基于GPU/CPU和震源随机编码技术的混合域全波形反演
2017-03-15冯海新刘志伟
冯海新,刘 洪,孙 军,胡 婷,刘志伟
(1.中国科学院地质与地球物理研究所,北京100029;2.中国科学院油气资源研究重点实验室,北京100029;3.中国科学院大学,北京100049;4.唐山学院,河北唐山063020;5.中国地质科学院,北京100037)
基于GPU/CPU和震源随机编码技术的混合域全波形反演
冯海新1,2,3,刘 洪1,2,3,孙 军4,胡 婷1,2,3,刘志伟5
(1.中国科学院地质与地球物理研究所,北京100029;2.中国科学院油气资源研究重点实验室,北京100029;3.中国科学院大学,北京100049;4.唐山学院,河北唐山063020;5.中国地质科学院,北京100037)
传统的全波形反演利用普通炮集进行反演,反演计算量过大;且利用传统的相位编码技术进行全波形反演,会产生炮间串扰问题,因此,提出了基于GPU/CPU和震源随机编码技术的混合域全波形反演。该方法将参与反演的多个炮集随机组合并分成炮集数相同的组,各组炮集叠加形成多个组合炮集,然后将组合炮集代替普通炮集进行反演。与传统的相位编码反演方法相比,震源随机编码技术在反演效率和收敛速度方面均有优势,且减少了炮间串扰噪声;并且在GPU的加速下,计算效率会再次提升。Marmousi模型数据测试结果表明:组合炮集方法得到了与普通炮集方法相同的反演效果,但计算效率却比普通炮集方法明显提高,且相较于传统的相位编码技术,组合炮集方法有效抑制了串扰噪声。
混合域;全波形反演;GPU/CPU;组合炮集;震源随机编码
全波形反演(FWI)综合利用了地震记录中振幅、走时和相位等信息,通过拟合实际波场和预测波场来定量提取地下介质的弹性参数,进而为勘探地震成像及速度建模、深部大尺度构造演化分析[1-2]等提供可靠依据。
TARANTOLA[3]在1984年提出了基于广义最小二乘反演理论的时间域全波形反演,PRATT等[4]和SHIN等[5]在其基础上进一步发展了频率域和Laplace-Fourier域波形反演方法。频率域和Laplace-Fourier域波形反演本质上都是多尺度的反演方法,两者都遵循低频到高频的反演策略。利用SIRGUE等[6]的频率域优选策略,基于直接法的二维频率域反演效果相对于时间域反演效果更加有效。对于三维频率域波形反演问题,矩阵分解法有着极大的内存需求和计算量,使得大尺度三维频率域全波形反演问题变得困难。迭代法可以解决这个问题,但会失去频率域算法多炮高效正演的优势,并且随着频率的升高和模型复杂程度的增加,其收敛性也会变差。Laplace-Fourier域方法是一种使用复数频率的频率域方法(频率虚部代表地震记录在时间方向上的衰减系数),该方法可以恢复大尺度构造,并且能降低反演算法对初始模型的依赖;但是,作为一种频率域方法的扩展,它继承了频率域方法的缺点,即基于直接法的三维模型需要很大的内存和计算量。
考虑到这些问题,SIRGUE等[7]通过离散傅里叶变换,将时间域FWI和频率域FWI结合起来,提出了混合域FWI方法。该方法将波传播在时间域进行,即在时间域正演,利用离散傅里叶正变换(DFT)提取响应的频率成分,进而在频率域构造梯度场。这种方法可用最小的耗时来获得任意频率成分,尤其当GPU参与到程序并行计算时,其计算效率会更高。此外,相对频率域窗函数在混合域更易添加,从而得到某些波至的特征,如早至波、反射波等,这些波经常被用来降低反演的非线性。KIM等[8]将这种混合域的思想应用到了Laplace-Fourier域,并将其应用到了三维宽方位角的实际资料FWI中。由于时间域算法相对频率域和Laplace-Fourier域有着更少的内存占用和计算量,所以混合域的方法使得三维多尺度波形反演具备实现的可能性。JUN等[9]进一步将该思想应用到了二维时间-Laplace-Fourier混合域弹性波全波形反演。
