多核SMP集群混合并行编程技术的研究*
2017-03-10祝永志
刘 超,祝永志
(曲阜师范大学 信息科学与工程学院,山东 日照276826)
多核SMP集群混合并行编程技术的研究*
刘 超,祝永志
(曲阜师范大学 信息科学与工程学院,山东 日照276826)
目前,高性能计算领域中大多数系统采用层次化硬件设计,具有若干多核CPU共享存储的节点通过高速网络互联起来。混合并行编程技术将节点间的分布式存储与节点内的共享存储进行了融合。针对多核SMP集群体系结构的特点,进一步研究了适用于多核SMP集群的层次化混合并行编程模型MPI/OpenMP,以及多核SMP节点间和节点内多级并行的机制。充分利用消息传递编程模型和共享内存编程模型各自的优势,在此基础上研究了多粒度并行化编程方法。
多核SMP集群;混合编程;MPI/OpenMP
0 引言
随着CMP技术的发展以及SMP集群体系结构的推广,融合SMP与MPP双重特点的多核SMP集群成为高性能计算(HPC)领域广泛采用的新型多核体系架构与主流研发趋势。这种分布式存储与共享存储相结合的体系架构继承了MPP在性能和可扩展性上的优势,改善了SMP可扩展性差的缺点,同时又具有集群高效通信的优点[1]。这种节点间使用消息传递和节点内利用共享内存的多级混合并行编程模型,更好地匹配了多核SMP集群特点。

图1 多核SMP集群体系架构
图1显示了具有N个节点(每个节点为两个四核CPU,圆形表示处理器内核)的多核SMP集群体系结构。处理器之间通过BUS/CROSSBAR互联,并共享内存区域与I/O设备。多核SMP节点通过高速通信网络(如Myrinet、以太网等)连接,节点间利用消息传递进行通信[2]。
1 混合平台上的并行编程模型
严格来说,一个并行编程模型是计算机系统结构的抽象[3],它不依赖于任何特定的机器类型。但因CPU的组合方式不同,建立起的并行系统会产生许多可能的并行编程模型。图2显示了混合平台上并行编程模型的分类。
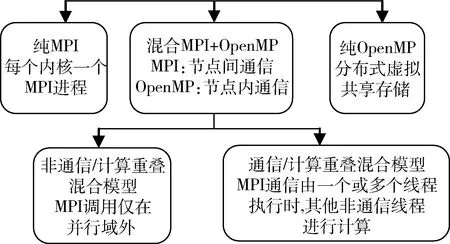
图2 混合架构并行编程模型的分类
1.1 共享存储编程模型 OpenMP
常见的共享内存编程标准为OpenMP,它是为在多处理机上编写并行程序而设计的API,其目的是易于共享存储并行编程。通过在源程序代码中加入指导性注释(Compiler Directive)、编译指导指令#pragma行来指定程序的并发性。在OpenMP中,线程并行已高度结构化,常采用Fork-Join并行执行模式[4]:首先由一个主线程串行运行程序,当需要并行计算时,派生的若干从线程与主线程共同并行执行任务。在执行结束后派生的从线程同步或中断,控制流重回主线程中,如图3所示。

图3 Fork-Join并行执行模式
OpenMP的特点为:隐式通信;高层次抽象;支持增量并行;可扩展性高,移植性好;支持粗粒度和细粒度并行;面向应用的同步原语,易于编并行程序;不仅能在共享存储系统使用,也能在非共享存储结构上实现,只是效率不同。
1.2 消息传递编程模型 MPI
常见的消息传递编程标准为MPI(Message Passing Interface),它并不是一种编程语言,而是绑定在Fortran语言或C语言中的消息传递库以及API接口,其目的是服务于进程间通信。对于分布式存储系统而言,MPI是一种自然的编程模型,而且能够实现SPMD并行模型,常采用Master-Woker工作模式:Master进程把数据分配给Worker进程;所有的Worker进程接收相应的数据;每个Worker进程进行数据计算;Worker进程将结果发送给主进程[5]。应用程序的每次迭代都是重复这个逻辑,根据问题的性质,Master进程可能必须等待来自所有Worker进程的结果之后才能发送新的数据,如图4所示。

图4 Master-Work工作模式
MPI特点是:显式通信;效率高,移植性好;特别适用于粗粒度并行;多种优化的组通信库函数;通过在计算/通信的叠加,以提升并行性能。能在分布式存储系统与共享存储系统上运行; 用户控制对数据的划分和进程的同步。
OpenMP与MPI的主要特点对比如表1所示。

