用于不平衡数据分类的0阶TSK型模糊系统
2017-03-12顾晓清蒋亦樟王士同
顾晓清 蒋亦樟 王士同
模糊系统是对处理生产和实践过程中的思维、分析、推理与决策等过程构建的一种数学模型,能够将自然语言直接转译成计算机语言.由于具备不确定和模糊信息的处理能力,并具有高度的可解释性和强大的学习能力,模糊系统在分类问题上受到广泛关注,应用领域有信号处理,医疗诊断等[1−7]方面.模糊系统的参数学习一般可由专家经验人为赋值或基于相关数据的学习来获得,但很多情况下专家经验并不存在或不完备,而后一种方法因其强大的学习能力在实践中更具可行性.在现实生活中,不平衡数据的分类问题应用广泛,例如,医疗诊断应用中,绝大部分对象都是正常人群,只有很少一部分是疾病患者;入侵检测和钓鱼网站识别应用中,异常样本通常只占所有样本非常小的比例.然而,在许多实际应用中,与多数类样本相比,少数类样本的有效识别更具有意义,也往往是研究者关注的重点对象.
确定所需规则数和规则空间的划分以及确定模糊规则的后件参数是模糊系统建模的两大关键技术[8].对于第一项,传统模糊系统构建分类器时常采用聚类的方法,一种是不考虑样本的标签信息,在整个数据集上进行聚类;另一种是在每一个类别的样本中独立进行聚类,然后再将各聚类结果进行整合.但是,这两种方法在处理不平衡数据分类问题时存在以下不足:前者由于没有利用样本的类别标签信息,往往会因为少数类样本的数量稀少而把少数类样本视为异常点或噪声;后者仅是简单地将各类别样本割裂开来,两类样本重叠区域会出现聚类中心间距过小或中心点重叠的现象.对于模糊规则的后件参数学习,传统模糊系统一般遵循模型误差最小化的原则,如文献[9]中的递推最小二乘法,文献[10]中的不对称最小二乘法,这类方法在处理样本容量平衡的分类问题时具有较高精度.但是在处理不平衡数据的分类问题时,这类模糊系统往往倾向于追求多数类样本的高识别率来达到整体样本分类误差的最小化,在这种情况下,分类面不可避免地会向少数类样本发生偏移,少数类样本的识别就存在较高的误判率[11].因此,研究模糊系统在不平衡数据分类上的应用是有必要的和值得关注的.
目前针对不平衡数据的分类问题,在模糊系统领域一般通过过采样或欠采样技术来调整正负类样本的比例,如文献[12−13]采用过采样技术给模糊规则设置不同权重来提高少数类样本的分类精度;文献[14−15]先定位样本点的分布然后抽取不同类别的代表点实现类别间数据的平衡.文献[16]提出了过采样和欠采样的结合方法来处理不平衡数据的分类问题.但是这类算法的缺点是会改变样本的原始分布结构,采取精确复制少数类样本的策略容易造成分类器的过拟合,而采取欠抽样多类样本的策略容易丢失部分样本信息.另外,由于代价敏感学习[17−18]关注错分样本的代价,其相关算法也常用来解决不平衡数据的学习问题.
针对上述模糊系统在不平衡数据分类中前/后件参数学习的不足,本文提出了一种适用于不平衡数据分类的0阶TSK型模糊系统(Zero-Order-Takagi-Sugeno-Kang fuzzy system for imbalanced data classi fi cation,0-TSK-IDC),能在较好地处理不平衡数据分类的同时,保证所得规则的可解释性.鉴于0阶TSK型模糊系统具有简单性和可解释性等优点[19],本文将其作为研究对象.0-TSK-IDC在不改变原有样本分布结构的基础上,从模糊规则的前件参数学习和后件参数学习两个方面进行研究,首先,在模糊规则前件参数的学习上,受文献[20]使用惩罚对手的竞争学习来加速聚类收敛性和文献[21]防止聚类中心重合而最大化聚类中心间距的启发,本文认为在样本的类别标签已知的情况下,不同类别样本的聚类中心在学习过程中会产生了一种“竞争”关系,即聚类中心受同类别样本的吸引向该类别的数据密集区域“靠近”,同时也受到其他类别样本的“排斥”而被推离异类数据.本文将这一思想融入贝叶斯聚类(Bayesian fuzzy clustering,BFC)[22]模型中,提出了一种新的竞争贝叶斯模糊聚类(Bayesian fuzzy clustering based on competitive learning,BFCCL).BFCCL在聚类过程中考虑样本的结构信息和不同类别聚类中心之间的排斥作用,采用不同类别样本交替优化的策略,并通过马尔科夫蒙特卡洛方法实现整个数据集的模糊划分.BFCCL的优点在于能够在类别不平衡的空间划分中表现出准确性,有利于后件参数的学习,同时能有效增强所得模糊规则的可解释性.
其次,本文设计的模糊规则后件参数学习的策略是在遵循分类面“大间隔”的同时考虑纠正分类面的偏移,使少数类样本到分类面的距离大于多数类样本到分类面的距离.该策略在目标函数的设计中同时考虑了结构风险和经验风险,其训练过程可转化为二次规划问题求解,保证结果的全局最优解,从而0-TSK-IDC模糊系统具有较高的泛化性和鲁棒性.
本文结构如下:第1节回顾了相关工作,包括TSK型模糊系统和BFC算法的相关概念及原理;在此基础上第2节提出了BFCCL算法;第3节提出了用于不平衡数据分类的0-TSK-IDC模糊系统;第4节通过在人工数据集和4个不平衡医学诊断数据集上的实验说明了BFCCL及0-TSK-IDC的有效性;第5节总结全文.
1 相关工作
1.1 TSK型模糊系统
经典模糊系统可分为3类[23−24]:Mamdani型模糊系统、Takagi-Sugeno-Kang(TSK)型模糊系统和Generalized模糊系统.其中,
TSK型模糊系统的第k个模糊规则的表示形式如下[25]:
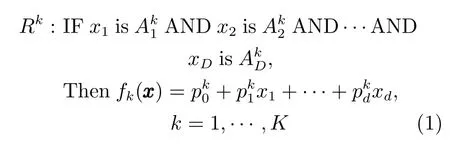
其中,TSK型模糊系统中每一条规则都有与之对应的输入向量,并把输入空间的模糊子集投影到输出空间的模糊集为输入向量xxx第i维所对应的第k条规则的模糊子集,K是模糊规则数,D是样本维数.当模糊规则后件部分为一个实数值,即时,表示该模糊系统为0阶TSK型模糊系统.由于0阶TSK型模糊系统输出的简洁性,以及模糊规则后件参数更具有可解释性,而受到广泛关注.0阶TSK型模糊系统的实值输出为
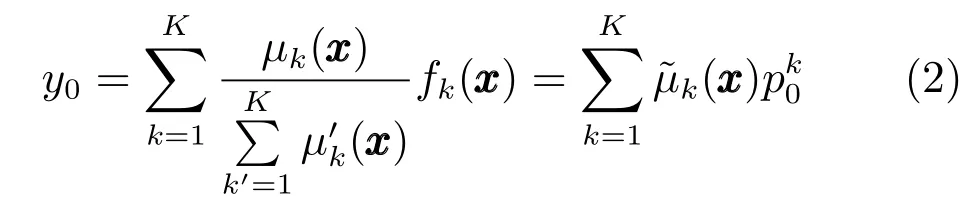
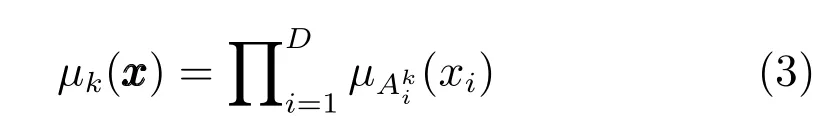
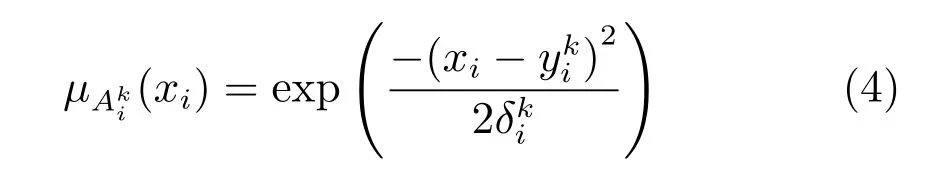

