目为中等,如果取最小值,则聚类产生的数目也较少[10]。
AP聚类算法通过迭代的过程在数据点间传递两种类型的消息,它们分别是吸引度(responsibility)和归属度(availability)。这两类消息分别对应吸引度矩阵R和归属度矩阵A。其中R(i,k)表示从数据点i发送到候选聚类中心k的数值消息, 反映了数据点k是否适合作为数据点i的聚类中心。而A(i,k)表示从候选聚类中心k发送到数据点i的数值消息,反映了数据点i是否选择k作为其聚类中心。R(i,k)与A(i,k)越大,则数据点k作为聚类中心的可能性就越大,i点越容易选择k点作为聚类中心。
AP聚类通过迭代过程不断更新吸引度矩阵和归属度矩阵,直到产生k个高质量的exemplar。吸引度矩阵的更新是用归属度矩阵A和相似度S实现,如式(1)所示:
(1)
归属度矩阵的更新用吸引度矩阵实现,如式(2)所示。
(2)
2 基于时序的层次轨迹聚类算法
2.1 算法概述
本文提出了一种基于时序的轨迹聚类算法。因为不同时段轨迹路径之间的关联程度要远远小于间隔内轨迹路径之间的关联,所以算法首先将一个完整的轨迹数据按一定的时间进行分割。然后对每一个时间间隔内的数据分别利用AP聚类算法进行聚类,生成相应的聚类子集。为实现轨迹数据的整体聚类,算法对聚类子集进行二次AP聚类,最后生成相应的聚类结果。
2.2 相似性度量
计算对象间的相似性是聚类算法的基础,本文聚类算法涉及两种相似性的度量。一种是两条子轨迹的相似性度量,另一种是两个子聚类集合之间的相似性度量。
2.2.1 轨迹线段相似性度量
文献[11]认为两条子轨迹之间的相似性由中心点相似性(simicenter)、角度相似性(simiθ)和平行相似性(simiparallel)3部分构成,见式(3)。其中,L1、L2分别对应2个子轨迹,L1表示较长的子轨迹,L2表示较短的子轨迹。
simi(L1,L2)=simicenter(L1,L2)+
(3)
子轨迹中心点相似性用欧几里得距离进行计算,其中和分别对应两条子轨迹的中心点。
(4)
在子轨迹角度相似性计算中,用θ表示两条子轨迹间较小的交叉角。由于本文不考虑子轨迹的方向性,因此θ的取值满足0°≤θ≤180°。式(5)给出了子轨迹角度相似性的计算方法。
(5)
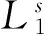
(6)
(7)
则两条子轨迹的并行相似性为para1和para2的最小值,如式(8)所示。
simiparallel(L1,L2)=min(para1,para2)
(8)
2.2.2 代表子轨迹
采用元组TL={N,LScenter,LSθ,LSlength}来描述子轨迹聚类后每个聚类子集合的信息,其中N代表聚类中子轨迹的数目,LScenter,LSθ,LSlength分别表示所有子轨迹中心点、角度和长度总和。

(9)
(10)

图1 代表子轨迹
2.3 HTCTS算法
给定轨迹路径集合TR和时间间隔参数t,HTCTS算法的步骤如下:
步骤1 根据给定的时间间隔分割轨迹路径集合TR,将轨迹路径集合中的轨迹路径简化成子轨迹集合。
步骤2 依据式(3)计算每一个时间间隔内子轨迹的相似性,并应用AP聚类生成聚类子集。
步骤3 计算每一个聚类子集的代表子轨迹。
步骤4 计算代表子轨迹间相似性。
步骤5 应用AP聚类算法聚类代表子轨迹。
步骤6 将相应的聚类子集分配到所属代表子轨迹所在聚类。
步骤7 输出聚类结果C。
3 实验
