基于HMM的维吾尔语腭裂患儿语音理解度评估方法
2017-03-24亚尔肯·阿吉努尔麦麦提·尤鲁瓦斯许辉
亚尔肯·阿吉+努尔麦麦提·尤鲁瓦斯+许辉+木合塔尔·霍加+白慧子


医院 口腔颌面外科,新疆 乌鲁木齐 830001)
摘要:为维吾尔语腭裂患者语音理解度的评估提供一种非主观的临床辅助手段,提出了一种通过语音识别技术对腭裂患者进行语音评估的方法。结合腭裂病理性语音特征和维吾尔语特点,提取维吾尔语正常儿童语音特征参数,建立了基于隐马尔科夫模型(HMM)的腭裂语音评估系统。再用此系统对腭裂患儿进行了语音理解度评估实验。将此方法评估结果与由专家判听来完成的主观评估方法比较。实验结果显示,该方法对于腭裂患儿的语音评估结果与主观评估结果具有高度一致性,该方法有一定的临床价值,值得进一步研究。
关键词:腭裂;语音理解度;维吾尔语;隐马尔科夫模型;语音识别
中图分类号:TP18 文献标识码:A 文章编号:1009-3044(2017)01-0200-04
Abstract: A method for evaluation of evaluation of speech intelligibility for children with cleft palate through speech recognition technology is proposed to provide a non-subjective clinical supplementary measure for Uyghur children with cleft palate. Cleft palate speech evaluation system based on Hidden Markov Model(HMM) is built by extracting the speech features of normal Uyghur children in combination of pathological characteristics of Uyghur language. Besides, the speech intelligibility evaluation experiment for children with cleft palate is carried out through this system. Through comparison of this evaluation result into the subjective assessment method judged by the experts, the experimental result shows that the result of speech evaluation on children with cleft palate through this method is highly consistent with that of subjective evaluation. As a result, this method has certain clinical value and is worth further being studied.
Key words: cleft palate; speech intelligibility; Uyghur; Hidden Markov Model(HMM); speech recognition
1 概述