无论是时间域、频率域、Laplace域,还是混合域反演,FWI都面临着海量计算的问题。FWI技术已逐渐由理论模型研究发展到实际数据应用研究,然而计算量超大制约了该技术在实际生产中的广泛应用。针对FWI的大计算量问题,DIAZ等[10]提出了一种改进的策略,利用随机抽取的炮集在时间域进行全波形反演,相对于未改进的波形反演,在每次迭代时,并不是让全部炮集参与反演,而是随机抽取炮集参与反演。在此基础上,HA等[11]采取对普通炮集进行循环采样,在每次迭代时仅仅对循环采样选取的炮集进行反演计算。这两种方法都能在一定程度上提高反演的计算效率,但是难以从根本上解决全波形反演的大计算量问题。KREBS等[12]基于多炮同时反演的思想提出了一种基于相位编码技术的多炮同时反演方法,利用随机产生的相位编码函数分别与震源实际地震记录褶积,形成一个超级震源和超级炮记录,这样对于所有炮的反演计算即可转换成对一个超级炮集记录进行反演,大幅度提高了全波形反演的计算效率(计算效率约可提高炮数比的倍数)。由于该方法是对一个超级炮记录进行反演,即多炮同时反演,因此会产生大量的炮间串扰噪声(cross-talk),从而影响整个全波形反演的计算精度和收敛效率。
GPU俗称“显卡”,是一款用于计算机显示的硬件设备,是一种高并行度、多线程、计算能力巨大和存储器带宽极高的多核处理器。CUDA(Compute Unified Device Architecture)语言是一种基于指令集架构和新的并行编程模型的通用计算架构,能够利用GPU的并行计算引擎,比CPU更高效地解决许多细粒度的计算任务。在石油工业中,尤其是地震数据处理领域,GPU受到越来越多的重视。LI等[13]率先将GPU并行计算应用于非对称走时Kirchhoff叠前时间偏移,大幅度提升了成像计算效率。LIU等[14]在GPU上实现了三维逆时偏移,并给出了程序优化策略。MICIKEVICIUS[15]用GPU实现了三维有限差分程序,并提出了单通法和双通法两种优化策略,也是目前常用的程序优化方法。GPU在石油工业普及的趋势,已经逐渐将GPU推举为下一代地震资料处理的主要计算平台。
针对传统混合域全波形反演策略,本文提出了一种基于GPU/CPU和震源随机编码技术的混合域全波形反演方法,在频率域迭代时,利用震源随机编码技术,将实际炮记录随机组合,分成若干组,每组炮集数相同,然后将每组炮记录叠加,形成一个组合炮集或超级炮集(Super-Shot)。最后,利用Marmousi模型数据验证了本文方法的有效性。
1 方法原理
1.1 混合域反演原理
全波形反演按照波场求取方式可分为:时间域全波形反演、频率域全波形反演和Laplace-Fourier域全波形反演。混合域全波形反演是在时间域进行正演、在频率域进行反演的一种反演方法。频率域声波方程可以写成:
(1)
式中:f(ω)为震源项;S(v,ω)为系数矩阵,与模型参数、差分离散格式、频率和边界条件有关;v是速度模型参量,反演即是对v不断更新;u(ω)为频率域的声波波场。
梯度场为:
(2)
式中:F表示所有虚震源的集合;δd*表示残差波场的复共轭;r表示残差反传波场。
