NIH生物医学数据共享仓储分析
2017-03-22,,,
,, ,
[作者单位]中国医学科学院医学信息研究所,北京 100005
科学数据的快速增长为科学研究和发展带来了巨大挑战和机会,对数据重要价值的认知促使各资助机构、科研院所等争先制定相关数据政策,促进数据仓储更有效地利用和共享科学数据。数据仓储(Data Repository,DR)的宗旨是在科学研究领域内,促进数据转化为知识和再利用。数据仓储的建设需要完成数据的收缴、数据的质量控制、数据组织与长期存储、数据内容的描述,并提供检索、查询、调用等服务[1]。
国内已有相关文献分析了生命科学领域科研数据仓储的建设年代、学科领域等分布情况,从宏观角度分析了代表性数据仓储。本文则聚焦数据仓储建设,拟以数据上传、下载、管理、访问等方面为切入点,系统梳理和深入探索美国国立卫生研究院(National Institutes of Health,NIH)生物医学共享数据仓储中典型仓储的建设模式,全面了解数据仓储的建设情况,为我国生物医学科学数据共享仓储的建设提供可资借鉴的参考。
1 NIH生物医学数据共享仓储概述
NIH以列表形式,汇集了73个生物数据共享仓储,提供数据存储和共享服务,促进数据复用。该仓储涵盖癌症、生物纳米技术样本、多肽、眼部等多个领域。本文根据数据仓储权威性、领域影响力、应用广泛性和规范性等方面的特点,确保仓储中涵盖内容格式单一型仓储及内容格式集成型仓储,涵盖前沿的基因、蛋白、肿瘤领域及传统的生物、技术、模型、临床等领域,并根据对数据管理模式及流程的调研,筛选具有代表性,详尽、规范及自身特性鲜明的仓储,最终遴选出Protein Data Bank (PDB)、PubChem、GenBank、TCIH、FlyBase、CaNanolab、iDash、Uniprot、dbGaP、Clinicaltrials.gov等10个典型的数据共享仓储进行研究。