腭裂是口腔頜面部常见的先天性畸形,是由于在胚胎发育过程中两侧腭突未能按时相互并与鼻中隔融合所致。腭裂畸形常常引起患儿的多种生理功能障碍,特别是语音功能障碍对患者的日常生活、学习、社交等均可带来不良的影响。在临床上需要多学科相互合作,对腭裂患儿进行较长周期的综合序列治疗。腭裂语音评估作为腭裂序列治疗的重要步骤之一,是评价腭裂术后效果的重要指标,还是进行语音治疗的主要依据[1]。因存在生理缺陷,腭裂患儿在发音过程中不能形成有效的阻碍或因口鼻腔相通,致使鼻音和口音相混,产生具有鼻音异常、鼻漏气等异常语音表现[2]。除此之外,由于部分即使是手术修复后的患者仍存在结构或功能问题无法在口腔内保持一定的高压力,导致辅音发音出现问题,表现为辅音的省略、替代和扭曲,这个特点尤其是在浊塞音、塞擦音和清塞音的发音上更为明显。当发音存在问题时,患者识图表达的词义也会受到影响,所以腭裂患儿与人交流的过程中最严重的问题其实就是听者不能理解其语义。而提高语音理解度是腭裂语音治疗的首要目标,也是评估腭裂语音异常严重程度的一个重要指标[3]。
在我国新疆地区因先天性腭裂导致语音障碍的维吾尔族患者数量较多,占新疆总患者数的一半以上[4]。维吾尔语是主要在新疆地区通用的一种语言,属于阿尔泰语系突厥语族,是黏着性语。现代标准维吾尔语有32个音素,其中元音8个,辅音24个。维吾尔语中每个音节必须且只能含有一个元音,一个元音与零至三个辅音构成一个音节,不存在带复合元音的音节类型。维吾尔语中一个词根或词干与一个或多个词缀链接后组成新单词,并以单词的形式表达语义。所以,维吾尔语腭裂患儿语音理解度的评估方法中需要以词表作为测试语料,以单词表达的语义是否可被理解作为评价标准。
目前认为由专业人员判听来完成的主观评估是腭裂语音理解度评估的金标准[5],但是主观评估法受主观因素的影响,而且专业人员的培训需要较长时间。到目前为止,还没有一个能全面代替人听觉功能的设备。因此,国外有学者开始关注语音识别技术,希望利用此技术对腭裂语音实现计算机自动评估。语音识别技术作为实现人机语音交互中最关键的技术,在各个领域得到了广泛的应用和发展,其同样在腭裂病理性语音的评估方面开始起到了一定的作用,也让腭裂患者语音理解度的自动评估成为了可能。基于语音识别的腭裂语音评估方法的优点是具有自动、简便、无创、无痛等特点。且HMM的语音识别原理和特点在腭裂语音自动评估中有着很大的优势[6]。因此,国外许多学者开始利用基于HMM的语音识别方法对腭裂语音进行了自动评估[7-8]。在国内基于HMM的语音识别方法也已经实现对于汉语腭裂患者语音中单独的某个病理性语音特征,如高鼻音、辅音省略的识别[9-10]。但是,目前对于我国少数民族腭裂患儿的语音评估方面的研究较少,也未见关于维吾尔语腭裂语音评估相关文献。
我们前期的研究发现,维吾尔族腭裂患儿在声学方面存在不同于汉族患儿的特征[11]。而随着维吾尔语语音声学参数数据库的建立,维吾尔语孤立词语音识别及维吾尔语连续语音识别研究已经取得了一定的进展[12]。本文从维吾尔语的单词结构出发,结合腭裂语音理解度评估要求,将单词作为识别单元,提出了基于HMM的维吾尔语腭裂语音理解度评估方法。并且将此方法判别结果与专家主观评估出判别结果进行比较,分析结果,反复调节系统参数设计,使该方法与专家主观评估出的维吾尔语腭裂患儿语音理解度达到最大拟合。
2 语音数据
2.1 语音测试表
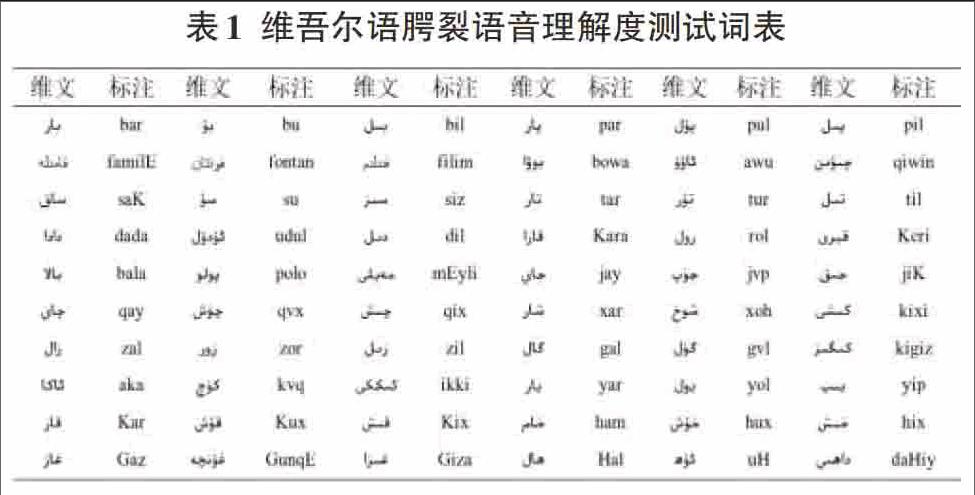
录音材料选用新疆维吾尔自治区人民医院与新疆大学合作建立的维吾尔语腭裂语音理解度测试词表,词数为60个(如表1所示)。选词的原则是尽量选以该辅音起首的单音节词,在没有合适的单音节词的情况下,就选择词重音所在音节的起首辅音为测试目标的双音节词。词表中去排除了构词极少的舌叶浊擦音/?/及3个与受腭裂语音影响较小的鼻辅音/m/、/n/、/?/。按照腭裂语音理解度评估的要求,选词时筛除了生僻词,存在方言差异的词,尽可能选择具有实际语意,有画面感,可以引发联想,学龄前儿童也能理解的词。
2.2 录音及数据采集方法
录音间墙面采用隔音材质制作,录音环境安静,密闭,尽可能地减少了噪声,杂音的影响。录音方式是以跟读的方式进行,所有受试者戴耳机,观看幻灯片跟读语料。体位舒适,精神放松,音量适中,语音样本重复2次。录音设备选用索尼公司生产的线性PCM 录音棒(型号PCM-D50),采样率调为44.10kHz,采样位调节为16bit,单声道,调整麦克风与被测对象口唇的距离为15cm。语音数据以无损音频格式WAV文件存储。