表1 OpenMP与MPI模型主要特点对比
1.3 OpenMP/MPI混合编程模型
结合多核SMP集群层次化存储的结构特点,充分利用上述两种编程模型的优势:共享存储模型的编程效率与分布式存储模型的可扩展性。基本思想是:(1)将问题规模进行MPI划分,形成通信不密集的若干子任务;(2)将每个子任务(即一个MPI进程)分配到一个多核SMP节点上,节点之间依靠消息传递进行通信;(3)在每个节点上使用OpenMP编译制导语句将子任务再次划分,并分配到节点的不同处理核心上由多线程并行执行,节点内利用共享变量进行通信,如图5所示。
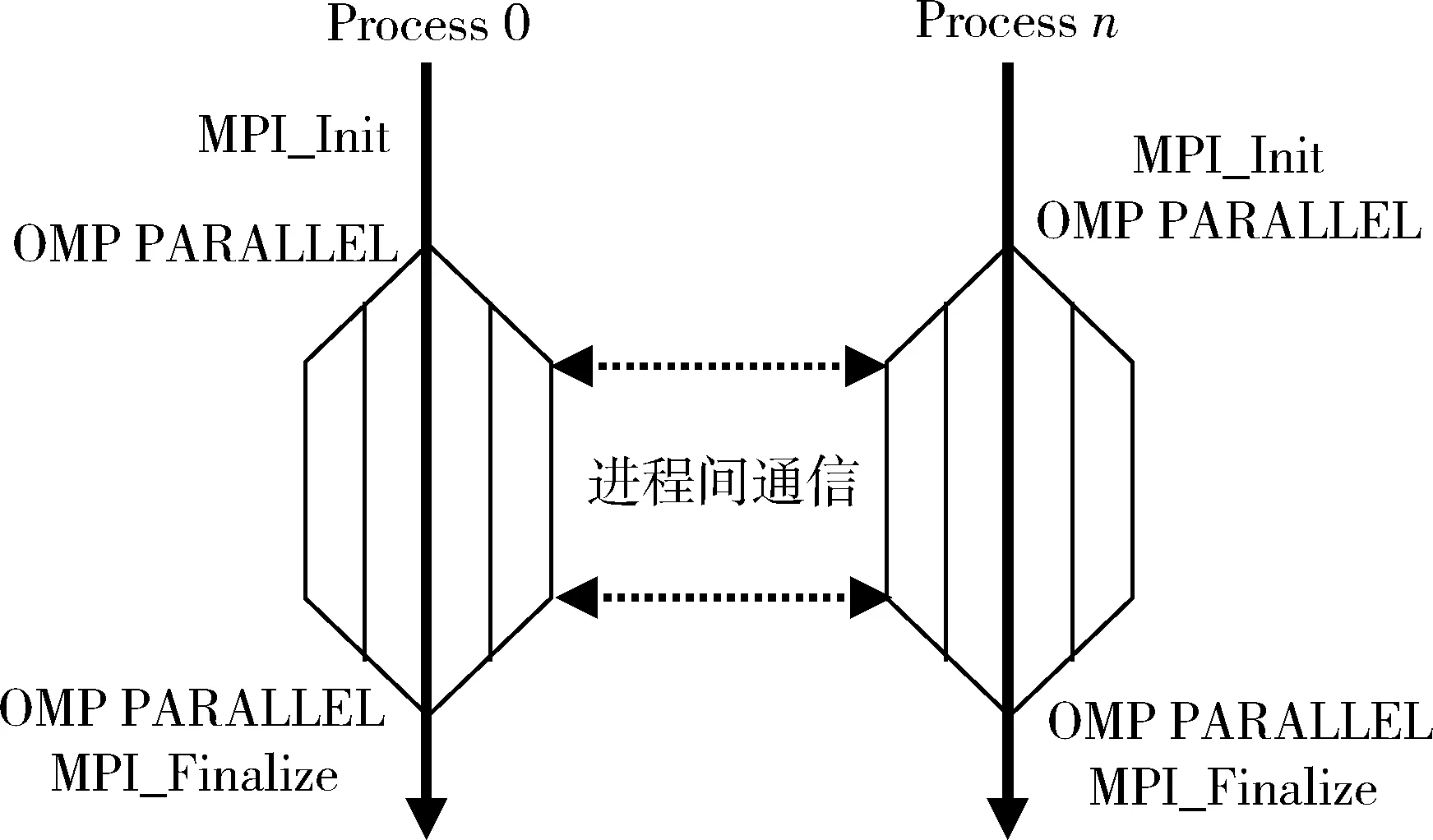
图5 Hybrid MPI/OpenMP编程模型
Hybrid MPI/OpenMP编程模型的优势:
(1)匹配当前硬件的发展趋势——多核和多处理器计算机;
(2)明确两个并行层次:粗粒度(适用于MPI)和细粒度(适用于OpenMP);
(3)某些应用或系统特点可能会限制MPI进程数量(可扩展性问题),因此OpenMP可以提供增量并行;
(4)有些应用在MPI层工作负载不平衡,OpenMP通过分配不同数量的线程到MPI进程以解决此问题;
(5)OpenMP避免了由MPI计算节点引起的额外通信开销。
在现有MPI代码中引入OpenMP意味着同时引入OpenMP的一些缺陷:
(1)控制任务分配与同步时的限制;
(2)线程创建和同步产生的开销;
(3)对编译器的依赖以及对OpenMP运行时库的支持;
(4)共享存储问题;
(5)MPI与OpenMP运行时库相互作用可能对程序性能产生负面影响。
大部分的Hybrid代码基于一个层次模型,这使得在MPI层利用大中型粒度并行和OpenMP层利用细粒度并行成为可能。在高层次,程序被显示地构造为若干MPI任务,其顺序代码中引入OpenMP制导指令,加入多线程以利用共享存储的特点。这种编程模型根据通信与计算之间是否重叠分为两类:
(1)无计算/通信重叠。这类又分为两种方式:①只在并行域和主线程外调用MPI。优点是SMP节点内没有消息传递。缺点是效率低,即在主线程进行通信时,其他线程进入休眠,没有实现计算/通信的重叠。②应用程序代码在并行域外调用MPI,但MPI通信由多个CPU完成。MPI通信线程可由MPI库自动完成或由使用线程安全的MPI库的应用程序显示完成。该方式示意图如图6所示。