癌症影像档案库TCIA[2]为公众提供大量去识别化的医学癌症影像的档案资料[3]。FlyBase[4]是一个果蝇染色体和基因的数据库,包括蛋白质组数据、微数列等[5];caNanoLab[6]是旨在促进全球生物医学纳米技术研究社区的信息共享,以促进并验证生物医学中的纳米技术的用途[7];iDash[8]提供数据仓储、开源软件、架构、模型、算法等资源[9];Uniprot[10]旨在为科学界提供一个全面、高质量和能够自有获取的蛋白质序列和功能信息资源[11];蛋白质数据库(PDB)[12]是关于大型生物分子的3D结构信息的单一全球信息库[13];基因型和表型数据库(dbGaP)[14]是精选和发布由调查基因型和表型间相互作用的研究所产生的信息的数据仓库[15];PubChem[16]提供关于小分子的生物活性的信息[17];ClinicalTrials.gov提供患者及其家属、医疗专家、科研人员和公众的研究数据的入口[18];GenBank[19]是基因序列数据库,旨在提供和鼓励科学界获得最新和全面的DNA序列信息[20]。
2 数据共享仓储分析
NIH数据仓储中心提供了所有仓储的情况。本文围绕数据管理系统机制,提出分析框架,从数据提交、数据管理、数据检索、数据访问、数据下载、数据引用等层面对这些数据仓储进行深入分析。
2.1 数据提交规范各异
数据提交细化为数据内容、格式规范、提交流程、质量规定、审核流程和上传方式6个方面。
数据内容方面,各仓储内容横跨癌症影像、表型、基因组、序列、生物大分子结构、生物表达信息、健康相关信息、序列信息等。按照涉及领域划分,iDash、dbGaP、GenBank、FlyBase属基因领域,ClinicalTrials.gov、iDash属健康领域,UniProt、PDB属蛋白领域,PubChem属化合物领域,TCIA属肿瘤领域;按数据类型划分,ClinicalTrials.gov、TCIA均属于数据类型和内容单一型仓储,FlyBase、UniProt、PDB、PubChem属于内容单一的数据类型丰富的仓储,iDash则是在内容上较为丰富的集成型仓储。格式规范方面,多数仓储没有明确限制数据格式,也有给出建议格式的,如UniProt建议使用UniProtKB/Swiss-Prot格式,GenBank、PubChem给出了通用的格式;TCIA由于主要收集影像资料,格式主要为DICOM;PDB则对于提交的不同类型规定了不同的格式。