(3)
如果S(v,ω)矩阵对称,则有:
(4)
如果S(v,ω)矩阵不对称,则需要用到LU分解的转置。
第i个模型参量对应的梯度场可以表示为:
(5)
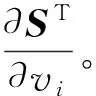
由公式(1)得出,频率域声波方程系数矩阵的微扰可以表示为:
将公式(7)代入公式(5)得到频率域梯度求取公式:
(8)
1.2 震源随机编码技术
普通震源编码技术,就是对单炮集进行编码,选取固定数目的单炮,形成一个组合炮,然后以组合炮为单位来计算公式(8)的梯度值。该方法的缺点是,当多炮叠加到一起时,炮与炮之间会相互干扰。利用随机编码技术可以消除这种不良影响。随机编码可以在两个方向上随机:①在横向方向上使炮点位置随机;②沿着纵向方向给各个炮点加上时延,并使时延长度随机。本文以炮点位置随机为例说明随机编码的实现方式和有效性。
组合炮集对应的目标函数可表示为:
式中:Ucal,Uobs分别为模拟数据组合炮集、实际数据组合炮集;shot为单炮记录;Ms是组合炮集的个数;xi是组合炮集的位置,由M个普通炮集叠加而成。i为Rand函数产生1到Ns(单炮个数)的一组随机数,每一个随机数对应一个炮点位置(即震源位置),即对震源进行编码;利用该随机数可以有效压制炮间串扰现象。模拟组合炮集是由组合震源激发产生,Ucal(xj,ω;xi)满足公式:
(11)
其中,DFT表示傅里叶正变换。
(12)
组合炮集的个数和普通炮集个数满足关系式:
(13)
式中:floor代表向下取整运算。
理论上,采用组合炮集方法可使计算量降低为普通炮集方法的1/M倍。但是炮点的组合会引入串扰噪声,即波场之间的相互重叠造成所在位置对应的模型参量更新有误。我们对普通炮集进行随机编码,形成Ms个组合炮和Ms个组合震源,将组合炮代替普通炮集参与反演计算,使串扰噪声产生的可能性降低。且每次迭代时随机编码改变,这样每次对应的地下重叠位置会随机变化,避免相同的串扰噪声作用于每次迭代,随着叠加和迭代的进行,串扰噪声便会被压制。因此,在反演精度和收敛速度方面,基于震源随机编码技术的全波形反演要优于传统的相位编码技术。当M=1时,便是普通炮集反演技术。当组合炮集个数较少时,其反演效果要比普通炮集反演效果差,这时,我们可以通过增加组合炮集个数来改善反演效果。
1.3 GPU/CPU协同并行计算
GPU将问题分解成线程块的网格,每块包含多个线程,如图1所示,其中黄色部分表示线程块的网格,绿色部分表示每一个网格中所包含的线程块,蓝色部分表示每一个线程块所包含的线程束。块可以按照任意顺序执行。CUDA内部有自建的变量ThreadIdx,BlockIdx来标明线程号和块号。一个线程可以通过线程号、块号以及线程维度信息来获取其在所有线程中的一个标号。在一维情况下标号等于ThreadIdx.x,在Block大小为(Bx,By)的二维时,标号为ThreadIdx.x+ThreadIdx.y×Bx。而在(Bx,By,Bz)的三维Block情况下,线程标号为ThreadIdx.x+ThreadIdx.y×Bx+ThreadIdz.z×By×Bz。在Grid下的不同Block中线程之间的执行完全是并行的,没有同步机制,也不能够串行执行。
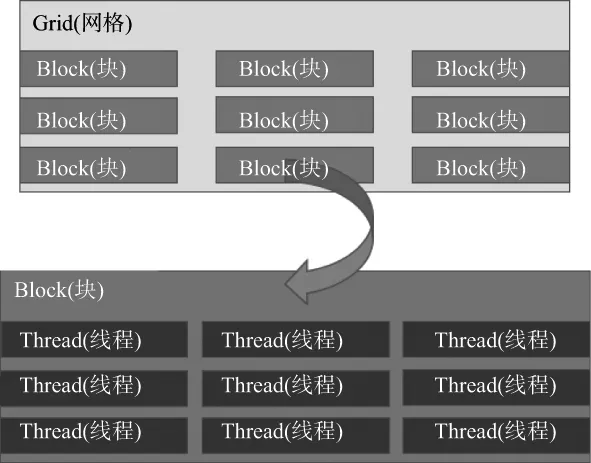
图1 GPU线程组成
