基于机器学习的中小企业贷款意愿预测研究
2017-03-28苏晓丽陈暮紫郑丽芬叶展望
苏晓丽陈暮紫郑丽芬叶展望
1. 北京工商大学计算机与信息工程学院 2、3、4中央财经大学管理科学与工程学院
基于机器学习的中小企业贷款意愿预测研究
苏晓丽1陈暮紫2郑丽芬3叶展望4
1. 北京工商大学计算机与信息工程学院 2、3、4中央财经大学管理科学与工程学院
本文以某银行1887家贷款意愿已知的中小企业为研究对象,依托大数据环境下的网络爬虫技术,从互联网采集中小企业的工商、失信、裁判、百度以及招聘信息,建立影响中小企业贷款意愿的指标体系,并利用决策树和Logistic回归算法分别对中小企业贷款意愿进行预测。最后通过准确率、F测度和ROC面积等评价指标的对比分析发现,决策树模型的预测结果优于Logistic回归模型,并且企业是否有百度信息、是否发生工商变更、一级行业对中小企业的贷款意愿有显著的影响,为银行发掘贷款目标客户提供有益参考,同时在一定程度上缓解了中小企业融资难、融资贵问题。
大数据 机器学习 中小企业 贷款意愿预测
1 引言
所谓精准营销,就是使用数据驱动,在正确的时间通过正确的渠道提供正确的信息给正确的人的营销活动。对于银行来说,营销的首要目标是要找到正确的客户——即有贷款意愿的客户。在我国企业总数中,中小企业占比超过99%,是我国国民经济和社会发展的重要力量。然而,由于我国中小企业的经营规模往往较小,企业自有资金有限,同时,缺乏健全的日常管理及财务管理制度,存在严重的信息不透明,长期以来制约我国中小企业生存和发展的融资难题,依旧突出。
因此,在大数据时代背景下,依托互联网爬虫技术,获取中小企业信息,并使用机器学习的算法实现对中小企业贷款意愿的预测具有重要的现实意义,一方面在一定程度上缓解了中小企业融资难、融资贵问题,另一方面,为银行挖掘有贷款意愿的目标客户提供了有益参考。
2 数据来源与指标体系的建立
本文以某银行的1887家贷款意愿已知的中小企业为研究对象,通过互联网爬虫技术,从11315、工商、失信、裁判、百度、招聘等网站获取海量公开的中小企业信息,通过变量缺失、内部关联强度和相似度等的整理和排除,共选取16个变量构成影响中小企业贷款意愿的指标体系,并对这些指标影响中小企业贷款意愿的相关关系进行了一定的经济学假设,具体指标如表1所示。
