基于迭代神经动态规划的数据驱动非线性近似最优调节
2017-04-01王鼎穆朝絮刘德荣
王鼎 穆朝絮 刘德荣
基于迭代神经动态规划的数据驱动非线性近似最优调节
王鼎1,2穆朝絮2刘德荣3
利用数据驱动控制思想,建立一种设计离散时间非线性系统近似最优调节器的迭代神经动态规划方法.提出针对离散时间一般非线性系统的迭代自适应动态规划算法并且证明其收敛性与最优性.通过构建三种神经网络,给出全局二次启发式动态规划技术及其详细的实现过程,其中执行网络是在神经动态规划的框架下进行训练.这种新颖的结构可以近似代价函数及其导函数,同时在不依赖系统动态的情况下自适应地学习近似最优控制律.值得注意的是,这在降低对于控制矩阵或者其神经网络表示的要求方面,明显地改进了迭代自适应动态规划算法的现有结果,能够促进复杂非线性系统基于数据的优化与控制设计的发展.通过两个仿真实验,验证本文提出的数据驱动最优调节方法的有效性.
自适应动态规划,数据驱动控制,迭代神经动态规划,神经网络,非线性近似最优调节
最优控制研究如何设计控制器使得系统的性能指标达到最优.它广泛存在于工程技术和社会生活中,是现代控制理论的重要内容之一.与线性系统的最优控制问题需要求解Riccati方程不同,研究非线性系统的最优控制通常需要求解非线性Hamilton-Jacobi-Bellman(HJB)方程.例如,对于离散时间非线性系统而言,这一过程就包含求解非线性偏微分方程,这在很多情况下是难以实现的.虽然动态规划是求解最优控制问题的经典方法,但是其后向求解的特点往往导致“维数灾”现象的发生[1],同时这种后向求解模式也不利于该方法的实际应用.于是,基于人工神经网络良好的自适应、自学习等特性,自适应(或者近似)动态规划(Adaptive/approximate dynamic programming,ADP)方法应运而生[2].文献[3−5]针对ADP方法的基本原理、实现结构和目前的发展状况,给出了阶段性总结与研究展望,并且指出ADP实际上是一种有效的数据驱动方法[5−6].根据文献[2]和文献[7],可以将ADP方法划分为三种主要结构:1)启发式动态规划(Heuristic dynamic programming,HDP);2)二次启发式动态规划(Dual heuristic dynamic programming, DHP);3)全局二次启发式动态规划(Globalized DHP,GDHP).在与上述内容相关的三种执行依赖结构(Action-dependent)中,执行依赖HDP类似于机器学习领域的Q-学习(Q-learning)[8].另外,Si和Wang[9]提出的神经动态规划也是一种类似于执行依赖HDP的在线学习控制方法,具有容易实现、在线优化、不依赖被控对象模型等特点,对于ADP结构的发展产生了很大的影响.但是,值得注意的是,上述神经动态规划方法的重点在于强调控制系统的在线学习与优化设计,没有从理论上证明控制算法的收敛性,因此可以看到,实验结果的成功具有一定的概率.
近年来,正在兴起的许多社会和工程新技术的重要特点是拥有实时海量的大数据信息[10].在大数据技术快速发展的背景下,随着对数据驱动思想和类脑学习理念的深入研究,ADP已经发展成为进行智能控制与优化设计的有效途径,因此受到了许多学者的重视.针对离散时间系统[11−20]和连续时间系统[21−26],这种基于数据的自学习控制都取得了丰硕的研究成果.Al-Tamimi等[11]针对离散时间仿射非线性系统xk+1=f(xk)+g(xk)uk,首次提出基于贪婪迭代的HDP算法研究无限时间最优控制设计,创造性地将求解代数方程的迭代思想引入ADP方法的框架之中.这促进了迭代ADP算法的快速发展,由此涌现出大量的研究成果[12−19].在基本的迭代ADP算法中,一般需要构建两个神经网络,即评判网络和执行网络,分别用以近似代价函数和控制函数.然后利用特定的最优化算法,通过在迭代过程中不断更新神经网络的权值矩阵,从而自适应地学习最优权值.值得一提的是,Wang等[14]针对有限时间域上的非线性最优控制问题,提出迭代ε-ADP算法,得到和文献[11]不同的收敛性结论,从全新的角度诠释迭代ADP算法的精髓.但是,也应该注意到,在现有的迭代ADP算法中,针对执行网络的训练大多数依赖于控制矩阵g(xk)的直接信息或者其神经网络表示,也就是在一定程度上依赖于系统动态.于是,Zhong等[19]提出一种新的目标导向型(Goal representation)ADP结构求解非线性系统的在线优化控制,以发展神经动态规划的结论,放松对系统动态的要求,但是基于HDP的实现结构导致评判网络不能直接输出代价函数的导函数信息,而且HDP结构的控制效果也有待改进.实际上,已有的研究表明,在ADP方法的实现结构中,DHP和GDHP会在一定程度上得到比HDP更好的控制效果[12,16].总的来说,虽然基于ADP的非线性系统最优控制研究已经取得了很大的进展,但是仍然缺少基于GDHP实现结构的迭代意义下神经动态规划的报道,因此对于现有执行网络的更新方法也鲜有改进.基于此,本文提出一种基于迭代神经动态规划的离散时间非线性系统数据驱动近似最优控制方法,旨在改进执行网络的训练方法,进一步降低迭代ADP算法对于控制系统动态模型的依赖,促进基于数据的复杂非线性系统优化控制的发展.
1 问题描述
考虑离散时间非线性系统