就某一领域,数据的某种格式很可能是通用的,如基因领域,通用格式是FASTA。质量规定方面,60%的仓储,如caNanoLab等采用人工审核,其中,ClinicalTrials.gov会为用户提供审查标准供用户自行检查,再由审核人员控制;20%的仓储考虑加入自动审核,如dbGaP自动完成针对数据格式、元数据核对等一系列质量审核。提交流程方面,多数仓储仍然采用传统的提交数据、审核、通过后发布的模式设计流程,并加入与自身仓储特性结合的环节。以仅将原数据发布作为目标的机构为例,TCIA通过人员和软件的共同协作实现提交;iDash则需要用户先签订一份提交协议,包括内容和法律条款等,而后提交数据;UniProt、dbGaP、PubChem、ClinicalTrials.gov要求用户注册并填报所需元数据项(表1)。数据审核方面,除dbGaP仓储采用自动审核的方式外,其余均为人工审核。值得一提的是,PubChem审核数据更新情况时,采用半人工半自动的方式。数据上传方面,多数仓储使用最基本的附件上传方式,其余上传方式包括批量上传、FTP上传等,部分仓储实现了工具上传,如TCIA、GenBank分别使用CTP(临床试验处理器)及Sequin程序等工具上传。其中CTP可以在数据提交前根据DICOM标准对数据执行去识别的工作,Sequin用于在MAC、PC和UNIX平台通过FTP指导提交过程,ClinicalTrials.gov则直接输入数据元素。

表1 数据共享仓储数据提交规范
2.2 数据管理规范
数据管理细化为内容管理、数据管理和版本管理3个方面。
数据共享仓储数据管理规范情况见表2。
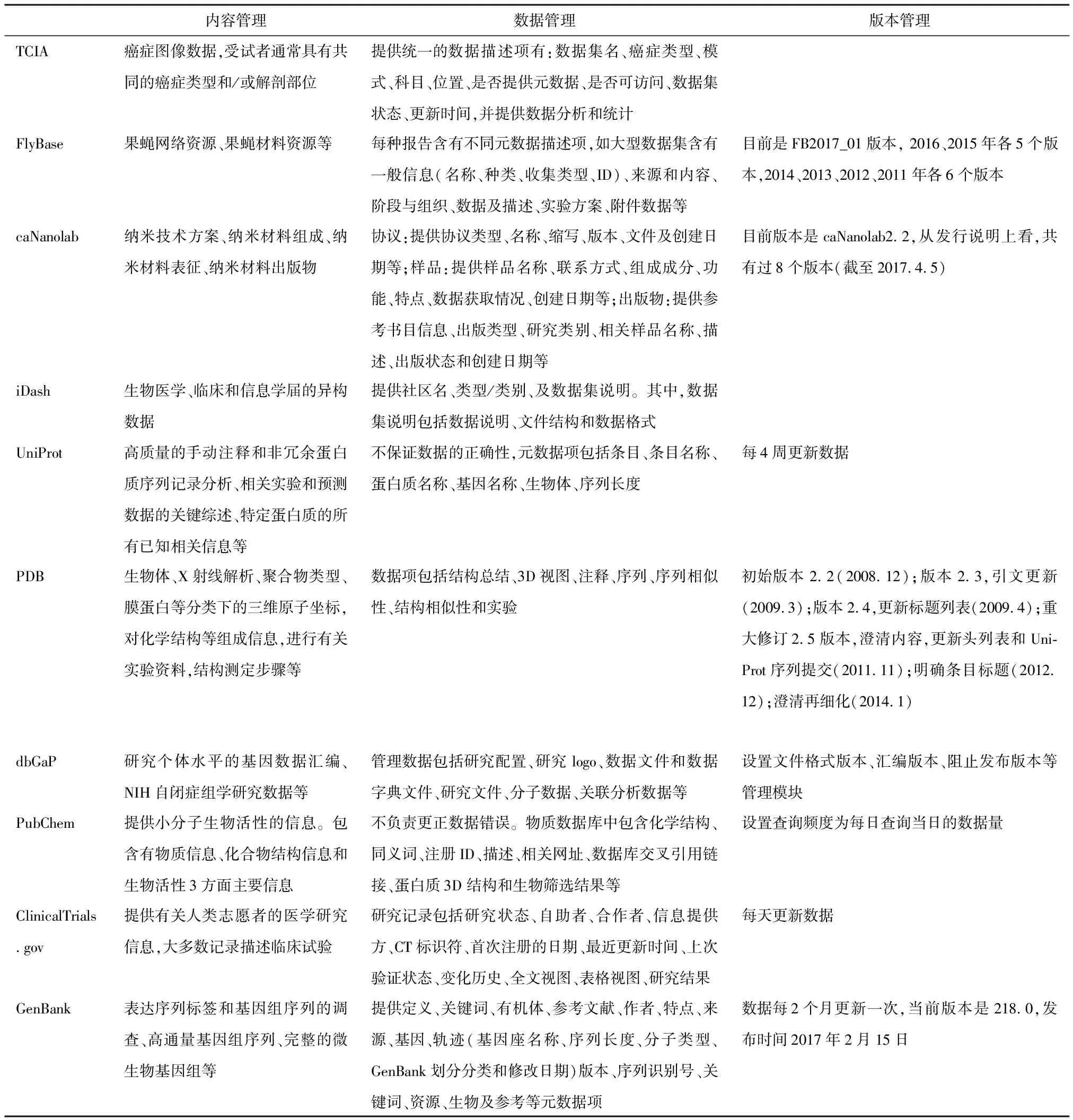
表2 数据共享仓储数据管理规范