2.3 维吾尔族正常儿童语音语料库与维吾尔族腭裂术后患儿语音语料库
正常组选择来自南北疆100例正常儿童,其中,男55例,女45例,年龄5~12岁,平均年龄8.6岁。均无智力及听力障碍,无严重牙列畸形,近期无上呼吸道疾病,及其他影响语言功能疾病,并可顺利配合跟读采集语音样本。腭裂术后组选用从2011年1月至2013年12月期间因术后复查或拟进行语音治疗前来我院的患者中选择20例维吾尔族腭裂术后患儿,其中男12例,女8例,年龄5~12岁,平均年龄8.8岁。均未接受过语音治疗,腭裂手术封闭裂隙12个月以上,非综合征型腭裂患者,能配合跟读,录音时无影响发音的上呼吸道疾病,无其他可能影响语音的重要异常,如智力缺陷、听力障碍等。两组儿童录音完成后选用PRAAT语音分析软件(版本号5.1.43),进行词为一个层级的标注。因该软件需将Unicode形式的维吾尔文转换成英文字母表示,本文用英文26个字母表示26个维文音素,其余6个采用英文字母的大写形式来表示,停顿用sp,静音用sil表示,总共包括34个音素(如表2所示)。
3 基于HMM的腭裂语音评估系统
本文按照训练数据与测试数据8:2的比例,从维吾尔族正常儿童语音语料库随机选取80例正常儿童作为训练数据,提取美尔频谱倒谱系数(mel frequency cepstrum coefficient,MFCC)特征参数,利用HMM识别模式,经过多次训练建立模型。利用经过预处理和MFCC特征提取后的测试数据对该模型进行性能测试。最终,将同样经过预处理和MFCC特征参数提取的腭裂患儿语音数据输入该评估系统进行评估,具体步骤如图1:
3.1 预处理
预处理分为预加重、分帧和加窗与端点检测三个步骤进行。预加重处理中,使用了高通滤波函数传导,滤掉较低频率,突出较高频率。由于人体发生机理中存在发音器官的惯性运动,语音信号的短时平稳性被认为在15ms-25ms,所以进行分帧来增加对语音信号处理的效果。分帧由于存在边缘平滑的动态信息,需要在每两个帧以内都设计加入一个窗,将非分帧代入到窗函数表达式中。本文中选帧长为24ms,帧移为12ms。在本研究中实验对象为儿童,在录音过程中可能发出与实验无关的叹气音等噪声或者干扰,腭裂儿童也容易发出不必要的口唇音,因此端点检测可以有效地从语音信号中确定语音的起点和終点,去除其他的干扰。本文采用结合语音信号的过零率和短时能量的传统端点检测算法。
3.2 MFCC特征参数提取
MFCC作为一种将人耳的听觉感知特性和语音的产生机制相结合的语音特征参数,是目前维吾尔语语音识别特征提取上最主要的方法之一[13]。Mel频率尺度的值应与实际频率的对数分布关系相对应,其具体关系可用公式(1)表示为:
MFCC特征区别于其他普通倒谱特征的最重要的特点是对频谱轴的不均匀划分。频率用公式(1)转换成Mel域后,Mel带通滤波器组的中心频率就可以按照Mel频率刻度均匀排列。在实际应用中,通过预处理得到语音帧的短时时域信号后通过快速傅里叶变换(fast Fourier transform,FFT)把短时时域信号转换为频域信号并求出短时能量谱,通过 FTT计算短时能量谱时用M个Mel带通滤波器进行滤波,再将每个滤波器频带内的能量进行叠加,输出第K个滤波器输出功率谱x′(k)。然后,将每个滤波器的输出的功率谱取对数,得到相应频带的对数功率谱。最终MFCC系数对功率谱进行反离散余弦变换后得到,其关系可用公式(2)表示:
其中n=1,2...,L。
这里得到的MFCC特征参数为静态,经过做一阶和二阶差分,使得最终得到相应的动态特征,最后两个不同的特征相连后生成当前帧所对应的有效混合特征参数。
3.3 HMM声学模型的定义与训练