其中,k是描述系统运行轨迹的时间步骤,xk=[x1k, x2k,···,xnk]T∈Ωx⊂Rn为系统的状态向量,uk=[u1k,u2k,···,umk]T∈Ωu⊂Rm为系统的控制向量.我们设定时间步骤k=0时的状态x0=[x10, x20,···,xn0]T为被控系统的初始状态向量.这里,式(1)描述的是一般意义下的离散时间非线性系统.容易知道,具有仿射形式的非线性系统,即xk+1=f(xk)+g(xk)uk,其中,g(xk)为控制矩阵,是系统(1)的一种特殊情况.这里给出下面两个基本假设[11−12,16].
假设1.动态函数F(·,·)在属于Rn并且包含原点的集合Ωx上Lipschitz连续且有F(0,0)=0,因此,x=0是系统(1)在控制u=0时的一个平衡状态.
假设2.动态系统(1)可控,即在集合Ωu中存在一个能够渐近镇定被控系统的连续控制律,使得在其作用下产生的控制输入序列能够将系统从初始状态转移到平衡状态.
本文研究无限时间域上的最优调节器设计问题.这里,最优调节的目标是设计一个状态反馈控制律u(x),将系统从初始状态x0镇定到平衡状态,同时使得在其作用下的(无限时间)代价函数

达到最小,其中,U是效用函数,U(0,0)=0,且对于任意的xp,up,有U(xp,up)≥0,折扣因子γ满足0<γ≤1.方便讨论起见,选取二次型形式的效用函数U(xp,up)=xTpQxp+uTpRup,其中,Q和R为正定矩阵.事实上,对于最优控制问题,待设计的反馈控制律不仅能够在Ωx上镇定被控系统,而且使得相应的代价函数有限,这就是容许控制的概念[11−12,16].
根据经典的最优控制理论,最优代价函数

可以写为

于是,J∗(xk)满足离散时间HJB方程

相应的最优控制为

注1.通过式(4)发现,求解当前时刻k的最优控制u∗,需要得到最优代价J∗,但是却与系统下一时刻的状态向量xk+1有关,这在当前时刻是不能做到的.因此,在难以得到HJB方程解析解的情况下,有必要研究如何获得其近似解.ADP以及随后出现的迭代ADP算法,就是为了克服这些难题而提出的近似求解方法.
2 迭代ADP算法及其收敛性
根据迭代ADP算法的基本思想[11−13,16],需要构建两个序列,即代价函数序列{Vi(xk)}和控制律序列{vi(xk)},通过迭代运算得到收敛性结论.这里,记i为迭代指标,并初始化代价函数V0(·)=0.对于i=0,1,···,迭代过程包括不断计算控制律和更新代价函数
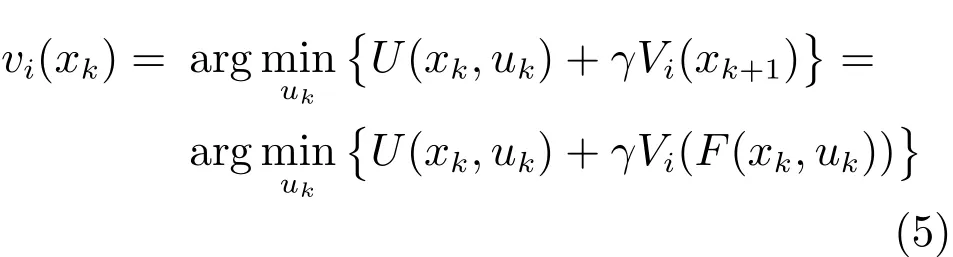

直到算法收敛(当i→∞ 时,有Vi→J∗和vi→ u∗).
在证明上述迭代算法的收敛性与最优性之前,首先给出下面两个引理[11−12,16].
引理1.(有界性)定义代价函数序列{Vi(xk)}如式(6)所示.如果系统可控,则存在一个上界Y使得对于任意的i,都有0≤Vi(xk)≤Y成立.
引理2.(单调性)定义代价函数序列{Vi(xk)}如式(6)所示且有V0(·)=0,同时定义控制律序列{vi(xk)}如式(5)所示.那么,{Vi(xk)}是一个单调非减序列,即0≤Vi(xk)≤Vi+1(xk),∀i.
定理 1.定义代价函数序列{Vi(xk)}如式(6)所示,且V0(·)=0,控制律序列{vi(xk)}如式(5)所示.执行迭代ADP算法,代价函数序列{Vi(xk)}收敛于离散时间HJB方程中的最优代价函数J∗(xk),即当i→ ∞ 时,有Vi(xk)→ J∗(xk).相应地,当i→∞ 时,{vi(xk)}收敛于最优控制律u∗(xk),即limi→∞vi(xk)=u∗(xk).
证明.根据引理1和引理2,代价函数序列{Vi(xk)}单调非减且有上界,所以,它的极限存在.定义limi→∞Vi(xk)=V∞(xk)为其极限.
一方面,对于任意的uk和i,根据式(6),可得