其中,ujk为输入向量隶属于第k类的模糊隶属度,尺度参数h为一正常数.
传统的0阶TSK型模糊系统的规则后件参数学习常遵循模型误差最小化原则[9−10],其可表示为

其中,yi为期望输出.如在式(6)基础上考虑结构风险最小化原则,规则后件参数的学习可转化成线性回归的二次规划问题.但其在处理不平衡数据分类时,往往倾向于对多数类具有较高的识别率,而对少数类的识别率却很低.
1.2 贝叶斯模糊聚类(BFC)
贝叶斯模糊聚类(BFC)算法[22]从概率的角度重新阐释了FCM 聚类,并依据贝叶斯推理通过马尔科夫蒙特卡洛(Markov chain Monte Carlo,MCMC)方法[27]来估计模型的最大后验概率,得到隶属度和聚类中心的全局最优解.对于给定的样本集,BFC模型可表示为:


其中,N是样本数,C是聚类数,unc是样本属于第c个聚类的隶属度,m是模糊指数,是第c个聚类中心,是D维单位矩阵,是归一化常数.BFC算法假设样本服从正态分布为分布的中心,为分布的协方差矩阵.可见BFC中每个样本具有独立的概率分布.同一个聚类中的样本分布共享一个期望值,但具有不同的协方差.

其中,xc≥0,c=1,···,C且.Dirichlet分布打破了FCM算法中模糊指数m必须大于1的限定,BFC算法中m值可以取任意实数.BFC模型假设每个聚类中心均满足高斯分布,聚类中心先验可以写成:


其中,符号“∝”表示两边仅相差一个不依赖于任何变量的常数因子.
2 竞争贝叶斯模糊聚类(BFCCL)
2.1 BFCCL基本思想
为了建立适用于不平衡数据分类的模糊规则前件参数学习方法,同时也为了提高所得模糊规则的准确性和可解释性,本文提出了竞争贝叶斯模糊聚类(BFCCL).BFCCL聚类的出发点为:在聚类过程中,一类样本会对另一类别的聚类中心产生排斥的影响,特别是在不同类别样本的重叠区域,一方面,聚类中心受到本类别样本的吸引而靠近该区域;另一方面,聚类中心受到异类别样本的排斥而远离该区域.这种排斥关系可表现为不同类别的聚类中心在样本叠加区域的一种竞争学习关系.当样本重叠区域的重叠密度越大时,属于不同类别的聚类中心之间的竞争力也就越大.本文将这思想融入到BFC贝叶斯概率模型中,在样本的类别标签已知的前提下,采用在两类样本交替循环执行的策略,两类的聚类中心分别作为已知数据,参与到另一类样本聚类的过程中,起到聚类中心竞争学习的作用.两类聚类中心交替影响,直至两类聚类中心都处于稳定状态.BFCCL聚类的构造原理示意图如图1所示.
2.2 目标函数的构造和参数学习方法
由图1可知,BFCCL聚类通过两类交替循环的策略实现数据集的最佳模糊划分,本节以某一类样本为例,重点阐述BFCCL聚类模型的目标函数和参数学习方法. 设给定某一类样本集,聚类数为C1,假设另一类样本的聚类中心已知,为,聚类数为C2.基于BFC模型的贝叶斯概率模型,样本XXX服从正态分布,并且每个样本具有独立的概率分布,因此BFCCL聚类中样本集XXX中数据和参数的联合概率模型可表示为式(13).

图1 BFCCL聚类的构造原理示意图Fig.1 The principle of BFCCL clustering
其中,样本集和另一类聚类中心矩阵为模型的已知数据,需构建的聚类中心矩阵和模糊隶属度矩阵是模型的参数.通过对上式取对数,可得BFCCL模型的目标函数:

结合上述联合概率模型(13)和目标函数式(14),给出如下分析和说明:
1)不同于常规聚类方法不考虑样本所带的标签信息,BFCCL模型目标函数中的前2项表示出不同类别的聚类中心间的竞争关系.在另一类样本的聚类中心已知的前提下,待求聚类中心必然会与这些已知聚类中心对模糊隶属度产生“竞争”关系,这种竞争关系可理解为不同类别聚类中心间的相互排斥关系;同时这种竞争关系能保证空间划分的清晰性和增强所得模糊规则的准确性和可解释性.
2)由图1可知,为了获得整个数据集的最佳空间划分,需在正负类样本上采取交替循环的策略来求解式(13)的最大后验值.在循环的过程中两类聚类中心相互影响,直至两类的聚类中心处于稳定状态.
3)模糊指数m起到调节竞争力强弱的作用,m的值越大,聚类中心间的竞争力就越弱;反之,m的值越小,聚类中心间的竞争力就越强.
为了获得最优模糊隶属度矩阵和聚类中心矩阵,BFCCL通过先后两次使用Metropolis-Hastings(MH)采样[27]构造一条Markov链来获得模型参数的最大后验值,其参数的学习过程如图2所示.从图2可知,该Markov链的第n次迭代的过程可主要分为3步:
图2 BFCCL参数学习示意图Fig.2 The parameter learning strategy of BFCCL
步骤1.在给定样本和聚类中心的情况下,使用Metropolis-Hastings方法对模糊隶属度进行采样:
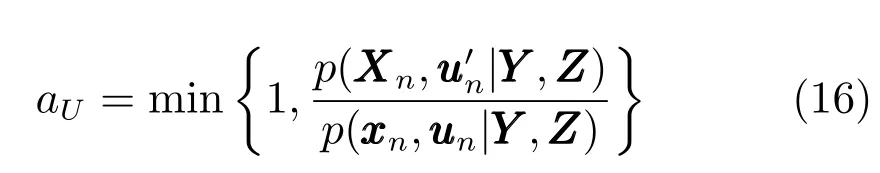