为了验证HTCTS算法的性能,设置实验的运行环境是Windows XP professional操作系统, 硬件配置包括Intel Xeon 2.00GHz、2GB内存、500G硬盘。HTCTS算法的编写采用 C++ 语言和gcc编译器,轨迹数据存储在SQL Server 2000。实验数据集来自微软亚洲研究院领导的一个Geolife项目*http://research.microsoft.com/en-us/projects/urbancomputing/.。数据集中包括了2007年4月到2012年8月之间的182个用户的轨迹数据。本文随机从数据集中选择了100个用户在1天之间的轨迹数据进行实验。实验从聚类时间和聚类数目2个角度进行衡量。本文的聚类时间包含路径分割、路径简化、相似度计算和2次聚类。每次实验重复5次,聚类时间为5次的平均值。由于AP聚类自动发现聚类中心,并分配节点到相应的聚类,因此聚类数目无法确定,但通过聚类数目,可以判断算法发现有效路径的能力。如果聚类集合子轨迹数目低于某一阈值,则认为这些子轨迹是噪音数据,由其产生的路径不具有普遍性。
3.1 聚类质量评价
实验按一定时间间隔将轨迹数据进行分割, 然后对分割轨迹数据采用HTCTS算法进行聚类。 表1列出了不同时间间隔轨迹路径聚类时间和聚类数目。从实验结果分析, 聚类时间间隔对聚类效率影响不大。如将轨迹路径按1 h时间间隔划分时,聚类时间为2.67 s。而当时间间隔缩小至0.5 h,聚类时间只增加了0.16 s。其原因在于短时间间隔内的子轨迹数目低于长时间间隔子轨迹数目, 相应的每次聚类子轨迹之间相似性计算量和聚类子轨迹规模都下降。虽然聚类次数增加,但由于每次聚类数据量远小于长时间间隔的数据量,因此迭代次数也低于长时间间隔的聚类迭代次数,因此时间变化不明显。
本实验中统计的聚类数目只选择子轨迹数目高于一定阈值的聚类结果,本文设定为20。其余低于阈值的聚类结果被视为噪音区,即不是所有用户共同拥有的特征。聚类数目实验结果表明:时间间隔的设置将影响聚类数目的变化,由于AP聚类不需要指定聚类数目,算法在迭代的过程中会逐步发现聚类中心。当时间间隔长时,有一些比较稀疏的轨迹段被列为噪音区,因此聚类数目低于短时间间隔的聚类数目。

表1 HTCTS轨迹路径聚类质量
3.2 同类算法的对比
本文将HTCTS同TRACLUS和DBSCAN聚类算法相比。从图2可以看出:HTCTS在聚类轨迹路径时具有更好的运行效率,且聚类数目也多余其它算法。其主要原因在于HTCTS通过时间分割将轨迹路径划分成子集进行聚类,由于各时间间隔的轨迹路径关联性不大,因此这种分割并没有影响聚类质量,但时间效率却得到了提升。

图2 不同算法之间性能比较
4 结束语
随着物联网技术在各个领域的广泛应用,通过手机、GPS等可用设备可以获取大量可用的轨迹数据,分析这些数据可以获取巨大的商业价值,也可以辅助社会管理者做出重要决策。如本文通过聚类用户的活动数据,可以发现这些用户频繁活动的路径、不同时间重点活动区域等信息,进而总结一类人群在一个时间段内(如工作日)的工作模式和社会规律,为商业、交通提供有价值信息,更好地提高社会管理质量和服务水平。
传统轨迹聚类算法大都针对完整的轨迹路径进行,针对整体轨迹路径数据量大、聚类效率低、一定时间间隔内轨迹路径关联性更大等原因,本文提出了一种基于时序的层次轨迹聚类算法(HTCTS)。HTCTS将轨迹路径进行2种分割:第一种是为实现分块聚类而进行的时间分割;第二种是为确定聚类对象而进行的子轨迹分割。HTCTS接着采用二次聚类方式对轨迹路径进行聚类,其中,第1次是聚类每个时间间隔内的子轨迹;第2次是对子轨迹聚类结果进行整体聚类。实验验证了不同时间间隔对聚类结果的影响,并且将HTCTS算法同整体轨迹聚类算法进行对比。结果表明:HTCTS的聚类效率和聚类质量有很大的提高。
[1] ZHENG Y,ZHOU X F.Computing with spatial trajectories[M].Berlin:Springer,2011.