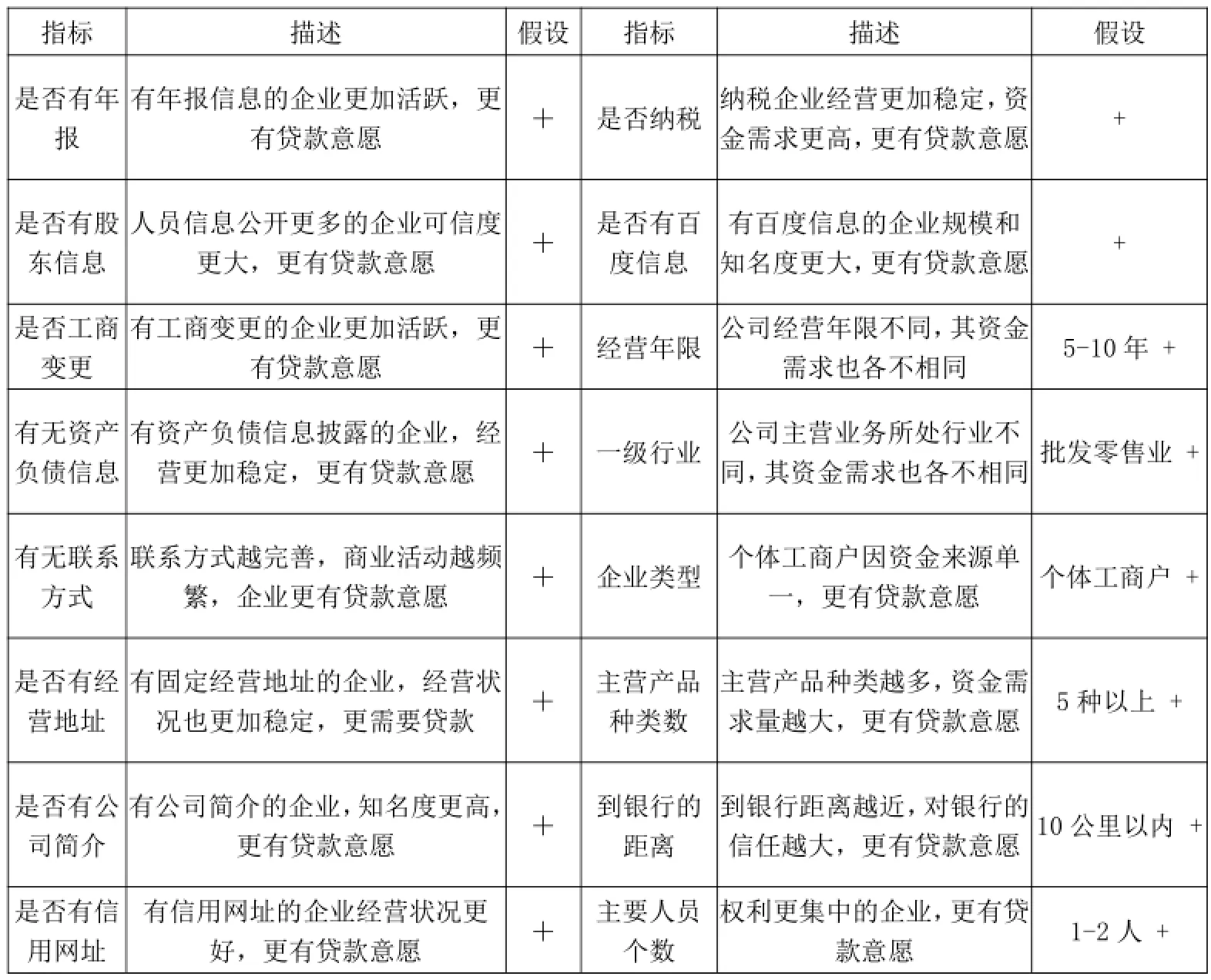
表1 影响中小企业贷款意愿的指标体系
3 实证分析
3.1 决策树模型
决策树在分类、预测和规则提取等领域有着广泛应用。本研究主要采用CART算法,目的是将中小企业划分为两类,有贷款意愿的企业和无贷款意愿的企业,决策树的各节点即影响中小企业贷款意愿的各个指标。CART决策树是一种十分有效的非参数分类和回归方法,通过构建树、修剪树、评估树来构建一个二叉树。CART算法主要采用最小GINI信息增益来选择节点属性。
本研究样本为1887家贷款意愿已知的中小微企业,按照7:3的比例,将样本分为训练样本和测试样本,其中训练样本1358家,测试样本529家。通过R软件中的Rpart函数实现基于CART算法的分类回归树模型,分析结果如图1所示。
从图1可以看出,在16个候选变量中共有6个显著变量,决策过程为:
①是否有百度信息。在测试样本中29%的企业有百度信息,其中有贷款意愿的占比38%,故判断这些企业没有贷款意愿;而剩下的71%的企业没有百度信息,但其中有贷款意愿的企业占比90%,故没有百度信息的企业贷款意愿更加强烈。
②是否纳税。在29%的有百度信息的企业中,纳税企业占比25%,但这部分企业有贷款意愿的占比28%,故判断纳税企业没有贷款意愿;而另外4%没有纳税信息的企业中,有94%的企业有贷款意愿,故没有纳税信息的企业贷款意愿更加强烈。
③企业类型和是否工商变更。通过图1决策树,可以看出这两个变量的取值,并不影响企业的贷款意愿,故这两个变量相比另外4个变量对企业贷款意愿的影响程度相对较低,但相对于没有进入决策树的变量,二者对贷款意愿的影响程度相对较高。
④一级行业。对于没有百度信息但有工商变更的个体工商户在全体样本中占比8%,其中一级行业是批发零售业的企业占比7%,其中有贷款意愿的企业占比44%,故判断这部分企业没有贷款意愿;而一级行业不是批发零售业的企业占比2%,有贷款意愿的企业占比91%,故判断这部分企业有贷款意愿。