基于CUDA进行编程时,主机作为Host,主要有两个功能:①利用主机函数(Host Function)负责程序的串行计算;②负责CPU和GPU之间的数据传输,并行计算时,CPU读取输入数据并复制到GPU卡中,计算结束将结果复制到CPU中,为其串行计算提供数据。GPU作为设备(Device),其内运行的函数称之为核函数(Kernel Function),主要负责程序的并行部分。
我们所采用的硬件设备是单GPU卡节点。该节点由一个CPU和一个NVIDIA GeForce GTX 580显卡组成。每炮数据的梯度求取涉及多个GPU模块,包括:执行空间高阶有限差分GPU模块,PML吸收边界GPU模块,地表接收波场提取的GPU模块,波场正传时的离散傅里叶变换GPU模块,时间域残差求取的GPU模块,目标函数值求取的GPU模块,残差波场加载的GPU模块,残差波场反传时的离散傅里叶变换GPU模块,梯度场求取的GPU模块,求取梯度场最大值的GPU模块,优化步长求取的GPU模块,更新速度模型的GPU模块。这些模块都是在GPU上完成。基于GPU/CPU协同计算的伪代码如图2所示。

图2 基于GPU/CPU和震源随机编码技术的全波形反演伪代码
图2中的主要函数和参数说明见表1,其中后缀“cuda”表示在GPU上运行的程序。
1.4 实现流程
本文根据GPU/CPU的加速方法和CUDA代码的实现方式,结合震源随机编码技术,实现了Host函数和Kernel函数。本文方法实现流程如图3所示,其中绿色部分表示在GPU上实现的模块,红色方块部分表示本文方法相对于传统混合域方法[16]的改进之处。

表1 图2中主要函数及参数说明
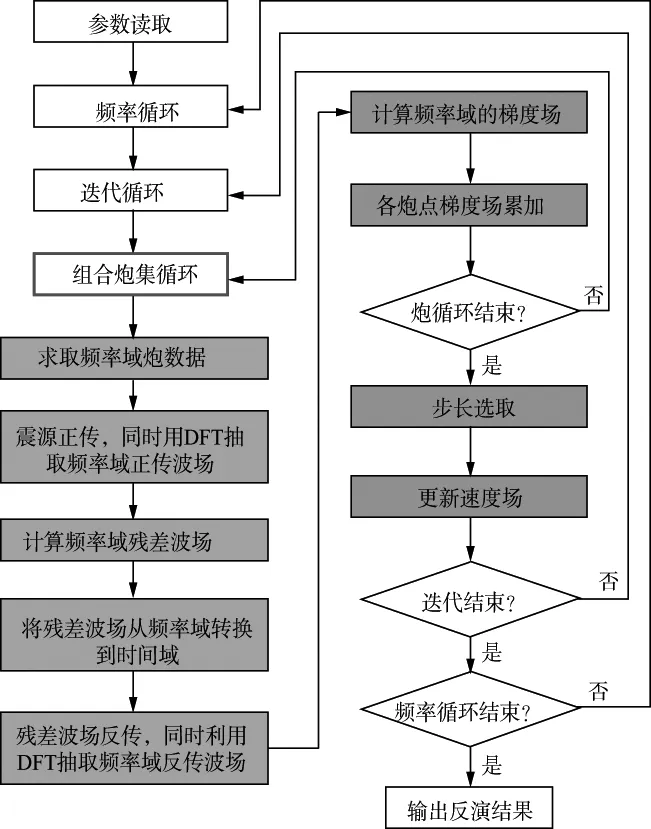
图3 本文方法实现流程
2 模型应用及效果分析
采用Marmousi模型,对本文方法进行测试。该模型网格大小为400×120,网格间距均为5m。基于该模型建立道固定、炮移动的观测系统。起始炮位于网格点(3,2)处,炮点个数为65,炮间距为30m,每一炮均采用双边接收,检波器个数固定为400个,检波器间距为5m,采样时间长度为2s,时间采样间隔为0.001s。我们采用空间优化12阶,时间2阶差分格式进行正演,采用PML边界条件,其中,PML边界大小为20层。震源采用主频为18Hz的Richer子波。初始速度模型采用平滑速度模型,反演算法采用拟Hessian矩阵法,步长求取采用步长衰减法,虽然该步长求取方法精度较低,但计算量小,更多的计算资源主要用于梯度场求取。图4和图5分别为真实速度模型和初始速度模型。我们分别采用组合炮集和普通炮集进行反演。
本文采用等差频率进行反演,从3.5Hz开始,每次增加1.5Hz,直到39.5Hz,总共25个频率,分成24个频率组,每个频率的最大迭代次数为18。我们选取第6组、第12组、第18组及第24组的反演结果进行对比。图6,图7,图8和图9分别为采用普通炮集方法和本文组合炮集方法在第6组、第12组、第18组和第24组的反演结果。分别抽取真实速度模型、初始速度模型、普通炮集方法和组合炮集方法的反演结果在水平网格点200处(水平方向1000m处)的速度曲线进行对比,结果如图10所示。对比图6,图7,图8和图9,并分析图10,可见,组合炮集反演结果与普通炮集反演结果相差无几,两种方法的反演速度曲线拟合得较好。
我们采用的迭代终止条件为:|fmod-fmod_pre|/fmod<0.001,利用(‖V实际-V反演‖2/‖V实际‖2)×100%来评价反演精度。两种方法得到的迭代终止条件值和反演精度如表2所示。