内容方面,TCIA、FlyBase、caNanolab较为单一,如FlyBase主要涉及果蝇资源,aNanolab主要涉及纳米技术;其余仓储数据类型相对丰富,如iDash是生物医学异构数据的集合库,PubChem集成了物质信息、化合物信息和生物活性等方面的信息数据。就内容所属领域来说,UniProt、PDB、dbGaP、GenBank均包含基因组或蛋白质序列的内容,其细化研究领域各有专攻,如PDB对生物体、蛋白质、结构测定等更为关注,dbGaP主要研究个体水平的基因数据汇编,UniProt专攻蛋白质序列记录及分析等,GenBank则含有更多表达序列标签和基因组序列的信息。
数据管理方面,80%的仓储将数据发布后,会为用户提供相对统一的元数据项;对于仓储中包含多种类型数据的情况,会区别对待,如caNanolab,协议和样品需提供的元数据项是不相同的。另外20%的仓储可能由于内容的不同,如FlyBase中每种报告可能含有不同的元数据描述项,iDash数据以社区形式存放,相关说明由数据上传者提供,所以元数据项无法统一。
版本管理方面,FlyBase等4个仓储提供数据版本发布及管理功能,dbGaP设置文件格式版本、汇编版本、阻止发布版本等版本管理模块;数据更新频率方面,多数仓储保持每日到数月更新一次的频率。
2.3 数据访问
6个仓储可无限制访问和下载,部分设置权限。如dbGaP出于保护研究参与人员的意愿和隐私考虑,设置访问权限,并采取其他数据安全措施;TCIA中部分数据集需特定权限;caNanolab 、iDash 、PubChem 部分开放。6个仓储提供了详细的数据量数据。TCIA绝大部分数据集无需登录即可下载;caNanolab 则是由数据提交人或审核人决定该数据是否公开;iDash仓储中因包含很多安全、保密的数据库,故其部分数据集设有权限限制,用户需要首先加入数据社区,才能访问该社区内的资源(表3)。
2.4 数据检索规范
各仓储均提供多种检索方式,包括简单检索、高级检索与关联检索,部分仓储已经将检索工具投入使用。80%的仓储实现了高级检索,如PDB列出了包括机体、X射线分辨率、发布日期、酶分类、蛋白质对称性等检索类别,提供基于关键词、结构注释、所有实验类别等方面的筛选条件;ClinicalTrials.gov提供研究类型、研究结果、所属单位、年龄、性别、定向搜索等检索条件。