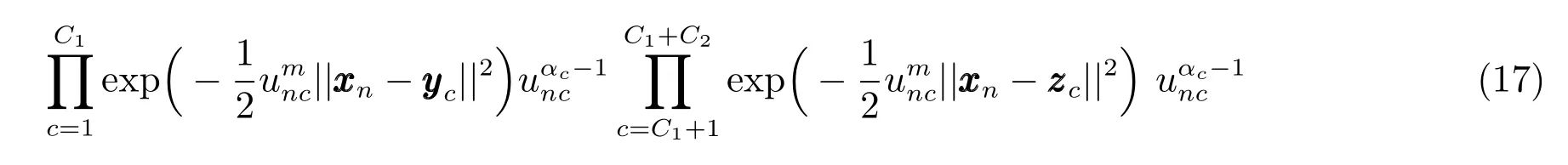
步骤2.为了获得聚类中心矩阵的最优值,BFCCL使用Metropolis-Hastings方法对进行采样:
a)通过以下正态分布对聚类中心进行采样,即
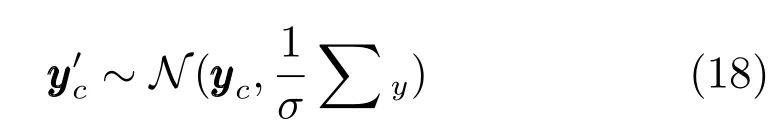
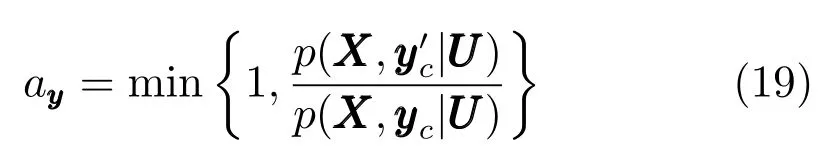

步骤3.根据式(13)计算的值并与当前的值进行比较,若,则用替换当前的.
2.3 BFCCL聚类算法
本文将研究重点置于最基本的二元分类问题.结合图1所示的BFCCL聚类构造原理示意图和第2.2节的内容,本节给出BFCCL聚类算法在整个数据集上实施的具体步骤,见算法1. 设全体样本和其对应的类别标签,其中和分别表示正负两类样本.为了获得全体样本的最佳空间划分,需在正负类上采取交替循环的策略来执行式(13).两类聚类中心交替影响,直至两类的聚类中心处于稳定状态.
BFCCL聚类采取两类样本交替循环执行的策略来获得聚类中心和模糊隶属度的最优解,BFCCL聚类中单次循环的时间复杂度主要在于步骤2的执行,而步骤2又由两部分构成:计算模糊隶属度矩阵和聚类中心矩阵,前者的时间复杂度由式(17)产生,为O(NCD+CD2);后者的时间复杂度由式(20)产生,为O(CD2).因此,BFCCL聚类算法执行的时间复杂度为O(vmaxtmax(NCD+CD2)),其中tmax和vmax分别是算法正负类交替迭代和Metropolis-Hastings采样方法中迭代的次数.另外,实验中一般可将式(18)中的协方差矩阵设为对角阵,此时,算法1的复杂度可减少至O(vmaxtmaxNCD).可见,BFCCL聚类算法运行的时间效率与样本的分布和结构有关,为了在一定程度上提高本文方法的执行效率,可以采用KPCA等降维方法对样本进行相应的预处理,或者采用正交三角(QR)等分解法对式(20)中的协方差矩阵进行变换处理.
算法1.BFCCL聚类算法
输入.正负两类数据集和,模糊指数m,正、负类样本的聚类个数分别为C(1)和C(2),MH采样最大迭代次数vmax,两类交替循环最大迭代次数tmax,误差阈值ε;
输出.模糊隶属度矩阵和聚类中心.
初始化.在数据集和分别计算正负类样本的均值和协方差;在数据集和分别进行两类模糊隶属度矩阵和进行初始化,其中矩阵中的元素矩阵中的元素;在数据集和分别对两类聚类中心矩阵和进行初始化,其中矩阵中的元素:矩阵中的元素;在数据集和分别对模糊隶属度矩阵和聚类中心矩阵的最大后验值进行初始化,;

步骤1.令
步骤2.
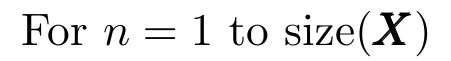
{步骤2.1.根据式(15)得到隶属度;
步骤2.2.根据式(16)计算和,并以式(17)的概率接受;
步骤2.3.根据式(17),如果,那么;
步骤2.4.如果n>N,则转至步骤2.5;否则,置n=n+1,并返回步骤2.1};
Endn
Forc=1 to size(C1)
{步骤2.5.根据式(18)采样新的聚类中心;
步骤2.6.以式(19)的概率接受;
步骤2.7.根据式(20),如果,那么;
步骤2.8.如果c>C1,则转至步骤2.9;否则,置c=c+1,返回步骤2.6;
步骤2.9.如果,那么
Endc
步骤2.10.如果t>tmax,则将和分别设置为当前样本的模糊隶属度矩阵和聚类中心矩阵的最大后验值并转至步骤3;否则,转至步骤2.1;
步骤3.令
步骤4.转向步骤2
Endt
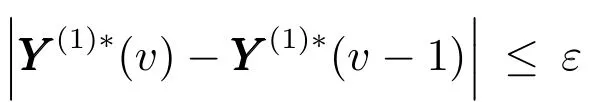
Endv.
3 用于不平衡数据分类的0阶TSK型模糊系统(0-TSK-IDC)
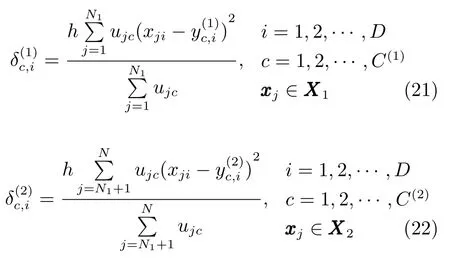
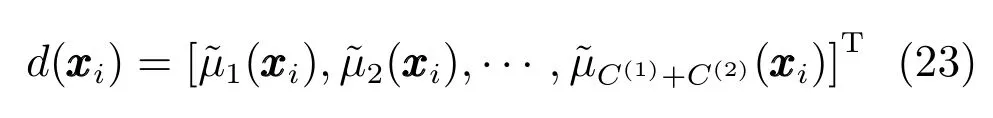
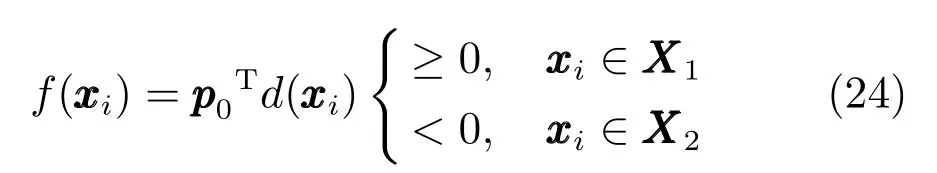
传统分类面的大间隔的策略是达到两类间距离的最大化,但这种分类面在处理不平衡分类问题中易向少数类发生偏移.为纠正分类面的偏移,本文寻找的分类面在达到两类间距离的最大化的同时,保证少数类到分类面的距离不得小于多数类到分类面的距离,其示意图如图3所示.因此后件参数的学习问题可用以下最优化问题来表示:

其中,v,λ1和λ2为 3个正常数,且λ1/λ2=N2/N1=(N−N1)/N1.
求解式(25)可以利用Lagrange技巧,引入非负的Lagrange因子方程的各变量求偏导数,并令各偏导方程为零,上述最优化问题可以转换成对偶形式:
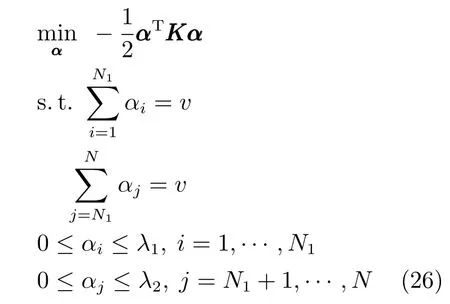