由引理2,对于任意的i,都有Vi(xk)≤V∞(xk)成立.因此,式(7)变为
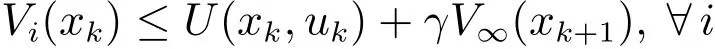
令i→∞,则

考虑到式(8)中的控制向量uk是任意的,可以得到
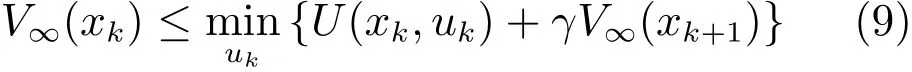
另一方面,由于对任意的i,迭代过程中的代价函数满足

再次考虑Vi(xk)≤V∞(xk),我们有

令i→∞,则

结合式(9)和式(10),可以得到
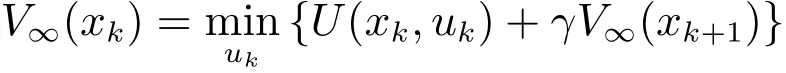
同样地,记limi→∞vi(xk)=v∞(xk)为控制律序列{vi(xk)}的极限.根据式(5)和式(6),有

其中,

注意式(11)和式(3),同时注意式(12)和式(4),可以得到,V∞(xk)=J∗(xk)和v∞(xk)=u∗(xk),即,limi→∞Vi(xk)=J∗(xk)且limi→∞vi(xk)= u∗(xk).由此验证了迭代算法的收敛性和最终得到的控制律的最优性. □
注2.利用迭代代价函数的表达式(6),依据迭代指标i逐次进行递推,我们有

进而,考虑到V0(xk+i+1)=0这一事实,可以将迭代代价函数Vi+1(xk)写成关于效用函数加和的形式

观察式 (13)可以发现,在迭代代价函数Vi+1(xk)中,构成效用函数的控制输入序列是由一个控制律组(vi,vi−1,···,v0)产生的,即其中的每一个控制输入都依赖于不同的控制律,因此控制输入是vi−l(xk+l)的形式,其中,l=0,1,···,i.尽管如此,最终作用到被控对象的控制律,是经过上述迭代算法之后得到的收敛的(状态反馈)控制律.事实上,根据定理1和容许控制的概念,最终得到的v∞=u∗是一个可以镇定系统的稳定控制.在其作用下,将会产生一个控制输入序列,实现被控非线性系统的最优调节.
3 迭代神经动态规划及其实现
由于这里研究的被控对象是一般的非线性系统,难以直接求解HJB方程.虽然通过执行迭代ADP算法(5)和(6),可以从理论上得到最优控制律和最优代价函数,但是迭代控制律和代价函数的信息是不能精确获得的,而且进行迭代运算需要被控系统的近似动态信息.所以,利用函数近似结构(例如神经网络)来重构系统动态以及vi(xk)和Vi(xk).这里,将基于神经动态规划思想的迭代ADP算法称为迭代神经动态规划方法.本节给出基于GDHP技术的迭代神经动态规划实现方案,包含构建三种神经网络,即模型网络、评判网络和执行网络.
3.1 模型网络
为了不依赖被控系统的动态信息F(xk,uk),在执行主要的迭代过程之前,首先构建一个模型网络并记隐藏层神经元个数为Nm,输入层到隐藏层的权值矩阵为νm∈R(n+m)×Nm,隐藏层到输出层的权值矩阵为ωm∈RNm×n.输入状态向量xk和近似的控制向量ˆvi(xk)如下文所示,模型网络的输出为
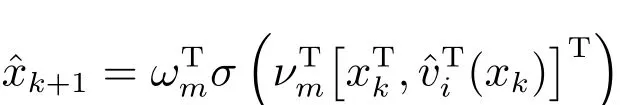
其中,σ(·)∈RNm为激活函数(下同).模型网络的误差函数为emk= ˆxk+1−xk+1,训练目标函数为Emk=(1/2)eTmkemk.利用梯度下降法更新模型网络的权值矩阵

其中,αm>0是模型网络的学习率且j是训练权值参数的迭代指标.当模型网络经过充分学习之后,保持其权值不再改变,并开始执行迭代神经动态规划的主要步骤,即训练评判网络和执行网络.
3.2 评判网络
评判网络的作用是近似代价函数Vi(xk)及其偏导数(称为协函数,记为λi(xk),即λi(xk)根据定理1,当i→ ∞ 时,Vi(xk)→ J∗(xk).由于则相应的协函数序列{λi(xk)}在i→∞时也是收敛的,即λi(xk)→λ∗(xk).这在仿真研究中也会得到验证.
设评判网络的隐藏层神经元个数为Nc,输入层到隐藏层的权值矩阵为νc∈Rn×Nc,隐藏层到输出层的权值矩阵为ωc∈RNc×(n+m).在进行第i次迭代时,可以将权值矩阵写为νci和ωci,于是,评判网络的输出为