40%的仓储提供了检索工具,如FlyBase提供的检索工具QueryBuilder允许用户使用模板查询、导入保存的查询或者构建新查询,自动创建与查询匹配的记录交叉引用的记录集,从单个页面提供到仓储中所有相关记录的链接;UniProt提供的检索工具BLAST可以查找序列之间的局部相似性区域并推测序列之间的功能及进化关系,GenBank提供的基本局部比对搜索工具BLAST等[21]和PubChem提供的基于结构相似度的物质聚类工具、识别结构活性关系并检查化合物的靶选择性和特异性的工具、支持快速搜索和检索单个生物测定记录的测试结果的工具以及用于检查和比较多个生物测试中的生物学结果的工具等(表3)。
2.5 数据下载规范
各仓储下载方式包括链接直接下载、FTP下载、API下载、批量下载等。多数仓储提供直接下载和FTP下载,ClinicalTrials.gov只提供在线搜索查看。其中有些仓储是以某个数据版本打包下载的,如Uniprot;也有以提供数据资源列表方式支持下载的,如TCIA。权限方面,4个仓储提供公开的数据集服务,4个仓储部分数据提供公开服务,2个仓储需要相关访问权限。其中,dbGaP则需要申请访问权限并符合相关政策,GenBank则做出了关于数据权限的说明。格式方面,除了TCIA格式较为单一外,其余仓储多含有通用格式及其他格式,具体信息参见表4。
2.6 数据引用规范
70%的仓储提供用户引用时的推荐格式,其中caNanolab还针对普通引用、已发布的数据引用和未发布的数据引用做出区分。个别仓储未标明引用样例格式,但给出了相关要求,包括dbGaP遵循DUC协议,ClinicalTrials.gov给出了引用时需标明的几点要求,iDash需要发表引用声明。引用协议方面,各仓储均根据自身情况引用了相关协议,如TCIA从促进数据共享与复用的强烈意愿为出发点,使用CC BY 3.0的引用协议。该协议标明用户可以自由共享或演绎,但必须署名,提供许可协议链接,如有修改需标明。iDash由于包含较多保密数据,因此要求用户遵循HIPAA法案。HIPAA法案(健康保险携带与责任法案)在卫生信息化环境下如何保护个人隐私的问题上开展了较为深入的探索[22]。