图3 0-TSK-IDC分类面示意图Fig.3 The classi fi cation hyperplane of 0-TSK-IDC
引理1[28].令是上的一个紧集,是Mercer核当且仅当是上连续对称函数且关于任意的的Gram矩阵半正定.
定理1.如果模糊系统中前件的模糊隶属函数是连续函数,则式(26)的核函数是Mercer核.
证明.根据式 (26)的定义,,容易看出是一个实对称矩阵.其次,对任意的,由式(23),有且是连续函数,因此核函数是Mercer核.
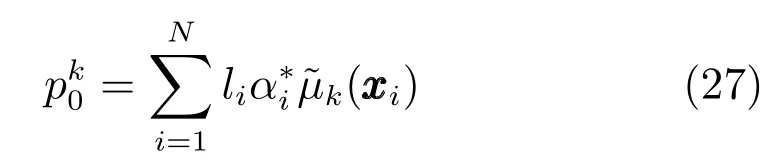

根据上文的分析和推导,0-TSK-IDC使用BFCCL算法得到准确性和可解释性强的规则前件参数,规则后件参数着眼于分类面的偏移纠正.这里总结出0-TSK-IDC模糊系统的具体训练步骤,具体如下:
算法2.0-TSK-IDC模糊系统
输入.数据集,模糊规则数(C(1)+C(2)),模糊指数m,尺度参数h,MH采样最大迭代次数vmax,两类交替循环最大迭代次数tmax,误差阈值ε,调节参数v,正则化参数λ1和λ2;
输出.分类决策函数F(xxx).
步骤 1.根据算法1得到隶属度矩阵,和聚类中心矩阵;
步骤2.由式(22)计算高斯隶属度函数的方差矩阵δ(1)和δ(2);
步骤 3.由式(3)~(5)0-TSK-IDC将原始数据集映射至特征空间形成新的数据集;
步骤 4.由式(26)求解得到Lagrange因子α;
步骤5.由式(27)得到0-TSK-IDC的后件参数;
步骤6.由式(28)得到0-TSK-IDC的决策函数.
0-TSK-IDC模糊系统的时间复杂度主要集中在算法1和二次规划求极值问题上.二次规划问题的时间复杂度为O(N3),因此,0-TSK-IDC模糊系统的时间复杂度为O(vmaxtmax(NCD+CD2)+N3).本文使用SMO(Sequential minimal optimization)[20]等分解方法处理二次规划问题,0-TSK-IDC模糊系统的时间复杂度降低至O(vmaxtmax(NCD+CD2)+N2).
需要指出的是,0-TSK-IDC模糊系统后件参数的学习策略与支持向量机(Support vector machine,SVM)[29]较为相似,但这两种方法之间存在着本质差异,0-TSK-IDC通过模糊规则完成特征空间的映射,而SVM 通过核函数直接将原始数据映射到特征空间上;其次,0-TSK-IDC分类决策函数中的参数同时也是模糊系统中模糊规则的参数,其具有高度的语义性和可解释性,这一特性是模糊系统特有的.
4 实验结果与分析
4.1 实验设置
一般认为当少数类与多数类的样本比例低于1:2时,数据集具有不平衡特征.而现实生活中的医学诊断数据往往呈现出不平衡性,本文的实验部分将利用人工Banana数据集[30]和4个UCI医学数据集[31](基本信息见表1)所示对BFCCL算法和0-TSK-IDC模糊系统进行验证和评价.依照不平衡数据分类问题中常用的设定方法,实验中将少数类指定为正类,将多数类指定为负类.

表1 数据集的基本信息Table 1 The basic information of datasets
本文的实验分成两个部分:1)0-TSK-IDC中规则前件参数学习分别使用BFCCL算法和BFC算法来进行性能的比较;2)0-TSK-IDC模糊系统与 FS-FCSVM[32]、L2-TSK-FS[25]、Adaboost[33]和 CS-SVM[34]算法进行性能的比较,其中 FSFCSVM和L2-TSK-FS是基于模糊聚类的模糊系统;Adaboost和CS-SVM 是处理不平衡数据分类的算法.为了验证本文所提的模糊规则的后件参数学习方法在不平衡分类问题上的有效性,实验中还将0-TSK-IDC模糊系统与BFCCL-TSK-FS模糊系统进行了对比,BFCCL-TSK-FS模糊系统中规则前件参数的学习使用BFCCL聚类方法;规则后件参数的学习使用与FS-FCSVM模糊系统相同的方法,即标准的SVM算法.
实验参数设置如下:0-TSK-IDC中最大迭代次数tmax=103,vmax=103,式(19)中的参数σ=3,误差阈值ε=10−5,根据文献[35]模糊指数m取值为2,此时物理意义最明确,其他可人工设定的参数通过网格搜索的方式来确定,尺度参数h取值为{0.22,0.42,···,22},调节参数v取值为{1,5,···,30},正则化参数λ2取值为{10−3,···,103},λ1的值根据λ1=λ2N2/N1来确定,模糊规则数C1和C(2)取值均为{1,2,···,10}.实验中,FS-FCSVM 和L2-TSK-FS的规则前件由FCM聚类获得,模糊指数m取值为2,规则后件学习的正则化参数的设置与λ2相同.CSSVM 算法中的核函数采用高斯核,核参数取值为{10−3,···,103}, 正则化参数的设置与λ1和λ2相同.Adaboost算法中设置弱分类器的个数为10.BFCCL-TSK-FS算法中BFCCL聚类的参数设置参照0-TSK-IDC,其他参数的设置参照FS-FCSVM.
为了更好地呈现出不同程度的非平衡性对算法性能产生的影响,本文采用G-mean和F-measure[36−37]两种评价准则来评价算法的分类性能:

其中,G-mean是关注数据集整体分类性能的评价指标,Positive Accuracy=Recall=TP/(TP+FN),Negative Accuracy=TN/(TN+FP)为真负率.F-measure是查全率和查准率的调和均值,Recall=TP/(TP+FN)为查全率,Precision=TP/(TP+FP)为查准率,β通常设置为1.这2个评价准则中用到的TP指标是指被正确分类的正类样本的数目,FN指标是指被错误分类的正类样本的数目,FP指标是指被错误分类的负类样本的数目,TN指标是指被正确分类的负类样本的数目.可见,G-mean准则可以合理地评价在保持正、负类分类精度平衡下最大化两类的精度,而F-measure准则可以合理地评价分类器对于少数类的分类性能.本文实验中每个数据集进行5折交叉验证,运行5次以平均后的G-mean和F-measure作为最终分类精度.本文的实验在2.53GHz quadcore CPU,8GB RAM,Windows 7系统下执行,所有算法均在Matlab 2009b环境下实现.
4.2 BFCCL与BFC在0-TSK-IDC模糊分类器中的性能比较
4.2.1 人工数据集
实验中构造了3组正负类比例不同的Banana数据集,即:选取全部1500个负类样本,并分别随机选取600,200,100个正类样本.图4~7是分别使用BFC和BFCCL算法正负类聚类数均为3和4时,交叉验证中某一折的聚类结果示意图,两图中正类样本分别是480,160和80个(用黑点表示),负类样本均为1200个(用灰点表示),正类和负类的聚类中心分别用黑色和白色矩形表示.可以看出:
1)当在正负两类样本中分别使用BFC算法聚类时,图4中(a)~(c)中负类样本的聚类效果完全相同,图6亦如此.同时在样本重叠区域出现了聚类中心间的距离狭小的现象,自然由此聚类效果得到的模糊规则的模糊集会存在交叉和重叠的现象.这是因为BFC聚类不考虑不同类别聚类中心间的排斥关系,运用到模糊系统前件学习中时,得到的模糊规则其清晰性得不到保证.