分析表2可知,组合炮集方法的第12组和普通炮集方法的第18组、第24组的迭代终止条件值均小于0.001,表示反演没有达到最大迭代次数,便会终止迭代,进入下一组频率反演计算。并且,第6组、第12组、第18组以及第24组,每组组合炮集方法的反演精度均低于普通炮集反演方法的反演精度,但随着反演频率组数的增加,两种方法的反演精度之差在逐渐缩小,到最后一组反演频率,反演精度之差已经降低到0.26%,充分说明本文方法的反演效果与普通炮集方法的反演结果相当。
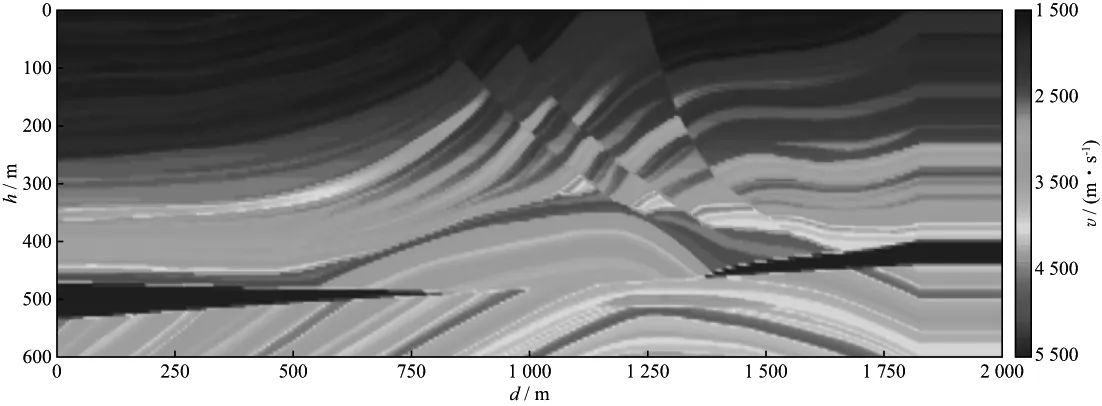
图4 真实速度模型

图5 初始速度模型

图6 第6组速度反演结果a 普通炮集方法; b 组合炮集方法
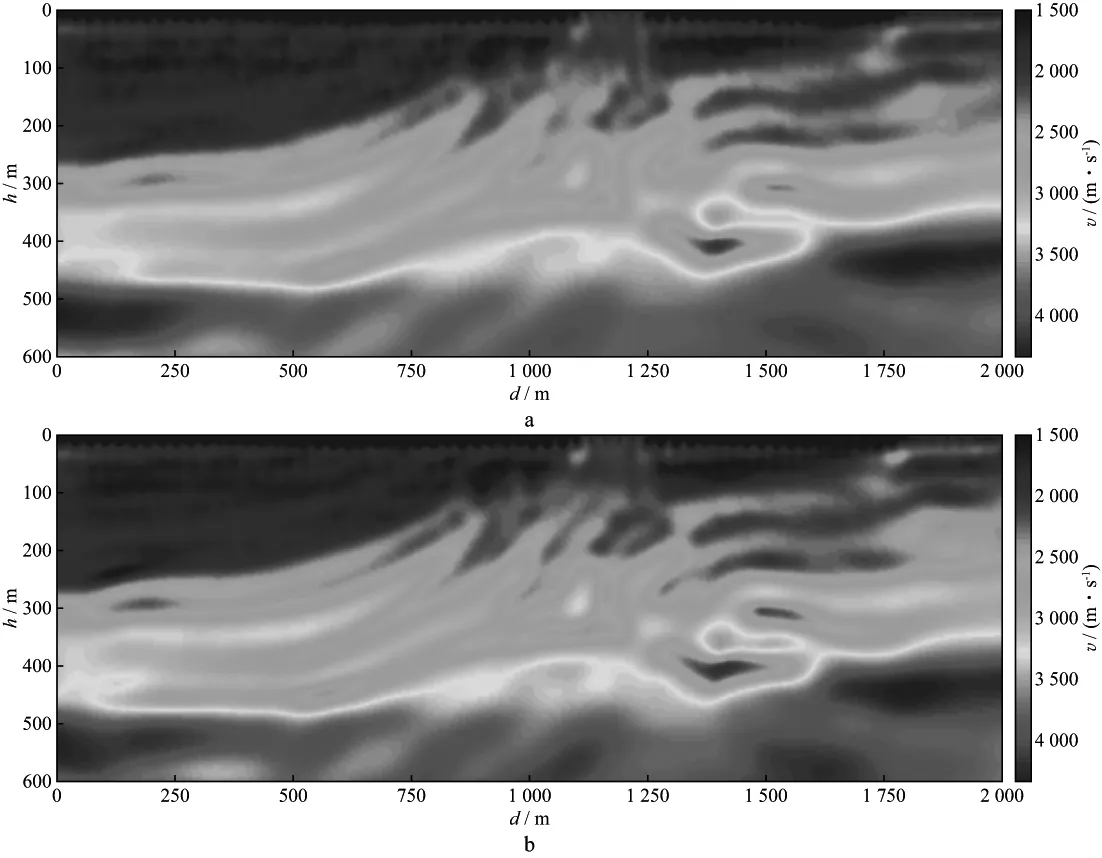
图7 第12组速度反演结果a 普通炮集方法; b 组合炮集方法

图8 第18组速度反演结果a 普通炮集方法; b 组合炮集方法

图9 第24组速度反演结果a 普通炮集方法;b 组合炮集方法
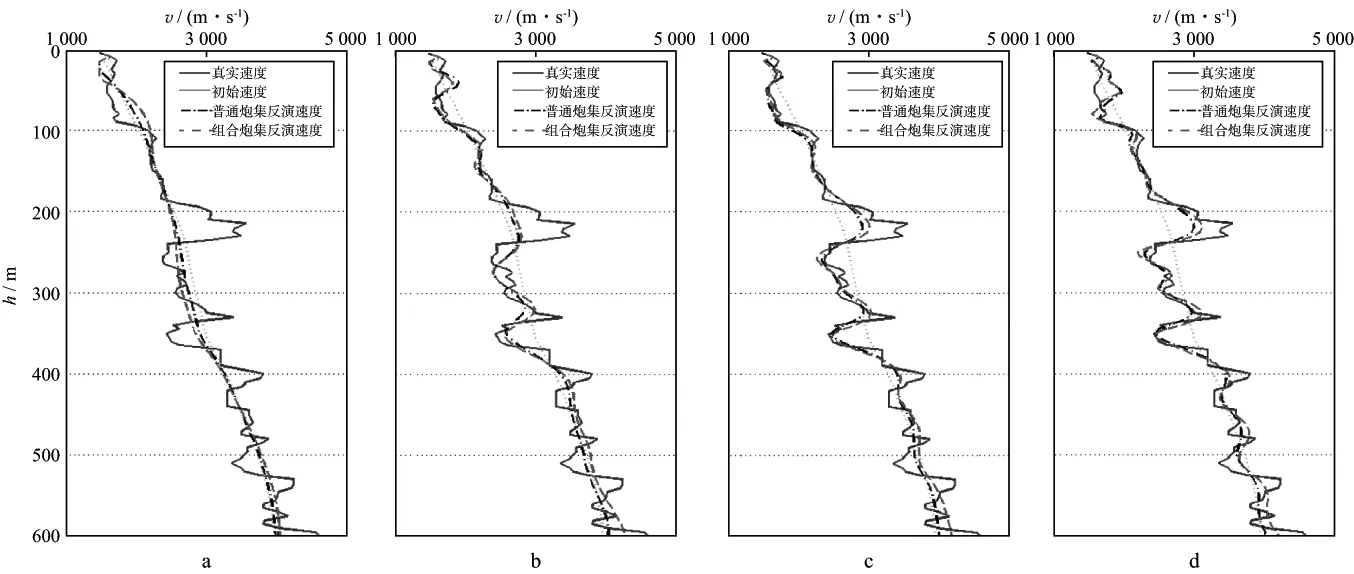
图10 第6组(a)、第12组(b)、第18组(c)和第24组(d)反演速度曲线
由于实验模型较小,本文在单GPU卡上进行计算,组合炮集混合域波形反演所用时间为105s左右,普通炮集混合域波形反演所用时间为530s左右,组合炮集反演所用时间约为普通炮集反演所用时间的1/5。
与GPU代码对应,我们编写了相应的CPU代码,从而测试了两种代码的执行效率。此次测试我们所采用的硬件设备是一个联想ThinkCentre小型工作站,CPU为主频3.0Hz的8核i7处理器,内存8GB,并且配备了Kelper架构的GTX680显卡。该显卡共有1536个处理器,2GB的共享内存,时钟频率为1.06Hz。CUDA版本为4.2。针对该模型,GPU代码需要105s完成一次迭代,而CPU代码需要2971s,加速比为28.3。
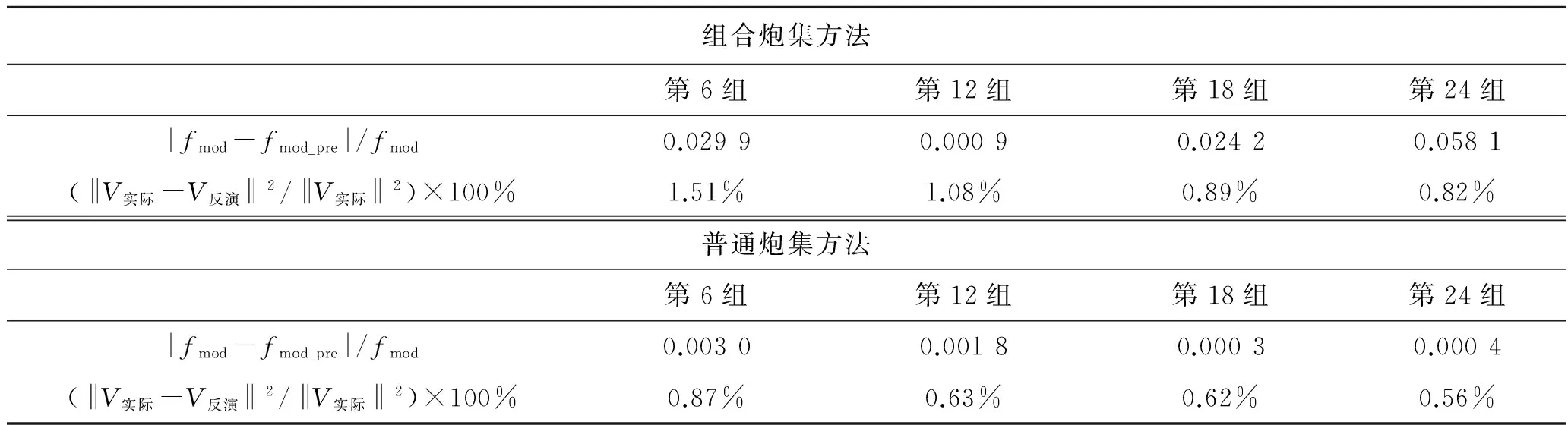
表2 迭代终止条件值及反演精度
3 结论
本文提出并实现了基于GPU/CPU和震源随机编码技术的混合域全波形反演,利用GPU/CPU协同计算,提高了计算效率,并在此基础上对混合域全波形反演由利用普通炮集反演变为利用随机组合炮集进行反演,实现了震源随机编码技术在混合域全波形反演中的应用。通过理论分析和模型实验得出如下结论:
1) 震源随机编码技术通过对随机炮的选取,压制炮间串扰噪声,从而获得比传统相位编码技术更高的反演精度和收敛效率。理论上讲,在相同的迭代次数和反演频率的情况下,可以通过增加随机组合炮集数来达到与普通炮集反演相同的精度。
2) 利用GPU卡进行全波形反演大幅度提高了混合域全波形反演计算效率。
[1] BLEIBINHAUS F,HOLE J A,RYBERG T,et al.Structure of the California Coast Ranges and San Andreas Fault at SAFOD from seismic waveform inversion and reflection imaging[J].Journal of Geophysical Research:Solid Earth,2007,112(B6):3015-3018