UniProt要求遵循Creative Commons Attribution-NoDerivs协议[23]。该协议允许用户共享,前提是用户必须给出适当的信用值,提供许可链接,并指明是否进行了更改;如果对内容进行各种形式的重构,则不能分发结果。PDB以数据共享为出发点,数据完全开放[24],部分内容遵循CC-BY-4.0协议。该协议旨在无限制地允许用户进行共享和重构,用户同样需要遵循相关条件。其余数据仓储需遵循NIH相应管理政策。数据共享仓储下载与引用规范见表4。
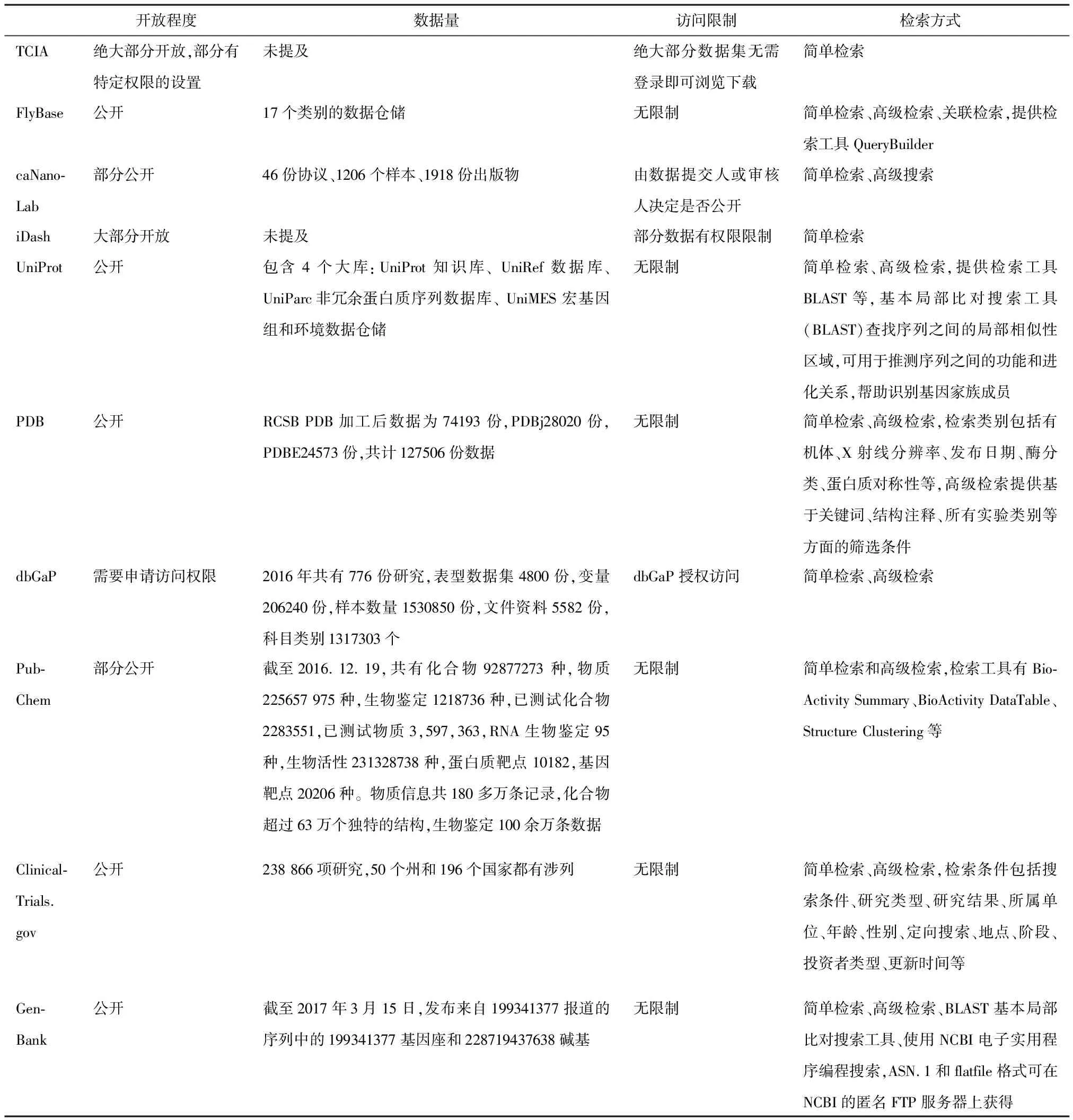
表3 数据共享仓储数据访问与检索规范

表4 数据共享仓储数据下载与引用规范
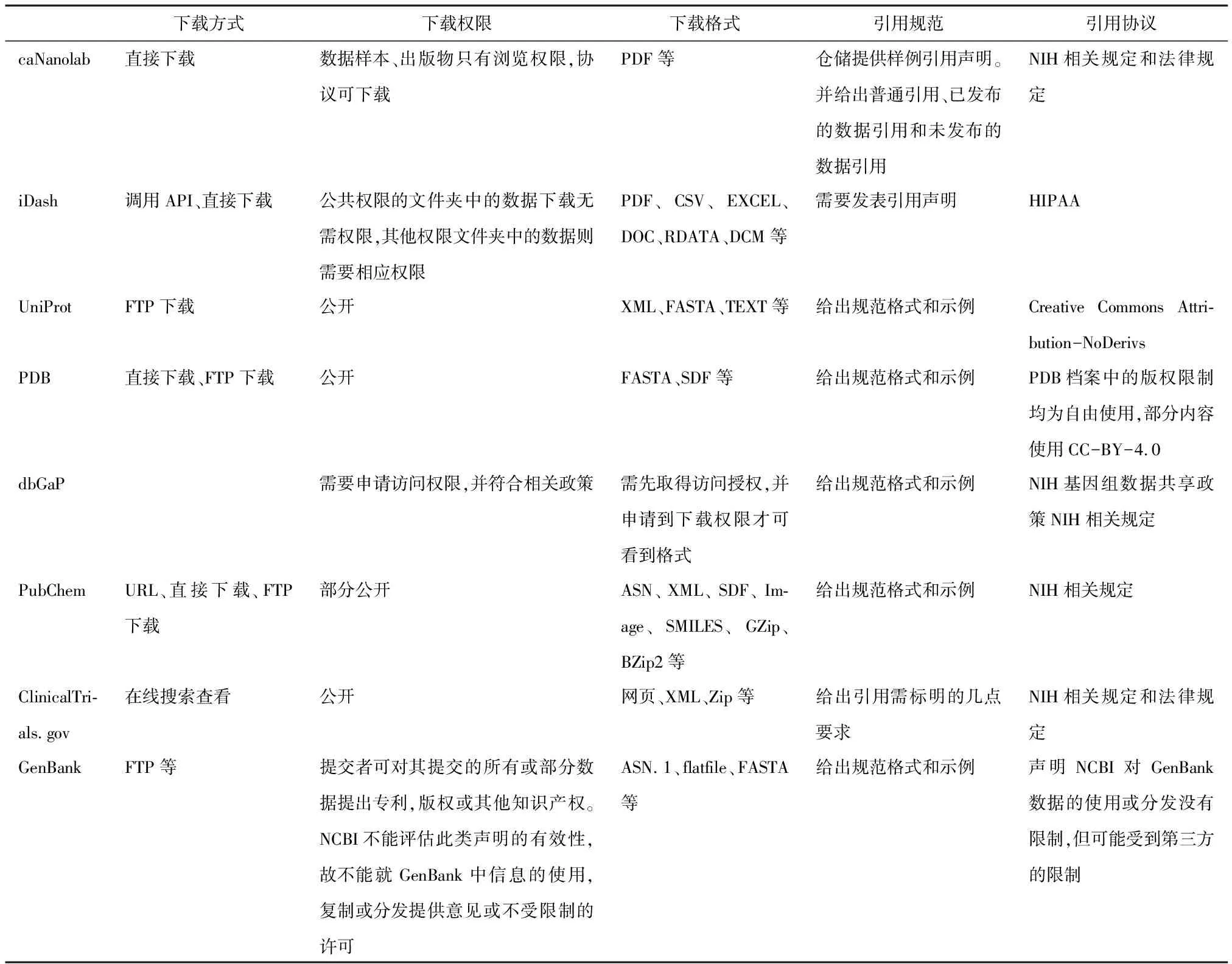
(续表4)
3 结语
NIH生物医学数据共享仓储的如下特点值得我们参考和借鉴。
数据提交方面,根据领域给出元数据内容要求,不限制数据格式。在附件上传的基础上,设计及应用了上传工具便于用户上传数据。为更好地进行数据核验,保留对数据资源人工审核质量的模式,个别仓储对半人工半自动或自动质量审核模式进行了探索。另外,在数据提交的过程中,iDash强调法律权益及版权方面的问题,因此事先拟定了要签署的协议,值得借鉴。
数据管理方面,各仓储内容不同,但均尽可能收集详细全面的元数据,并总结和发布相对统一的元数据项,同时提供数据的分析统计。仓储具有较好的版本管理规范,并定期对数据进行更新与检查。
数据服务方面,多数检索提供简单检索和高级检索,积极开展个性化检索工具的尝试与应用。仓储提供多种下载方式和数据格式,对于需要引用数据的用户,提供多种引用规范格式或样例,或做出声明,制定符合自身仓储特点的引用规范,并采用符合自身仓储特点、与行业标准、国家标准与政策相符合的数据引用协议(如CC协议)。
由于时间与精力限制,本文未对NIH生物医学数据共享仓储下的所有仓储进行全面调研,但通过对典型仓储进行分析比较及特点总结,希望能够为我国开展生物医学数据共享仓储建设提供一定的经验和启示。