图4 BFC在Banana集上正负类聚类数均为3时的聚类效果Fig.4 The clustering results on the Banana dataset in BFC with three clustering on the positive and negative classes,respectively
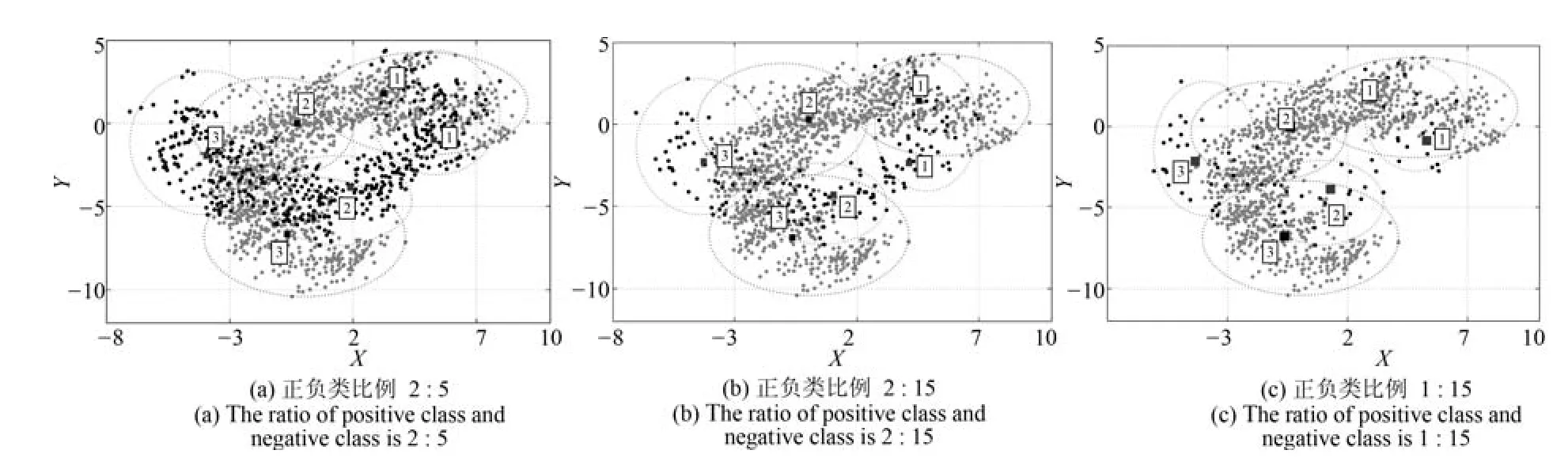
图5 BFCCL在Banana集上正负类聚类数均为3时的聚类效果Fig.5 The clustering results on the Banana dataset in BFCCL with three clustering on the positive and negative classes,respectively

图6 BFC在Banana集上正负类聚类数均为4时的聚类效果Fig.6 The clustering results on the Banana dataset in BFC with four clustering on the positive and negative classes,respectively
2)BFCCL算法考虑了在样本重叠区不同类别聚类中心的竞争关系,聚类中心由于受到另一个类别样本的排斥而尽量地远离该区域,这种排斥力最终促使正负类样本的聚类中心尽可能地远离对方样本区域,从图5和图7的聚类效果可知,随着正类样本数量和分布的变化,其对负类样本的聚类中心的排斥力的强弱也发生了变化,负类样本的聚类效果也随之受到了影响.因此在样本重叠区域不会发生聚类中心间的距离狭小的情况.
图8给出了0-TSK-IDC模糊系统基于图7(b)聚类结果所获得的模糊集示意图.我们知道,聚类中心(即模糊规则中心)的分布是决定所获得的模糊规则清晰性和可解释性的决定性因素之一.由图8可知,BFCCL聚类中的不同类别间聚类中心竞争学习的策略可以保证获得的模糊规则具有良好的可解释性.表3为0-TSK-IDC模糊系统中规则前件分别使用BFCCL与BFC算法的性能比较.根据表3结果可知,在正负类样本具有不同比例不平衡性的情况下,与BFC聚类相比,使用BFCCL聚类获得的解释性强的规则前件参数有助于提高0-TSK-IDC模糊系统的分类性能,此时G-mean和F-measure指标均有相应的提高.
4.2.2 真实数据集
为了对BFCCL聚类算法性能作进一步地探讨和分析,本节使用4个不平衡UCI医学诊断集对BFCCL与BFC算法应用到模糊规则前件参数学习时,所得的0-TSK-IDC模糊系统的分类性能进行比较.G-mean和F-measure值及其方差的比较结果如表3所示.从表3结果可知,真实数据集上的实验结果与上一节人工数据集实验上观察到的结果基本保持一致,在0-TSK-IDC模糊系统中使用BFCCL算法方法后F-measure和G-mean评价指标均高于使用BFC算法的情况,说明在使用聚类算法获取模糊规则前件参数的学习中,充分考虑不同类别聚类中心之间的竞争关系,有助于提升模糊空间划分的准确性和清晰性.

图7 BFCCL在Banana集上正负类聚类数均为4时的聚类效果Fig.7 The clustering results on the Banana dataset in BFCCL with four clustering on the positive and negative classes,respectively

图8 0-TSK-IDC基于图7(b)聚类结果的所获得模糊集示意图Fig.8 A plot of rulebase of 0-TSK-IDC from the clustering result in Fig.7(b)
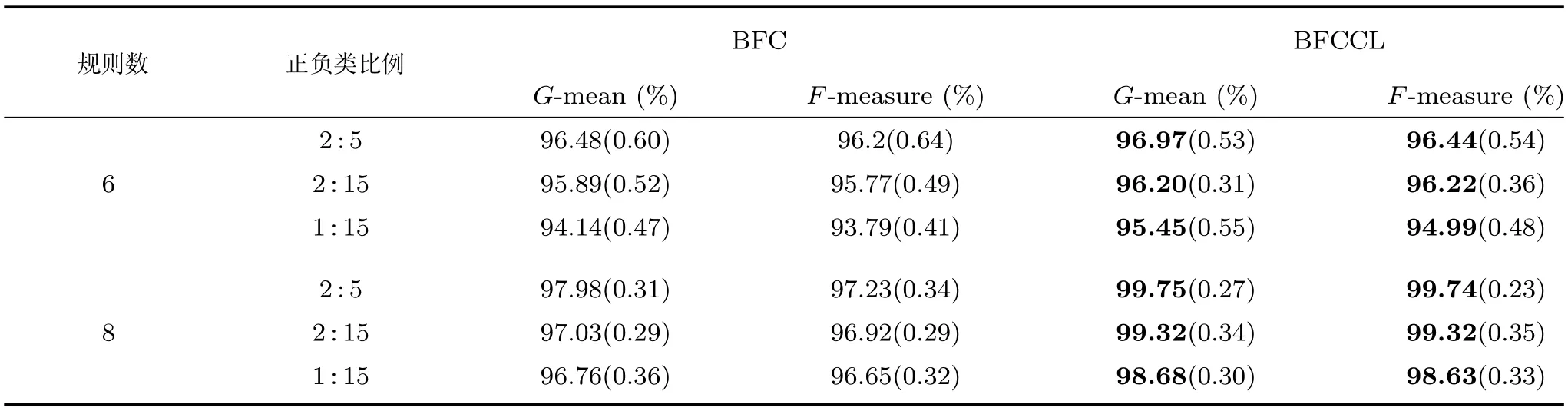
表2 Banana集上基于BFC与BFCCL图4~7聚类结果的0-TSK-IDC模糊系统中的G-mean和F-measure及其方差的比较Table 2 G-mean,F-measure and their standard deviations comparison of 0-TSK-IDC with the clustering results in Fig.4~7 by using the BFC and BFCCL on the Banana dataset