这里,GDHP技术中评判网络的结构如图1所示.可以看出,它将HDP和DHP技术中的评判网络进行了融合.
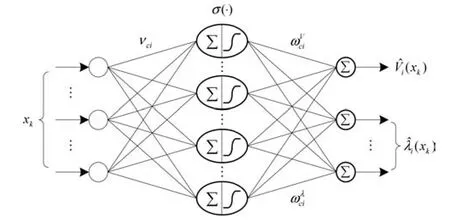
图1 评判网络结构Fig.1 The architecture of critic network
在GDHP实现结构中,评判网络的训练目标由代价函数和协函数两部分组成,即

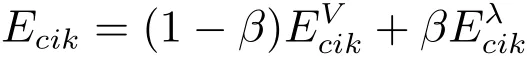

其中,αc>0为评判网络的学习率,j为更新权值参数的迭代指标,0≤β≤1是一个常数,反映HDP和 DHP在GDHP技术中相结合的权重大小.
注3.这里采用的GDHP技术综合了HDP能够直接输出代价函数和DHP控制效果好的优点.虽然引入协函数会在一定程度上增加计算复杂度,但是可以获得比初等的ADP方法(例如HDP)更好的运行效果.
3.3 执行网络
构建执行网络的作用是近似控制律,设其隐藏层神经元个数为Na,输入层到隐藏层的权值矩阵为νa∈Rn×Na,隐藏层到输出层的权值矩阵为ωa∈RNa×m.在上述的迭代环境下,我们将权值矩阵写成νa(i−1)和ωa(i−1)的形式,则执行网络的输出为


其中,αa>0是执行网络的学习率,j是更新权值参数的迭代指标.
总的来说,本文提出的迭代神经动态规划的结构如图2所示,其中,模块γDX表示ˆxk+1关于xk的偏导数计算结果n×n方阵的γ倍.
注4.传统的迭代ADP算法,例如文献[11−18],在训练执行网络时需要利用控制矩阵的直接信息或者其神经网络表示. 其中,针对仿射系统[11−13,15,17],需要系统控制矩阵的直接信息g(xk)[11,12,17],或者辨识控制矩阵得到其近似表示ˆg(xk)[13,15];针对非仿射系统[14,16,18],也需要神经网络表示.那样,执行网络的训练目标为
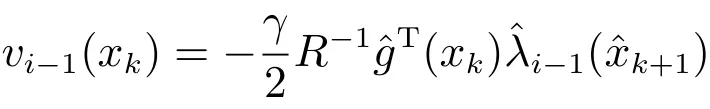
误差函数定义为¯ea(i−1)k=ˆvi−1(xk)−vi−1(xk),在此基础上训练执行网络.这样的实现方法,很大程度上依赖于控制系统的动态信息,尤其是控制矩阵的信息.这里提出的迭代神经动态规划方法,不仅沿用迭代ADP算法的基本框架,能够保证迭代算法的收敛性;而且引入神经动态规划的思想,放松对系统动态的要求,所以更利于达到数据驱动控制的目的.

图2 迭代神经动态规划结构Fig.2 The architecture of iterative neural dynamic programming
3.4 设计步骤
设xk为任意可控状态,J∗(xk)为最优代价函数.根据定理1中的收敛性结论,当迭代指标i→∞时,Vi(xk)→J∗(xk).但是,在计算机实现中,不可能无限地执行迭代算法.从工程应用角度来看,我们更关心是否存在一个有限的i,使得
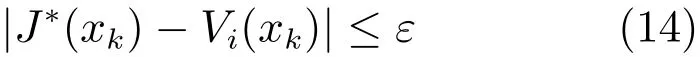
成立.因此,将J∗(xk)和Vi(xk)之间的误差ε引入迭代ADP算法,使得代价函数序列{Vi(xk)}能够在经过有限次迭代之后收敛.从这个角度来看,这里设计的控制器实现了对被控系统近似最优调节的目的.实际上,这种近似意义上的收敛,能够满足一般的设计需求;也是ADP方法在无法精确求解HJB方程的背景下,进行近似最优控制设计的体现.
但是,也应该看到,在一般情况下,最优代价函数J∗(xk)事先未知,难以利用停止准则(14)来验证迭代算法是否达到要求.因此,这里提出一种相对容易判定的算法停止准则,即