[2] 袁冠,夏士雄,张磊,等.基于结构相似度的轨迹聚类算法[J].通信学报,2011,32(9):103-110.
YUAN Guan,XIA Shixiong,ZHANG Lei,et al.Trajectory clustering algorithm based on structural similarity[J].Journal on Communications,2011,32(9):103-110.
[3] 曲冰洁.基于物联网技术的煤矿智能物流的支撑器件与技术态势[J].电子元件与材料,2014,33(5):103-104.
QU Bingjie.Supporting Device and Technology Situation of Frozen Coal Mine Intelligent Logistics Networking Technology Based on [J].Electronic Components and Materials,2014,33(5):103-104.
[4] GAFFNEY S and SMYTH P.Trajectory clustering with mixtures of regression models[C]//proceedings of the 5th International Conference on Knowledge Discovery and Data Mining.USA:[s.n],1999:63-72.
[5] CADEZ I V,GAFFNEY S,and SMYTH P.A general probabilistic framework for clustering individuals and objects[C]//proceedings of the 6th International Conference on Knowledge Discovery and Data Mining.USA:[s.n],2000:140-149.
[6] GAFFNEY S J,ROBERTSON A W,SMYTH P,et al.Probabilistic clustering of extratropical cyclones using regression mixture models[J].Climate Dynamics,2007,29(4):423-440.
[7] LEE J G,HAN J,WHANG K Y.Trajectory clustering:a partition-and-group framework[C]//ACM SIGMOD International Conference on Management of Data.USA:[s.n],2007:593-604.
[8] KHARRAT A,POPA I S,ZEITOUNI K,et al.Clustering Algorithm for Network Constraint Trajectories[C]//Headway in Spatial Data Handling,International Symposium on Spatial Data Handling.USA:[s.n],2008:631-647.
[9] XIA Y,WANG G Y,ZHANG X et al.Research of spatio-temporal similarity measure on network constrained trajectory data[J].International Journal of Computational Intelligence Systems,2010,4(5):491-498.
[10]FREY B J,DUECK D.Clustering by passing messages between data points[ J].Science,2007,315(5814):972-976.
[11]LI Z,LEE J G,LI X,et al.Incremental clustering for trajectories[C]//International Conference on Database Systems for Advanced Applications.USA:[s.n],2010:32-46.
(责任编辑 刘 舸)
A Hierarchical Trajectory Clustering Algorithm Based on Time Series
LENG Yong-lina, LU Fu-yub
( a.College of Information Science and Technology; b.Office of Academic Affairs, Bohai University, Jinzhou 121000, China)
Clustering movement trajectories to get the motion feature of object are one of the goals of the trajectory clustering. Aiming at the large scale trajectory data, to address the low efficiency of clustering, this paper proposes a hierarchical trajectory clustering algorithm based on time series (HTCTS). The algorithm first divides trajectory data by time interval, and then respectively clusters the sub paths. Finally, for all cluster subset, HTCTS executes cluster algorithm again to produce the final clustering results. The experimental results show that HTCTS algorithm in clustering efficiency and quality is superior to the trajectory clustering algorithms which cluster the whole dataset directly.
trajectory clustering; trajectory path; similarity; AP clustering
2016-11-10 基金项目:辽宁省社科基金资助项目(L14AGL002,L13AGL002);辽宁省教育科学规划十三五项目(JG16DB009);辽宁省社科联2015年度合作项目(lslgslhl-020)
冷泳林(1978—),女,辽宁营口人,硕士,副教授,主要从事数据挖掘、数据存储与索引研究,E-mail:lengyonglin@qq.com;鲁富宇(1980—),男,硕士,主要从事数据挖掘研究。
冷泳林, 鲁富宇.一种基于时序的层次轨迹聚类算法[J].重庆理工大学学报(自然科学),2017(3):123-127.
format:LENG Yong-lin, LU Fu-yu.A Hierarchical Trajectory Clustering Algorithm Based on Time Series [J].Journal of Chongqing University of Technology(Natural Science),2017(3):123-127.
10.3969/j.issn.1674-8425(z).2017.03.018
TP311
A
1674-8425(2017)03-0123-05