表3 UCI医学集上分别使用BFCCL与BFC得到规则前件时0-TSK-IDC模糊系统中的G-mean和F-measure值及其方差的比较Table 3 G-mean,F-measure and their standard deviations comparison of 0-TSK-IDC with BFC and BFCCL on UCI datasets
4.3 0-TSK-IDC模糊分类器与相关分类算法性能比较
为了对0-TSK-IDC模糊分类器的性能进行评估,本节对0-TSK-IDC与FS-FCSVM、L2-TSKFS、BFCCL-TSK-FS、Adaboost和CS-SVM 五种分类算法进行比较.
4.3.1 人工数据集
本节依旧采用与第4.2.1节相同的Banana数据集进行训练和测试,表4列出了6种对比算法的G-mean和F-measure指标的比较.从实验结果可以看出,随着Banana数据集中正负类不平衡比例的提高,6种算法的F-measure和G-mean指标都呈现出一定的下降趋势,可见,数据的不平衡性将严重影响分类的效果.特别是FS-FCSVM、L2-TSK-FS和BFCCL-TSK-FS算法,由于未考虑类别不平衡性,当正类样本太少而不能充分学习会导致分类面向正类样本发生了较大的偏移,其结果是正类样本的分类准确率迅速降低,因而G-mean和F-measure指标值也迅速降低.由于充分考虑了不同类别的聚类中心间的竞争学习及数据的不平衡性,本文提出的0-TSK-IDC模糊系统在分类性能上相比其他5种算法都有提高.CS-SVM算法更多地考虑少数类即正类样本的分类代价,对正类样本的识别率较高而负类样本的识别率较低;而Adaboost算法通过过采样技术来增加少数类样本的数量,由于改变了样本的分布结构容易造成分类器过拟合的情况.因此,这两种算法获得的G-mean和F-measure指标值在绝大多数情况下均落后于0-TSK-IDC.
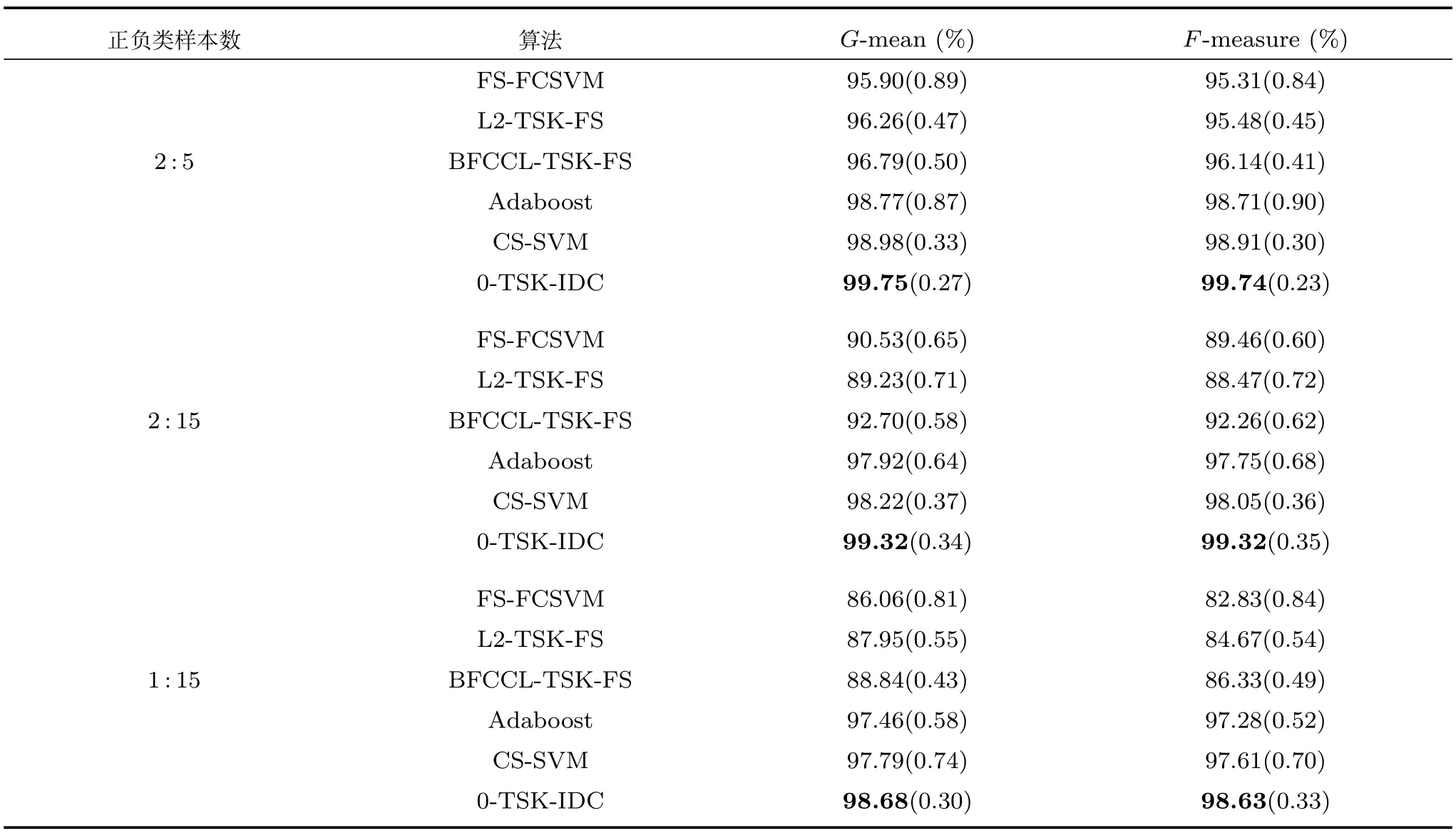
表4 Banana数据集上0-TSK-IDC模糊分类器与其他算法的G-mean和F-measure值及其方差的比较Table 4 G-mean,F-measure and their standard deviations comparison of 0-TSK-IDC and other algorithms on the Banana dataset
4.3.2 真实数据集
本节给出0-TSK-IDC、FS-FCSVM、BFCCLTSK-FS、L2-TSK-FS、Adaboost和 CS-SVM 算法在4个UCI医学诊断数据集上的性能比较,G-mean和F-measure变化曲线如图9和图10所示.从实验结果可以看出,
1)UCI数据集上获得的实验结果与人工数据集的实验结果是一致的.本文所提的0-TSK-IDC在不同程度的类别不平衡场合均表现出优良的分类性能;特别对不平衡性较大的数据集,0-TSK-IDC更能体现其较强的鲁棒性.其原因在于0-TSK-IDC模糊系统前件参数的学习使用了BFCCL聚类,BFCCL聚类通过类别间竞争学习的策略能合理获取不平衡两类上的空间划分,能保证获得的模糊规则中的模糊集的准确性和可解释性;0-TSK-IDC模糊系统后件参数的学习从纠正分类面的偏移入手,最终得到的分类面在达到两类间距离的最大化的同时,保证少数类到分类面的距离不小于多数类到分类面的距离.
2)真实数据集上类别间样本数量的不平衡性严重影响算法的分类性能,如图9和图10所示,随着实验中类别不平衡性的加剧,三种模糊系统FS-FCSVM、L2-TSK-FS和BFCCL-TSK-FS得到的G-mean和F-measure值也急剧下降.但由于BFCCL-TSK-FS能够借助BFCCL聚类算法得到准确的空间划分结果,所以其分类效果要优于FS-FCSVM和L2-TSK-FS,具体表现为BFCCLTSK-FS在4个UCI数据集上获得的G-mean和F-measure值均高于FS-FCSVM和L2-TSK-FS获得的值.
3)Adaboost和CS-SVM算法在G-mean和F-measure值上得到的结果较为相近,与FSFCSVM、L2-TSK-FS和BFCCL-TSK-FS这三种模糊系统相比,两者具有明显的优势;但与0-TSKIDC相比两者的性能略差.值得注意的是,0-TSKIDC模糊系统另一个突出优点是其构建的模糊规则具有高度的可解释性,而这一特性是Adaboost和CS-SVM算法所不具备的.
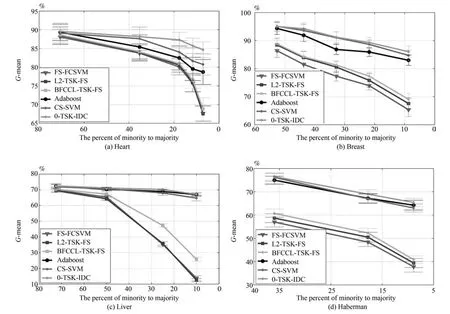
图9 UCI医学集上不同算法的G-mean比较Fig.9 G-mean and its standard deviation comparison of 0-TSK-IDC and other algorithms on UCI dataset