定理 2.对于非线性系统(1)和代价函数(2),在使用迭代神经动态规划方法时,由式(14)和式(15)描述的两种收敛性准则是等价的.
证明.一方面,若|J∗(xk)−Vi(xk)|≤ε成立,则有J∗(xk)≤Vi(xk)+ε.根据引理2和定理1可知Vi(xk)≤Vi+1(xk)≤J∗(xk)成立.于是,有Vi(xk)≤Vi+1(xk)≤Vi(xk)+ε.即,0≤Vi+1(xk)−Vi(xk)≤ε,也即式(15)成立.
另一方面,根据定理1,|Vi+1(xk)−Vi(xk)|→0意味着Vi(xk)→J∗(xk).这样,如果对于任意小的ε都有|Vi+1(xk)−Vi(xk)|≤ε成立,则当i相当大时,|J∗(xk)−Vi(xk)|≤ε成立.由此证明了两种准则的等价性. □
考虑到神经网络的近似作用,在具体的实现过程中,采用近似的代价函数构建停止准则,即这里给出利用迭代神经动态规划方法设计非线性系统近似最优调节器的具体步骤,如算法1所示.
算法1.迭代神经动态规划方法

注5.定理2的重要作用在于,它提供了利用迭代神经动态规划方法实现离散时间非线性系统近似最优调节的具有实用意义的设计准则.因此,在实际应用中,我们可以运行算法1得到合理可行的结果.
4 仿真实验
本节开展两个仿真实验:1)针对仿射非线性系统;2)针对非仿射形式的一般非线性系统.
例1.考虑离散时间(仿射)非线性系统

这是对文献[14]和文献[20]中仿真例子的修改,其中,xk=[x1k,x2k]T∈R2和uk∈R分别是被控系统的状态向量和控制向量.选取二次型形式的效用函数U(xk,uk)=xTkxk+uTkuk.
利用三层反向传播(Back propagation)神经网络来构建模型网络、评判网络和执行网络,且三者的结构分别为3-8-2、2-8-3和2-8-1.激活函数通常选取为
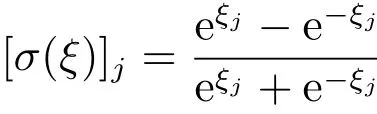
其中,ξ是一个列向量且维数与隐藏层神经元个数相同,ξj代表该向量的第j个分量.
注6.这里对隐藏层神经元个数的设定主要是凭借工程经验,同时在计算精度要求和计算复杂度之间取得一个折衷方案.
利用迭代神经动态规划方法,运行算法1,首先需要训练模型网络:输入层和隐藏层、隐藏层和输出层之间的权值分别在区间[−0.5,0.5]和[−0.1,0.1]中随机初始化.参数设置(如学习率)会在一定程度上影响算法的收敛速度.我们通过实验选取合适的学习率αm=0.1,采集500组数据进行学习,并在训练结束之后保持其权值不再变化.其次,评判网络和执行网络的初始权值都在区间[−0.1,0.1]中随机选取.然后,选取折扣因子γ=1,GDHP技术的调节参数β=0.5,在k=0时刻执行神经动态规划方法完成59次迭代(即i=1,2,···,59),使得计算误差达到预先定义的精度10−6.在每次迭代中,都对评判网络和执行网络分别进行2000次训练,并且学习率参数取为αc=αa=0.05.评判网络和执行网络的权值矩阵范数的收敛结果如图3所示.这里,我们对比两种不同的实现方法的收敛效果.这种不同主要体现在对执行网络的训练方法上(如第3.3节和注4所述).对于k=0和x0=[0.5,−1]T,代价函数及其偏导数序列的收敛过程如图4所示(清楚起见,只刻画前15次迭代的结果),其中,星线代表本文提出的迭代神经动态规划方法,点线代表传统的迭代ADP算法[12−18](下同).可以发现,迭代神经动态规划方法在不利用系统动态信息的情况下,也基本达到了和传统迭代ADP算法一样的收敛效果,这验证了迭代神经动态规划方法的有效性.
最后,对于给定的初始状态x0=[0.5,−1]T,我们将基于两种不同实现方法的GDHP近似最优控制律运用于被控对象(16).在运行15个时间步后得到的系统状态响应曲线及相应的控制曲线分别如图5和图6所示.由此可以清楚地看到,采用两种不同的实现方法得到的控制效果是很相近的.这再次验证了融合迭代ADP算法,神经动态规划思想,和GDHP技术的优点.
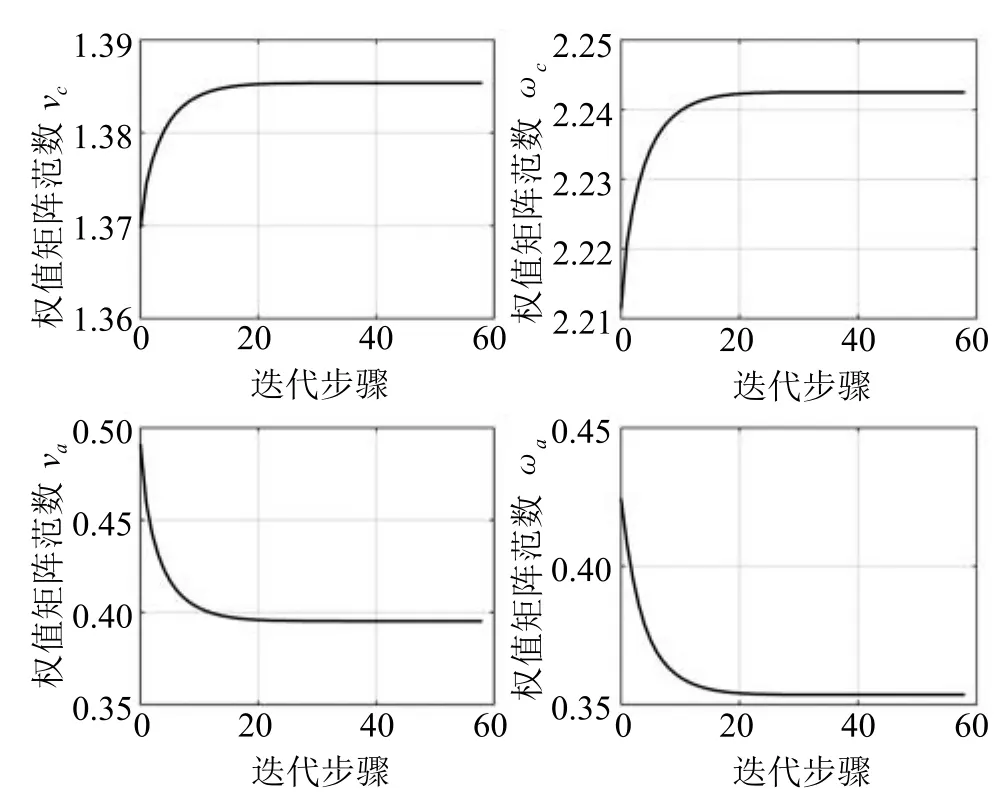
图3 权值矩阵范数的收敛过程Fig.3 The convergence process of the norm of weight matrices