图6 无计算/重叠编程方式
(2)计算/通信重叠。为了避免MPI通信期间计算线程闲置而从OpenMP线程组中分离出一个或多个线程来处理与计算并行的通信,此时MPI函数的调用应在Critical、Master 或 Single相应的区域内。有两种方法:①当通信由主线程(或几个线程)执行时,所有通信都注入到主线程,其他所有非通信线程执行数据计算任务;②当每个线程都有通信需求时,通信会注入到多个线程。计算/重叠编程方式示意图如图7所示。

图7 计算/重叠编程方式
2 层次化混合编程的实现
解决混合并行编程所存在问题的核心策略就是标准,从这个角度来看,有分布式存储编程MPI和共享式存储OpenMP,这就构成了开发混合编程的策略基础。利用现有的MPI或OpenMP代码构建混合并行应用程序,具体方法如下:
(1)使用OpenMP改良MPI。这是一种简单的混合编程实现方式,仅需将OpenMP编译制导指令插入原循环代码段外部。其性能取决于能被OpenMP并行求解的循环部分的计算量(通常是细粒度并行)。这种方式有利于通信绑定的应用程序,因为其减少了需要进行通信的MPI进程数。但是,如果程序中循环较多,使用的编译指令也将随之增多,创建并行域或线程同步的开销将会增大[6]。因此,在进行循环级并行化时,应首选全局时间中计算时间占比较大的循环[7]。以下是细粒度伪混合程序代码:
#include"mpi.h"
#include"omp.h"
......
//一些计算和MPI通信
#pragma omp paralle num_threads(...)
#pragam omp for private(...)
for(...)
{ //计算 }
//一些计算和MPI通信
......
MPI_Finalize();
(2)使用MPI改良OpenMP。这种方法(粗粒度并行)不同于前一个,需要考虑每个进程如何与其他进程通信,它可能需要完全重新设计并行性。编译制导指令通常在程序的最外层,OpenMP线程紧随MPI进程而生成,生成的线程与SPMD模式中的进程较为相似,即在不同的数据上执行相同的代码段。与SPMD的不同之处在于多核SMP节点内各处理器共享存储,无需预分配数据到各处理器上。此方法优点是OpenMP编译制导指令使用较少,调用与通信开销较低。然而,OpenMP多线程的使用类似于MPI多进程的使用,特别是当使用混合模型中多级并行机制时,编程复杂性则会增大。以下是OpenMP部分伪混合代码:
......
omp_set_num_threads(...)
#pragma omp paralle private(...)
th_id=omp_get_thread_num();
th_size=omp_get_num_threads();
......
for(...)
{..//计算}
#pargma omp barrier
#pargma omp master/single
{...//MPI通信}
......//MPI通信
......
3 实验
考虑到性能和易用性两方面的因素,本文从整体上采用类似SMPD的模式:节点内OpenMP细粒度并行与节点间MPI粗粒度并行,即Hybrid OpenMP/MPI层次化编程。选取矩阵乘法为案例,在矩阵规模和执行内核数量不同的情况下对比Non-hybirid混合编程所表现出的性能差异。
3.1 曙光TC5000高性能计算集群系统
曙光TC5000集群系统整体计算能力为5.7万亿次, 一台A620r-H作为管理节点,6台CB65作为计算节点,一套磁盘阵列提供存储。每个刀片计算节点有两颗AMD Opteron6128 2 GHz四核处理器,共计8核,整个集群配有144 GB内存。
集群软件环境:SUSE Linux Enterprise Server 10SP操作系统; 并行环境:MPI版本为MPICH2, GCC4.2.4编译器;NFS文件共享服务;InfiniBand高速计算网络管理并行通信等。
3.2 实验及结果分析
使用集群中6个双路四核计算节点运行MPI代码与MPI/OpenMP代码进行对比测试。运行混合MPI/OpenMP代码时,每个计算节点分配一个MPI进程和8个线程(节点内的线程数不应超过物理处理器个数[7])。应当注意到,在矩阵相乘计算的核心部分,可以认为两个循环都可以并行执行。如果将内部循环并行,程序在外部循环的每次迭代中都进行线程的Fork-Join操作,这样做的开销可能高于将内部循环在多线程间并行化所节省的时间;若对外层循环并行化,将使用一次Fork-Join操作,并可使程序有更大的粒度。程序中使用的矩阵规模分别为500×500,1 000×1 000,1 500×1 500。如表2所示,表中每个时间点对应的值都是该程序运行五次的平均值。从图8可以清晰地看到在使用不同节点数时混合MPI/OpenMP程序与MPI程序的加速比。随着节点数的增加,混合编程的加速比明显高于纯MPI的加速比。因为在运行MPI程序时CPU的利用率较低,并未充分利用处理器资源;而混合编程中CPU利用率较高,这进一步验证了在多核处理器中使用OpenMP多线程对程序性能的影响(这些结果是在没有任何优化措施的情况下得到的)。