[2] OPERTO S,VIRIEUX J,DESSA J X,et al.Crustal seismic imaging from multifold ocean bottom seismometer data by frequency domain full waveform tomography:application to the eastern Nankai trough[J].Journal of Geophysical Research:Solid Earth,2006,111:B09306
[3] TARANTOLA A.Inversion of seismic reflection data in the acoustic approximation[J].Geophysics,1984,49(8):1259-1266
[4] PRATT R G,SHIN C,HICKS G J.Gauss-Newton and full Newton methods in frequency-space seismic waveform inversion[J].Geophysical Journal International,1998,133(2):341-362
[5] SHIN C,CHA Y H.Waveform inversion in the Laplace—Fourier domain[J].Geophysical Journal International,2009,177(3):1067-1079
[6] SIRGUE L,PRATT R.Efficient waveform inversion and imaging:a strategy for selecting temporal frequencies[J].Geophysics,2004,69(1):231-248
[7] SIRGUE L,ETGEN J,ALBERTIN U.3D frequency domain waveform inversion using time domain finite difference methods[J].Expanded Abstracts of 70thEAGE Annual Conference,2008:F022
[8] KIM Y,SHIN C,CALANDRA H,et al.An algorithm for 3D acoustic time-Laplace-Fourier-domain hybrid full waveform inversion[J].Geophysics,2013,78(4):R151-R166
[9] JUN H,KIM Y,SHIN C,et al.2D elastic time-Laplace-Fourier-domain hybrid full waveform inversion[J].Expanded Abstracts of 83rdAnnual Internat SEG Mtg,2013:1008-1013
[11] HA W,SHIN C.Efficient full waveform inversion using a cyclic shot sampling method[J].Expanded Abstracts of 82ndAnnual Internat SEG Mtg,2012:1-5
[12] KREBS J R,ANDERSON J E,HINKLEY D,et al.Fast full-wavefield seismic inversion using encoded sources[J].Geophysics,2009,74(6):WCC105