图4 代价函数及其偏导数的收敛过程Fig.4 The convergence process of the cost function and its derivative
例2.考虑离散时间(非仿射)非线性系统
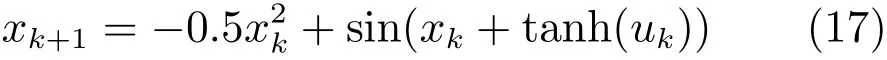
其中,xk∈R和uk∈R分别是被控系统的状态向量和控制向量.构建模型网络、评判网络和执行网络,且三者的结构分别为2-6-1、1-6-2和1-6-1.首先训练模型网络,得到的最终权值为

图5 系统状态轨迹xFig.5 The system state trajectory x

图6 控制输入轨迹uFig.6 The control input trajectory u

对于评判网络和执行网络,选取初始的权值矩阵分别为

其他参数设置同例1.在k=0时刻执行算法1并完成19次迭代,使得计算误差达到预先定义的精度10−5.评判网络和执行网络的权值矩阵范数的收敛结果如图7所示.对于k=0和x0=0.8,代价函数及其偏导数序列的收敛过程如图8所示.最后,对于给定的初始状态x0=0.8,利用GDHP技术和迭代神经动态规划方法得到的最优控制律运用于被控对象(17),在运行60个时间步后得到的系统状态响应曲线及相应的控制曲线如图9所示.这些仿真结果验证了迭代神经动态规划设计方法的有效性.