HMM是一种由马尔可夫链演变来的用于描述随机过程统计特性的概率模型。HMM不仅具有良好的识别性能和抗噪性能,而且可以很好地描述时序动态信号的变化规律。在本研究中将词表中的每一个词都要设计一个HMM模型,每个HMM模型选择一个反映状态数、观察函数形式、状态转换排列的priori结构。我们为所有HMM模型选择同一个结构,系数向量大小取39。模型定义完成后,在训练模型之前,为了使得训练算法快速精准收敛,HMM模型参数必须根据训练数据正确初始化,模型的每个状态给定相同的平均向量和变化向量。本文中,选择用HTK工具HCompV 模块对训练数据估计初始模型参数,使用HTK 提供的HERest嵌入式训练工具进行模型训练[14]。使用Baum-Welch重估计算法,对模型进行循环往复的估计与重对齐,通过训练不断地调整模型参数,使系统中的所有模型彼此间的距离尽可能达到最大。
3.4 语言模型的建立
在本研究中因为腭裂语音理解度测试表中的测试词是固定的,而且是以单词作为识别单元,没有牵扯到造句语法。因此,我们定义最简单的语法变量与测试表中每个单词对应即可。这种信息存储在文本文件中,命名为任务词典。任务语法选择用HTK工具HParse模块对任务词典进行编译获得。
3.5 模型匹配
声学模型的训练和语言模型的建立完成后,将经过预处理和特征提取的测试数据与参考模型进行匹配,使用Viterbi算法计算能描述该观测序列的最优的状态序列。Viterbi算法的思想是前向算法与似然概率最大状态序列,本文中选择HTK工具HVite模块,将输入信号的声学特征对识别网络进行Viterbi搜索,寻找一条最优路径,然后将得到的候选识别结果继续处理,通过语言学的语言模型、词法、语义信息等的约束,得到最终识别结果。
4 评估实验及结果分析
4.1 主观评估结果
由经验丰富的颌面外科维吾尔族医师和语音治疗师组成的3名专家参与主观评估,专家根据患儿发音能否被正确理解进行评估。语音理解度值=被判听者正确理解的词数/测试表中的词总数×100%。对3名专家主观评估的结果进行一致性检验,从Kendall相关性分析结果来看,3名专家之间评估结果相关系数为0.984,P=0.000,相关性显著,表明3个专家之间的评估结果具有高度一致性,评估结果可靠。
4.2 基于HMM的腭裂语音评估方法与主观评估方法的比较
20例正常儿童与20例腭裂患儿的语音数据经过预处理和MFCC特征提取后,使用基于HMM的语音评估系统进行语音评估。系统对正常儿童的语音识别率为91.59%±3.01%,显著高于腭裂儿童的33.33%±12.64%。两组之间的识别率做独立样本t检验,统计结果P<0.05,差异有统计学意义,两组之间识别率差异显著。说明基于HMM的腭裂语音理解度评估系统对正常语音具有较高的识别率,腭裂语音的识别率明显低且个体之间差异较大。主观评估与计算机评估对于正常儿童语音识别率也未达到100%,原因可能是语音识别技术自身存在局限性,而且参加本次实验的儿童年龄段较小,语言能力处于发育阶段。基于HMM的腭裂语音评估系统评估语音理解度值取识别系统的正确识别率Corr=被识别系统正确识别的词数/测试表中的词总数×100%。两种评估方法评估腭裂患儿语音理解度的结果对比(见表3),相关系数为0.884,P=0.000,相关性显著,由此可以看出,提出的基于HMM的语音理解度评估方法与作为“金标准”的专家主观判听方法的结果具有高度的一致性,临床上,可以作为一种有效的腭裂语音理解度评估辅助方法。
5 结束语
将腭裂语音理解度评价方法结合于维吾尔语的语音特点,本文提出了基于HMM的维吾尔语腭裂语音理解度评估方法。实验结果表明,本文提出的评估方法对腭裂术后患儿的语音评估结果与主观评估结果具有高度一致性。说明该方法具有继续研究的价值,有望成为一种腭裂语音理解度评估的临床辅助手段,同时,为建立维吾尔语腭裂语音异常的识别方法提供了一定的基础。
参考文献:
[1] Koh K S, Kang B S, Seo D W. Speech evaluation after repair of unilateral complete cleft palate using modified 2-flap palatoplasty.[J]. J Craniofac Surg, 2009, 20(1):111-114.