[13] 李博,刘国峰,刘洪.地震叠前时间偏移的一种图形处理器提速实现方法[J].地球物理学报,2009,52(1):245-252 LI B,LIU G F,LIU H.A method of using GPU to accelerate seismic pre-stack time migration[J].Chinese Journal of Geophysics,2009,52(1):245-252
[14] LIU G F,LIU Y N,REN L,et al.3D seismic reverse time migration on GPU[J].Computers & Geosciences,2013,59(3):17-23
[15] MICIKEVICIUS P.3D finite difference computation on GPUs using CUDA[R].Workshop on General Purpose Processing on Graphics Processing Units,2009:79-84
[16] LIU L,DING R,LIU H,et al.3D hybrid-domain full waveform inversion on GPU[J].Computers & Geosciences,2015,83:27-36
(编辑:顾石庆)
Hybrid domain full waveform inversion based on GPU/CPU and source random coding technique
FENG Haixin1,2,3,LIU Hong1,2,3,SUN Jun4,HU Ting1,2,3,LIU Zhiwei5
(1.InstituteofGeologyandGeophysics,ChineseAcademyofSciences,Beijing100029,China;2.KeyLaboratoryofPetroleumResourcesResearch,Beijing100029,China;3.UniversityofChineseAcademyofSciences,Beijing100049,China;4.TangshanCollege,Tangshan063020,China;5.ChineseAcademyofGeologicalSciences,Beijing100037,China)
For the conventional waveform inversion we use the common shot gathers,which consumes too much computation capacity.The conventional phase coding technique to carry out the full waveform inversion will induce the problem of cross talk between the shots.In order to solve these problems,we propose a hybrid domain full waveform inversion based on GPU/CPU and source random coding