图10 UCI医学集上不同算法的F-measure比较Fig.10 F-measure and its standard deviation comparison of 0-TSK-IDC and other algorithms on UCI dataset
为了进一步考察在真实数据集上0-TSK-IDC构建的模糊规则的可解释性,图11给出了Heart集正负类样本数6:17、Breast集正负类样本数75:229、Liver正负类样本数1:4和Haberman集正负类样本数8:45时,G-mean指标随规则数变化的曲线.可以看出,图9中0-TSK-IDC模糊系统识别率最高时所需的模糊规则数分别是7、12、7和6.模糊系统的特点是建立分类性能和模糊规则数之间的平衡,通常情况下规则数越少的模糊系统其可解释性越强,图11的实验结果可以说明从规则数角度看0-TSK-IDC模糊系统具有高度的可解释性.
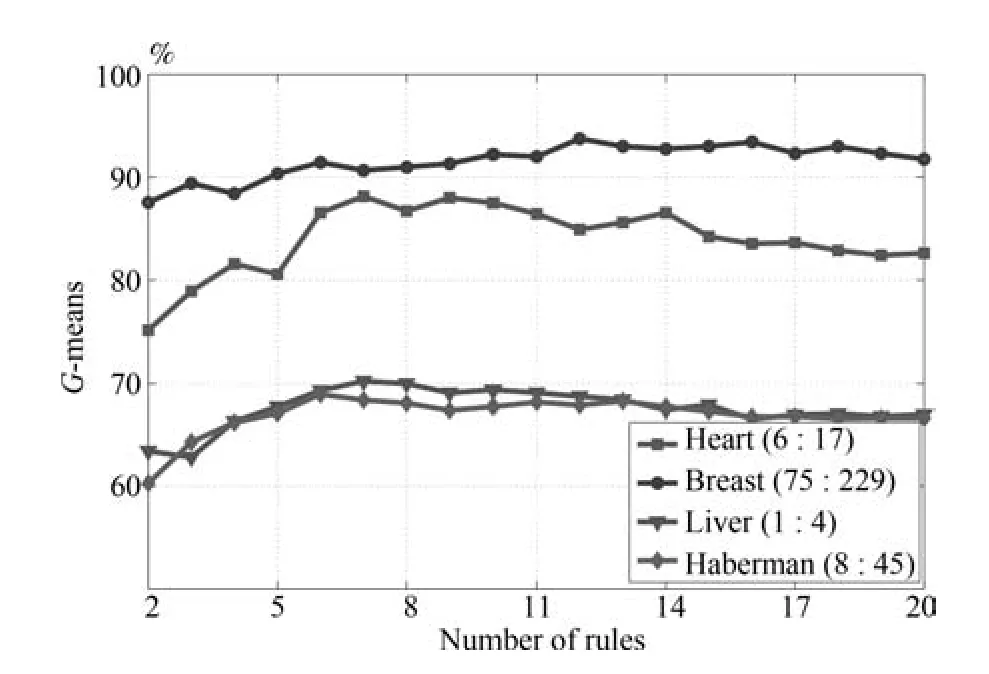
图11 UCI医学集上G-mean随规则数变化的示意图Fig.11 G-mean with the different fuzzy rules on UCI databases
5 结论
本文提出的0-TSK-IDC模糊系统利用BFCCL算法进行模糊规则前件参数的学习,使基于聚类中心竞争机制和概率模型的聚类算法在类别不平衡的空间划分中表现出了清晰性和可解释性;0-TSKIDC模糊系统在模糊规则后件参数的学习中,使用了“大间隔”的机制并设置少数类到分类面的距离大于多数类到分类面的距离,从而使得0-TSK-IDC具有较强的泛化能力.本文的主要贡献可以归纳为:1)建立一种利用概率模型改进模糊系统的框架;2)提出了一种利用聚类模糊系统解决不平衡分类问题的方法.另外,0-TSK-IDC模糊系统亦可处理类别平衡的分类问题,只要设置式(23)和(24)中参数v为0即可.对于多分类问题,0-TSK-IDC可以采用类似于SVM 方法,用类别组合的方式来实现.应当指出,本文对0-TSK-IDC模糊系统能否有效解决大样本等问题没有进行深入探讨,当样本容量极大时,若从聚类速度和二次规划求解角度而言,0-TSK-IDC仍面临进一步提高实用性的挑战,这将作为我们近期的研究重点.
1 Richardson J,Korniak J,Reiner P D,Wilamowski B M.Nearest-neighbor spline approximation(NNSA)improvement to TSK fuzzy systems.IEEE Transactions on Industrial Informatics,2016,12(1):169−178
2 Deng Z H,Cao L B,Jiang Y Z,Wang S T.Minimax probability TSK fuzzy system classi fi er:a more transparent and highly interpretable classi fi cation model.IEEE Transactions on Fuzzy Systems,2015,23(4):813−826
3 Jia Li,Yang Ai-Hua,Qiu Ming-Sen.Research on multisignal based neuro-fuzzy Hammerstein-Wiener model.Acta Automatica Sinica,2013,39(5):690−696(贾立,杨爱华,邱铭森.基于多信号源的神经模糊Hammerstein-Wiener模型研究.自动化学报,2013,39(5):690−696)
4 Liu Y J,Tong S C,Chen C L P,Li D J.Neural controller design-based adaptive control for nonlinear MIMO systems with unknown hysteresis inputs.IEEE Transactions on Cybernetics,2016,46(1):9−19
5 Cheng W Y,Juang C F.A fuzzy model with online incremental SVM and margin-selective gradient descent learning for classi fi cation problems.IEEE Transactions on Fuzzy Systems,2014,22(2):324−337
6 Jiang Y Z,Chung F L,Ishibuchi H,Deng Z H,Wang S T.Multitask TSK fuzzy system modeling by mining intertask common hidden structure.IEEE Transactions on Cybernetics,2015,45(3):534−547
7 Liu Y J,Tong S C.Adaptive fuzzy control for a class of unknown nonlinear dynamical systems.Fuzzy Sets and Systems,2015,263:49−70
8 Wong S Y,Yap K S,Yap H J,Tan S C,Chang S W.On equivalence of FIS and ELM for interpretable rule-based knowledge representation.IEEE Transactions on Neural Networks and Learning Systems,2015,26(7):1417−1430
9 Leski J M.TSK-fuzzy modeling based onε-insensitive learning.IEEE Transactions on Fuzzy Systems,2005,13(2):181−193
10 Leski J M.Fuzzy(c+p)-means clustering and its application to a fuzzy rule-based classi fi er:toward good generalization and good interpretability.IEEE Transactions on Fuzzy Systems,2015,23(4):802−812
11 Fern´andez A,del Jesus M J,Herrera F.On the 2-tuples based genetic tuning performance for fuzzy rule based classi fi cation systems in imbalanced data-sets.Information Sciences,2010,180(8):1268−1291
12 Fern´andez A,del Jesus M,Herrera F.Hierarchical fuzzy rule based classi fi cation systems with genetic rule selection for imbalanced data-sets.International Journal of Approximate Reasoning,2009,50(3):561−577
13 Ramentol E,Caballero Y,Bello R,Herrera F.SMOTERSB∗:a hybrid preprocessing approach based on oversampling and undersampling for high imbalanced data-Sets using SMOTE and rough sets theory.Knowledge and Information Systems,2012,33(2):245−265
14 L´opez V,Fern´andez A,del Jesus M,Herrera F.A hierarchical genetic fuzzy system based on genetic programming for addressing classi fi cation with highly imbalanced and borderline datasets.Knowledge Based Systems,2013,38:85−104
15 Galar M,Fern´andez A,Barrenechea E,Herrera F.EUSBoost:enhancing ensembles for highly imbalanced data-sets by evolutionary undersampling.Pattern Recognition,2013,46(12):3460−3471