表2 执行时间与加速比

图8 MPI与MPI/OpenMP
4 结论
本文分析了多核SMP集群并行体系结构的特点,研究适用于多核SMP集群的混合并行编程模型,针对MPI程序存在负载不平衡与可扩展性差的问题,使用OpenMP改造MPI程序,这种细粒度并行化的MPI+OpenMP更容易实现且能提高程序性能。目前尚不清楚这种编程技术对多核SMP集群而言是否是最为有效的机制,还有很多问题尚待解决,这需要进一步研究。
[1] 孙凝晖, 李凯, 陈明宇. HPP:一种支持高性能和效用计算的体系结构[J]. 计算机学报, 2008,31(9): 1503-1508.
[2] RABENSEIFNER R, HAGER G, JOST G. Hybrid MPI/OpenMP parallel programming on clusters of multi-core SMP nodes[C]. Proceedings of 17th Euromicro International Conference on Parallel, Distributed, and Network-based Processing. 2009:427-436.
[3] KOTOBI A, ABDUL H N A W, OTHMAN M, et al. Performance analysis of hybrid OpenMP/MPI based on multi-core cluster architecture[C]. 2014 International Conference on,Computational Science and Technology (ICCST). IEEE, 2015:1-6.
[4] MATTSON T G, SANDERS B A, MASSINGILL B. Patterns for parallel programming[M]. Addison-Wesley Professional, 2005.
[5] CASTELLANOS A, MORENO A, SORRIBES J, et al. Performance model for Master/Worker hybrid applications on multicore clusters[C]. IEEE International Conference on High Performance Computing and Communications, 2013:210-217.
[6] 祝永志. 多核SMP集群Hybrid并行编程模式的研究与分析[J]. 电子技术, 2016(2):72-75.
[7] 陈勇, 陈国良, 李春生,等. SMP机群混合编程模型研究[J]. 小型微型计算机系统, 2004, 25(10):1763-1767.
Research on hybrid parallel programming technology on multi-core SMP cluster
Liu Chao,Zhu Yongzhi
(School of Information Science and Engineering, Qufu Normal University, Rizhao 276826,China)
Currently, the majority of high-performance computing systems use hierarchical hardware design. Nodes have a plurality of multi-core CPU shared memory interconnect by high-speed network. Hybrid parallel programming technology fuses inter-nodes of distributed memories and intra-nodes of sharing memories. Therefore, according to the characteristics of multi-core SMP cluster architecture, this paper further studies the hierarchy hybrid parallel programming model MPI/OpenMP applied to multi-core SMP cluster, and multi-core SMP inter-nodes and intra-nodes multi-level parallelism mechanisms. On the basis of making full use of respective advantages of message passing programming model and shared-memory programming model, this paper studies a multi-granularity parallel programming method.
multi-core SMP cluster; hybrid programming; MPI/OpenMP
山东省自然科学基金(ZR2013FL015)
TP301
A
10.19358/j.issn.1674- 7720.2017.04.006
刘超,祝永志.多核SMP集群混合并行编程技术的研究[J].微型机与应用,2017,36(4):18-21.
2016-08-31)
刘超(1984-),男,硕士研究生,主要研究方向:并行计算。
祝永志(1964-),男,硕士,教授,主要研究方向:分布式数据库,并行与分布式计算。