图8 代价函数及其偏导数的收敛过程Fig.8 The convergence process of the cost function and its derivative
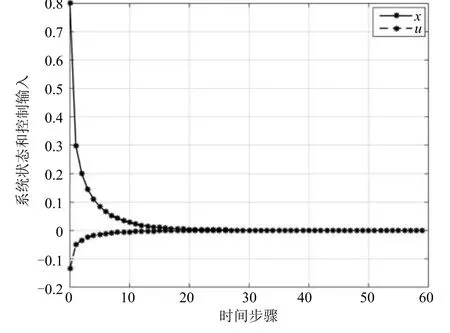
图9 系统状态轨迹x和控制输入轨迹uFig.9 The system state trajectory x and control input trajectory u
5 结论
本文利用基于数据的思想,建立针对离散时间非线性系统近似最优调节的迭代神经动态规划方法.提出离散时间非仿射非线性系统的迭代ADP算法并且证明其满足收敛性与最优性.通过构建三种神经网络(模型网络、评判网络和执行网络),结合GDHP技术,给出迭代算法的具体实现步骤.在这种新颖的迭代神经动态规划结构中,训练执行网络不需要利用系统动态信息,尤其是仿射非线性系统xk+1=f(xk)+g(xk)uk中的控制矩阵g(xk).这在很大程度上减少了迭代算法对系统动态的依赖,改进了以往的实现结构.通过仿真研究,验证了本文建立的数据驱动最优调节器设计策略的有效性.值得注意的是,本文研究的是无限时间近似最优控制问题.如何将神经动态规划思想与有限时间迭代ADP算法[14]相结合,改进执行网络的训练方法,从而将迭代神经动态规划方法推广到有限时间近似最优调节器设计是值得深入研究的主题之一.另外,本文目前的研究侧重于理论方面的收敛性分析和具体的算法实现,如何将提出的方法应用于实际系统也有待于进一步讨论.
1 Bellman R E.Dynamic Programming.Princeton,NJ: Princeton University Press,1957.
2 Werbos P J.Approximate dynamic programming for realtime control and neural modeling.Handbook of Intelligent Control.New York:Van Nostrand Reinhold,1992.
3 Lewis F L,Vrabie D,Vamvoudakis K G.Reinforcement learning and feedback control:using natural decision methods to design optimal adaptive controllers.IEEE Control Systems,2012,32(6):76−105
4 Zhang Hua-Guang,Zhang Xin,Luo Yan-Hong,Yang Jun. An overview of research on adaptive dynamic programming. Acta Automatica Sinica,2013,39(4):303−311 (张化光,张欣,罗艳红,杨珺.自适应动态规划综述.自动化学报, 2013,39(4):303−311)
5 Liu De-Rong,Li Hong-Liang,Wang Ding.Data-based selflearning optimal control:research progress and prospects. Acta Automatica Sinica,2013,39(11):1858−1870 (刘德荣,李宏亮,王鼎.基于数据的自学习优化控制:研究进展与展望.自动化学报,2013,39(11):1858−1870)
6 Hou Z S,Wang Z.From model-based control to data-driven control:survey,classi fi cation and perspective.Information Sciences,2013,235:3−35
7 Prokhorov D V,Wunsch D C.Adaptive critic designs.IEEE Transactions on Neural Networks,1997,8(5):997−1007
8 Sutton R S,Barto A G.Reinforcement Learning—An Introduction.Cambridge,MA:MIT Press,1998.
9 Si J,Wang Y T.Online learning control by association and reinforcement.IEEE Transactions on Neural Networks, 2001,12(2):264−276
10 Wang Fei-Yue.Parallel control:a method for data-driven and computational control.Acta Automatica Sinica,2013, 39(4):293−302 (王飞跃.平行控制:数据驱动的计算控制方法.自动化学报,2013, 39(4):293−302)
11 Al-Tamimi A,Lewis F L,Abu-Khalaf M.Discrete-time nonlinear HJB solution using approximate dynamic programming:convergence proof.IEEE Transactions on Systems, Man,Cybernetics,Part B,Cybernetics,2008,38(4):943−949
12 Zhang H G,Luo Y H,Liu D R.Neural-network-based nearoptimal control for a class of discrete-time affine nonlinear systems with control constraints.IEEE Transactions on Neural Networks,2009,20(9):1490−1503
13 Dierks T,Thumati B T,Jagannathan S.Optimal control of unknown affine nonlinear discrete-time systems using offlinetrained neural networks with proof of convergence.Neural Networks,2009,22(5−6):851−860
14 Wang F Y,Jin N,Liu D R,Wei Q L.Adaptive dynamic programming for fi nite-horizon optimal control of discrete-time nonlinear systems with ε-error bound.IEEE Transactions on Neural Networks,2011,22(1):24−36
15 Liu D R,Wang D,Zhao D B,Wei Q L,Jin N.Neuralnetwork-based optimal control for a class of unknown discrete-time nonlinear systems using globalized dual heuristic programming.IEEE Transactions on Automation Science and Engineering,2012,9(3):628−634
16 Wang D,Liu D R,Wei Q L,Zhao D B,Jin N.Optimal control of unknown nonaffine nonlinear discrete-time systems based on adaptive dynamic programming.Automatica, 2012,48(8):1825−1832
17 Zhang H G,Qin C B,Luo Y H.Neural-network-based constrained optimal control scheme for discrete-time switched nonlinear system using dual heuristic programming.IEEE Transactions on Automation Science and Engineering,2014, 11(3):839−849
18 Liu D R,Li H L,Wang D.Error bounds of adaptive dynamic programming algorithms for solving undiscounted optimal control problems.IEEE Transactions on Neural Networks and Learning Systems,2015,26(6):1323−1334
19 Zhong X N,Ni Z,He H B.A theoretical foundation of goal representation heuristic dynamic programming.IEEE Transactions on Neural Networks and Learning Systems, 2016,27(12):2513−2525
20 HeydariA,BalakrishnanS N.Finite-horizon controlconstrained nonlinear optimal control using single network adaptive critics.IEEE Transactions on Neural Networks and Learning Systems,2013,24(1):145−157
21 Jiang Y,Jiang Z P.Robust adaptive dynamic programming and feedback stabilization of nonlinear systems.IEEE Transactions on Neural Networks and Learning Systems, 2014,25(5):882−893
22 Na J,Herrmann G.Online adaptive approximate optimal tracking control with simpli fi ed dual approximation structure for continuous-time unknown nonlinear systems. IEEE/CAA Journal of Automatica Sinica,2014,1(4):412−422
23 Liu D R,Yang X,Wang D,Wei Q L.Reinforcement
learning-based robust controller design for continuous-time uncertain nonlinear systems subject to input constraints. IEEE Transactions on Cybernetics,2015,45(7):1372−1385
24 Luo B,Wu H N,Huang T W.O ff-policy reinforcement learning for H∞control design.IEEE Transactions on Cybernetics,2015,45(1):65−76
25 Mu C X,Ni Z,Sun C Y,He H B.Air-breathing hypersonic vehicle tracking control based on adaptive dynamic programming.IEEE Transactions on Neural Networks and Learning Systems,2017,28(3):584−598
26 Wang D,Liu D R,Zhang Q C,Zhao D B.Data-based adaptive critic designs for nonlinear robust optimal control with uncertain dynamics.IEEE Transactions on Systems,Man, and Cybernetics:Systems,2016,46(11):1544−1555
Data-driven Nonlinear Near-optimal Regulation Based on Iterative Neural Dynamic Programming
WANG Ding1,2MU Chao-Xu2LIU De-Rong3
An iterative neural dynamic programming approach is established to design the near optimal regulator of discrete-time nonlinear systems using the data-driven control formulation.An iterative adaptive dynamic programming algorithm for discrete-time general nonlinear systems is developed and proved to guarantee the property of convergence and optimality.Then,a globalized dual heuristic programming technique is developed with detailed implementation by constructing three neural networks,where the action network is trained under the framework of neural dynamic programming.This novel architecture can approximate the cost function with its derivative,and simultaneously,adaptively learn the near-optimal control law without depending on the system dynamics.It is signi fi cant to observe that it greatly improves the existing results of iterative adaptive dynamic programming algorithm,in terms of reducing the requirement of control matrix or its neural network expression,which promotes the development of data-based optimization and control design for complex nonlinear systems.Two simulation experiments are described to illustrate the e ff ectiveness of the data-driven optimal regulation method.
Adaptive dynamic programming,data-driven control,iterative neural dynamic programming,neural networks,nonlinear near-optimal regulation