表2 Logistics回归结果

图1 Rpart决策树
⑤经营年限。没有百度信息、企业类型为个体工商户、发生工商变更、一级行业为批发零售业的企业占比7%,这部分企业中,经营年限为5-10年的有4%,有贷款意愿的占比35%,故判断它们没有贷款意愿,而经营年限不是5-10年的占比3%,其中55%的企业有贷款意愿,故判断这部分企业有贷款意愿。
3.2 Logistic模型
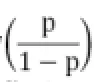

在本研究中,P表示中小企业有贷款意愿的概率,1-P表示中小企业无贷款意愿的概率,β0为常数,X1,...,Xi为解释变量,即影响中小企业贷款意愿的各个指标,β1,β2,...,βi为回归系数,ε为随机误差。
本研究通过R软件中的glm函数逐步回归实现Logistic模型,结果如表2所示。
通过表2可知,共有7个变量的P-Value的值都远小于0.05,分别为是否工商变更、是否有经营地址、是否有信用网址、是否有百度信息、主要人员个数未知、一级行业其他以及到我行的距离10公里以外,并依次用X1,X2,...,X7分别表示。由Logistics模型可知:企业有贷款意愿的概率P与各显著变量Xi的关系可用如下式所示:

其中是否有信用网址、一级行业其他、到我行的距离10公里以外等三个变量的系数为正,它们与企业贷款意愿呈正相关,且系数越大,贷款意愿越大;而是否工商变更、是否有经营地址、是否有百度信息、主要人员个数未知等四个变量的系数为负,它们与企业贷款意愿呈负相关,且系数越大,越没有贷款意愿。

表3 两种算法预测结果评估表
3.3 模型结果的对比分析
分类模型通常利用准确率、精确率、召回率、F值和ROC面积等指标进行评估,本研究中将有贷款意愿的中小企业标注为正类,无贷款意愿的中小企业标注为负类。则共出现四种情况:
真正类(True Positive,TP):被模型预测为有贷款意愿的有贷款意愿样本;
假正类(False Positive,FP):被模型预测为有贷款意愿的无贷款意愿样本;
假负类(False Negative,FN):被模型预测为无贷款意愿的有贷款意愿样本;
真负类(True Negative,TN):被模型预测为无贷款意愿的无贷款意愿样本。
①准确率(Accuracy),反映的是正确预测样本所属类别的概率。
一般情况下,模型的ROC>0.5,即认为模型的效果较好。通过表3结果的对比分析发现,决策树模型的准确率、精确率、召回率、F测度和ROC面积均优于Logistic模型,预测效果更好。
4 结论
本文依托大数据环境下的网络爬虫技术,全方面获取企业在第三方网站上的信息,突破了传统研究中影响中小企业贷款意愿指标体系的局限性;并且通过决策树和Logistic模型分别对企业贷款意愿进行预测,结果表明决策树模型预测效果更好,一方面帮助银行更加精准地筛选目标客户,另一方面也在一定程度上缓解了中小企业融资难问题。但本文存在的不足是,两种模型的显著变量对企业贷款意愿的影响方向并不完全和假设方向一致,这也是本文今后应该深入研究的地方。
[1]杨茜. 基于大数据的客户细分模型及精确营销策略研究[D].南京邮电大学,2015
[2]张良均,云伟标等.R语言挖掘与实战[M].北京:机械工业出版社,2015:89-95

本文受国家自然科学基金(71673315)、北京市社科基金(16yjb036)的资助。