[2] Derakhshandeh F, Nikmaram M, Hosseinabad H H, et al. Speech characteristics after articulation therapy in children with cleft palate and velopharyngeal dysfunction – A single case experimental design[J]. Int J Pediatr Otorhinolaryngol 2016, 86:104-113.
[3] 马思维,杜良智,文抑西.腭裂语言理解度的概念及其与语音清晰度的关系研究[J].中国美容医学,2010,19(12):1792-1794.
[4] 王小丽, 王磊, 陈永慧,等. 新疆6地(州)出生缺陷防治现况调查[J]. 中国优生与遗传杂志, 2016,24(5):102-103.
[5] 亚尔肯·阿吉, 许辉, 等. 腭裂语音理解度评估方法研究进展[J]. 中华实用诊断与治疗杂志, 2016, 30(6):525-527.
[6] Lederman D, Zmora E, Hauschildt S, et al. Classification of cries of infants with cleft-palate using parallel hidden Markov models.[J]. Med Biol Eng Comput, 2008, 46(10):965-75.
[7] Schuster M, Maier A, Bocklet T, et al. Automatically evaluated degree of intelligibility of children with different cleft type from preschool and elementary school measured by automatic speech recognition[J]. Int J Pediatr Otorhinolaryngol.,2012,76(3):362–369.
[8] Maier A, H?nig F, Bocklet T, et al. Automatic detection of articulation disorders in children with cleft lip and palate[J]. J Acoust Soc Am.,2009,126(5):2589-602.
[9] 袁亞南, 何凌, 龚晓峰,等. 基于MFCC和HMM的腭裂语音辅音省略识别算法[J].计算机工程与设计, 2014, 35(2):615-619.
[10] 尹恒, 何凌, 张劲,等. 基于非线性参数的腭裂患者高鼻音自动识别[J].计算机工程与设计, 2013,34(10):3701-3704.
[11] 许辉,木合塔尔·霍加,祁恩春,等.新疆维吾尔族腭裂患者元音共振峰分析[J].新疆医科大学学报,2012,35(5):638-641.
[12] 努尔麦麦提·尤鲁瓦斯, 吾守尔·斯拉木. 面向大词汇量的维吾尔语连续语音识别研究[J].计算机工程与应用, 2013, 49(9):115-119.
[13] 努尔麦麦提·尤鲁瓦斯, 吾守尔·斯拉木. 维吾尔语连续语音识别声学模型优化研究[J].计算机工程与应用, 2013, 49(2):145-147.
[14] Majidnezhad V. A HTK-based Method for Detecting Vocal Fold Pathology[J]. Acta Informatica Medica, 2014, 22(4):246-248.