王 鼎 中国科学院自动化研究所副研究员.2009年获得东北大学理学硕士学位,2012年获得中国科学院自动化研究所工学博士学位.主要研究方向为自适应与学习系统,智能控制,神经网络.本文通信作者.E-mail:ding.wang@ia.ac.cn(WANG Ding Associate professor at the Institute of Automation,Chinese Academy of Sciences.He received his master degree in operations research and cybernetics from Northeastern University,Shenyang, China and his Ph.D.degree in control theory and control engineering from the Institute of Automation,Chinese Academy of Sciences,Beijing,China,in 2009 and 2012,respectively.His research interest covers adaptive and learning systems,intelligent control,and neural networks.Corresponding author of this paper.)

穆朝絮 天津大学电气自动化与信息工程学院副教授.2012年获得东南大学工学博士学位.主要研究方向为非线性控制理论与应用,智能控制与优化,智能电网.E-mail:cxmu@tju.edu.cn(MU Chao-Xu Associate professor at the School of Electrical and Information Engineering,Tianjin University. She received her Ph.D.degree in control science and engineering from Southeast University,Nanjing,China,in 2012. Her research interest covers nonlinear control and application,intelligent control and optimization,and smart grid.)

刘德荣 北京科技大学教授.主要研究方向为自适应动态规划,计算智能,智能控制与信息处理,复杂工业系统建模与控制.E-mail:derong@ustb.edu.cn(LIU De-Rong Professor at University of Science and Technology Beijing.His research interest covers adaptive dynamic programming,computational intelligence,intelligent control and information processing,and modeling and control for complex industrial systems.)
王鼎,穆朝絮,刘德荣.基于迭代神经动态规划的数据驱动非线性近似最优调节.自动化学报,2017,43(3): 366−375
Wang Ding,Mu Chao-Xu,Liu De-Rong.Data-driven nonlinear near-optimal regulation based on iterative neural dynamic programming.Acta Automatica Sinica,2017,43(3):366−375
2016-03-16 录用日期2016-05-17
Manuscript received March 16,2016;accepted May 17,2016国家自然科学基金(61233001,61273140,61304018,61304086,615 33017,U1501251,61411130160),北京市自然科学基金(4162065),天津市自然科学基金(14JCQNJC05400),中国科学院自动化研究所复杂系统管理与控制国家重点实验室优秀人才基金,天津市过程检测与控制重点实验室开放课题基金(TKLPMC-201612)资助
Supported by National Natural Science Foundation of China (61233001,61273140,61304018,61304086,61533017,U1501251, 61411130160),Beijing Natural Science Foundation(4162065), Tianjin Natural Science Foundation(14JCQNJC05400),the Early Career Development Award of the State Key Laboratory of Management and Control for Complex Systems(SKL-MCCS)of the Institute of Automation,Chinese Academy of Sciences(CASIA),and Research Fund of Tianjin Key Laboratory of Process Measurement and Control(TKLPMC-201612)本文责任编委侯忠生
Recommended by Associate Editor HOU Zhong-Sheng
1.中国科学院自动化研究所复杂系统管理与控制国家重点实验室北京100190 2.天津市过程检测与控制重点实验室,天津大学电气自动化与信息工程学院天津300072 3.北京科技大学自动化学院北京100 083
1.The State Key Laboratory of Management and Control for Complex Systems,Institute of Automation,Chinese Academy of Sciences,Beijing 100190 2.Tianjin Key Laboratory of Process Measurement and Control,School of Electrical and Information Engineering,Tianjin University,Tianjin 300072 3.School of Automation and Electrical Engineering,University of Science and Technology Beijing,Beijing 100083
DOI10.16383/j.aas.2017.c160272