16 Chawla N V,Bowyer K W,Hall L O,Kegelmeyer W P.SMOTE:synthetic minority over-sampling technique.Journal of Arti fi cial Intelligence Research,2002,16(1):321−357
17 Sun Y M,Kamel M S,Wong A K C,Wang Y.Costsensitive boosting for classi fi cation of imbalanced data.Pattern Recognition,2007,40(12):3358−3378
18 Tang Y C,Zhang Y Q,Chawla N V,Krasser S.SVMs modeling for highly imbalanced classi fi cation.IEEE Transactions on Systems,Man,and Cybernetics,Part B:Cybernetics,2009,39(1)281−288
19 Deng Z H,Jiang Y Z,Chung F L,Ishibuchi H,Wang S T.Knowledge-leverage-based fuzzy system and its modeling.IEEE Transactions on Fuzzy Systems,2013,21(4):597−609
20 Zhu L,Chung F L,Wang S T.Generalized fuzzy C-means clustering algorithm with improved fuzzy partitions.IEEE Transactions on Systems,Man,and Cybernetics,Part B:Cybernetics,2009,39(3):578−591
21 Deng Z H,Choi K S,Chung F L,Wang S T.Enhanced soft subspace clustering integrating within-cluster and betweencluster information.Pattern Recognition,2010,43(3):767−781
22 Glenn T C,Zare A,Gader P D.Bayesian fuzzy clustering.IEEE Transactions on Fuzzy Systems,2015,23(5):1545−1561
23 Jiang Yi-Zhang, Deng Zhao-Hong, Wang Shi-Tong.Mamdani-Larsen type transfer learning fuzzy system.Acta Automatica Sinica,2012,38(9):1393−1409(蒋亦樟,邓赵红,王士同.ML型迁移学习模糊系统.自动化学报,2012,38(9):1393−1409)
24 Azeem M F,Hanmandlu M,Ahmad N.Generalization of adaptive neuro-fuzzy inference systems.IEEE Transactions on Neural Networks,2000,11(6):1332−1346
25 Deng Z H,Choi K S,Chung F L,Wang S T.Scalable TSK fuzzy modeling for very large datasets using minimalenclosing-ball approximation.IEEE Transactions on Fuzzy Systems,2011,19(2):210−226
26 Hall L O,Goldgof D B.Convergence of the single-pass and online fuzzy C-means algorithms.IEEE Transactions on Fuzzy Systems,2011,19(4):792−794
27 Meyn S P,Tweedie R L.Markov Chains and Stochastic Stability.London:Springer,1993.
28 Nesterov Y.Introductory Lectures on Convex Optimization:A Basic Course.US:Springer,2004.
29 Vapnik V N.Statistical Learning Theory.New York:Wiley,1998.
30 Ni T G,Chung F L,Wang S T.Support vector machine with manifold regularization and partially labeling privacy protection.Information Sciences,2015,294:390−407
31 UCI database[Online],available:http://www.ics.uci.edu/.
32 Juang C F,Chiu S H,Shiu S J.Fuzzy system learned through fuzzy clustering and support vector machine for human skin color segmentation.IEEE Transactions on Systems,Man,and Cybernetics-Part A:Systems and Humans,2007,37(6):1077−1087
33 Wang S,Yao X.Multiclass imbalance problems:analysis and potential solutions.IEEE Transactions on Systems,Man,and Cybernetics,Part B:Cybernetics,2012,42(4):1119−1130
34 Masnadi-Shirazi H,Vasconcelos N,Iranmehr A.Costsensitive support vector machines.Journal of Machine Learning Research,2012,arXiv:1212.0975
35 Bezdek J C.A physical interpretation of fuzzy ISODATA.IEEE Transactions on Systems,Man,and Cybernetics,1976,SMC-6(5):387−389
36 Sun Z B,Song Q B,Zhu X Y,Sun H L,Xu B W,Zhou Y M.A novel ensemble method for classifying imbalanced data.Pattern Recognition,2015,48(5):1623−1637
37 Parambath S A P,Usunier N,Grandvalet Y.Optimizing F-measures by cost-sensitive classi fi cation.In: Proceedings of Advances in Neural Information Processing Systems 27.Montreal,Canada:Curran Associates,Inc.,2014.2123−2131
猜你喜欢
杂志排行

自动化学报的其它文章
- Convolutional Sparse Coding in Gradient Domain for MRI Reconstruction
- 视频中旋转与尺度不变的人体分割方法
- Bayesian Saliency Detection for RGB-D Images
- Interactive Multi-label Image Segmentation With Multi-layer Tumors Automata
- 双时间尺度下的设备随机退化建模与剩余寿命预测方法
- Robust H∞Consensus Control for High-order Discrete-time Multi-agent Systems With Parameter Uncertainties and External Disturbances