technique.This method randomly combines the shot gathers and divides the shot gathers into groups with the same number of shot gather.Then,the common shot gathers are replaced by the combined shot gathers to carry out inversion.Compared with the traditional phase coding technique,source random coding technique can effectively increase the efficiency and the convergence rate and reduce the cross talk noise.With the acceleration of the GPU computation,the full waveform inversion efficiency of the hybrid domain is effectively improved further.The testing result with Marmousi model shows that the common shot gathers and the combined shot gathers have the same inversion result,but the computational efficiency of the combined shot gathers is significantly higher than that of the common shot gathers.Compared with the traditional phase encoding technique,crosstalk is effectively suppressed by the combined shot gathers.
hybrid domain,full waveform inversion,GPU/CPU,combined shot gathers,source random coding
2016-07-20;改回日期:2016-11-25。
冯海新(1987-),男,博士在读,主要从事油储地球物理方面的研究。
刘洪(1959-),男,研究员,主要从事油储地球物理方面的研究。
国家重点研发计划(2016YFC0601101)和中国石油集团“弹性波地震成像技术合作研发课题”(2015A-3613)联合资助。
P631
A
1000-1441(2017)01-0107-09
10.3969/j.issn.1000-1441.2017.01.013
This research is financially supported by the National Key Basic Research Program of China (Grant No.2016YFC0601101) and the Collaboration Project of Seismic Imaging in Elastic Medium of China National Petroleum Corporation (Grant No.2015A-3613).
